小資料池和深淺拷貝
一、深淺拷貝
1.賦值
賦值就是一個容器有多個標簽
lst = [1,2,3,[6,7,8]]
執行以上程式,內容空間發生的變化就是下圖:
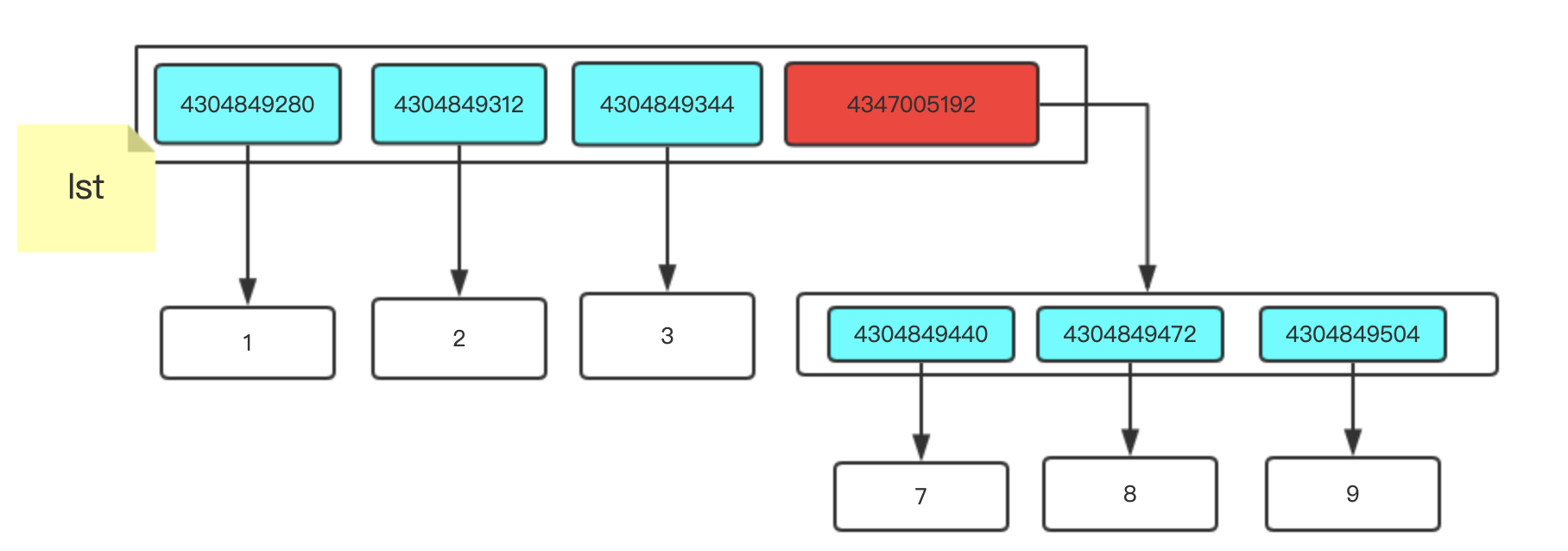
一個串列用兩個標簽,通過標簽lst 找到的和標簽lst1找到的是同一個,圖中的那些一長串數字就是記憶體地址,Python中是通過記憶體地址來查看值
