
?? 作者:韓信子@ShowMeAI
?? 資料分析實戰系列:https://www.showmeai.tech/tutorials/40
?? 本文地址:https://www.showmeai.tech/article-detail/393
?? 宣告:著作權所有,轉載請聯系平臺與作者并注明出處
?? 收藏ShowMeAI查看更多精彩內容
做 Python 資料分析和機器學習的同學都非常喜歡 pandas 這個工具庫,它操作簡單功能強大,可以很方便完成資料處理、資料分析、資料變換等程序,優雅且便捷,
?? Python資料分析實戰教程
但是,pandas對于大型的資料處理卻并不是很高效,在讀取大檔案時甚至會消耗大量時間,那么對于大型資料集,是否有一個工具,既可以像 pandas 一樣便捷操作 Dataframe,又有極高的效率,同時也沒有 spark 那樣復雜的用法和硬體環境要求呢?有!大家可以試試 ??Vaex,

??Vaex 是一個非常強大的 Python DataFrame 庫,能夠每秒處理數億甚至數十億行,而無需將整個資料集加載到記憶體中,這使得它對于超過單臺機器可用 RAM 的大型資料集的探索、可視化和統計分析特別有用,而且 Vaex 還兼具便利性和易用性,
在本文中,ShowMeAI將給大家介紹這個強大的工具,讓你在處理大資料分析作業時更加高效,
?? vaex 使用詳解
?? 1.巨型檔案讀取&處理(例如CSV)
Vaex 工具的設計初衷就包括以高效的方式處理比可用記憶體大得多的檔案,借助于它,我們可以輕松處理任意大的資料集,Vaex 在過去的版本中支持二進制檔案格式,例如 HDF5、 Arrow 和 Parquet ,從4.14.0版本以來,它也可以像使用上述格式一樣輕松打開和使用巨型 CSV 檔案,這在一定程度上要歸功于 ??Apache Arrow專案,它提供了一個相當高效的 CSV 讀取器,

注:本文使用到的資料可以在 ??資料官網 獲取,
下面是讀取大檔案時的用法:
print('Check file size on disk:')
!du -h chicago_taxi_2013_2020.csv
print()
df = vaex.open('chicago_taxi_2013_2020.csv')
print(f'Number of rows: {df.shape[0]:,}')
print(f'Number of columns: {df.shape[1]}')
