前言
? 對于我們平時寫代碼運行,我們很少去關注編譯和鏈接的程序,因為現在的開發環境都是集成(IDE)的,這些IDE一般都會將編譯和鏈接的程序一步搞定,這一程序又被稱為構建,但若經常寫代碼,經常會有很多莫名其妙的錯誤讓我們不知所措,對于這些錯誤若我們能知其原因,那是再好不過了,因此本系列就是帶你了解這些編譯器和聯結器在背后的作業
夢開始的地方
? 讓我們先來看一個最最最經典的例子
//hello.c
#include <stdio.h>
int main()
{
printf("hello world");
return 0;
}
? 事實上,運行以上程序,可以被分解為四步:預處理、編譯、匯編、鏈接
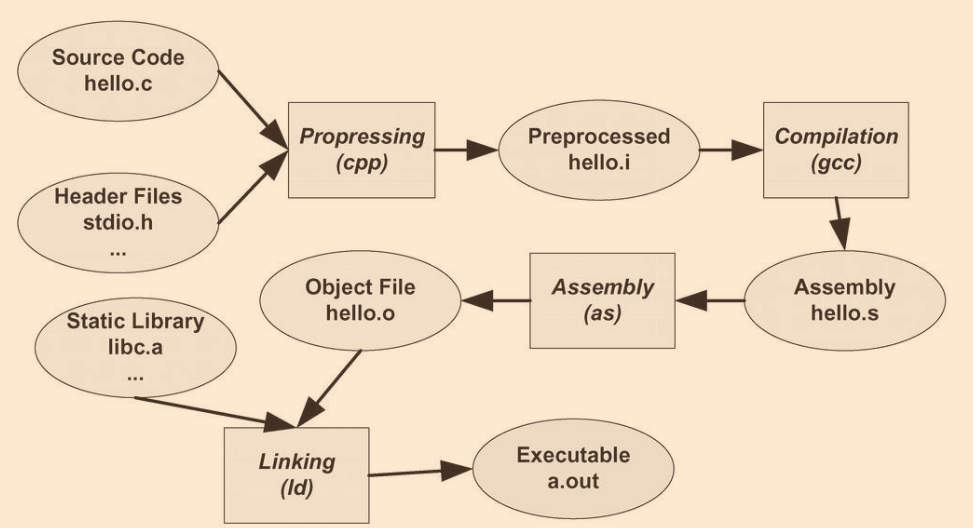
預編譯
? 前處理器在預編譯階段會將源代碼檔案.c和相關的頭檔案編譯為一個.i檔案,其中主要處理“#”開頭的預編譯指令
? 預編譯程序主要處理規則:
- 洗掉所有注釋 "//" 和 "/**/"
- 處理所有條件預編譯指令 "#if"、"#ifdef"等
- 洗掉所有 "#define",且展開所有宏定義
- 處理預編譯指令"#include",將被包含的檔案插入到相應的預編譯指令位置,當然可能插入的檔案還包含其他檔案
- 添加行號和檔案名標識,以便于編譯器在編譯時產生除錯所用的行號資訊和產生編譯錯誤或警告時可以顯示行號
- 保留所有#pragma指令,便于編譯器使用
編譯
? 所謂編譯,就是將上一個預處理階段處理完的檔案進行詞法分析、語法分析、語意分析和優化后生成的匯編代碼檔案,其程序最為關鍵且復雜,但是現在版本的GCC已經把預編譯和編譯合并為一個步驟,使用cc1來完成
? 現有如下片段:
array[index] = (index + 4) * ( 2 + 6 )
詞法分析
? 首先,源代碼程式被輸入到掃描器,運用類似有限狀態機的演算法將源代碼的字符序列分割為一系列記號(token)
| 記號 | 型別 |
|---|---|
| array | 識別符號 |
| [ | 左方括號 |
| index | 識別符號 |
| ] | 右方括號 |
| = | 賦值 |
| ( | 左圓括號 |
| index | 識別符號 |
| + | 加號 |
| 4 | 數字 |
| ) | 右圓括號 |
| * | 乘號 |
| ( | 左圓括號 |
| 2 | 數字 |
| + | 加號 |
| 6 | 數字 |
| ) | 右圓括號 |
- 詞法分析的記號可分為:關鍵字、識別符號、字面量(數字、字串等)、特殊符號(加號等)
- 識別記號時,掃描器也會將識別符號放入符號表,將字面量常量放入文字表,以備往后的步驟使用
語法分析
? 接下來時語法分析,語法分析器對掃描器產生的記號進行語法分析,再產生語法樹,語法樹時以運算式為節點的樹,語法分析程序會采用背景關系無關語法
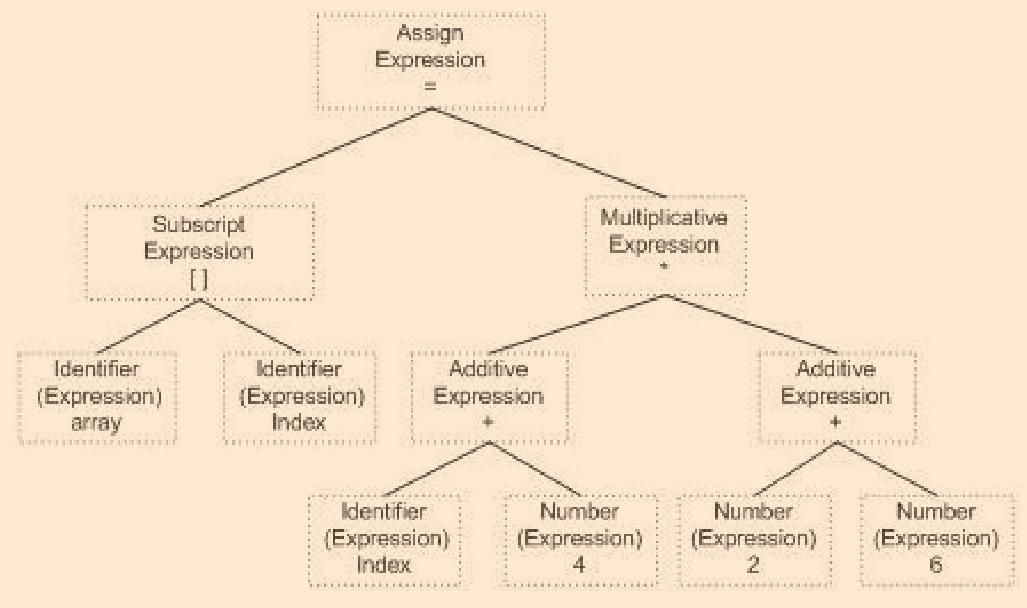
- 語法分析程序,會確定運算子號的優先級和含義,此時若出現運算式不合法,編譯器則會報告語法分析階段的錯誤
語意分析
? 語法分析會對完成了運算式的語法層面的分析,但其并不知道這個陳述句是否有意義,因此需要語意分析器進行語意分析,從而對整個語法樹的運算式標識型別;若有型別需要做隱式轉換,會在語法樹中插入相應的轉換節點
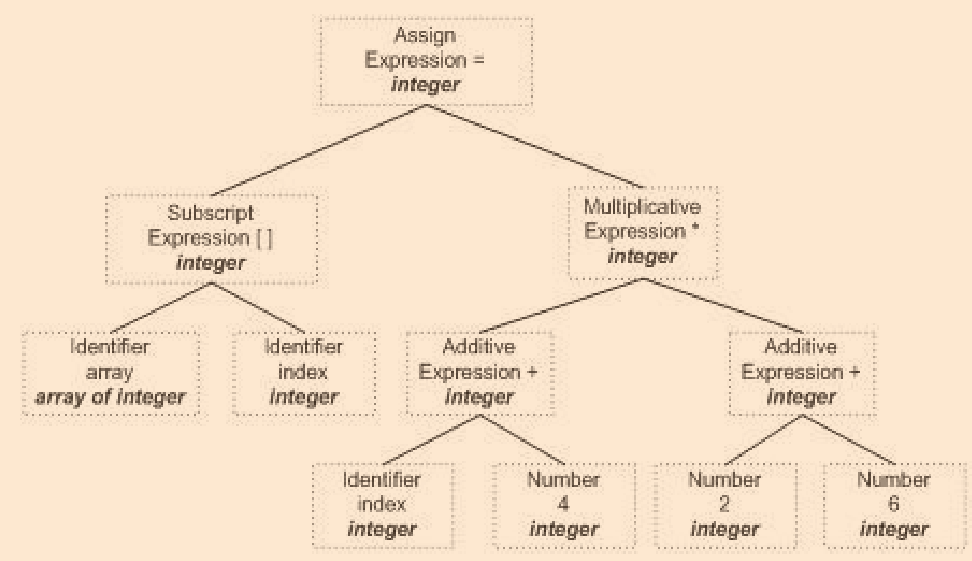
? 語意分析分為兩類,靜態語意是編譯器再編譯器可以確定的語意;動態語意則是在運行期才能確定的語意
- 靜態語意包括宣告、型別的匹配和型別的轉換,比如浮點型別賦值給整型,需要進行型別轉換
生成中間語言
? 編譯器有很多不同的優化,其中一種便是在源代碼級別用原始碼級優化器進行優化,直接在語法樹上優化較為困難,因此源代碼優化器將語法樹轉換為中間代碼
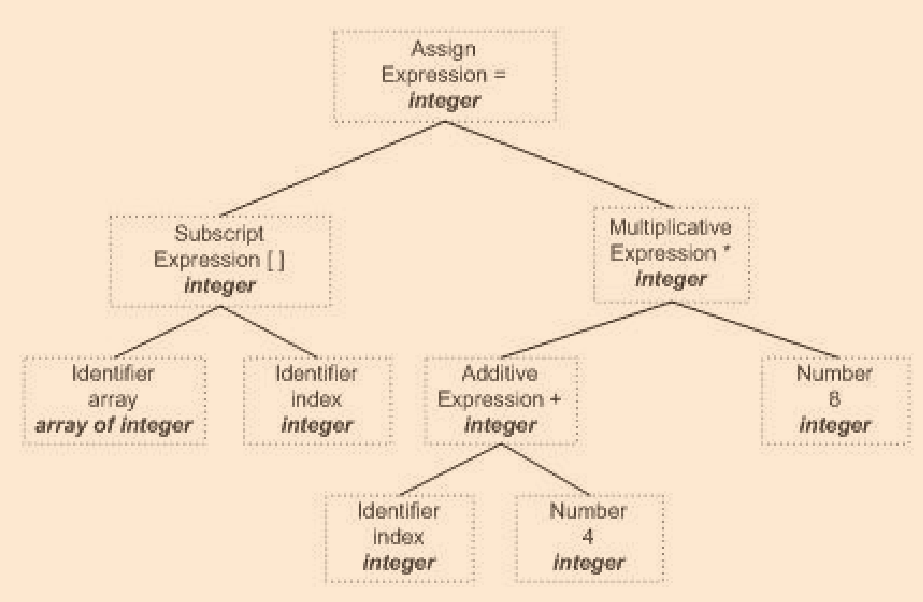
-
雖然中間代碼看上去已經十分接近目標代碼了,但中間代碼和機器以及運行時環境無關
-
中間代碼型別:三地址碼,P-代碼
//三地址碼 //表示將y z進行op操作后賦值給x x = y op z t1 = 2 + 6 t2 = index + 4 t3 = t2 * t1 array[index] = t3; //優化 //優化程式會計算2 + 6 t2 = index + 4 t2 = t2 * 8 array[index] = t2; -