lst1 = lst #賦值
lst[-1].append(9) #-1索引處追加元素 值為9
我們通過lst這個標簽找到這個串列然后添加一個9,再通過lst1找到這個串列也就多了一個9 因為lst和lst1都是貼在一個地方
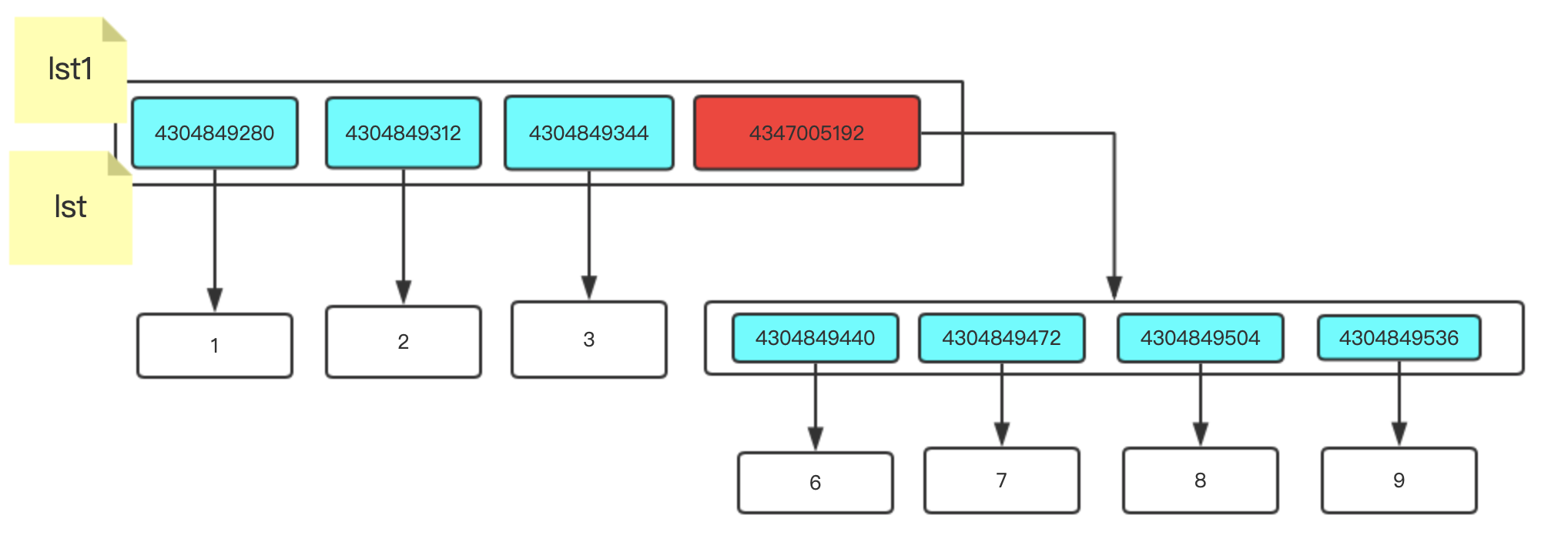
2.淺拷貝
