Java面試題系列:將面試題中比較經典和核心的內容寫成系列文章持續在公眾號更新,可鞏固基礎知識,可梳理底層原理,歡迎大家持續關注【程式新視界】,本篇為面試題系列第2篇,
常見面試問題
下面代碼中創建了幾個物件?
new String("abc");
答案眾說紛紜,有說創建了1個物件,也有說創建了2個物件,答案對,也不對,關鍵是要學到問題底層的原理,
底層原理分析
在上篇文章《面試題系列第1篇:說說==和equals的區別?你的回答可能是錯誤的》中我們已經提到,String的兩種初始化形式是有本質區別的,
String str1 = "abc"; // 在常量池中
String str2 = new String("abc"); // 在堆上
當直接賦值時,字串“abc”會被存盤在常量池中,只有1份,此時的賦值操作等于是創建0個或1個物件,如果常量池中已經存在了“abc”,那么不會再創建物件,直接將參考賦值給str1;如果常量池中沒有“abc”,那么創建一個物件,并將參考賦值給str1,
那么,通過new String("abc");的形式又是如何呢?答案是1個或2個,
當JVM遇到上述代碼時,會先檢索常量池中是否存在“abc”,如果不存在“abc”這個字串,則會先在常量池中創建這個一個字串,然后再執行new操作,會在堆記憶體中創建一個存盤“abc”的String物件,物件的參考賦值給str2,此程序創建了2個物件,
當然,如果檢索常量池時發現已經存在了對應的字串,那么只會在堆內創建一個新的String物件,此程序只創建了1個物件,
在上述程序中檢查常量池是否有相同Unicode的字串常量時,使用的方法便是String中的intern()方法,
public native String intern();
下面通過一個簡單的示意圖看一下String在記憶體中的兩種存盤模式,
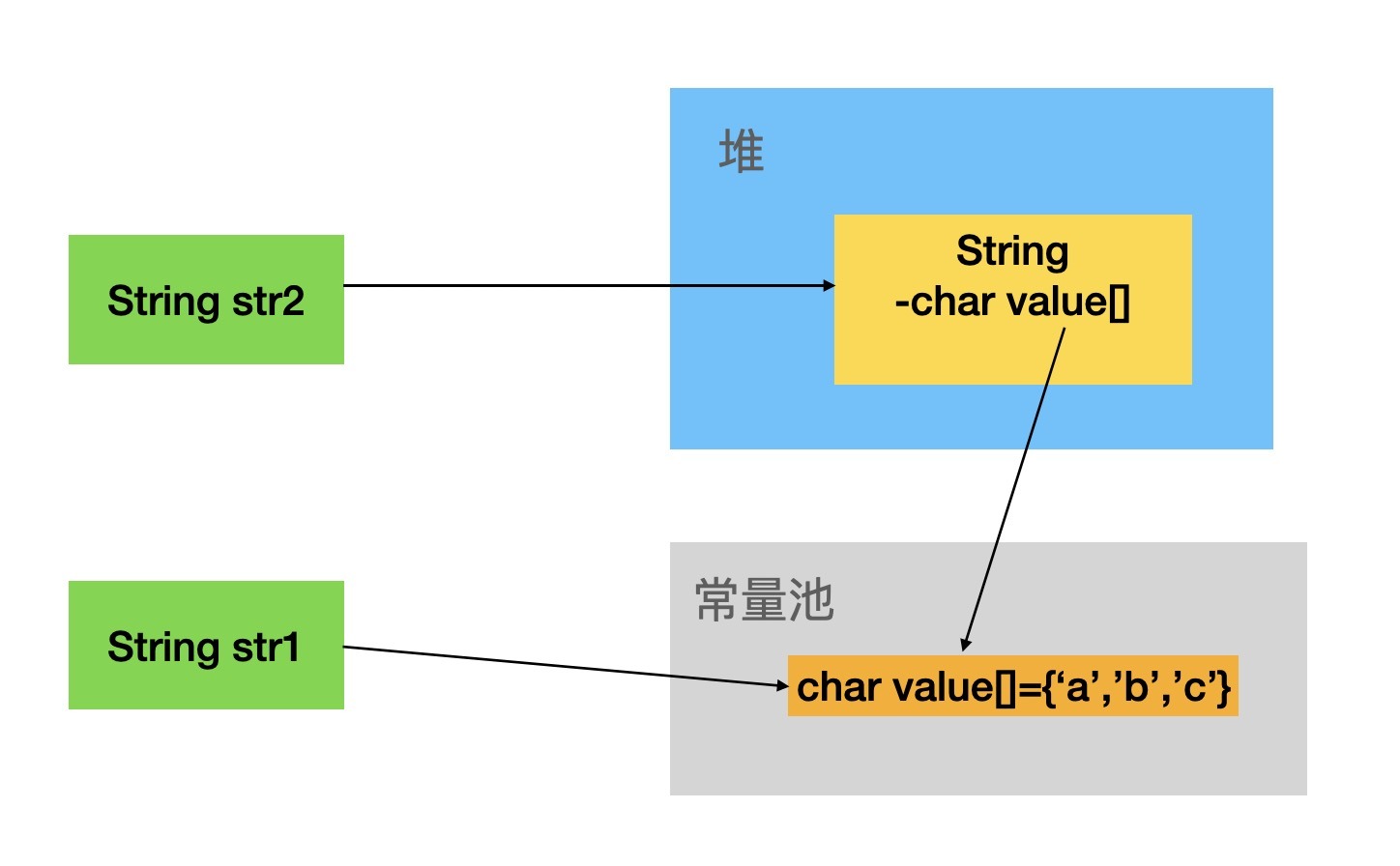
上面的示意圖我們可以看到在堆內創建的String物件的char value[]屬性指向了常量池中的char value[],
還是上面的示例,如果我們通過debug模式也能夠看到String的char value[]的參考地址,
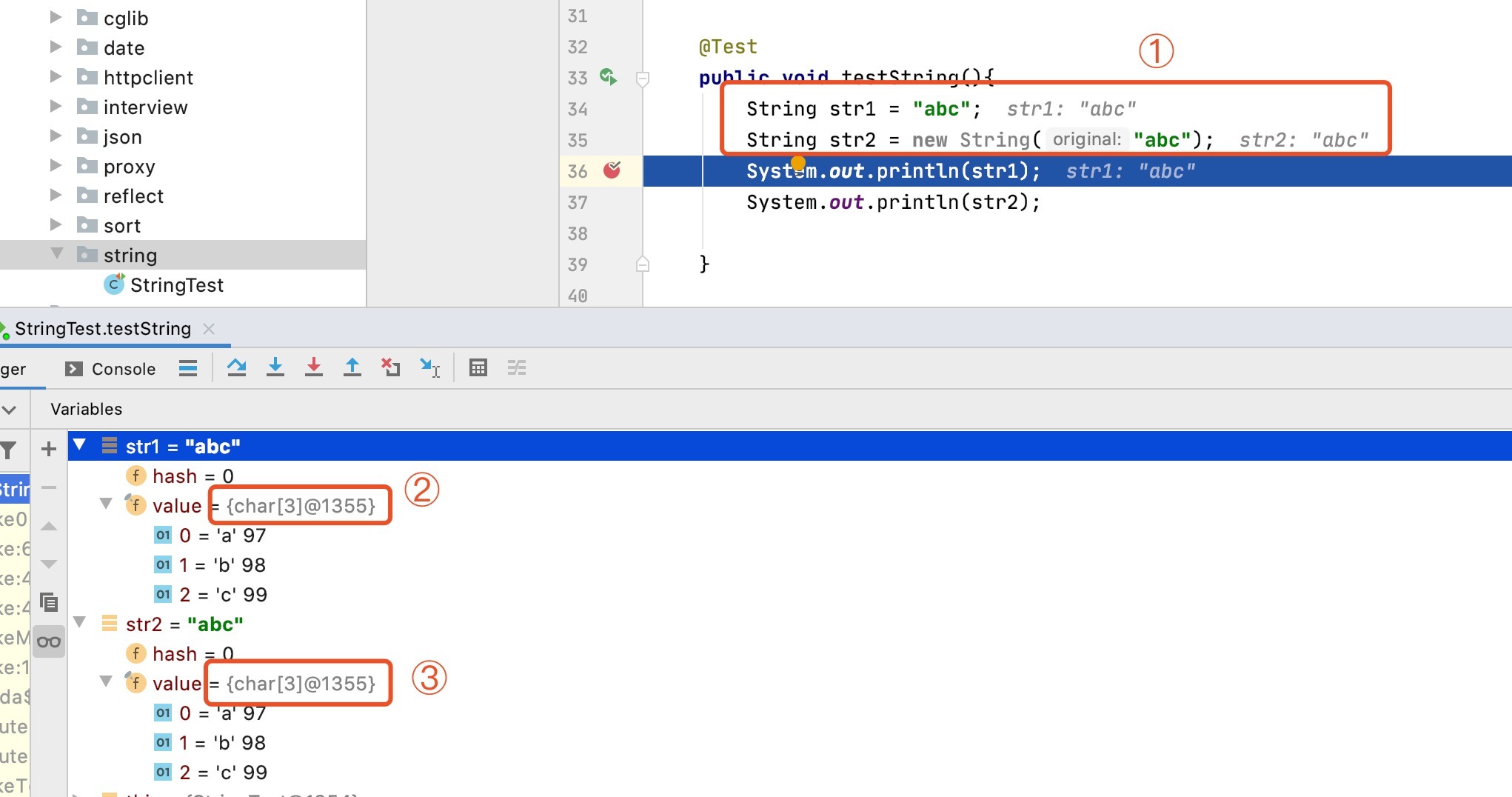
