RabbitMQ 常見問題 昔我往矣,楊柳依依,今我來思,雨雪霏霏,
1、什么是RabbitMQ?
RabbitMQ是一款開源的、Erlang撰寫的訊息中間件;最大的特點就是消費并不需要確保提供方存在,實作了服務之間的高度解耦,可以用它來:解耦、異步、削峰,2、MQ的優點
- 異步處理 - 相比于傳統的串行、并行方式,提高了系統吞吐量,
- 應用解耦 - 系統間通過訊息通信,不用關心其他系統的處理,
- 流量削鋒 - 可以通過訊息佇列長度控制請求量;可以緩解短時間內的高并發請求,
- 日志處理 - 解決大量日志傳輸,
- 訊息通訊 - 訊息佇列一般都內置了高效的通信機制,因此也可以用在純的訊息通訊,比如實作點對點訊息佇列,或者聊天室等,
3、訊息佇列有什么缺點
1. 系統可用性降低 本來系統運行好好的,現在你非要加入個訊息佇列進去,那訊息佇列掛了,你的系統不是呵呵了,因此,系統可用性會降低; 2. 系統復雜度提高 加入了訊息佇列,要多考慮很多方面的問題,比如:一致性問題、如何保證訊息不被重復消費、如何保證訊息可靠性傳輸等,因此,需要考慮的東西更多,復雜性增大, 3. 一致性問題 A 系統處理完了直接回傳成功了,人都以為你這個請求就成功了;但是問題是,要是 BCD 三個系統那里,BD 兩個系統寫庫成功了,結果 C 系統寫庫失敗了,咋整?你這資料就不一致了,4、你們公司生產環境用的是什么訊息中間件?
- 比如用的是RabbitMQ,然后可以初步給一些你對不同MQ中間件技術的選型分析,
- 舉個例子:比如說ActiveMQ是老牌的訊息中間件,國內很多公司過去運用的還是非常廣泛的,功能很強大,但是問題在于沒法確認ActiveMQ可以支撐互聯網公司的高并發、高負載以及高吞吐的復雜場景,在國內互聯網公司落地較少,而且使用較多的是一些傳統企業,用ActiveMQ做異步呼叫和系統解耦,
- 然后可以說說RabbitMQ,他的好處在于可以支撐高并發、高吞吐、性能很高,同時有非常完善便捷的后臺管理界面可以使用,另外,他還支持集群化、高可用部署架構、訊息高可靠支持,功能較為完善,而且經過調研,國內各大互聯網公司落地大規模RabbitMQ集群支撐自身業務的case較多,國內各種中小型互聯網公司使用RabbitMQ的實踐也比較多,除此之外,RabbitMQ的開源社區很活躍,較高頻率的迭代版本,來修復發現的bug以及進行各種優化,因此綜合考慮過后,公司采取了RabbitMQ,但是RabbitMQ也有一點缺陷,就是他自身是基于erlang語言開發的,所以導致較為難以分析里面的原始碼,也較難進行深層次的原始碼定制和改造,畢竟需要較為扎實的erlang語言功底才可以,
