比賽說明:
比賽在四個學校開展,南理南航南農和礦大,
題目
查找文本差異
要求
origin和dest中分別包含1000w+條資料dest對資料進行了打亂操作,即origin和dest中相同資料行的順序不相同- 程式運行的總記憶體消耗不能超過
30MB - 程式運行的總時間消耗不能超過
10分鐘 origin中存在但dest中不存在的資料,取origin中的行號;dest中存在但origin中不存在的資料,取dest中的行號- 輸出的行號陣列按照升序排列
判定規則
- 總記憶體消耗超過
30MB,判定為不合格 - 總時間消耗超過
10分鐘,判定為不合格
示例
假設 origin 檔案內容為:
e630f353-01b3-4b2c-989c-6236b476140a
cc8626ef-c45b-4b9a-96b6-3206d8adc518
8c622fb7-8150-4487-91f2-6a860eb14feb
78c0fe67-b0ea-4fe5-9ef0-4157d956e3d2
假設 dest 檔案內容為:
78c0fe67-b0ea-4fe5-9ef0-4157d956e3d2
14fbf539-a614-402c-8ab9-8e7438f3bd72
e630f353-01b3-4b2c-989c-6236b476140a
cc8626ef-c45b-4b9a-96b6-3206d8adc518
輸出結果為:
[1, 2]
解決方案:
先分析本題的資料量,本題檔案資料量兩個檔案大約在3000萬條左右,比較符合海量資料的處理,同時對時間和記憶體的限定也十分的苛刻,
所以本題采用的方法是將大檔案每行按hash值放入對應的小檔案中,然后依次處理每個小檔案,
步驟:
首先將兩個大檔案按hash值分別放入切割后的小檔案,兩個檔案一共800mb,2800w行左右
while ((destLine=dest.readLine())!=null){
int code = hash(destLine)%200;
if (code<0)code=-code;//取絕對值
/**
* 追加檔案需要在FileWriter第二個引數選擇true
*/
BufferedWriter out = new BufferedWriter(new FileWriter("src/main/resources/file/"+code+".txt",true));
out.write(destLine);
out.write(","+String.valueOf(count)); //添加逗號是為了將行號加入,減少后面再去尋找行號的時間
out.write("\n");
out.flush();
count++;
}
while ((originLie=origin.readLine())!=null){
int code = hash(originLie)%200;
if (code<0)code=-code;//取絕對值
/**
* 追加檔案需要在FileWriter第二個引數選擇true
*/
BufferedWriter out = new BufferedWriter(new FileWriter("src/main/resources/file/"+code+".txt",true));
out.write(originLie);
out.write(","+count);
out.write("\n");
out.flush();
count++;
}
//寫入第一個檔案花費 16000ms
//寫入兩個大概33000ms

然后分別遍歷這些小檔案中的資料
String line=null;
List<String> list = new ArrayList<>();
for (int i=0;i<200;i++){
HashMap<String,String> hashMap = new HashMap<>();
BufferedReader bufferedReader = new BufferedReader(new FileReader("src/main/resources/file/"+i+".txt"));
while( (line = bufferedReader.readLine())!=null){
String[] a = line.split(",");
line = a[0];
String num = a[1];
//若HashMap中沒有字串,則將字串和行號放入
//若后續出現重復,則將行號改為true
if (hashMap.containsKey(line)){
hashMap.replace(line,"true");
}
else {
hashMap.put(line,num);
}
}
Set<String> Key = hashMap.keySet();
//向list中添加行號
for (String key:Key){
if (!hashMap.get(key).equals("true")){
list.add(hashMap.get(key));
}
}
hashMap=null; //置空 等GC
}
然后便是將list轉化為int型別陣列輸出
int [] result = new int[list.size()];
int index =0;
for (int i=0;i<list.size();i++){
String num = list.get(i);
result[index++] = Integer.parseInt(num);
}
處理結果:
時間花費6分鐘
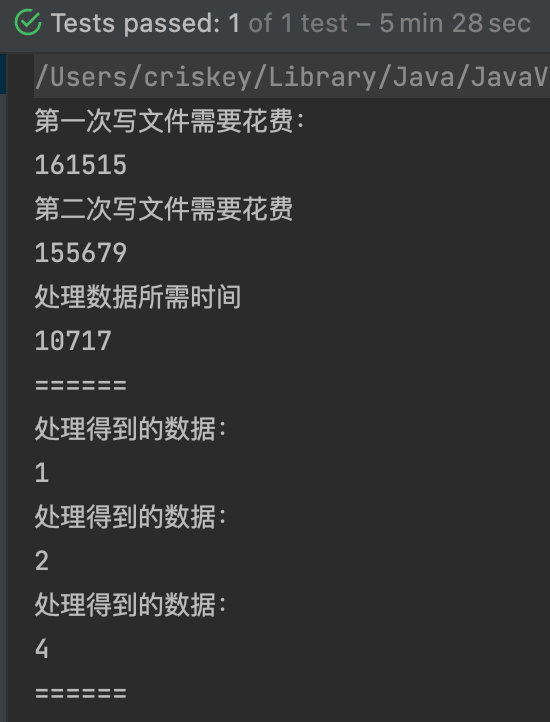
至此記憶體與時間的限制都滿足了,
注意問題
hashMap記憶體的釋放
全部代碼:
package com.focustech.fpc.algorithm;
import java.io.*;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.*;
