
大家好,又見面了,
本文是筆者作為掘金技術社區簽約作者的身份輸出的快取專欄系列內容,將會通過系列專題,講清楚快取的方方面面,如果感興趣,歡迎關注以獲取后續更新,
通過《深入理解快取原理與實戰設計》系列專欄的前兩篇內容,我們介紹了快取的整體架構、設計規范,也闡述了快取的常見典型問題及其使用策略,作為該系列的第三篇文章,本篇我們將一起探討下專案中本地快取的各種使用場景與應對實作策略 —— 也通過本篇介紹的幾個本地快取的實作策略與關鍵特性的支持,體會到本地快取使用與構建的關注要點,也作為我們下一篇文章要介紹的手寫本地快取通用框架的鋪墊,

本地快取的遞進史
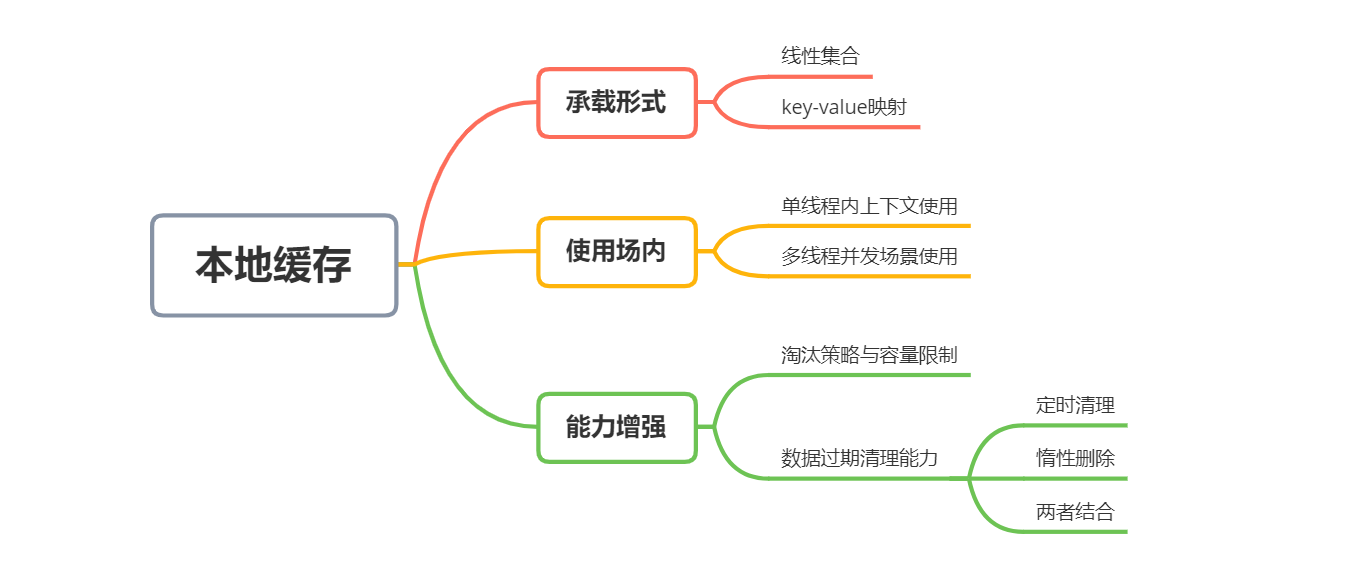
從本質上來說,快取其實就是一堆資料的集合(甚至有的時候,這個集合中只有1個元素,比如一些快取計數器),再直白點,它就是一個容器而已,在各個編程語言中,容器類的物件型別都有很多不同種類,這就需要開發人員根據業務場景不同的訴求,選擇不同的快取承載容器,并進行二次加工封裝以契合自己的意愿,
下面我們就一起看下我們實作本地快取的時候,可能會涉及到的一些常見的選型型別,
小眾訴求 —— 最簡化的集合快取
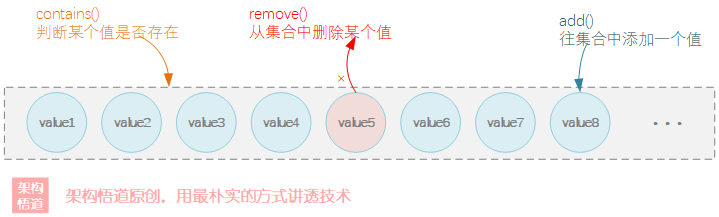
List或者Array算是比較簡單的一種快取承載形式,常用于一些黑白名單類資料的快取,業務層面上用于判斷某個值是否存在于集合中,然后作出對應的業務處理,
比如有這么個場景:
在一個論壇系統中,管理員會將一些違反規定的用戶拉入黑名單中禁止其發帖,這些黑名單用戶ID串列是存盤在資料庫中一個獨立的表中,
當用戶發帖的時候,后臺需要判斷此用戶是否在被禁言的黑名單串列里,如果在,則禁止其發帖操作,
因為黑名單ID的數量不會很多,為了避免每次用戶發帖操作都查詢一次DB,可以選擇將黑名單用戶ID加載到記憶體中進行快取,然后每次發帖的時候判斷下是否在黑名單中即可,實作時,可以簡單的用List去承載:
public class UserBlackListCache {
private List<String> blackList;
public boolean inBlackList(String userId) {
return blackList.contains(userId);
}
public void addIntoBlackList(String userId) {
blackList.add(userId);
}
public void removeFromBlackList(String userId) {
blackList.remove(userId);
}
}
作為一個基于List實作的黑名單快取,一共對外提供了三個API方法:
| 介面名稱 | 功能說明 |
|---|---|
| inBlackList | 判斷某個用戶是否在黑名單 |
| addIntoBlackList | 將某個用戶添加到黑名單中 |
| removeFromBlackList | 將某個用戶從黑名單中移除 |
List或者Array形式,由于資料結構比較簡單,無冗余資料,快取存盤的時候記憶體占用量相對會比較經濟些,當然,受限于List和Array自身的資料結構特點,實作按條件查詢操作的時候時間復雜度會比較高,所以使用場景相對有限,