- 然后可以聊聊RocketMQ,是阿里開源的,經過阿里的生產環境的超高并發、高吞吐的考驗,性能卓越,同時還支持分布式事務等特殊場景,而且RocketMQ是基于Java語言開發的,適合深入閱讀原始碼,有需要可以站在原始碼層面解決線上生產問題,包括原始碼的二次開發和改造,
- 另外就是Kafka,Kafka提供的訊息中間件的功能明顯較少一些,相對上述幾款MQ中間件要少很多,但是Kafka的優勢在于專為超高吞吐量的實時日志采集、實時資料同步、實時資料計算等場景來設計,因此Kafka在大資料領域中配合實時計算技術(比如Spark Streaming、Storm、Flink)使用的較多,但是在傳統的MQ中間件使用場景中較少采用,
5、MQ 有哪些常見問題?如何解決這些問題?
MQ 的常見問題有:- 訊息的順序問題
- 訊息的重復問題
訊息的順序問題
訊息有序指的是可以按照訊息的發送順序來消費, 假如生產者產生了 2 條訊息:M1、M2,假定 M1 發送到 S1,M2 發送到 S2,如何保證 M1 先于 M2 被消費?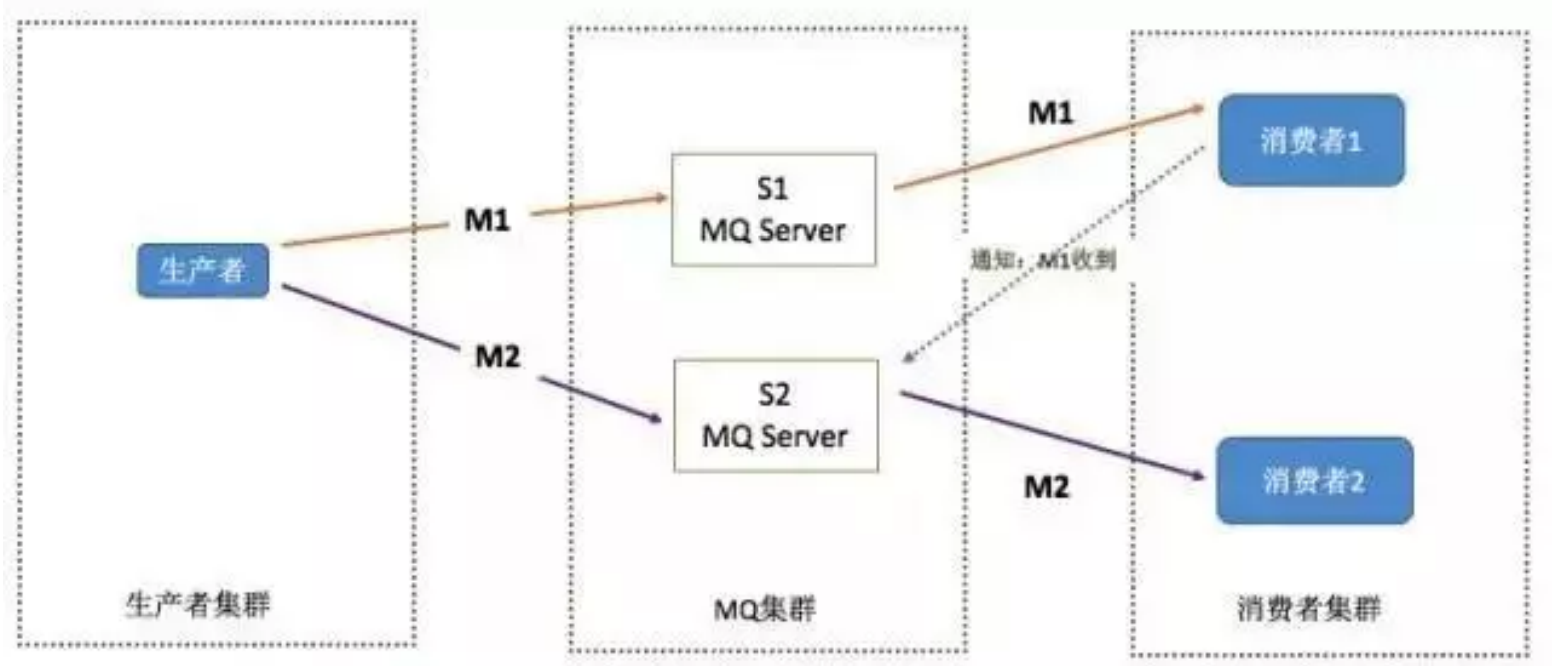 解決方案:
1. 保證生產者 - MQServer - 消費者是一對一對一的關系
解決方案:
1. 保證生產者 - MQServer - 消費者是一對一對一的關系
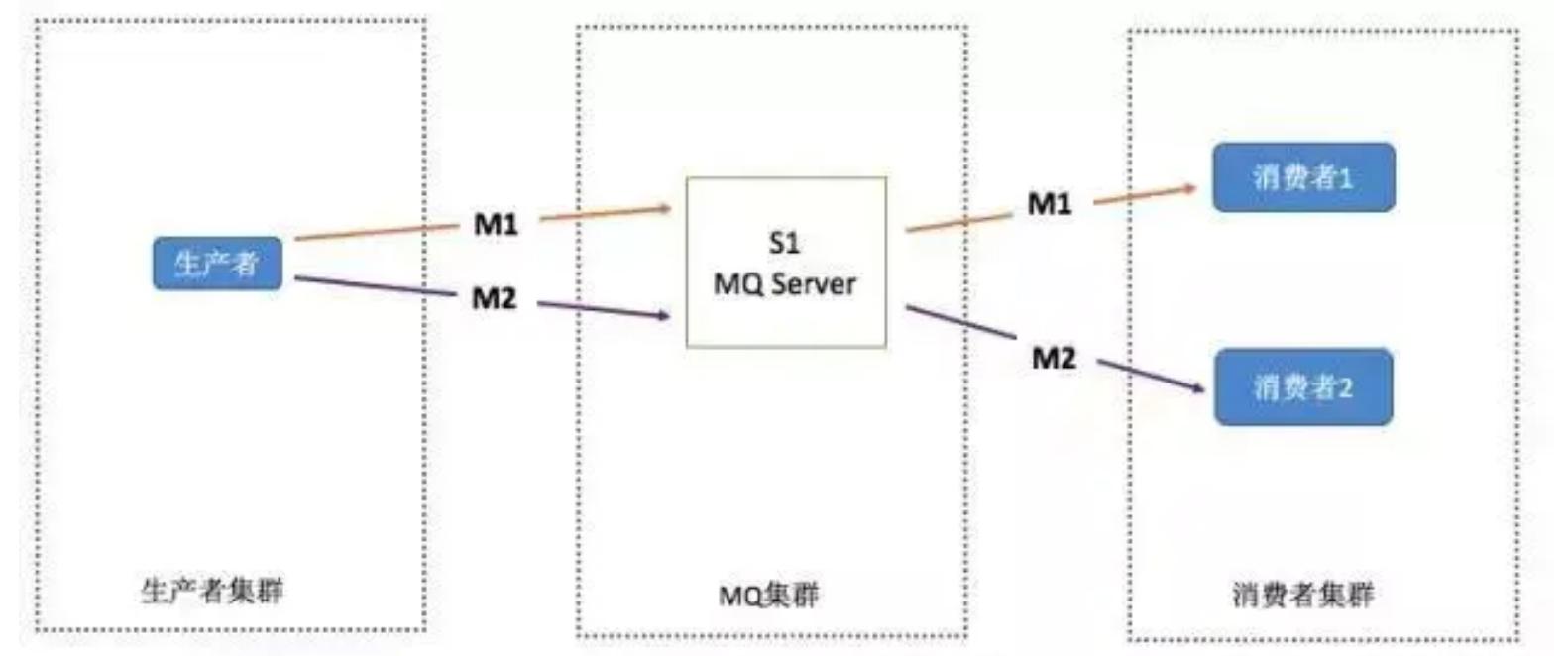
- 并行度就會成為訊息系統的瓶頸(吞吐量不夠)
- 更多的例外處理,比如:只要消費端出現問題,就會導致整個處理流程阻塞,我們不得不花費更多的精力來解決阻塞的問題,
- 不關注亂序的應用實際大量存在
- 佇列無序并不意味著訊息無序,所以從業務層面來保證訊息的順序而不僅僅是依賴于訊息系統,是一種更合理的方式,
訊息的重復問題
- 造成訊息重復的根本原因是:網路不可達,
- 所以解決這個問題的辦法就是繞過這個問題,那么問題就變成了:如果消費端收到兩條一樣的訊息,應該怎樣處理?