淺拷貝就是只拷貝第一層的元素
lst = [1,2,3,[6,7,8]]
# lst2 = lst[:] # 淺拷貝
lst2 = lst.copy()
圖中橙色的是新開辟的空間,淺藍色的是數字型別,紅色的串列型別
這樣就是淺拷貝,淺拷貝只把原串列中記錄的記憶體地址拿到一個新開辟的串列中
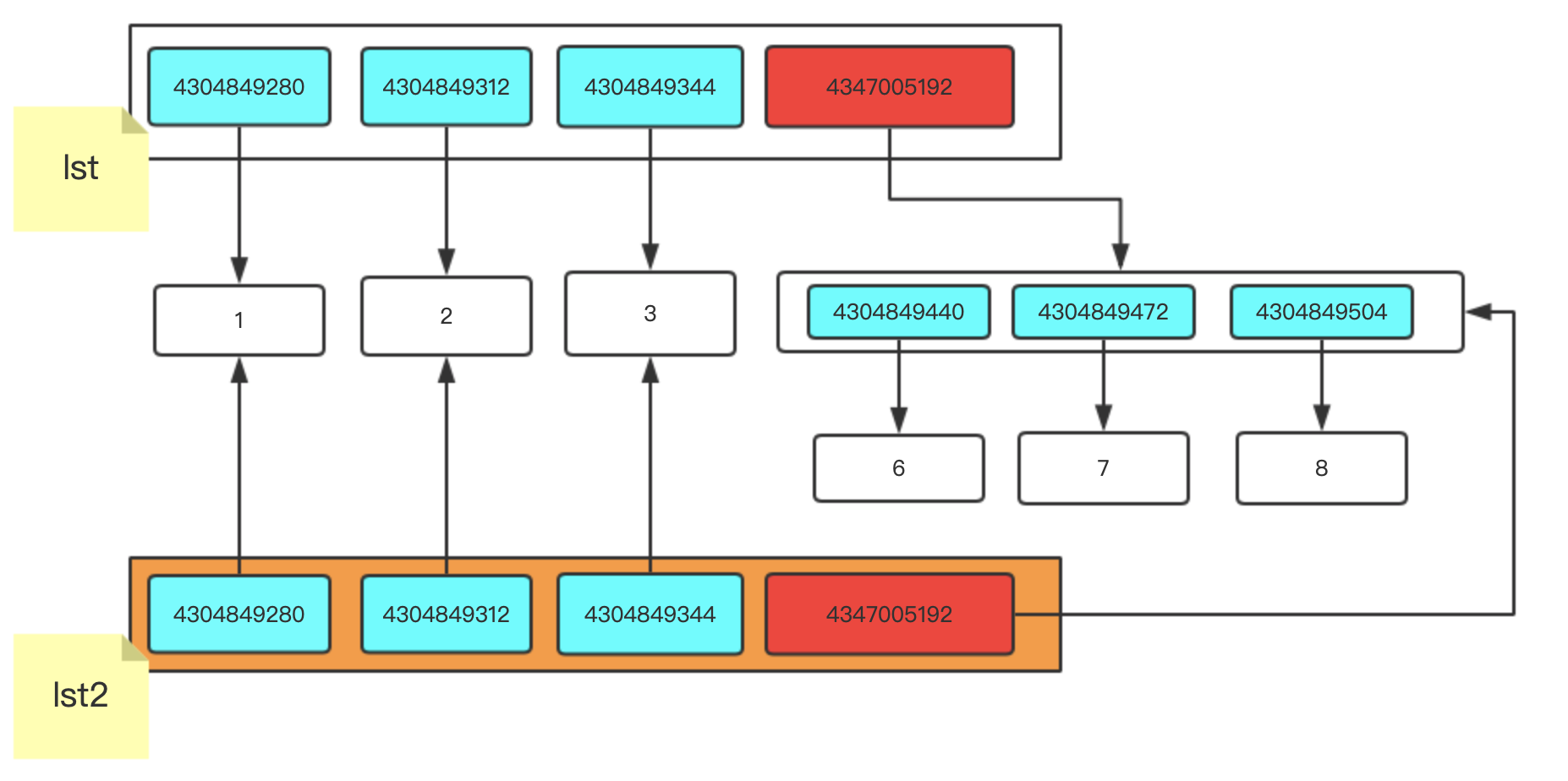