眾生形態 —— 常規鍵值對快取
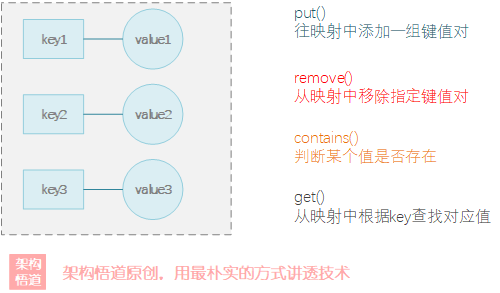
相比List這種線性集合容器而言,在實際專案中,更多的場景會選擇使用一些key-value格式的映射集(比如HashMap)來作為容器 —— 這也是大部分快取的最基礎的資料結構形態,業務上可以將查詢條件作為key值,然后將實際內容作為value值進行存盤,可以實作高效的單條資料條件查詢匹配,
還是上述的發帖論壇系統的一個場景:
用戶登錄論壇系統,查看帖子串列的時候,界面需呼叫后端提供的帖子串列查詢請求,在帖子串列中,會顯示每個帖子的發帖人資訊,
由于帖子的發帖人只存盤了個UID資訊,而需要給到界面的是這個UID對應用戶的簡要資訊,比如頭像、昵稱、注冊年限等等,所以在帖子串列回傳前,還需要根據UID查詢到對應的用戶資訊,最后一并回傳給前端,
按照上述的要求,如果每次查詢到帖子串列之后,再去DB中根據UID逐個去查詢每個帖子對應的用戶資訊,勢必會導致每個串列介面都需要呼叫很多次DB查詢用戶的操作,所以如果我們將用戶的簡要資訊映射快取起來,然后每次直接從快取里面根據UID查詢即可,這樣可以大大簡化每次查詢操作與DB的互動次數,
使用HashMap來構建快取,我們可以將UID作為key,而UserInfo作為value,代碼如下:
public class UserCache {
private Map<String, UserInfo> userCache = new HashMap<>();
public void putUser(UserInfo user) {
userCache.put(user.getUid(), user);
}
public UserInfo getUser(String uid) {
if (!userCache.containsKey(uid)) {
throw new RuntimeException("user not found");
}
return userCache.get(uid);
}
public void removeUser(String uid) {
userCache.remove(uid);
}
public boolean hasUser(String uid) {
return userCache.containsKey(uid);
}
}
為了滿足業務場景需要,上述代碼實作的快取對外提供幾個功能介面:
| 介面名稱 | 功能說明 |
|---|---|
| putUser | 將指定的用戶資訊存盤到快取中 |
| getUser | 根據UID獲取對應的用戶資訊資料 |
| removeUser | 洗掉指定UID對應的用戶快取資料 |
| hasUser | 判斷指定的用戶是否存在 |
使用HashMap構建快取,可以輕松的實作O(1)復雜度的資料操作,執行性能可以得到有效保障,這也是為什么HashMap被廣泛使用在快取場景中的原因,
容量約束 —— 支持資料淘汰與容量限制的快取
通過類似HashMap的結構來快取資料是一種簡單的快取實作策略,可以解決很多查詢場景的實際訴求,但是在使用中,有些問題也會慢慢浮現,
