前提知識
1、解決回圈依賴的核心依據:實體化和初始化步驟是分開執行的
2、實作方式:三級快取
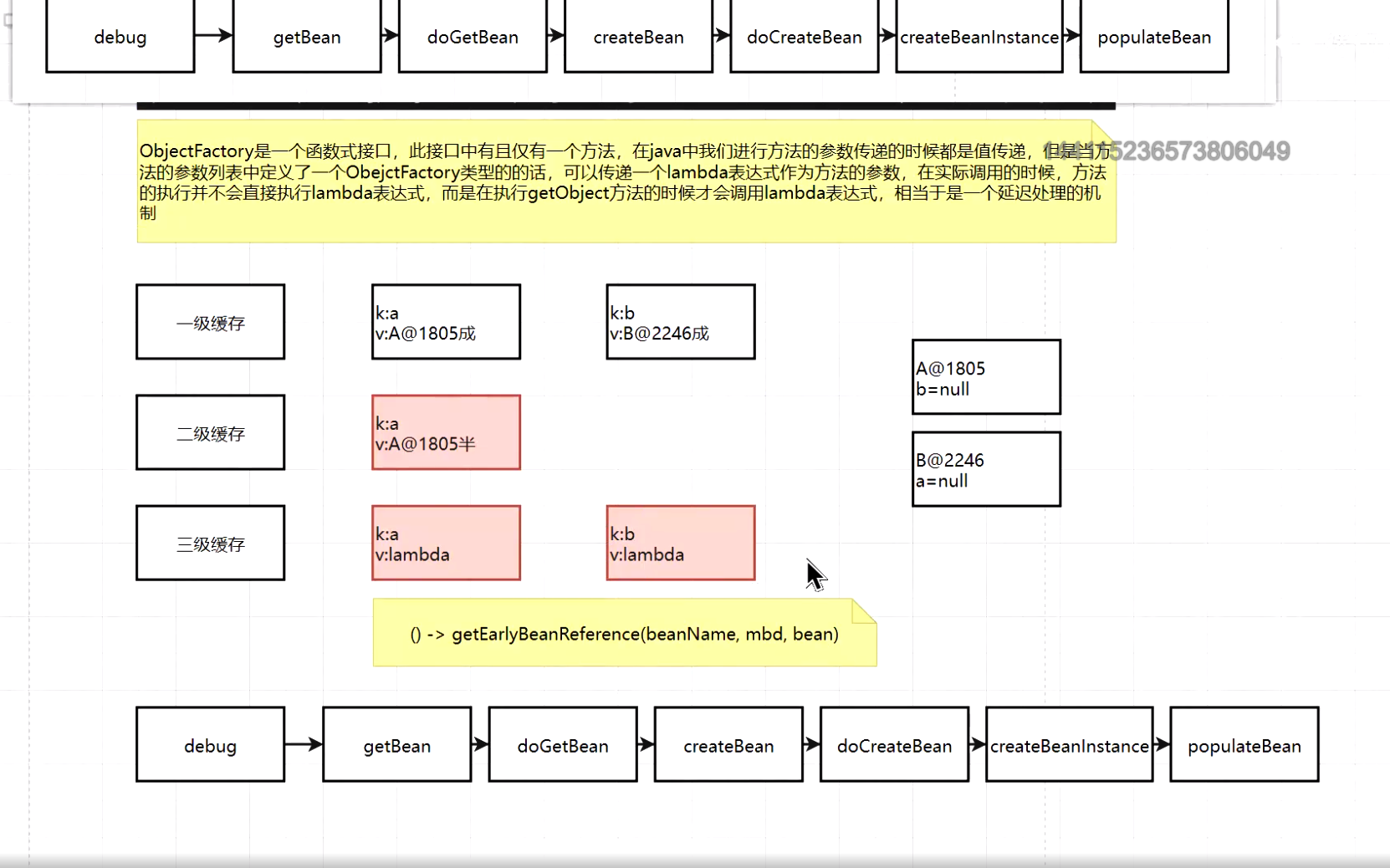
3、lambda運算式的延遲執行特性
spring原始碼執行邏輯

核心方法refresh(), populateBean()填充bean物件,設定屬性值;
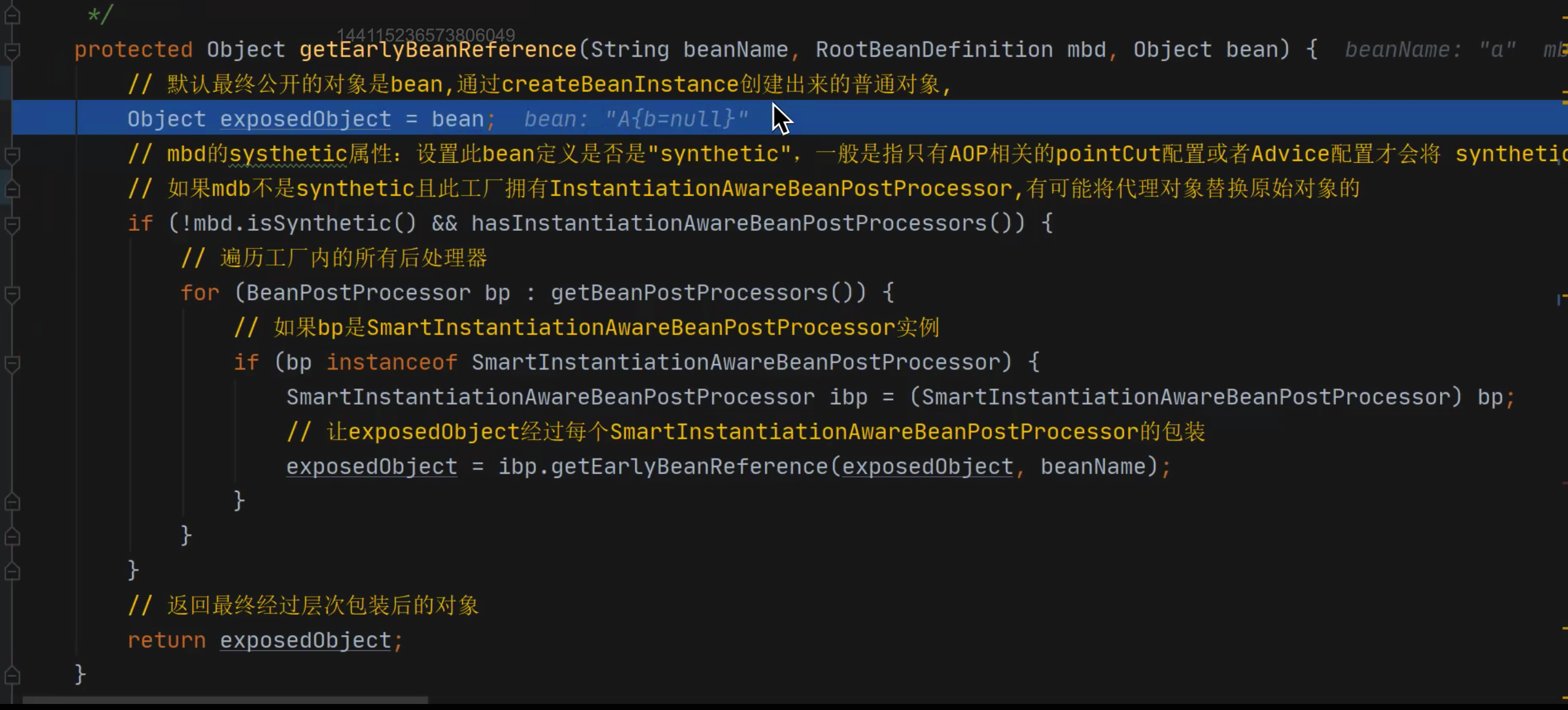
