前言
本篇是c++總結的第二篇,關于c++的物件模型,在構造、拷貝虛函式上重點分析,也包含了c++11class的新用法和特性,如有不當,還請指教!
c++三大特性
- 訪問權限
? 在c++中通過public、protected、private三個關鍵字來控制成員變數和成員函式的訪問權限,它們分別表示為公有的、受保護的、私有的,稱為成員訪問限定符
? 在類的內部,無論成員被宣告為public、protected還是private,并沒有訪問權限的限制,都可以互相訪問;在類的外部,只能通過物件訪問成員,且只能訪問public權限的,不可訪問private、protected
? 無論繼承是public、private還是protected,base class的private成員都不能被derived class成員訪問,base class中的public和protected成員能被派生類訪問
? 對于public繼承,derived class物件只能訪問base class中的public成員;對于protected 和 private繼承,derived class不能訪問base class的所有成員,而derived class的成員可以通過derived class物件來訪問base class的derived成員
? private繼承意為"根據某物實作出",且private繼承只繼承實作,忽略介面,這純粹只是繼承了實作細節,也就是說它在軟體設計上沒有意義,意義在于軟體實作.若派生類需要訪問基類private的成員,或需要重新定義繼承而來的虛函式,則采用private繼承
class Base
{
public:
int num3;
protected:
int num1;
};
class derived : public Base
{
void func(Base&);
void func(derived&);
int num2;
};
void derived::func(Base& b) { b.num1 = 0; } //不合法
void derived::func(derived& d) //合法
{
d.num1 = 0;
d.num3 = num1;
}
- 繼承
定義:讓某類獲得另一個類的屬性和方法
功能:使用現有類的所有功能,并可以在無需重新撰寫原來的類的情況下對功能進行擴展
三種繼承方式:
- 實作繼承(非虛函式):使用基類的屬性和方法而無需額外撰寫
- 介面繼承(純虛函式):僅使用基類的屬性和方法的名稱,但子類須重新撰寫對應的方法
- 可視繼承(虛函式):子表單(類)使用基表單(類)的外觀和實作代碼的能力
- 封裝
定義:資料和代碼捆綁在一起,避免外界干擾和不確定性訪問
功能:將客觀事物封裝成抽象的類,且類可以把自己的資料和方法只讓可信的類或物件操作,對不可信的進行隱藏,比如public修飾公共的資料和方法,private修飾那些進行隱藏的資料和方法
c++對于結構體和函式(不包含virtual和non-inline)的封裝并沒有增加布局成本,在布局以及存取時間上主要的額外負擔是由virtual引起
- 多型
定義:一個public 基類的指標或參考,尋址出一個派生類物件
功能:允許將子型別別的指標賦值給父型別別的指標
實作多型的兩種方式:override和overload(c++常見關鍵字總結 - 愛莉希雅 - 博客園 (cnblogs.com))
c++用以下三種方法支持多型:
- 經由隱式轉化,將derived class指標型別轉化為public基型別別
- 經由虛函式機制
- 經由dynamic_cast和typeid運算子
? 虛函式:當基類希望派生類定義適合自己版本的函式,就將對應的函式宣告為虛函式
虛函式依靠虛函式表作業,表中保存虛函式地址,當用基類指標指向派生類時,虛表指標指向對應派生類的虛函式表,如此保證派生類中的虛函式被準確呼叫
虛函式是動態系結的 使用虛函式的指標和參考是去尋找目標類的對應函式,而不是執行類的函式,且發生在運行期,所對應的函式和屬性依賴于物件的動態型別
多型中,呼叫函式是通過指標或參考的,這個被呼叫的函式必須是虛函式且進行了重寫
同一個class的所有物件都使用同一個虛表
派生類的override虛函式的回傳型別和形參必須和父類完全一致,除非父類中回傳值為一個指標或參考,子類的回傳值可以回傳這個指標或參考的派生
? 那么虛函式機制是如何分辨指標型別的不同的呢?比如以下例子,指向A類的指標如何與指向int的指標或指向模板Array的指標有所不同呢?
A* px;
int* px;
Array<String>*pta;
首先,一個指標不管它指向哪個型別,它的大小是固定的,在記憶體需求來講,它們三個都需要有足夠的記憶體來放置一個機器地址(通常為word)
這三者之間的不同并不在表示法、地址,而是在其尋址出的物件型別不同,也就是說,指標型別會告訴編譯器如何解釋某個特定地址的記憶體內容及其大小
這引出一個問題void型別的指標如何解釋呢?答案是我們不知道將涵蓋多大的地址空間.這也說明了另一件事——一個void指標只能持有一個地址,而不能通過它來操作所指的object.轉換是一種編譯器指令,大部分情況并不改變一個指標所含的真正地址,只影響被指出的記憶體大小和內容
? 虛函式實體:
class A
{
public:
A();
virtual ~A();
virtual void Afunc();
protected:
int numA;
std::string strA;
};
class B : public A
{
public:
B();
~B();
void Afunc() override;
virtual void Bfunc();
int numB;
};
B b;
//兩個指標都指向B物件的起始地址,差別是pa涵蓋的地址只包含子物件A,而pb涵蓋整個B
A* pa = &b;
B* pb = &b;
pa->numB; //不合法
//顯式的downcast即可
(static_cast<B*>(pa) )->numB;
//以下方式更安全,但成本較高,是一個運行期運算子
if (B* pb2 = dynamic_cast<B*>(pa))
{
pb2->numB;
}
//以下pa的型別將在編譯期決定以下兩點
//1.固定的可用介面,pa只能呼叫A的public
//2.該介面的訪問級,此處函式為public
pa->Afunc();
//以下行為有兩個問題
//初始化將一個物件的內容完整拷貝到另一個物件去,為什么vptr沒有指向b的vtbl?因為編譯器必須確定如果某個物件含有一個及以上的vptrs,這些vptrs的內容不會被基類物件初始化或改變
//為什么a呼叫的Afunc函式的版本是A的?多型雖然"支持一個以上的型別",但不能在"直接存取物件"這方面做支持,因為面向物件并不支持對 物件的直接處理,且前面說過指標或參考支持多型是因為它們只是改變所指向的記憶體的"大小和內容解釋方式",并不改變物件記憶體大小
//這里以派生類物件對基類物件進行初始化或賦值,派生類物件會被切割塞進基類記憶體中,而派生類的型別并不其中,這會導致多型不再起作用
A a = b; //造成切割
a.Afunc();
? 純虛函式:將類定義為抽象類,不可實體化物件,純虛函式一般來說沒有定義體,但也可以有
形式:virtual 資料型別 函式名(形參) = 0;
? 抽象類:抽象類描述了類的行為和功能,而不需要完成類的實作
類中至少有一個函式被宣告為純虛函式,則此類就是抽象類
抽象類不可實體化,只能作為介面使用
虛基類最有效的運用方式是一個抽象基類,且沒有任何資料成員
c++的三種物件模型
class Point
{
public:
Point(float xval);
virtual ~Point();
float x() const;
static int PointCount();
protected:
virtual ostream& print( ostream & os ) const;
float _x;
static int _point_count;
}
對于以上封裝,c++通過三種物件模型來表示:
-
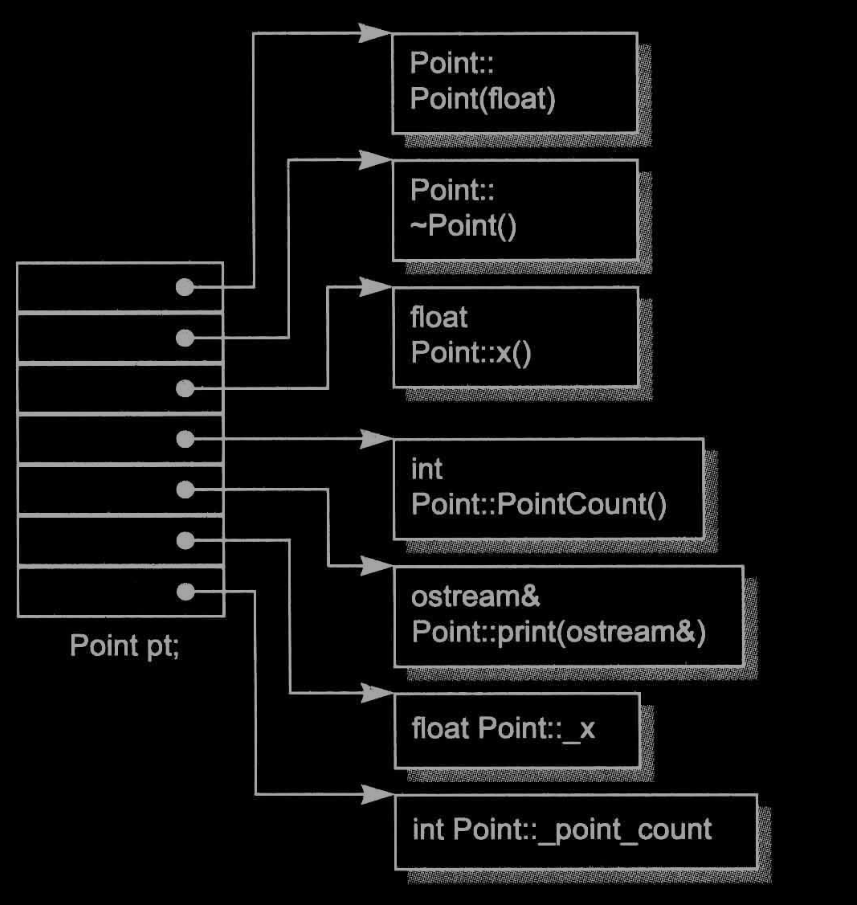
A Simple Object Model
一個物件包含一系列槽slots,每一個slots指向一個成員,各個成員按其宣告順序,各被指定一個slot,每一個資料成員和函式成員都有自己的一個slot
盡量減低C++ complier的設計復雜度,但會損失空間和執行器的效率
這個模型后來被應用到"指向成員的指標"觀念中
-
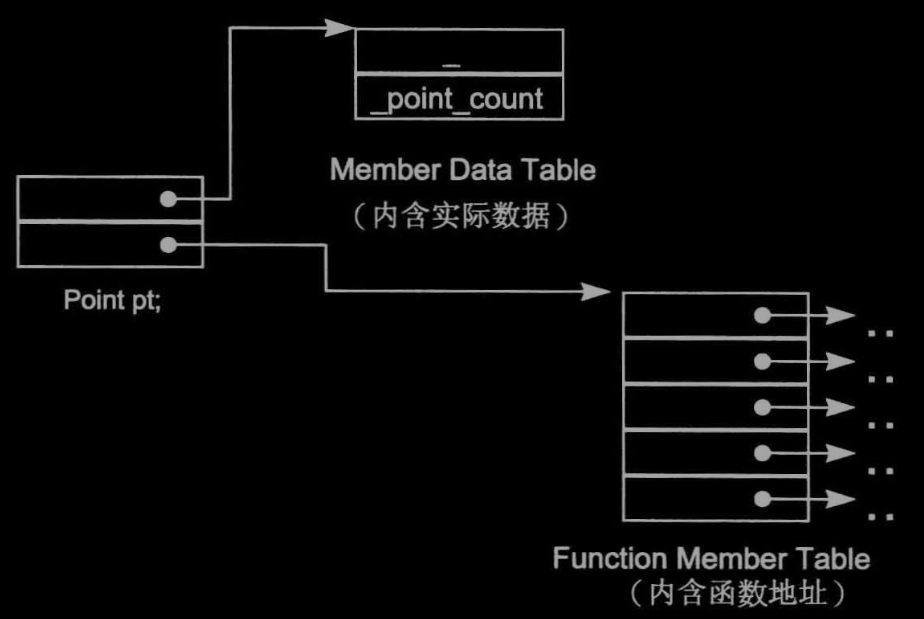
A Table-driven Object Model
將所有成員的資訊抽離出來放在一個 資料成員表 和一個 成員函式表 中,而class則含有指向這兩個表的指標
這個模型后來成為虛函式的一個方案
-
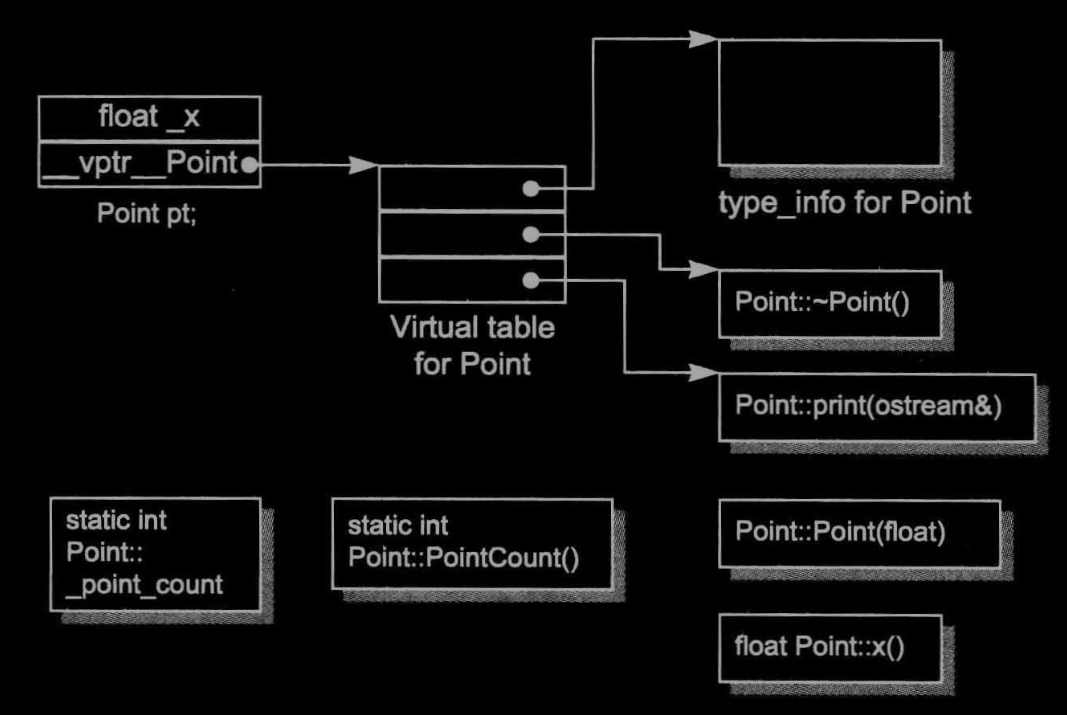
The C++ Object Model
Nonstatic 資料成員存放在于每一個class物件內,static資料成員、static成員函式、 nonstatic成員函式則被存放在class物件外,虛函式用兩個步驟來支持此model:
- 每個class生成指向虛函式的指標,其中一個指標對應一個虛函式,這些指標放在表格中,這個表格被稱為虛函式表virtual table(vtbl)
- 每個class物件中安插一個指標,這個指標指向相關的虛函式表,這個指標被稱為虛指標vptr,vptr的設定和重置都由class里的建構式、解構式、拷貝賦值運算子自動完成,每個class關聯的type_info object(支持runtime type identification,RTTI)亦由虛函式表指出,通常放于表格中的第一個slot
?
class和struct
? 在c中,資料與處理資料的操作(函式)是分開宣告的,struct是被看作一個結構體,其中包含多個變數或陣列,這些成員的資料型別可以不同;而在c++中,資料和處理資料的操作應該被視為一個整體,使用abstract data type(ADT)或class hierarchy的資料封裝,struct被看作一個類,其中包含資料和處理資料的方法,這是希望自定義型別更加健全
? 為什么struct看起來似乎和class并無太大區別?那是因為c++為了維護與c之間的兼容性,所以c++需要做到向下兼容,若非如此,c++完全可以摒棄struct,直接用關鍵字class支持類的觀念
? 那么什么時候應該用struct取代class呢?答案是你認為struct好則用struct,否則是class.struct和class并無太大區別,struct也可以支持public、protected、private,virtual以及單一繼承、多重繼承、虛擬繼承等等
//以下定義,你說他是struct或class都可以
{
public:
operator int();
virtual void foo();
//...
protected:
static int i;
//...
