我正在使用 Oracle 和 SQL Developer。我已經下載了 HR 模式,需要用它做一些查詢。現在我正在使用表 Employees。作為用戶,我需要查看其薪水與相應部門所有后來雇用同事的平均薪水之間差距最大的員工。這看起來很有趣也很復雜。我已經閱讀了一些檔案并嘗試過,例如 LEAD(),它可以同時訪問一個表的多個行:
SELECT
employee_id,
first_name
|| ' '
|| last_name,
department_id,
salary,
hire_date,
LEAD(hire_date)
OVER(PARTITION BY department_id
ORDER BY
hire_date DESC
) AS Prev_hiredate
FROM
employees
ORDER BY
department_id,
hire_date;
這顯示了部門中每個人對后來雇用人員的雇用率。我也嘗試使用視窗子句來理解它的概念:
SELECT
employee_id,
first_name
|| ' '
|| last_name,
department_id,
hire_date,
salary,
AVG(salary)
OVER(PARTITION BY department_id
ORDER BY
hire_date ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING
) AS avg_sal
FROM
employees
ORDER BY
department_id,
hire_date;
此查詢的結果將是: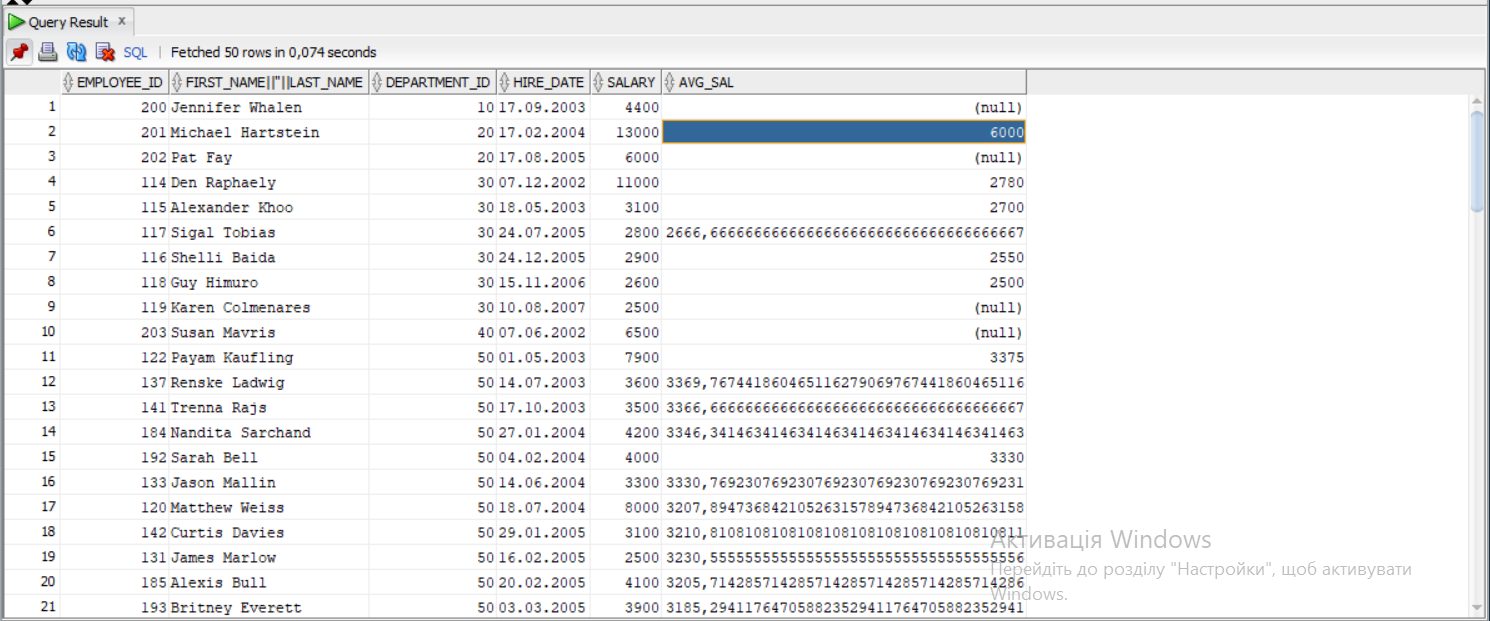
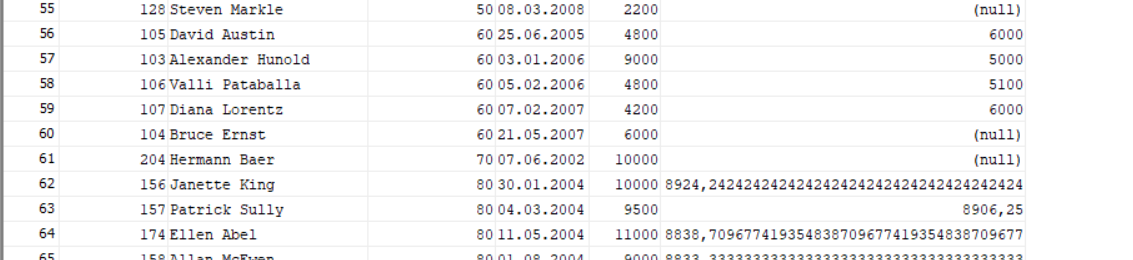
但是,這并不是我所需要的。我需要通過添加帶有差距的列 (salary-avr_sal) 來減少結果,其中差距最大,每個部門接收一名員工。結果應該是怎樣的:比如我們有60個部門。我們有 5 名員工在 hire_date 之前訂購。第一有工資4800,第二-9000,第三-4800,第四-4200,第五-6000。如果我們計算:4800 - ((9000 4800 4200 6000)/4)=-1200, 9000-((4800 4200 6000)/3)=4000, 4800 -((4200 6000)/2)=-300, 4200 - 6000=-1800部門最后一個人的差距最大:6000 - 0 = 6000。讓我們來看看20個部門。我們那里有兩個人:第一個有薪水 13000,第二個 - 6000。計算:13000 - 6000 = 7000,6000 - 0 = 6000. 最大的差距將是第一人稱。所以對于部門 20,結果應該是薪水 13000 的人,對于部門 60,結果應該是薪水 6000 的人,依此類推。應該如何查看我的查詢以獲得適當的結果(我需要的是粗體標記,我還想看到差距最大的列,可以是具有分析功能的不同解決方案,但必須包含視窗子句)?
uj5u.com熱心網友回復:
您只需調整 avg 的 rows 子句,即可獲得在當前員工之前雇用的員工的平均工資:
AVG(salary) OVER(
PARTITION BY department_id
ORDER BY hire_date
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS avg_salary
該1 PRECEDING子句告訴資料庫不要在視窗中包含當前行。
如果您正在尋找與平均水平差距最大的員工,我們可以只order by使用結果集:
SELECT e.*,
AVG(salary) OVER(
PARTITION BY department_id
ORDER BY hire_date
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS avg_salary
FROM employees e
ORDER BY ABS(salary - avg_salary) DESC;