lst = [1,2,3,[6,7,8]]
lst2 = lst[:]
lst.append(9)
為什么lst2中沒有添加,是因為咱們先進行的淺拷貝,淺拷貝把原串列中有的記憶體地址復制了一份放到新開辟的空間中,后期對原串列添加的內容新串列里是不會有的,再看看下邊的例子
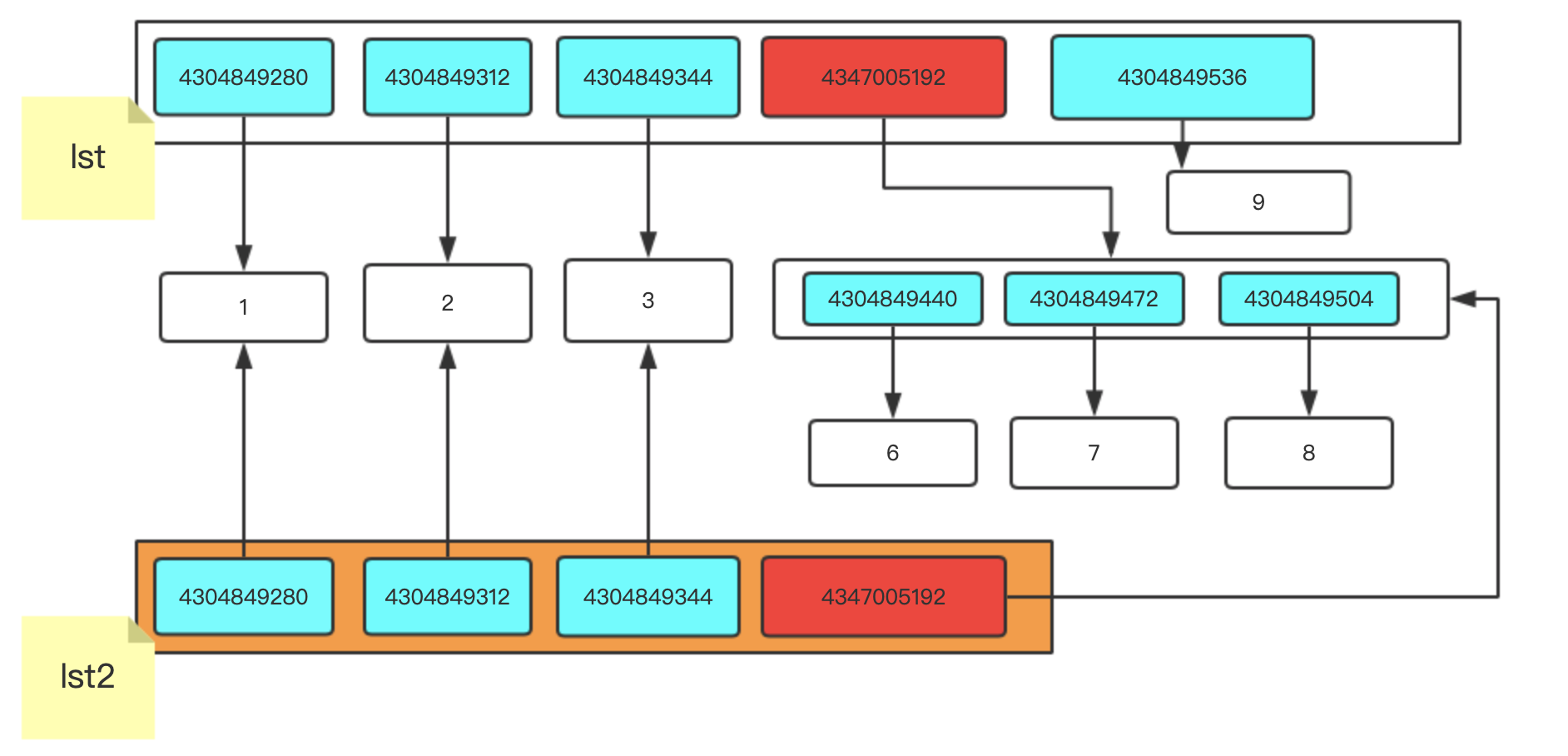