在線上問題定位程序中,經常會遇到一些記憶體溢位的問題,而這些問題的原因,很大一部分都是由于對容器類的使用不加約束導致的,
所以很多情況下,出于可靠性或者業務自身訴求考量,會要求快取的HashMap需要有最大容量限制,如支持LRU策略,保證最多僅快取指定數量的資料,
比如在上一節中,為了提升根據UID查詢用戶資訊的效率,決定將用戶資訊快取在記憶體中,但是這樣一來:
-
論壇的用戶量是在一直增加的,這樣就會導致加載到記憶體中的用戶資料量也會越來越大,記憶體占用就會
無限制增加,萬一用戶出現井噴式增長,很容易會把記憶體撐滿,造成記憶體溢位問題; -
論壇內的用戶,其實有很多用戶注冊之后就是個僵尸號,或者是最近幾年都沒有再使用系統了,這些資料加載到記憶體中,業務幾乎不會使用到,白白占用記憶體而已,
這種情況,就會涉及到我們在前面文章中提到的一個快取的基礎特性了 —— 快取淘汰機制!也即支持熱點資料存盤而非全量資料存盤,我們可以對上一節實作的快取進行一個改造,使其支持限制快取的最大容量條數,如果超過此條數,則基于LRU策略來淘汰最不常用的資料,
我們可以基于LinkedHashMap來實作,比如我們可以先實作一個支持LRU的快取容器LruHashMap,代碼示例如下:
public class LruHashMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1287190405215174569L;
private int maxEntries;
public LruHashMap(int maxEntries, boolean accessOrder) {
super(16, 0.75f, accessOrder);
this.maxEntries = maxEntries;
}
/**
* 自定義資料淘汰觸發條件,在每次put操作的時候會呼叫此方法來判斷下
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxEntries;
}
}
如上面實作的快取容器,提供了一個構造方法,允許傳入兩個引數:
-
maxEntities :此快取容器允許存盤的最大記錄條數,
-
accessOrder :決定資料淘汰排序策略,傳入
true則表示基于LRU策略進行排序,false則表示基于資料寫入先后進行排序,
往快取里面寫入新資料的時候,會判斷快取容器中的資料量是否超過maxEntities,如果超過就會基于accessOrder所指定的排序規則進行資料排序,然后將排在最前面的元素給洗掉,挪出位置給新的待插入資料,
我們使用此改進后的快取容器,改寫下前面的快取實作:
public class UserCache {
private Map<String, UserInfo> userCache = new LruHashMap<>(10000, true);
public void putUser(UserInfo user) {
userCache.put(user.getUid(), user);
}
public UserInfo getUser(String uid) {