- 消費端處理訊息的業務邏輯保持冪等性,只要保持冪等性,不管來多少條重復訊息,最后處理的結果都一樣,保證每條訊息都有唯一編號且保證訊息處理成功與去重表的日志同時出現,利用一張日志表來記錄已經處理成功的訊息的 ID,如果新到的訊息 ID 已經在日志表中,那么就不再處理這條訊息,
6、rabbitmq 的使用場景
(1)服務間異步通信 (2)順序消費 (3)定時任務 (4)請求削峰7、RabbitMQ基本概念
- Broker: 簡單來說就是訊息佇列服務器物體
- Exchange: 訊息交換機,它指定訊息按什么規則,路由到哪個佇列
- Queue: 訊息佇列載體,每個訊息都會被投入到一個或多個佇列
- Binding: 系結,它的作用就是把exchange和queue按照路由規則系結起來
- Routing Key: 路由關鍵字,exchange根據這個關鍵字進行訊息投遞
- VHost: vhost 可以理解為虛擬 broker ,即 mini-RabbitMQ server,其內部均含有獨立的queue、exchange 和 binding 等,但最最重要的是,其擁有獨立的權限系統,可以做到 vhost 范圍的用戶控制,當然,從 RabbitMQ 的全域角度,vhost 可以作為不同權限隔離的手段(一個典型的例子就是不同的應用可以跑在不同的 vhost 中),
- Producer: 訊息生產者,就是投遞訊息的程式
- Consumer: 訊息消費者,就是接受訊息的程式
- Channel: 訊息通道,在客戶端的每個連接里,可建立多個channel,每個channel代表一個會話任務
- 由Exchange、Queue、RoutingKey三個才能決定一個從Exchange到Queue的唯一的線路,
8、RabbitMQ的作業模式
simple模式(即最簡單的收發模式)
1. 訊息生產者產生訊息,將訊息放入佇列, 2. 訊息的消費者(consumer) 監聽 訊息佇列,如果佇列中有訊息,就消費掉,訊息被拿走后,自動從佇列中洗掉(隱患:訊息可能沒有被消費者正確處理,就已經從佇列中消失了,造成訊息的丟失,這里可以設定成手動的ack,但如果設定成手動ack,處理完后要及時發送ack訊息給佇列,否則會造成記憶體溢位),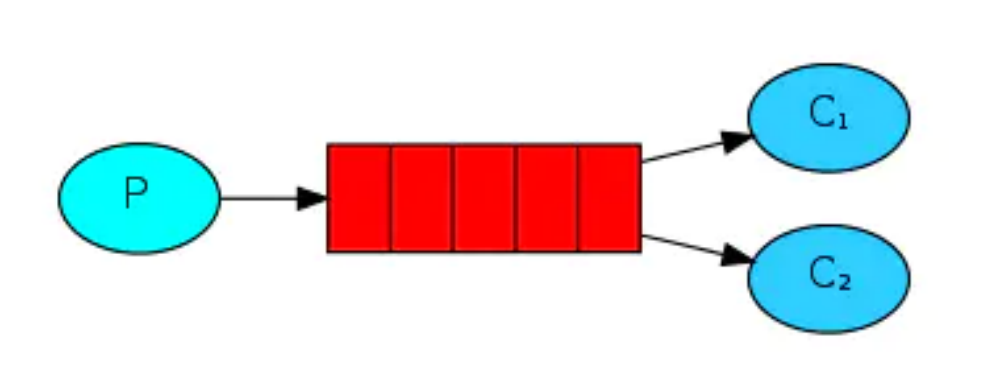
work作業模式(資源的競爭)
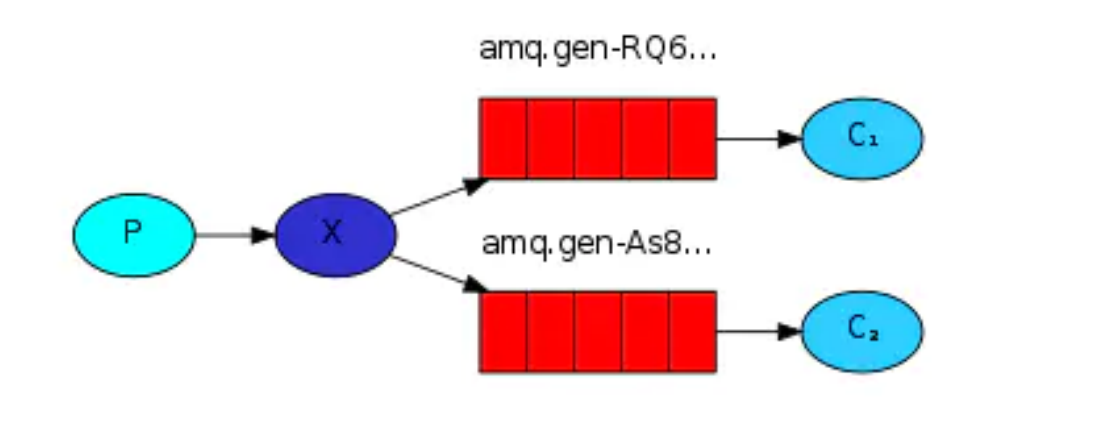
訊息產生者將訊息放入佇列,消費者可以有多個,消費者1、消費者2 同時監聽同一個佇列,訊息被消費, C1、C2共同爭搶當前的訊息佇列內容,誰先拿到誰負責消費訊息(隱患:高并發情況下,默認會產生某一個訊息被多個消費者共同使用,可以設定一個開關(syncronize) 保證一條訊息只能被一個消費者使用),publish/subscribe發布訂閱(共享資源)
- 每個消費者監聽自己的佇列;
- 生產者將訊息發給broker,由交換機將訊息轉發到系結此交換機的每個佇列,每個系結交換機的佇列都將接收到訊息,
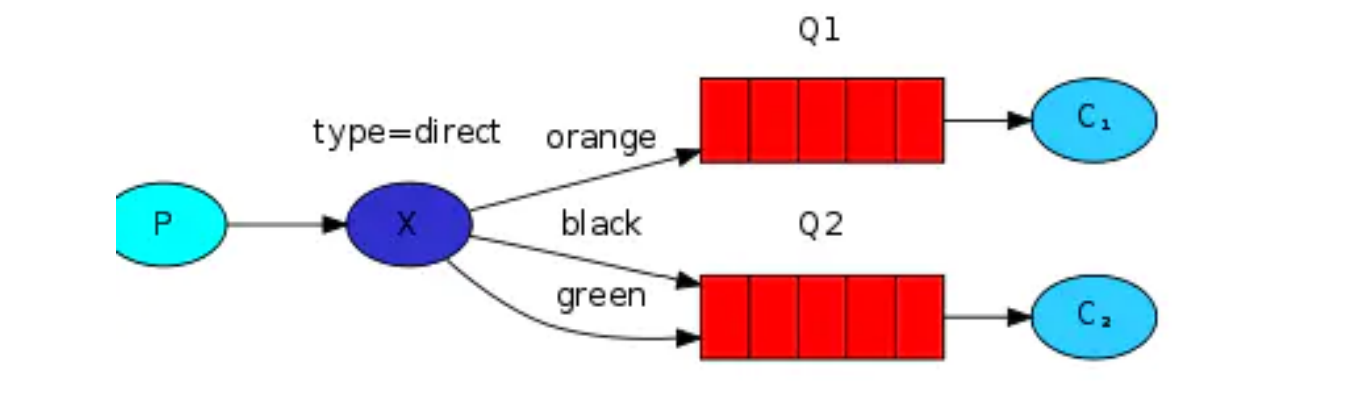
routing路由模式
- 訊息生產者將訊息發送給交換機按照路由判斷,路由是字串(info) 當前產生的訊息攜帶路由字符(物件的方法),交換機根據路由的key,只能匹配上路由key對應的訊息佇列,對應的消費者才能消費訊息;
- 根據業務功能定義路由字串
- 從系統的代碼邏輯中獲取對應的功能字串,將訊息任務扔到對應的佇列中,
- 業務場景:error 通知;EXCEPTION;錯誤通知的功能;傳統意義的錯誤通知;客戶通知;利用key路由,可以將程式中的錯誤封裝成訊息傳入到訊息佇列中,開發者可以自定義消費者,實時接收錯誤;,
topic 主題模式(路由模式的一種)
1. 星號井號代表通配符 2. 星號代表多個單詞,井號代表一個單詞 3. 路由功能添加模糊匹配,routing查詢的一種模糊匹配,就類似sql的模糊查詢方式 4. 訊息產生者產生訊息,把訊息交給交換機 5. 交換機根據key的規則模糊匹配到對應的佇列,由佇列的監聽消費者接收訊息消費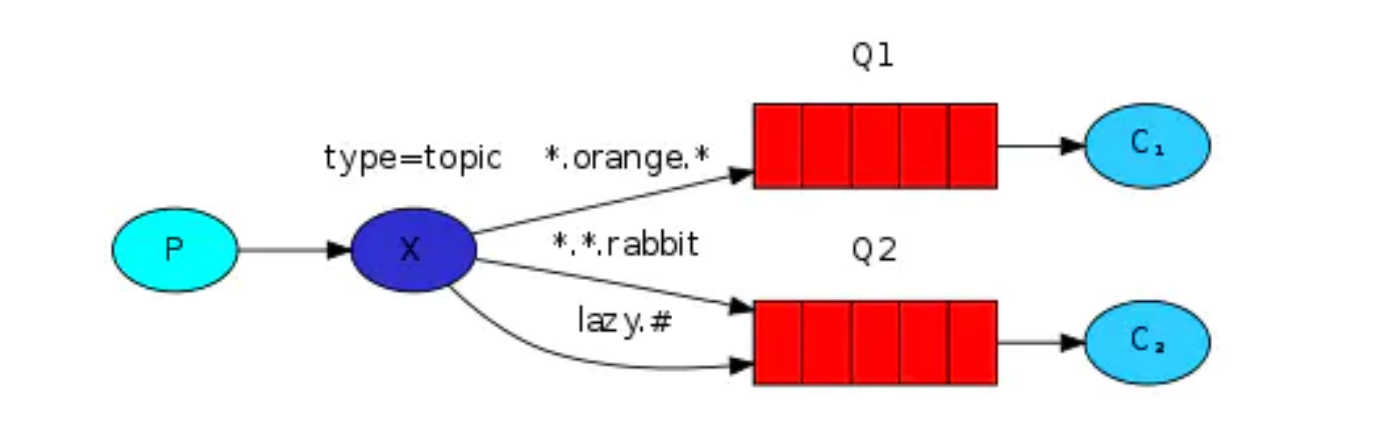
9、如何保證RabbitMQ訊息的順序性?