lst = [1,2,3,[6,7,8]]
lst2 = lst.copy()
lst[1] = "22"
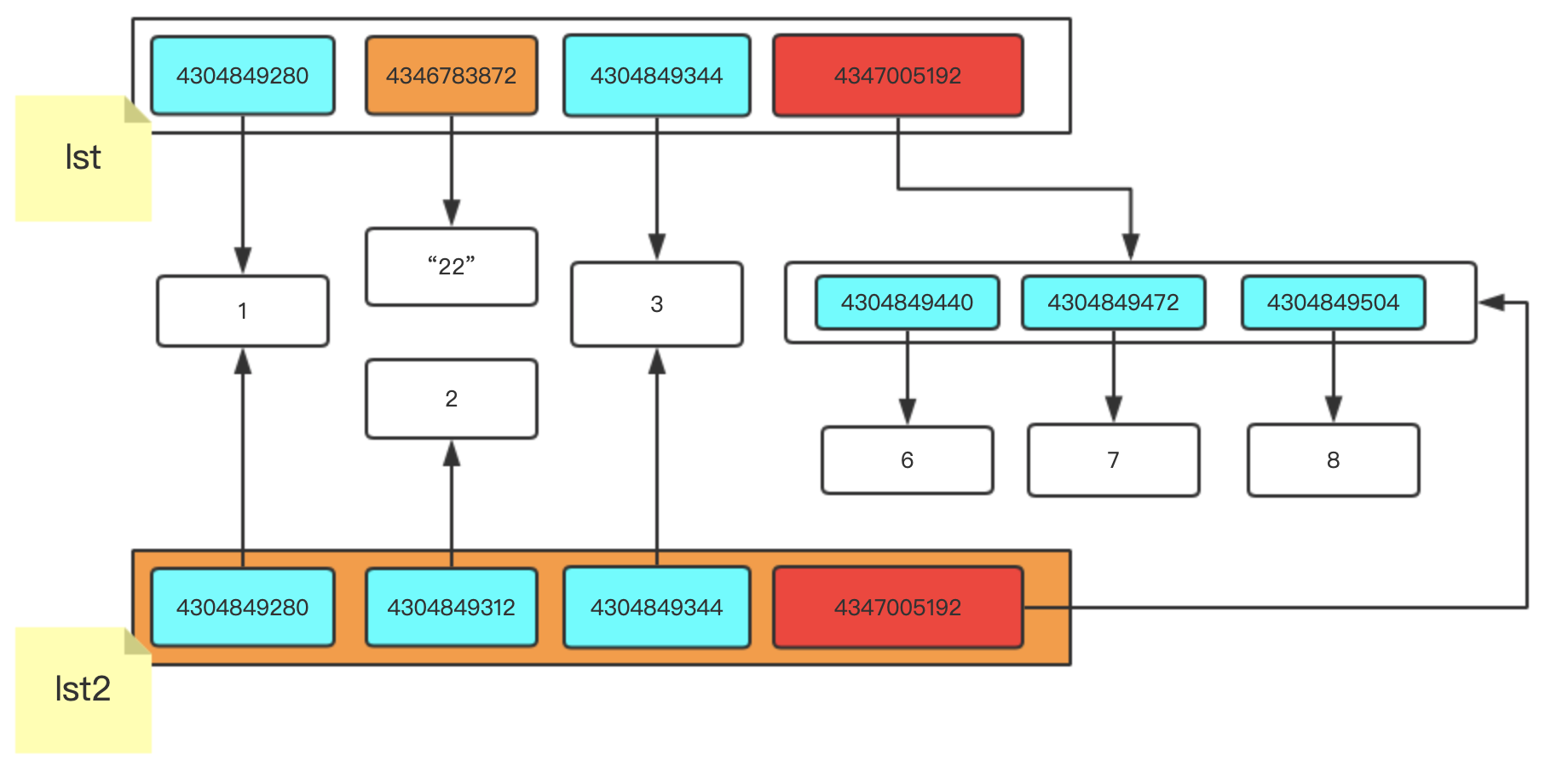
我們修改成字串"22" 就是在串列中將以前的記憶體地址更換成新開辟的空間地址
lst = [1,2,3,[6,7,8]]
lst2 = lst.copy()
lst[-1].append(9)