mean_tip_amount = df.tip_amount.mean(progress='widget')
print(f'Mean tip amount: {mean_tip_amount:.2f}')
df.fare_amount.viz.histogram(shape=128, figsize=(6, 4), limits=[0, 42], progress='widget');
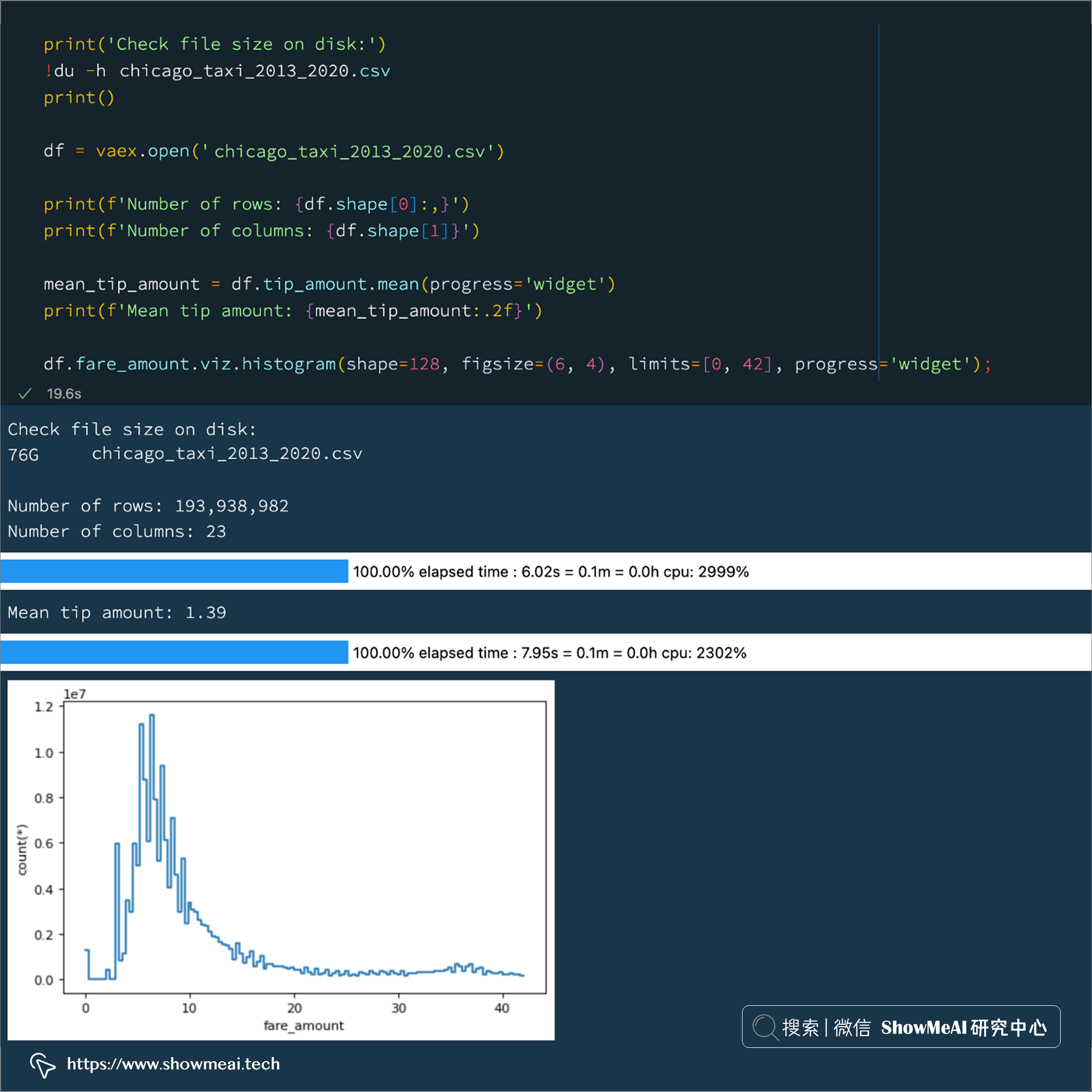
上面的示例顯示了 vaex 輕松處理巨型 CSV 檔案(76 GB CSV 檔案),上述程序的詳細說明如下:
① 當我們使用vaex.open()對于 CSV 檔案,Vaex 將流式處理整個 CSV 檔案以確定行數和列數,以及每列的資料型別,這個程序不會占用大量 RAM,但可能需要一些時間,具體取決于 CSV 的行數和列數,
可以通過
schema_infer_fraction控制 Vaex 讀取檔案的程度,數字越小,讀取速度越快,但資料型別推斷可能不太準確(因為不一定掃描完所有資料),在上面的示例中,我們使用默認引數在大約 5 秒內讀取了 76 GB 的 CSV 檔案,其中包含近 2 億行和 23 列,
② 然后我們通過 vaex 計算了tip_amount列的平均值,耗時 6 秒,
③ 最后我們繪制了tip_amount列的直方圖,耗時 8 秒,
也就是說,我們在 20 秒內讀取了整個 76 GB CSV 檔案 3 次,而無需將整個檔案加載到記憶體中,
?? 注意,無論檔案格式如何,Vaex 的 API 都是相同的,這意味著可以輕松地在 CSV、HDF5、Arrow 和 Parquet 檔案之間切換,而無需更改代碼,
當然,就本身性能而言,使用 CSV 檔案并不是最佳選擇,出于各種原因,通常應避免使用,盡管如此,大型 CSV 檔案在日常作業中還是會遇到,這使得此功能對于快速檢查和探索其內容以及高效轉換為更合適的檔案格式非常方便,
?? 2.統計:分組聚合
資料分析中最常見的操作之一就是分組聚合統計,在 Vaex 中指定聚合操作主要有兩種方式:
- ① 指定要聚合的列,以及聚合操作的方法名稱,
- ② 指定輸出列的名稱,然后顯式實作vaex聚合統計方法,
下面我們看下如何實際操作,本文后續部分,我們將使用 ??NYC Taxi 資料集的一個子集,包含10億+條資料記錄,