// 因為是熱點快取,非全量,所以快取中沒有資料,則嘗試去DB查詢并加載到記憶體中(演示代碼,忽略例外判斷邏輯)
if (!userCache.containsKey(uid)) {
UserInfo user = queryFromDb(uid);
putUser(user);
return user;
}
return userCache.get(uid);
}
}
相比于直接使用HashMap來構建的快取,改造后的快取增加了基于LRU策略進行資料淘汰的能力,可以限制快取的最大記錄數,既可以滿足業務上對快取資料有要求的場景使用,又可以規避因為呼叫方的原因導致的快取無限增長然后導致記憶體溢位的風險,還可以減少無用冷資料對記憶體資料的占用浪費,
執行緒并發場景
為了減少記憶體浪費、以及防止記憶體溢位,我們上面基于LinkedHashMap定制打造了個支持LRU策略的限容快取器,具備了更高級別的可靠性,但是作為快取,很多時候是需要行程內整個系統全域共享共用的,勢必會涉及到在并發場景下去呼叫快取,
而前面我們實作的幾種策略,都是非執行緒安全的,適合區域快取或者單執行緒場景使用,多執行緒使用的時候,我們就需要對前面實作進行改造,使其變成執行緒安全的快取容器,
對于簡單的不需要淘汰策略的場景,我們可以使用ConcurrentHashMap來替代HashMap作為快取的容器存盤物件,以獲取執行緒安全保障,
而對于我們基于LinkedHashMap實作的限容快取容器,要使其支持執行緒安全,可以使用最簡單粗暴的一種方式來實作 —— 基于同步鎖,比如下面的實作,就是在原有的LruHashMap基礎上嵌套了一層保護殼,實作了執行緒安全的訪問:
public class ConcurrentLruHashMap<K, V> {
private LruHashMap<K, V> lruHashMap;
public ConcurrentLruHashMap(int maxEntities) {
lruHashMap = new LruHashMap<>(maxEntities);
}
public synchronized V get(Object key) {
return lruHashMap.get(key);
}
public synchronized void put(K key, V value) {
lruHashMap.put(key, value);
}
private static class LruHashMap<K, V> extends LinkedHashMap<K, V> {
private int maxEntities;
public LruHashMap(int maxEntities) {
super(16, 0.75f, true);
this.maxEntities = maxEntities;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxEntities;
}
}
}
為了盡量降低鎖對快取操作性能的影響,我們也可以對同步鎖的策略進行一些優化,比如可以基于分段鎖來降低同步鎖的粒度,減少鎖的競爭,提升性能,