- 拆分多個 queue(訊息佇列),每個 queue(訊息佇列) 一個 consumer(消費者),就是多一些 queue(訊息佇列)而已,確實是麻煩點;
- 或者就一個 queue (訊息佇列)但是對應一個 consumer(消費者),然后這個 consumer(消費者)內部用記憶體佇列做排隊,然后分發給底層不同的 worker 來處理,
10、訊息如何分發?
若該佇列至少有一個消費者訂閱,訊息將以回圈(round-robin)的方式發送給消費者,每條訊息只會分發給一個訂閱的消費者(前提是消費者能夠正常處理訊息并進行確認),通過路由可實作多消費的功能,11. 訊息怎么路由?
- 訊息提供方->路由->一至多個佇列訊息發布到交換器時,訊息將擁有一個路由鍵(routing key),在訊息創建時設定,通過佇列路由鍵,可以把佇列系結到交換器上,訊息到達交換器后,RabbitMQ 會將訊息的路由鍵與佇列的路由鍵進行匹配(針對不同的交換器有不同的路由規則);
- 常用的交換器主要分為一下三種:
- fanout:如果交換器收到訊息,將會廣播到所有系結的佇列上
- direct:如果路由鍵完全匹配,訊息就被投遞到相應的佇列
- topic:可以使來自不同源頭的訊息能夠到達同一個佇列, 使用 topic 交換器時,可以使用通配符
12、訊息基于什么傳輸?
由于 TCP 連接的創建和銷毀開銷較大,且并發數受系統資源限制,會造成性能瓶頸,RabbitMQ使用信道的方式來傳輸資料,信道是建立在真實的 TCP 連接內的虛擬連接,且每條 TCP 連接上的信道數量沒有限制,12、消費時的冪等性?
- 先說為什么會重復消費:正常情況下,消費者在消費訊息的時候,消費完畢后,會發送一個確認訊息給訊息佇列,訊息佇列就知道該訊息被消費了,就會將該訊息從訊息佇列中洗掉;
- 但是因為網路傳輸等等故障,確認資訊沒有傳送到訊息佇列,導致訊息佇列不知道自己已經消費過該訊息了,再次將訊息分發給其他的消費者,
- 針對以上問題,一個解決思路是:保證訊息的唯一性,就算是多次傳輸,不要讓訊息的多次消費帶來影響;保證訊息等冪性;
- 比如:在寫入訊息佇列的資料做唯一標示,消費訊息時,根據唯一標識判斷是否消費過;
- 假設你有個系統,消費一條訊息就往資料庫里插入一條資料,要是你一個訊息重復兩次,你不就插入了兩條,這資料不就錯了?但是你要是消費到第二次的時候,自己判斷一下是否已經消費過了,若是就直接扔了,這樣不就保留了一條資料,從而保證了資料的正確性,
13、如何確保訊息正確地發送至 RabbitMQ? 如何確保訊息接收方消費了訊息?
發送方確認模式
- 將信道設定成 confirm 模式(發送方確認模式),則所有在信道上發布的訊息都會被指派一個唯一的 ID,
- 一旦訊息被投遞到目的佇列后,或者訊息被寫入磁盤后(可持久化的訊息),信道會發送一個確認給生產者(包含訊息唯一 ID),
- 如果 RabbitMQ 發生內部錯誤從而導致訊息丟失,會發送一條 nack(notacknowledged,未確認)訊息,
- 發送方確認模式是異步的,生產者應用程式在等待確認的同時,可以繼續發送訊息,當確認訊息到達生產者應用程式,生產者應用程式的回呼方法就會被觸發來處理確認訊息,
接收方確認機制
- 消費者接收每一條訊息后都必須進行確認(訊息接收和訊息確認是兩個不同操作),只有消費者確認了訊息,RabbitMQ 才能安全地把訊息從佇列中洗掉,
- 這里并沒有用到超時機制,RabbitMQ 僅通過 Consumer 的連接中斷來確認是否需要重新發送訊息,也就是說,只要連接不中斷,RabbitMQ 給了 Consumer 足夠長的時間來處理訊息,保證資料的最終一致性;
下面羅列幾種特殊情況
- 如果消費者接收到訊息,在確認之前斷開了連接或取消訂閱,RabbitMQ 會認為訊息沒有被分發,然后重新分發給下一個訂閱的消費者,(可能存在訊息重復消費的隱患,需要去重)
- 如果消費者接收到訊息卻沒有確認訊息,連接也未斷開,則 RabbitMQ 認為該消費者繁忙,將不會給該消費者分發更多的訊息,
14、如何保證RabbitMQ訊息的可靠傳輸?