}
? class和struct的微小區別:
- 默認的訪問和繼承權限,class默認private,struct默認public,這很有道理,因為c中struct很明顯是公有的
- 模板并不打算和c兼容,因此模板中只能使用class作為型別別,使用struct代替class是不合法的
? c風格的struct在c++的一個合理的用法:傳遞復雜的class物件的全部或部分到c函式時,struct宣告可以將資料封裝起來,并保證擁有與c兼容的空間布局,不過只用在組合情況下
? class和struct的布局:c++對于結構體和函式(不包含virtual和non-inline)的封裝并沒有增加布局成本,主要的額外負擔是由virtual引起的(之前已用圖說明過)
現有如下片段:
typedef struct
{
float x, y, z;
}Point;
Point global;
Point foobar()
{
Point local;
Point* heap = new Point;
*heap = local;
delete heap;
return local;
}
對于Point這樣的宣告,在c++會被貼上Plain OI' Data標簽,編譯器并不會為其宣告default constrcutor、destructor、copy constructor、copy assignment operator
對于 Point global; 這樣的定義,在c++中members并沒有被定義或呼叫,行為和c如出一轍,編譯器并不會呼叫constructor和destructor,除非在c中,global被視作臨時性定義
臨時性定義:因為沒有顯示初始化操作,一個臨時性定義可以在程式多次發生,但編譯器最侄訓將這些實體鏈接折疊起來,只留下一個實體,放在data segment中"保留給未初始化的global object使用的"空間 但在c++中并不支持臨時性定義,對于此例,會阻止后續的定義
對于 Point* heap = new Point;編譯器并不會呼叫default constructor,只是 Point* heap = __new( sizeof(Point) ),delete亦是如此
對于*heap = local;編譯器并不會呼叫copy assignment operator做拷貝,但只是像c那樣做簡單的bitwise
return操作也是,只是簡單的bitwise,并沒有呼叫copy constructor
建構式
? 定義:類通過一個或多個特殊的成員函式來控制其物件的初始化程序,這些函式叫做建構式(constructor)
? 建構式名字和類名相同,但沒有回傳型別,除此以外和普通函式沒啥區別.建構式支持多載,并支持普通函式的多載規則,但建構式不可宣告為const,因為建構式任務是進行初始化,宣告為const無法修改
? 無論何時只要類的物件被創建,就會執行建構式
? 默認建構式:不用實參進行呼叫的建構式,這包含兩種情況:
- 沒有明顯的形參
- 提供默認實參
? 合成的默認建構式:當我們沒有定義建構式時,編譯器在需要建構式時,會合成默認建構式,這種合成的默認建構式執行滿足編譯器所需要的行動(不負責初始化資料成員),但為了程式繼續執行下去,編譯器有時候還是會初始化所需資料成員,若資料成員含有類內的初始值,則用此來初始化成員,否則默認初始化該成員
? "= default"要求編譯器合成默認建構式.若=default和宣告一起出現在類的內部,則合成的默認建構式是inline的;出現在類外部,則不是inline的
? 對于一個類,如果開發人員沒有宣告任何一個建構式,則會隱式宣告一個默認建構式,這種被隱式宣告出的建構式若不滿足后面所講的四種情況且又沒有宣告任何建構式的class,是沒有用的(trivial)建構式,那么什么是有用的(nontrivial)呢?一個有用的默認建構式是編譯器需要的那種,必要的話會由編譯器合成出來
? 在討論有用的默認建構式有哪些情況前,我們需要知道:在c++各個不同的編譯模塊(檔案)中,編譯器將合成的default constructor、copy constructor、destructor、assignment copy operator都用inline方式完成來避免合成多個default constructor;但若函式太復雜,用inline不合適,而是會合成出一個顯式的non-inline static實體
四種有用的nontrivial默認建構式
以下四種情況默認的建構式會被視為有用的:
帶有默認建構式的成員類物件
? 如果一個class沒有任何建構式,但其內含的成員物件擁有默認建構式,編譯器需要為該class合成默認建構式,不過這個合成操作只有在建構式真正需要被呼叫時才發生;不過若若類中包含一個其他型別別的成員且這個成員的型別沒有建構式,編譯器不會合成默認建構式,將無法初始化該成員,這種情況需要開發者自己定義建構式
例子:
//假設B包含A
class A
{
public:
A();
A(int);
//...
};
class B
{
public:
A a;
char* str;
//...
};
void func()
{
B b; //A::a必須在此初始化,合成的默認建構式內涵必要代碼,能夠呼叫A的默認建構式來處理成員物件B::a
if (str) //之前說過編譯器不負責初始化資料成員,但程式想要執行下去,編譯器在此處必須初始化str
{
//...
}
}
? 上面例子種合成的默認建構式可能是這個樣子:
inline B::B()
{
a.A::A();
}
? 在這個例子中如果開發者已經為class B顯示定義一個默認建構式,但這個建構式并沒有呼叫所需要的 物件的建構式,這時編譯器會在當前的默認建構式中進行擴張,在顯式的開發者定義的代碼前安插一些代碼,以滿足編譯器需求,如果有多個class成員物件,則按照這些成員物件在class中的宣告順序來呼叫對應的建構式,內部可能長這樣:
B::B() { str = 0;} //開發者定義的
//擴張后的默認建構式
B::B()
{
//編譯器定義的代碼
a.A::A();
//顯式的代碼
str = 0;
}
? 那如果顯式的定義了建構式而沒有默認建構式,還需要合成默認的建構式嘛?并不會,會根據編譯器要求擴張現有的建構式,并不會再合成默認的建構式
帶有默認建構式的基類
這種情況下有用的默認建構式道理和上面的類似,如果一個沒有建構式的類派生自一個有默認建構式的基類,那么此時派生類的默認建構式會被視為有用的并合成出來,這個建構式將上一層基類的默認建構式(根據他們的宣告順序)
帶有虛函式的類
? 以下兩種情況需合成默認建構式:
- class宣告或繼承一個虛函式
- class派生自一個繼承串鏈,其中有一個及以上的虛基類(virtual base classes)
例子:
//B和C派生自A
class A
{
public:
virtual void func() = 0;
//...
};
void callfunc(const A& a) { a.func(); }
void foo()
{
B b;
C c;
callfunc(b);
callfunc(c);
}
? 這里為了支持虛函式機制需要合成或對現有的建構式進行擴張,兩個擴張行動在編譯期發生:
- 一個虛函式表vtbl被編譯器產出,其中放置對應類的虛函式地址
- 每個類物件中,編譯器產出一個虛表指標vptr,內含相關的class的虛函式表的地址
? a.func()的虛擬呼叫會進行重寫,以支持虛函式機制
其中:
- 1表示虛函式表陣列的索引(在前面的第三種物件模型可以看到布局)
- 后面的引數其實就是this指標
//a.func()的轉變
( *a.vptr[1] )(&a)
? 對于建構式的合成規則也是遵循之前的,沒有則合成,有則在每個建構式中安插
帶有虛基類的class
? 對于每個class所定義的每一個建構式,編譯器會安插"允許每個虛基類的執行期存取操作"的代碼;若沒有宣告建構式,則編譯器為其合成一個默認建構式
? 不同的編譯器對虛基類的實作有極大的差異,但每種實作的思想都是必須使虛基類在其每個派生類中的位置能夠在運行期確定
先來看個例子:
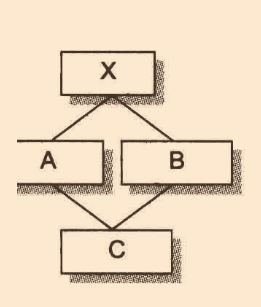
//菱形繼承
class X
{
public:
int nX;
};
class A : virtual public X
{
public:
int nA;
};
class B : virtual public X
{
public:
double nB;
};
class C : public A, public B
{
public:
int nK;
};
//無法在編譯期確定pa->X::nX的地址
void func( A* pa) { pa->nX = 1024; }
func(new A);
func(new C);
? 對于以上例子,編譯器無法固定經由pa存取的X::nx的實際偏移地址,因為虛擬派生類物件中的虛基類偏移位置是會隨著派生而變化的(詳細原因請移至虛擬繼承),編譯器必須改變執行存取操作的代碼,使X::nx可以延遲至運行期決定正確結果
? 在此我們提供cfront的做法:在派生類的每個虛基類中安插一個指標,所有經由指標或參考來存取一個虛基類的操作都可通過相關指標來完成
? 可能的轉變操作:
其中,__vbcX表示編譯器所產生的指標,指向所對應的虛基類
void func( A* pa) { pa->__vbcX->nX = 1024; }
成員初值列
? 我們知道由編譯器合成的建構式不負責初始化資料成員,因此我們應該確保每一個建構式都將物件的每個成員進行初始化,而這一保證通過成員初值列(member initialization list)來完成
? 別混淆賦值和初始化.對于建構式來說,類成員的初值可以通過member initialization list或在建構式體內進行賦值
//賦值
class A
{
public:
A(int _i, int _j)
{
i = _i;
j = _j;
}
private:
int i, j;
};
//成員初值列
A( int _i, int _j) : i(_i), j(_j) {}
對于將class中成員設定常量值,使用explicit initialization list更有效率,因為當函式的活動記錄(activation record)被放進堆疊,initialization list的常量即可放入local1記憶體中
注:活動記錄程序的呼叫是程序的一次活動,當程序陳述句(及其呼叫)結束后,活動生命周期結束,變數的生命周期為其從被定義后有效存在的時間
對于以下四種情況,為確保程式順利編譯,必須使用member initialization list:
- 初始化一個
參考成員時 - 初始化一個
const成員時 - 呼叫
基類的建構式,且這個建構式有一組引數時 - 呼叫
成員class的建構式,且此建構式有一組引數時
對于賦值,在這四種情況下,編譯的效率并不高;相反成員初值列更有效率
來看一個例子:
class Word
{
String _name;
int _cnt;
public:
Word()
{
_name = 0;
_cnt = 0;
}
};
//編譯器會在建構式中產生一個臨時性的String物件,然后再初始化,僅僅是提供給另一個物件進行拷貝賦值,最后會被摧毀
Word::Word()
{
_name.String::String();
String temp = String(0); //臨時物件
_name.String::operator=(temp);
temp.String::~String(); //摧毀臨時物件
_cnt = 0;
}
//成員初值列
Word::Word : _name(0), _cnt(0){}
//進行擴張
Word::Word()
{
_name.String::String();
_cnt = 0;
}
? member initialization list不是一組函式呼叫,編譯器按照成員在class中的宣告順序一一操作member initialization list,會在任何顯式的用戶代碼前以適當順序安插初始化操作,若不注意宣告順序,產生的bug很難觀察出來,因此盡量把一個成員的初始化和另一個放在一起
來看一個例子:
class A
{
int i;
int j;
public:
//i比j先宣告,因此是先初始化i再初始化j
A( int val ) : j(val), i(j) { }
}
//改善
A::A(int val) : j(val)
{
i = j;
}
? c++規定,物件的成員變數的初始化動作發生在進入建構式本體前,也就是這些成員的建構式被自動呼叫時,也就是說上面改善的方案,i == j并不會有問題(因為理論上是i先初始化)
你可能會問,在member initialization list中實參傳回函式的回傳值可以嗎?當然可以,但是最好是使用"存在建構式體內的一個成員",而非"member initialization list內的成員",因為你并不知道這個函式是否需要class的資料成員,所以將這種初始化放在構造體內就完全沒有問題
來看一個例子:
X::X(int val) : i( func(val) ), j(val) { } //萬一func需要資料成員q,而q的宣告順序在i之后
//擴張
X::X()
{
i = this->func(val);
j = val;
}
如果一個派生類成員函式被呼叫,不要將其回傳值做為基類建構式的一個引數
來看一個例子:
class AA : public A
{
int _AAval;
public:
int AAval() { return _AAval; } //派生類的成員函式
AA( int val ) : _AAval(val), A( AAval() ) { }
};
//擴張
AA()
{
A::A(this, this->AAval() ); //先構造基類,但需要資料成員,可是這個資料成員在后面進行初始化
_AAval = val;
}
explicit initialization list也有不足:
- class成員需要為public
- 只能指定常量,因為其常量在編譯器即可求值
- 編譯器并沒有自動施行它,初始化很可能失敗
編譯器對建構式的擴充
定義一個物件,編譯器會對于建構式進行如下擴充操作:
- 記錄在member initialization list的資料成員初始化會被放進建構式本體,以成員宣告順序為順序,若有一個成員沒有出現在member initialization list,但其有默認建構式,那么該default constructor必須被呼叫
- 在那之前,若class物件有virtual table pointers,其需指定初值
- 在那之前,所有上層的base class constructors必須被呼叫,以base class的宣告順序
- 若class被列于member initialization list,如果有任何顯示指定的引數,都應傳過去;若沒有列于list,而class有默認建構式,則呼叫之
- 若基類是多重繼承下的第二或后繼基類,那么this指標需調整
- 在那之前,所有的虛基類的建構式必須被呼叫,從左到右,從深到淺
- 若class被列于member initialization list,如果有任何顯示指定的引數,都應傳過去,若沒有列于list,而class有default constructor,則呼叫此
- 此外,class中的每個虛基類 subobject的offset必須在執行期可被存取
- 若 class物件是最底層的class,其建構式可能被呼叫;某些用以支持這一行為的機制必須被放進來
拒絕編譯器合成的默認函式
對于一個空類,編譯器會為我們自動合成默認的建構式、拷貝建構式、拷貝賦值運算子、解構式(非虛函式)
有時候我們想禁止一個class物件的拷貝操作,就需要進制拷貝建構式和拷貝復制運算子,問題是,不顯式宣告他們,編譯器可能會為我們自動合成一個默認的;但是想要避免編譯自動生成,又得自己定義一個,屬于是陷入惡性回圈了,那么如何解決這個問題呢?
有兩種解決方案:
-
將拷貝建構式、拷貝賦值運算子宣告為private屬性的函式,如此便不能呼叫這兩個函式
class A { public: A() = default; private: A( const A& ); A& operator=( const A& ); }其實這樣問題并沒有完全解決,因為A的其他成員函式和友元函式依舊可以呼叫private
-
定義一個基類專門阻止拷貝
class unA { protected: unA() {} ~unA() {} private: unA( const unA& ) {} unA& operator=( const unA& ) {} }; class A : private unA { public: A() = default; }現在,就算是A的成員函式或友元函式,也無法呼叫,編譯器的嘗試合成的動作將被基類阻止
別在構造程序呼叫虛函式
class A
{
public:
A();
virtual fFunc() const = 0;
//...
};
A::A()
{
fFunc();
}
class derivedA : public A
{
public:
virtual void fFunc() const;
}
//先構造基類
A a;
這個時候會先進行基類的構造,fFunc()的呼叫將是基類那個版本的,這就意味著我們多呼叫了一個函式,永遠不可能下降到當前這個子類的層級(因為父類構造先于子類,此時子類的成員并未初始化,若呼叫子類版本的虛函式,程式將報錯)
最根本的原因是子類物件在呼叫基類建構式期間,物件型別是基類而不是子類,不僅虛函式會使用基類版本,此時dynamic_cast和typeid也會將物件視為基型別別
令operator=回傳?個系結到*this的引?
也就是如下形式:
class A {
public:
...
A& operator=(const A& other) { ... return *this; }
}
//目的是為了連鎖賦值
int x, y, z;
x = y = z = 100;
//原理如下
x = (y = (z = 100))
也并非需要一定讓operator=回傳?個系結到*this的引?,不遵守這個規則代碼一樣可以通過,但是這樣效率更高,可以呼叫更少的構造和解構式
拷貝構造
? 拷貝建構式(copy constructor):在創建物件時,使用同一型別的class物件來初始化新創建的物件
拷貝建構式的形式,采用ClassName&(類的名稱)型別作為引數:
class A
{
public:
A( const A& );
}
? 以下三種情況會以一個類物件的內容作為另一個類物件的初值:
-
顯式地以一個類物件的內容作為另一個類物件的初值
class A { ... }; A a; A aa = a; -
物件被當作引數傳給某函式
void do( A a ); void do2() { A aa; func( aa ); } -
函式傳回類物件
A do2() { A a; return a; }
設計一個class,并以一個class object指定給另一個class object,我們有三種選擇:
- 什么都不做,實施默認行為
- 提供一個explicit 拷貝賦值運算子
- 顯示拒絕把class物件指定給另一個class物件,也就是將拷貝賦值運算子宣告為private,且不提供定義
只有在默認的memberwise copy行為不安全或不正確時,才需要設計一個拷貝賦值運算子,且如果class有bitwise copy,隱式的賦值運算子不會合成
class對于default copy assignment operator,在以下情況,不會表現bitwise copy:
- 當class 內含成員物件,而其class有一個拷貝賦值運算子
- 當class的基類有一個拷貝賦值運算子
- 當class宣告了任何虛函式,一定別拷貝右邊class物件的vptr地址,它很有可能是派生類物件
- 當class繼承自虛基類
即使賦值由bitwise copy完成,并沒有呼叫copy assignment operator,但還是需要提供一個copy constructor(編譯器合成的也算),以此打開NRV優化
盡可能不要允許一個虛基類的拷貝操作,不要在任何虛基類中宣告資料
對于單一繼承和多重繼承,若class使用bitwise copy,一般不會合成拷貝構造,就不會增加效率成本
對于虛擬繼承,bitwise copy不再支持,而是合成拷貝賦值運算子r和inline 拷貝構造,導致成本大大增加,且繼承體系復雜度增加,物件拷貝和構造的成本也會增加
memberwise initialization
? 若一個類未定義顯式的拷貝建構式,并一個類物件以另一個類物件作為初值時,其內部以default memberwise initialization(成員初始化)方式完成,也就是將每個內部的或派生的資料成員的值,從某個物件拷貝一份到另一個物件身上,不過并不會拷貝成員類物件,而是以遞回的方式施行memberwise initialization
? memberwise initialization有兩種方式:
- 展現bitwise copy semantics,進行位逐次拷貝
- 未展現bitwise copy semantics,編譯器合成默認的拷貝建構式,呼叫內部的類的拷貝建構式
當一個類未定義顯式的拷貝建構式,若類展現出"bitwise copy semantics",編譯器將不會合成默認的拷貝建構式;若未展現,則合成,也就是說,和建構式類似,是否合成默認的建構式也是看編譯器的需求
位逐次拷貝(bitwise copy semantics ):對 源類中的成員變數 中的每一位 都逐次 復制到 目標類中,編譯器只是直接將資料成員的地址拷貝過來,并不拷貝其值
class A
{
public:
A( const char* );
~A() { delete []str; }
//...
int cnt;
char* str;
};
//進行位逐次拷貝,不合成默認的建構式
A a2("c++");
A a1 = a2;
當然這種方式會導致一個問題,比如當前例子中的char*指標,會造成a1的指標和a2的指標指向同一記憶體地址,呼叫兩次解構式,必將報錯,因此對于這類情況,只有靠設計者實作一個顯式的拷貝建構式
那什么情況時沒有展現bitwise copy semantics呢?class含有另一個class,后面這個class定義了顯式的拷貝建構式
//將char*改為String
class A
{
public:
A( const std::String&);
//...
int cnt;
const std::String str;
};
//string宣告了顯式的拷貝建構式
class String
{
public:
String( const String& );
//...