import java.util.stream.Stream;
import static java.util.Objects.hash;
/**
* 差異分析器實作類示例
* @author KeC
**/
public class DemoDifferenceAnalyser implements IDifferenceAnalyser{
@Override
public int[] diff() {
/**
* 將大檔案分割成多份小檔案
* 使用hashSet進行查看是否含有
* 用流來讀取檔案
* 難點在于在規定時間內使用規定記憶體
* 用hashSet可以節省時間
*/
try {
ArrayList<Integer> res = new ArrayList<>();
int cnt = 0;
File file=new File("src/main/resources/dest");
String fileDestName=file.getName();
long fileDestSize=file.length();
File file1 = new File("src/main/resources/origin");
String fileOriginName = file1.getName();
long fileOriginSize = file1.length();
//緩沖流 =================================================
InputStream inputDest = this.getClass().getClassLoader().getResourceAsStream("dest");
InputStreamReader destReader= new InputStreamReader(inputDest);
BufferedReader dest = new BufferedReader(destReader);
InputStream inputOrigin = this.getClass().getClassLoader().getResourceAsStream("origin");
InputStreamReader originReader= new InputStreamReader(inputOrigin);
BufferedReader origin = new BufferedReader(originReader);
//========================================================
/**
* 分割檔案 兩個大檔案分割成400份小檔案
* 本次操作為創建400個檔案
*/
for(int i=0;i<200;i++){
File file2 = new File("src/main/resources/file/"+i+".txt");
if (file2.exists()) file2.delete();
if (!file2.exists()) file2.createNewFile();
}
String destLine,originLie;
/*
根據哈希值將檔案中的行數放到400個檔案中,
哈希值相同的會被放到一個檔案里
*/
long timeStart1 = System.currentTimeMillis();
int count = 0;
while ((destLine=dest.readLine())!=null){
int code = hash(destLine)%200;
if (code<0)code=-code;//取絕對值
/**
* 追加檔案需要在FileWriter第二個引數選擇true
*/
BufferedWriter out = new BufferedWriter(new FileWriter("src/main/resources/file/"+code+".txt",true));
out.write(destLine);
out.write(","+String.valueOf(count));
out.write("\n");
out.flush();
count++;
}
System.out.println("第一次寫檔案需要花費:");
System.out.println(System.currentTimeMillis()-timeStart1);
long timeStart2 = System.currentTimeMillis();
count = 0;
while ((originLie=origin.readLine())!=null){
int code = hash(originLie)%200;
if (code<0)code=-code;//取絕對值
/**
* 追加檔案需要在FileWriter第二個引數選擇true
*/
BufferedWriter out = new BufferedWriter(new FileWriter("src/main/resources/file/"+code+".txt",true));
out.write(originLie);
out.write(","+count);
out.write("\n");
out.flush();
count++;
}
/**
* 讀寫操作約耗時5min
*/
System.out.println("第二次寫檔案需要花費");
System.out.println(System.currentTimeMillis()-timeStart2);
/**
* 接下來遍歷200個檔案
*/
String line=null;
List<String> list = new ArrayList<>();
// HashMap<String,String> numMap = new HashMap<>();
for (int i=0;i<200;i++){