- 訊息不可靠的情況可能是訊息丟失,劫持等原因;
- 丟失又分為:生產者丟失訊息、訊息串列丟失訊息、消費者丟失訊息;
1. 生產者丟失訊息
- 從生產者弄丟資料這個角度來看,RabbitMQ提供transaction和confirm模式來確保生產者不丟訊息;
- transaction機制就是說:發送訊息前,開啟事務(channel.txSelect()),然后發送訊息,如果發送程序中出現什么例外,事務就會回滾(channel.txRollback()),如果發送成功則提交事務(channel.txCommit()),
- 然而,這種方式有個缺點:吞吐量下降;
- confirm模式用的居多:一旦channel進入confirm模式,所有在該信道上發布的訊息都將會被指派一個唯一的ID(從1開始),一旦訊息被投遞到所有匹配的佇列之后;rabbitMQ就會發送一個ACK給生產者(包含訊息的唯一ID),這就使得生產者知道訊息已經正確到達目的佇列了;
- 如果rabbitMQ沒能處理該訊息,則會發送一個Nack訊息給你,你可以進行重試操作,
2. 訊息佇列丟資料:訊息持久化,
- 處理訊息隊列丟資料的情況,一般是開啟持久化磁盤的配置,
- 這個持久化配置可以和confirm機制配合使用,你可以在訊息持久化磁盤后,再給生產者發送一個Ack信號,這樣,如果訊息持久化磁盤之前,rabbitMQ陣亡了,那么生產者收不到Ack信號,生產者會自動重發,
- 那么如何持久化呢?其實也很容易,就下面兩步
- 將queue的持久化標識durable設定為true,則代表是一個持久的佇列,
- 發送訊息的時候將deliveryMode=2這樣設定以后,即使rabbitMQ掛了,重啟后也能恢復資料,
3. 消費者丟失訊息
- 消費者丟資料一般是因為采用了自動確認訊息模式,改為手動確認訊息即可!
- 消費者在收到訊息之后,處理訊息之前,會自動回復RabbitMQ已收到訊息;
- 如果這時處理訊息失敗,就會丟失該訊息;解決方案:處理訊息成功后,手動回復確認訊息,
15、為什么不應該對所有的 message 都使用持久化機制?
- 首先,必然導致性能的下降,因為寫磁盤比寫 RAM 慢的多,message 的吞吐量可能有 10 倍的差距,
- 其次,message 的持久化機制用在 RabbitMQ 的內置 cluster 方案時會出現“坑爹”問題,矛盾點在于,若 message 設定了 persistent 屬性,但 queue 未設定 durable 屬性,那么當該 queue 的owner node 出現例外后,在未重建該 queue 前,發往該 queue 的 message 將被 blackholed;若 message 設定了 persistent 屬性,同時 queue 也設定了 durable 屬性,那么當 queue 的owner node 例外且無法重啟的情況下,則該 queue 無法在其他 node 上重建,只能等待其owner node 重啟后,才能恢復該 queue 的使用,而在這段時間內發送給該 queue 的 message將被 blackholed ,
- 所以,是否要對 message 進行持久化,需要綜合考慮性能需要,以及可能遇到的問題,若想達到100,000 條/秒以上的訊息吞吐量(單 RabbitMQ 服務器),則要么使用其他的方式來確保message 的可靠 delivery ,要么使用非常快速的存盤系統以支持全持久化(例如使用 SSD),另外一種處理原則是:僅對關鍵訊息作持久化處理(根據業務重要程度),且應該保證關鍵訊息的量不會導致性能瓶頸,
16、如何保證高可用的?RabbitMQ 的集群?
RabbitMQ 是比較有代表性的,因為是基于主從(非分布式)做高可用性的,我們就以 RabbitMQ為例子講解第一種 MQ 的高可用性怎么實作,RabbitMQ 有三種模式:單機模式、普通集群模式、鏡像集群模式,1. 單機模式
就是 Demo 級別的,一般就是你本地啟動了玩玩兒的,沒人生產用單機模式,2. 普通集群模式
意思就是在多臺機器上啟動多個 RabbitMQ 實體,每個機器啟動一個, 你創建的 queue,只會放在一個 RabbitMQ 實體上,但是每個實體都同步 queue 的元資料(元資料可以認為是 queue 的一些配置資訊,通過元資料,可以找到 queue 所在實體),你消費的時候,實際上如果連接到了另外一個實體,那么那個實體會從 queue 所在實體上拉取資料過來,這方案主要是提高吞吐量的,就是說讓集群中多個節點來服務某個 queue 的讀寫操作,3. 鏡像集群模式
- 這種模式,才是所謂的 RabbitMQ 的高可用模式,跟普通集群模式不一樣的是,在鏡像集群模式下,你創建的 queue,無論元資料還是 queue 里的訊息都會存在于多個實體上,就是說,每個 RabbitMQ 節點都有這個 queue 的一個完整鏡像,包含 queue 的全部資料的意思,然后每次你寫訊息到 queue 的時候,都會自動把訊息同步到多個實體的 queue 上,RabbitMQ 有很好的管理控制臺,就是在后臺新增一個策略,這個策略是鏡像集群模式的策略,指定的時候是可以要求資料同步到所有節點的,也可以要求同步到指定數量的節點,再次創建 queue 的時候,應用這個策略,就會自動將資料同步到其他的節點上去了,
- 這樣的好處在于,你任何一個機器宕機了,沒事兒,其它機器(節點)還包含了這個 queue的完整資料,別的 consumer 都可以到其它節點上去消費資料,壞處在于,第一,這個性能開銷也太大了吧,訊息需要同步到所有機器上,導致網路帶寬壓力和消耗很重!RabbitMQ一個 queue 的資料都是放在一個節點里的,鏡像集群下,也是每個節點都放這個 queue 的完整資料,
17、如何解決訊息佇列的延時以及過期失效問題?訊息佇列滿了以后該怎么處理?有幾百萬訊息持續積壓幾小時,怎么辦?