中間代碼可以將編譯器分為前后端,前端由編譯器產生機器無關的中間代碼;而后端由編譯器將中間代碼轉換為目標機器代碼,前端關注的是正確反映代碼含義的靜態結構,而后端關注讓代碼良好運行的動態結構,好處是對于跨平臺的編譯器,它們可以針對不同平臺使用同一個前端和針對不同機器的數個后端
目標代碼生成于優化
? 編譯器后端包括代碼生成器和目標代碼優化器,代碼生成器將中間代碼轉換為目標機器代碼,目標代碼優化器會將目標代碼進行優化
革命尚未結束
? 也許你覺得到這里我們已經萬事俱備,已經形成可執行檔案,但其實之前的步驟只是將源代碼檔案編譯為目標檔案,但在目標檔案中我們還未確定index和array的地址,若index和array的地址在另一個程式模塊,便沒法確定地址,我們還需其他手段
? 這個問題由鏈接解決,事實上,定義在其他模塊的全域變數和函式最終運行時的絕對地址都需要在鏈接時才能確定,編譯器將一個源代碼檔案編譯為一個未鏈接的目標檔案,隨后由聯結器最終將目標檔案鏈接未可執行檔案,編譯器只是暫時擱置呼叫地址的指令,最后等到鏈接時由聯結器去修正地址
匯編
? 匯編器將匯編代碼轉變成機器指令(機器可以執行的指令)
- 由于每個匯編陳述句幾乎都對應一潭訓器指令,因此匯編程序較為簡單,沒有復雜語法、語意、指令優化,只需根據匯編指令和機器指令的對照表一一翻譯便好
深挖中間目標檔案
? 中間目標檔案又簡稱目標檔案(object檔案):編譯器編譯源代碼后生成的檔案,從結構上來說,目標檔案是已經編譯后的可執行檔案格式,只是沒有經過鏈接,其中某些符號和地址還沒有調整,但其本身是按照可執行檔案格式存盤的
? 往后我們將深入分析目標檔案格式,介紹ELF檔案的重要段及檔案頭、段表、重定位表、字串表、符號表、除錯資訊等相關結構;我們會了解到可執行檔案、目標檔案、庫都是以段為基礎的檔案,不僅是資料和代碼存放在相應段中,編譯器也會將一些輔助資訊按照表的方式存盤
目標檔案格式
? 現如今的pc平臺流行的可執行檔案格式為windows的PE和Linux的ELF,都是COFF格式的變種
? 目標檔案格式和編譯器和作業系統有關,不同平臺下的格式各有不同
? ELF格式的檔案型別分為四類:
| ELF檔案型別 | 說明 | 實體 |
|---|---|---|
| 可重定位檔案(relocatable file) | 包含資料和代碼,可被用來鏈接成可執行檔案或共享目標檔案,靜態鏈接庫也屬于此類 | Linux .o windows .obj |
| 可執行檔案(executable file) | 包含可直接執行的程式,一般沒有擴展名 | /bin/bash檔案 windows .exe |
| 共享目標檔案(shared object file) | 包含資料和代碼,可在以下兩種情況使用,一是聯結器可以使用這種檔案跟其他的可重定位檔案和共享目標檔案鏈接,生成新的目標檔案;二是動態聯結器可以將幾個這樣的共享目標檔案與可執行檔案結合,作為行程映像的一部分運行 | Linux .so,如/lib/glibc-2.5.so windows的DLL |
| 核心轉儲檔案(core dump file) | 當行程意外終止時,系統可將該行程的地址空間的內容及終止時的其他資訊轉儲到核心轉儲檔案 | Lindex的core dump |
目標檔案的重要段
? 目標檔案包含機器指令代碼、資料、鏈接時所需要的資訊(符號表、除錯資訊、字串);以"字"和"段"進行存盤,都表示一定長度的區域,基本不加以區別,以后的都統一為"段"
? 機器指令被放于代碼段,常見的名稱有".code"或".text";
? 全域變數和區域靜態變數資料放于資料段,常見的名稱有".data";
? 未初始化的全域變數和區域變數放于".bss"段
? 檔案頭(file header)描述整個檔案的屬性,其中包含檔案是否可執行、靜態鏈接還是動態鏈接及入口地址、目標硬體、目標作業系統等資訊,ELF檔案還包括一個段表(描述檔案中各個段的陣列),其描述了檔案中各個段在檔案中的偏移量、段名、長度、讀寫權限等
? ELF檔案布局會隨著討論不斷深入而擴大
? 
? 總的來說,源代碼編譯后主要分為兩種段:指令和資料
? 那么,我們為什么要對這些指令和資料進行分類呢?這有什么好處呢?
