引言
盡管 redis 是一款非常優秀的 NoSQL 資料庫,但更重要的是,作為使用者我們應該學會在不同的場景中如何更好的使用它,更大的發揮它的價值,主要可以從這四個方面進行優化:Redis鍵值設計、批處理優化、服務端優化、集群配置優化
1. Redis慢查詢日志使用
Redis 提供了慢日志命令的統計功能,它記錄了有哪些命令在執行時耗時比較久,
查看 Redis 慢日志之前,你需要設定慢日志的閾值,例如,設定慢日志的閾值為 5 毫秒,并且保留最近 500 條慢日志記錄:
# 命令執行耗時超過 5 毫秒,記錄慢日志
CONFIG SET slowlog-log-slower-than 5000
# 只保留最近 500 條慢日志
CONFIG SET slowlog-max-len 500
設定完成之后,所有執行的命令如果操作耗時超過了 5 毫秒,都會被 Redis 記錄下來,
此時,你可以執行以下命令,就可以查詢到最近記錄的慢日志:
- slowlog len:查詢慢查詢日志長度
- slowlog get [n]:讀取n條慢查詢日志
- slowlog reset:清空慢查詢串列
127.0.0.1:6379> SLOWLOG get 5
1) 1) (integer) 12691 # 慢日志ID
2) (integer) 16027264377 # 執行時間戳
3) (integer) 6989 # 執行耗時(微秒)
4) 1) "LRANGE" # 具體執行的命令和引數
2) "goods_list:100"
3) "0"
4) "-1"
2) 1) (integer) 12692
2) (integer) 16028254247
3) (integer) 5454
4) 1) "GET"
2) "good_info:100"
有可能會導致操作延遲的情況:
- 經常使用 O(N) 以上復雜度的命令,例如 SORT、SUNION、ZUNIONSTORE 聚合類命令,要花費更多的 CPU 資源
- 使用 O(N) 復雜度的命令,但 N 的值非常大,Redis 一次需要回傳給客戶端的資料過多,更多時間花費在資料協議的組裝和網路傳輸程序中,
你可以使用以下方法優化你的業務:
- 盡量不使用 O(N) 以上復雜度過高的命令,對于資料的聚合操作,放在客戶端做
- 執行 O(N) 命令,保證 N 盡量的小(推薦 N <= 300),每次獲取盡量少的資料,讓 Redis 可以及時處理回傳
2. Redis鍵值設計
2.1 優雅的key結構
Redis的Key雖然可以自定義,但最好遵循下面的幾個最佳實踐約定:
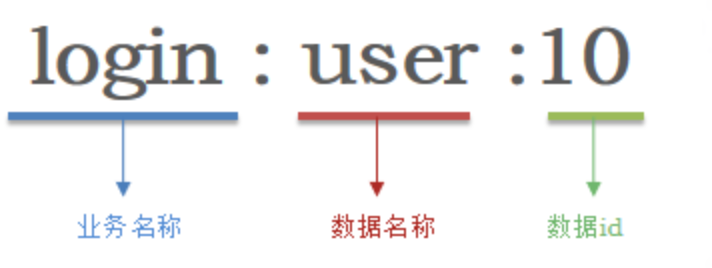
- 遵循基本格式:[業務名稱]:[資料名]:[id]
- 長度不超過44位元組
- 不包含特殊字符
例如:我們的登錄業務,保存用戶資訊,其key可以設計成如下格式:
這樣設計的好處:
- 可讀性強
- 避免key沖突
- 方便管理
- 更節省記憶體: key是string型別,底層編碼包含int、embstr和raw三種,embstr在小于44位元組使用,采用連續記憶體空間,記憶體占用更小,當位元組數大于44位元組時,會轉為raw模式存盤,在raw模式下,記憶體空間不是連續的,而是采用一個指標指向了另外一段記憶體空間,在這段空間里存盤SDS內容,這樣空間不連續,訪問的時候性能也就會收到影響,還有可能產生記憶體碎片
2.2 拒絕BigKey
2.2.1 什么是BigKey
如果一個 key 寫入的 value 非常大,那么 Redis 在分配記憶體時就會比較耗時,同樣的,當洗掉這個 key 時,釋放記憶體也會比較耗時,這種型別的 key 我們一般稱之為 bigkey,
BigKey 通常以 Key 的大小和 Key 中成員的數量來綜合判定,例如:
- Key 本身的資料量過大:一個 String 型別的 Key ,它的值為 5 MB
