一、背景介紹
你好,我是 @馬哥python說 ,一名10年程式猿,
1.1 老版本
之前我開發過一個百度搜索的python爬蟲代碼,具體如下:
【python爬蟲案例】用python爬取百度的搜索結果!
這個爬蟲代碼自發布以來,受到了眾多小伙伴的關注:
?
但是,很多不懂python編程的小伙伴無法使用它,非常痛苦!
于是,我把這個程式封裝成了一個桌面軟體(exe檔案),無需python運行環境也可以使用,
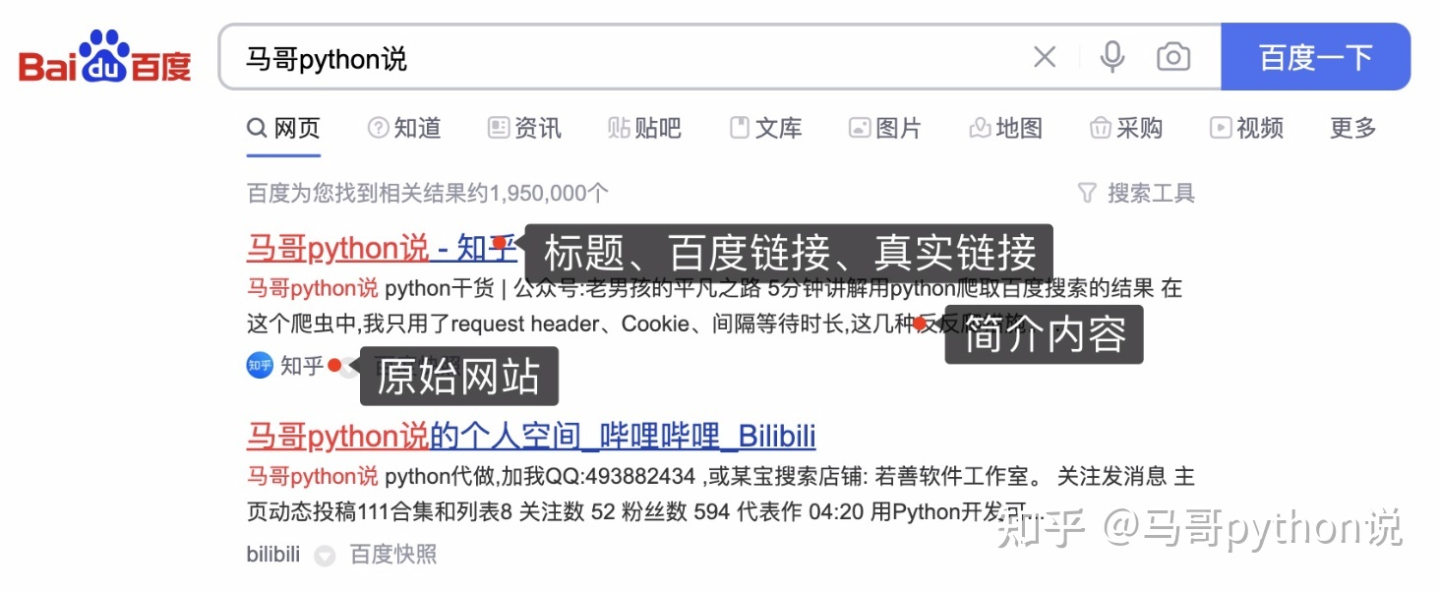
1.2 爬取目標
?
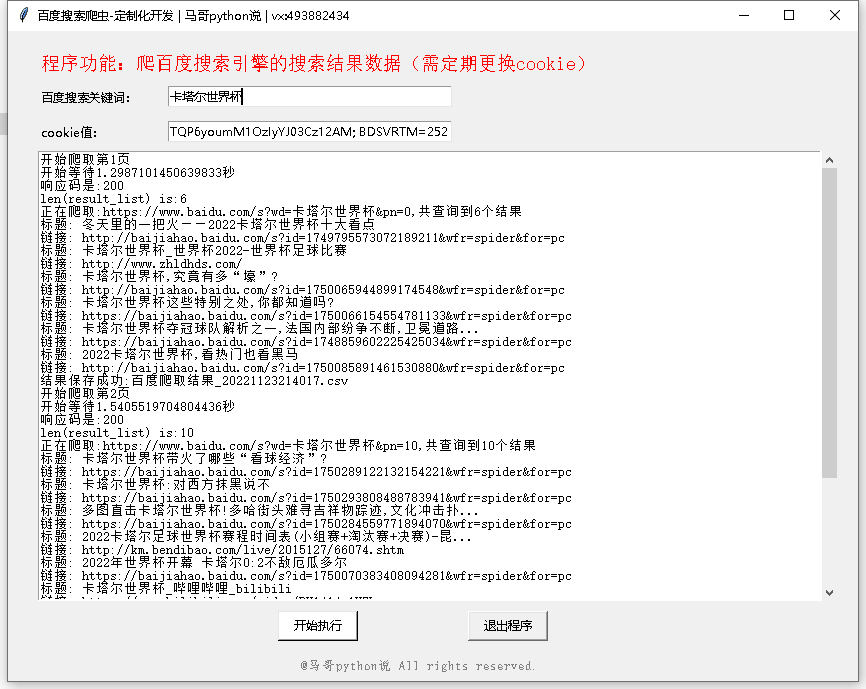
1.3 軟體運行截圖
?