df = vaex.open('yellow_taxi_2009_2015_f32.hdf5')
print(f'Number of rows: {df.shape[0]:,}')
print(f'Number of columns: {df.shape[1]}')
df.groupby(df.vendor_id, progress='widget').agg(
{'fare_amount': 'mean', # Option 1
'tip_amount_mean': vaex.agg.mean(df.tip_amount), # Option 2
})
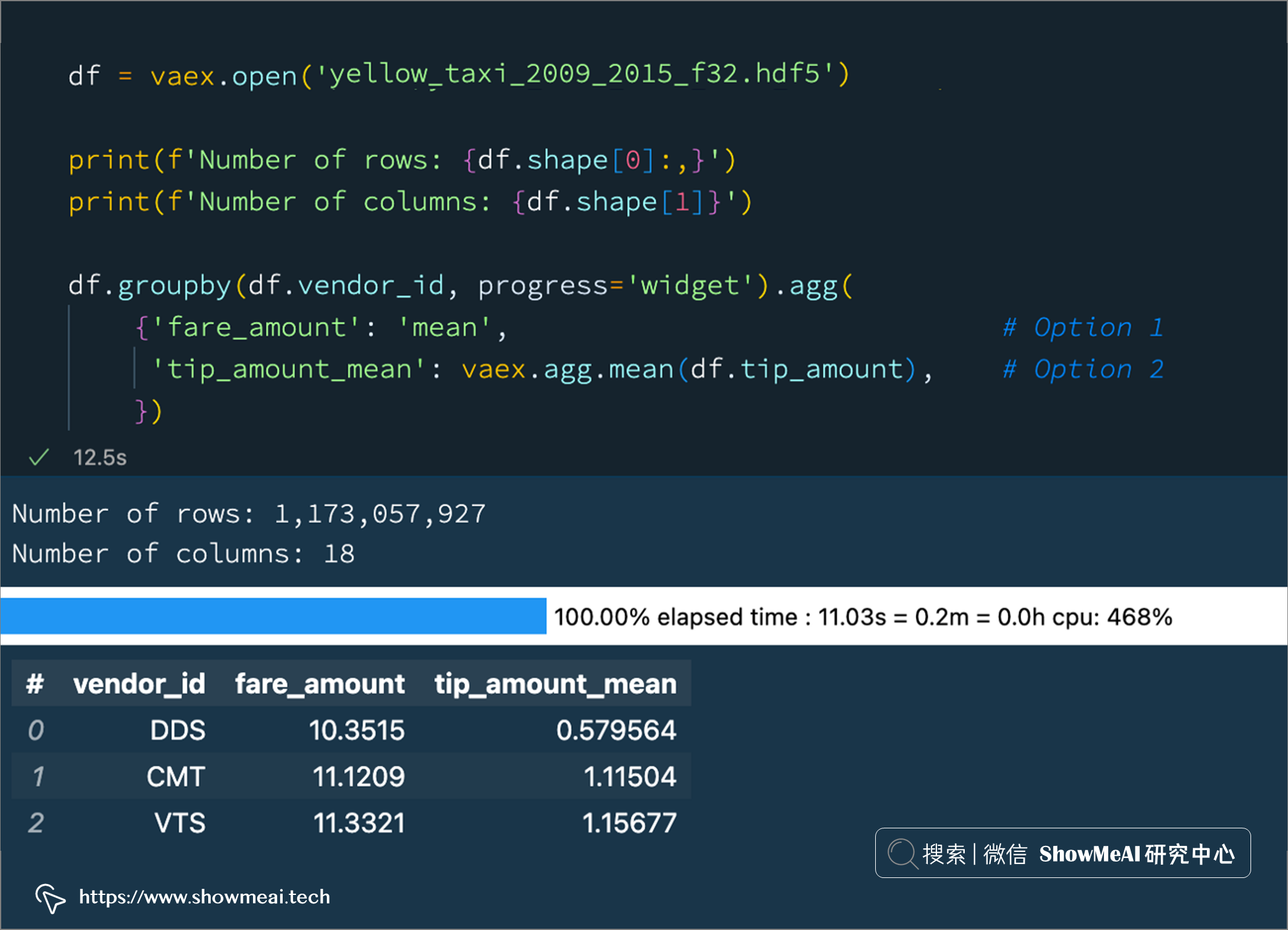
上述的操作方法和 pandas Dataframe 是基本一致的,Vaex 還支持如下的第2種方式:
df.groupby(df.vendor_id, progress='widget').agg(
{'fare_amount_norm': vaex.agg.mean(df.fare_amount) / vaex.agg.std(df.fare_amount)}
)
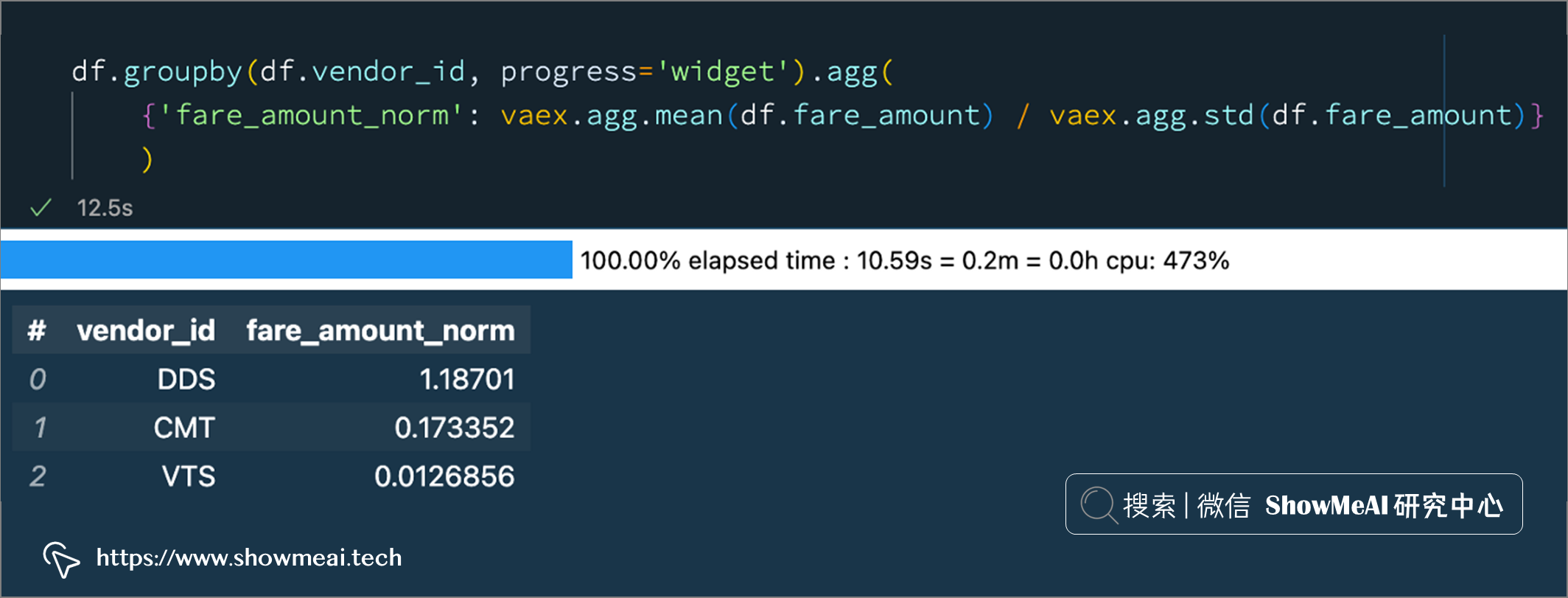
明確定義聚合函式方法(上面的第2種方式)還支持進行條件選擇,例如下例中,我們對全部資料,以及passenger_count為 2 和 4 的資料進行聚合統計:
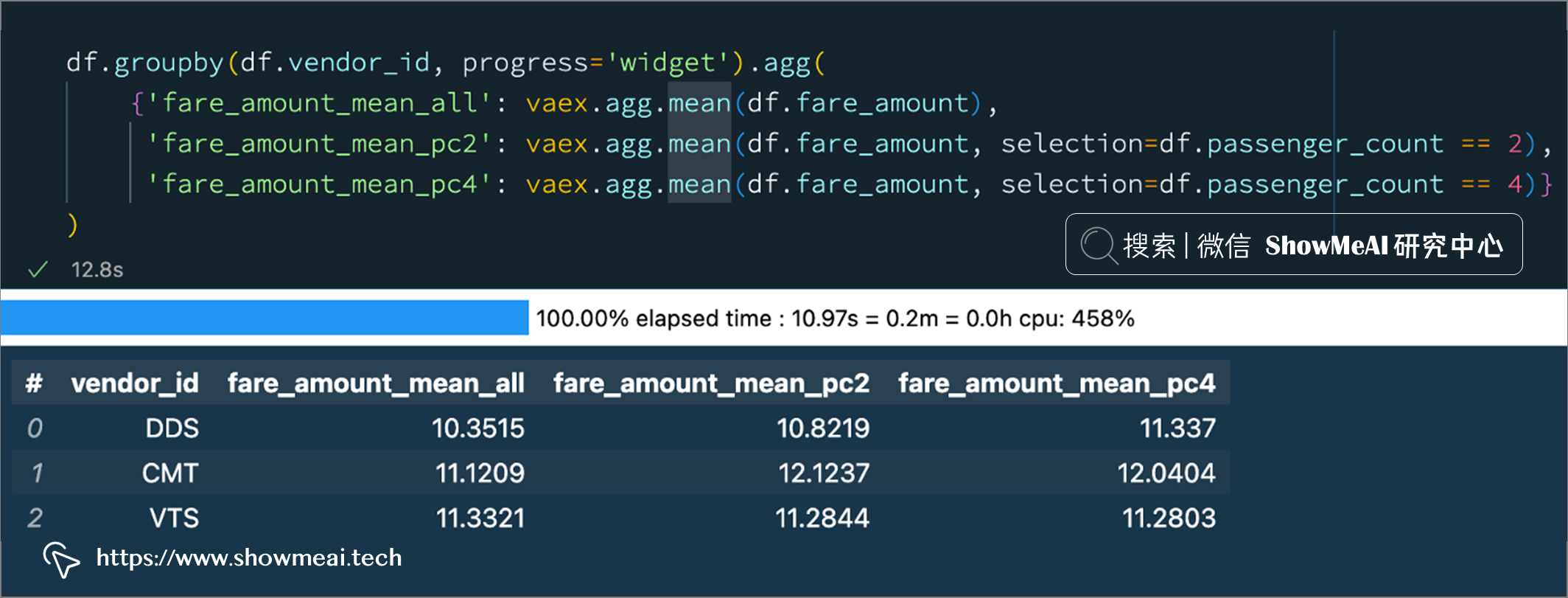
df.groupby(df.vendor_id, progress='widget').agg(
{'fare_amount_mean_all': vaex.agg.mean(df.fare_amount),
'fare_amount_mean_pc2': vaex.agg.mean(df.fare_amount, selection=df.passenger_count == 2),
'fare_amount_mean_pc4': vaex.agg.mean(df.fare_amount, selection=df.passenger_count == 4)}
)
?? 3.進度條
大家在之前使用 pandas 進行資料分析時,有時候我們會將中間程序構建為 pipeline 管道,它包含各種資料處理變換步驟,每次執行,如果我們只能等待資料處理完畢,那我們對全程序沒有太多的把控,