- 訊息積壓處理辦法:臨時緊急擴容,
- 先修復 consumer 的問題,確保其恢復消費速度,然后將現有 cnosumer 都停掉,新建一個 topic,partition 是原來的 10 倍,臨時建立好原先 10 倍的 queue 數量,然后寫一個臨時的分發資料的 consumer 程式,這個程式部署上去消費積壓的資料,消費之后不做耗時的處理,直接均勻輪詢寫入臨時建立好的 10 倍數量的 queue,接著臨時征用 10 倍的機器來部署 consumer,每一批 consumer 消費一個臨時 queue 的資料,這種做法相當于是臨時將 queue 資源和 consumer 資源擴大 10 倍,以正常的 10 倍速度來消費資料,等快速消費完積壓資料之后,得恢復原先部署的架構,重新用原先的 consumer 機器來消費訊息,
- MQ中訊息失效:假設你用的是 RabbitMQ,RabbtiMQ 是可以設定過期時間的,也就是 TTL,如果訊息在 queue 中積壓超過一定的時間就會被 RabbitMQ 給清理掉,這個資料就沒了,那這就是第二個坑了,這就不是說資料會大量積壓在 mq 里,而是大量的資料會直接搞丟,我們可以采取一個方案,就是批量重導,這個我們之前線上也有類似的場景干過,就是大量積壓的時候,我們當時就直接丟棄資料了,然后等過了高峰期以后,比如大家一起喝咖啡熬夜到晚上12點以后,用戶都睡覺了,這個時候我們就開始寫程式,將丟失的那批資料,寫個臨時程式,一點一點的查出來,然后重新灌入 mq 里面去,把白天丟的資料給他補回來,也只能是這樣了,假設 1 萬個訂單積壓在 mq 里面,沒有處理,其中 1000 個訂單都丟了,你只能手動寫程式把那 1000 個訂單給查出來,手動發到 mq 里去再補一次,
- mq訊息佇列塊滿了:如果訊息積壓在 mq 里,你很長時間都沒有處理掉,此時導致 mq 都快寫滿了,咋辦?這個還有別的辦法嗎?沒有,誰讓你第一個方案執行的太慢了,你臨時寫程式,接入資料來消費,消費一個丟棄一個,都不要了,快速消費掉所有的訊息,然后走第二個方案,到了晚上再補資料吧,
18、設計MQ思路
- 比如說這個訊息佇列系統,我們從以下幾個角度來考慮一下;
- 首先這個 mq 得支持可伸縮性,就是需要的時候快速擴容,就可以增加吞吐量和容量,那怎么搞?設計個分布式的系統,參照一下 kafka 的設計理念,broker -> topic -> partition,每個partition 放一個機器,就存一部分資料,如果現在資源不夠了,給 topic 增加partition,然后做資料遷移,增加機器,不就可以存放更多資料,提供更高的吞吐量了?
- 其次你得考慮一下這個 mq 的資料要不要落地磁盤吧?那肯定要了,落磁盤才能保證別行程掛了資料就丟了,那落磁盤的時候怎么落啊?順序寫,這樣就沒有磁盤隨機讀寫的尋址開銷,磁盤順序讀寫的性能是很高的,這就是 kafka 的思路,
- 其次你考慮一下你的 mq 的可用性啊?這個事兒,具體參考之前可用性那個環節講解的 kafka 的高可用保障機制,多副本 -> leader & follower -> broker 掛了重新選舉 leader 即可對外服務,
19、RocketMq有什么功能?
1、業務解耦:這也是發布訂閱的訊息模型,生產者發送指令到MQ中,然后下游訂閱這類指令的消費者會收到這個指令執行相應的邏輯,整個程序與具體業務無關,抽象成了一個發送指令,存盤指令,消費指令的程序, 2、前端削峰:前端發起的請求在短時間內太多后端無法處理,可以堆積在MQ中,后端按照一定的順序處理,秒殺系統就是這么實作的, 3、億級訊息的堆積能力,單個佇列中的百萬級訊息的累積容量, 4、高可用性:Broker服務器支持多Master多Slave的同步雙寫以及Master多Slave的異步復制模式,其中同步雙寫可保證訊息不丟失, 5、高可靠性:生產者將訊息發送到Broker端有三種方式,同步、異步和單向,其中同步和異步都可以保證訊息成功的成功發送,Broker在對于訊息刷盤有兩種策略:同步刷盤和異步刷盤,其中同步刷盤可以保證訊息成功的存盤到磁盤中,消費者的消費模式也有集群消費和廣播消費兩種,默認集群消費,如果集群模式中消費者掛了,一個組里的其他消費者會接替其消費,綜上所述,是高可靠的, 6、支持分布式事務訊息:這里是采用半訊息確認和訊息回查機制來保證分布式事務訊息的, 7、支持訊息過濾:建議采用消費者業務端的tag過濾, 8、支持順序訊息:訊息在Broker中是采用佇列的FIFO模式存盤的,也就是發送是順序的,只要保證消費的順序性即可, 9、支持定時訊息和延遲訊息:Broker中由定時訊息的機制,訊息發送到Broker中,不會立即被Consumer消費,會等到一定的時間才被消費,延遲訊息也是一樣,延遲一定時間之后才會被Consumer消費,20、RoctetMq的架構
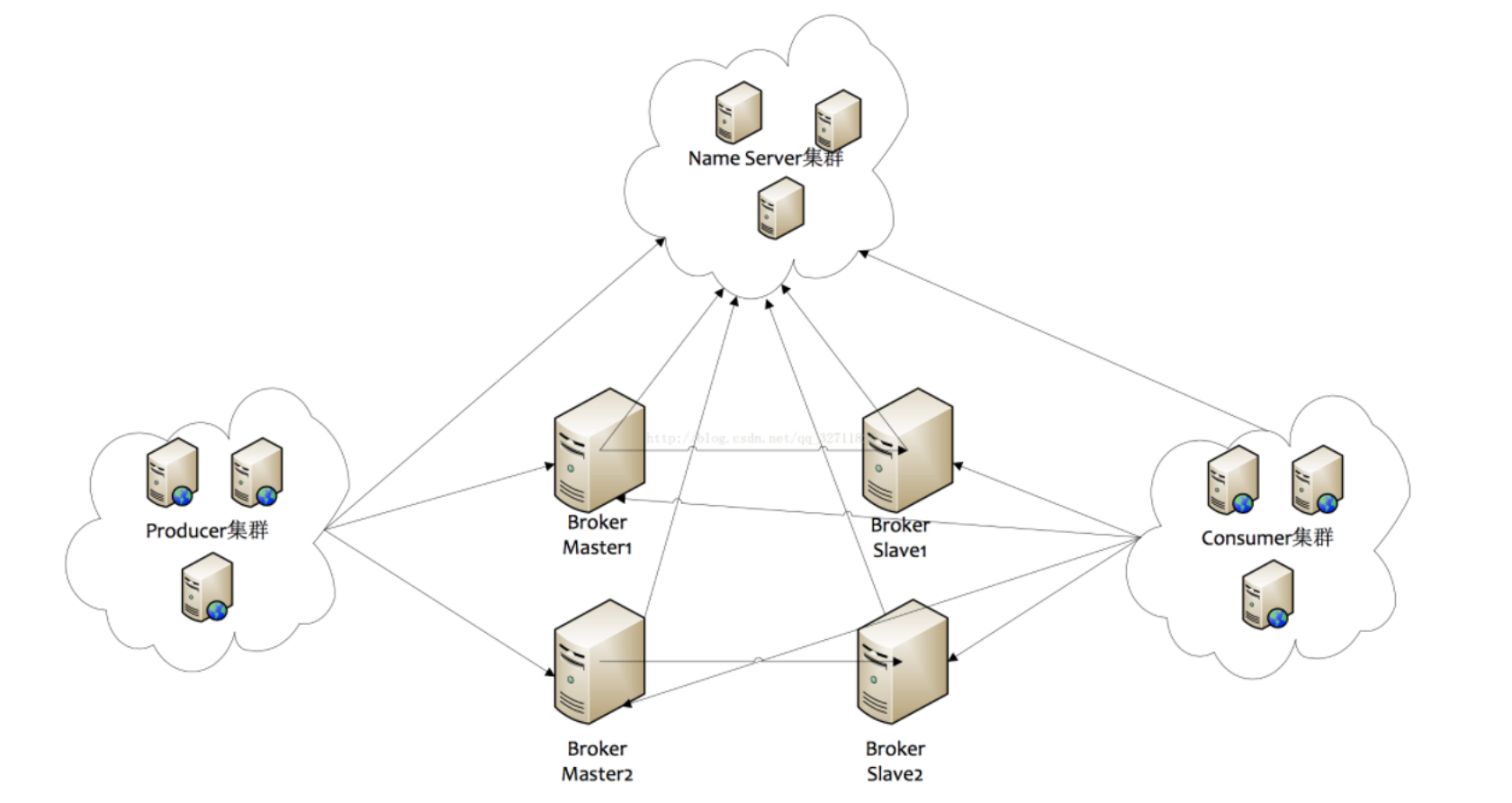 RocketMq一共有四個部分組成:NameServer,Broker,Producer生產者,Consumer消費者,每一部分都是集群部署的,
RocketMq一共有四個部分組成:NameServer,Broker,Producer生產者,Consumer消費者,每一部分都是集群部署的,
NameServer
NameServer是一個無狀態的服務器,角色類似于Dubbo的Zookeeper,但比Zookeeper更輕量, 特點:- 每個NameServer結點之間是相互獨立,彼此沒有任何資訊互動,
