您好,我是湘王,這是我的博客園,歡迎您來,歡迎您再來~
多數碼農在開發的時候,要么處理同步應用,要么處理異步,但是如果能學會使用CompletableFuture,就會具備一種神奇的能力:將同步變為異步(有點像用了月光寶盒后同時穿梭在好幾個時空的感覺),怎么做呢?來看看代碼,
新增一個商店類Shop:
/**
* 商店類
*
* @author 湘王
*/
public class Shop {
private String name = "";
public Shop(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
private double calculatePrice(String product) {
delay();
return 10 * product.charAt(0);
}
private void delay() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 同步得到價格
public double getPrice(String word) {
return calculatePrice(word);
}
// 增加異步查詢:將同步方法轉化為異步方法
public Future<Double> getPriceAsync(String product) {
CompletableFuture<Double> future = new CompletableFuture<>();
new Thread(() -> {
double price = calculatePrice(product);
// 需要長時間計算的任務結束并回傳結果時,設定Future回傳值
future.complete(price);
}).start();
// 無需等待還沒結束的計算,直接回傳future物件
return future;
}
}
然后再增加兩個測驗方法,一個同步,一個異步,分別對應商店類中的同步和異步方法:
// 測驗同步方法
public static void testGetPrice() {
Shop friend = new Shop("某寶");
long start = System.nanoTime();
double price = friend.getPrice("MacBook pro");
System.out.printf(friend.getName() + " price is: %.2f%n", price);
long invocationTime = (System.nanoTime() - start) / 1_000_000;
System.out.println("同步呼叫花費時間:" + invocationTime + " msecs");
// 其他耗時操作(休眠)
doSomethingElse();
long retrievalTime = (System.nanoTime() - start) / 1_000_000;
System.out.println("同步方法回傳所需時間:" + retrievalTime + " msecs");
}
// 測驗異步方法
public static void testGetPriceAsync() throws InterruptedException, ExecutionException {
Shop friend = new Shop("某東");
long start = System.nanoTime();
Future<Double> futurePrice = friend.getPriceAsync("MacBook pro");
long invocationTime = (System.nanoTime() - start) / 1_000_000;
System.out.println("異步方法花費時間:" + invocationTime + " msecs");
// 其他耗時操作(休眠)
doSomethingElse();
// 從future物件中讀取價格,如果價格未知,則發生阻塞
double price = futurePrice.get();
System.out.printf(friend.getName() + " price is: %.2f%n", price);
long retrievalTime = (System.nanoTime() - start) / 1_000_000;
System.out.println("異步方法回傳所需時間:" + retrievalTime + " msecs");
}
這里之所以采用微秒,是因為代碼量太少的緣故,如果用毫秒根本看不出來差別,運行之后會發現異步的時間大大縮短,
假設現在咱們做了一個網站,需要針對同一個商品查詢它在不同電商平臺的價格(假設已經實作了這樣的介面),那么顯然,如果想查出所有平臺的價格,需要一個個地呼叫,就像這樣(為了效果更逼真一些,將回傳的價格做了一些調整):
private double calculatePrice(String product) {
delay();
return new Random().nextDouble() * product.charAt(0) * product.charAt(1);
}
/**
* 測驗客戶端
*
*/
public class ClientTest {
private List<Shop> shops = Arrays.asList(
new Shop("taobao.com"),
new Shop("tmall.com"),
new Shop("jd.com"),
new Shop("amazon.com")
);
// 根據名字回傳每個商店的商品價格
public List<String> findPrice(String product) {
List<String> list = shops.stream()
.map(shop ->
String.format("%s price is %.2f RMB",
shop.getName(), shop.getPrice(product)))
.collect(Collectors.toList());
return list;
}
// 同步方式實作findPrices方法,查詢每個商店
public void test() {
long start = System.nanoTime();
List<String> list = findPrice("IphoneX");
System.out.println(list);
System.out.println("Done in " + (System.nanoTime() - start) / 1_000_000 + " ms");
}
public static void main(String[] args) {
ClientTest client = new ClientTest();
client.test();
}
}
由于呼叫的是同步方法,因此結果查詢較慢——叔可忍嬸不能忍!
如果可以同時查詢所有的電商平臺是不是會快一些呢?可以試試,使用流式計算中的并行流:
// 根據名字回傳每個商店的商品價格
public List<String> findPrice(String product) {
List<String> list = shops.parallelStream()// 使用并行流
.map(shop ->
String.format("%s price is %.2f RMB",
shop.getName(), shop.getPrice(product)))
.collect(Collectors.toList());
return list;
}
改好之后再試一下,果然快多了!