最后,如果你想要每個部門最高的“離群工資”,那么我們至少需要多一個級別。表達這一點的最短方式可能是使用ROW_NUMBER()每個部門的員工根據他們與平均工資的差距對員工進行排名,然后使用以下方法獲取每個組的所有頂部行WITH TIES:
SELECT *
FROM (
SELECT e.*,
AVG(salary) OVER(
PARTITION BY department_id
ORDER BY hire_date
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS avg_salary
FROM employees e
) e
ORDER BY ROW_NUMBER() OVER(
PARTITION BY department_id
ORDER BY ABS(salary - avg_salary) DESC
)
FETCH FIRST ROW WITH TIES
uj5u.com熱心網友回復:
也許這就是您要找的。
樣本資料:
WITH
emp (ID, EMP_NAME, HIRE_DATE, SALARY, DEPT) AS
(
Select 601, 'HILLER', To_Date('23-JAN-82', 'dd-MON-yy'), 4800, 60 From Dual Union All
Select 602, 'MILLER', To_Date('23-FEB-82', 'dd-MON-yy'), 9000, 60 From Dual Union All
Select 603, 'SMITH', To_Date('23-MAR-82', 'dd-MON-yy'), 4800, 60 From Dual Union All
Select 604, 'FORD', To_Date('23-APR-82', 'dd-MON-yy'), 4200, 60 From Dual Union All
Select 605, 'KING', To_Date('23-MAY-82', 'dd-MON-yy'), 6000, 60 From Dual Union All
Select 201, 'SCOT', To_Date('23-MAR-82', 'dd-MON-yy'), 13000, 20 From Dual Union All
Select 202, 'JONES', To_Date('23-AUG-82', 'dd-MON-yy'), 6000, 20 From Dual
),
使用多個分析函式和視窗子句創建名為 grid 的 CTE。它們并非都是必需的,但下面生成的資料集顯示了包含所有組件的邏輯。
grid AS
(
Select
g.*, Max(GAP) OVER(PARTITION BY DEPT) "DEPT_MAX_GAP"
From
(
Select
ROWNUM "RN",
Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN Unbounded Preceding And Current Row) "RN_DEPT",
ID, EMP_NAME, HIRE_DATE, DEPT, SALARY,
--
Nvl(Sum(SALARY) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following), 0) "SUM_SAL_LATER",
Nvl(Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following), 0) "COUNT_EMP_LATER",
--
Nvl(Sum(SALARY) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following) /
Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following), 0) "AVG_LATER",
--
SALARY -
Nvl((
Sum(SALARY) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following) /
Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following)
), 0) "GAP"
from
emp
Order By
DEPT, HIRE_DATE, ID
) g
Order By
RN
)
CTE 網格結果資料集:
| 注冊護士 | RN_部門 | ID | EMP_NAME | 聘用日期 | 部門 | 薪水 | SUM_SAL_LATER | COUNT_EMP_LATER | AVG_LATER | 差距 | DEPT_MAX_GAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1個 | 1個 | 601 | 希勒 | 23-JAN-82 | 60 | 4800 | 24000 | 4個 | 6000 | -1200 | 6000 |
| 2個 | 2個 | 602 | 磨坊主 | 23-FEB-82 | 60 | 9000 | 15000 | 3個 | 5000 | 4000 | 6000 |
| 3個 | 3個 | 603 | 史密斯 | 82 年 3 月 23 日 | 60 | 4800 | 10200 | 2個 | 5100 | -300 | 6000 |
| 4個 | 4個 | 604 | 福特 | 23-APR-82 | 60 | 4200 | 6000 | 1個 | 6000 | -1800 | 6000 |
| 5個 | 5個 | 605 | 王 | 23-MAY-82 | 60 | 6000 | 0 | 0 | 0 | 6000 | 6000 |
| 6個 | 1個 | 201 | 蘇格蘭人 | 82 年 3 月 23 日 | 20 | 13000 | 6000 | 1個 | 6000 | 7000 | 7000 |
| 7 | 2個 | 202 | 瓊斯 | 23-AUG-82 | 20 | 6000 | 0 | 0 | 0 | 6000 | 7000 |
主SQL
SELECT
g.ID, g.EMP_NAME, g.HIRE_DATE, g.DEPT, g.SALARY, g.GAP
FROM
grid g
WHERE
g.GAP = g.DEPT_MAX_GAP
Order By
RN
結果為:
| ID | EMP_NAME | 聘用日期 | 部門 | 薪水 | 差距 |
|---|---|---|---|---|---|
| 605 | 王 | 23-MAY-82 | 60 | 6000 | 6000 |
| 201 | 蘇格蘭人 | 82 年 3 月 23 日 | 20 | 13000 | 7000 |
沒有 CTE 并且排除了所有不必要的列,它看起來像這樣:
SELECT ID, EMP_NAME, HIRE_DATE, DEPT, SALARY, GAP
FROM
(
( Select g.*, Max(GAP) OVER(PARTITION BY DEPT) "DEPT_MAX_GAP"
From( Select
ID, EMP_NAME, HIRE_DATE, DEPT, SALARY,
SALARY -
Nvl(( Sum(SALARY) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following) /
Sum(1) OVER(Partition By DEPT Order By DEPT, HIRE_DATE, ID ROWS BETWEEN 1 Following And Unbounded Following)
), 0) "GAP"
From emp
Order By DEPT, HIRE_DATE, ID
) g
)
)
WHERE GAP = DEPT_MAX_GAP
Order By DEPT, HIRE_DATE, ID
似乎這就是您所需要的。
問候...
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/534411.html
標籤:数据库甲骨文平均窗口函数