getEarlyBeanReference() 在未完成屬性賦值之前,提前暴露代理物件,在賦值的時候才確定真實物件,
1、三個map結構分別存盤什么型別的物件?
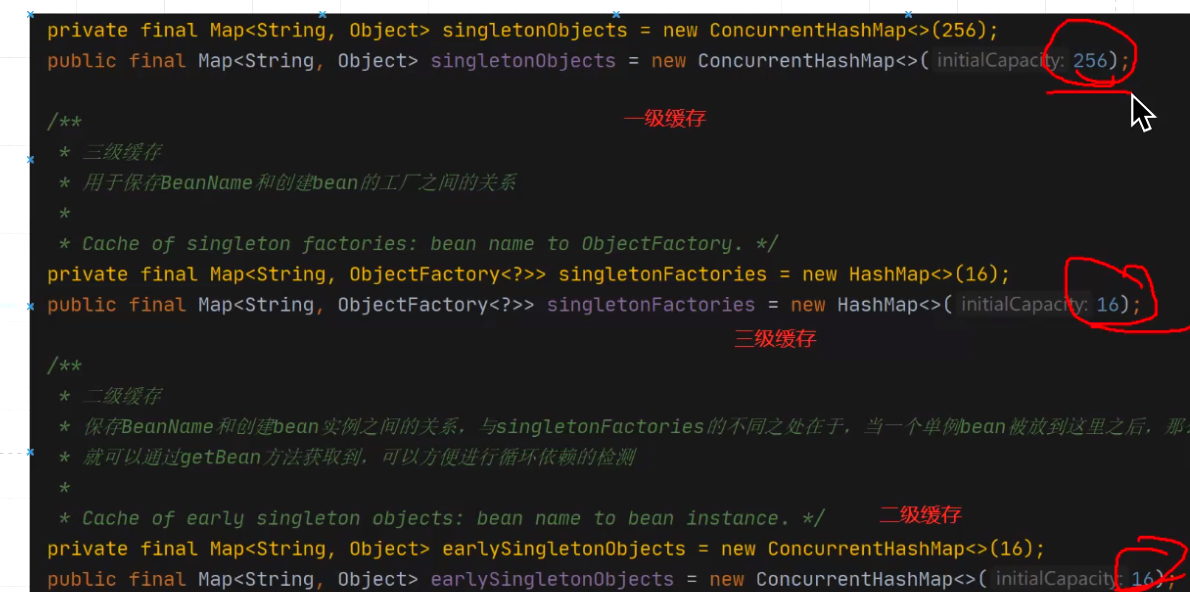
-級快取:成品物件
級快取:半成品物件
三級快取:lambda運算式
2、三個map結構在進行物件查找的時候,查找的順序是什么樣的?