- 程式被裝載后,資料和指令分別被映射到兩個虛擬存盤區域,資料區域對行程來說是可讀寫,而指令區域是只讀的,如此可以防止指令被惡意改寫
- cpu在當下擁有十分強大的快取,因此程式需要想盡一切辦法提高快取的命中率;而指令和資料進行分類后有利于提高程式的區域性,就可以提高命中率了
- 當系統中運行多個同一個程式的副本且它們的指令也是相同的,記憶體中只需要保存一份此程式的指令部分,當然其他只讀資料也是同樣的道理;不過資料區域是行程私有,因此每個副本行程的資料是不同的
紙上談來終覺淺
? 如果只是對目標檔案了解概念上的知識,而不深入其具體細節,我認為這并不可能真正了解他,因此接下來我將以一個具有代表性的例子撩開這層神秘的面紗
? 現有一個instance.c程式:
int globalInitVar = 1;
int globalUninitVar;
int printf( const char* format, ... );
void func1( int i )
{
printf( "%d\n", i );
}
int main()
{
static int staticVar = 2;
static int staticVar2;
int a = 1;
int b;
func1( staticVar + staticVar2 + a + b );
return a;
}
? 用gcc編譯(-c)此檔案,再通過binutils的工具objdump(-h將基本資訊列印出來,-x資訊更多)查看object內部結構:
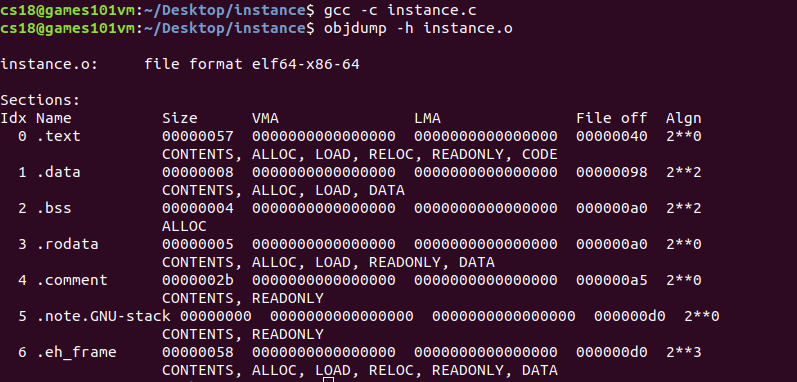
? 我們先來看幾個重要的段屬性,Size表示是段的長度;File off表示段的偏移量,也就是所在的位置;CONTENTS表示該段在檔案中存在,我們可以看到.bss并沒有CONTENTS,說明它在ELF中沒有內容
- size 查看ELF檔案的代碼段、資料段、BSS的長度和(dec十進制,hex十六進制)

? 接下來,我們將細探這幾個段所包含的內容
? 用objdump的-s將所有段的內容以十六進制方式列印出來,-d將所有包含指令的段反匯編
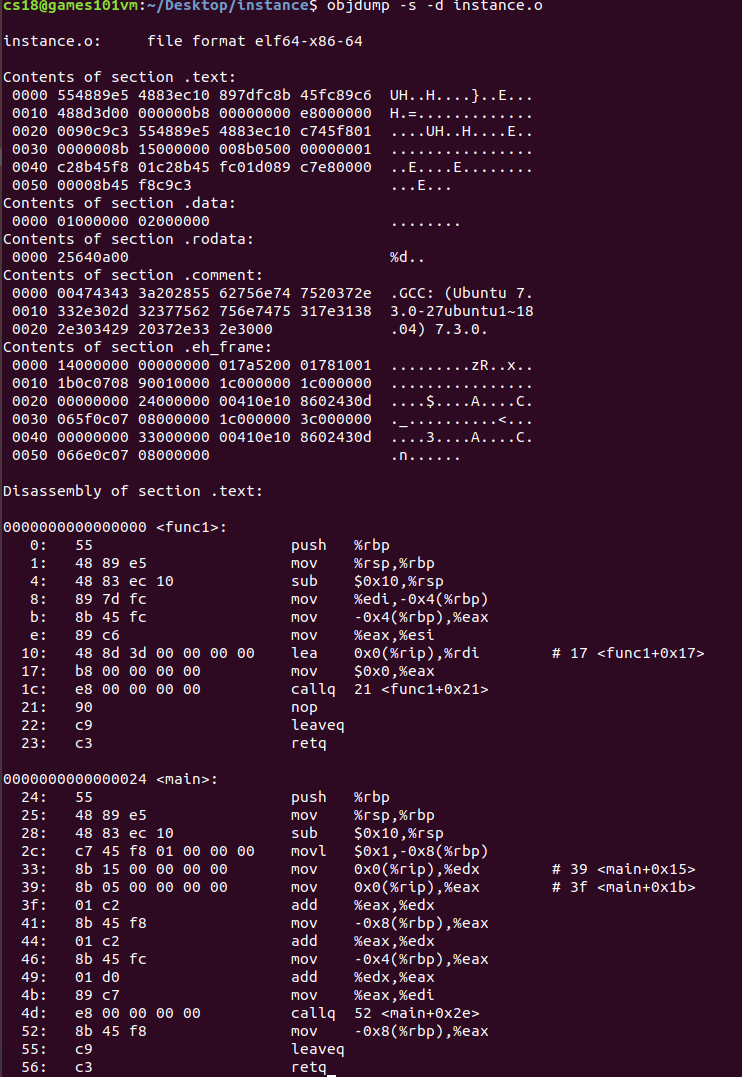
- 首先是代碼段:
contents of section.text是.text的資料用十六進制列印出來的,其中最左邊的是offset偏移量;中間四列是十六進制內容,也就是段長度,這里是0x5b和之前看到的是一致的;最后一列是當前段的ASCII碼形式,下面的是反匯編結果,很顯然兩個函式func1和main正是本例程式里的
- 其次是資料段和只讀資料段:
.rodata段存放只讀資料,如字串常量和const修飾的,在這里呼叫printf時用到的字串常量"%d\n"就是只讀資料,因此將其放在.rodata段,但有些編譯器會把字串常量放到.data段
? 設立.rodata段的好處:
- 支持c++關鍵字
- 作業系統在加載時可以將.rodata段屬性映射為只讀,保證安全性
? objdump -x -s -d instance.o查看data情況:
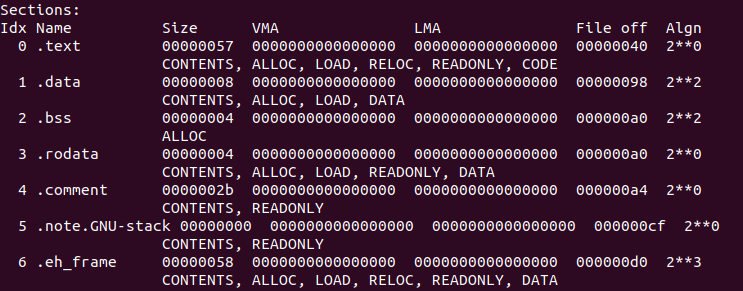

? contents of section .data的中間部分前四個位元組為0x01、0x00、0x00、0x00這個值也就是globalInitVar.后四個位元組為0x02、0x00、0x00、0x00,這個值也就是staticInitVar
? 在這里你可能會有疑惑,為什么globalInitVar的次序不是0x00、0x00、0x00、0x01呢?這與CPU的位元組序有關,現在有請我們的嘉賓大端和小端登場!
在不同的計算機結構中,對于資料的存盤和傳輸機制有所不同,這導致了一個問題——通信雙方的資訊單元應該以怎樣的順序傳送?目前計算機體系中最常用的位元組存盤機制有兩種:大端和小端
? 在了解大端和小端前,我們還需了解兩個概念——MSB(most significant bit/byte)和LSB(least significant bit/byte),MSB表示在一個bit序列或一個byte序列中對整個序列取值影響最大的那個bit/byte;LSB表示在在一個bit序列或一個byte序列中對整個序列取值影響最小的那個bit/byte
? 比如0x32857233,0x32則是MSB,0x33時LSB
? 大端規定了存盤時MSB放在低地址,傳輸時MSB放在流開始處,存盤時LSB放在高地址,傳輸時LSB放在流的末尾處;小端與大端相反
? pc的CPU的兼容機中經常用小端,而mac機器以及TCP/IP、java虛擬機用大端.至于是大端好還是小端好,這個問題已經爭論很久了但也沒有結論
- 然后是.bss段:
? .bss段為globalUninitVar和staticVar2預留了空間,但很奇怪的是這個段的長度只有四個位元組,而globalUninitVar和staticVar2的大小總和是8,通過符號表查找,原來只有static_var2存放在.bss段,而globalUninitVar卻沒有存放在任何段,其表現形式是一個未定義的COM符號,關于這個現象與編譯器實作有關,有些編譯器會將全域靜態未初始化的變數存放在.bss段,只是預留未定義的全域變數符號,等到最終鏈接成可執行檔案時再為.bss分配空間
? 當然除了.text、.data、.bss這三個常用的段外,ELF檔案也很有可能包含其他種類的段
| 常用段名 | 說明 |
|---|---|
| .rodata1 | 只讀資料 |
| .comment | 編譯器版本資訊 |
| .debug | 除錯資訊 |
| .dynamic | 動態鏈接資訊 |
| .hash | 符號哈希表 |
| .line | 除錯時的行號表,也就是源代碼行號和編譯后指令的對應表 |
| .note | 額外的編譯器資訊,如程式的公司名、發布版本 |
| .strtab | 字串表,存盤ELF檔案中用到的字串 |
| .symtab | 符號表 |
| .shstrtab | 段名表 |
| .plt .got |
動態鏈接的跳轉表和全域入口表 |
| .init .fini |
程式初始化和終結代碼段 |
- 以上這些段都是系統保留的,我們也可以使用一些非系統保留的名字作為自定義段的名字
ELF檔案總體結構
ELF檔案將要了解的重要結構:
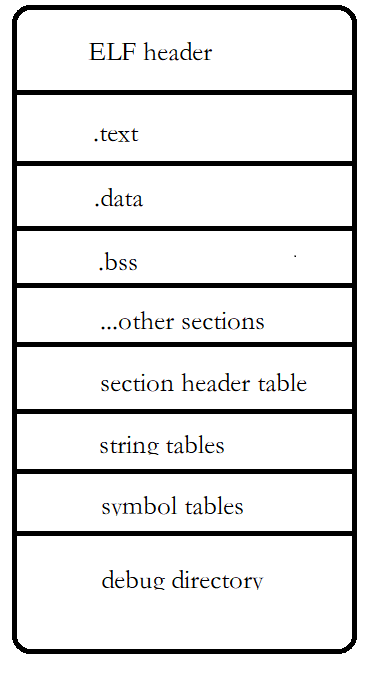
ELF檔案頭
? 檔案頭作為ELF目標檔案的最前部包含描述整個檔案的屬性,如ELF檔案版本、目標機器型號、程式入口地址、包含段描述符的段表等等
? 我們通過readelf -h instance.o來查看ELF檔案內容:
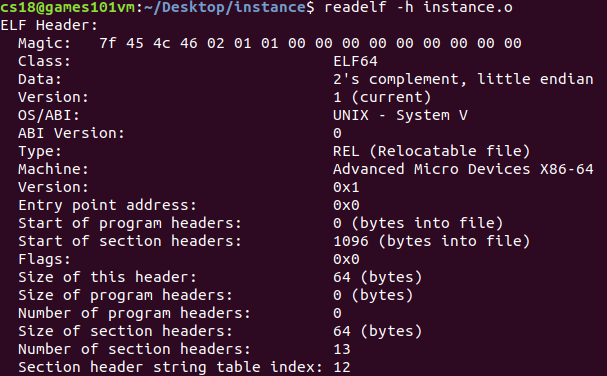
? 可以看到ELF檔案中包含了ELF魔數(Magic)、機器位元組長度(Class)、資料存盤方式(Data)、版本(Version)、作業系統運行平臺(OS/ABI)、ABI版本、ELF檔案型別(Type)、硬體平臺(Machine)、硬體平臺版本(Version)、入口地址(Entry point address)、程式和段表的起始位置(Start of program headers、Start of section headers)、當前ELF檔案頭大小(Size of this header)、程式頭大小(Size of program headers)、程式頭數量(Number of program headers)、段表描述符大小(Size of section headers)、段表描述符數量(Size of section headers)、段表字串表所在段在段表中的下標(section header string table index)
? ELF檔案有32位和64位版本,檔案頭亦是如此,分別是"Elf32_Ehdr"和"Elf64_Ehdr",定義在"/usr/include/elf.h"兩個版本檔案頭內容都一樣,只是部分成員大小不同,以下是檔案頭"elf.h"使用typredef定義的變數體系
| 自定義型別 | 描述 | 原始型別 | 長度(位元組) |
|---|---|---|---|
| Elf32_Addr | 32位版本程式地址 | uint32_t | 4 |
| Elf32_Half | 32位版本的無符號短整型 | uint16_t | 2 |
| Elf32_Off | 32位版本的偏移地址 | uint32_t | 4 |