另外,Google Guava開源庫中也有提供一個ConcurrentLinkedHashMap,同樣支持LRU的策略,并且在保障執行緒安全方面的鎖機制進行了優化,如果專案中有需要的話,也可以考慮直接引入對應的開源庫進行使用,
曲終人散 —— TTL快取過期機制
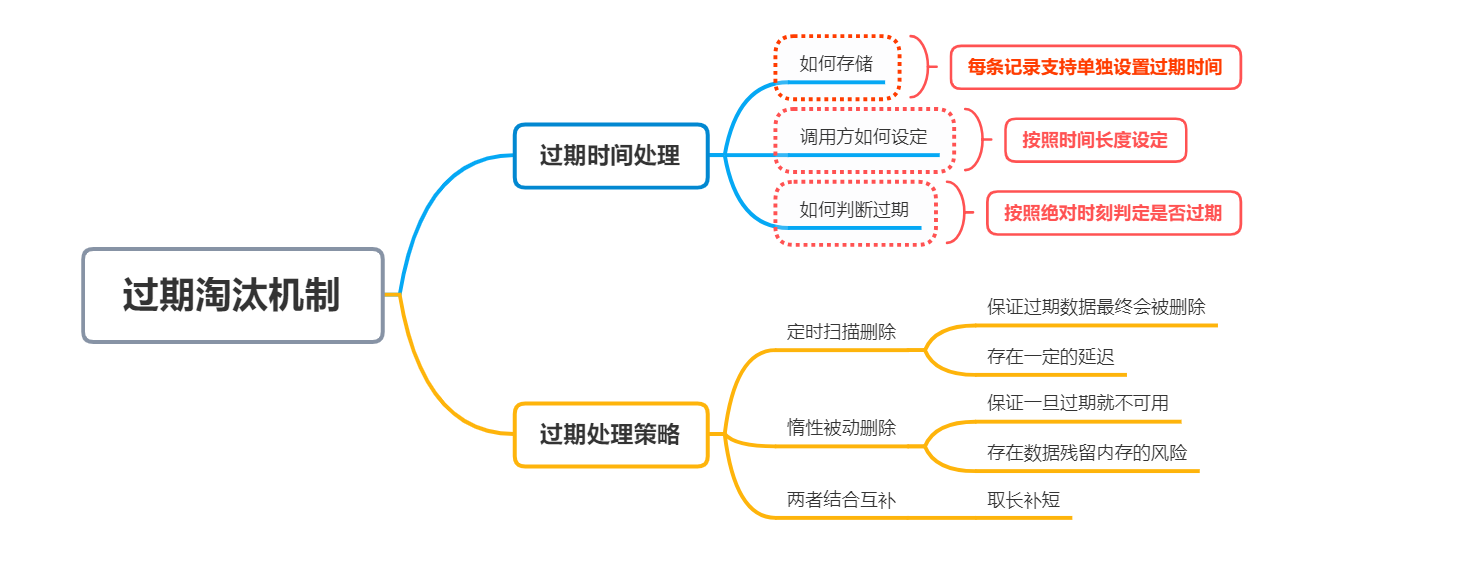
使用快取的時候,經常會需要設定快取記錄對應的有效期,支持將過期的快取資料洗掉,要實作此能力,需要確定兩點處理策略:
-
如何存盤每條資料的過期時間
-
何種機制去洗掉已經過期的資料
下面展開聊一聊,
過期時間存盤與設定
既然要支持設定過期時間,也即需要將過期時間一并存盤在每條記錄里,對于常規的key-value型別的快取架構,我們可以對value結構進行擴展,包裹一層公共的快取物件外殼,用來存盤一些快取管理需要使用到的資訊,比如下面這種實作:
@Data
public class CacheItem<V> {
private V value;
private long expireAt;
// 后續有其它擴展,在此補充,,,
}
其中value用來存盤真實的快取資料,而其他的一些輔助引數則可以一并隨value存盤起來,比如用來記錄過期時間的expireAt引數,
對于過期時間的設定,一般有兩種時間表述形式:
-
使用絕對時刻,比如指定2022-10-13 12:00:00過期
-
使用時間間隔,比如指定5分鐘過期
對于使用方而言,顯然第2種形式設定起來更加方便、也更符合業務的實際使用場景,而對于快取實作而言,顯然使用第1種方式,管理每條資料是否過期的時候會更可行(如果用時間間隔,還需要額外存盤時間間隔的計時起點,或者不停的去扣減剩余時長,比較麻煩),作為應對之策,我們可以在快取過期時間設定的時候進行一次轉換,將呼叫方設定的過期時間間隔,轉換為實際存盤的絕對時刻,這樣就可以滿足兩者的訴求,
結合上面的結論,我們可有寫出如下代碼:
public class DemoCache<K, V> {
private Map<K, CacheItem<V>> cache = new HashMap<>();
/**
* 單獨設定某個key對應過期時間
* @param key 唯一標識
* @param timeIntvl 過期時間
* @param timeUnit 時間單位
*/
public void expireAfter(K key, int timeIntvl, TimeUnit timeUnit) {
CacheItem<V> item = cache.get(key);
if (item == null) {
return;
}
long expireAt = System.currentTimeMillis() + timeUnit.toMillis(timeIntvl);
item.setExpireAt(expireAt);
}
/**
* 寫入指定過期時間的快取資訊
* @param key 唯一標識
* @param value 快取實際值
* @param timeIntvl 過期時間
* @param timeUnit 時間單位
*/
public void put(K key, V value, int timeIntvl, TimeUnit timeUnit) {