- Nameserver被設計成幾乎是無狀態的,通過部署多個結點來標識自己是一個偽集群,Producer在發送訊息前從NameServer中獲取Topic的路由資訊也就是發往哪個Broker,Consumer也會定時從NameServer獲取topic的路由資訊,Broker在啟動時會向NameServer注冊,并定時進行心跳連接,且定時同步維護的Topic到NameServer,
- 1、跟Broker結點保持長連接,
- 2、維護Topic的路由資訊,
Broker
訊息存盤和中轉角色,負責存盤和轉發訊息,- Broker內部維護著一個個Message Queue,用來存盤訊息的索引,真正存盤訊息的地方是CommitLog(日志檔案),
- 單個Broker與所有的Nameserver保持著長連接和心跳,并會定時將Topic資訊同步到NameServer,和NameServer的通信底層是通過Netty實作的,
Producer
訊息生產者,業務端負責發送訊息,由用戶自行實作和分布式部署, Producer的負載均衡 Producer的負載均衡是由MQFaultStratege.selectOneMessageQueue()來實作的,這個方法就是隨機選擇一個要發送訊息的broker來達到負載均衡的效果,選擇的標準:盡量不選剛剛選過的broker,盡量不選發送上條訊息延遲過高或沒有回應的broker,也就是找到一個可用的broker, Producer發送的三種策略 Producer發送訊息有三種方式:同步、異步和單向- 同步:同步發送是指發送方發出資料后等待接收方發回回應后在發送下一個資料包,一般用于重要的訊息通知,如重要的通知郵件或者營銷短信等,
- 異步:異步發送是指發送方發出資料后不等接收方發回回應就發出下一個資料包,一般用于可能鏈路耗時較長而對回應時間比較敏感的場景,如視頻上傳后通知啟動轉碼服務,
- 單向:單向發送是指只負責發送訊息而不等待接收方發送回應且沒有回呼函式,適合那些耗時比較短且對可靠性要求不高的場景,例如日志收集,
Consumer
訊息消費者,負責消費訊息,由用戶自行實作并進行集群部署, 推拉消費模式- PULL:拉取型消費者主動從broker中拉取訊息消費,只要拉取到訊息,就會啟動消費程序,稱為主動型消費,
- PUSH:推送型消費者就是要注冊訊息的監聽器,監聽器是要用戶自行實作的,當訊息達到broker服務器后,會觸發監聽器拉取訊息,然后啟動消費程序,但是從實際上看還是從broker中拉取訊息,稱為被動消費型,
- 集群消費:broker中的一條訊息會發送給訂閱這個topic的一個消費組里的唯一一個消費者進行消費,如果這個消費者掛掉了,組里的其他消費者會接替它進行消費,
- 廣播消費:broker中的一條訊息會發送給訂閱這個topic的一個消費組里的每一個消費者進行消費,
- Consumer的負載均衡是指將MessageQueue中的訊息佇列分配到消費者組里的具體消費者,
- Consumer在啟動的時候會實體化rebalanceImpl,這個類負責消費端的負載均衡,通過rebalanceImpl呼叫allocateMesasgeQueueStratage.allocate()完成負載均衡,
- 每次有新的消費者加入到組中就會重新做一下分配,每10秒自動做一次負載均衡,
21、RocketMq訊息模型
Message
就是要傳輸的訊息,一個訊息必須有一個主題,一條訊息也可以有一個可選的Tag(標簽)和額外的鍵值對,可以用來設定一個業務的key,便于開發中在broker服務端查找訊息,Topic
主題,是訊息的第一級型別,每條訊息都有一個主題,就像信件郵寄的地址一樣,主題就是我們具體的業務,比如一個電商系統可以有訂單訊息,商品訊息,采購訊息,交易訊息等,Topic和生產者和消費者的關系非常松散,生產者和Topic可以是1對多,多對1或者多對多,消費者也是這樣,Tag
標簽,是訊息的第二級型別,可以作為某一類業務下面的二級業務區分,它的主要用途是在消費端的訊息過濾,比如采購訊息分為采購創建訊息,采購審核訊息,采購推送訊息,采購入庫訊息,采購作廢訊息等,這些訊息是同一Topic和不同的Tag,當消費端只需要采購入庫訊息時就可以用Tag來實作過濾,不是采購入庫訊息的tag就不處理,Group
組,可分為ProducerGroup生產者組合ConsumerGroup消費者組,一個組可以訂閱多個Topic,一般來說,某一類相同業務的生產者和消費者放在一個組里,Message Queue
訊息佇列,一個Topic可以劃分成多個訊息佇列,Topic只是個邏輯上的概念,訊息佇列是訊息的物理管理單位,當發送訊息的時候,Broker會輪詢包含該Topic的所有訊息佇列,然后將訊息發出去,有了訊息佇列,可以使得訊息的存盤可以分布式集群化,具有了水平的擴展能力,offset
是指訊息佇列中的offffset,可以認為就是下標,訊息佇列可看做陣列,offffset是java long型,64位,理論上100年不會溢位,所以可以認為訊息佇列是一個長度無限的資料結構,22、如何保證順序訊息?
- 順序由producer發送到broker的訊息佇列是滿足FIFO的,所以發送是順序的,單個queue里的訊息是順序的,多個Queue同時消費是無法絕對保證訊息的有序性的,所以,同一個topic,同一個queue,發訊息的時候一個執行緒發送訊息,消費的時候一個執行緒去消費一個queue里的訊息,
- 追問:怎么保證訊息發到同一個queue里?RocketMQ給我們提供了MessageQueueSelector介面,可以重寫里面的介面,實作自己的演算法,比如判斷i%2==0,那就發送訊息到queue1否則發送到queue2,
23、如何實作訊息過濾?