HashMap<String,String> hashMap = new HashMap<>();
BufferedReader bufferedReader = new BufferedReader(new FileReader("src/main/resources/file/"+i+".txt"));
while( (line = bufferedReader.readLine())!=null){
String[] a = line.split(",");
line = a[0];
String num = a[1];
if (hashMap.containsKey(line)){
hashMap.replace(line,"true");
}
else {
hashMap.put(line,num);
}
}
Set<String> Key = hashMap.keySet();
for (String key:Key){
if (!hashMap.get(key).equals("true")){
list.add(hashMap.get(key));
}
}
hashMap=null; //置空 等GC
}
dest.close();
origin.close();
int [] result = new int[list.size()];
int index =0;
for (int i=0;i<list.size();i++){
String num = list.get(i);
result[index++] = Integer.parseInt(num);
}
Arrays.sort(result);
System.out.println(result);
return result;
} catch (IOException ex) {
ex.printStackTrace();
}
return new int[0];
}
}
改進
使用單執行緒讀檔案,多執行緒寫檔案,
創建一個ToFile類 繼承Thread類
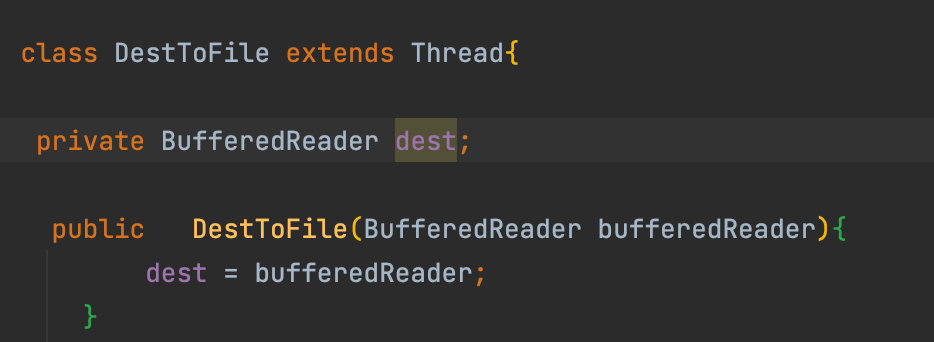
多執行緒寫檔案時碰到的問題
java.io.IOException: Stream closed
這是因為在執行緒啟動后,主執行緒沒有等子執行緒結束并接著運行,主執行緒關閉了子執行緒的檔案流,

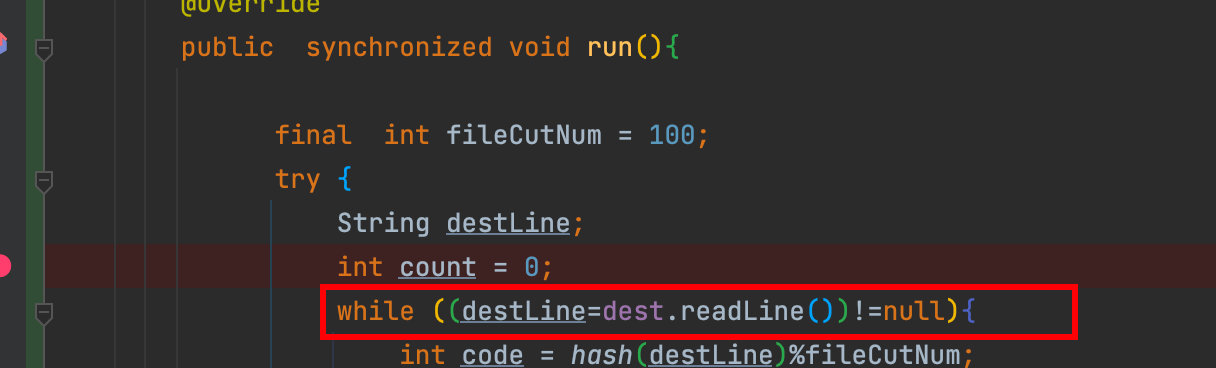
需要在子執行緒啟動后加
測驗結果:
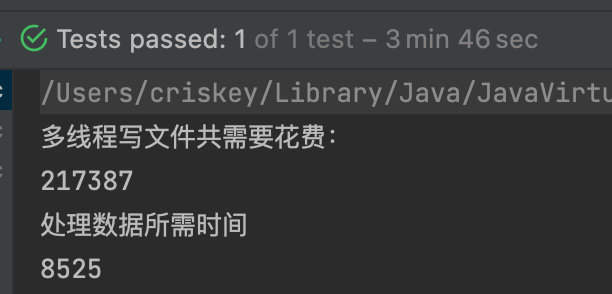
多執行緒處理后時間減少了兩分鐘左右,
多執行緒全部代碼:
package com.focustech.fpc.algorithm;
import java.io.*;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.*;
import java.util.stream.Stream;
import static java.util.Objects.hash;
/**
* 差異分析器實作類示例
* @author KeC
**/
public class DemoDifferenceAnalyser implements IDifferenceAnalyser{
final static int fileCutNum = 100;
@Override
public int[] diff() {
/**
* 將大檔案分割成多份小檔案
* 使用hashSet進行查看是否含有
* 用流來讀取檔案
* 難點在于在規定時間內使用規定記憶體
* 用hashSet可以節省時間
*/
try {
ArrayList<Integer> res = new ArrayList<>();
int cnt = 0;
File file=new File("src/main/resources/dest");
String fileDestName=file.getName();
long fileDestSize=file.length();
File file1 = new File("src/main/resources/origin");
String fileOriginName = file1.getName();
long fileOriginSize = file1.length();
//緩沖流 =================================================
InputStream inputDest = this.getClass().getClassLoader().getResourceAsStream("dest");
InputStreamReader destReader= new InputStreamReader(inputDest);
BufferedReader dest = new BufferedReader(destReader);
InputStream inputOrigin = this.getClass().getClassLoader().getResourceAsStream("origin");
InputStreamReader originReader= new InputStreamReader(inputOrigin);
BufferedReader origin = new BufferedReader(originReader);
//========================================================
/**
* 分割檔案 兩個大檔案分割成400份小檔案
* 本次操作為創建400個檔案
*/
for(int i=0;i<fileCutNum;i++){
File file2 = new File("src/main/resources/file/"+i+".txt");