Vaex非常強大,它可以指示每個步驟需要多長時間以及整個管道完成之前還剩下多少時間,在處理巨型檔案時,進度條非常有用,
實際在巨型檔案上操作的程序和結果是下面這樣的:
with vaex.progress.tree('rich'):
result_1 = df.groupby(df.passenger_count, agg='count')
result_2 = df.groupby(df.vendor_id, agg=vaex.agg.sum('fare_amount'))
result_3 = df.tip_amount.mean()
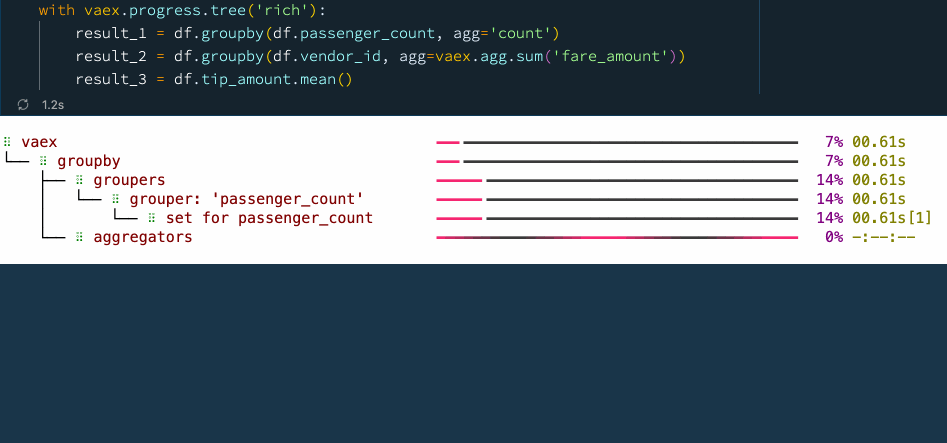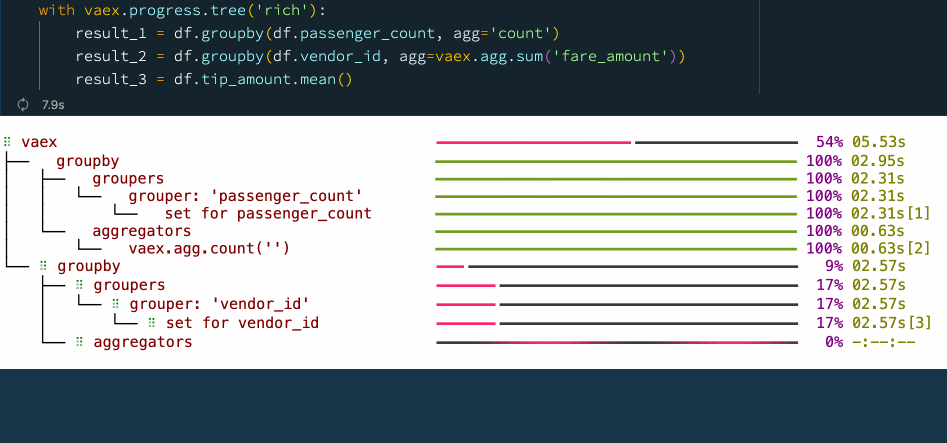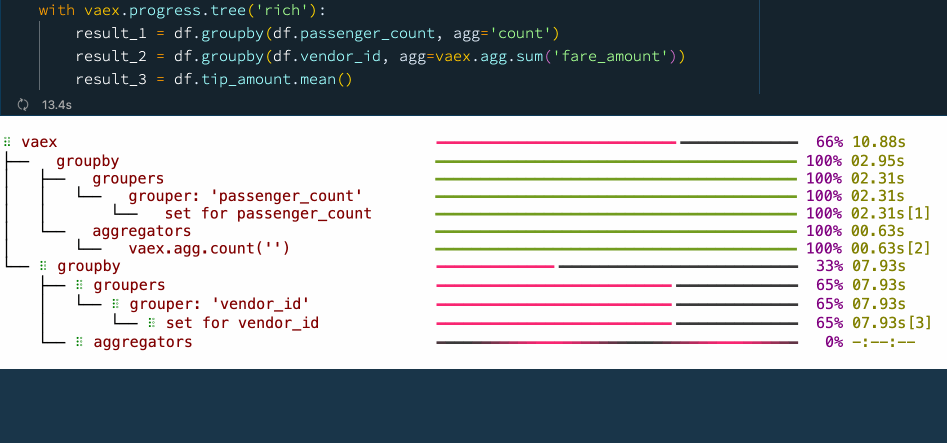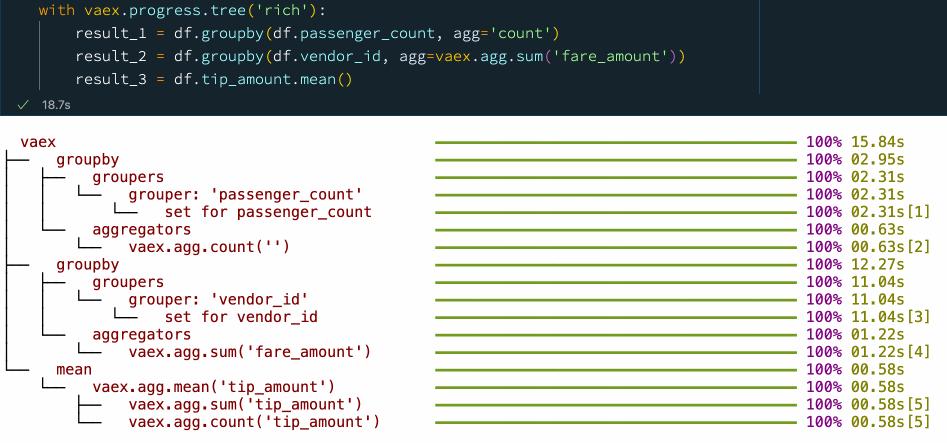
在上圖示例的進度條圖中,您可以看到每個步驟所花費的時間,這不僅能讓我們掌握資料處理的進度和程序,也讓我們知道整個流程的時間瓶頸在哪,以便更好地進行優化和處理,
?? 4.異步計算
Vaex 具備懶惰計算(lazy computation)的特效,只在必要時計算運算式,一般準則是,對于不改變原始 DataFrame 基本性質的操作,這些操作是惰性計算的,例如:
- 從現有列中創建新列
- 將多個列組合成一個新列
- 進行某種分類編碼
- DataFrame 資料過濾
其他的一些操作,會進行實質性計算,例如分組操作,或計算聚合(例列的總和或平均值),
在進行互動式資料探索或分析時,這種作業流在性能和便利性之間提供了良好的平衡,
當我們定義好資料轉換程序或資料管道時,我們希望工具在計算時能進行性能優化,Vaex 支持delay=True等引數,可以并行執行計算與操作,使得 Vaex 可以提前構建計算圖,并嘗試找到最有效的計算結果的方式,
如下例:
with vaex.progress.tree('rich'):
result_1 = df.groupby(df.passenger_count, agg='count', delay=True)
result_2 = df.groupby(df.vendor_id, agg=vaex.agg.sum('fare_amount'), delay=True)