圖中兩個String物件的value值的參考均為{char[3]@1355},也就是說,雖然是兩個物件,但它們的value值均指向常量池中的同一個地址,當然,大家還可以拿一個復雜物件(Person)的字串屬性(name)相同時的debug結果進行比對,結果是一樣的,
深入問法
如果面試官說程式的代碼只有下面一行,那么會創建幾個物件?
new String("abc");
答案是2個?
還真不一定,之所以單獨列出這個問題是想提醒大家一點:沒有直接的賦值操作(str="abc"),并不代表常量池中沒有“abc”這個字串,也就是說衡量創建幾個物件、常量池中是否有對應的字串,不僅僅由你是否創建決定,還要看程式啟動時其他類中是否包含該字串,
升級加碼
以下實體我們暫且不考慮常量池中是否已經存在對應字串的問題,假設都不存在對應的字串,
以下代碼會創建幾個物件:
String str = "abc" + "def";
上面的問題涉及到字串常量多載“+”的問題,當一個字串由多個字串常量拼接成一個字串時,它自己也肯定是字串常量,字串常量的“+”號連接Java虛擬機會在程式編譯期將其優化為連接后的值,
就上面的示例而言,在編譯時已經被合并成“abcdef”字串,因此,只會創建1個物件,并沒有創建臨時字串物件abc和def,這樣減輕了垃圾收集器的壓力,