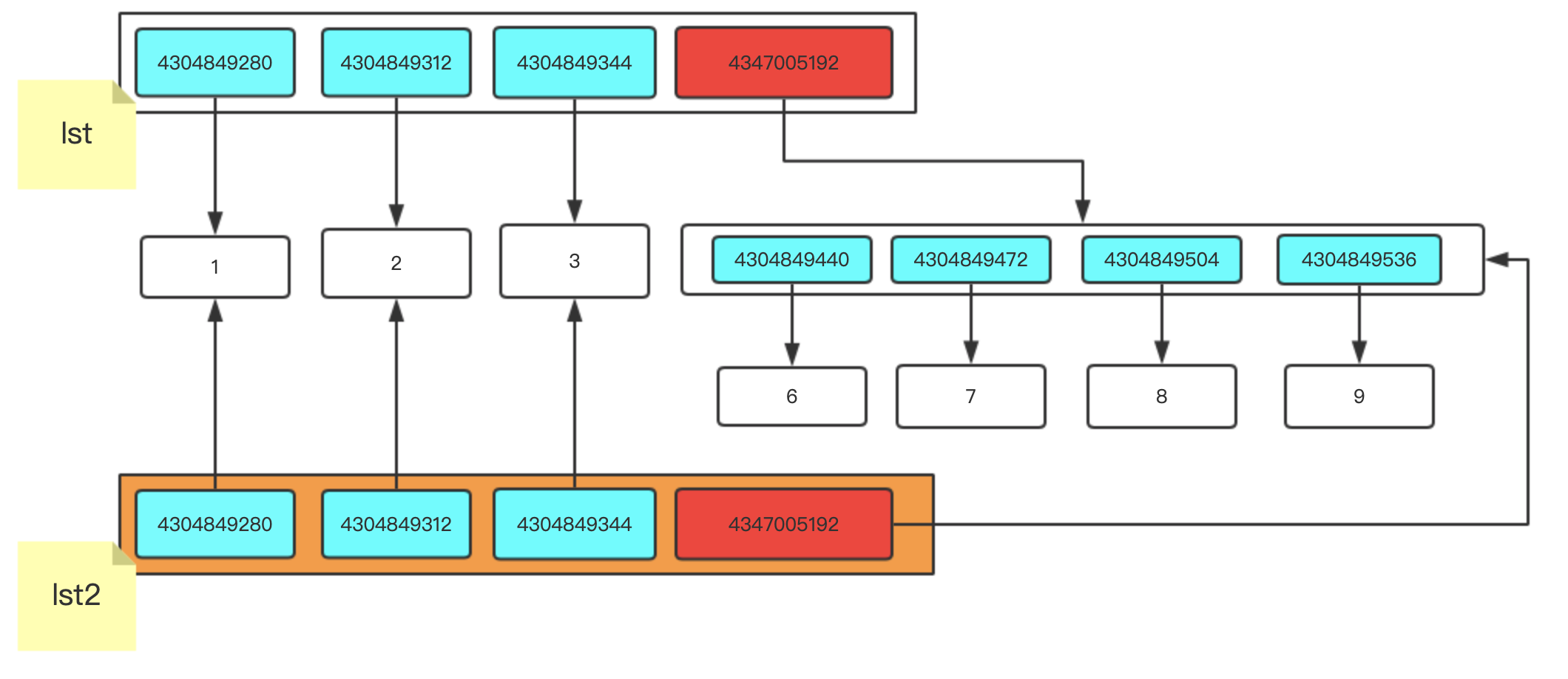
因為我們對里邊的串列進行修改,串列本身就是可變的資料型別,我們通過原串列修改最里層的小串列,小串列進行變化,新開辟的串列里存放就是小串列中的記憶體地址.在去查看的時候就有變動
3.深拷貝
深拷貝是自己單獨開辟了一個新的空間,我們現在修改原串列對新開辟的串列沒有任何影響.