| Elf32_Sword | 32位版本有符號整型 | int32_t | 4 |
| Elf32_Word | 32位版本無符號整型 | uint32_t | 4 |
| Elf64_Addr | 64位版本程式地址 | uint64_t | 8 |
| Elf64_Half | 64位版本的無符號短整型 | uint16_t | 2 |
| Elf64_Off | 64位版本的偏移地址 | uint64_t | 8 |
| Elf64_Sword | 64位版本有符號整型 | int32_t | 4 |
| Elf64_Word | 64位版本無符號整型 | uint32_t | 4 |
? 舉例Elf32_Ehdr:
typedef struct
{
//ELF魔數(Magic)、機器位元組長度(Class)、資料存盤方式(Data)、版本(Version)、作業系統運行平臺(OS/ABI)、ABI版本
unsigned char e_ident[16];
//ELF檔案型別
Elf32_Half e_type;
//ELF檔案的CPU屬性
Elf32_Half e_machine;
//ELF版本號
Elf32_Word e_version;
//入口地址
Elf32_Addr e_entry;
//start of program headers
Elf32_Off e_phoff;
//start of section headers 段表起始位置
Elf32_Off e_shoff;
//ELF標志位,標識ELF相關屬性
Elf32_Word e_flags;
//size of this header ELF檔案頭大小
Elf32_Half e_ehsize;
//將在后面的系列動態鏈接講解
Elf32_Half e_phentsize;
//將在后面的系列動態鏈接講解
Elf32_Half e_phnum;
//段表描述符大小
Elf32_Half e_shentsize;
//段表描述符數量
Elf32_Half e_shnum;
//段表字串表在所在段表的下標
Elf32_Half e_shstrndx;
}Elf32_Ehdr;
? Magic 從前面readelf輸出的內容可以得知,Magic后面16個位元組對應于e_ident,用來標識ELF檔案的平臺屬性,如ELF字長是32位還是64位下的、位元組序是大端還是小端、ELF檔案版本;其中前四個位元組也就是這里所說的ELF魔數,這四個位元組的魔數用來確認檔案型別,作業系統在加載可執行檔案時會確認魔數是否正確,若不對則拒絕加載;

? 上面這個例子,前面四個位元組是標識碼,所有ELF檔案都相同,也就是ELF魔數,這四個位元組的魔數用來確認檔案型別,作業系統在加載可執行檔案時會確認魔數是否正確,若不對則拒絕加載;第一個位元組0x7f對應ASCII字符里的DEL控制符,后面三個位元組0x45、0x4c、0x46是ELF這三個字母的ASCII標識碼;第五個位元組表示系統位數,也就是Class,64位是0x02,32位是0x01;第六個位元組表示位元組序,也就是Data,0x01是小端,0x02是大端;第七個位元組表示ELF檔案的主版本號,也就是Version,一般為1,因為ELF標準在1.2往后就沒更新了;最后九位位元組沒有定義,填0,但有些平臺會使用這九個位元組作為擴展標志
? Type e_type表示ELF檔案型別,在之前我們提到過4種ELF檔案型別,其中三種檔案型別對應一個常量,系統通過這個常量來判斷ELF檔案型別,而不是檔案擴展名
| 常量 | 值 | 含義 |
|---|---|---|
| ET_REL | 1 | 可重定位檔案,.o |
| ET_EXEC | 2 | 可執行檔案 |
| ET_DYN | 3 | 共享目標檔案,.so |
? Machine ELF檔案格式在不同平臺可以使用,但這并不代表一個ELF檔案可以在不同的平臺使用,只是不同平臺遵守同一套ELF檔案標準
? e_machine表示該ELF檔案的平臺屬性
| 常量 | 值 | 定義 |
|---|---|---|
| EM_M32 | 1 | AT&T WE 32100 |
| EM_SPARC | 2 | SPARC |
| EM_386 | 3 | Intel x86 |
| EM_68k | 4 | Motorola 680000 |
| EM_88K | 5 | Motorola 880000 |
| EM_860 | 6 | Intel 80860 |
段表
? 我們使用段表來包含各式各樣的段,它描述各個段的資訊,比如名字、長度等;編譯器、聯結器和裝載器都是依靠段表來定位訪問各個段
? 在ELF檔案中,段表的位置由ELF檔案頭的"e_shoff"成員記錄
? 段表是一個以"Elf32_Shdr"結構體為元素的陣列,每個元素對應一個段,也可以稱這個結構體為段描述符.Elf32_Shdr定義在"/usr/include/elf.h"
? 我們用readelf -S instance.o來查看完整的段表資訊
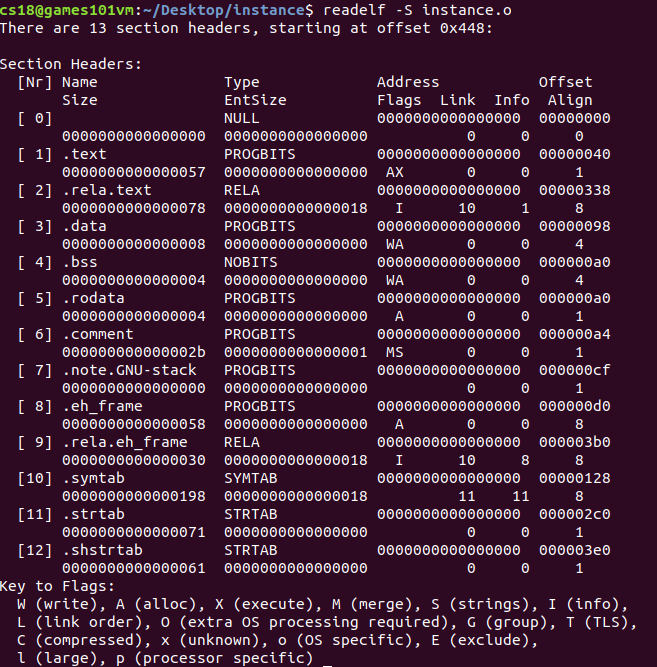
可以看到,段表陣列中的第一個元素是個無效的段描述符,型別為NULL,除此以外都是有效的
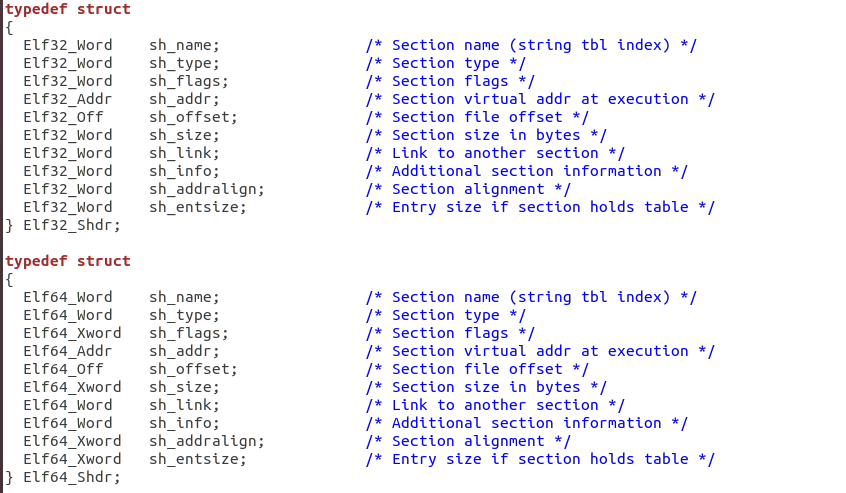
? 在這里我們解釋Elf32_Shar各個成員的含義
| sh_name | Section name 段名 一個字串,位于一個叫做".shstrtab"的字串表 |
|---|---|
| sh_type | section type 段的型別 |
| sh_flags | section flag 段的標志位 |
| sh_addr | section address 段的虛擬地址 |
| sh_offset | section offset 段偏移 |
| sh_size | section size 段長 |
| sh_link 和 sh_info | section link and section information 段鏈接資訊 |
| sh_addralign | section address alignment 段地址對齊 |
| sd_entsize | section entry size 項長 包含一些固定大小的項,如符號表,其包含的每個符號大小相同 |
- sh_type sh_flag 段名只在編譯鏈接程序有意義,但它并不真正表示段的型別;而對于編譯器來說,主要決定段屬性的是段型別和段標志位.其中段標志位表示該段在行程虛擬地址中的屬性,如是否可寫,是否可執行等
? sh_type相關常量
| 常量 | 值 | 含義 |
|---|---|---|
| SHT_NULL | 0 | 無效段 |
| SHT_PROGBITS | 1 | 程式段 |
| SHT_SYMTAB | 2 | 表示該段內容為符號表 |
| SHT_STRTAB | 3 | 表示該段內容為字串表 |
| SHT_RELA | 4 | 重定位表,包含重定位資訊 |
| SHT_HASH | 5 | 符號表的哈希表 |
| SHT_DYNAMIC | 6 | 動態鏈接資訊 |
| SHT_NOTE | 7 | 提示資訊 |
| SHT_NOBITS | 8 | 表示該在檔案中無內容 |
| SHT_REL | 9 | 包含重定位資訊 |
| SHT_SHLIB | 10 | 保留 |
| SHT_DNYSYM | 11 | 動態鏈接的符號表 |
? sh_flag相關常量
| 常量 | 值 | 含義 |
|---|---|---|
| SHF_WRITE | 1 | 表示該段在行程空間可寫 |
| SHF_ALLOC | 2 | 表示該段在行程空間中需要分配空間 |
| SHF_EXECINSTR | 4 | 表示該段在行程空間中可被執行 |
- 段鏈接資訊
? sh_link 和 sh_info所包含的意義
| sh_type | sh_link | sh_info |
|---|---|---|
| SHT_DYNAMEIC | 該段所使用的字串表在段表中的下標 | 0 |
| SHT_HASH | 該段所使用的符號表在段表中的下標 | 0 |
| SHT_REL SHT_RELA |
該段所使用的相應符號表在段表中的下標 | 該重定位表所作用的段在段表中的下標 |
| SHT_SYMTAB SHT_DYNSYM |
與作業系統有關 | 與作業系統有關 |
| other | SHN_UNDEF | 0 |
重定位表
? 