1.4 爬取資料
?
1.5 實作思路
通過python爬蟲技術,爬取百度搜索結果資料,包含欄位:
頁碼、標題、百度鏈接、真實鏈接、簡介、網站名稱,
并把原始碼封裝成exe檔案,方便沒有python環境,或者不懂技術的人使用它,
二、代碼講解
2.1 爬蟲
首先,匯入需要用到的庫:
import requests # 發送請求
from bs4 import BeautifulSoup # 決議頁面
import pandas as pd # 存入csv資料
import os # 判斷檔案存在
from time import sleep # 等待間隔
import random # 隨機
import re # 用正則運算式提取url
定義一個請求頭:
# 偽裝瀏覽器請求頭
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"Connection": "keep-alive",
"Accept-Encoding": "gzip, deflate, br",
"Host": "www.baidu.com",
# 需要更換Cookie
"Cookie": "換成自己的cookie"
}
Cookie是個關鍵,如果不加Cookie,回應碼可能不是200,獲取不到資料,而且Cookie值是有有效期的,需要定期更換,如果發現回傳無資料或回應碼非200,嘗試替換最新的Cookie,
怎么獲取到Cookie呢?打開Chrome瀏覽器,訪問百度頁面,按F12進入開發者模式:
?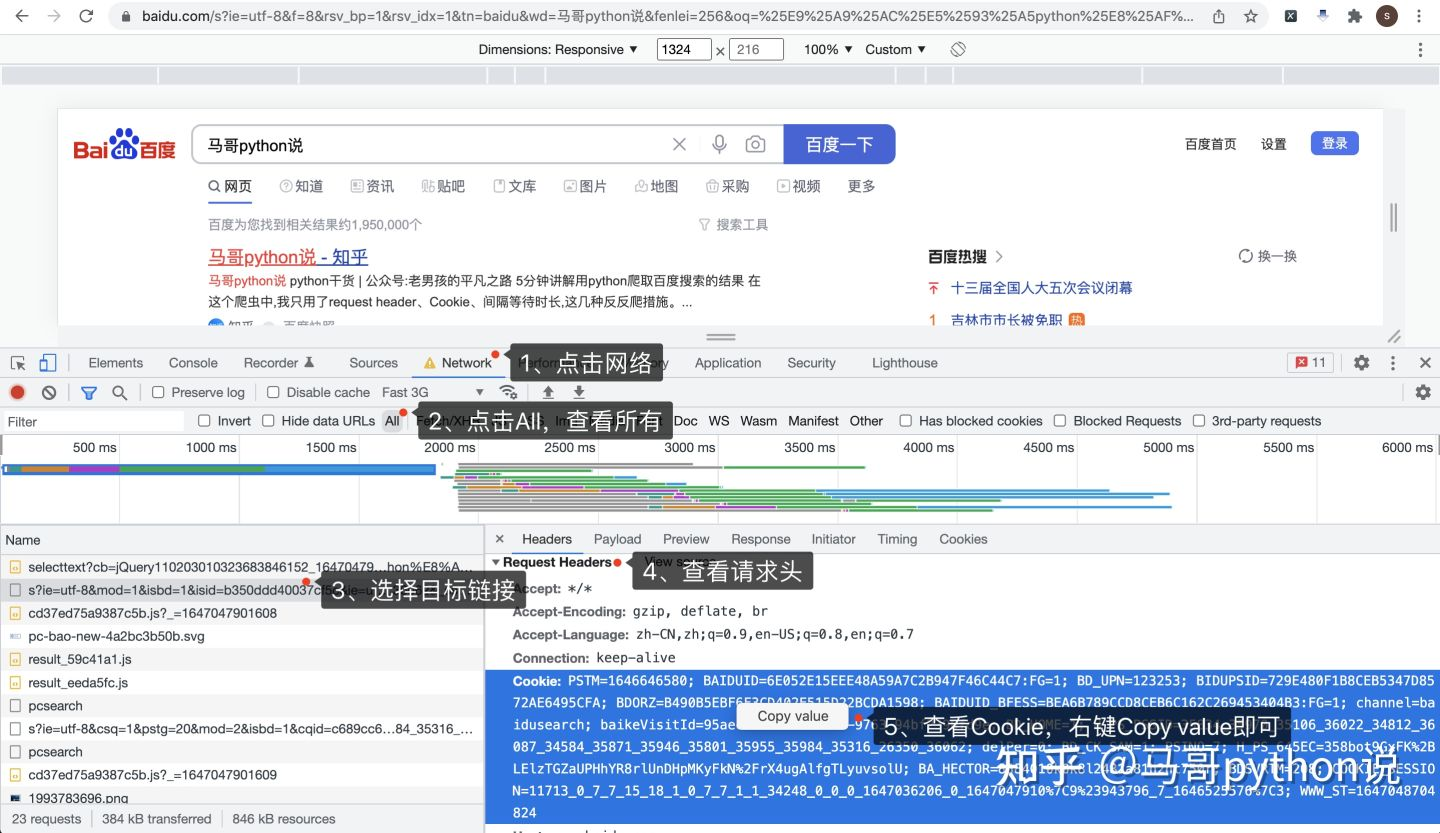
按照圖示順序,依次:
- 點擊Network,進入網路頁
- 點擊All,查看所有網路請求
- 選擇目標鏈接,和地址欄里的地址一致
- 查看Request Headers請求頭
- 查看請求頭里的Cookie,直接右鍵,Copy value,粘貼到代碼里
然后,分析頁面請求地址:
?
wd=后面是搜索關鍵字"馬哥python說",pn=后面是10(規律:第一頁是0,第二頁是10,第三頁是20,以此類推),其他URL引數可以忽略,
然后,分析頁面元素,以搜索結果標題為例:
?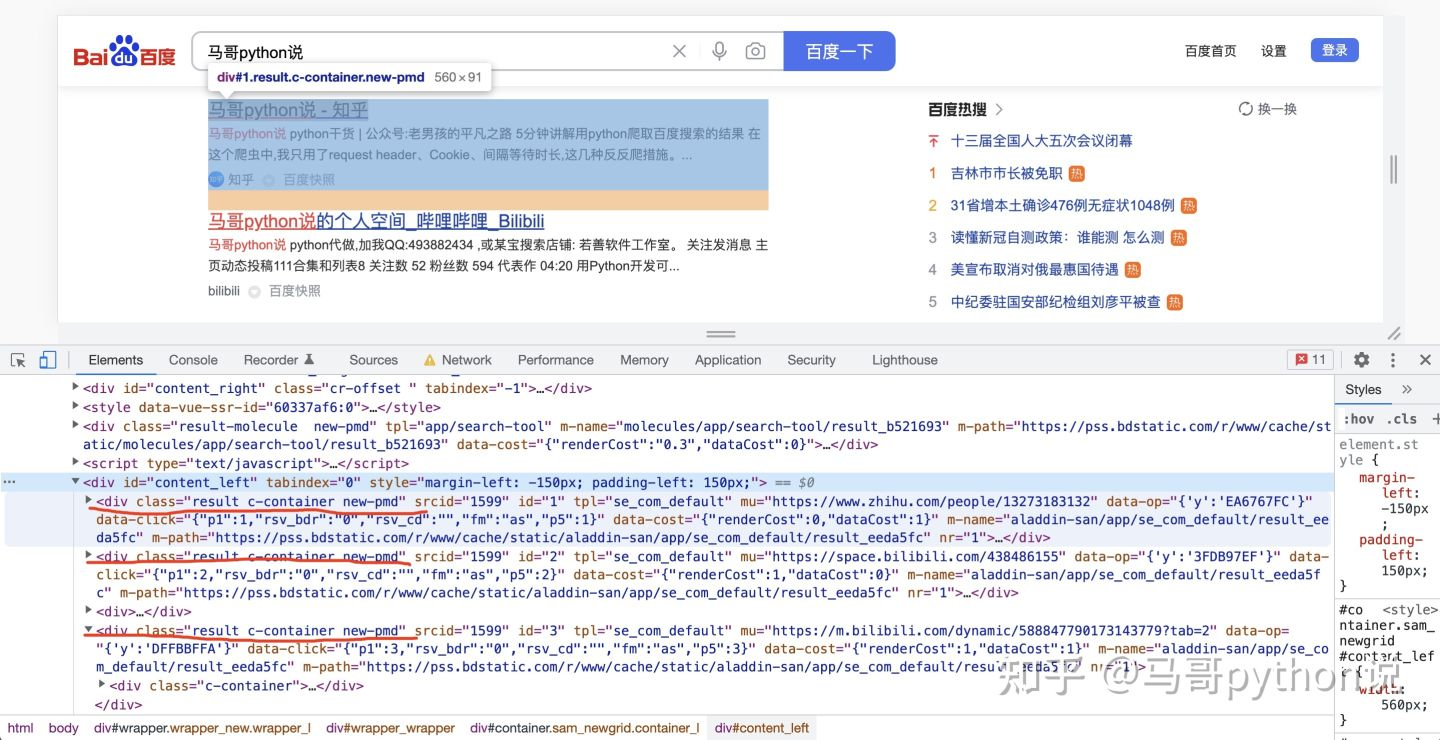
每一條搜索結果,都是,下層結構里有簡介、鏈接等內容,決議內部子元素不再贅述,
所以根據這個邏輯,開發爬蟲代碼,
# 獲得每頁搜索結果
for page in range(v_max_page):
print('開始爬取第{}頁'.format(page + 1))
wait_seconds = random.uniform(1, 2) # 等待時長秒
print('開始等待{}秒'.format(wait_seconds))
sleep(wait_seconds) # 隨機等待
