一、Kafka存在哪些方面的優勢
1. 多生產者
可以無縫地支持多個生產者,不管客戶端在使用單個主題還是多個主題,
2. 多消費者
支持多個消費者從一個單獨的訊息流上讀取資料,而且消費者之間互不影響,
3. 基于磁盤的資料存盤
支持消費者非實時地讀取訊息,由于訊息被提交到磁盤,根據設定的規則進行保存,當消費者發生例外時候,意外離線,由于有持久化的資料保證,可以實作聯機后從上次中斷的地方繼續處理訊息,
4. 伸縮性
用戶在開發階段可以先試用單個broker,再擴展到包含3個broker的小型開發集群,然后隨著資料量不斷增長,部署到生產環境的集群可能包含上百個broker,
5. 高性能
Kafka可以輕松處理巨大的訊息流,在處理大量資料的同事,它還能保證亞秒級的訊息延遲,
二、Kafka常見的使用場景
1. 訊息
kafka更好的替換傳統的訊息系統,訊息系統被用于各種場景(解耦資料生產者,快取未處理的訊息等),與大多數訊息系統比較,kafka有更好的吞吐量,內置磁區,副本和故障轉移,這有利于處理大規模的訊息,
根據我們的經驗,訊息往往用于較低的吞吐量,但需要低的端到端延遲,并需要提供強大的耐用性的保證,
在這一領域的kafka比得上傳統的訊息系統,如ActiveMQ或RabbitMQ等,
2. 網站活動追蹤
kafka原本的使用場景是用戶的活動追蹤,網站的活動(網頁游覽,搜索或其他用戶的操作資訊)發布到不同的話題中心,這些訊息可實時處理,實時監測,也可加載到Hadoop或離線處理資料倉庫,
3. 指標
kafka也常常用于監測資料,分布式應用程式生成的統計資料集中聚合,
4. 日志聚合
許多人使用Kafka作為日志聚合解決方案的替代品,日志聚合通常從服務器中收集物理日志檔案,并將它們放在中央位置(可能是檔案服務器或HDFS)進行處理,Kafka抽象出檔案的細節,并將日志或事件資料更清晰地抽象為訊息流,這允許更低延遲的處理并更容易支持多個資料源和分布式資料消費,
5. 流處理
kafka中訊息處理一般包含多個階段,其中原始輸入資料是從kafka主題消費的,然后匯總,豐富,或者以其他的方式處理轉化為新主題,例如,一個推薦新聞文章,文章內容可能從“articles”主題獲取;然后進一步處理內容,得到一個處理后的新內容,最后推薦給用戶,這種處理是基于單個主題的實時資料流,從0.10.0.0開始,輕量,但功能強大的流處理,就可以這樣進行資料處理了,
除了Kafka Streams,還有Apache Storm和Apache Samza可選擇,
6. 事件采集
事件采集是一種應用程式的設計風格,其中狀態的變化根據時間的順序記錄下來,kafka支持這種非常大的存盤日志資料的場景,
7. 提交日志
kafka可以作為一種分布式的外部日志,可幫助節點之間復制資料,并作為失敗的節點來恢復資料重新同步,kafka的日志壓縮功能很好的支持這種用法,這種用法類似于Apacha BookKeeper專案,
三、Kafka架構深度剖析
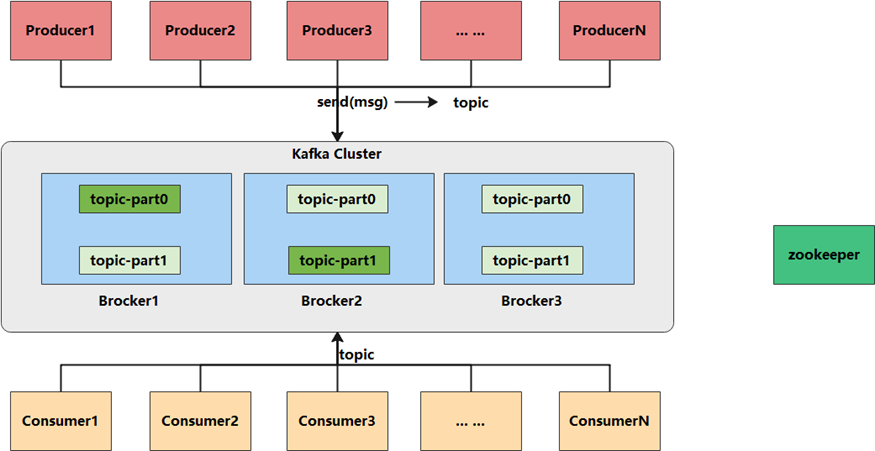
1. Kafka資料處理步驟
1.1 Producer產生訊息,發送到Broker中
1.2 Leader狀態的Broker接收訊息,寫入到相應topic中
1.3 Leader狀態的Broker接收完畢以后,傳給Follow狀態的Broker作為副本備份
1.4 Consumer消費Broker中的訊息
2. Kafka 核心組件
2.1 Producer:訊息生產者,產生的訊息將會被發送到某個topic
2.2 Consumer:訊息消費者,消費的訊息內容來自某個topic
2.3 Topic:訊息根據topic進行歸類,topic其本質是一個目錄,即將同一主題訊息歸類到同一個目錄
2.4 Broker:每一個kafka實體(或者說每臺kafka服務器節點)就是一個broker,一個broker可以有多個topic
2.5 Zookeeper: Zookeeper集群不屬于kafka內的組件,但kafka依賴 Zookeeper集群保存meta資訊,所以在此做宣告其重要性,
3. broker和集群
一個獨立的Kafka服務器稱為broker,broker接收來自生產者的訊息,為訊息設定偏移量,并提交訊息到磁盤保存,broker為消費者提供服務,對讀取磁區的請求作出回應,回傳已經提交到磁盤上的訊息,根據特定的硬體及其性能特征,單個broker可以輕松處理數千個磁區以及每秒百萬級的訊息量,