- Key 中的成員數過多:一個 ZSET 型別的 Key ,它的成員數量為 10,000 個
- Key 中成員的資料量過大:一個 Hash 型別的 Key ,它的成員數量雖然只有 1,000 個但這些成員的 Value(值)總大小為 100 MB
那么如何判斷元素的大小呢?redis 也給我們提供了命令
MEMORY USAGE KEY
推薦值:
- 單個 key 的 value 小于 10KB
- 對于集合型別的 key,建議元素數量小于 1000
2.2.2 BigKey 的危害
-
網路阻塞
對 BigKey 執行讀請求時,少量的 QPS 就可能導致帶寬使用率被占滿,導致 Redis 實體,乃至所在物理機變慢
-
資料傾斜
BigKey 所在的 Redis 實體記憶體使用率遠超其他實體,無法使資料分片的記憶體資源達到均衡
-
Redis 阻塞
對元素較多的 hash、list、zset 等做運算會耗時較舊,使主執行緒被阻塞
-
CPU 壓力
對 BigKey 的資料序列化和反序列化會導致 CPU 的使用率飆升,影響 Redis 實體和本機其它應用
2.2.3 如何發現BigKey
redis-cli --bigkeys -a `密碼`
利用 redis-cli 提供的–bigkeys 引數,可以遍歷分析所有 key,并回傳 Key 的整體統計資訊與每個資料型別的 Top1 的 big key
這個命令的原理,就是 Redis 在內部執行了 SCAN 命令,遍歷整個實體中所有的 key,然后針對 key 的型別,分別執行 STRLEN、LLEN、HLEN、SCARD、ZCARD 命令,來獲取 String 型別的長度、容器型別(List、Hash、Set、ZSet)的元素個數,
這里需要提醒你的是,當執行這個命令時,要注意 2 個問題:
- 對線上實體進行 bigkey 掃描時,Redis 的 OPS 會突增,為了降低掃描程序中對 Redis 的影響,最好控制一下掃描的頻率,指定 -i 引數即可,它表示掃描程序中每次掃描后休息的時間間隔,單位是秒
- 掃描結果中,對于容器型別(List、Hash、Set、ZSet)的 key,只能掃描出元素最多的 key,但一個 key 的元素多,不一定表示占用記憶體也多,你還需要根據業務情況,進一步評估記憶體占用情況
scan cursor count n
自己編程,利用 scan 掃描 Redis 中的所有 key,利用 strlen、hlen 等命令判斷 key 的長度(此處不建議使用 MEMORY USAGE)
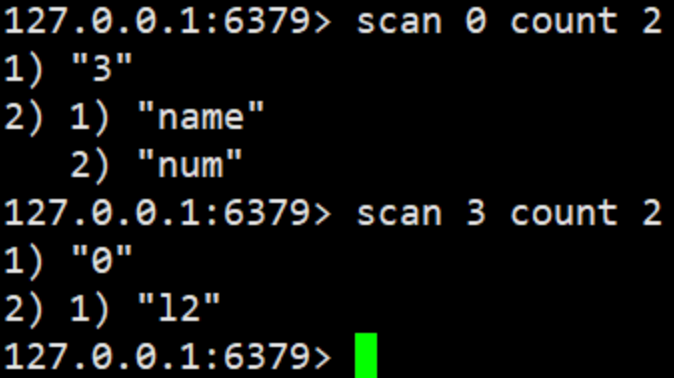
scan 命令呼叫完后每次會回傳 2 個元素,第一個是下一次迭代的游標,第一次游標會設定為 0,當最后一次 scan 回傳的游標等于 0 時,表示整個 scan 遍歷結束了,第二個回傳的是 List,一個匹配的 key 的陣列
public class JedisTest {
private Jedis jedis;
@BeforeEach
void setUp() {
// 1.建立連接
// jedis = new Jedis("192.168.150.101", 6379);
jedis = JedisConnectionFactory.getJedis();
// 2.設定密碼
jedis.auth("123321");
// 3.選擇庫
jedis.select(0);
}
final static int STR_MAX_LEN = 10 * 1024;
final static int HASH_MAX_LEN = 500;
@Test
void testScan() {
int maxLen = 0;
long len = 0;
String cursor = "0";
do {
// 掃描并獲取一部分key
ScanResult<String> result = jedis.scan(cursor);