long expireAt = System.currentTimeMillis() + timeUnit.toMillis(timeIntvl);
CacheItem<V> item = new CacheItem<>();
item.setValue(value);
item.setExpireAt(expireAt);
cache.put(key, item);
}
// 省略其他方法
}
上面代碼中,支持設定不同的時長單位,比如是Second、Minute、Hour、Day等,這樣可以省去業務方自行換算時間長度的操作,并且,提供了一個2個途徑設定超時時間:
-
獨立介面指定某個資料的過期時長
-
寫入或者更新快取的時候直接設定對應的過期時長
而最終存盤的時候,也是在快取內部將呼叫方設定的超時時長資訊,轉換為了一個絕對時間戳值,這樣后續的快取過期判斷與資料清理的時候就可以直接使用,
具體業務呼叫的時候,可以根據不同的場景,靈活的進行過期時間的設定,比如當我們登錄的時候會生成一個token,我們可以將token資訊快取起來,使其保持一定時間內有效:
public void afterLogin(String token, User user) {
// ... 省略業務邏輯細節
// 將新創建的帖子加入快取中,快取30分鐘
cache.put(token, user, 30, TimeUnit.MINUTES);
}
而對于一個已有的記錄我們也可以單獨去設定,這種經常使用于在快取續期的場景中,比如上面說的登錄成功后會將token資訊快取30分鐘,而這個時候我們希望用戶如果一直在操作的話,就不要使其token失效,否則使用到一半就要求用戶重新登錄,這種體驗就會很差,我們可以這樣:
public PostInfo afterAuth(String token) {
// 每次使用后,都重新設定過期時間為30分鐘后(續期)
cache.expireAfter(token, 30, TimeUnit.MINUTES);
}
這樣一來,只要用戶登錄后并且一直在做操作,token就一直不會失效,直到用戶連續30分鐘未做任何操作的時候,token才會從快取中被過期洗掉,
過期資料洗掉機制
上面一節中,我們已經確定了快取過期時間的存盤策略,也給定了呼叫方設定快取時間的操作介面,這里還剩一個最關鍵的問題需要解決:對于設定了過期時間的資料,如何在其過期的時候使其不可用?下面給出三種處理的思路,
定時清理
這是最容易想到的一種實作,我們可以搞個定時任務,定時的掃描所有的記錄,判斷是否有過期,如果過期則將對應記錄洗掉,因為涉及到多個執行緒對快取的資料進行處理操作,出于并發安全性考慮,我們的快取可以采用一些執行緒安全的容器(比如前面提過的ConcurrentHashMap)來實作,如下所示:
public class DemoCache<K, V> {
private Map<K, CacheItem<V>> cache = new ConcurrentHashMap<>();
public DemoCache() {
timelyCleanExpiredItems();
}
private void timelyCleanExpiredItems() {