result_3 = df.tip_amount.mean(delay=True)
df.execute()
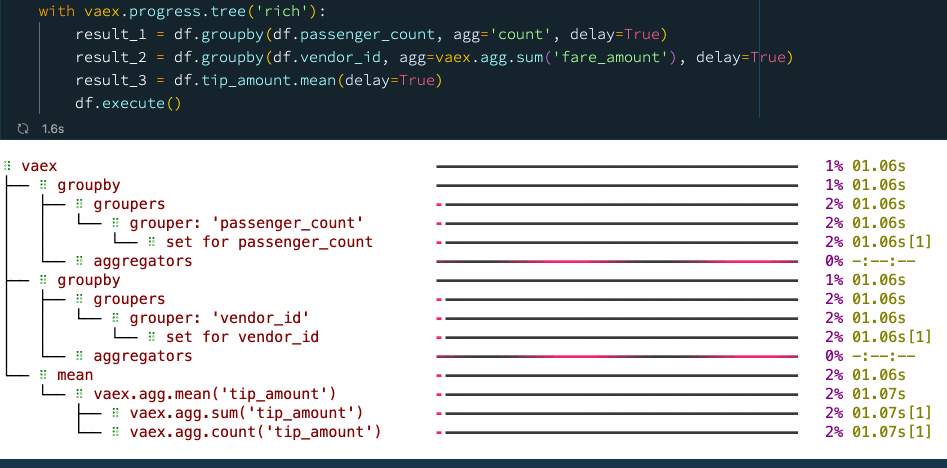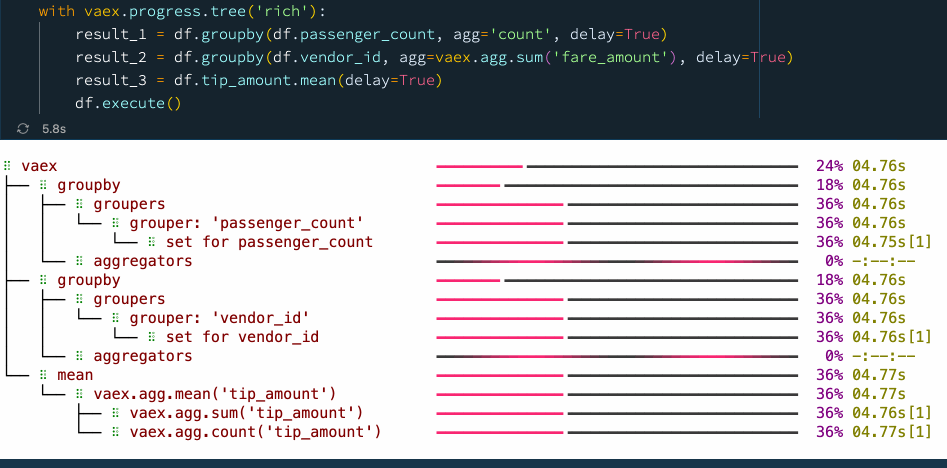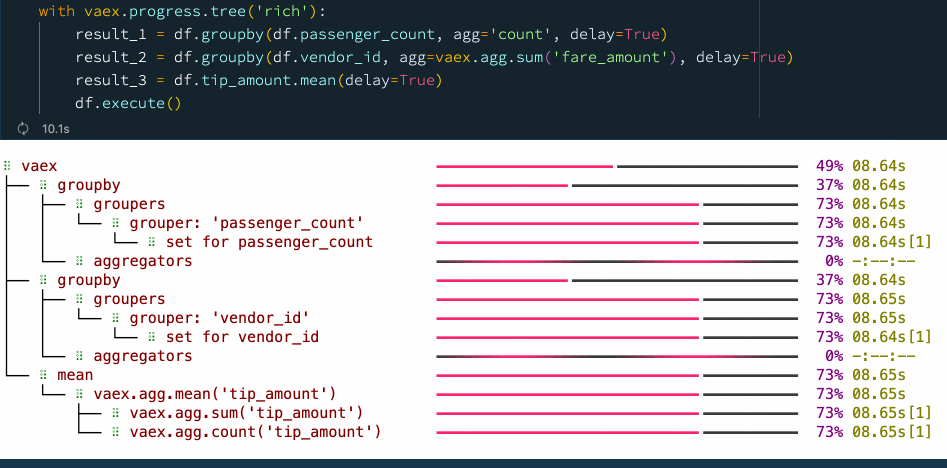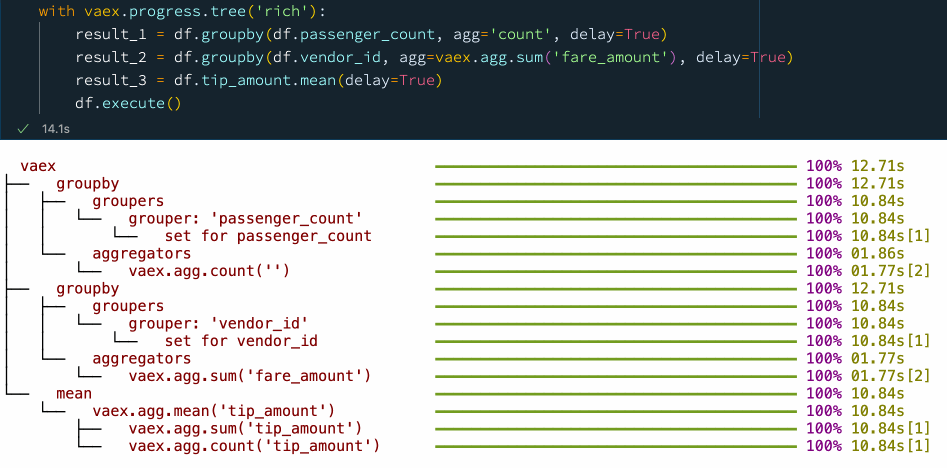
我們看到,通過顯式使用延遲計算,我們可以提高性能并減少檢查資料的次數,在這種情況下,我們在使用延遲計算時從 5 次通過資料變為僅 2 次,從而使速度提高了大約 30%,大家可以在 ??Vaex異步編程官方指南 里找到更多示例,
?? 5.結果快取
因為效率高,Vaex經常會用作儀表板和資料應用程式的后端,尤其是那些需要處理大量資料的應用程式,
使用資料應用程式時,通常會在相同或相似的資料子集上重復執行某些操作,例如,用戶將從同一個“主頁”開始,選擇常見或高頻的選項,然后再深入研究資料,在這種情況下,快取操作結果通常很有用,Vaex 實作了一種 ??先進的細粒度的快取機制 ,它允許快取單個操作的結果,以后可以重復使用,
以下示例是具體使用方法:
vaex.cache.on()
with vaex.progress.tree('rich'):
result_1 = df.passenger_count.nunique()
with vaex.progress.tree('rich'):
result_2 = df.groupby(df.passenger_count, agg=vaex.agg.mean('trip_distance'))
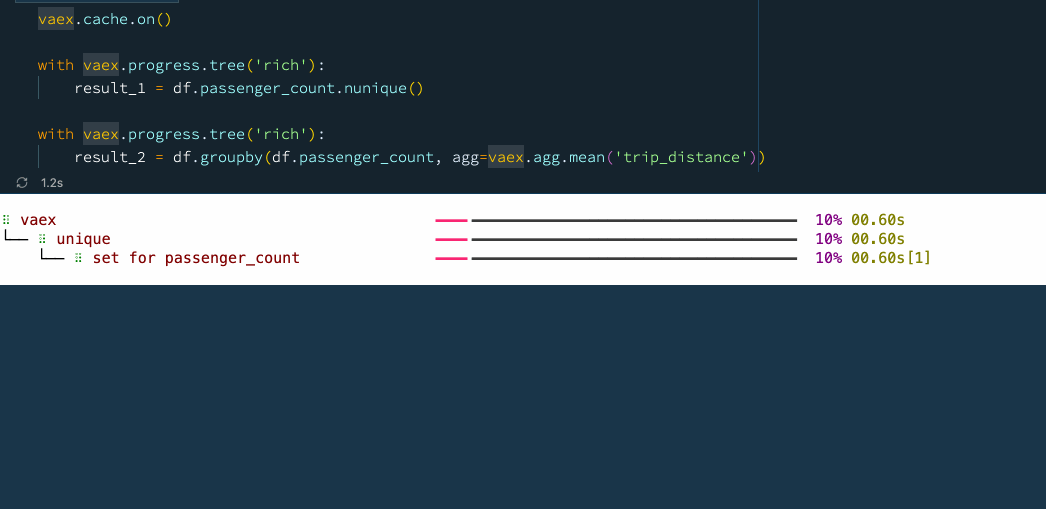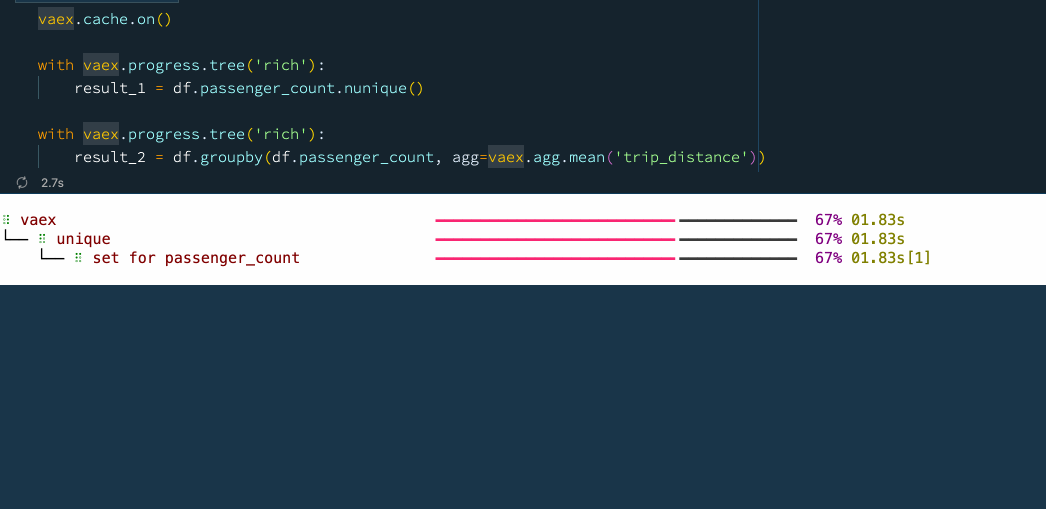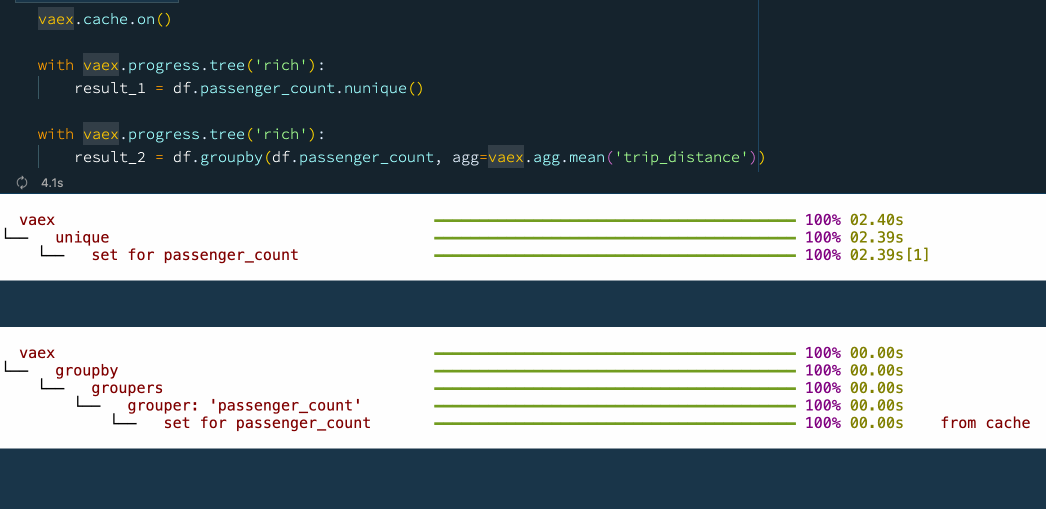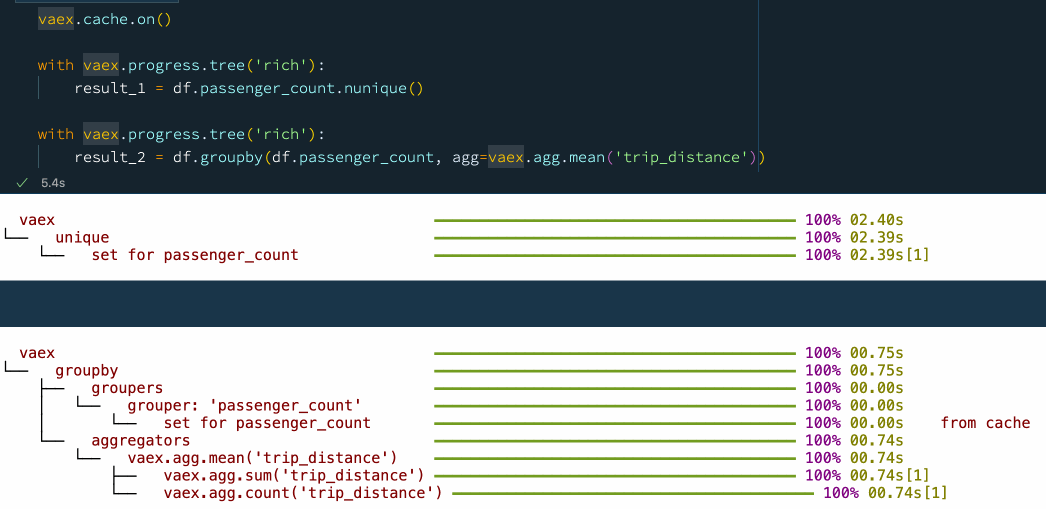
?? 6.提前停止
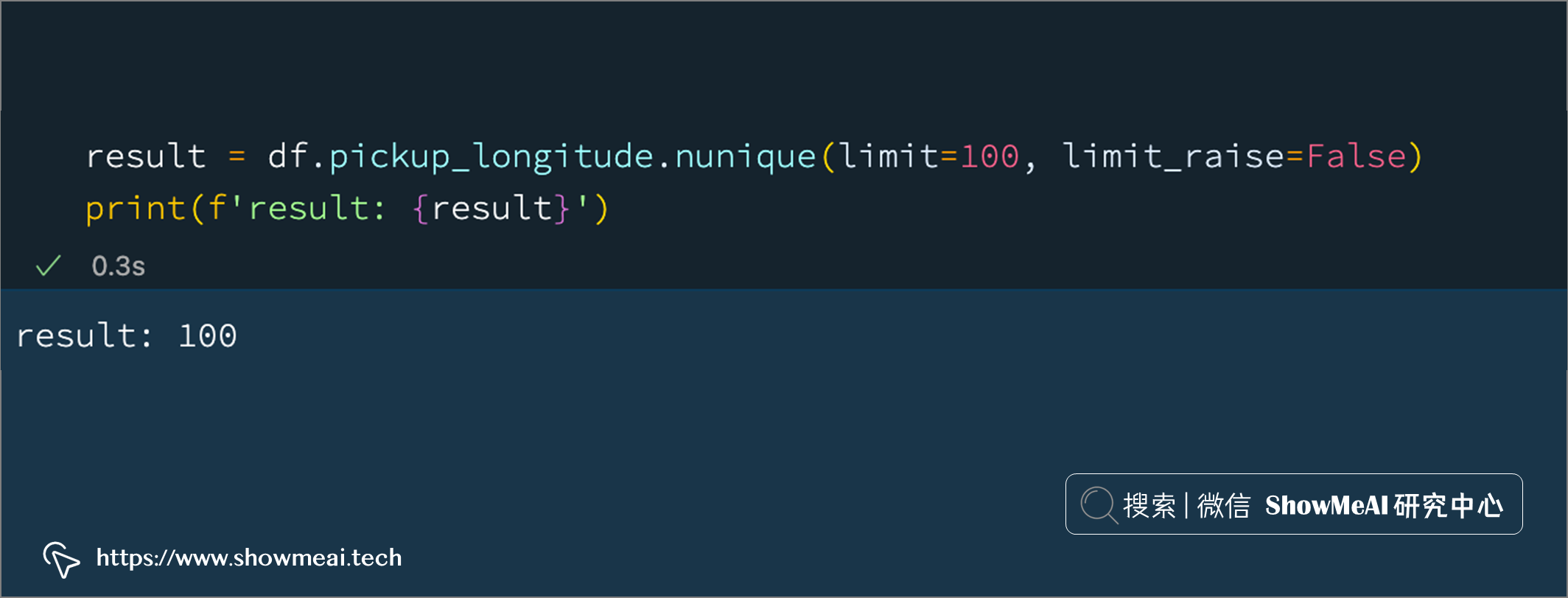
Vaex 有一種直接的方式來確定資料讀取的規模,當我們在資料分析時使用 unique, nunique或者 groupby方法,在全量資料上可能會有非常大的時延,我們可以指定 limit引數,它會限制我們計算的范圍,從而完成提速,