來看看深拷貝是怎樣的操作
import copy
lst = [1,2,3,[6,7,8,9]]
lst2 = copy.deepcopy(lst)
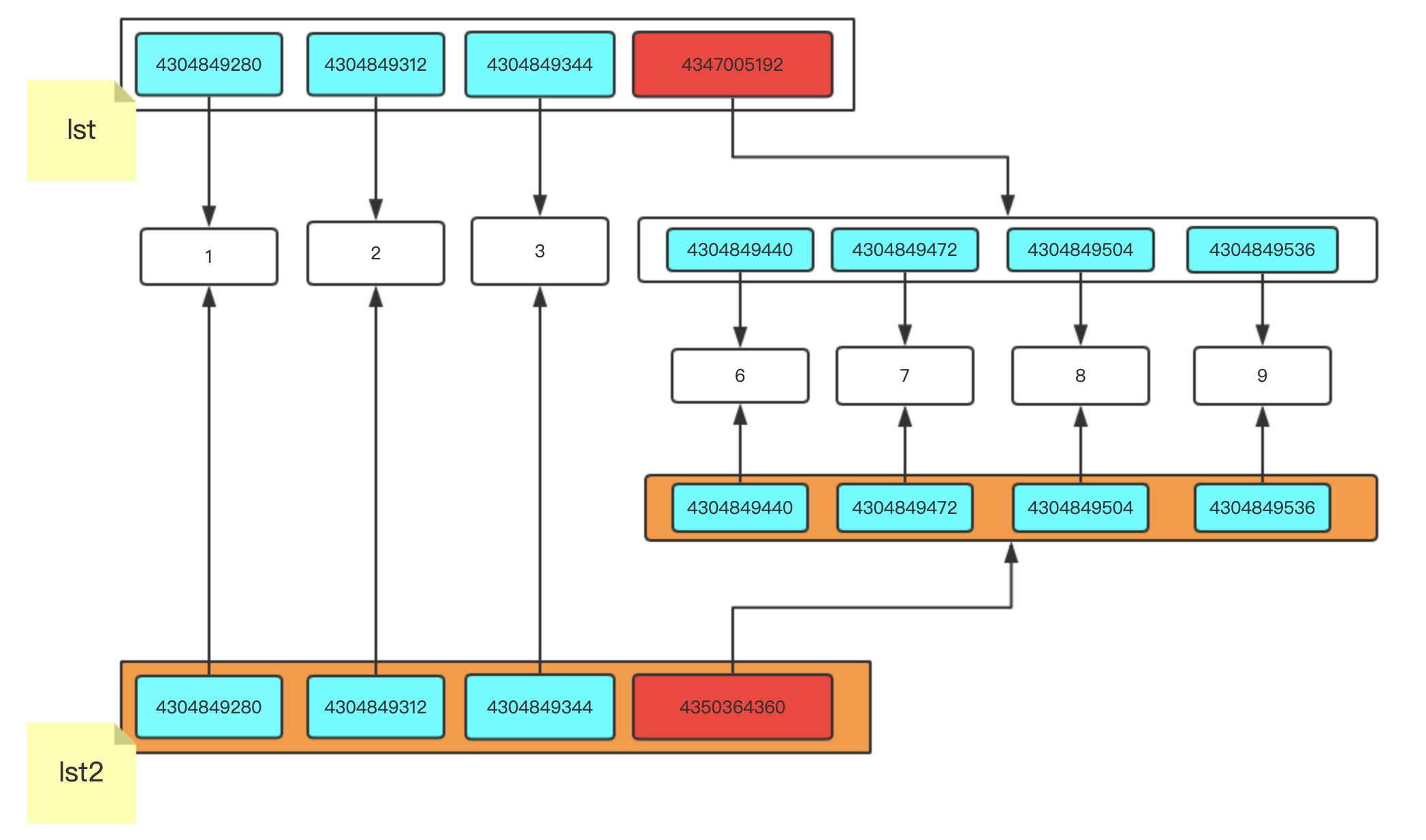
通過上面的各種測驗,總結以下規律:
- 賦值:
- 兩個或多個變數名指向同一個記憶體地址,有一個操作記憶體地址的值進行改變,其余的變數名在查看的時候都進行更改(換個變數名,但記憶體地址不變)
- 淺拷貝:
- 只拷貝串列中第一層的記憶體地址,原串列修改了不可變資料型別,新開辟的串列不進行變動,因為只是在原串列中將記憶體地址進行修改了,新開辟的串列中的記憶體地址還是用的之前的記憶體地址(只復制第一層,小串列的記憶體地址還是一致的,舊的改 新的跟著改,但第一層的內容舊的改新的不變)
- 原串列對可變資料型別進行了添加,新開辟的串列中存放就是可變資料型別的地址,在去查看的時候就發現進行更改了
- 深拷貝:
- 不管你修改原資料的不可變型別還是可變型別,新開辟的空間中都不會進行改變,因為可變資料型別新開辟了一個空間(完全復制!記憶體地址全部另辟空間,舊的改 不影響新的)
二、小資料池
== id is
==我們都用過了,就是進行判斷的,判斷兩邊的值是否一樣,例如
a = 10
b = 10
print(a == b)
a = "yangmei"
b = "yangmei"
print(a == b)
這樣就是查看==兩邊的值是否一樣.