url = 'https://www.baidu.com/s?wd=' + v_keyword + '&pn=' + str(page * 10)
r = requests.get(url, headers=headers)
html = r.text
print('回應碼是:{}'.format(r.status_code))
soup = BeautifulSoup(html, 'html.parser')
result_list = soup.find_all(class_='result c-container new-pmd')
print('正在爬取:{},共查詢到{}個結果'.format(url, len(result_list)))
其中,獲取到的標題鏈接,一般是這種結構:
http://www.baidu.com/link?url=7sxpKz_qoESU5b1BHZThKRAnXxPngB5kx1nZdUBCaXh7a4BgUgx9Zz-IqpeqDZTOIjvfY0u6ebnJdVWIfm5Tz_
這顯然是百度的一個跳轉前的地址,不是目標地址,怎么獲取它背后的真實地址呢?
向這個跳轉前地址,發送一個請求,然后邏輯處理下:
def get_real_url(v_url):
"""
獲取百度鏈接真實地址
:param v_url: 百度鏈接地址
:return: 真實地址
"""
r = requests.get(v_url, headers=headers, allow_redirects=False) # 不允許重定向
if r.status_code == 302: # 如果回傳302,就從回應頭獲取真實地址
real_url = r.headers.get('Location')
else: # 否則從回傳內容中用正則運算式提取出來真實地址
real_url = re.findall("URL='(.*?)'", r.text)[0]
print('real_url is:', real_url)
return real_url
如果回應碼是302,就從回應頭中的Location引數獲取真實地址,
如果是其他回應碼,就從回應內容中用正則運算式提取出URL真實地址,
把爬取到的資料,保存到csv檔案:
df = pd.DataFrame(
{
'關鍵詞': kw_list,
'頁碼': page_list,
'標題': title_list,
'百度鏈接': href_list,
'真實鏈接': real_url_list,
'簡介': desc_list,
'網站名稱': site_list,
}
)
if os.path.exists(v_result_file):
header = None
else:
header = ['關鍵詞', '頁碼', '標題', '百度鏈接', '真實鏈接', '簡介', '網站名稱'] # csv檔案標頭