在下面的示例中,我們設定 limit到 100,它告訴 Vaex 在達到 100 時就計算并回傳結果:
result = df.pickup_longitude.nunique(limit=100, limit_raise=False)
print(f'result: {result}')
 ## ?? 7.云支持
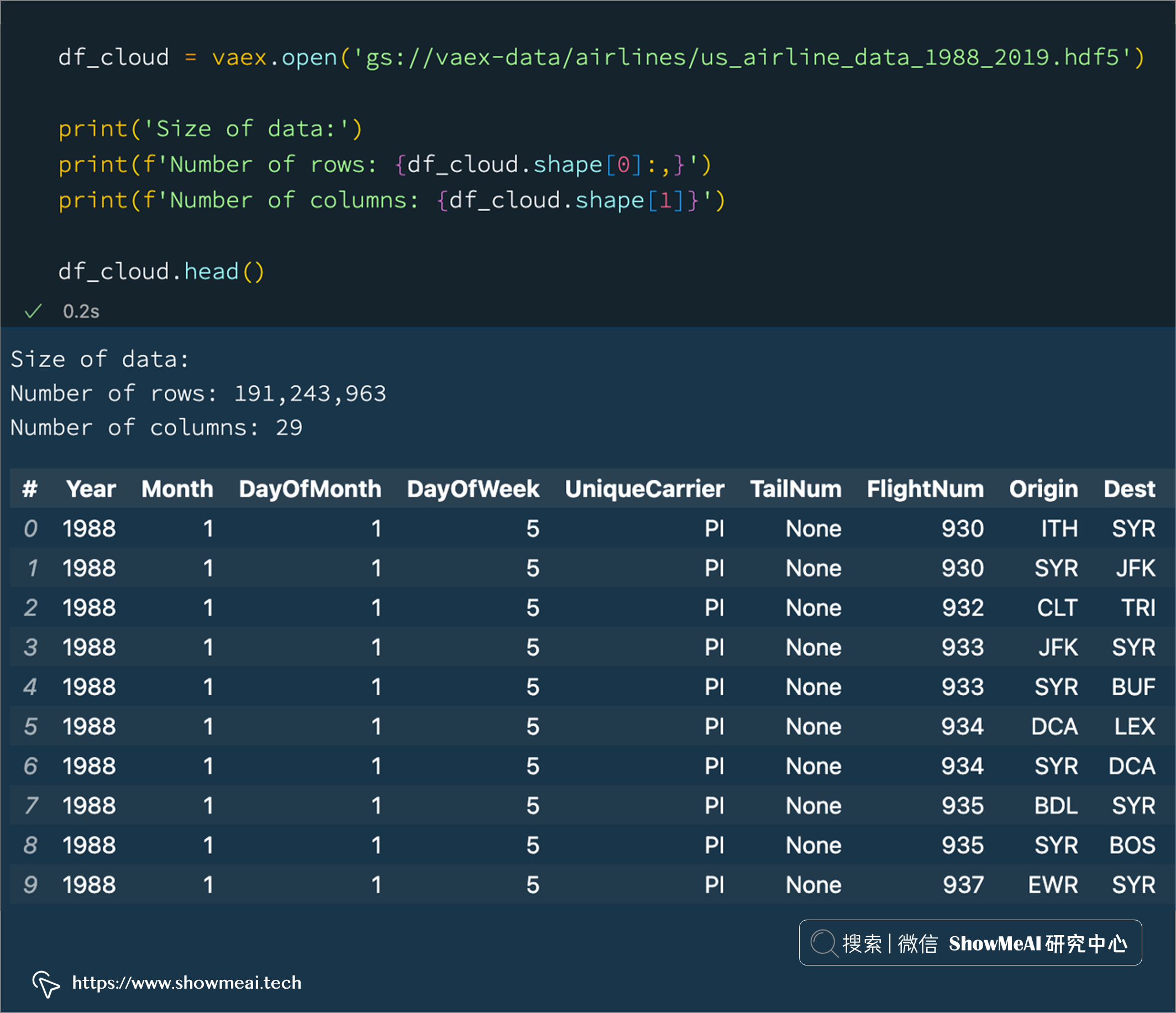
## ?? 7.云支持
隨著資料集的增長,將它們存盤在云中變得越來越普遍和實用,并且只將部分資料子集保留在本地,Vaex 對云非常友好——它可以輕松地從任何公共云存盤下載(流式傳輸)資料,
并且 Vaex 只會獲取需要的資料,例如,在執行 df.head() 時,只會獲取前 5 行,要計算一列的平均值,只會獲取該特定列的所有資料,Vaex 將流式傳輸該部分資料,因此并不會占用大量帶寬和網路資源:
df_cloud = vaex.open('gs://vaex-data/airlines/us_airline_data_1988_2019.hdf5')
print('Size of data:')
print(f'Number of rows: {df_cloud.shape[0]:,}')
print(f'Number of columns: {df_cloud.shape[1]}')
df_cloud.head()
?? 8.GPU加速
最后,Vaex 還有非常強大功能,它可以使用 GPU 來加速,并且它支持的平臺非常多:適用于 Windows 和 Linux 平臺的 NVIDIA、適用于 Mac OS 的 Radeon 和 Apple Silicon,
下例中,我們定義了一個函式來計算球體上兩點之間的弧距,這是一個相當復雜的數學運算,涉及大量的計算,我們使用先前的資料(資料集包含超過 10 億行),嘗試計算紐約出租車資料集中所有出租車行程的平均弧距:
print(f'Number of rows: {df.shape[0]:,}')
def arc_distance(theta_1, phi_1, theta_2, phi_2):
temp = (np.sin((theta_2-theta_1)/2*np.pi/180)**2
+ np.cos(theta_1*np.pi/180)*np.cos(theta_2*np.pi/180)