}
//這個時候簡單的位逐次拷貝無法滿足編譯器需求,因為需要呼叫String的拷貝建構式,因此編譯器需要合成默認的拷貝建構式
A a2("c++");
A a1 = a2;
//合成的默認拷貝建構式
inline A::A( const A& a )
{
str.String::String( a.str );
cnt = a.cnt;
}
不展現bitwise copy semantics的四種情況
? 其實不展現"bitwise copy semantics"有四種情況:
-
class
內含一個成員物件,而后者的class宣告了一個拷貝構造時(無論是顯式的,還是編譯器合成的) -
class
繼承自一個基類而這個基類存在一個拷貝構造時(無論是顯式的,還是編譯器合成的)第一點和第二點在上面已經解釋過了
-
class宣告一個及以上的
虛函式若class含有虛函式,在建構式中會安插一個vtbl和一個vptr,呼叫拷貝建構式時需要正確的處理其初值,因此,當編譯器在class中匯入一個vptr時,某些情況下,bitwise copy semantics將不在生效
來看一個例子:
class ZooAnimal { public: ZooAnimal(); virtual ~ZooAnimal(); virtual void animate(); virtual void draw(); //... }; class Bear : public ZooAnimal { public: Bear(); void animate() override; void draw() override; virtual void dance(); //... }; Bear yogi; Bear winnie = yogi;在這里,
兩個型別相同,bitwise copy semantics依舊生效(動態轉換的指標除外),將yogi的vptr的賦值給winnie是安全的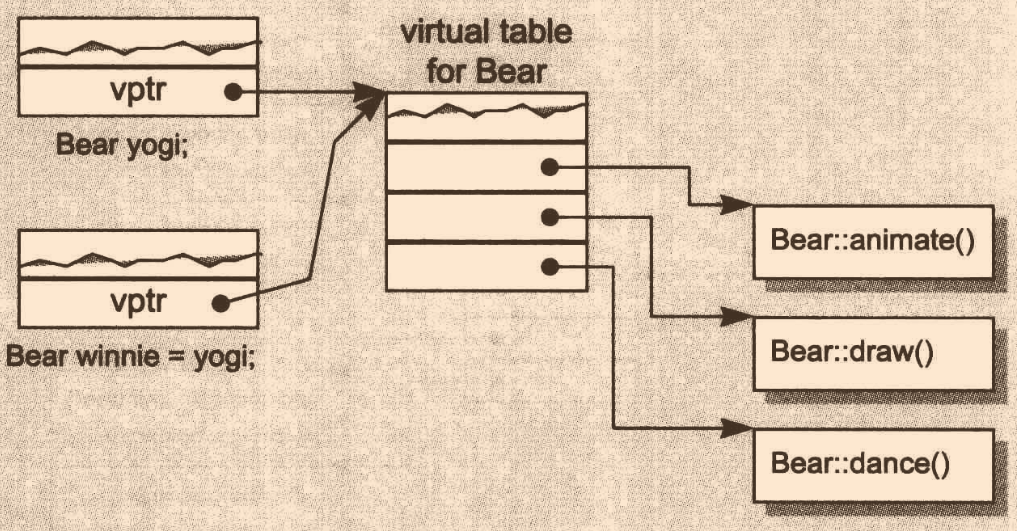
但是要注意,當一個基類物件以派生類物件的內容初始化時,vptr的復制操作需保證安全
來看一個例子:
void draw( const ZooAnimal& zoey ) { zoey.draw(); } void fun() { ZooAnimal franny = yogi; //造成切割 draw(yogi); draw(franny); }事實上franny只有ZooAnimal那一部分,Bear那部分已經被切割掉,這里呼叫的是ZooAnimal的版本,那么問題來了,vptr不是會進行賦值操作嘛,為什么vptr還是指向ZooAnimal的vbtl?答案是,對于這種情況,
合成出來的ZooAnimal的默認拷貝建構式不再進行簡單的拷貝賦值操作,而是顯式設定vptr指向ZooAnimal class的vbtl,這也就是為什么包含虛函式的情況下bitwise copy semantics會失效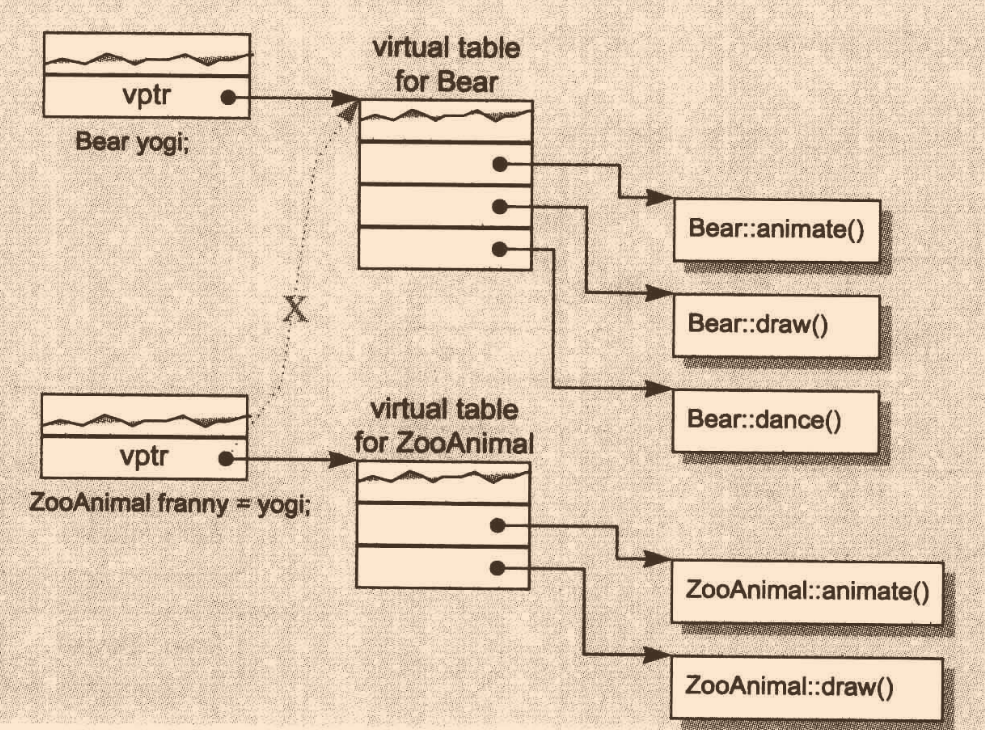
-
class派生自一個繼承串鏈,其中有一個及以上的
虛基類
在一個類物件以其派生類物件作為初值的情況下,bitwise copy semantics依然會失效,因為虛基類的位置并不確定,簡單的進行bitwise copy semantics可能會破壞這個位置,所以編譯器必須合成默認的拷貝建構式做出判斷;不過若是相同的型別之間進行賦值,bitwise copy semantics依舊生效(動態轉換的指標除外)
來看一個例子:
class Raccoon : public virtual ZooAnimal
{
public:
Raccoon();
Raccoon(int val);
//...
};
class RedPanda : public Raccoon
{
public:
RedPanda();
RedPanda(int val);
//...
};
//兩個相同類物件,bitwise copy semantics依舊生效
Raccoon rocky;
Raccoon little_critter = rocky;
//一個類物件以其派生類物件作為初值,bitwise copy semantics不生效
//這個時候編譯器必須合成一個拷貝建構式,已初始化虛基類指標
RedPanda little_red;
Raccon little_critter = little_red;
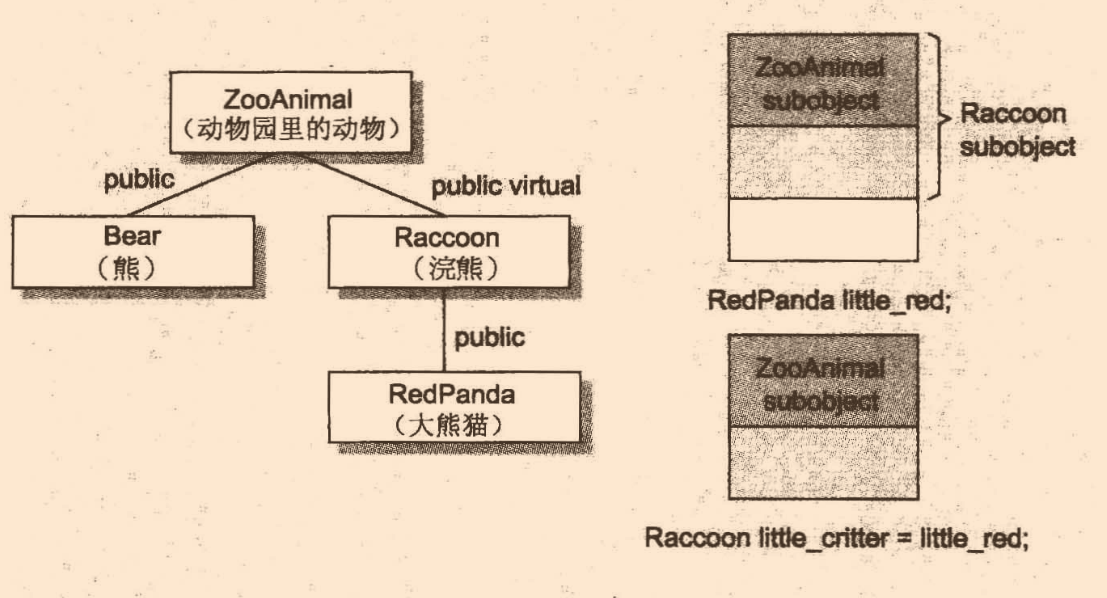
這種情況下,編譯器必須合成默認的拷貝建構式,額外任務是安插必要代碼來設定虛基類的指標的初值
對于以下這樣的情況,因為不知道指標真正指定的物件型別,因此編譯器并不知道bitwise copy semantics是否生效
Raccoon* ptr;
Raccoon little_critter = *ptr;
程式轉化
先來看一段代碼:
A func()
{
A aa;
//...
return aa;
}
對于以上代碼,你可能會認為每次func被呼叫,就傳回aa的值;且如果class A定義了一個拷貝構造,那么當func被呼叫時,保證該拷貝構造也會被呼叫,這可能成立也可能不成立,具體如何視編譯器的優化來定
分析這個問題之前,我們先來看幾個基礎轉化:
-
顯式的初始化
來看一個例子:
A a0; void func1() { //定義a1、a2、a3 A a1(a0); A a2 = a0; A a3 = A(a0); }這里程式會進行轉化,而這轉化可以分為兩個階段:
- 重寫每一個定義,去除初始化操作
- 安插class的拷貝構造呼叫
可能的轉化如下:
void func1() { //重寫定義 A a1; A a2; A a3; //安插拷貝構造呼叫 a1.A::A( a0 ); a2.A::A( a0 ); a3.A::A( a0 ); } -
引數的初始化
將一個class物件作為引數傳給一個函式或作為函式的回傳值,相當于以下的初始化操作:
A aa; void func( A a0 ); A a0 = aa;這會要求區域物件a0以memberwise的方式將aa作為初值.編譯器針對這個要求有不同的做法,其中一種做法是匯入所謂的臨時物件,并呼叫拷貝建構式將其初始化,再將此臨時物件交給函式
以上例子可能的轉化:
A __temp0; __temp0.A::A( aa ); //需要將函式引數改為&,否則這會多進行一次bitwise foo( A& a0 ); //隨后便對臨時物件進行析構 -
回傳值的初始化
A func() { A aa; //... return aa; }對于以上片段中,你可能會問函式的回傳值如何從區域物件aa中拷貝而來?其中一種做法是進行雙階段轉化:
- 首先加上一個額外引數,型別是class物件的參考,放置進行構造后的物件
- 在return前安插一個拷貝建構式的呼叫操作,將想要傳回的物件的內容當作新增引數的初值
可能進行以下轉化:
void func( A& __result ) { A aa; aa.A::A(); __result.A::A(aa); return; } //編譯器必須轉換每個func的呼叫 A a0 = func(); //可能的轉化 A a0; func( a0 ); func().mem(); //對于以上呼叫可能的轉化 A __temp0; ( func( _temp0 ), __temp0 ).mem(); //對于函式指標 A (*pa) (); pa = func; //可能的轉化 void (*pa)(A&); pa = func;
以上三種轉化其實效率并不算好,我可以在兩方面進行優化:
-
開發人員層面
//不再是以下這樣 A func( const T& y, const T&z ) { A aa; //...用y和z處理aa return aa; } //而是定義一個用于計算的建構式,這樣減少了拷貝次數 A func( A& __result, const T& y, const T&z ) { __result.A::A(y,z); return; } -
編譯器層面
以__result引數取代named return value(NRV),主要注意的是NRV優化需要copy constructor編譯器才可實施
//用__result取代aa void func( A& __result ) { __result.A::A(); return; }不過NRV優化,也有缺點:
-
優化由編譯器完成,但是我并不知道這項優化是否真的完成
-
一旦函式變得復雜,優化會難以實施
因為對于函式體內若嵌套了塊block,塊里又包含return陳述句,此時NRV優化大概率會關閉
-
某些程式員不喜歡自己的代碼被優化,因為很可能打亂本來正確的順序
來看一個例子:
void callFunc() { //呼叫拷貝構造 A aa = func(); //呼叫析構 }這種情況下,雖然程式優化了速度很快,但卻是錯誤的,因為在前面的例子可以看到NRV優化會剔除建構式
-
現在讓我們回到最初的兩個問題:
-
每次func被呼叫,就傳回aa的值
很明顯,編譯器對函式進行了轉化,通過參考__result傳回aa
-
如果class A定義了一個拷貝構造,那么當func被呼叫時,保證該拷貝構造也會被呼叫
不一定,視編譯器優化而定,NRV優化施行了的話,便不會呼叫拷貝構造
A func()
{
A aa;
//...
return aa;
}
是否需要拷貝構造?