df.to_csv(v_result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
print('結果保存成功:{}'.format(v_result_file))
to_csv的時候需加上選項(encoding='utf_8_sig'),否則存入資料會產生亂碼,尤其是windows用戶!
2.2 軟體界面
界面部分代碼:
# 創建主視窗
root = tk.Tk()
root.title('百度搜索爬蟲-定制化開發 | 馬哥python說')
# 設定視窗大小
root.minsize(width=850, height=650)
show_list_Frame = tk.Frame(width=800, height=450) # 創建<訊息串列磁區>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=120, anchor='nw') # 擺放位置
# 滾動條
scroll = tk.Scrollbar(show_list_Frame)
# 放到Y軸豎直方向
scroll.pack(side=tk.RIGHT, fill=tk.Y)
2.3 日志模塊
軟體運行程序中,會在同級目錄下生成logs檔案夾,檔案夾內會出現log檔案,記錄下軟體在整個運行程序中的日志,方便長時間運行、無人值守,出現問題后的debug,
部分核心代碼:
class Log_week():
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志級別
self.logger.setLevel(logging.DEBUG)
# 控制臺日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志檔案名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 將其保存到特定目錄,ap方法就是尋找專案根目錄,該方法博主前期已經寫好,
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
self.logger.addHandler(sh)
sh.setFormatter(log_formatter)
self.logger.addHandler(info_handler)
info_handler.setFormatter(log_formatter)
return self.logger
三、軟體運行演示
演示視頻:
【爬蟲GUI演示】用python爬百度搜索,并開發成exe桌面軟體!
?
我是 @馬哥python說,持續分享python干貨!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/538311.html
標籤:其他
上一篇:記一次博客園隨筆被爬經歷