我們再來看看id是個什么東西,我們知道在定義一個變數的時候,記憶體空間中其實是開辟了一塊空間,這個開辟的空間是有號碼的,我們來試一下
name = "yangmei"
print(id(name)) #查看記憶體地址
# 2646445653360
is 也是判斷,只不過這次判斷的是兩邊值得記憶體地址是否相同,我們來看看
a = 10
b = 10
print(id(a)) # 140726887389120
print(id(b)) # 140726887389120
print(a is b) # True
# 獲取的結果是True是因為a和b的記憶體地址是相同的
發現一個問題 == 和 is 都是True啊,這個is是判斷記憶體地址是否一樣,Python考慮到我們會經常定義一些值,需要開辟空間和銷毀空間,它底層就維護了一個小資料池,這個小資料就是規定一個區間使用的是同一個記憶體地址,比如小資料池中數字的區間范圍是 -5 ~ 256,我們剛剛測驗的10在區間內,所以獲取到的是相同的記憶體地址,我們試一試不在范圍的數字
a = 500
b = 500
print(id(a)) # 2756092656496
print(id(b)) # 2756092656496
print(a is b) # True
不再區間內,怎么記憶體地址還是一樣的啊,這就要說說python的另一個機制 — 代碼塊
代碼塊是防止我們頻繁的開空間降低效率設計的,當我們定一個變數需要開辟空間的時候,它會先去檢測我們定義的這個值在空間中有沒有進行開辟,如果沒有開辟就開辟一個空間,如果記憶體中開辟過就使用同一個,
一個檔案,一個函式,一個模塊,一個類,終端中一行就是一個代碼塊
代碼塊支持:
- 字串:
- 定義字串的時候內容,長度任意記憶體地址相同,
- 字串進行乘法的時候總長度 <=20 記憶體地址相同,
- 中文,特舒符號 乘法的時候只能乘以1或 0
- 數字:
- 相同的數字記憶體地址相同
- 布林值:
- 相同的記憶體地址相同
這就是我們為什么在pycharm中測驗的時候都是True,我們現在去終端上測驗一下數字的范圍

當代碼塊和小資料池兩個在一起,先執行代碼塊
我們知道了代碼塊支持的資料型別和支持怎樣的操作,現在來看看小資料池的支持資料型別和范圍:
小資料支持:
- 字串:
- 純字母和數字的時候長度任意,記憶體地址相同,
- Python36純字母和數字乘法總長度 <= 20 記憶體地址相同,
- Python37純字母和數字乘法總長度 <= 4096 記憶體地址相同,
- 中文和特殊符號乘法的時候只能乘以 0 記憶體地址相同
- 數字:
- -5 ~ 256
- 布林值:
- True
- False
小資料池和代碼塊都是Python內置的,咱們開發的時候不使用,他們統稱為駐留機制,有了小資料池和代碼塊能夠提升Python的效率
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/53185.html
標籤:Python
下一篇:詳解Python字典資料型別