是否需要拷貝構造視情況而定,若bitwise copy即可滿足,則不定義顯式的拷貝建構式,因為編譯器想得比你周到,已經為你施行了最好的方案;但若需要大量的memberwise操作,也就是說bitwise copy不再滿足開發者要求,這種情況需要提供一個顯式的建構式且編譯器提供NRV優化,當然難度非常高,因此推薦禁止拷貝建構式
class Point3d
{
public:
//都符合NRV優化
Point3d operator+(const Point3d&);
Point3d operator-(const Point3d&);
Point3d operator*(const Point3d);
//...
private:
float _x, _y, _z;
};
//合理
Point3d::Point3d( const Point3d &rhs )
{
_x = rhs._x;
_y = rhs._y;
_z = rhs._z;
}
//但是可以更有效率
Point3d::Point3d( const Point3d &rhs )
{
memcpy( this, &rhs, sizeof(Point3d) ); //memset也可以
}
不過這里如果存在編譯器生成的內部成員如虛指標,memcpy或memset將使得編譯器生成的成員的值被改寫
class A
{
public:
A() { memset( this, 0, sizeof(A) ); }
//這里有虛函式或虛基類
};
//擴張
A()
{
__vptr__A = __vbtl__A;
memset( this, 0, sizeof(A) );
}
值得一提的是,當?個class內含有reference/const成員時,編譯器不會提供拷?賦值運算子的補充,只能由開發人員??撰寫.因為C++不允許改變reference成員的指向,也不允許更改const成員
賦值物件時勿忘其每個成員
? copy函式包含:拷貝建構式,拷貝賦值運算子
? 當定義了copy函式后,編譯器將不再生成默認版本,若編譯器有額外需求,編譯器會在copy函式中安插必要的代碼,不過這并不意味著編譯器會為你的遺漏服務
? 當為class添加?個成員變數,必須同時修改copy函式
? 為派生類定義copy函式時,要注意對基類成員的復制,基類成員通常是private,派生類?法直接訪問,應該讓派生類的復制函式調?相應的基類復制函式
? 不能為了簡化代碼,就在拷貝建構式中調?拷貝賦值運算子,也不能在拷貝賦值運算子中調?拷貝建構式,因為拷貝建構式?來初始化新物件,?賦值運算子只能?于已初始化的物件
? 要想消除copy函式的重復代碼,可以建??個新的成員函式給copy函式調?,這個函式通常是private且命名為init
移動構造
右值參考
左值:指運算式結束后依然存在的持久物件,可以取地址,具名變數或物件
右值:運算式結束后就不再存在的臨時物件,不可以取地址,沒有名字
變數和文字常量都有存盤區,并且有相關的型別,區別在于變數是可尋址的(addressable).對于每一個變數都有兩個值與其相聯:
- 它的
資料值,存盤在某個記憶體地址,有時這個值也被稱為物件的右值(rvalue,讀做are-value).也可認為右值是被讀取的值(read value). 文字常量和變數都可 被用作右值 - 它的
地址值,有時被稱為變數的左值(lvalue,讀作ell-value),也可認為左值是位置值location value.文字常量不能被用作左值
也就是說,有些變數可作左值和右值;而文字常量只能作右值
例子:
//a++.a為右值
int temp = a;
a = a + 1;
return temp;
//++a.a為左值
a = a + 1;
return a;
純右值:臨時變數值、不跟物件關聯的字面量值.右值是純右值
將亡值:將要被移動的物件、T&&函式回傳值、std::move回傳值和轉換為T&&的型別的轉換函式的回傳值,可以理解為“盜取”其他變數記憶體空間,在確保其他變數不再被使用、或即將被銷毀時,通過“盜取”的方式可以避免記憶體空間的釋放和分配,能夠延長變數值的生命期
左值參考:對一個左值進行參考的型別,必須進行初始化.左值參考是有名變數的別名
常量左值參考是一個“萬能”的參考型別,可以接受左值、右值、常量左值和常量右值
右值參考:右值參考必須立即進行初始化操作,且只能使用右值進行初始化.右值參考是不具名變數的別名
右值參考可以對右值進行修改.c++支持定義常量右值參考
定義的右值參考并無實際用處,右值參考主要用于移動語意和完美轉發,其中前者需要有修改右值的權限
通過右值參考,這個將亡的右值又“重獲新生”,它的生命周期與右值參考型別變數的生命周期一樣,只要這個右值參考型別的變數還活著,那么這個右值臨時量就會一直活著,可利用這一點會一些性能優化,避免臨時物件的拷貝構造和析構
右值參考通常不能系結到任何的左值,要想系結一個左值到右值參考,通常需要std::move()將左值強制轉換為右值
T&&是什么,一定是右值嗎?
來看個例子:
template<typename T>
void f(T&& t){}
f(10); //t是右值
int x = 10;
f(x); //t是左值
T&&表示的值型別不確定,可能是左值又可能是右值
右值參考獨立于左值和右值,意思是右值參考型別的變數可能是左值也可能是右值
來看個例子:
int&& var1 = 1; //var1型別為右值參考,但var1本身是左值,因為具名變數都是左值
例子:
//常量左值
int num = 10;
const int &b = num;
const int &c = 10;
//右值參考
int num = 10;
int && a = num; //不合法,右值參考不能初始化為左值
int && a = 10;
//對右值參考對右值進行修改
int && a = 10;
a = 100;
cout << a << endl;
//常量右值參考
const int&& a = 10;//合法
移動建構式
-
為什么需要移動建構式?
在之前的拷貝建構式中我們學到了,對于指標這種進行淺拷貝,而后很容易進行兩次析構導致程式崩潰,而深拷貝或編譯器自行合成默認的拷貝建構式,又會生成臨時物件,這會導致效率大大降低,雖然有NRV優化,但NRV優化也有限制,因此,c++針對這一狀況引進了移動建構式
-
什么是移動建構式?
c++引入右值參考,借助它可以實作移動語意
什么是移動語意?將資源(如動態分配的記憶體)從一個物件轉移到另一個物件,也就是說允許從臨時物件(無法在程式中的其他位置參考)轉移資源
舉個例子:
struct A { A(); A(const A& a); ~A(); }; A GetA() { return A(); } int main() { A a = GetA(); return 0; } //生成一個臨時物件,最后還會多呼叫一次解構式,一次拷貝 //可能的轉化如下 void GetA( A& __result ) { A aa; aa.A::A(); __result.A::A(aa); aa.~A::A(); return; }可以看到這樣效率不高,但是通過移動語意,就可以提高效率
改動如下:
//少呼叫一次拷貝構造和析構 A&& a = GetA();通過右值參考,比之前少了一次拷貝構造和一次析構,原因在于右值參考系結了右值,讓臨時右值的生命周期延長了,我們可以利用這個特點做一些性能優化,即避免臨時物件的拷貝構造和析構
事實上,在c++98/03中,通過
常量左值參考也經常用來做性能優化改動如下:
const A& a = GetA();我們來看一個移動建構式的例子:
class A { public: A() :m_ptr(new int(0)){} A(const A& a):m_ptr(new int(*a.m_ptr)) //深拷貝的拷貝建構式 { cout << "copy construct" << endl; } A(A&& a) :m_ptr(a.m_ptr) //移動構造 { a.m_ptr = nullptr; cout << "move construct" << endl; } ~A(){ delete m_ptr;} private: int* m_ptr; }; int main(){ A a = Get(); } 輸出: construct move construct move construct這個建構式并沒有做深拷貝,僅僅是將指標的所有者轉移到了另外一個物件,同時,將引數物件a的指標置為空,這里僅僅是做了淺拷貝,因此,這個建構式避免了臨時變數的深拷貝問題,這個建構式其實就是移動建構式,引數是一個右值參考型別.為什么會匹配到這個建構式?因為這個建構式只能接受右值引數,而函式回傳值是右值
值得一提的是,提供移動建構式的同時提供一個拷貝建構式,以防止移動不成功的時候還能拷貝構造,更有嚴謹性
?
移動拷貝建構式的定義:定義一個空的建構式方法,該方法采用一個對class型別的右值參考作為引數MemoryBlock(MemoryBlock&& other) : _data(nullptr) , _length(0) { } //在移動建構式中,將源物件中的class資料成員添加到要構造的物件 _data = https://www.cnblogs.com/chenglixue/archive/2022/11/26/other._data; _length = other._length; //將源物件的資料成員分配給默認值, 這可以防止解構式多次釋放資源(如記憶體) other._data = nullptr; other._length = 0;移動賦值運算子的定義:定義一個空的賦值運算子,該運算子采用一個對class型別的右值參考作為引數并回傳一個對class型別的參考MemoryBlock& operator=(MemoryBlock&& other) { } //在移動賦值運算子中,如果嘗試將物件賦給自身,則添加不執行運算的條件陳述句 if (this != &other) { }? 你可能會疑惑在拷貝建構式中的轉化,是構造一個臨時物件,再進行拷貝,這個臨時物件是個左值;而在這里移動構造引數接受的是右值,如何實作呢?可能是使用了std::move,將這個左值轉為右值
? std::move():將左值轉換為右值,從而方便應用移動語意.move是將
物件資源的所有權從一個物件轉移到另一個物件,只是轉移,沒有記憶體的拷貝.也就是說,使用move幾乎沒有任何代價如果一個物件內部有較大的對記憶體或者動態陣列時,很有必要寫move語意的拷貝建構式和賦值函式;如果是基本型別比如int和char[10]定長陣列等,使用move仍然會發生拷貝(因為沒有對應的移動建構式)
std::move()的定義:template <class Type> constexpr typename remove_reference<Type>::type&& move(Type&& Arg) noexcept;
委托構造
為什么引入委托構造?
? 如下,現有三個class含有執行類似操作的多個建構式:
class class_c {
public:
int max;
int min;
int middle;
class_c() {}
class_c(int my_max) {
max = my_max > 0 ? my_max : 10;
}
class_c(int my_max, int my_min) {
max = my_max > 0 ? my_max : 10;
min = my_min > 0 && my_min < max ? my_min : 1;
}
class_c(int my_max, int my_min, int my_middle) {
max = my_max > 0 ? my_max : 10;
min = my_min > 0 && my_min < max ? my_min : 1;
middle = my_middle < max && my_middle > min ? my_middle : 5;
}
};
我們可以通過添加一個包含所有驗證的函式來減少重復的代碼,但是如果一個建構式可以將部分作業委托給其他建構式,則這樣的代碼更易于了解和維護,對于這種情況,c++11引入了委托建構式,目的是簡化建構式的書寫,提高代碼的可維護性,避免代碼冗余膨脹
什么是委托建構式?
一個委托建構式使用它所屬的類的其他建構式執行自己的初始化程序,或者說它把自己的一些或全部職責委托給了其他建構式
? 委托建構式的語法:constructor (. . .) : constructor (. . .)
例子:
class class_c {
public:
int max;
int min;
int middle;
class_c(int my_max) {
max = my_max > 0 ? my_max : 10;
}
class_c(int my_max, int my_min) : class_c(my_max) {
min = my_min > 0 && my_min < max ? my_min : 1;
}
class_c(int my_max, int my_min, int my_middle) : class_c (my_max, my_min){
middle = my_middle < max && my_middle > min ? my_middle : 5;
}
};
int main() {
class_c c1{ 1, 3, 2 };
}
現在,建構式 class_c(int, int, int) 首先呼叫建構式 class_c(int, int),該建構式再來呼叫 class_c(int)
? 和其他建構式一樣,一個委托建構式也有一個成員初始化串列和一個函式體,成員初始化串列只能包含一個其它建構式,不能再包含其它成員變數的初始化,且引數串列必須與建構式匹配
? 呼叫的第一個建構式將初始化物件,以便此時初始化其所有成員, 不能在委托給另一個建構式的建構式中執行成員初始化
例子:
class class_a {
public:
class_a() {}
// member initialization here, no delegate
class_a(string str) : m_string{ str } {}
//can't do member initialization here
// error C3511: a call to a delegating constructor shall be the only member-initializer
class_a(string str, double dbl) : class_a(str) , m_double{ dbl } {}
// only member assignment
class_a(string str, double dbl) : class_a(str) { m_double = dbl; }
double m_double{ 1.0 };
string m_string;
};
? 如果建構式還將初始化給定的資料成員,則將重寫成員初始值
例子:
class class_a {
public:
class_a() {}
class_a(string str) : m_string{ str } {}
class_a(string str, double dbl) : class_a(str) { m_double = dbl; }
double m_double{ 1.0 };
string m_string{ m_double < 10.0 ? "alpha" : "beta" };
};
int main() {
class_a a{ "hello", 2.0 }; //expect a.m_double == 2.0, a.m_string == "hello"
int y = 4;
}
? 建構式委托語法不會阻止建構式的遞回. - Constructor1 將呼叫 Constructor2(其呼叫 Constructor1),在出現堆疊溢位之前不會出錯,應當避免這個遞回
例子:
class class_f{
public:
int max;
int min;
// don't do this
class_f() : class_f(6, 3){ }
class_f(int my_max, int my_min) : class_f() { }
};
? 如果在委托建構式中使用try,可以捕獲目標建構式中拋出的例外
解構式
? 解構式(destructor)是成員函式的一種,它的名字與類名相同,但前面要加~,沒有引數和回傳值
? 解構式在物件消亡時即自動被呼叫,可以定義解構式在物件消亡前做善后作業.也就是說,在物件超出范圍或通過呼叫 delete 顯式銷毀物件時,會自動呼叫解構式
? 一個類有且僅有一個解構式
? 若class沒定義destructor,只有在class內含member object含有destructor時,編譯器才會合成destructor;對許多類來說,這就足夠了, 只有當類存盤了需要釋放的系統資源的句柄,或擁有其指向的記憶體的指標時,你才需要定義自定義解構式
? 宣告解構式的規則:
- 不接受自變數
- 沒有回傳值(或 void)
- 不能宣告為 const、volatile 或 static, 但是,可以為宣告為 const、volatile 或 static的物件的析構呼叫它們
- 可以宣告為 virtual, 通過使用虛擬解構式,無需知道物件的型別即可銷毀物件(使用虛函式機制呼叫該物件的正確解構式),解構式也可以宣告為抽象類的純虛函式
? 解構式在物件消亡時即自動被呼叫,可以定義解構式在物件消亡前做善后作業.也就是說,在物件超出范圍或通過呼叫 delete 顯式銷毀物件時,會自動呼叫解構式
? 當符合以下條件時,將呼叫解構式:
- 具有塊范圍的本地(自動)物件超出范圍
- 使用 delete顯式解除分配了使用 new運算子分配的物件
- 臨時物件的生存期結束
- 程式結束,并且存在全域或靜態物件
- 使用解構式的完全限定名顯式呼叫了解構式
? 若base class不含desturctor,那么derived class也不需要desturctor
destructor被擴展的方式,與constructor相似,但順序相反:
- destructor函式本體先被執行
- 若class含有member class object,而后者含有destructors,他們會以其宣告順序的相反順序被呼叫
- 若object內含vptr,現需被重新指定,指向適當的base class的virtual table
- 若有任何直接的nonvirtual base classes含有destructor,它們會以其相反的宣告順序被呼叫
- 若由任何virtual base classes含有destructor,如之前的PVertex例子,會以其原來的構造順序的相反順序呼叫
? 很少需要顯式呼叫解構式, 但是,對置于絕對地址的物件進行清理會很有用, 這些物件通常使用采用位置引數的用戶定義的 new運算子進行分配,delete運算子不能釋放該記憶體,因為它不是從自由存盤區分配的
? 一般而言,constructor和destructor的安插都如預期那樣:
{
Point point;
//point.Point::Point() 安插于此
...
//point.Point::~Point() 安插于此
}
但有些情況desctructor需要放在每一個離開點(此時object還存活)前,例如swith,goto:
{
Point point;
//point.Point::Point() 安插于此
swith ( int(point.x() ) )
{
case -1 :
...
//point.Point::~Point() 安插于此
return;
case 0 :
...
//point.Point::~Point() 安插于此
return;
case 1 :
...
//point.Point::~Point() 安插于此
return;
default :
...