我們通過javap查看class檔案可以看到如下內容,
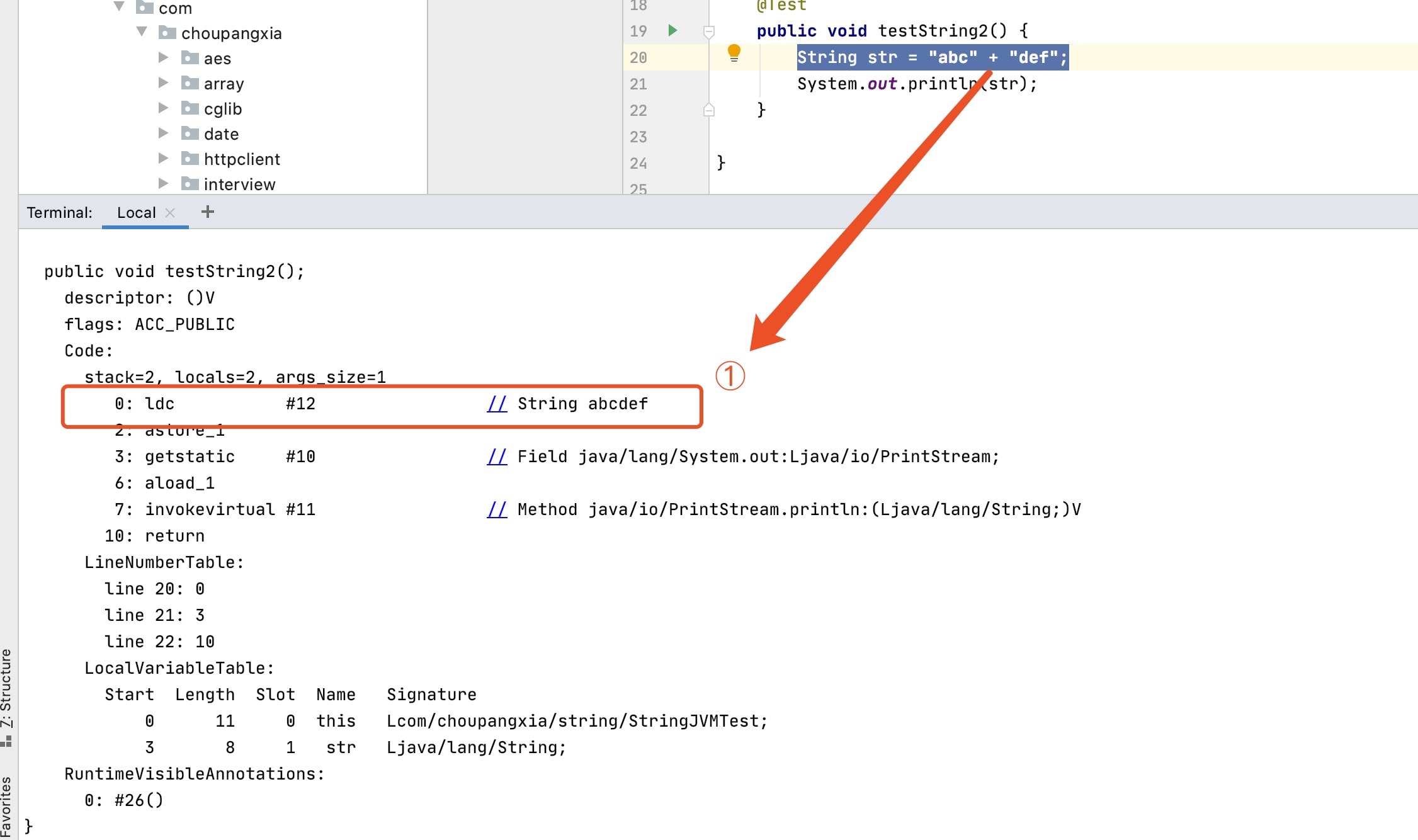
很明顯,位元組碼中只有拼接好的abcdef,
針對上面的問題,我們再次升級一下,下面的代碼會創建幾個物件?
String str = "abc" + new String("def");
創建了4個,5個,還是6個物件?
4個物件的說法:常量池中分別有“abc”和“def”,堆中物件new String("def")和“abcdef”,
這種說法對嗎?不完全對,如果說上述代碼創建了幾個字串物件,那么可以說是正確的,但上述的代碼Java虛擬機在編譯的時候同樣會優化,會創建一個StringBuilder來進行字串的拼接,實際效果類似:
String s = new String("def");
new StringBuilder().append("abc").append(s).toString();
很顯然,多出了一個StringBuilder物件,那就應該是5個物件,
那么創建6個物件是怎么回事呢?有同學可能會想了,StringBuilder最后toString()之后的“abcdef”難道不在常量池存一份嗎?