// 記錄cursor
cursor = result.getCursor();
List<String> list = result.getResult();
if (list == null || list.isEmpty()) {
break;
}
// 遍歷
for (String key : list) {
// 判斷key的型別
String type = jedis.type(key);
switch (type) {
case "string":
len = jedis.strlen(key);
maxLen = STR_MAX_LEN;
break;
case "hash":
len = jedis.hlen(key);
maxLen = HASH_MAX_LEN;
break;
case "list":
len = jedis.llen(key);
maxLen = HASH_MAX_LEN;
break;
case "set":
len = jedis.scard(key);
maxLen = HASH_MAX_LEN;
break;
case "zset":
len = jedis.zcard(key);
maxLen = HASH_MAX_LEN;
break;
default:
break;
}
if (len >= maxLen) {
System.out.printf("Found big key : %s, type: %s, length or size: %d %n", key, type, len);
}
}
} while (!cursor.equals("0"));
}
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close();
}
}
}
第三方工具
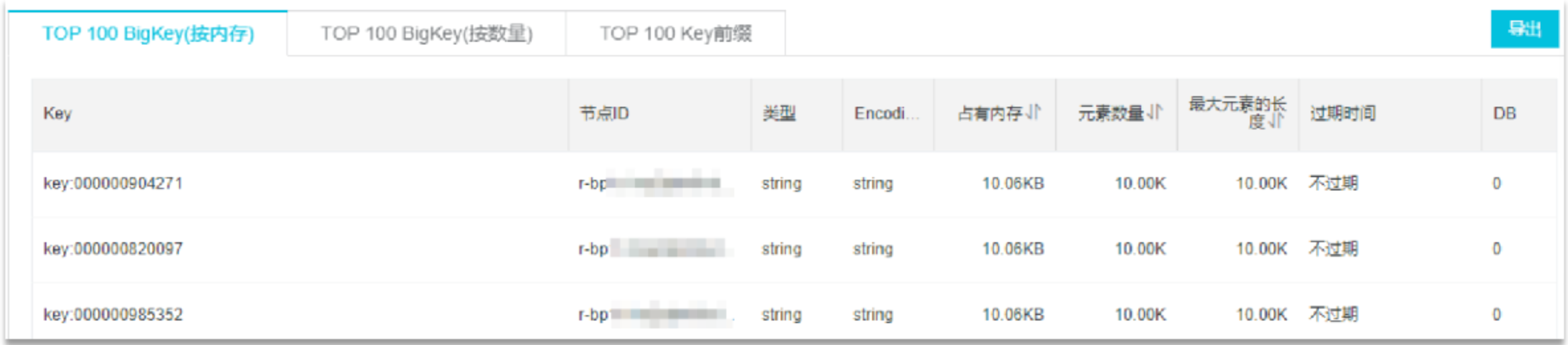
- 利用第三方工具,如 Redis-Rdb-Tools 分析 RDB 快照檔案,全面分析記憶體使用情況
- https://github.com/sripathikrishnan/redis-rdb-tools
網路監控
- 自定義工具,監控進出 Redis 的網路資料,超出預警值時主動告警
- 一般阿里云搭建的云服務器就有相關監控頁面
2.2.4 BigKey 解決方案
這里有兩點可以優化:
- 業務應用盡量避免寫入 bigkey
- 如果你使用的 Redis 是 4.0 以上版本,用 UNLINK 命令替代 DEL,此命令可以把釋放 key 記憶體的操作,放到后臺執行緒中去執行,從而降低對 Redis 的影響
- 如果你使用的 Redis 是 6.0 以上版本,可以開啟 lazy-free 機制(
lazyfree-lazy-user-del = yes),在執行 DEL 命令時,釋放記憶體也會放到后臺執行緒中執行
bigkey 在很多場景下,都會產生性能問題,例如,bigkey 在分片集群模式下,對于資料的遷移也會有性能影響,以及我后面即將講到的資料過期、資料淘汰、透明大頁,都會受到 bigkey 的影響,因此,即使 reids6.0 以后,仍然不建議使用 BigKey
2.3 總結
- Key 的最佳實踐
- 固定格式:[業務名]:[資料名]:[id]
- 足夠簡短:不超過 44 位元組
- 不包含特殊字符
- Value 的最佳實踐:
- 合理的拆分資料,拒絕 BigKey
- 選擇合適資料結構
- Hash 結構的 entry 數量不要超過 1000
- 設定合理的超時時間
3. 批處理優化
3.1 Pipeline
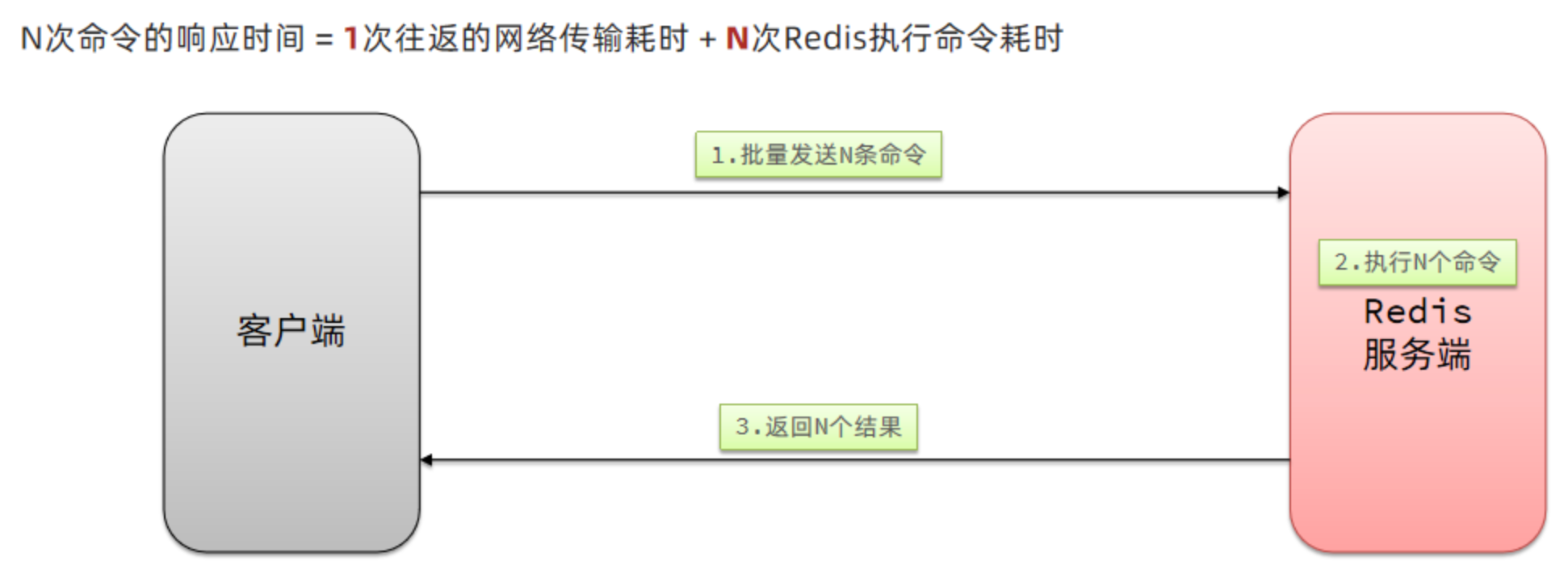
3.1.1 客戶端與服務端互動
單個命令的執行流程

N 條命令的執行流程

redis 處理指令是很快的,主要花費的時候在于網路傳輸,于是乎很容易想到將多條指令批量的傳輸給 redis