? 以上例子,在段表中有一個稱為".rela.text"的段,其型別為"SHT_REL",就是重定位表,也就是說重定位表也是一個段;該表是針對.text段的重定位表,其"sh_link"表示符號表下標,"sh_info"表示其作用于哪個段,比如當前這個例子,".rela.text"作用于".text"段,因為".text"段下標為1,"sh_info"就為1
字串表
? ELF檔案中會經常用到字串,比如段名、變數名之類的;但因為字串的長度大多數情況是不確定的,所以用固定大小的結構去表示它行不通,一種常用的方法是將字串存放在一個表中,用字串的偏移量來參考字串,也就是字串表;這樣參考字串只需一個數字下標即可搞定而不用考慮長度的問題
如以下字串表

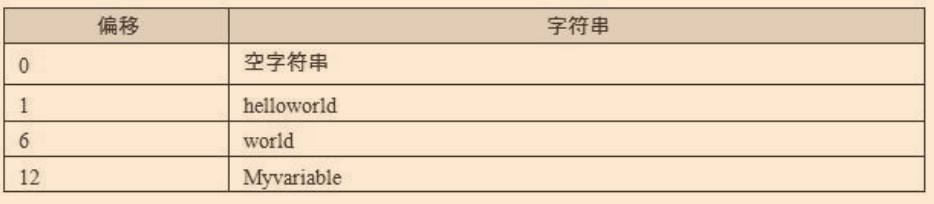
? 字串表在ELF檔案中同樣以段的形式存盤,如"strtab"為字串表,保存普通的字串;"shstrtab"為段表字串表,保存段表中用到的字串
? "e_shstrndx"是Elf32_Ehdr中的成員,表示"shstrtab"在段表中的下標,也就是段表字串表在段表中的下標
符號表
? 鏈接(具體請查看2.5鏈接)的本質就是其實就是將一個復雜的系統逐步分割成小系統,把每個源代碼模塊獨立編譯,再按需將它們組裝,其原理便是將指令對其他符號地址的參考加以修正,而鏈接程序非常關鍵的一部分就是對符號的管理,也就是符號表;每個目標檔案都含有一個符號表,其中包含了當前目標檔案所用的所有符號
? 每個符號都有值,對于變數函式來說,這個值就是它們的地址,被稱為符號值
? 下面,我們對符號分一下類:
- 在目標檔案內定義的全域符號,可以被其他目標檔案參考,如,之前的例子中的"glovalInitVar"、"func1"
- 在目標檔案內參考其他目標檔案的全域符號,并沒有定義在當前目標檔案,稱為外部符號,如,"printf"
- 區域符號,只在編譯單元內可見,對鏈接無用,因此聯結器會忽視這類符號,作用是除錯器使用這類符號分析核心轉儲檔案
- 段名
- 行號
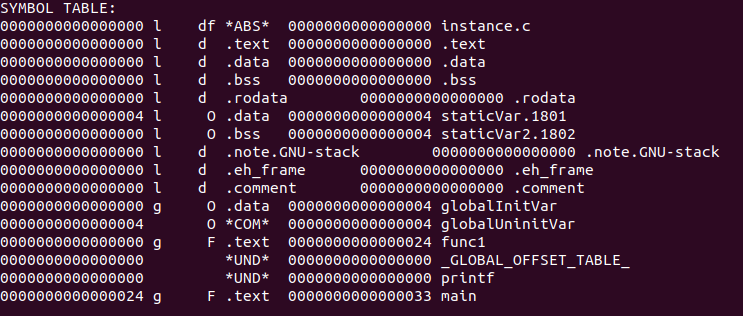
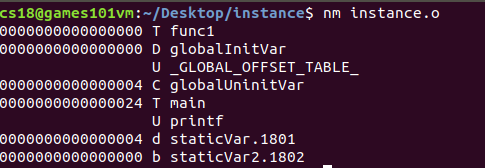
? 使用nm instance.o查看符號表;readelf -s instance.o查看符號表中的符號
? 
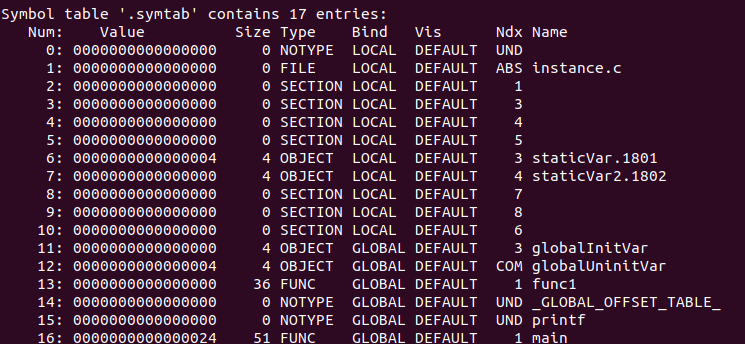
? 符號表結構 ELF檔案中符號表往往是一個段,叫做".symtab";結構上是一個包含Elf32_Sym結構體的陣列,其中Elf32_Sym對應一個符號,從上表我們可以得知,符號表的第一個元素是未定義符號,也就是無效的
? 以下是Elf32_Sym的結構體定義
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) 符號名,這個成員是該符號名的下標,因為我們是通過偏移量得出符號名 */
Elf32_Addr st_value; /* Symbol value 符號值 */
Elf32_Word st_size; /* Symbol size 符號型別的大小 */
unsigned char st_info; /* Symbol type and binding 符號型別和系結資訊 */
unsigned char st_other; /* Symbol visibility 目前為0,暫時沒用 */
Elf32_Section st_shndx; /* Section index 符號所在的段 */
} Elf32_Sym;
? st_info符號型別和系結資訊 該型別低4位識別符號號型別,高28位識別符號號系結資訊
符號系結資訊
| 宏定義名 | 值 | 說明 |
|---|---|---|
| STB_LOCAL | 0 | 區域符號 |
| STB_GLOBAL | 1 | 全域符號 |
| STB_WEAK | 2 | 弱參考 |
符號型別
| 宏定義名 | 值 | 說明 |
|---|---|---|
| STT_NOTYPE | 0 | 未知型別符號 |
| STT_OBJECT | 1 | 資料物件,如變數 |
| STT_FUNC | 2 | 函式或其他可執行代碼 |
| STT_SECTION | 3 | 段,此類符號必須為STB_LOCAL |
| STT_FILE | 4 | 檔案名,一般為目標檔案的源檔案名,必須是STB_LOCAL,其st_shndx必須為SHB_ABS |
? st_shndx符號所在段 若定義在本目標檔案內,表示符號所在段在段表中的下標;若不是,則較為特殊
| 宏定義名 | 值 | 說明 |
|---|---|---|
| SHN_ABS | 0xfff1 | 表示一個絕對的值,如意為檔案名的符號 |
| SHN_COMMON | 0xfff2 | 表示一個"COMMON塊"型別,一般來說是未初始化的全域符號 |
| SHN_UNDEF | 0 | 表示未定義,在本檔案參考,定義在其他目標檔案 |
? st_value符號值 按之前說的符號值是函式或變數的地址,但需分情況
- 目標檔案內,若表示的是符號的定義且不為"COMMON"(即st_shndx不為SHN_COMMON),則st_value表示該符號在段內偏移量
- 目標檔案內,若符號位"COMMON",則st_value表示符號的對齊屬性
- 可執行檔案內,st_value表示符號的虛擬地址
