
大家好,又見面了,
本文是筆者作為掘金技術社區簽約作者的身份輸出的快取專欄系列內容,將會通過系列專題,講清楚快取的方方面面,如果感興趣,歡迎關注以獲取后續更新,
在前面的幾篇文章中,我們一起聊了下本地快取的動手實作、本地快取相關的規范等,也聊了下Google的Guava Cache的相關原理與使用方式,比較心急的小伙伴已經坐不住了,提到本地快取,怎么能不提一下“地上最強”的Caffeine Cache呢?
能被小伙伴稱之為“地上最強”,可見Caffeine的魅力之大!的確,提到JAVA中的本地快取框架,Caffeine是怎么也沒法輕視的重磅嘉賓,前面幾篇文章中,我們一起探索了JVM級別的優秀快取框架Guava Cache,而相比之下,Caffeine可謂是站在巨人肩膀上,在很多方面做了深度的優化與改良,可以說在性能表現與命中率上全方位的碾壓Guava Cache,表現堪稱卓越,
下面就讓我們一起來解讀下Caffeine Cache的設計實作改進點原理,揭秘Caffeine Cache青出于藍的秘密所在,并看下如何在專案中快速的上手使用,

巨人肩膀上的產物
先來回憶下之前創建一個Guava cache物件時的代碼邏輯:
public LoadingCache<String, User> createUserCache() {
return CacheBuilder.newBuilder()
.initialCapacity(1000)
.maximumSize(10000L)
.expireAfterWrite(30L, TimeUnit.MINUTES)
.concurrencyLevel(8)
.recordStats()
.build((CacheLoader<String, User>) key -> userDao.getUser(key));
}
而使用Caffeine來創建Cache物件的時候,我們可以這么做:
public LoadingCache<String, User> createUserCache() {
return Caffeine.newBuilder()
.initialCapacity(1000)
.maximumSize(10000L)
.expireAfterWrite(30L, TimeUnit.MINUTES)
//.concurrencyLevel(8)
.recordStats()
.build(key -> userDao.getUser(key));
}
可以發現,兩者的使用思路與方法定義非常相近,對于使用過Guava Cache的小伙伴而言,幾乎可以無門檻的直接上手使用,當然,兩者也還是有點差異的,比如Caffeine創建物件時不支持使用concurrencyLevel來指定并發量(因為改進了并發控制機制),這些我們在下面章節中具體介紹,
相較于Guava Cache,Caffeine在整體設計理念、實作策略以及介面定義等方面都基本繼承了前輩的優秀特性,作為新時代背景下的后來者,Caffeine也做了很多細節層面的優化,比如:
-
基礎資料結構層面優化
借助JAVA8對ConcurrentHashMap底層由鏈表切換為紅黑樹、以及廢棄分段鎖邏輯的優化,提升了Hash沖突時的查詢效率以及并發場景下的處理性能, -
資料驅逐(淘汰)策略的優化
通過使用改良后的W-TinyLFU演算法,提供了更佳的熱點資料留存效果,提供了近乎完美的熱點資料命中率,以及更低消耗的程序維護 -
異步并行能力的全面支持
完美適配JAVA8之后的并行編程場景,可以提供更為優雅的并行編碼體驗與并發效率,
通過各種措施的改良,成就了Caffeine在功能與性能方面不俗的表現,
Caffeine與Guava —— 是傳承而非競爭
很多人都知道Caffeine在各方面的表現都由于Guava Cache, 甚至對比之下有些小伙伴覺得Guava Cache簡直一無是處,但不可否認的是,在曾經的一段時光里,Guava Cache提供了盡可能高效且輕量級的并發本地快取工具框架,技術總是在不斷的更新與迭代的,縱使優秀如Guava Cache這般,終究是難逃淪為時代眼淚的結局,
縱觀Caffeine,其原本就是基于Guava cache基礎上范訓而來的改良版本,眾多的特性與設計思路都完全沿用了Guava Cache相同的邏輯,且提供的介面與使用風格也與Guava Cache無異,所以,從這個層面而言,本人更愿意將Caffeine看作是Guava Cache的一種優秀基因的傳承與發揚光大,而非是競爭與打壓關系,
