這篇博客開始介紹《深度探索C++物件模型》第四章的剩余部分,包括成員函式指標和行內函式,
成員函式指標
對于靜態成員函式,其和常規的函式是一樣的,故這里不做介紹,下面主要介紹非靜態的成員函式指標,包括普通的非virtual成員函式指標和virtual成員函式指標,
注意,這篇是按照《深度探索C++物件模型》的內容寫的,最后講到支持多繼承的成員函式指標時才會給出真正的成員函式指標的實作!
非virtual成員函式指標
對于一個非virtual的成員函式取址,得到的就是該成員函式在記憶體中的地址,但是它不能單獨呼叫,需要使用其系結的物件/指標/參考呼叫,
// test26.cpp
class Test {
public:
Test(int i)
: m_i(i)
{}
int getInt() const {
return m_i;
}
void setInt(int i) {
m_i = i;
}
private:
int m_i;
};
int main() {
Test t(1);
int i = t.getInt();
void (Test::*pMemberFunc)(int) = nullptr; // 成員函式指標
pMemberFunc = &Test::setInt;
(t.*pMemberFunc)(2);
i = t.getInt();
}
支持“指向虛成員函式”的指標
對于非虛成員函式我們可以直接拿到其地址,因為其沒有多型性,但對于虛函式,其地址要在運行時確定,因此對于虛成員函式我們取的應該是其相對虛表指標的偏移index,
所以如果有如下類:
class Point {
public:
Point(int x, int y);
virtual
~Point();
int x() const {return m_x;}
int y() const {return m_y;}
virtual
int z() const { return 0; }
private:
int m_x;
int m_y;
};
對于解構式取值&Point::~Point取得的是0,
對于x()和y()取址&Point::x, &Point::y得到的是其地址,因為他們不是虛函式,
對于z()取址&Point::z得到的是1,通過pMemberFunc呼叫z(),其會是類似下面的形式:
(*ptr->vptr[(int)pMemberFunc])(ptr)
支持多繼承的成員函式的指標
在多繼承的情況下還要考慮虛函式表的位置問題,因為在多重繼承下可能有多個虛函式表;還有this指標可能需要進行偏移,如果派生類沒有覆寫第二個或后面的基類的虛函式的話,
為了要支持以上種種特性:如果是非虛函式,指標中要包括其地址;如果是虛函式,要包括其相對虛表指標的偏移;如果是多重繼承,還要找到虛函式在哪個虛表中和對this指標進行偏移,
在《深度探索C++物件模型》中提出的是這樣的結構:
struct _mptr{
int delta;
int index;
union {
PtrToFunc faddr;
int v_offset;
};
};
其中delta是this指標要進行的偏移,index是虛函式在虛表指標指向空間中的下標,faddr是非虛函式的地址,v_offset是虛表指標的的位置,
所以下面的操作:
(ptr->*pmf)();
會變成:
// 我覺得這個可能是有問題
pmf.index < 0
? // 非虛函式呼叫
(*pmf.faddr)(paddr)
: // 虛函式呼叫
(*ptr->vptr[pmf.index])(ptr)
《深度探索C++物件模型》中是這么寫的,但按照作者的說法,實際的代碼應該是:
pmf.index < 0
?