broker是集群的組成部分,每個集群都有一個broker同時充當了集群控制器的角色(自動從集群的活躍成員中選舉出來),控制器負責管理作業,包括將磁區分配給broker和監控broker,在集群中,一個磁區從屬于一個broker,該broker被稱為磁區的首領,一個磁區可以分配多個broker,這個時候會發生磁區復制,這種復制機制為磁區提供了訊息冗余,如果一個broker失效,其他broker可以接管領導權,不過,相關的消費者和生產者都要重新連接到新的首領,
4. Consumer與topic關系
kafka只支持Topic
? 每個group中可以有多個consumer,每個consumer屬于一個consumer group;通常情況下,一個group中會包含多個consumer,這樣不僅可以提高topic中訊息的并發消費能力,而且還能提高”故障容錯”性,如果group中的某個consumer失效那么其消費的partitions將會由其它consumer自動接管,
? 對于Topic中的一條特定的訊息,只會被訂閱此Topic的每個group中的其中一個consumer消費,此訊息不會發送給一個group的多個consumer;那么一個group中所有的consumer將會交錯的消費整個Topic,每個group中consumer訊息消費互相獨立,我們可以認為一個group是一個”訂閱”者,
? 在kafka中,一個partition中的訊息只會被group中的一個consumer消費(同一時刻);
一個Topic中的每個partions,只會被一個”訂閱者”中的一個consumer消費,不過一個consumer可以同時消費多個partitions中的訊息,
? kafka的設計原理決定,對于一個topic,同一個group中不能有多于partitions個數的consumer同時消費,否則將意味著某些consumer將無法得到訊息,而處于空閑狀態,
kafka只能保證一個partition中的訊息被某個consumer消費時是順序的;事實上,從Topic角度來說,當有多個partitions時,****訊息仍不是全域有序的,
5. Kafka訊息的分發
? Producer客戶端負責訊息的分發
? kafka集群中的任何一個broker都可以向producer提供metadata資訊,這些metadata中包含”集群中存活的servers串列”、“partitions leader**串列”等資訊;
? 當producer獲取到metadata資訊之后, producer將會和Topic下所有partition leader保持socket連接;
? 訊息由producer直接通過socket發送到broker,中間不會經過任何”路由層”,事實上,訊息被路由到哪個partition上由producer客戶端決定,比如可以采用”random””key-hash””輪詢”等,
? 如果一個topic中有多個partitions,那么在producer端實作”訊息均衡分發”**是必要的,
? 在producer端的組態檔中,開發者可以指定partition路由的方式,
? Producer訊息發送的應答機制
設定發送資料是否需要服務端的反饋,有三個值0,1,-1
0: producer不會等待broker發送ack
1: 當leader接收到訊息之后發送ack
2: 當所有的follower都同步訊息成功后發送ack
request.required.acks=0
6. Consumer的負載均衡
當一個group中,有consumer加入或者離開時,會觸發partitions均衡.均衡的最終目的,是提升topic的并發消費能力,步驟如下:
-
假如topic1,具有如下partitions: P0,P1,P2,P3
-
加入group A 中,有如下consumer: C0,C1
-
首先根據partition索引號對partitions排序: P0,P1,P2,P3
-
根據consumer.id排序: C0,C1
-
計算倍數: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
-
然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/538789.html
標籤:Java