if (file2.exists()) file2.delete();
if (!file2.exists()) file2.createNewFile();
}
// String destLine,originLie;
/*
根據哈希值將檔案中的行數放到400個檔案中,
哈希值相同的會被放到一個檔案里
*/
long timeStart1 = System.currentTimeMillis();
ToFile threadOne = new ToFile(dest);
ToFile threadTwo = new ToFile(origin);
threadOne.start();
threadTwo.start();
threadOne.join();
threadTwo.join();
Thread.sleep(100);
System.out.println("多執行緒寫檔案共需要花費:");
System.out.println(System.currentTimeMillis()-timeStart1);
/**
* 接下來遍歷多個檔案
*/
long startTime = System.currentTimeMillis();
String line=null;
List<String> list = new ArrayList<>();
for (int i=0;i<fileCutNum;i++){
HashMap<String,String> hashMap = new HashMap<>();
BufferedReader bufferedReader = new BufferedReader(new FileReader("src/main/resources/file/"+i+".txt"));
while( (line = bufferedReader.readLine())!=null){
String[] a = line.split(",");
line = a[0];
String num = a[1];
if (hashMap.containsKey(line)){
hashMap.replace(line,"true");
}
else {
hashMap.put(line,num);
}
}
Set<String> Key = hashMap.keySet();
for (String key:Key){
if (!hashMap.get(key).equals("true")){
list.add(hashMap.get(key));
}
}
hashMap=null; //置空 等GC
}
dest.close();
origin.close();
int [] result = new int[list.size()];
int index =0;
for (int i=0;i<list.size();i++){
String num = list.get(i);
result[index++] = Integer.parseInt(num);
}
Arrays.sort(result);
System.out.println("處理資料所需時間");
System.out.println(System.currentTimeMillis()-startTime);
System.out.println("======");
for (int i=0;i< result.length;i++){
System.out.println("處理得到的資料:");
System.out.println(result[i]);
}
System.out.println("======");
return result;
} catch (IOException ex) {
ex.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return new int[0];
}
}
class ToFile extends Thread{
private BufferedReader dest;
public ToFile(BufferedReader bufferedReader){
dest = bufferedReader;
}
@Override
public synchronized void run(){
final int fileCutNum = 100;
try {
String destLine;
int count = 0;
while ((destLine=dest.readLine())!=null){
int code = hash(destLine)%fileCutNum;
if (code<0)code=-code;//取絕對值
/**
* 追加檔案需要在FileWriter第二個引數選擇true
*/
BufferedWriter out = new BufferedWriter(new FileWriter("src/main/resources/file/"+code+".txt",true));
out.write(destLine);
out.write(","+String.valueOf(count));
out.write("\n");
out.flush();
count++;
}
}catch (Exception e){
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
若記憶體不夠可以調整檔案切割數量,數量越大所需的記憶體越少,但是回應檔案處理時間會增多,
資料集鏈接:https://www.aliyundrive.com/s/HSNYbfJbsWV
提取碼s66l
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/535129.html
標籤:Java
下一篇:Java反應式編程(3)