1, 2, 3
3、為什么一級快取有物件之后就要把二級和三級給移除掉?
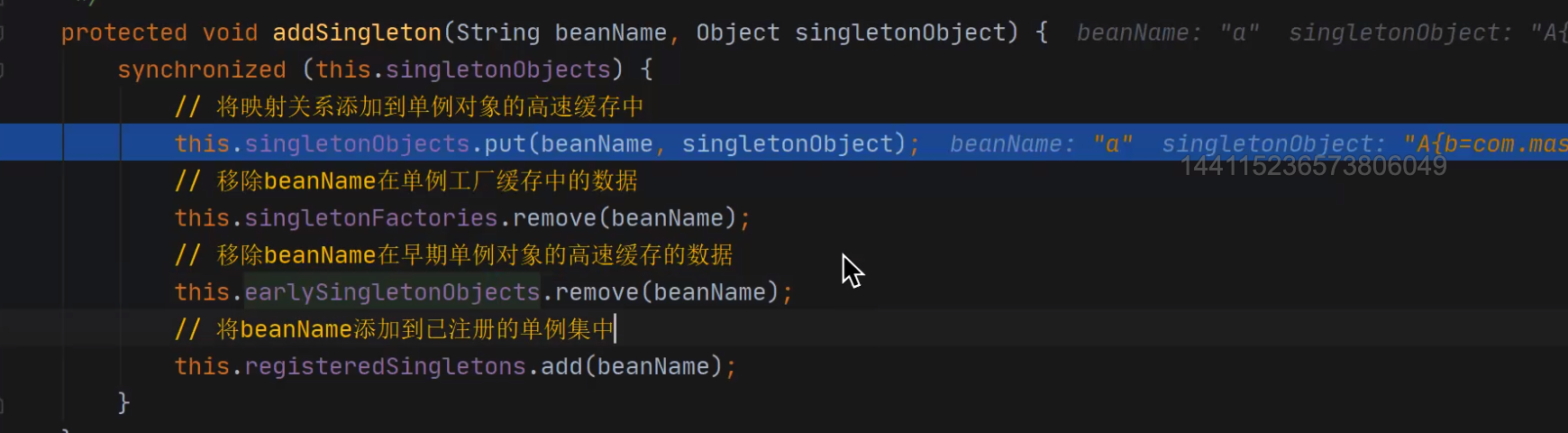
因為物件的查找順序是1,2,3,如果在一級中找到了,那么二級永遠也不會進行查找,以此類推
4、如果只有一個map結構,能否解決回圈依賴問題?
原則上是可以的,但是操作起來比較麻煩,當只有一個map結構的時候就意味著成品物件和半成品物件要放到一起,而半成品物件是不能暴露給外部使用的,要不會報空指標例外,所以需要添加標識位,而容器中物件的名字都是固定的,所以標識位只能在value中,也就意味著每次在判斷的時候都要獲取到value然后判斷完標志位之后才能進行下一步操作,比較麻煩,直接用兩個map可以輕松解決這個問題
5、如果只有兩個map結構,能否解決回圈依賴問題?
原則上是可以的,但是有前提條件:整個代碼的執行邏輯中不能包含代理物件的創建,否則會報錯
6、為什么必須要使用三個map結構來解決回圈依賴問題?三級快取是如何解決回圈依賴問題的?
(1)在創建代理物件的時候是否需要創建原始物件?
需要
(2)容器中能否同時存在兩個同名的不同物件?
不能
(3)如果創建出了代理物件,那么原始物件應該怎么處理?
當創建出代理物件之后,需要將代理物件覆寫原始物件
(4)那么為什么要引入三級快取呢?為什么要傳入一個lambda運算式呢?
正常的bean的生命周期是先通過createBeanlnstance創建出原始物件,然后在populateBean的方法中完成物件屬性的賦值作業,然后在BeanPostProcessor的后置處理方法中完成代理物件的創建作業,也就是說按照正常的執行邏輯,是完成屬性的賦值之后才會創建出代理物件,那么意味著最后創建出的是代理物件,但是賦值的時候賦的是原始物件,所以會出現一個錯誤:that said other beans do not use the final version of the bean. 當引入lambda運算式之后相當于將生成代理物件的程序給提前了,也就是說在完成物件的屬性賦值的時候必須要唯一性的確定好我需要的到底是代理物件還是原始物件,參考 (getEarlyBeanReference方法)也就是說我們在賦值的前一刻必須要確定好最終的結果,但是又因為我們沒有辦法確定什么時刻會給什么物件的屬性賦值,所以采用lambda運算式的方法延遲執行,只有在物件賦值的最后一刻才確定出到底是什么物件,
點擊訪問我的網址:http://yonghomes.cn/
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/527968.html
標籤:Java