? 下面我們來分析實際的符號表內容
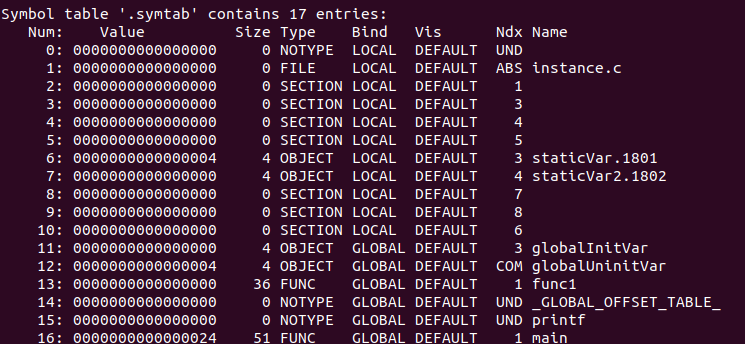
? Num對應st_name表示陣列下標;Value對應st_value表示符號值;Size對應st_size表示符號大小;Type和Bind對應st_info表示符號型別和系結資訊;Vis對應st_other在c/c++內并未使用,忽略,
我們可以看到符號型別Type存在SECTION型別的,這些型別表示下標為Ndx的段的段名,它們并沒有顯示符號名,因為段名就是它們的符號名.如Num為2的Ndx為1,說明它是".text"段的段名
? 特殊符號 聯結器進行鏈接產生可執行檔案時,會定義許多特殊符號,這些符號并不是在我們的程式中定義,但我們可以參考它,如:
- _executable_start,表示程式最開始的地址
- _end或end,程式結束地址
- __etext或_etext或etext,表示代碼為結束地址
- _edata或edata,表示資料段結束地址
? 符號修飾 在以前,編譯后產生的目標檔案,符號名與對應的變數函式的名字是一樣的,沒有變化;后來演化出相當多由匯編撰寫的庫和目標檔案,這時就產生了一個問題,程式若要使用這些庫,就不能使用庫中定義的變數函式的名字作為符號名,否則會發生沖突,為了防止符號名發生沖突,會對原本定義的名字加一些符號,如"_",也就是所謂的符號修飾,這并沒有從根本上解決問題,因此后來c++推出了名稱空間來解決這類問題
? 函式簽名 函式簽名包含一個函式的函式名、引數型別、所處類、名稱空間及其他資訊,函式簽名用于識別不同函式,在編譯器及聯結器處理符號時,會使用某種名稱修飾方法,使得每個函式簽名對應一個修飾后的名稱;這種方法不僅對函式有效,全域變數和靜態變數也在使用
? 弱符號和強符號 若我們在多個目標檔案中定義了相同名字的全域符號,鏈接時將會出現名稱重復的錯誤
? 編譯器默認函式和已初始化的全域變數為強符號;未初始化的全域變數為弱符號,當然,也可以通過"__attribute__((weak))"定義任何一個強符號為弱符號
? 判斷為強化號還是弱符號,是通過定義,而非參考
? 下面我們來分析一個例子
extern int exa;
int strong = 2;
int weak;
__attribute__((weak)) weak2 = 3;
int main()
{
//...
}
? 上述片段中,強符號有strong、main,弱符號有weak、weak2,exa都不是
? 聯結器會按如下規則處理和選擇被多次定義的全域符號:
- 不允許強符號被多次定義,否則聯結器報符號重復定義錯誤
- 若一個符號在一個目標檔案內為強符號,在其他檔案中都為弱符號,則選擇強符號
- 若一個符號在所用目標檔案內都為弱符號,則選擇占用空間最大的一個為強符號
? 盡量不要使用多個不同型別的弱符號,容易導致難以發現的錯誤
? 弱符號的優點:庫中定義的弱符號可以被用戶定義的強符號覆寫,使得程式可以使用定義的庫函式
除錯資訊
? 目標檔案內可能包含除錯資訊,且除錯資訊占用很大的空間,比代碼和資料還大幾倍
? 在gcc編譯時用"-g"引數,編譯器就會在目標檔案里加上除錯資訊
鏈接
? 也許你會疑惑已經轉變成機器指令了,為什么還需要鏈接?為什么不直接輸出可執行檔案反而輸出目標檔案?鏈接程序到底包含了什么?
? 在計算機最早的時候,撰寫并不像現在如此快捷輕松,當時的程式員使用機器語言在紙上寫好程式,當程式要被執行時,便手動地將程式寫入存盤設備紙帶(在紙帶上會打相應的孔),若一條指令需要執行的內容是跳轉到目的地的絕對地址;此時會面臨一個問題,程式并不是一層不變,大概率會經常被修改;若目的地的絕對地址發生變動,程式員又需要手動修改之前執行跳轉的指令,這種來來回回修改會使得開發效率十分低下,這個時候匯編語言如同救世主一般降臨,匯編語言因其使用接近人類的各種符號和標記幫助記憶,開發效率提高了很多,但問題到這里并沒有戛然而止,隨著軟體規模的日漸龐大,代碼里也快速地膨脹,這導致我們需要考慮將不同功能的代碼以一定方式組織起來,使得更加容易閱讀理解,對于以后維護十分有用,于是,逐漸地人們開始將代碼按功能或性質進行劃分,形成不同的功能模塊,不同模塊間按照層次結構組織;這些模塊相互依賴且相對獨立,問題接踵而至,當一個程式被分割為多個模塊后,這些模塊間如何形成一個單一程式?這就很像模塊間如何通信?
? 模塊間通信有兩種,都需要知道地址,也就是模塊間符號的參考:
- 模塊間函式呼叫
- 模塊間變數訪問
? 綜上,我們便可得出鏈接其實就是將一個復雜的系統逐步分割成小系統,把每個源代碼模塊獨立編譯,再按需將它們組裝,其原理便是將指令對其他符號地址的參考加以修正
? 聯結器所要做的便是將各個模塊之間相互作用的部分處理好,使得各個模塊間可以正確銜接,使用聯結器可以直接參考其他模塊的函式和全域變數而無需知其地址,因為鏈接時聯結器會根據參考的符號去自動查找符號的地址,再將參考符號地址的指令進行修正
? 鏈接的程序主要包括:地址空間分配、符號決議、重定位等
? 以下便是最基本的靜態鏈接程序:每個模塊的源代碼檔案經編譯器編譯為目標檔案,目標檔案和庫一起鏈接形成最終的可執行檔案
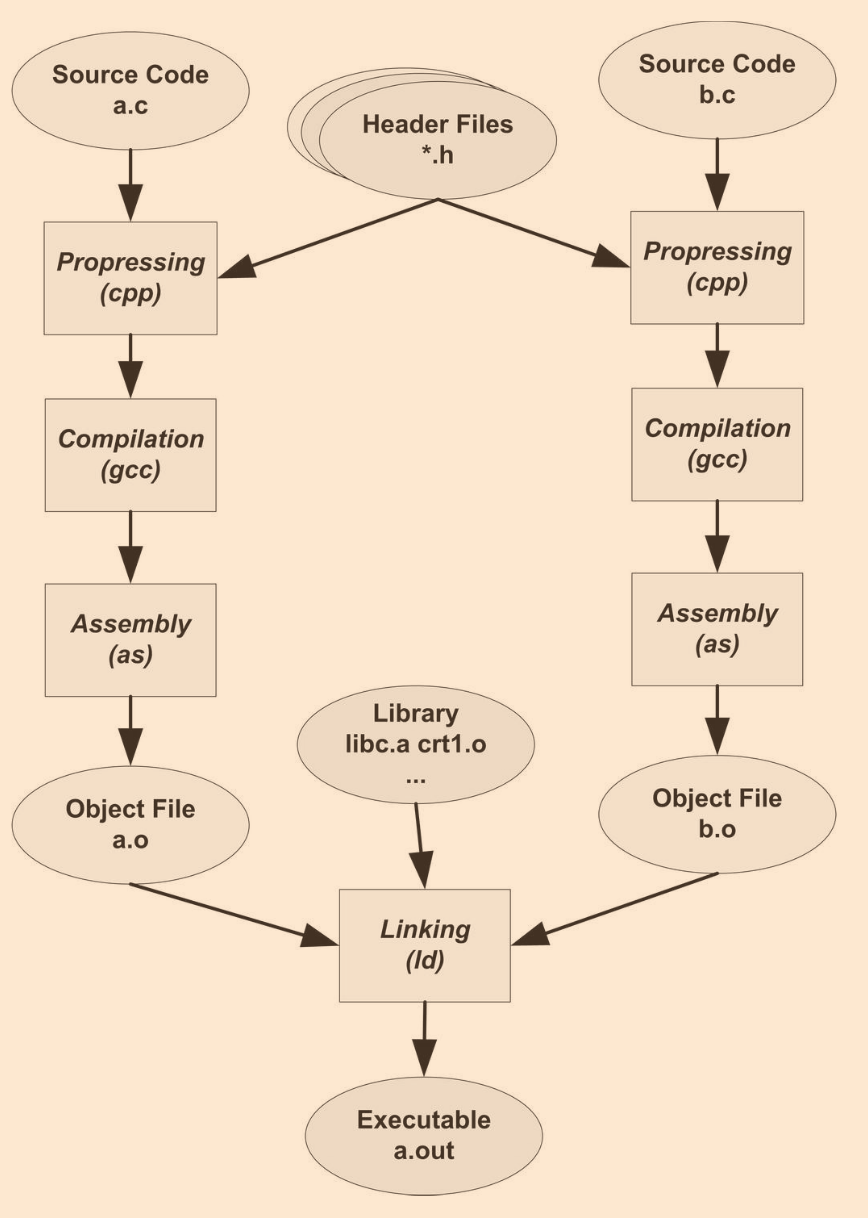
靜態鏈接
? 在這之前我們了解了基本的預編譯、編譯、匯編、鏈接的程序,并分析了ELF檔案輪廓和內容,接下來我們將進入本文的核心內容靜態鏈接
? 既然我們知道鏈接會將目標檔案合并為一個可執行檔案,那么這個程序要經歷哪些步驟?