這個還真沒有存,我們來看一下這段代碼:
@Test
public void testString3() {
String s1 = "abc";
String s2 = new String("def");
String s3 = s1 + s2;
String s4 = "abcdef";
System.out.println(s3==s4); // false
}
按照上面的分析,如果s1+s2的結果在常量池中存了一份,那么s3中的value參考應該和s4中value的參考是一樣的才對,下面我們看一下debug的效果,
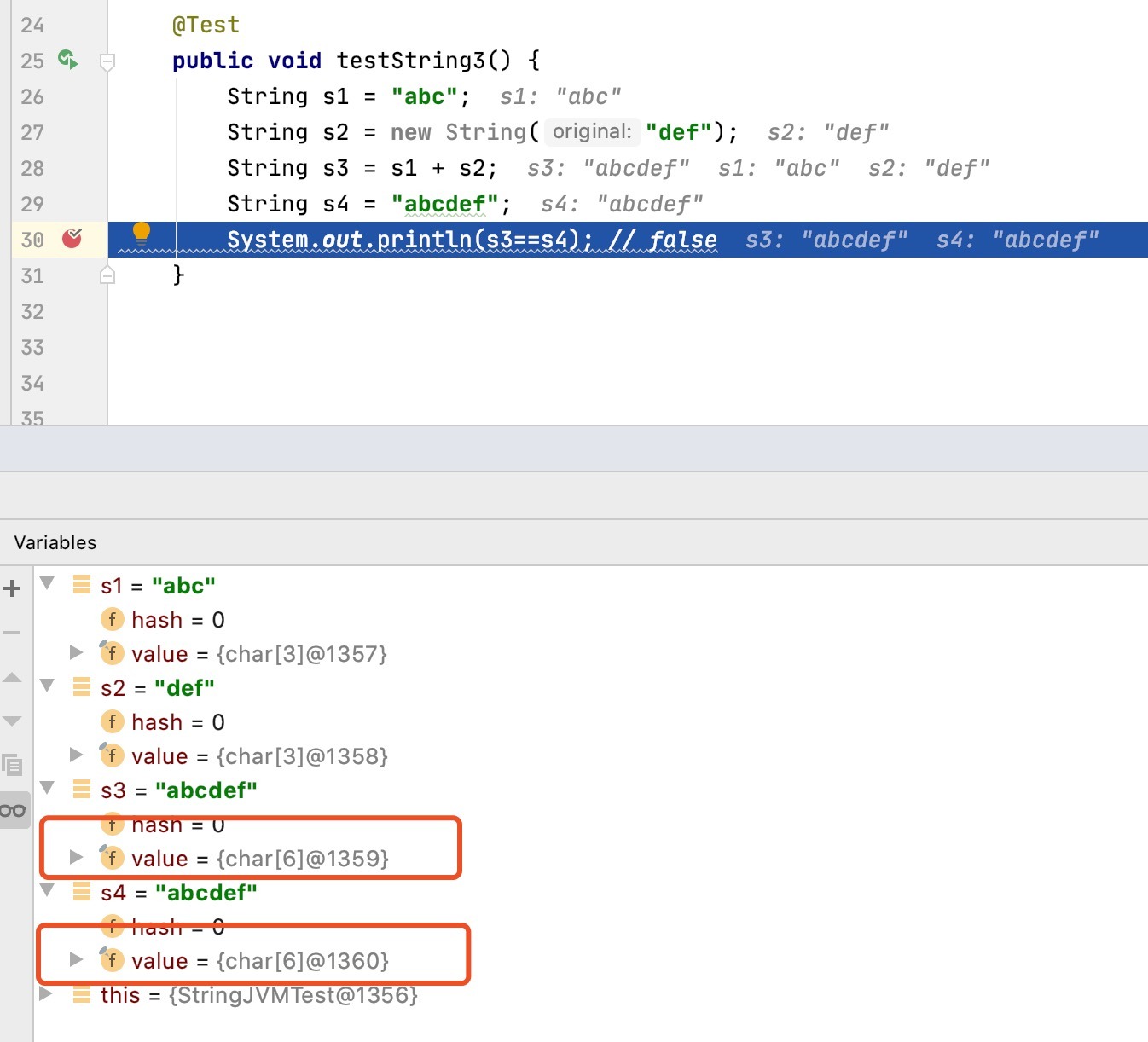
很明顯,s3和s4的值相同,但value值的地址并不相同,即便是將s3和s4的位置調整一下,效果也一樣,s4很明確是存在于常量池中,那么s3對應的值存盤在哪里呢?很顯然是在堆物件中,
我們來看一下StringBuilder的toString()方法是如何將拼接的結果轉化為字串的:
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
很顯然,在toString方法中又新創建了一個String物件,而該String物件傳遞陣列的構造方法來創建的:
public String(char value[], int offset, int count)
也就是說,String物件的value值直接指向了一個已經存在的陣列,而并沒有指向常量池中的字串,
因此,上面的準確回答應該是創建了4個字串物件和1個StringBuilder物件,
小結
我們通過一行創建字串的代碼逐步分析String物件的整個構建及拼接程序,了解了底層實作原理,是不是很有意思?當你掌握了這些底層基本知識,即便面試題的形式如何變化,你必定能一眼識破真相,
下篇文章,(讀者提議)我們來講講Integer的比較的底層邏輯,歡迎持續關注,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/53102.html
標籤:Java
下一篇:PHP 的擴展型別及安裝方式