* np.sin((phi_2-phi_1)/2*np.pi/180)**2)
distance = 2 * np.arctan2(np.sqrt(temp), np.sqrt(1-temp))
return distance * 3958.8
df['arc_distance_miles_numpy'] = arc_distance(df.pickup_longitude, df.pickup_latitude,
df.dropoff_longitude, df.dropoff_latitude)
# Requires cupy and NVDIA GPU
df['arc_distance_miles_cuda'] = df['arc_distance_miles_numpy'].jit_cuda()
# Requires metal2 support on MacOS (Apple Silicon and Radeon GPU supported)
# df['arc_distance_miles_metal'] = df['arc_distance_miles_numpy'].jit_metal()
result_cpu = df.arc_distance_miles_numpy.mean(progress='widget')
result_gpu = df.arc_distance_miles_cuda.mean(progress='widget')
print(f'CPU: {result_cpu:.3f} miles')
print(f'GPU: {result_gpu:.3f} miles')
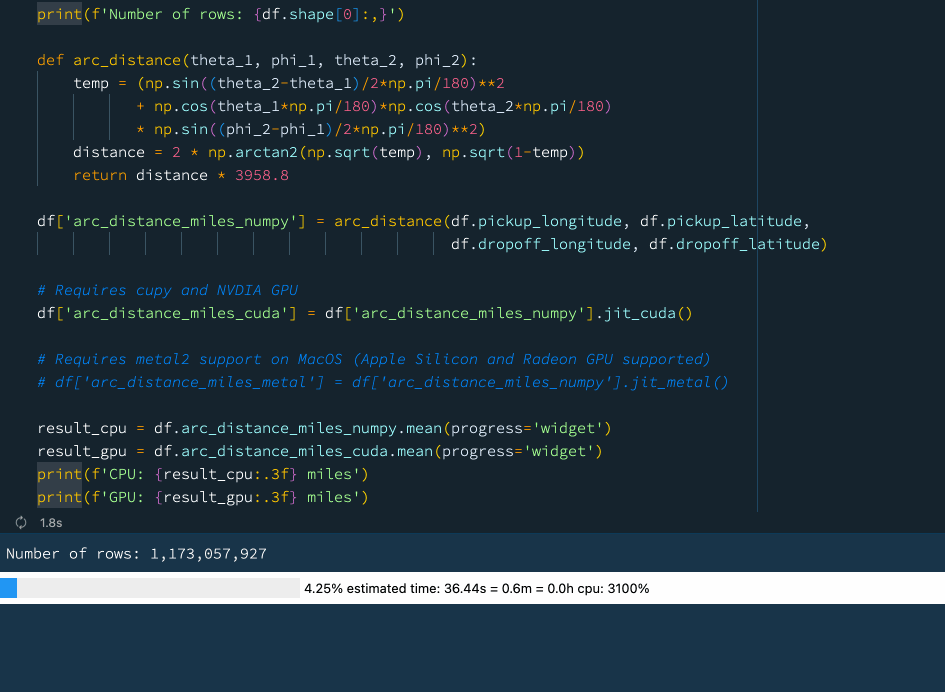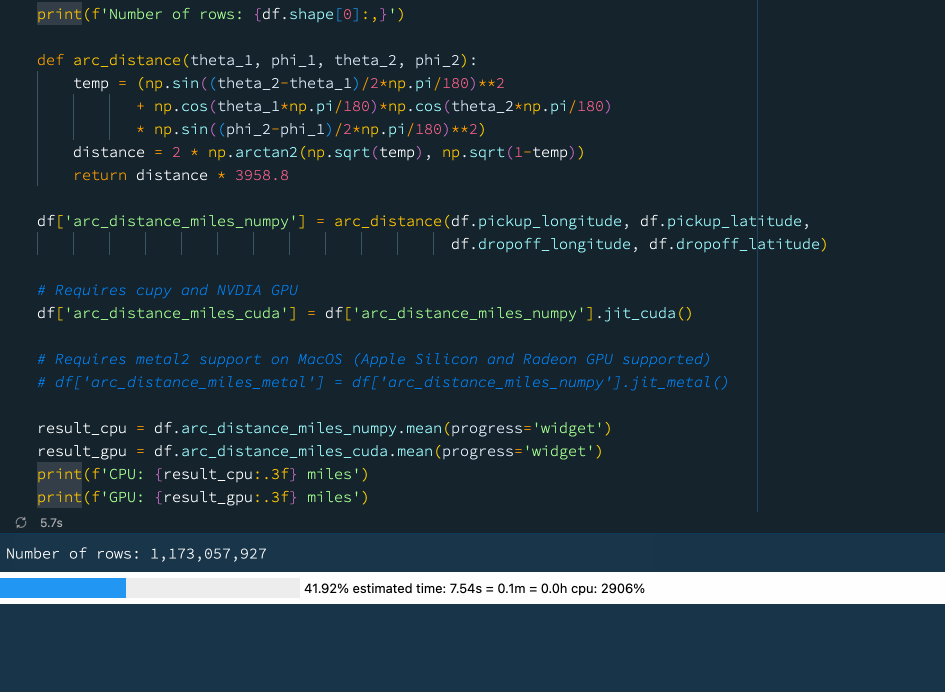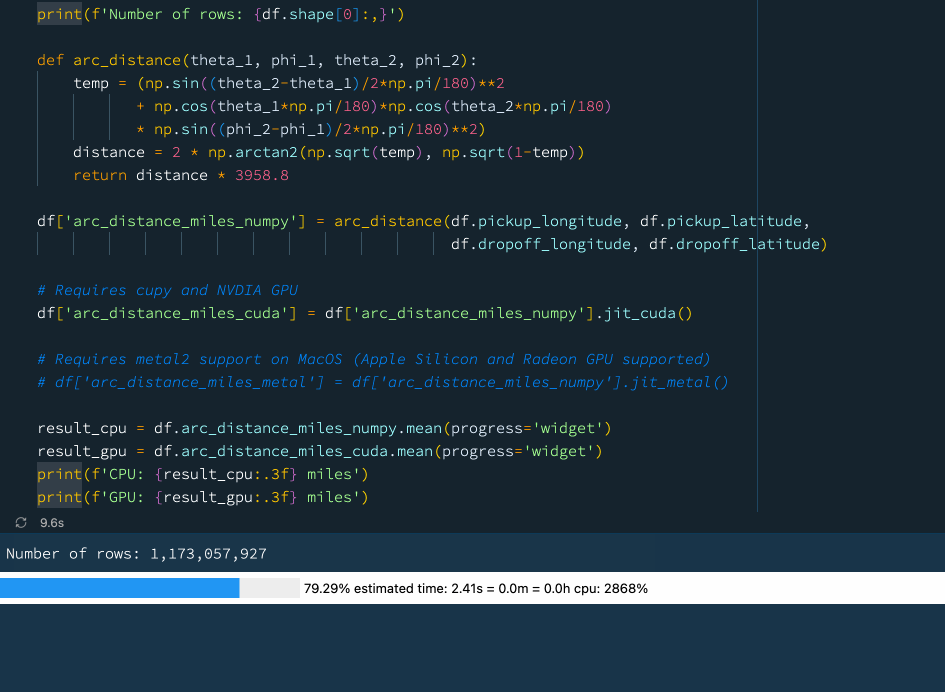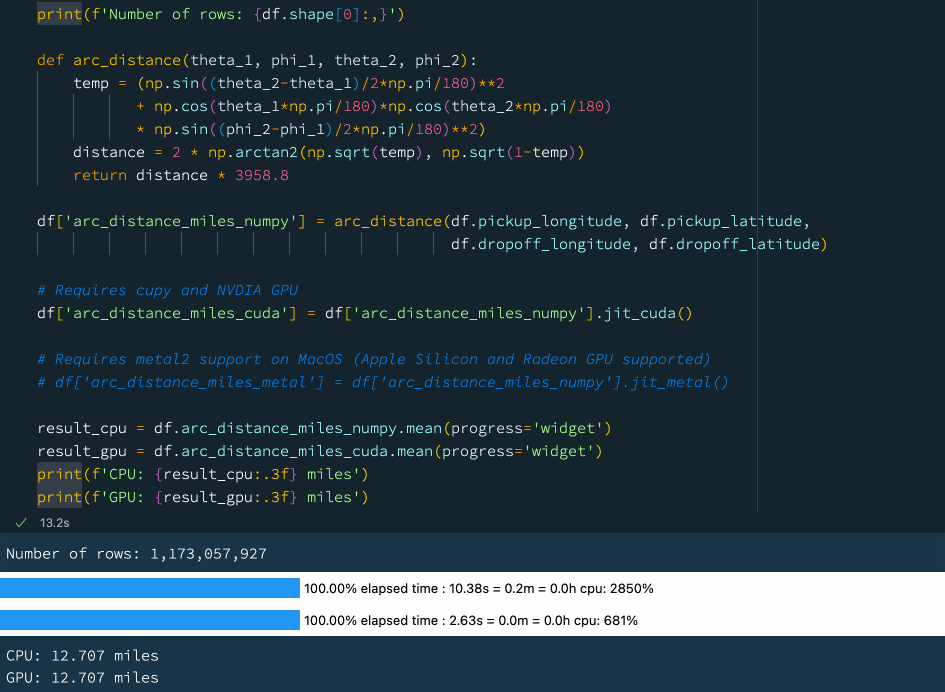
在上圖中大家可以看到使用 GPU 可以獲得相當不錯的性能提升,如果我們沒有GPU,也不用擔心!Vaex 還支持通過 ??Numba和 ??Pythran 進行即時編譯,這也可以顯著提高性能,
參考資料
- ?? Python資料分析實戰教程:https://www.showmeai.tech/tutorials/40
