徹底搞懂c語言陣列與指標
部分參考
- c語言指標怎么理解 知乎
- 程式設計入門————c語言 (浙江大學翁愷)
- 《c primer plus》第六版
基礎知識
1. 指標基礎
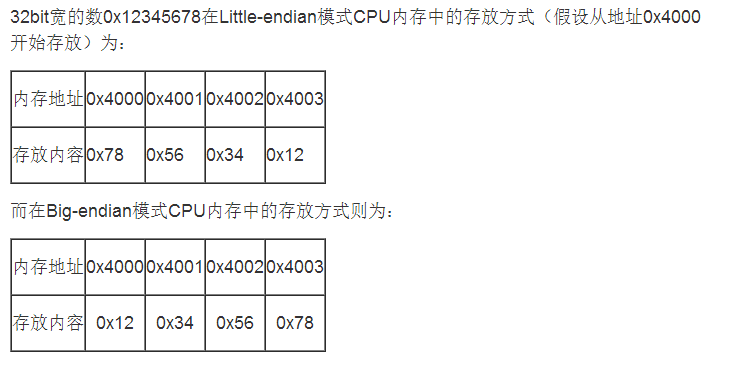
- 關于電腦大小端的討論:大端是指是指資料的高位元組,保存在記憶體的低地址中,而資料的低位元組,保存在記憶體的高地址中,小端是指資料的高位元組保存在記憶體的高地址中,而資料的低位元組保存在內在的低地址中,例如下圖:
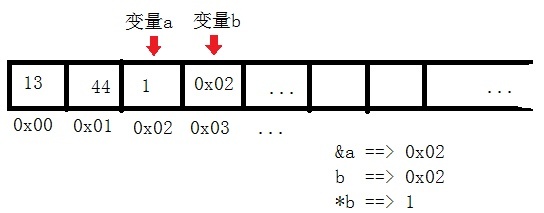
- 假設 int b=4; int *a = &b 則*a=4: 因為*a代表a變數中的地址所指的值,重復一下對比:&b是指標型別,值是地址;*b是實際指標b所指的變數的值,
- 如果列印地址則用%p,以16進制顯示指標的值,而不是用%x,如: printf("%p\n", &i)
- 32位和64位下指標的長處不同,32位下為4個位元組,和int一樣,64位下8個位元組,
2. 陣列基礎
-
陣列特點:
- 陣列大小一旦定義不可改變
- 所有的元素具有相同的資料型別
- 陣列中的元素在記憶體中是連續依次排列的
- 陣列的集成初始化:int a[] = {1,2,3,4,25,6,5,4}; 即讓編譯器自己來數元素的數量
- 如果這樣賦值:int a[3] = {2}; 則結果是這個陣列有三個元素,a[0]=2,a[1]=0,a[2]=0;編譯器自動補全后面的數字為0;
- 集成初始化的定位:int a[6] = {[1] = 2, [3] = 3, 6}; 結果是 a[0]=0, a[1]=2, a[2]=0, a[3]=3, a[4]=6, a[5]=0; 適合初始資料稀疏的陣列,
- 如果想讓定義的陣列變成只讀,即不可修改的型別,則可以在最前面加上一個const,如:const int a[2] = {2, 3, 4}; 當然此條也適用于二維陣列,
- 陣列只有在最開始即定義初始化的時候可以集成賦值,下列賦值方法錯誤:int a[3] = {}; a[3] = {1,2,3}; 這時會錯誤,因為這是一個單個元素賦值的方法,況且a[3]已經超出了范圍,
- 求陣列的大小,穩定的方法是 sizeof(a)/sizeof(a[0]) ; 就算修改初始陣列a中的資料,也不用修改遍歷時的代碼;
- 陣列作為函式引數時,往往必須再用另一引數來傳入陣列的大小,
- 不能在[]中給出陣列的大小
- 不能在函式中再利用sizeof計算陣列的元素的個數
- 定義陣列a, b:int a[10]; b=[]; 則不能直接用b=a來給陣列b賦值,
- 對于陣列a,&a=a=&a[0]
-
二維陣列:
- int a[2][3] 相當于一個2行3列的矩陣
- int a[0][0] 表示第一行第一列,意味著下標同樣也是從0開始
- 二維陣列的遍歷需要嵌套for回圈
- a[i][j]表示第i行第j列的元素,a[i,j]是一個運算式,相當于a[j],沒有意義,會報錯,
- 二維陣列初始化的時候列數可以省略,行數可以由編譯器來數,例如:inta[][5] = {{0,1,2,3,4},{2,3,4,5,6}};
- 初始化二維陣列的兩種方法:部分初始化則將剩下的那部分賦值為0
- int a[2][3] = {{5, 6},{7, 8}}; 則a[0][0]=5, a[0][1]=6, a[0][2]=0, a[1][0]=7, a[1][1]=8, a[1][2]=0;
- int a[2][3] = {5, 6, 7, 8}; 則a[0][0]=5, a[0][1]=6, a[0][2]=7, a[1][0]=8, a[1][1]=0, a[1][2]=0;
- 三位陣列理解方法:比如int box[10][20][30]; 則可以理解成由10個二維陣列(每個是20行30列)堆疊起來,這20個陣列元素中的每個元素是內含30個元素的陣列,
通程序式加深理解一些概念
1. 陣列的名字就相當于這個陣列第一個元素的記憶體地址:
#include <stdio.h>
int main(){
int a[10]={1,2,3,4,5,6,7,8,9,10}; //定義一個整型陣列,這里a實質上是一個指向陣列中第一個資料a[0]的指標
int *p=a;
printf("%d\n",*p);
printf("%d",*(p+1));
return 0;
}
回傳結果為:
1
2
2. 利用指標對陣列進行初始化
#include <stdio.h>
int main(){
int d[10];
int *e;
e=&d[0]; //e保存了陣列d的第一個資料的地址
for (int i=0; i<10; i++){
*e = i; //把該地址中的資料依次賦值0,1,2,3,4,5,6,7,8,9
e++; //地址累加一次,也就是陣列中下一個資料的地址
}
for (int i=0; i<10; i++){
printf("%d\n", d[i]); //列印陣列d中的所有元素
}
return 0;
}
3. 陣列作為函式引數時,往往必須再用另一引數來傳入陣列的大小,
- 不能在[]中給出陣列的大小
- 不能在函式中再利用sizeof計算陣列的元素的個數
- 宣告陣列形參時,下列方法等價:(函式原型可以省略引數名)切記:此為函式宣告時用法,不可直接參考于函式定義
- int sum(int *ar, int len);
- int sum(int *, int);
- int sum(int ar[], int n);
- int sum(int [], int);
- 函式定義中不能省略引數名,以下兩種方法可行且等價:
- int sum(int *ar, int len)
{
//省略其他代碼
} - int sum(int ar[], int len)
{
//省略其他代碼
}