new Timer().schedule(new TimerTask() {
@Override
public void run() {
cache.entrySet().removeIf(entry -> entry.getValue().hasExpired());
}
}, 1000L, 1000L * 10);
}
// 省略其它方法
}
這樣,我們就可以根據快取的總體資料量以及快取對資料過期時間的精度要求,來設定一個合理的定時執行策略,比如我們設定每隔10s執行一次過期資料清理任務,那么當一個任務過期之后,最壞情況可能會在過期10s后才會被洗掉(所以過期時間精度控制上會存在一定的誤差范圍),
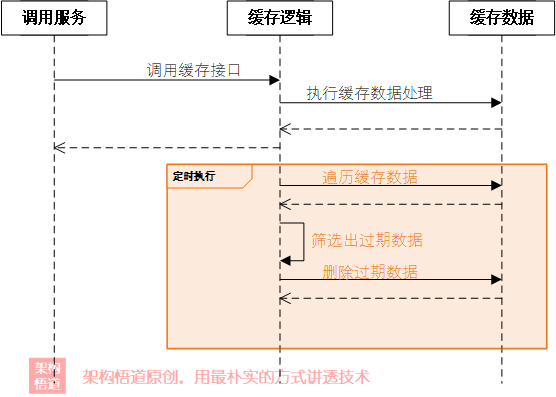
此外,為了盡可能保證控制的精度,我們就需要將定時清理間隔盡可能的縮短,但是當快取資料量較大時,頻繁的全量掃描操作,也會對系統性能造成一定的影響,
惰性洗掉
這是另一種資料過期的處理策略,與定時清理這種主動出擊的激進型策略相反,惰性洗掉不會主動去判斷快取是否失效,而是在使用的時候進行判斷,每次讀取快取的時候,先判斷對應記錄是否已經過期,如果過期則直接洗掉并且告知呼叫方沒有此快取資料,
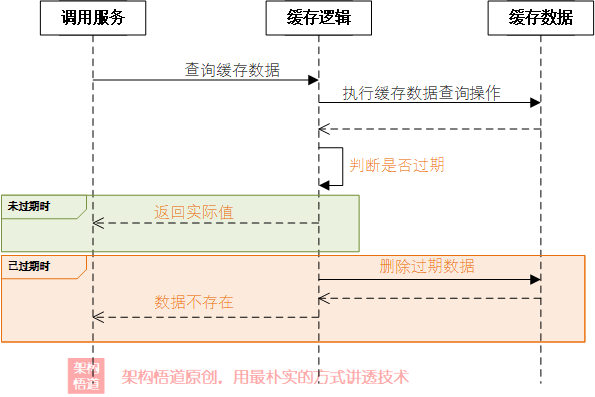
代碼如下所示:
public class DemoCache<K, V> {
private Map<K, CacheItem<V>> cache = new HashMap<>();
/**
* 從快取中查詢對應值
* @param key 快取key
* @return 快取值
*/
public V get(K key) {
CacheItem<V> item = cache.get(key);
if (item == null) {
return null;
}
// 如果已過期,則洗掉,并回傳null
if (item.hasExpired()) {
cache.remove(key);
return null;
}
return item.getValue();
}
// 省略其它方法
}
相比于定時清理機制,基于惰性洗掉的策略,在代碼實作上無需額外的獨立清理服務,且可以保證資料一旦過期后立刻就不可用,但是惰性洗掉也存在一個很大的問題,這種依靠外部呼叫來觸發自身資料清理的機制不可控因素太多,如果一個記錄已經過期但是沒有請求來查詢它,那這條已過期的記錄就會一直駐留在快取中,造成記憶體的浪費,
兩者結合
如前所述,不管是主動出擊的定時清理策略,還是躺平應付的惰性洗掉,都不是一個完美的解決方案:
-
定時清理可以保證記憶體中過期資料都被洗掉,但是頻繁執行易造成性能影響、且過期時間存在精度問題
-
惰性洗掉可以保證過期時間控制精準,且可以解決性能問題,但是易造成記憶體中殘留過期資料無法洗掉的問題
但是上述兩種方案的優缺點恰好又是可以相互彌補的,所以我們可以將其結合起來使用,取長補短,
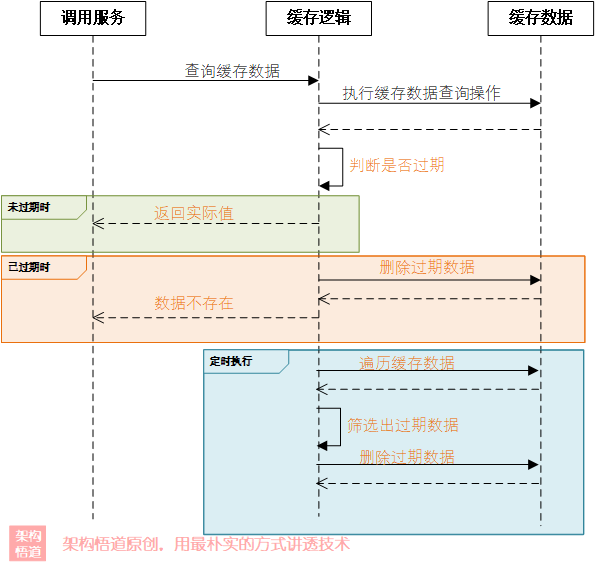
看下面的實作:
public class DemoCache<K, V> {
private Map<K, CacheItem<V>> cache = new ConcurrentHashMap<>();