可以用咱們學過的CompletableFuture再來把它改造一下:
// 使用CompletableFuture發起異步請求
// 這里使用了兩個不同的Stream流水線,而不是在同一個處理流的流水線上一個接一個地放置兩個map操作
// 這其實是有原因的:考慮流操作之間的延遲特性,如果在單一流水線中處理流,發向不同商家的請求只能以同步、順序執行的方式才會成功
// 因此,每個創建CompletableFuture物件只能在前一個操作結束之后執行查詢指定商家的動作、通知join()方法回傳計算結果
public List<String> findPrice(String product) {
List<CompletableFuture<String>> futures =
shops.parallelStream()
.map(shop -> CompletableFuture.supplyAsync(
() -> String.format("%s price is %.2f RMB",
shop.getName(), shop.getPrice(product))))
.collect(Collectors.toList());
return futures.stream()
// 等待所有異步操作結束(join和Future介面中的get有相同的含義)
.map(CompletableFuture::join)
.collect(Collectors.toList());
}
這樣一來,新的CompletableFuture物件只有在前一個操作完全結束之后,才能創建,而且使用兩個不同的Stream流水線,也可以讓前一個CompletableFuture在還未執行完成時,就創建新的CompletableFuture物件,它的執行程序就像下面這樣:
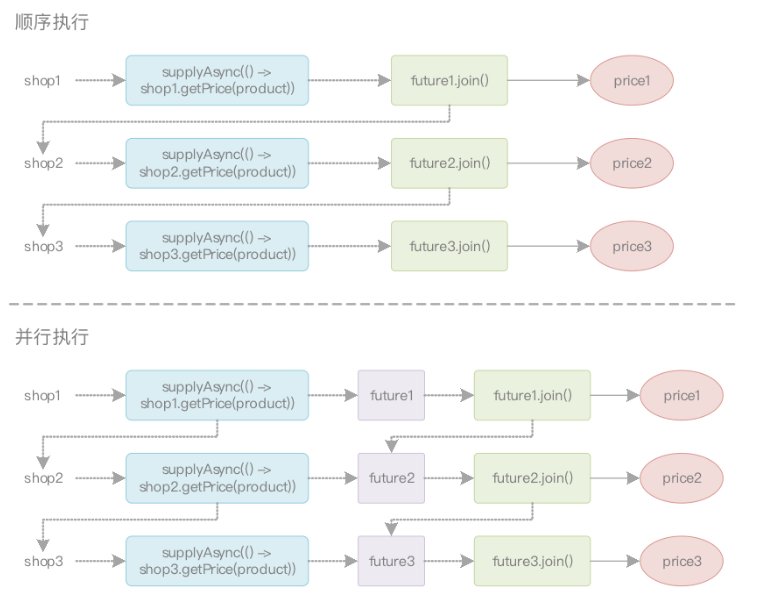
還有沒有改進空間呢?當然是有的!但是代碼過于復雜,而且在多數情況下,上面列舉出的所有代碼已經足夠解決實際作業中90%的問題了,不過還是把CompletableFuture結合定制Executor的代碼貼出來,這樣也有個大致的概念(不鼓勵鉆牛角尖),
// 使用定制的Executor配置CompletableFuture
public List<String> findPrice(String product) {
// 為“最優價格查詢器”應用定制的執行器Execotor
Executor executor = Executors.newFixedThreadPool(Math.min(shops.size(), 100),
(Runnable r) -> {
Thread thread = new Thread(r);
// 使用守護執行緒,這種方式不會阻止程式的關停
thread.setDaemon(true);
return thread;
}
);
// 將執行器Execotor作為第二個引數傳遞給supplyAsync工廠方法
List<CompletableFuture<String>> futures = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(
() -> String.format("%s price is %.2f RMB",
shop.getName(), shop.getPrice(product)), executor))
.collect(Collectors.toList());
return futures.stream()
// 等待所有異步操作結束(join和Future介面中的get有相同的含義)
.map(CompletableFuture::join)
.collect(Collectors.toList());
}
這基本上就是CompletableFuture全部的內容了,可以總結一下,對于集合進行并行計算有兩種方法:
1、要么將其轉化為并行流,再利用map這樣的操作開展作業
2、要么列舉出集合中的每一個元素,創建新的執行緒,在CompletableFuture內操作
CompletableFuture提供了更多的靈活性,它可以調整執行緒池的大小,確保整體的計算不會因為執行緒因為I/O而發生阻塞,因此使用建議是:
1、如果進行的是計算密集型操作,且無I/O操作,那么推薦使用并行parallelStream()
2、如果并行的計算單元還涉及等待I/O的操作(包括網路連接等待),那么使用CompletableFuture靈活性更好,
感謝您的大駕光臨!咨詢技術、產品、運營和管理相關問題,請關注后留言,歡迎騷擾,不勝榮幸~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/531544.html
標籤:Java
下一篇:K-最近鄰-有多少參考點/特征?