- int sum(int *ar, int len)
#include <stdio.h>
//此方法為最簡單,最基礎的陣列遍歷
int search(int key, int a[], int len)
int main()
{
int a[]= {1,3,5,2,9,4,12,23,15,32};
int r = search (12, a, sizeof(a)/sizeof(a[0])); //傳入引數的時候在main函式中計算好函式的個數傳入到search函式中;另外,此處a傳入的時a[0]元素的地址,
printf("%d\n", r);
return 0;
}
int search(int key, int a[], int len) //len變數必須要加,因為在search函式中無法用sizeof函式計算陣列的大小
{
int ret = -1;
int i;
for (i=0; i<len; i++){
if (key == a[i]){
ret = i;
break;
}
}
return ret;
}
4. 二維陣列中陣列名的含義
#include<stdio.h>
int main(){
int a[2][3]={{1,2,3},{4,5,6}};
printf("%p\n",a); //輸出指標a資料,也就是指標a[0]的地址
printf("%p\n",a+1); //輸出a+1的資料 ,也就是a[1]的地址
printf("%p\n",&a[0]);
printf("%p\n",&a[1]); //驗證上述
printf("%p\n",(*a)+1); //輸出的是a[0][1]的地址
printf("%p\n",&a[0][1]); //驗證
printf("%d\n",*(a[0])); //輸出的是a[0]a[0]的值
printf("%d\n",*(*(a+1)+1)); //輸出的是a[1][1]的值
}
注意:a是一個2行3列的數值,a+1表示的a[1]值所在的地址,a[1]的值又代表a[1][0]的值所在的地址
5. int與char指標型別的區別
int i=2; int *a=&i 和 char j='m'; char *b=&j 區別在于:int占據四個位元組,a中雖然記載的i的第一個位元組的地址,但是由于a是int型別的指標,*a讀取的時候自動再往后讀3個位元組;而b是char型別的指標,則只讀取當前記錄的這一個位元組,自然不能用指標b來保存int i的值,
#include <stdio.h>
int main(){
int i = 2;
int j = 's';
int *a = &i;
char *b = &i;
int *m = &j;
char *n = &j;
printf("%d\n", *a);
printf("%d\n", *b); //會產生warning
/* 解釋為什么前兩行輸出為什么一樣:
* 在存盤中,2作為int存盤為 00000010 00000000 00000000 00000000 四個位元組,用此種表示方法是因為我的電腦是個小端電腦(Little-endian),詳述見下條,
* a 和 b 所記錄的都是四個位元組中第一個位元組的地址,*a讀取到的是4個完整的位元組,而*b讀取到的是第一個位元組 00000010,由于巧合,二者所代表的都是數字1,
*/
printf("%c\n", *m); //會產生warning
printf("%c\n", *n);
return 0;
}
6. 指標記憶體位置理解深入剖析(一定在自己的電腦上運行試下)
#include <stdio.h>
int main()
{
int a = 1, b = 2;
char c = 'c', d = 'd';
int *m, *n;
char *j, *k;
m = &a;
n = &b;
j = &c;
k = &d;
printf("int變數在記憶體中的存盤情況");
printf("a %p\n", m);
printf("b %p\n", n);
//由于堆疊自頂向下的存盤方法,記憶體位置上a與b兩個元素是緊鄰著的,a位置高,b低,相差四個位元組,
printf("\n");
printf("對int指標變數+1會得到什么結果,實際改變幾個位元組?\n");
printf("&b+1 %p\n", n+1);
printf("&a-&b %d\n", m-n);
//上兩個陳述句測驗得到結果,a與b的地址m,n相差并不是4而是1,因為相差的是存盤單元數而不是位元組數
printf("\n");
printf("char指標變數什么情況,本來就相差1個位元組?\n");
printf("c %p\n", j);
printf("d %p\n", k);
//由于char變數只占1個位元組,所以這兩個變數位置地址相差為1
printf("\n");
printf("\n");
printf("int型指標變數占據幾個位元組?\n");
printf("&m %p\n", &m);
printf("&n %p\n", &n);
printf("char型指標變數占據幾個位元組?\n");
printf("&j %p\n", &j);
printf("&k %p\n", &k);
//可以得到,在64位系統上,像m,n這種指標本身的存盤都是占據8個位元組,不管是char型別還是int型別,
return 0;
}
一句話概括指標的加減:指標加1,指標的值遞增它所指向型別的大小(以位元組位單位),或者說增加一個存盤單元,
short dates; // dates的型別占2個位元組
dates + 2 == &dates[2] //相同的地址
*(dates + 2) == dates[2] //相同的值
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/52984.html
標籤:C