- 有兩種方案,一種是在broker端按照Consumer的去重邏輯進行過濾,這樣做的好處是避免了無用的訊息傳輸到Consumer端,缺點是加重了Broker的負擔,實作起來相對復雜,
- 另一種是在Consumer端過濾,比如按照訊息設定的tag去重,這樣的好處是實作起來簡單,缺點是有大量無用的訊息到達了Consumer端只能丟棄不處理,
24、如何實作訊息去重?
- 如果由于網路等原因,多條重復訊息投遞到了Consumer端,你怎么進行訊息去重?
- 這個得先說下訊息的冪等性原則:就是用戶對于同一種操作發起的多次請求的結果是一樣的,不會因為操作了多次就產生不一樣的結果,只要保持冪等性,不管來多少條訊息,最后處理結果都一樣,需要Consumer端自行實作,
- 去重的方案:因為每個訊息都有一個MessageId, 保證每個訊息都有一個唯一鍵,可以是資料庫的主鍵或者唯一約束,也可以是Redis快取中的鍵,當消費一條訊息前,先檢查資料庫或快取中是否存在這個唯一鍵,如果存在就不再處理這條訊息,如果消費成功,要保證這個唯一鍵插入到去重表中,
25、分布式事務訊息?
- 你知道半訊息嗎?RocketMQ是怎么實作分布式事務訊息的?
- 半訊息:是指暫時還不能被Consumer消費的訊息,Producer成功發送到broker端的訊息,但是此訊息被標記為“暫不可投遞”狀態,只有等Producer端執行完本地事務后經過二次確認了之后,Consumer才能消費此條訊息,
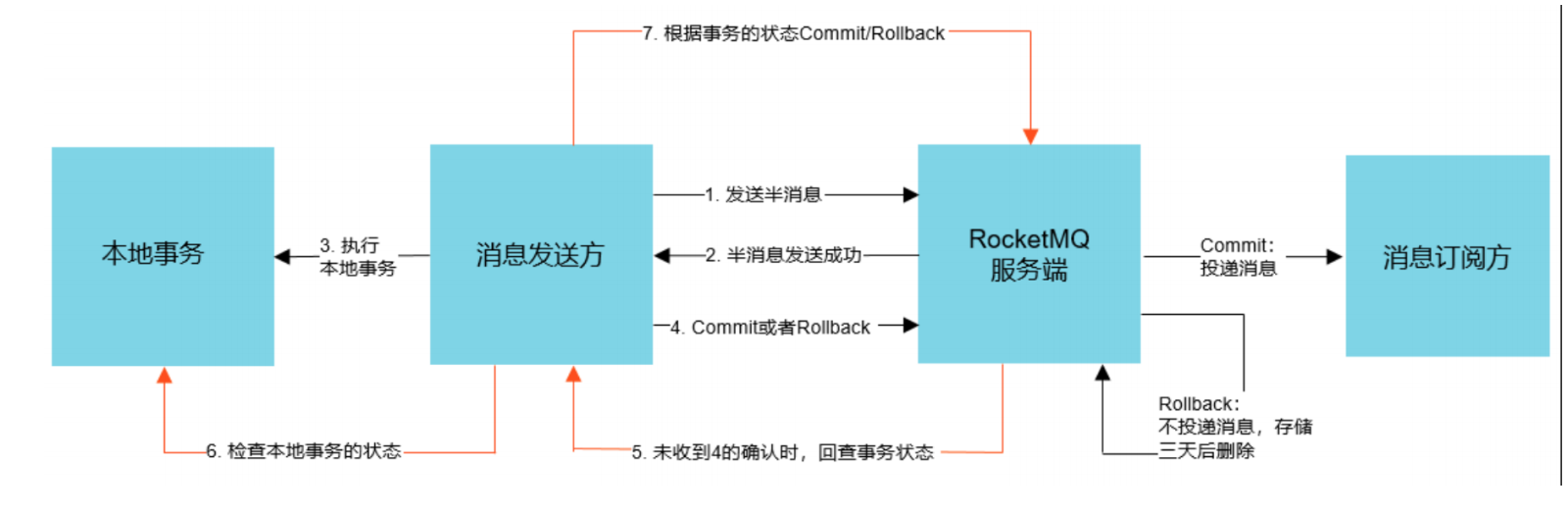
26、訊息的可用性?
RocketMQ如何能保證訊息的可用性/可靠性?(這個問題的另一種問法:如何保證訊息不丟失)要從Producer,Consumer和Broker三個方面來回答, 從Producer角度分析,如何確保訊息成功發送到了Broker?- 1、可以采用同步發送,即發送一條資料等到接受者回傳回應之后再發送下一個資料包,如果回傳回應OK,表示訊息成功發送到了broker,狀態超時或者失敗都會觸發二次重試,
- 2、可以采用分布式事務訊息的投遞方式,
- 3、如果一條訊息發送之后超時,也可以通過查詢日志的API,來檢查是否在Broker存盤成功,總的來說,Producer還是采用同步發送來保證的,
- 1、訊息只要持久化到CommitLog(日志檔案)中,即使Broker宕機,未消費的訊息也能重新恢復再消費,
- 2、Broker的刷盤機制:同步刷盤和異步刷盤,不管哪種刷盤都可以保證訊息一定存盤在pagecache中(記憶體中),但是同步刷盤更可靠,它是Producer發送訊息后等資料持久化到磁盤之后再回傳回應給Producer,
- 3、Broker支持多Master多Slave同步雙寫和多Master多Slave異步復制模式,訊息都是發送給Master主機,但是消費既可以從Master消費,也可以從Slave消費,同步雙寫模式可以保證即使Master宕機,訊息肯定在Slave中有備份,保證了訊息不會丟失,
25、刷盤實作
RocketMQ提供了兩種刷盤策略:同步刷盤 和 異步刷盤- 同步刷盤:在訊息達到Broker的記憶體之后,必須刷到commitLog日志檔案中才算成功,然后回傳Producer資料已經發送成功,
- 異步刷盤:異步刷盤是指訊息達到Broker記憶體后就回傳Producer資料已經發送成功,會喚醒一個執行緒去將資料持久化到CommitLog日志檔案中,
- 優缺點分析:同步刷盤保證了訊息不丟失,但是回應時間相對異步刷盤要多出10%左右,適用于對訊息可靠性要求比較高的場景,異步刷盤的吞吐量比較高,RT小,但是如果broker斷電了記憶體中的部分資料會丟失,適用于對吞吐量要求比較高的場景,
昔我往矣
楊柳依依
今我來思
雨雪霏霏
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/535975.html
標籤:Java
上一篇:day03-實作02