//point.Point::~Point() 安插于此
return;
}
//point.Point::~Point() 安插于此
}
資料成員的記憶體布局與繼承
影響class記憶體大小的因素
我們由一個例子引入記憶體布局的話題:
//64位系統
class A{ }; //sizeof(A)為1
class B : virtual public A{ }; //sizeof(B)為8
class C : virtual public A{ }; //sizeof(C)為8
class D : public B, public C{ }; //sizeof(D)為16
四個類的記憶體布局:
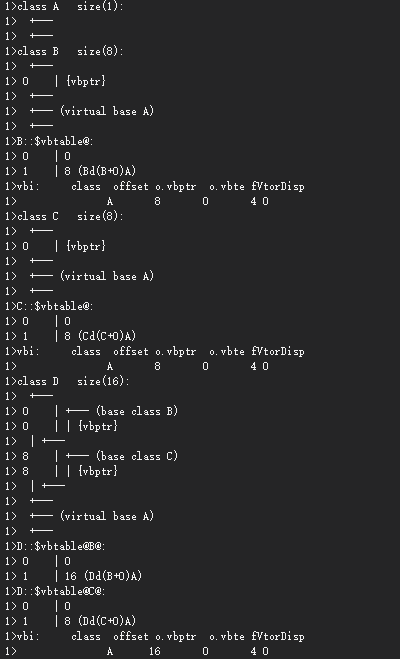
接下來我們一一分析為什么會產生這樣的結果
class A明明是一個空類,為什么它的記憶體大小為1呢?表面上它是個空類,但其實它并不是,它有一個隱藏的1byte大小的char,這使得這樣的class的不同物件在記憶體擁有獨一無二的地址
class B和C虛擬派生自A,為什么記憶體大小為8?這個大小與機器和編譯器都有關系,收到三個因素的影響:
-
語言本身額外的負擔,若派生類 派生自 虛基類,則派生類中含有一個虛表指標vbptr,此指標指向virtual base class subobject(某物件中的虛基類)或一個相關表格vbtable,而vbtable存放virtual base class subobject地址或編譯位置(offset) -
編譯器對特殊情況的優化處理,虛基類 A subobject的1 bytes的char一般放于派生類的固定部分的末端,某些編譯器會對空的虛基類提供特殊支持但空的虛基類情況不同,其不定義任何資料,提供一個virtual interface,在某些編譯器(比如vs c++)處理下,一個空的虛基類被視為派生類物件最開始的那一部分,并沒有使用任何的額外空間,因為含有成員,所以也沒有必要安插char,這就節省了1btyes
-
記憶體對齊alignment的限制,大部分機器上,聚合的結構體大小會受到記憶體對齊的限制,使它們能夠更有效地在記憶體中存取,在32位機器上,記憶體對齊為4bytes;64位機器上,記憶體對齊為8bytes
classD的記憶體大小為何為16?在一些并未對空的虛基類進行特別處理的編譯器上,大小將為24;進行特別處理的是16,我們討論的是未進行特別處理的
classD的記憶體大小受以下四點影響:
- 虛基類A,大小為1byte
- 基類Y和Z的大小,減去配置虛基類的大小,為8byte,總共16
- class D自己的大小0byte
- class D的記憶體對齊的大小,在這里為7
因此綜上得出class D的記憶體大小為1 + 16 + 7 = 24;而進行特殊處理的,只含有基類Y和Z的大小為16
值得一提的是,基類subobjects的排列順序或不同存取層級的資料成員的排列順序并未有標準的規定,一切都由廠商來自行定義
data成員
c++物件模型以空間優化和存取速度優化的角度來表現nonstatic資料成員,且保持和c風格struct data的兼容性,它將data存在每個class物件中,繼承而來的亦是如此,但并不強制定義它們的排列順序;而static資料成員則放置在全域資料段global data segment中,不影響class物件的大小
每個class物件需要分配足夠的空間來容納所有的nonstatic data members,有些情況下會超乎你的預料,原因是:
- 編譯器自動加上的額外資料成員,主要是virtual特性
- 記憶體對齊的需要
data成員的系結
以前的c++對data成員的系結與現在稍有不同
我們來看一個例子:
extern int x;
class A
{
public:
A( int, int, int );
int X() const { return x; }
void X( float _x ) const { x = _x; }
//...
private:
int x,y,z;
}
請問X()應該回傳哪一個x?絕大部分的人,會回答是內部的那個,這個答案放在如今是正確的,但在以前并不對,在以前這兩個X函式都會系結外部的那個
因此針對這一現象,衍生出了兩種防御性程式設計風格:
-
將所有資料成員放在class宣告開始處,以確保正確的保定
class A { private: int x,y,z; public: A( int, int, int ); int X() const { return x; } void X( float _x ) const { x = _x; } //... }; -
將所有inline函式,無論其大小都放于class宣告外
class A { private: int x,y,z; public: A( int, int, int ); int X() const { return x; } void X( float _x ) const { x = _x; } //... }; inline int A::X() const { return x; }
事實上,這種語言規則已經遺棄了,它的大致意思是"一個inline函式物體的回傳值和函式體內,在整個class宣告未被完全看見時,不會被評估求值(evaluated)",也就是說對inline函式的分析會推遲并放在class外;而在現在,inline是要被立刻評估求值,但兩種效果其實都是一樣的
class A
{
private:
int x,y,z;
public:
A( int, int, int );
int X() const { return x; }
void X( float _x ) const { x = _x; }
//...
}; //對函式本體的分析將在class宣告塊結束后才開始,也就是右大括號
//分析在此處進行
以前這一規則并不適用于成員函式的引數串列argument list,成員函式第一次遇見函式串列型別都會進行決議,編譯器往后如果看到了同一名字的不同型別的資料成員,會將前面的資料成員標示為非法;現在如今,c++語言依舊支持這一特性,但不再標示為非法(vs c++ 2022)
來看一個例子:
typedef float length;
class A
{
public:
//在這里func的length都會被決議為全域(global)型別也就是float而非int
//_val被決議為A::_val
void func( length val ) { _val = val; }
length func() { return _val; }
private:
//將之前系結的全域型別替換當前這個
typedef int length;
length_val;
}
對于這種情況,仍需防御性程式風格:將所有資料成員放在class宣告開始處,以確保正確的系結
data成員的布局
我們先來看一個程式片段:
class A
{
public:
//...
private:
float x;
static int a;
float y;
static int c;
float z;
}
//在class中可能的記憶體排列順序如下
//float x
//float y
//float z
nonstatic資料成員在class物件中記憶體排列順序應和宣告的順序相同,即使static資料成員宣告在nonstatic資料成員之間,也會不受static data members影響
在同一個訪問區段(access section.也就是private、public、protected范圍內)成員的排列只需符合較晚出現的成員在class物件中有較高的地址這一條件即可,也就是說各個成員不一定得連續排列,可能會有什么東西介于宣告的成員之間,這些東西是記憶體對齊,編譯器合成的用來支持物件模型的資料成員如vptr,在現在vptr放在class物件的最前端,以前是顯式宣告的成員這一范圍的末尾
編譯器可以將多個訪問區段內的資料成員自由排列,不必在意它們在class中宣告的順序,但大部分編譯器都是將一個以上的區段合并在一起,按照宣告順序,成為一個連續的區塊
也就是說,在上面那個例子可能有如下排列:
//當然排列方式不固定,依據編譯器
class A
{
private:
float x;
static int a;
private:
float y;
private:
static int c;
float z;
}
訪問區段的多少并不會影響記憶體大小,也就是說訪問區段并不會帶來額外負擔,宣告一個private和宣告八個private得到的物件大小都是相同的
data成員的存取
現有以下程式片段:
A a;
a.x = 0.0;
A* pa = &A;
pa->x = 0.0;
這里有兩個問題:
- x的存取成本?
- 通過pa存取x和通過物件存取x有何差異?
接下來我們將圍繞這兩個問題展開分析
-
static資料成員
宣告在class中的static資料成員,無論定義幾個當前class型別的物件,
static資料成員只有一個實體,存放在資料段(data segment)對一個static資料成員取地址,得到的是一個指向其資料型別的指標,而非一個指向其class成員的指標,因為static成員并不在class物件中
你可能會問如果兩個型別不同的class都宣告了一個static資料成員,這會導致名稱沖突啊,其實編譯器面對這種情況,會將每一個static資料成員進行名稱修飾,以獲得獨一無二的名稱
每一個成員的存取許可(priavte、public、protected)和與class的關聯,并不會帶來空間或時間上的額外負擔,對于static資料成員來說亦是如此
每次對static資料成員進行存取,編譯器會對其存取操作進行轉換
可能的轉換如下:
//a.x = 1; A::x = 1; //pa->x = 1; A::x = 1;也可以看出,用指標和物件對static資料成員進行存盤其實沒什么兩樣,事實上確實如此,這是c++中唯一一個通過指標和通過一個物件來存取成員結論完全相同的情況,即使它的繼承體系十分復雜,也無關緊要,因為在記憶體中只有唯一一份實體
你可能會問,static資料成員放于資料段(data segment),那為什么還要通過物件來存取?實際上,通過這種方式來存取只是因為方便,static成員并不在class物件中,因此存取它可以不用通過class物件
那么通過函式來呼叫呢?
來看一個例子:
func().x = 5; //可能的轉化 (void) func(); A.x = 5;可以看到即使func有回傳值,對x的存取其實并沒有用到這個回傳值
-
nonstatic資料成員
nonstatic資料成員直接存放在每個class物件中,只能由顯式或隱式的class物件來存取它們
顯式的自然就是加上this指標了
隱式的是編譯器進行的擴張.只要在一個成員函式中直接處理一個nonstatic資料成員,隱式的class物件就會發生
void A::translat( const A& obj ) { x += obj.x; y += obj.y; z += obj.z; } //進行如下轉換 void A::translat( A* this, const A& obj ) { this->x += obj.x; this->y += obj.y; this->z += obj.z; }但其實對一個資料成員進行存取,并沒有看上去的如此簡單,編譯器需要把class物件的起始地址加上資料成員的偏移位置(offset),這個offset在編譯期即可得知,即使成員派生自單一或多重繼承串鏈,也就是說
在這種情況下,存取一個nonstatic資料成員的效率其實和存取一個c風格的struct成員或一個不經過派生的class的成員是一樣的但在虛擬繼承的情況下,效率會有差異,比如:
A* pa; pa->x = 0;對于strcut、class、單一繼承、多重繼承情況下存取一個資料成員,效率都是相同的,因為在編譯期即可準備好它們的offset,而虛擬繼承因為指標或參考動態轉換的關系將會將offset的確定作業移至執行期(具體的在后面虛擬繼承將會講解)
來看一個例子:
a.y = 0.0; //&a.y的地址 &a + (&A::y - 1)為什么這里有個-1呢?這是因為指向資料成員的指標,它的offset總是會加上1,如此編譯系統可以區分"
一個指向資料成員的指標,用來指向class的第一個成員的指標" 和 "一個指向資料成員的指標,沒有指向任何成員"這兩種情況(若不明白這兩個含義,請移至指向data成員的指標)
現在我們回到最初的兩個問題
-
x的存取成本?
對于static資料成員并沒有什么額外成本;對于nonstatic資料成員和c風格的struct成員,以及不經過派生的class的成員是一樣的,需要經過指標或'.'(select operator).不過這種呼叫只是符號上的便利,編譯器會對這種呼叫進行轉化"A::"
-
通過pa存取x和通過物件存取x有何差異?
當這個物件是個派生class,繼承結構中有虛基類,且存取的成員從虛基類繼承而來,用指標存取將會有重大差異,因為編譯期無法確定指標具體的物件,只能在運行期確定,自然這個成員的offset也無法確定;而通過物件存取,其型別一定可以確定,也就可以在編譯期確定offset了
指向data成員的指標
如何區別class種一個"沒有指向任何資料成員的指標"和"一個指向第一個資料成員的指標"?答案是將指向資料成員的指標的值+1
你可能會疑惑為什么要這么做,來看一個例子:
class A
{
public:
float x;
const static int y = 1;
};
A a;
std::cout << &A::x <<std::endl; //結果為1,在class中的offset
std::cout << a.x <<std::endl; //x在記憶體中的地址
std::cout << &A::y <<std::endl; //對static資料成員取地址是它在記憶體中的地址
//若不加1,以下情況將無法區分
float A::* p1 = 0;
float A::* p2 = &A::x;
if( p1 == p2 ){}
因此,在使用指向資料成員的指標來指出一個成員前,需要減一,也就是說,對一個class中的nonstatic資料成員取地址,得到的是它在class中的offset;而對一個系結在class物件的資料成員取地址,得到的將是該成員在記憶體中的真正地址.對class中的static成員取地址是它在記憶體中的地址
在多重繼承中,若將第二個或后繼基類的指標,和一個"與派生類物件系結"的成員結合起來,結果可能會不如你意,需要做一些操作
struct A1
{
int val1;
};
struct A2
{
int val2;
};
struct D : A1, A2{ ... };
void func1( int D::* dmp,D* pd )
{
pd->*dmp;
}
void func1( D* pd )
{
int A2::*amp = &A2::val2;
func1(amp, pd); //此時pd指向的將是A1::val1,而非A2::val2
}
//因此編譯器需要進行轉換
func1( amp + sizeof(A1), pd );
//但需要防范amp == 0
func1( amp ? amp + sizeof( A1 ) : 0, pd );
效率
- 對于物件成員,在編譯期未優化時聚合、封裝、繼承方式在存取方面都有效率上的差異;優化后都是相同的,且封裝并不會帶來執行器的效率成本,其中聚合和封裝、單一繼承效率高,因為單一繼承中members被連續存盤在derived class中,且offset于編譯期就計算出了;但虛擬繼承的效率很低
- 對于指向data member的指標,在編譯期未優化時,通過指標間接存取效率相對于直接存取會更低,但優化后都是一樣的;單一繼承并不會降低效率,但虛擬繼承中,因每一層都匯入一個額外層次的間接性,因此效率較差
繼承
要說c++最具威力的便是繼承,一個繼承可以很簡單,但也非常非常復雜,這節我們將進一步了解單一繼承、多重繼承、虛擬繼承的威力
在c++繼承模型中,一個派生類物件內含的部分是自己的成員加上它的基類成員的總和,但它們的排列順序是由編譯器自行安排,不過大多數都是基類先出現,但虛基類除外(一般而言,任何一條規則遇見虛基類將不再如你預期)
單一繼承與多型
- 只考慮單一繼承非多型
我們先來看一個例子:
class Point2d
{
public:
//...
private:
float _x,_y;
};
class Point3d
{
public:
//...
private:
float _z;
}
對于這兩個class意為2d,3d坐標點,我們想要這些兩種坐標點通過一個class即可使用,這個時候就是繼承發揮作用的時候了,我們讓Point3d繼承自Point2d,這樣Point3d即可共享Point2d的方法和資料成員,并將之區域化,這種繼承被稱為具體繼承,一般而言,具體繼承并不會增加空間或存取時間上的額外負擔(虛基類,虛函式除外)
繼承后如下:
class Point2d
{
public:
Point2d( float x = 0.0, float y = 0.0 ) : _x(x), _y(y) { }
float x() { return _x; }
float y() { return _y; }
void operation+=( const Point2d& rhs )
{
_x += rhs.x();
_y += rhs.y();
}
protected:
float _x,_y;
};
class Point3d
{
public:
Point3d( float x = 0.0, float y = 0.0, float z = 0.0 ) : Point( x, y ), _z(z) { }
float z() { return _z; }
void z( float newZ ) { _z = newZ; }
void operator+=( const Point3d& rhs )
{
Point2d::operator+=( rhs );
_z += rhs.z();
}
protected:
float _z;
}
記憶體布局如下:
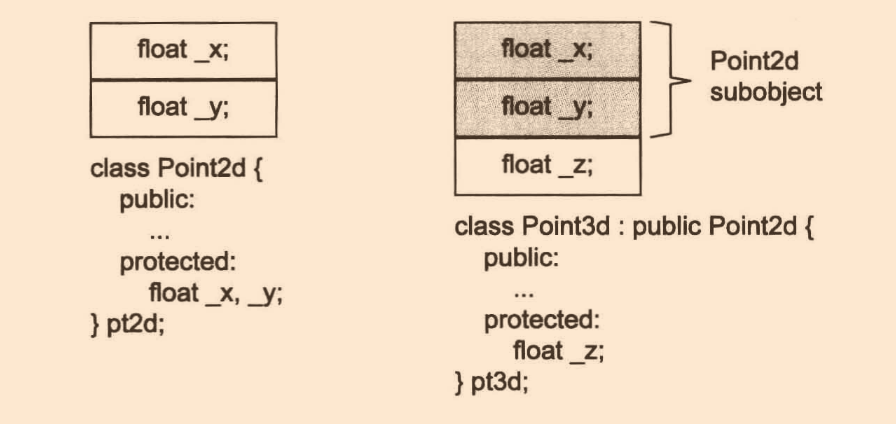
這里有一個易錯點,大多數人的設計可能會為了如上這種繼承而導致膨脹記憶體空間
我們來看一個例子:
//32位系統
class Concrete
{
public:
//...
private:
int val;
char c1;
char c2;
char c3;
};
//對以上以繼承體系實作
class Concrete1
{
public:
//...
private:
int val;
char bit1;
};
class Concrete2 : public Concrete1
{
public:
//...
private:
char bit2;
};
class Concrete3 : public Concrete2
{
public:
//...