(pmf.faddr)(pmf + delta)
:
(((vptr*)(ptr+pmf.v_offset))[pmf.index])(ptr+delta)
// (ptr+pmf.v_offset) 是虛表地址
// ((vptr*)(ptr+pmf.v_offset))[pmf.index] 是虛表的第pmf.index項
// ptr+delta是對this指標進行偏移
讓我們來看看g++中是怎么實作的:
// test27.cpp
class Point {
public:
Point(int x, int y);
virtual
~Point();
int x() const {return m_x;}
int y() const {return m_y;}
virtual
int z() const { return 0; }
private:
int m_x;
int m_y;
};
Point::Point(int x, int y)
: m_x(x), m_y(y)
{}
Point::~Point() {
m_x = m_y = 0;
}
int main() {
Point p(1, 2);
using MemberFunction_t = int (Point::*)() const ;
MemberFunction_t pVirtualMemberFunc = nullptr;
MemberFunction_t pMemberFunc = nullptr;
pMemberFunc = &Point::x;
pVirtualMemberFunc = &Point::z;
int x = (p.*pMemberFunc)();
int z = (p.*pVirtualMemberFunc)();
++z;
}
我們使用gdb看一下這個成員函式指標的size:
(gdb) p sizeof(MemberFunction_t)
$1 = 16
在賦值之后,查看pMemberFunc和pVirtualMemberFunc的二進制是什么:
(gdb) x/2ag &pMemberFunc
0x7ffffffee0d0: 0x8000a86 <Point::x() const> 0x0
(gdb) x/2ag &pVirtualMemberFunc
0x7ffffffee0c0: 0x11 0x0
可以看到g++實作的成員函式指標有兩個QWORD,如果函式指標指向的是非虛函式,第一個QWORD里面是該函式的地址;如果是的話,看上去是該虛函式相對于虛表的偏移+1,因為Point::z在vptr[2]的地方(vptr[0]是Point::~Point,但不呼叫::operator delete;vptr[0]也是Point::~Point,會隨后呼叫::operator delete),那偏移就是0x10,但內容是0x11,可能就是加了1,
讓我們看一下匯編代碼是怎么操作的:
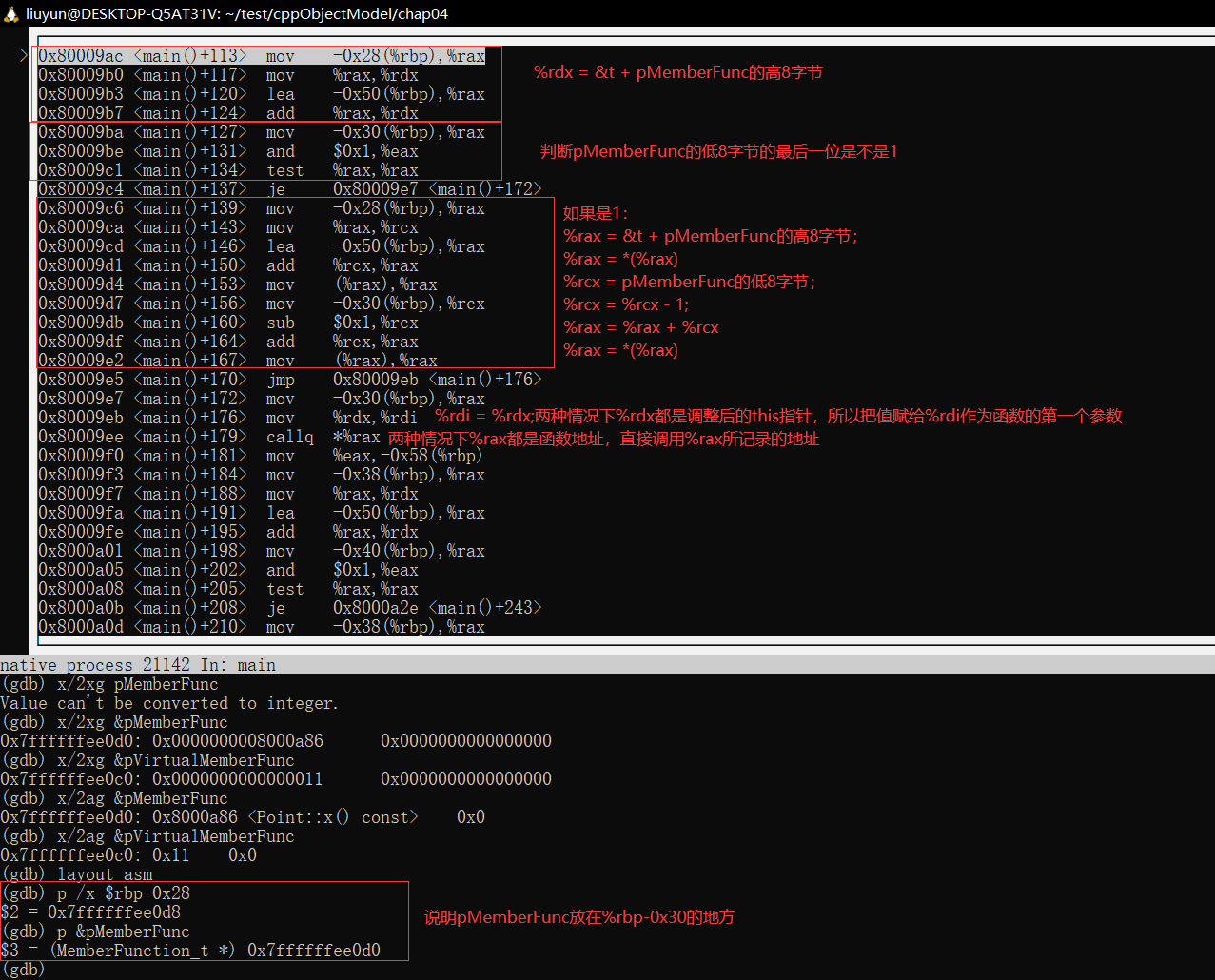
上面的匯編是即將執行int x = (p.*pMemberFunc)();這一陳述句,
總結如下:
- 如果不是虛函式,低8個位元組是函式的地址,高8個位元組是this指標的偏移;
- 如果是虛函式,低8個位元組是虛表指標相對于this指標的偏移&1(位與操作),而高8個位元組同樣是this指標的偏移;
這兩種情況就按低8個位元組的QWORD的最低位是不是1決定:如果是1則是虛成員函式指標,不是1則是非虛成員函式指標,
虛函式地址相對于vptr偏移的位元組數肯定是指標大小的整數倍,一般為4或8位元組,最后一位肯定是0,所以與一個1可以理解,用的時候只需要減去這一位即可,
但函式地址最后一位肯定是0嗎?我就這個問題查閱了資料,在博客《C++語言學習(十四)——C++類成員函式呼叫分析》中提到:
一般來說因為對齊的關系,函式地址都至少是4位元組對齊的,即函式地址的最低位兩個bit總是0,
雖然和我的觀察略微有不同(在我編譯的程式里,Point::x的地址是0x8000a86,只有最后一位是0,倒數第二位是1),但也說明了函式地址確實是有對齊這一現象的,
這里再繼續參考一下這篇博客里的論述,用以輔助讀者理解(感我寫得不如這篇博客遠矣):
GCC對于成員函式指標統一使用下面的結構進行表示:
struct { void* __pfn; //函式地址,或者是虛擬函式的index long __delta; // offset, 用來進行this指標調整 };不管是普通成員函式,還是虛成員函式,資訊都記錄在__pfn,一般來說因為對齊的關系,函式地址都至少是4位元組對齊的,即函式地址的最低位兩個bit總是0, GCC充分利用了這兩個bit,如果是普通的函式,__pfn記錄函式的真實地址,最低位兩個bit就是全0,如果是虛成員函式,最后兩個bit不是0,剩下的30bit就是虛成員函式在函式表中的索引值,
// 注意,在我的版本里(g++ (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0),檢查的是隨后一位,函式地址也只是2對齊,而不是4對齊
GCC先取出函式地址最低位兩個bit看看是不是0,若是0就使用地址直接進行函式呼叫,若不是0,就取出前面30位包含的虛函式索引,通過計算得到真正的函式地址,再進行函式呼叫,
這篇博客里還介紹了MSVC對于成員函式指標的實作,使用了thunk技術,大家可以去看一下,(其實這個在《深度探索C++物件模型》,里也有提到,大家感興趣也可以看看原書),
行內函式
關于這一部分只是做一個總結,我也不知道如何比較好得驗證其中的內容,
關鍵詞inline只是一個請求,一般而言,處理一個inline函式會有兩個階段:
- 分析函式定義,以解決函式的"intrinsic inline ability"(本質的inline能力),"intrinsic"(本質的、固有的)一詞在這里意指“與編譯器相關”【書中原話】
說白了就是編譯器要看看能不能行內,要是太復雜就直接編譯成函式,(在理想情況下)聯結器會把生成的重復的行內函式清理掉,strip命令也可以達成這個目的,
- 真正的inline函式擴展操作是在呼叫的那一點上,這會帶來引數的求值操作和臨時物件的管理,
所謂求值操作是和宏函式做對比的,宏函式只是簡單的復制粘貼,但inline函式在呼叫前會對傳參進行求值(無論其行內展開與否),
比如:
inline
int min(int i, int j) {
return i < j ? i : j;
}
對于minval = min(foo(), bar() + 1)會擴展成:
int t1, t2;
minval = (t1 = foo()), (t2 = bar() + 1),
t1 < t2 ? t1 : t2;
// 逗號運算子,
// 從左到右計算,運算式結果為最后一個值,
// 比如 t = foo(), bar();
// 會先呼叫foo(), 再呼叫bar(),t的值為bar()的回傳值
這種特性使得行內函式比宏函式安全得多,
而臨時物件管理則是在函式行內時會產生很多臨時變數,比如形參串列、行內函式中的區域變數等等,
其他比如成員函式指標的執行效率我就不多做測驗了,這一章也就結束了,
關于后面的內容,我會在有時間的時候做簡要的總結,不會像這兩章這么詳細得分析匯編了,因為我覺得物件布局和虛函式的實作就是書最主要的內容了,
好的,就這樣了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/528057.html
標籤:其他
上一篇:day11-Servlet01
下一篇:Optional用法與爭議點