3.1.2 MSet
Redis 提供了很多 Mxxx 這樣的命令,可以實作批量插入資料,例如:
- mset
- hmset
利用 mset 批量插入 10 萬條資料
@Test
void testMxx() {
String[] arr = new String[2000];
int j;
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
j = (i % 1000) << 1;
arr[j] = "test:key_" + i;
arr[j + 1] = "value_" + i;
if (j == 0) {
jedis.mset(arr);
}
}
long e = System.currentTimeMillis();
System.out.println("time: " + (e - b));
}
3.1.3 Pipeline
MSET 雖然可以批處理,但是卻只能操作部分資料型別,因此如果有對復雜資料型別的批處理需要,建議使用 Pipeline
@Test
void testPipeline() {
// 創建管道
Pipeline pipeline = jedis.pipelined();
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
// 放入命令到管道
pipeline.set("test:key_" + i, "value_" + i);
if (i % 1000 == 0) {
// 每放入1000條命令,批量執行
pipeline.sync();
}
}
long e = System.currentTimeMillis();
System.out.println("time: " + (e - b));
}
3.2 集群下的批處理
如 MSET 或 Pipeline 這樣的批處理需要在一次請求中攜帶多條命令,而此時如果 Redis 是一個集群,那批處理命令的多個 key 必須落在一個插槽中,否則就會導致執行失敗,大家可以想一想這樣的要求其實很難實作,因為我們在批處理時,可能一次要插入很多條資料,這些資料很有可能不會都落在相同的節點上,這就會導致報錯了
這個時候,我們可以找到 4 種解決方案
-
第一種方案:串行執行,所以這種方式沒有什么意義,當然,執行起來就很簡單了,缺點就是耗時過久,
-
第二種方案:串行 slot,簡單來說,就是執行前,客戶端先計算一下對應的 key 的 slot ,一樣 slot 的 key 就放到一個組里邊,不同的,就放到不同的組里邊,然后對每個組執行 pipeline 的批處理,他就能串行執行各個組的命令,這種做法比第一種方法耗時要少,但是缺點呢,相對來說復雜一點,所以這種方案還需要優化一下
-
第三種方案:并行 slot,相較于第二種方案,在分組完成后串行執行,第三種方案,就變成了并行執行各個命令,所以他的耗時就非常短,但是實作呢,也更加復雜,
-
第四種:hash_tag,redis 計算 key 的 slot 的時候,其實是根據 key 的有效部分來計算的,通過這種方式就能一次處理所有的 key,這種方式耗時最短,實作也簡單,但是如果通過操作 key 的有效部分,那么就會導致所有的 key 都落在一個節點上,產生資料傾斜的問題,所以我們推薦使用第三種方式,
3.2.1 串行化執行代碼實踐
public class JedisClusterTest {
private JedisCluster jedisCluster;
@BeforeEach
void setUp() {
// 配置連接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(8);
poolConfig.setMaxIdle(8);
poolConfig.setMinIdle(0);
poolConfig.setMaxWaitMillis(1000);