private:
char bit3;
}
記憶體布局如下:
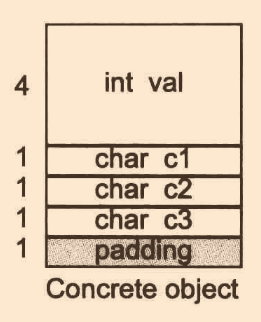
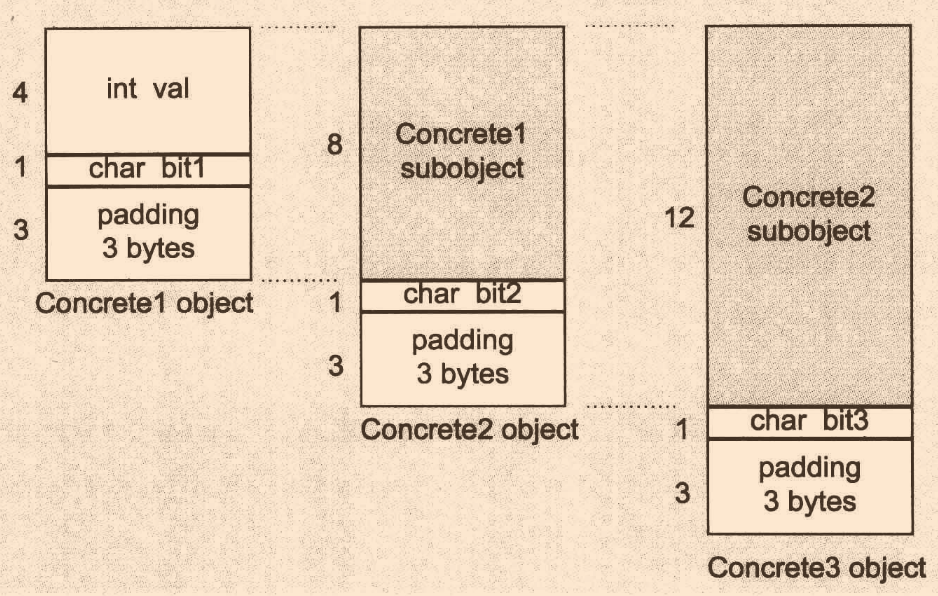
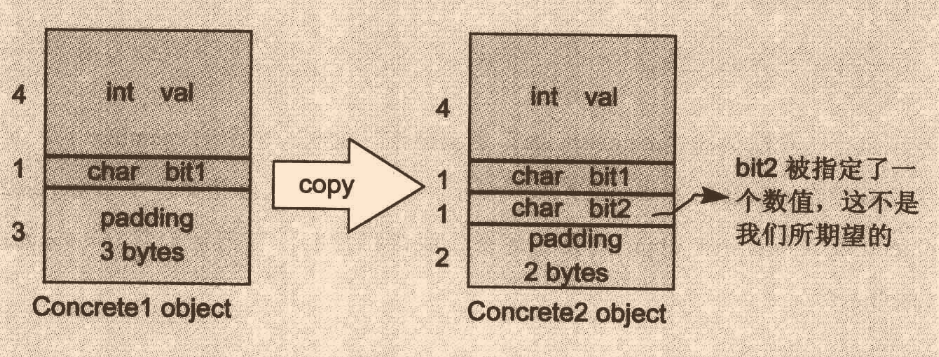
Concrete1內含val和bit1,總共5bytes,還需3bytes用作記憶體對齊,目前看著很正常;問題出現在Concrete2,大多數人會認為Concrete2記憶體只占了5bytes,于是加上一個bit2的1bytes和記憶體對齊2bytes,為8bytes,大錯特錯!這里應該是算對齊后的8bytes + bit2的1bytes + 3bytes的記憶體對齊,因此為12bytes
也許你會認為這太愚蠢了!這不白白多浪費了嗎?但你知道這么設計的緣由嗎?
我們繼續上面那個例子:
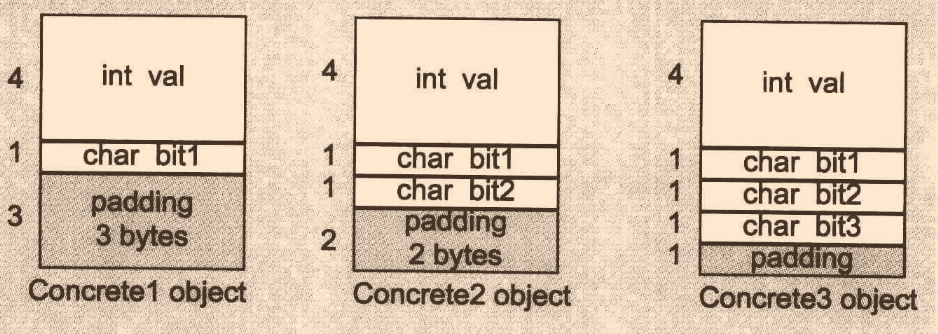
//現有一組指標,這三個指標可以指向前面三種任意class物件的對應部分
Concrete2* pc2;
Concrete1* pc1_1, pc1_2;
//這會導致Concrete1派生類sub object被覆寫,這個時候你應該能意識到為什么要這么設計了
pc1_1 = pc2;
*pc1_2 = *pc1_1;
若不這么設計,結果如下,這個bug都不好找!
- 單一繼承與多型
接著以上的例子,若要處理一個坐標點,并不在乎其具體是point2d或是point3d實體,實作方法是提供虛函式介面,這樣子類可以重寫這個方法表現不同的特性
改變如下:
class Point2d
{
public:
Point2d(float x = 0.0, float y = 0.0) : _x(x), _y(y) { };
virtual float z() { return 0.0; }
virtual void z(float) { }
virtual void operator+=(const Point2d& rhs)
{
_x += rhs.x();
_y += rhs.y();
}
protected:
float _x, _y;
};
class Point3d : public Point2d
{
public:
Point3d(float x = 0.0, float y = 0.0, float z = 0.0) : Point2d(x, y), _z(z) {}
float z() override { return _z; }
void z(float newZ)override { _z = newZ; }
void operation += (const Point2d & rhs) override
{
Point2d::operator+=(rhs);
_z += rhs.z();
}
protected:
float _z;
}
void func( Point2d& p1, Point2d& p2 ) //p1和p2可以為Point2d或Point3d
{
//...
p1 += p2;
}
想要支持多型這種彈性,勢必帶來空間和時間上的額外負擔,這些額外負擔如下:
- 虛函式表,存放虛函式地址和slots(支持運行期型別識別runtime type identification)
- 每個class 物件匯入一個vptr
- 加強建構式,在其中設定vptr的初值,使其指向當前class對應的virtual table
- 加強解構式,在其中抹去vptr
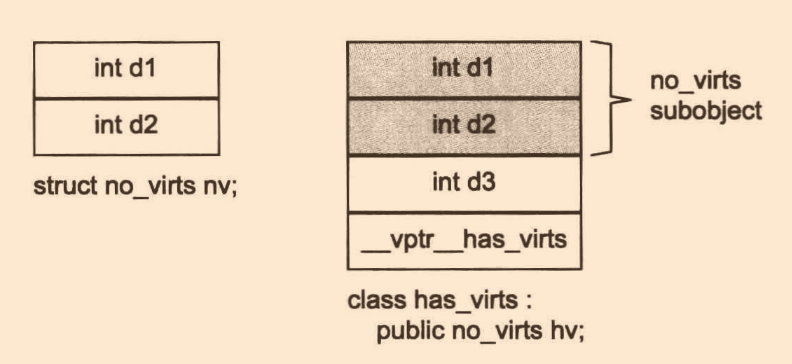
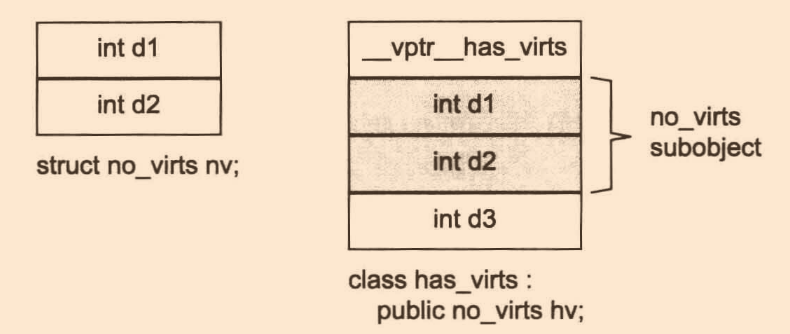
在c++最開始時,vptr一般放于class object尾端,如此可以保留基類class C struct的物件布局,放在c中亦可使用;但當后面需要支持虛擬繼承及抽象基類,微軟的vc++的編譯器將vptr放于class物件的開頭處,這對于通過指向class成員的指標呼叫虛函式是有益的
來看一個例子:
struct no_virts
{
int d1, d2;
};
class has_virts : public no_virts
{
public:
virtual void foo();
//...
private:
int d3;
};
no_virts* p = new has_virts;
記憶體布局如下:
多重繼承與多型
單一繼承不含virtual的情況下,基型別別和派生型別別之間的轉換(無論繼承串鏈多深),不需要編譯器去修改地址,發生的很自然,執行效率也很高,比如上面例子中,基類Point2d和派生類Point3d物件的地址開始的出都是相同的,不同之處是派生類更大
對于以下操作,只需將派生類物件地址賦給基類的指標或參考,不需要進行計算:
Point3d p3d;
Point2d* p = &p3d;
但是當基類沒有虛函式而派生類有,這一特性將不再生效,編譯器需要介入調整地址,若既是多重繼承又是虛擬繼承,更是如此
多重繼承的問題發生在派生類物件和其第二或后繼的基類物件間的轉換
來看一個例子:
class Point2d
{
public:
//含有virtual函式
protected:
float _x, _y;
};
class Point3d : public Point2d
{
public:
//...
protected:
float _z;
};
class Vertex
{
public:
//含有virtual函式
protected:
Vertex* next;
};
class Vertex3d : public point3d, public Vertex
{
public:
//...
protected:
float mumble;
};
Vertex3d v3d;
Vertex* pv;
Point2d* p2d;
Point3d* p3d;
pv = &v3d;
//內部轉換 pv = (Vertex*)( ( (char*)&v3d ) + sizeof(Point3d) );
//無需轉換
p2d = &v3d;
p3d = &v3d
Vertex3d* pv3d;
Vertex* pv;
//若想進行指標的指定操作,還需加個判斷
pv = pv3d ? (Vertex*)((char*)pv3d) + sizeof( Point3d ); //pv3d可能為野指標
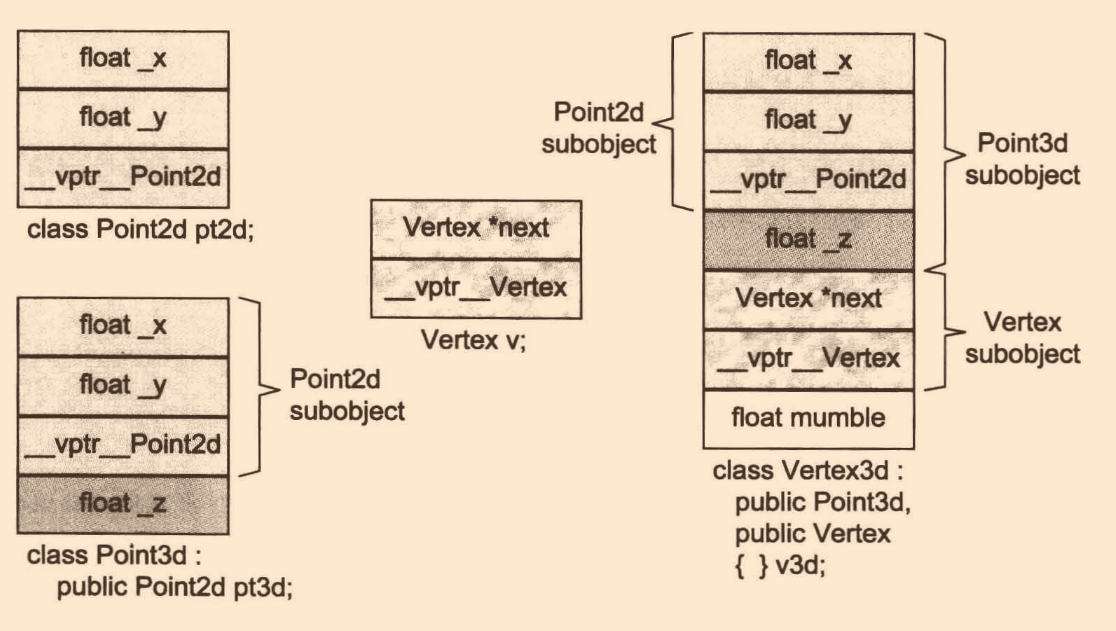
若要存取第二個或后繼的基類的資料成員,不需要付出額外成本,因為成員位置的offset在編譯期就確定了
c++并未要求派生類Vertex3d中,基類Point3d和Vertex按照特定的順序排列,具體順序還是按照編譯器排列,不過大多數是根據宣告順序來排列
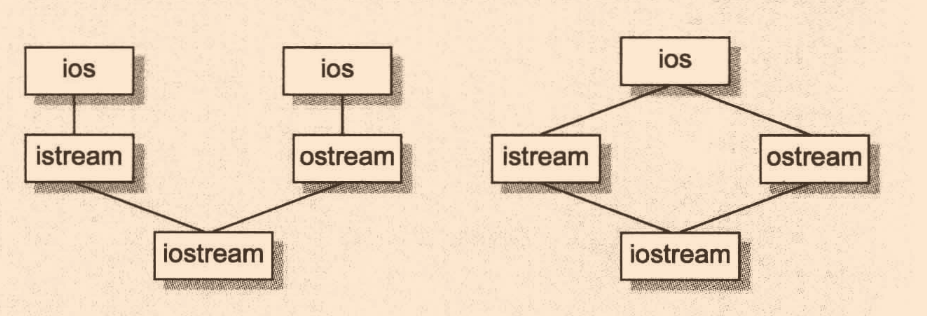
虛擬繼承
多重繼承有個問題,比如如下的iostream,istream和ostream都派生自ios,則會導致各自擁有一個ios,這不是浪費了記憶體嗎?
針對這一問題,虛擬繼承可以完美的支持,但背后的實作難度是頗高,需要將他們各自的ios折疊為一個,還能支持基類和派生類的指標之間的多型指定操作
//對應如下左圖
class ios {...};
class istream : public ios {...};
class ostream : public ios {...};
class iostream : public istream, public ostream {...};
//對應如下右圖
class ios {...};
class istream : virtual public ios {...};
class ostream : virtual public ios {...};
class iostream : public istream, public ostream {...};
實作方法如下.class若內涵一個或多個虛基類subobjects,將被分割為兩部分:前一個不變區域和后一個共享區域,先放置好不變區域,再放置共享區域
- 不變區域:含有固定的offset,不受影響,可以直接存取,其實就是除開虛基類那部分
- 共享區域:也就是虛基類subobjects,這一區域會受每次派生操作影響而變化,只可以被間接存取,什么叫派生操作呢?因為不變區域在前,共享區域在后,每次派生不變區域本擁有的subobjects是不會改變的,會在不變區域的最后放入當前派生類的資料成員,然后在這之后才是共享區域
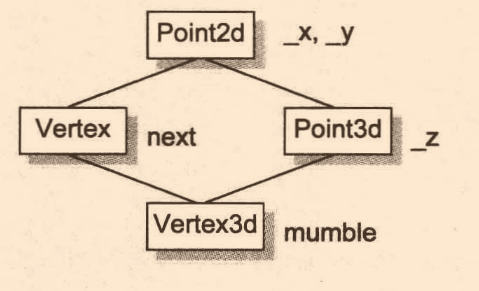
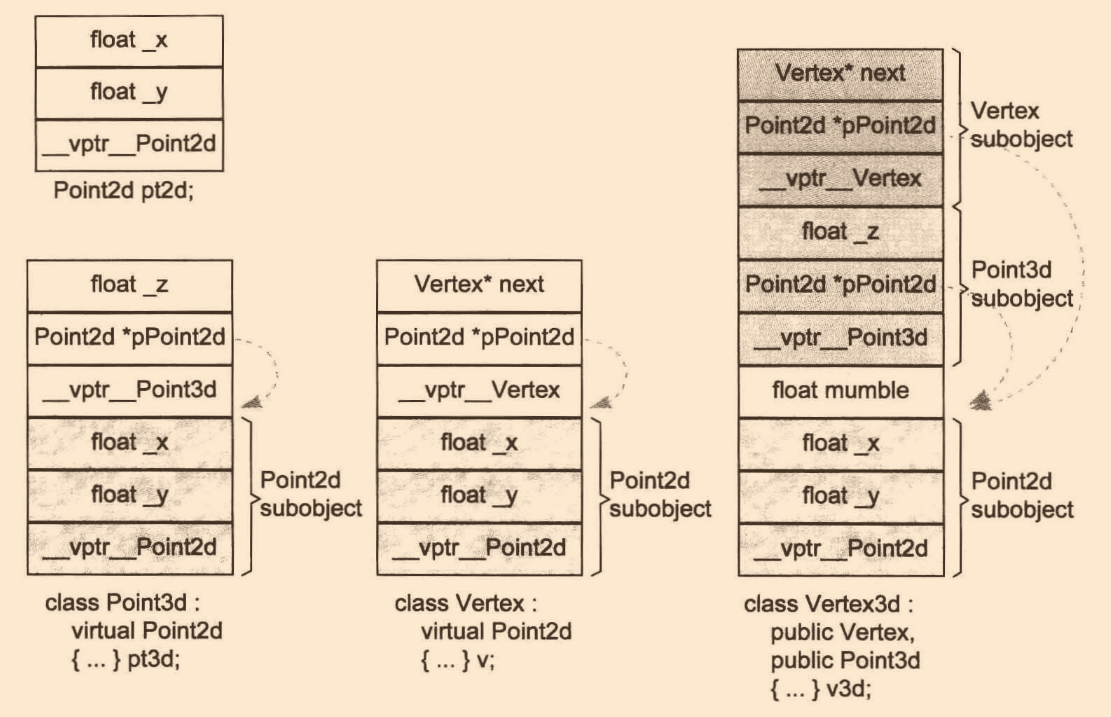
不同編譯器對于共享區域的實作是不同的,我們來看看實作策略:
class Point2d
{
public:
//...
