python網路爬蟲和資訊提取
《python網路爬蟲和資訊提取》是北京理工大學的一門網路課程(中國大學MOOC(慕課)),
偶然機會我在網上學習了這門課程,中國大學排名是老師在課程里舉的一個例子,作為一個認真學習的python菜鳥,我把老師的代碼認真敲打出來,一運行卻出現問題,
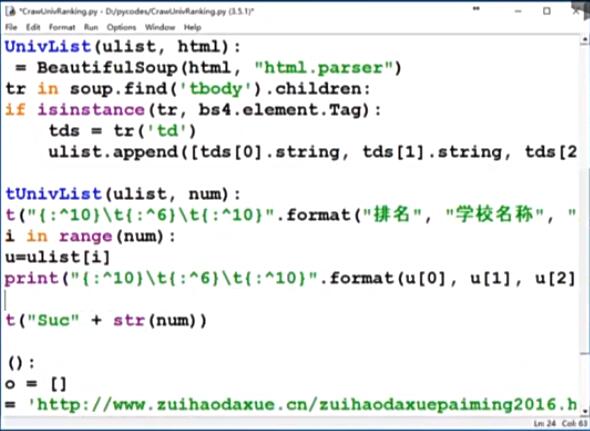
是老師的代碼有問題么?我把網址輸入瀏覽器,卻打不開,搜索了一下,發現幾年后的今天,原網站進行了升級,從域名到網站結構,都發生了翻天覆地的變化,原代碼當然不適用了,但在網上搜索,還能看到原封不動照搬老師代碼的所謂學習心得,誤人不淺,故把自己真正的學習心得放到這里,供和我一樣的菜鳥參考,
首先打開網頁對應清華大學排名源代碼部分,對相關標簽進行分析,

經過分析發現,名次1是tds[0],校名“清華大學”卻并不是單獨的tds[1],而是和英文校名、雙一流/211一起,都屬tds[1],在原代碼tds[1].string基礎上修改為:
tds[1]('a')[0].string,tds[1]('a')[1].string,tds[1]('p')[0].string,分別提取出了校名、英文校名、雙一流/211等資訊,但不知為什么,用tds[2].string,tds[3].string沒能正常提取出省市(北京)、類別(綜合)的資訊,仍顯示為None,用tds[4].string可以正常提取總分(999.4)資訊,請高手們指正,
修改后的代碼為:
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
print(r.request.url)
r.encoding = r.apparent_encoding
print(r.text[:1000])
return r.text
except:
# return ""
print('網頁抓取失敗!')
def fillUnivList(ulist,html):
soup = BeautifulSoup(html, "html.parser")
# print('title=',soup.title)
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td') # 串列形式
# print('tds=',tds)
ulist.append([tds[0].string,tds[1]('a')[0].string,tds[1]('a')[1].string,tds[1]('p')[0].string,tds[2].string,tds[3].string,tds[4].string])
# print('title=', soup.title)
print('省市=',tds[2].string)
# print('校名2=', tds[1]('a')[0].string)
print('ulist=',ulist)
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
# tplt = "{:^10}\t{:^6}\t{:^10}"
print(tplt.format("排名", "學校名稱", "總分", chr(12288)))
# print('%s\t\t%s\t\t%s' %("排名","學校名稱","總分"))
for i in range(num):
u = ulist[i]
# print('%s\t\t%s\t\t%s' %(u[0].strip('\n '),u[1],u[4].strip('\n '))) # 洗掉左邊的空格
print(tplt.format(u[0].strip('\n '),u[1],u[6].strip('\n '), chr(12288)))
def main():
url = 'https://www.shanghairanking.cn/rankings/bcur/2022.html'
uinfo = []
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20) # 20 univs
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/538338.html
標籤:Python
上一篇:函式式介面的案例詳解
下一篇:【驗證碼逆向專欄】安某客滑塊逆向