HashSet<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.150.101", 7001));
nodes.add(new HostAndPort("192.168.150.101", 7002));
nodes.add(new HostAndPort("192.168.150.101", 7003));
nodes.add(new HostAndPort("192.168.150.101", 8001));
nodes.add(new HostAndPort("192.168.150.101", 8002));
nodes.add(new HostAndPort("192.168.150.101", 8003));
jedisCluster = new JedisCluster(nodes, poolConfig);
}
@Test
void testMSet() {
jedisCluster.mset("name", "Jack", "age", "21", "sex", "male");
}
@Test
void testMSet2() {
Map<String, String> map = new HashMap<>(3);
map.put("name", "Jack");
map.put("age", "21");
map.put("sex", "Male");
//對Map資料進行分組,根據相同的slot放在一個分組
//key就是slot,value就是一個組
Map<Integer, List<Map.Entry<String, String>>> result = map.entrySet()
.stream()
.collect(Collectors.groupingBy(
entry -> ClusterSlotHashUtil.calculateSlot(entry.getKey()))
);
//串行的去執行mset的邏輯
for (List<Map.Entry<String, String>> list : result.values()) {
String[] arr = new String[list.size() * 2];
int j = 0;
for (int i = 0; i < list.size(); i++) {
j = i<<2;
Map.Entry<String, String> e = list.get(0);
arr[j] = e.getKey();
arr[j + 1] = e.getValue();
}
jedisCluster.mset(arr);
}
}
@AfterEach
void tearDown() {
if (jedisCluster != null) {
jedisCluster.close();
}
}
}
3.2.2 Spring 集群環境下批處理代碼
@Test
void testMSetInCluster() {
Map<String, String> map = new HashMap<>(3);
map.put("name", "Rose");
map.put("age", "21");
map.put("sex", "Female");
stringRedisTemplate.opsForValue().multiSet(map);
List<String> strings = stringRedisTemplate.opsForValue().multiGet(Arrays.asList("name", "age", "sex"));
strings.forEach(System.out::println);
}
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/538908.html
標籤:Java