protected:
float _x, _y;
}
class Point3d : virtual public Point2d
{
public:
//...
protected:
float _z;
}
class Vertex : virtual public Point2d
{
public:
//...
protected:
Vertex* next;
}
class Vertex3d : public Vertex, public Point3d
{
public:
//...
protected:
float mumble;
}
繼承體系:
這存在一個問題:如何存取共享部分呢?cfront編譯器是在每個派生物件中安插一些指標,每個指標指向一個虛基類,通過這些指標來存取虛基類成員
比如:
void Point3d::operator+=( const Point3d& rhs )
{
_x += rhs._x;
_y += rhs._y;
_z += rhs._z;
}
//cfront的轉換
//vbc為虛基類
__vbcPoint2d->_x += rhs.__vbcPoint2d->_x;
__vbcPoint2d->_y += rhs.__vbcPoint2d->_y;
_z += rhs._z;
//派生類與基類的轉換
Point2d* p2d = pv3d;
//進行如下轉換
Point2d* p2d = pv3d ? pv3d->__vbcPoint2d : 0;
這種實作模型有兩個缺點:
- 每個class背負一些指向對應的虛基類地址的額外指標,隨著虛基類個數的增長,這個指標也會變多,理想情況下是一個指標
- 隨著虛擬繼承串鏈的變長,導致間接存取層次的增加.比如三層虛擬派生,則需要經由三個虛基類指標進行間接存取,比如,假設Vertex也是虛擬繼承,Vertex3d內有一個指標,這個指向Vertex,再指向Point2d.理想情況是固定存取時間
對于第二點的改進方法是拷貝所有虛基類指標,再放在派生類中,不過這會導致空間換時間
改善后的記憶體布局:
對于第一點來說,有兩種實作方案:
-
在虛函式表中存放虛基類的offset,虛函式表經由正負來索引虛函式和虛基類,若為正值,則是索引虛函式;為負,則是索引虛基類
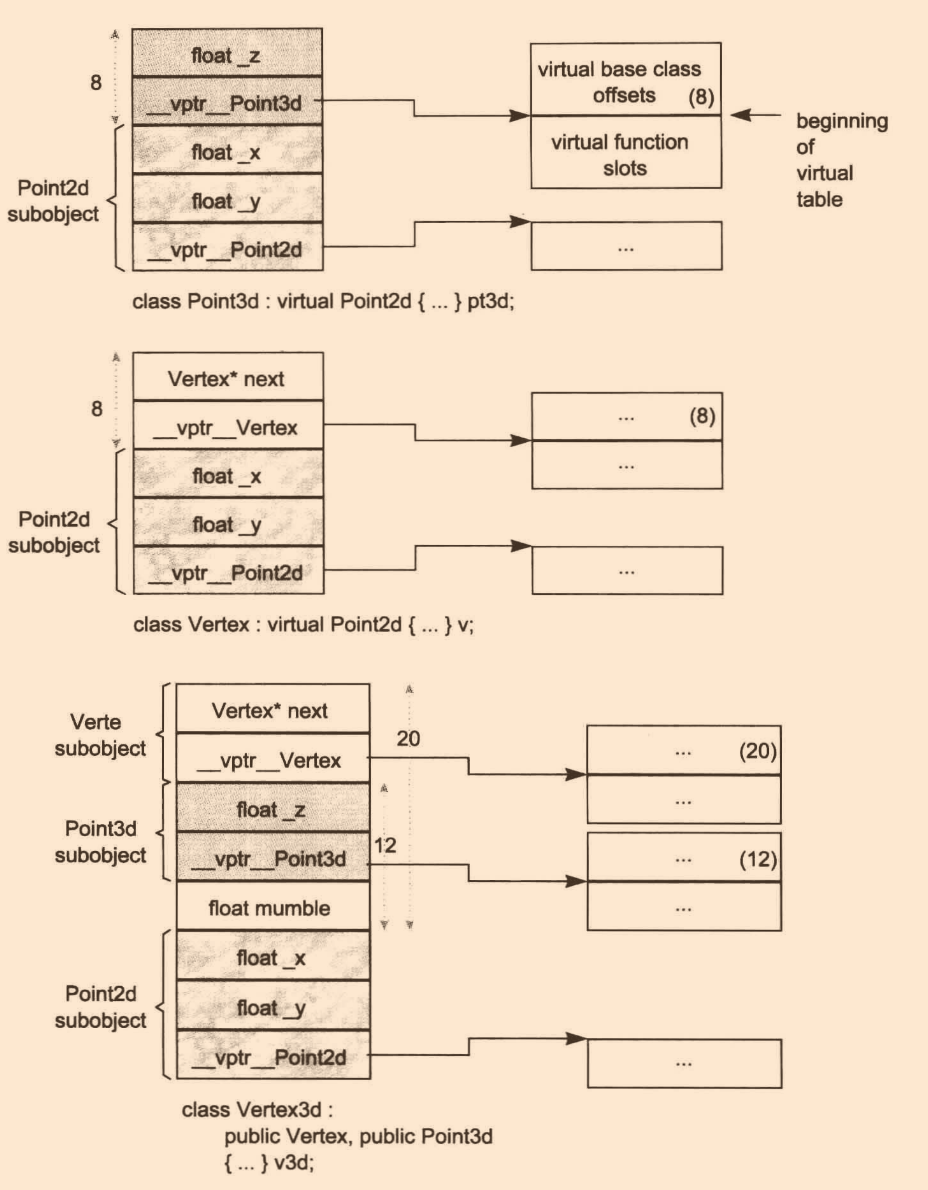
-
vc++引入虛基類表,這些虛基類表存放的是指向對應虛基類的指標,再在class的開頭處放置一個vbptr,這個指標指向虛基類表
成員函式
成員函式的呼叫方式
c++支持三種型別的member functions:static、nonstatic、virtual,且每一種呼叫方式不盡相同
-
nonstatic成員函式
呼叫成員函式時,編譯器會把成員函式轉換為非成員的形式,步驟如下:
-
向函式原型中安插一個額外引數this指標
-
對nonstatic資料成員的存取操作將改為由this指標來存取
-
對成員函式的名稱進行符號改編(name mangling)
為了防止多載和名稱沖突,資料成員和成員函式進行name mangling.一般而言,member的名稱前會加上class名稱,形成獨一無二的命名;而member function則還需加上引數鏈表
舉個例子:
class Bar{ public: int ival; } //ival可能的轉化 ival_3Bar; class Point { public: void x( float newX ); float x(); } //可能的轉化 void x__5PointFf( float newX ); float x__5PointFv();
-
-
虛函式
若func()為虛函式,對它的呼叫可能的轉化如下:
ptr->func(); //轉化 (*ptr->vptr[1])(ptr);轉化規則:
- vptr為編譯器生成的指標,指向虛函式表,也會進行namemangling
- [1]為虛函式表的slots,1為索引值
- prt表示this指標
-
static成員函式
static成員函式的特性:
- 沒有this指標,成為一個callback函式
- 不可直接存取class中的nonstatic members
- 不可被宣告為const、volatile、virtual
- 不需要經由class object呼叫
static 成員函式同樣也有name mangling
對static成員函式取地址,得到的是記憶體中的地址;由于沒有this指標,static member function地址型別是一個nonmember函式指標
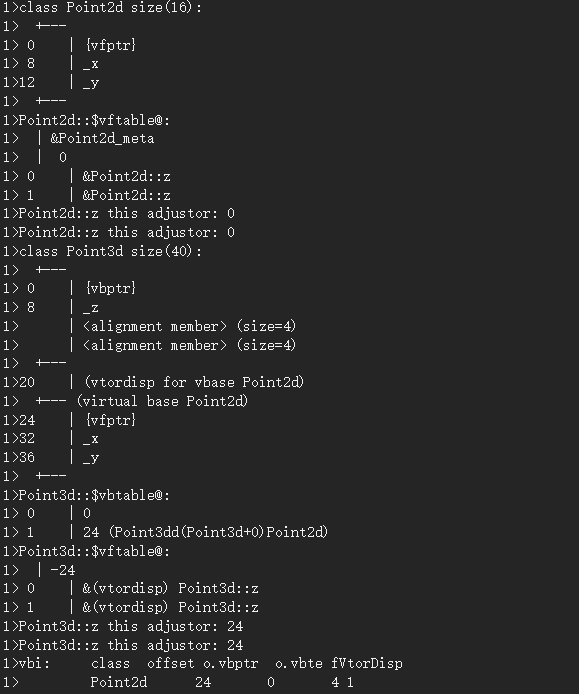
虛函式
單一繼承
為支持虛函式機制,必須能對于多型物件有一種"執行期型別判斷法"(RTTI),有了RTTI就可以在執行期查詢一個多型的pointer或參考
//以下呼叫需要ptr指標執行期的資訊
ptr->z();
RTTI鑒定一個class是否展現多型特性是通過查看它是否有虛函式,這就是RTTI進行判斷需要的額外資訊
那么究竟什么具體的額外資訊我們需要存盤?有以下兩個:
- ptr所指物件的真實型別.如此才能選擇正確的函式實體
- 函式的位置.如此才能呼叫它
具體的實作只需在每個class物件中增加兩個成員:
- 一個字串或數字,表示class型別
- 一個指標,指向一表格(陣列),表格中含有虛函式執行期地址.這一地址在編譯期即可得知,且固定不變
隨后只需兩步即可找到其地址:
- 每個class 物件安插一個由編譯器生成的指標,該指標指向表格
- 每個虛函式被指派一個表格索引值
以上作業都由編譯器完成,執行期要做的只是在特定的虛函式表的slot中呼叫虛函式
一個class只有一個虛函式表,同一個類的所有物件都使用同一個虛表,每個表內含對應的class物件中的active 虛函式實體地址,active 虛函式又包括:
- 這一class定義的函式實體
- 繼承自基類的函式實體
- 一個pure virtual called函式
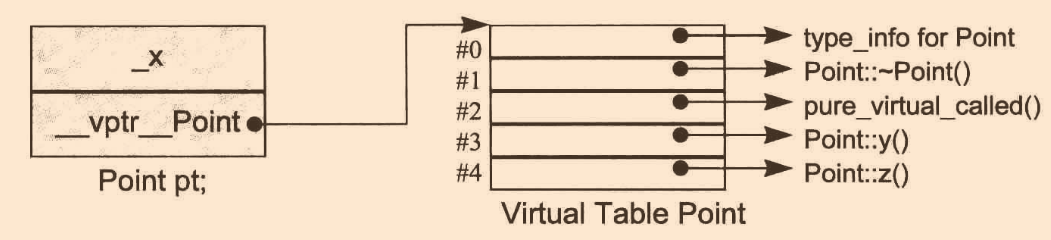
來看一個例子:
class Point
{
public:
virtual~Point();
virtual Point& mult(float) = 0;
float x() const { return _x; }
virtual float y() const { return 0; }
virtual float z() const { return 0; }
protected:
Point(float x = 0.0);
float _x;
};
對應的記憶體布局,pure_virtual_called是純虛函式:
讓我們再來看看一個class派生自基類,對于class來說虛函式又如何表現,有三種可能性:
- 派生類可以繼承基類所定義的虛函式,也可以說該函式實體的地址會被拷貝到派生類的虛函式表的相對應slot
- 派生類可以對基類的虛函式進行重寫,定義自己的版本
- 派生類可以寫入一個新的虛函式,虛函式表會增大一個slot,來容納這個新的虛函式
來看個例子:
class Point2d : public Point
{
public:
Point2d( float x = 0.0, float y = 0.0 ) : Point(x), _y(y) {}
~Point2d();
Point2d& mult( float );
float y() const { return _y; }
//...
protected:
float _y;
}
記憶體布局:
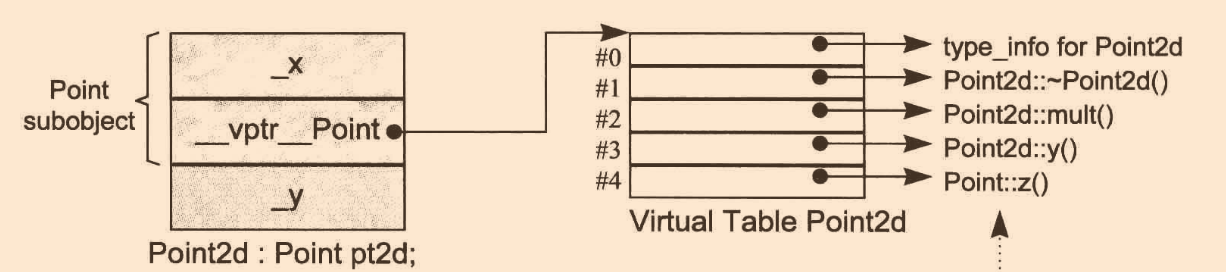
現在回歸到最開始的那個例子:
ptr->z()
在編譯期以下資訊來設定這個虛函式的呼叫:
- 雖然不知道ptr型別,但知道經由ptr可以存取物件的虛函式表
- 雖然不知道具體呼叫的哪個版本的虛函式,但知道虛函式在表中固定的slot
可能的轉化:
//假設虛函式的固定slot為4
(*ptr->vptr[4])(ptr)
多重繼承
多重繼承的虛函式實作將比單一繼承復雜不少,主要表現在第二個及后繼的基類,以及必須在執行期調整指標
先來看一個程式片段:
class Base1
{
public:
Base1();
virtual~Base1();
virtual void speakClearly();
virtual Base1* clone() const;
protected:
float data_Base1;
};
class Base2
{
public:
virtual~Base2();
virtual void mumble();
virtual Base2* clone() const;
protected:
float data_Base2;
};
class Derived : public Base1, public Base2
{
public:
Derived();
virtual ~Derived();
virtual Derived* clone() const;
protected:
float data_Derived;
};
在這里,我們將heap配置得到的Drieved物件的地址指定給Base2指標,它的new和delete都需要編譯器進行offset計算,但是deleted的offset計算無法在編譯期設定,因為指標指向的物件只有在執行期才能確定:
Base2* pbase2 = new Derived;
//new可能的轉化
Derived* temp = new Derived;
Base* pbase2 = temp ? temp + sizeof(Base1) : 0;
//delete可能進行轉化,也可能不用,因為delete一個class物件,需要先析構再呼叫delete,而這里解構式是虛函式,需要將指標指向Derived開頭處
delete pbase2;
也就是說,在這里我們需要必須確定offset,以及調整this指標,這需要由編譯器在某個地方插入,但問題是在哪里?如何實作?