- ?? Vaex的GitHub頁面:https://github.com/vaexio/vaex
- ?? Apache Arrow:https://arrow.apache.org/
- ?? 本文使用的資料下載官網:https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- ?? NYC Taxi 資料集的一個子集:https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- ?? Vaex異步編程官方指南:https://vaex.io/docs/guides/async.html
- ?? Vaex的先進的細粒度的快取機制:https://vaex.io/docs/guides/caching.html
- ?? Numba:https://numba.pydata.org/
- ?? Pythran:https://pythran.readthedocs.io/en/latest/
推薦閱讀
- ?? 資料分析實戰系列 :https://www.showmeai.tech/tutorials/40
- ?? 機器學習資料分析實戰系列:https://www.showmeai.tech/tutorials/41
- ?? 深度學習資料分析實戰系列:https://www.showmeai.tech/tutorials/42
- ?? TensorFlow資料分析實戰系列:https://www.showmeai.tech/tutorials/43
- ?? PyTorch資料分析實戰系列:https://www.showmeai.tech/tutorials/44
- ?? NLP實戰資料分析實戰系列:https://www.showmeai.tech/tutorials/45
- ?? CV實戰資料分析實戰系列:https://www.showmeai.tech/tutorials/46
- ?? AI 面試題庫系列:https://www.showmeai.tech/tutorials/48
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/538927.html
標籤:其他
上一篇:在Cloudreve網盤系統中集成kkFileView在線預覽(暫時)
下一篇:1.類&物件&構造方法