? 現在有這樣兩個源檔案,main.c檔案會參考sub.c內的swap函式和變數,接下來我們要做的是將它們鏈接形成一個可執行檔案
//m.c
extern int shared;
void swap( int*, int* );
int main()
{
int x = 100;
swap( &shared, &x );
return 0;
}
//sub.c
int shared = 1;
void swap( int* a, int* b )
{
*a ^= *b ^= *a ^= *b;
}
空間與地址分配
? 我們知道,可執行檔案的代碼段和資料段是通過合并多個目標檔案得來的,那么對于這些目標檔案,聯結器是怎樣重新分配空間給這些目標檔案呢?
按序疊加 將各個目標檔案按照順序疊加
? 這種方法非常簡單,但會造成空間上的浪費,因為對每個段都有地址和空間上的對齊要求,這會導致存在許多零散的段,合并的目標檔案越多,問題愈加明顯
注:這里的地址和空間有兩個含義,對于".text"這種有實際資料的段,在檔案中和虛擬地址中都要分配空間;而".bss"段裝載前并不占用檔案空間,因此對他只是分配虛擬地址空間
- 輸出的可執行檔案中的空間
- 裝在后的虛擬地址中的虛擬地址空間
相似段合并 將相同性質的段合并在一起,這種方法是現在聯結器采用的
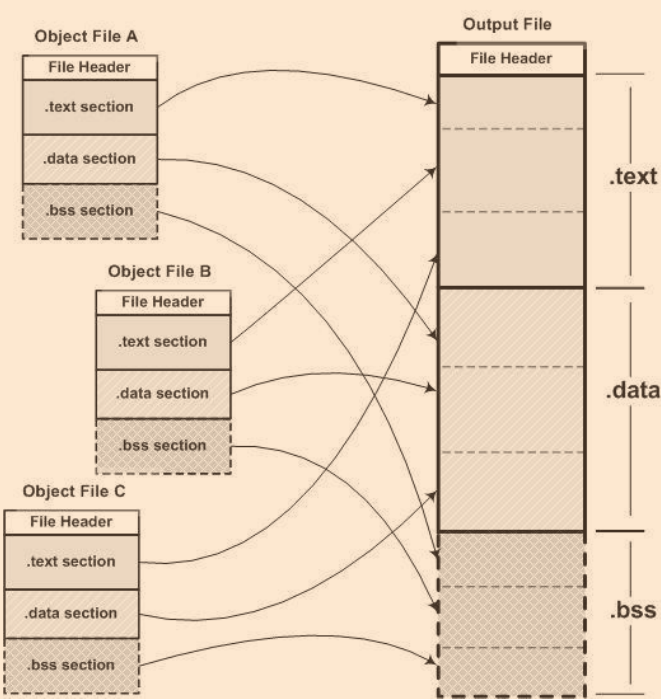
? 相似段合并鏈接分為兩步:
- 空間與地址分配 獲得所有目標檔案各自的各個段的長度、屬性、位置,計算出合并后的長度、位置并建立映射關系,將他們的符號表中所有的符號定義和符號參考統一放在一個全域符號表中
- 符號決議與重定位 獲得資訊后再進行符號決議、重定位、調整代碼中的地址等
? 下面,我們先編譯 m.c、sub.c,再用ld聯結器進行鏈接
? 其中, 編譯原始碼到目標檔案時,若沒有加“-fno-stack-protector”,默認會呼叫函式“__stack_chk_fail”進行堆疊相關檢查,且若是手動ld去鏈接,沒有鏈接“__stack_chk_fail”所在庫檔案,鏈接時必然會報此項錯誤,因此在編譯時加上“-fno-stack-protector”,強制gcc不做堆疊檢查,-e main表示將main函式作為程式入口,ld默認入口為_start;-o result表示輸出檔案名,默認為a.out

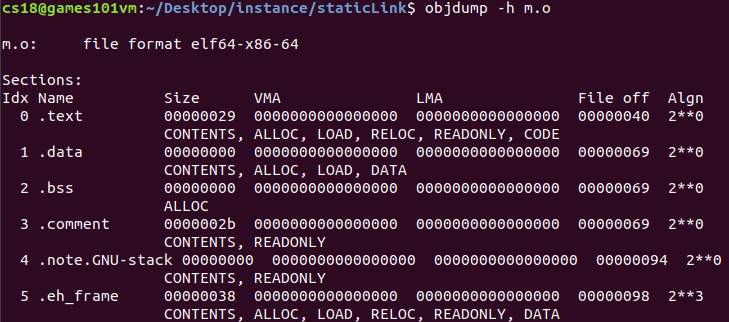
? 在用objdump查看鏈接前后地址的分配情況
m
? 
sub
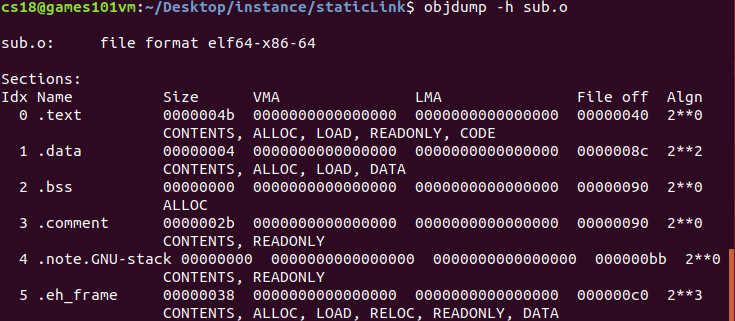
? 