public DemoCache() {
timelyCleanExpiredItems();
}
private void timelyCleanExpiredItems() {
new Timer().schedule(new TimerTask() {
@Override
public void run() {
cache.entrySet().removeIf(entry -> entry.getValue().hasExpired());
}
}, 1000L, 1000L * 60 * 60 *24);
}
public V get(K key) {
CacheItem<V> item = cache.get(key);
if (item == null) {
return null;
}
// 如果已過期,則洗掉,并回傳null
if (item.hasExpired()) {
cache.remove(key);
return null;
}
return item.getValue();
}
}
上面的實作中:
1.使用惰性洗掉策略,每次使用的時候判斷是否過期并執行洗掉策略,保證過期資料不會被繼續使用,
- 配合一個
低頻定時任務作為兜底(比如24小時執行一次),用于清理已過期但是始終未被訪問到的快取資料,保證已過期資料不會長久殘留記憶體中,由于執行頻率較低,也不會對性能造成太大影響,
小結回顧
回顧下本篇的內容,作為手寫本地快取框架的前菜,我們先介紹了一些專案中本地快取實作的幾種情況,一起一些諸如淘汰策略、過期失效等能力的開發初體驗,
這些內容在專案開發中出現的頻率極高,幾乎在任何有點規模的專案中都會或多或少使用到,我們將其稱之為手寫本地快取的“前菜”,是因為這些都是一些零散的獨立場景應對策略,就像一個個游擊隊,分散出擊,各自撐起自己的一小塊根據地,在本篇內容的基礎上,我們下一篇文章將會一起聊一聊如何在游擊隊經驗的基礎上,打造一支正規軍 —— 構建一個通用化、系統化的完整本地快取框架,
那么,關于本篇前面提到的各種“游擊隊”式的本地快取,你在編碼中是否有涉及過呢?你是如何實作的呢?歡迎評論區一起交流下,期待和各位小伙伴們一起切磋、共同成長,
?? 補充說明 :
本文屬于《深入理解快取原理與實戰設計》系列專欄的內容之一,該專欄圍繞快取這個宏大命題進行展開闡述,全方位、系統性地深度剖析各種快取實作策略與原理、以及快取的各種用法、各種問題應對策略,并一起探討下快取設計的哲學,
如果有興趣,也歡迎關注此專欄,
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點贊 + 關注讓我感受到您的支持,也可以關注下我的公眾號【架構悟道】,獲取更及時的更新,
期待與你一起探討,一起成長為更好的自己,

本文來自博客園,作者:架構悟道,歡迎關注公眾號[架構悟道]持續獲取更多干貨,轉載請注明原文鏈接:https://www.cnblogs.com/softwarearch/p/16853149.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/528117.html
標籤:Java