對此,c++引入thunk技術來支持多型的多重繼承,簡單來說,所謂thunk是一小段匯編(assembly)代碼,它有兩個用處:
-
以適當的offset值調整this指標
-
跳到虛函式去
例如:
//由Base2指標呼叫Derived解構式,可能的thunk pbase2_dtor_thunk: this += sizeof( base1 ); Derived::~Derived( this );thunk技術下,虛函式表的slot繼續內含一個簡單的指標.若需要調整this指標,則指向一個相關thunk;若不需要,則直接指向虛函式
我們知道在單一繼承下,一個class只含有一個虛函式表,而在多重繼承下,一個派生類內含n-1個額外的虛函式表,n表示上一層基類的個數
這些表格型別分為兩種:
- 主要表格,基類中最左端的,Base1
- 次要表格,基類中第二個以以后的,Base2
用以支持"一個class擁有多個虛函式表"的方法:將每個表以外部物件的形式產出,并給予獨一無二的名稱
//可能的名稱 vtbl__Derived; //主要表格 vtbl__Base2__Derived; //次要表格我們將當前派生類物件的地址指定給最左端的基類或當前派生類的指標時,被處理的是主要表格;而將當前派生類物件的地址指定給第二個及以后的基類的指標時,被處理的是次要表格
舉個例子:
Base1* pt1 = new Derived; //主要表格 Derived* ptD = new Derived; //主要表格 Base2* pt2 = new Derived; //次要表格記憶體布局:
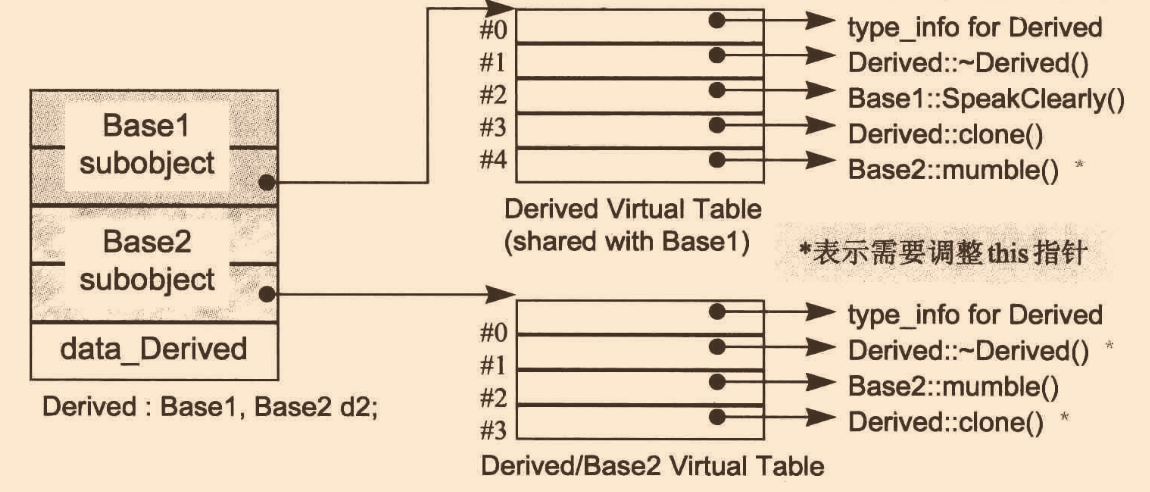
這樣執行會非常慢,可行的優化方案是將多個虛函式表連鎖為一個,指向次要表格的指標,由主要表格的地址加上一個offset獲得
現在,回到最開始的問題,第二個或后繼的基類會影響對虛函式的支持,有三種情況:
-
通過一個指向第二個基類的指標,呼叫派生類虛函式
例如:
Base2* ptr = new Derived; //如上圖得知,派生類的虛函式在主要表格中,因此ptr必須進行offset計算,指向derived開頭處 delete ptr; -
通過一個指向基類的指標,呼叫第二個基類中繼承而來的虛函式
例如:
Derived* pder = new Derived; //mumble屬于次要表格,需要offset pder->mumble(); -
因為虛函式的回傳值,需要改變指標指向
例如:
Base2* pb1 = new Derived; //調整pb1指向次要表格,但clone()屬于主要表格的,需要進行offset Base2* pb2 = pb1->clone();
不要在virtual base class中宣告nonstatic data members
同一個函式在不同的模型下執行,在編譯器優化的情況下,nonmember, static member nonstatic member他們的效率完全相同
inline函式
inline關鍵詞只是一個請求,若此請求被編譯期接受,編譯期則認為其可以用一個運算式將函式展開
inline函式的復雜度通過計算assignments、function calls、virtual function calls等操作的次數以及每個運算式種類的權值綜合決定
若函式因其復雜度或建構問題,被判斷不可稱為Inline,那么此函式將被轉換為static函式,并在"被編譯模塊"內產生對應的函式定義
inline function展開期間,做了以下兩件事:
-
每個形參都被對應的實參取代,但這其中可能會導致實際引數的多次求值,面對這種情況,需要引入臨時物件,比如,若實際引數是常量運算式,在替換前先引入臨時物件,常量運算式求值后賦值給臨時物件,后繼inline替換只需使用臨時物件
例子:
inline int min( int i, int j ) { return i < j ? i : j; } inline int bar() { int minval; minval = min( foo(), bar() + 1 ); return minval; } //minval = min( foo(), bar() + 1 )展開 int t1, t2; minval = ( t1 = foo() ), ( t2 = bar() + 1 ), t1 < t2 ? t1 : t2; -
若內含區域變數,則需將區域變數放在函式呼叫的一個封閉區段,且擁有一個獨一無二的名稱,因為,如果Inline以單一運算式的方式擴展多次,每次擴展都需要自己的區域變數,特別是還含有副作用引數,可能會導致大量臨時性物件產生;但如果是分離成多個式子擴展多次,只需一組區域變數即可重復使用
例子:
inline int min( int i, int j ) { int minval = i < j ? i : j; //區域變數 return minval; } { ... //minval = min(val1, val2); int __min_lv_minval; minval = (__min_lv_minval = val1 < val2 ? val1 : val2), __min_lv_minval; }
盡量不要Inline中套inline,可能會使簡單的Inline因其連鎖復雜度而沒辦法展開
指向成員函式的指標
取一個nonstatic成員函式的地址,若該函式不是虛函式,得到的結果是記憶體中的地址,但這個值不完全,還需要物件的地址
通過一個指向成員函式的指標來呼叫它,會進行轉化
例子:
double ( A::* pt )(); //宣告
double (A::*pt)() = &A::x; //初始化指標
//兩種呼叫
(a.*pt)();
(ptr->*pt)();
//轉化
(pt)(&a);
(pt)(ptr);
可以看出指向member function的指標和指向member selection operator的指標,其作用是作為this指標的空間保留者,這也說明了為什么static member function的指標型別是函式指標,畢竟其沒有this指標
使用member function指標,若不用于virtual function、多重virtual繼承、virtual base class,其成本不必用nomember function指標高
虛擬成員函式的地址在編譯期是未知的,我們所能知道的僅是虛函式在其相關之虛函式表的slots.因此對一個class的虛函式取地址,結果是其slots
絕不重新定義繼承而來的非虛函式
先來看個例子:
class B
{
public:
void mf();
};
class D : public B
{
void mf(); //覆寫基類的mf()
};
D d;
B* pB = &d;
pB->mf(); //呼叫B版本的
D* pD = &d;
pD->mf(); //呼叫D版本的
發生如上現象的原因是,public繼承說明,每個派生類的非虛函式一定會繼承基類的介面和實作,非虛函式采用的是靜態系結.那么,由于pB為指向B型別的指標,pb呼叫的非虛函式的版本永遠是B型別的
絕不重新定義繼承而來的預設引數值
原因和上一條類似,因為預設引數值是靜態系結,而虛函式才是動態系結
靜態型別是程式中被宣告時采用的型別;動態型別是目前指標或參考所指物件的型別
抽象基類
現有如下片段:
class Abstract_base
{
public:
virtual ~Abstract_base() = 0;
virtual void interface() const = 0;
virtual const char* mumble() const { return _mumble; }
protected:
char* _mumble;
}
以上抽象基類宣告有幾個問題:
- 即使class被宣告為抽象基類,其依然需要explicit constructor來初始化protected data member _mumble,否則derived class無法決定_mumble初值
- 抽象基類的virtual destructor不要宣告為pure,因為每個derived class destructor會被編譯器擴張,以靜態方式呼叫每個virtual base class和上一層base class的destructor
- mumble()不應宣告為virtual function,因為其定義的內容和型別無關,derived class并不會改寫此函式
合理的宣告如下:
class Abstract_base
{
public:
virtual ~Abstract_base();
virtual void interface() = 0;
const char* mumble() const { return _mumble; }
protected:
Abstract_base( char* pc = 0 );
char* _mumble;
}
一般而言,class的data member應被初始化,且只在constructor中或在class的其他member function中指定初值,其他操作都會破壞封裝性質,讓class的維護和修改變得愈加困難
我們可以定義和呼叫一個pure virtual function,不過它只能被靜態的呼叫,但不能經由虛擬機制
c++保證繼承體系中每個class object的destructors都能被呼叫,編譯期不可壓抑這一操作,且編譯器并沒有足夠知識合成pure virtual destructor函式定義
虛擬基類中,不要把所有的member functions都宣告為virtual function,再靠編譯器的優化把非必要的虛擬呼叫去除
虛擬基類中,virtual function盡量不要宣告為const
區分介面繼承和實作繼承
public繼承由函式介面繼承和函式實作繼承構成,是"is-a"的關系
純虛函式有兩個性質:
-
派生類必須重新定義基類的版本
-
在基類中通常不提供定義,但并非不可以,它可以提供一個默認預設,防止派生類忘記定義自己的版本
例子:
class Airport { ... }; // represents airports class Airplane { public: virtual void fly(const Airport& destination); ... }; void Airplane::fly(const Airport& destination) { default code for flying an airplane to the given destination } class ModelA: public Airplane { ... }; //若ModelA忘記定義自己版本的虛函式,將呼叫基類版本 Airport PDX(...); Airplane *pa = new ModelC; ... pa->fly(PDX); //基類版本為了避免上例的失誤,我們可以做如下改動:
//將fly宣告為抽象基類,并提供一個默認行為的普通函式,這樣派生類必須自己宣告一個 class Airplane { public: virtual void fly(const Airport& destination) = 0; ... protected: void defaultfly( const Airport& destination ); //默認行為 }; class ModelA : public Airplane { public: virtual void fly(const Airport& destination) { defaultfly(destination); } }
?
? 宣告?個純虛函式的目的是讓派生類只繼承函式介面,讓他們根據自身定義適合自己的版本
? 宣告非純虛函式的目的是讓派生類繼承基類版本的介面和預設實作,且必須支持一個虛函式,若不想重寫,可以呼叫基類提供的預設版本
? 宣告非虛函式的目的是讓派生類繼承函式介面和一份強制性實作,任何派生類都不能修改這類函式
友元
class可以允許其他class或函式訪問它的非公有成員,方法是讓這些class或函式稱為它的友元(friend)
在class定義中,使用 friend 關鍵字和非成員函式或其他class的名稱,以允許其訪問類的私有和受保護成員
宣告
一般來說,最好的class定義開始或結束前的位置集中宣告友元
friend 宣告中宣告的函式被視為使用 extern 關鍵字宣告
全域函式可以在其原型之前宣告為 friend函式,但是成員函式在它們的完整類宣告出現前不能宣告為friend函式
void func();
class B;
class A
{
public:
friend void B::funcB(); //不合法,我們只是宣告B,還沒定義funcB成員函式
};
//改成這樣就沒問題
class B
{
public:
void funcB();
};
在 C++11 中,一個類有兩種形式的友元宣告
friend class F;
friend F;
如果最內層的命名空間中找不到任何具有該名稱的現有類,則第一種形式引入新的類 F;第二種形式不引入新的類,當將 typedef 宣告為 friend 時,必須使用該形式
在參考型別尚未宣告時使用 friend class F:
namespace NS
{
class M
{
friend class F; // 參考F沒有定義它
};
}
如果使用尚未宣告的class型別為 friend,則會報錯:
namespace NS
{
class M
{
friend F; // error C2433: 'NS::F': 'friend' not permitted on data declarations
};
}
class F {};
namespace NS
{
class M
{
friend F; // 合法
};
}
用于 friend F 將 typedef 宣告為友元:
class Foo {};
typedef Foo F;
class G
{
friend F; // 合法
friend class F // Error C2371 -- redefinition
};
若要宣告兩個互為友元的類,則必須將整個第二個類指定為第一個類的友元
友元函式
friend函式是一個不為class成員的函式,但它可以訪問class的private和protected的成員, 友元函式不被視為class成員,它們是獲得了特殊訪問權限的普通外部函式
友元不在class的范圍內,除非它們是另一個class的成員,否則不會使用成員select運算子(. 和 ->)呼叫它們
friend 函式由授予訪問權限的class宣告, 可將 friend宣告放置在class宣告中的任何位置, 它不受訪問控制關鍵字的影響
例子:
//普通函式
class Point
{
friend void ChangePrivate( Point & );
public:
Point( void ) : m_i(0) {}
void PrintPrivate( void ){cout << m_i << endl; }
private:
int m_i;
};
void ChangePrivate ( Point &i ) { i.m_i++; }
//類的成員函式
class A {
public:
int Func1( B& b );
private:
int Func2( B& b );
};
class B {
private:
int _b;
// A::Func1 is a friend function to class B
// so A::Func1 has access to all members of B
friend int A::Func1( B& );
};
class
friend class是宣告為friend的所有成員函式都是另一個class的friend函式 的class,也就是說宣告為friend class的成員函式具有對另一個class的私有成員和受保護成員訪問權限
友元關系不能繼承
可以在class宣告中定義友元函式,,這些函式是inline函式, 類似于成員行內函式,其行為就像它們在所有class成員顯示后但在類范圍結束前(在類宣告的結尾)被定義時的行為一樣, 類宣告中定義的友元函式在封閉類的范圍內
例子:
class YourClass {
friend class YourOtherClass;
public:
YourClass() : topSecret(0){}
void printMember() { cout << topSecret << endl; }
private:
int topSecret;
};
class YourOtherClass {
public:
void change( YourClass& yc, int x ){yc.topSecret = x;}
};
型別轉換
轉換可以是顯式(通過呼叫從一個型別轉換為另一個型別時,例如強制轉換或直接初始化的情況),也可以是隱式(當語言或程式呼叫其他型別而非程式員給定的型別時)
以下將發生隱式轉換:
- 函式的形參和實參型別不同
- 函式的回傳值與函式本來定義的回傳值的型別不同
- 初始值運算式與其初始化的物件的型別不同
- 用于控制條件陳述句、回圈構造或切換的運算式不具有對其進行控制時所需的結果型別
- 提供給運算子的運算元與匹配的運算元引數的型別不同, 對于內置運算子,這兩個運算元的型別必須相同,并且要轉換為可表示它們的常規型別
建構式的轉換
默認情況下,當創建用戶定義的轉換時,編譯器可使用它來執行隱式轉換, 有時這是你需要進行的操作,但另一些時候用于指導編譯器進行隱式轉換的簡單規則會使其接受你不希望接受的代碼
例子:
#include <iostream>
class Money
{
public:
Money() : amount{ 0.0 } {};
Money(double _amount) : amount{ _amount } {};
double amount;
};
void display_balance(const Money balance)
{
std::cout << "The balance is: " << balance.amount << std::endl;
}
int main(int argc, char* argv[])
{
Money payable{ 79.99 };
display_balance(payable); //不發生轉換
display_balance(49.95); //發生轉換,因為Money有引數為double型別得建構式,他會先構造一個Money物件,再呼叫display_balance
display_balance(9.99f); //先執行一次標準轉換,再執行用戶定義的轉換
return 0;
}
class型別能定義由編譯器自動執行的轉換,不過編譯器每次只能執行一種class型別的隱式轉換:
class A
{
public:
A() : str("0") {};
A(std::string temp) : str(temp) {};
void func(A a) { ; }
private:
std::string str;
};
A a;
a.func("000"); //不合法
宣告轉換建構式的規則:
- 轉換的目標型別是要構造的用戶定義的型別
- 轉換建構式通常僅采用一個引數,它為源型別, 但是,當每個附加引數都具有默認值時,轉換建構式可指定這些附加引數, 源型別保留了第一個引數的型別
- 與所有建構式一樣,轉換建構式不指定回傳型別
- 轉換建構式可以為顯式
禁用建構式的轉換:explicit 關鍵字會告知編譯器指定的轉換不能用于執行隱式轉換, explicit可以創建簡便的轉換,它們只能用于執行顯式強制轉換或直接初始化
例子:
#include <iostream>
class Money
{
public:
Money() : amount{ 0.0 } {};
explicit Money(double _amount) : amount{ _amount } {};
double amount;
};
void display_balance(const Money balance)
{
std::cout << "The balance is: " << balance.amount << std::endl;
}
int main(int argc, char* argv[])
{
Money payable{ 79.99 };
display_balance(payable); // 合法
display_balance(49.95); // 不合法,已經禁用了隱式轉換,Error: no suitable conversion exists to convert from double to Money.
display_balance((Money)9.99f); // 合法,顯式轉換
return 0;
}
普通的成員函式一個道理
reference
知識星球 | 深度連接鐵桿粉絲,運營高品質社群,知識變現的工具 (zsxq.com)
C++解構式詳解 (biancheng.net)
C# 檔案 - 入門、教程、參考, | Microsoft Learn
(25條訊息) 左值和右值_coolwriter的博客-CSDN博客_左值
從4行代碼看右值參考 - qicosmos(江南) - 博客園 (cnblogs.com)
C++11委托建構式 - 騰訊云開發者社區-騰訊云 (tencent.com)
深度探索c++物件模型
c++ primer 5th
c++語言的設計和演化
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/538441.html
標籤:其他
下一篇:Java學習七