result
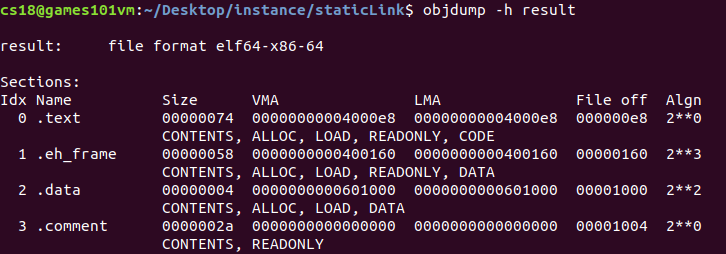
? 其中,VMA(virtual memory address)是虛擬地址,LMA(load memory address)是加載地址;大部分情況兩個值相同,但在某些嵌入式系統中可能不同,可以看到,鏈接前目標檔案中的所有VMA都為0,因此此時虛擬空間還沒有被分配,等到鏈接后,各個段都會被分配相應的虛擬地址;并且可以看到生成的可執行代碼result中的".text"Size大小是目標檔案m.c和sub.c的".text"之和,聰明的你也許發現了,可執行檔案中".text"段被分配到了0x4000e8,"data"段被分配到了0x400160,為什么虛擬地址不是從0開始呢?這與作業系統的行程虛擬地址空間分配規則有關,要將可執行檔案中的".text"和".data"段加載到一個新創建的行程中,Linux加載器會分配虛擬頁的一個連續的片(chunk),對于32位系統來說,地址是從0x08048000處開始的;對于64位系統來說,地址是從0x400000處開始的,然后把這些虛擬頁標記為無效的,也就是未被快取的,將頁表條目指向目標檔案中適當的位置(會詳細的內容會在以后的裝載部分討論)
確定符號地址 當完成前面段的虛擬地址確定后,聯結器就會開始計算各個符號的虛擬地址,因為符號在段內的相對位置是固定的,不會發生變化,因此我們只需給符號加上基礎地址,也就是它所處的段的虛擬地址
符號決議和重定位
? 空間和地址分配完成后,聯結器將進行符號決議和重定位,在進入這個主題前,我們先來看看鏈接前對兩個外部符號進行了什么操作,也就是說編譯m.c時,如何訪問外部符號
? 我們用objdump -d m.o查看反匯編結果
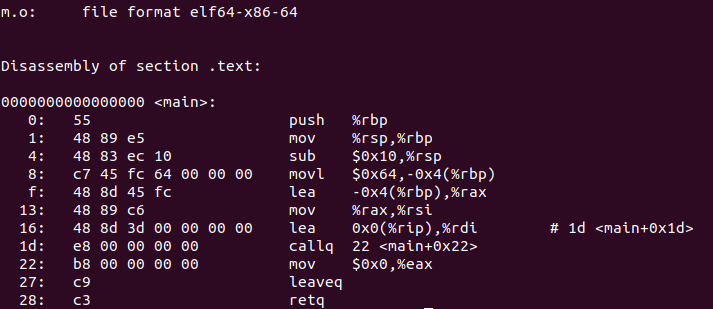
? 我們知道程式里代碼都用的虛擬地址,在未進行空間分配前,目標檔案代碼段的起始地址為0x00000000.最左邊那一串列示每條指令的偏移量,每一行表示一條指令,其中1d那一條指令表示參考"swap"的位置,第一個位元組表示操作碼,后四節表示被呼叫函式相對于呼叫指令的下一條指令的偏移量,相對偏移量也就是0,所以這條callq指令的實際呼叫地址時mov地址 + 0,也就是0x22;而16那一條指令lea表示對shared的參考,將shared地址賦值給rdi暫存器,前三個位元組為指令碼,后四個位元組時shared地址;其實兩個物件都是臨時地址,在編譯時并不知道外部符號的真正地址,等到鏈接時將真正的地址計算作業交給聯結器
? 通過先前的學習,我們知道地址和空間分配后就可確定所有符號的虛擬地址,隨后聯結器就可根據符號的地址對每個需要重定位的指令進行地址修正
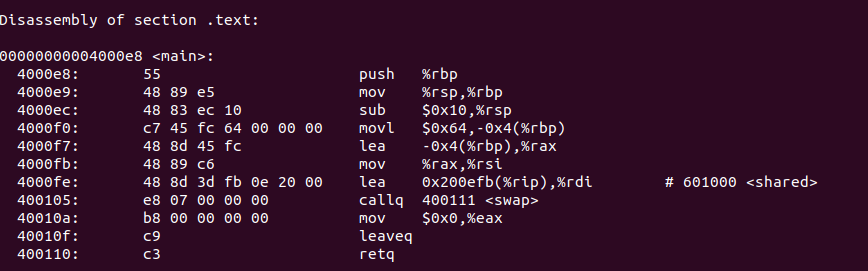
? 重定位 聯結器如何知道哪些指令是要被調整的呢?指令的哪些部分需要調整?如何調整?事實上是由重定位表告訴他,重定位表保存了重定位相關的資訊 ,描述如何修改相應的段的內容,每個要被重定位的段都有一個對應的重定位表
? 通過objdump -r m.o查看目標檔案的重定位表
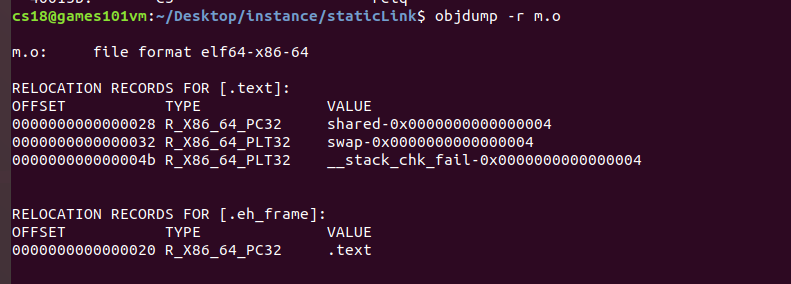
? 每個需要被重定位的地方叫做重定位入口,這里有四個;重定位入口的偏移量表示該入口在要被重定位的段中的位置
? 重定位表的結構
typedef struct
{
Elf32_Addr r_offset; /* Address 重定位入口的偏移.對于可重定位檔案來說,此值表示該重定位入口所要修正的位置的第一個位元組相對于段起始的偏移量;對于可執行檔案或共享物件檔案來說,此值表示該重定位入口所要修正的位置的第一個位元組的虛擬地址 */
Elf32_Word r_info; /* Relocation type and symbol index 重定位入口的型別和符號.低八位表示重定位入口的型別,高24位標識重定位入口的符號在符號表中的下標.各處理器的指令格式不同,因此重定位所修正的指令地址格式也不一樣*/
} Elf32_Rel;
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
} Elf64_Rel;
? 符號決議 重定位時,每個重定位入口都是對一個符號的參考,那么當聯結器要對某符號的參考進行重定位時,他需要確定這個符號的地址,因此聯結器就去全域符號表查找相應的符號,再進行重定位
? readelf -s m.o 查看符號表
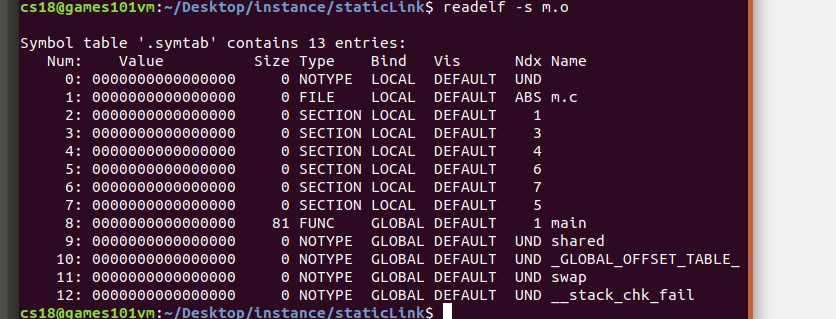
? 意料之中,我們可以看到shared和swap為UND型別,也就是未定義型別.在聯結器掃描完所有目標檔案后,必須能從全域符號表中查找到UND型別的符號,否則會報符號未定義的錯誤
靜態庫鏈接
? 我們知道,在我們平常使用的編程語言中有輸入輸出方式,這些輸入輸出肯定呼叫了系統提供的API,否則我們不可能僅憑一行代碼就能實作輸入輸出,而這些語言都會將API包裝成一個語言庫,例如,c++的cout需要呼叫<iostream>語言庫,當然,語言庫中有些函式并不會呼叫作業系統的API,如strlen()
? 在一個語言如c++的運行庫中,包含許多和系統功能有關的代碼,如輸入輸出、時間等,這其中包含了許許多多的目標檔案,若是將這些檔案直接給程式員使用,那恐怕程式員得禿頂了;因此會將這些目標檔案打包壓縮在一起,且標注編號和索引,便于查找和檢索,這也就是我們常說的靜態庫
? 根據上面的內容,我們可以定義靜態庫就是一組目標檔案的集合,很多目標檔案經過壓縮打包后形成的一個檔案
? 那靜態庫鏈接是什么呢?顯而易見答案已經呼之欲出了,將我們寫的源檔案編譯成目標檔案和需要的靜態庫里的目標檔案鏈接;當然很有可能,靜態庫里的目標檔案里的符號也依賴于其他目標檔案,相當于會遞回很多很多次;很顯然,我們鏈接時不可能將一個完整的目標檔案全部包含,由于之前說的會遞回很多次,這樣會造成運行庫中有許多許多的符號,會造成極大的空間浪費,因此只會包含目標檔案中需要的符號
BFD庫
? 現在的硬體和軟體平臺種類五花八門,這導致了不同平臺都有它自己獨特的目標檔案格式,這些差異導致編譯器和聯結器很難處理不同平臺間的目標檔案,因此對于這種問題,我們需要一種統一的介面處理不同平臺格式間的差異,BFD庫就做到了這一點
? BFD庫將目標檔案抽象為一個統一的模型,這個模型會抽象目標檔案的檔案頭、段、符號表等等,這樣使得BFD庫的程式只需使用這個抽象的模型就可以操作所有BFD支持的目標檔案格式
? GCC這種可跨平臺的工具就是使用BFD庫處理目標檔案,而不是直接使用目標檔案,好處是編譯器和聯結器處理的目標檔案分隔開來,一旦需要支持一種新的目標檔案格式,只須在BFD庫中添加對應的格式即可,無需修改編譯器和聯結器
總結
? 在本章中,我們講到編譯器和聯結器為我們服務時究竟做了哪些幕后作業,我們了解到從源檔案到最終可執行檔案的預編譯、編譯、匯編、鏈接整個程序是怎樣的,分析每個步驟的作用和前后間的關系;我們還深入分析了各種目標檔案格式及其包含的內容,主要介紹有代碼段、資料段、BSS段、檔案頭、段表、重定位表、字串表、符號表等,發現原來可執行檔案、目標檔案、庫也不過如此,都是基于段的檔案的集合;最后我們介紹了靜態鏈接這型別的奧秘,目標檔案在唄鏈接成可執行檔案時,目標檔案中的段是如何合并的,聯結器是如何為他們分配地址和空間的,最終地址確定后,聯結器會將各個目標檔案中對外部符號的參考進行決議,將段中重定位指令和資料進行指正,使他們指向正確的位置
? 請慢慢地咀嚼消化這些知識,接下來我們將進入裝載的世界,學習關于可執行檔案裝載到記憶體的知識以及這一程序究竟是怎樣的,它的本質是什么
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/528061.html
標籤:其他
上一篇:<一>類,物件,this指標
下一篇:第9章 記憶體模型和名稱空間