那么Caffeine能夠青出于藍的秘訣在哪呢?下面總結了其最關鍵的3大要點,一起看下,
貫穿始終的異步策略
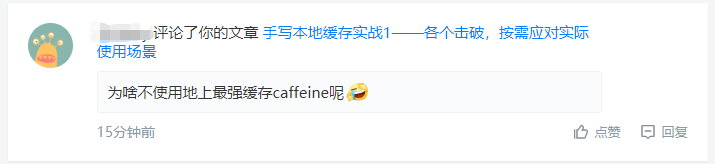
Caffeine在請求上的處理流程做了很多的優化,效果比較顯著的當屬資料淘汰處理執行策略的改進,之前在Guava Cache的介紹中,有提過Guava Cache的策略是在請求的時候同時去執行對應的清理操作,也就是讀請求中混雜著寫操作,雖然Guava Cache做了一系列的策略來減少其觸發的概率,但一旦觸發總歸是會對讀取操作的性能有一定的影響,
Caffeine則采用了異步處理的策略,get請求中雖然也會觸發淘汰資料的清理操作,但是將清理任務添加到了獨立的執行緒池中進行異步的不會阻塞 get 請求的執行與回傳,這樣大大縮短了get請求的執行時長,提升了回應性能,
除了對自身的異步處理優化,Caffeine還提供了全套的Async異步處理機制,可以支持業務在異步并行流水線式處理場景中使用以獲得更加絲滑的體驗,
Caffeine完美的支持了在異步場景下的流水線處理使用場景,回源操作也支持異步的方式來完成,CompletableFuture并行流水線能力,是JAVA8在異步編程領域的一個重大改進,可以將一系列耗時且無依賴的操作改為并行同步處理,并等待各自處理結果完成后繼續進行后續環節的處理,由此來降低阻塞等待時間,進而達到降低請求鏈路時長的效果,
比如下面這段異步場景使用Caffeine并行處理的代碼:
public static void main(String[] args) throws Exception {
AsyncLoadingCache<String, String> asyncLoadingCache = buildAsyncLoadingCache();
// 寫入快取記錄(value值為異步獲取)
asyncLoadingCache.put("key1", CompletableFuture.supplyAsync(() -> "value1"));
// 異步方式獲取快取值
CompletableFuture<String> completableFuture = asyncLoadingCache.get("key1");
String value = https://www.cnblogs.com/softwarearch/p/completableFuture.join();
System.out.println(value);
}
ConcurrentHashMap優化特性
作為使用JAVA8新特性進行構建的Caffeine,充分享受了JAVA8語言層面優化改進所帶來的性能上的增益,我們知道ConcurrentHashMap是JDK原生提供的一個執行緒安全的HashMap容器型別,而Caffeine底層也是基于ConcurrentHashMap進行構建與資料存盤的,
在JAVA7以及更早的版本中,ConcurrentHashMap采用的是分段鎖的策略來實作執行緒安全的(前面文章中我們講過Guava Cache采用的也是分段鎖的策略),分段鎖雖然在一定程度上可以降低鎖競爭的沖突,但是在一些極高并發場景下,或者并發請求分布較為集中的時候,仍然會出現較大概率的阻塞等待情況,此外,這些版本中ConcurrentHashMap底層采用的是陣列+鏈表的存盤形式,這種情況在Hash沖突較為明顯的情況下,需要頻繁的遍歷鏈表操作,也會影響整體的處理性能,
JAVA8中對ConcurrentHashMap的實作策略進行了較大調整,大幅提升了其在的并發場景的性能表現,主要可以分為2個方面的優化,
- 陣列+鏈表結構自動升級為
陣列+紅黑樹
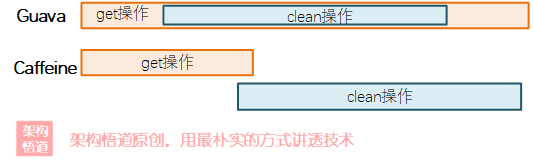
默認情況下,ConcurrentHashMap的底層結構是陣列+鏈表的形式,元素存盤的時候會先計算下key對應的Hash值來將其劃分到對應的陣列對應的鏈表中,而當鏈表中的元素個數超過8個的時候,鏈表會自動轉換為紅黑樹結構,如下所示:
在遍歷查詢方面,紅黑樹有著比鏈表要更加卓越的性能表現,
- 分段鎖升級為
synchronized+CAS鎖
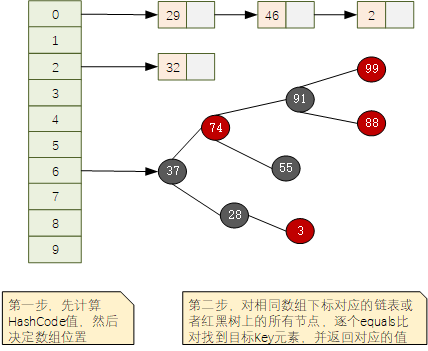
分段鎖的核心思想就是縮小鎖的范圍,進而降低鎖競爭的概率,當資料量特別大的時候,其實每個鎖涵蓋的資料范圍依舊會很大,如果并發請求量特別大的時候,依舊會出現很多執行緒搶奪同一把分段鎖的情況,
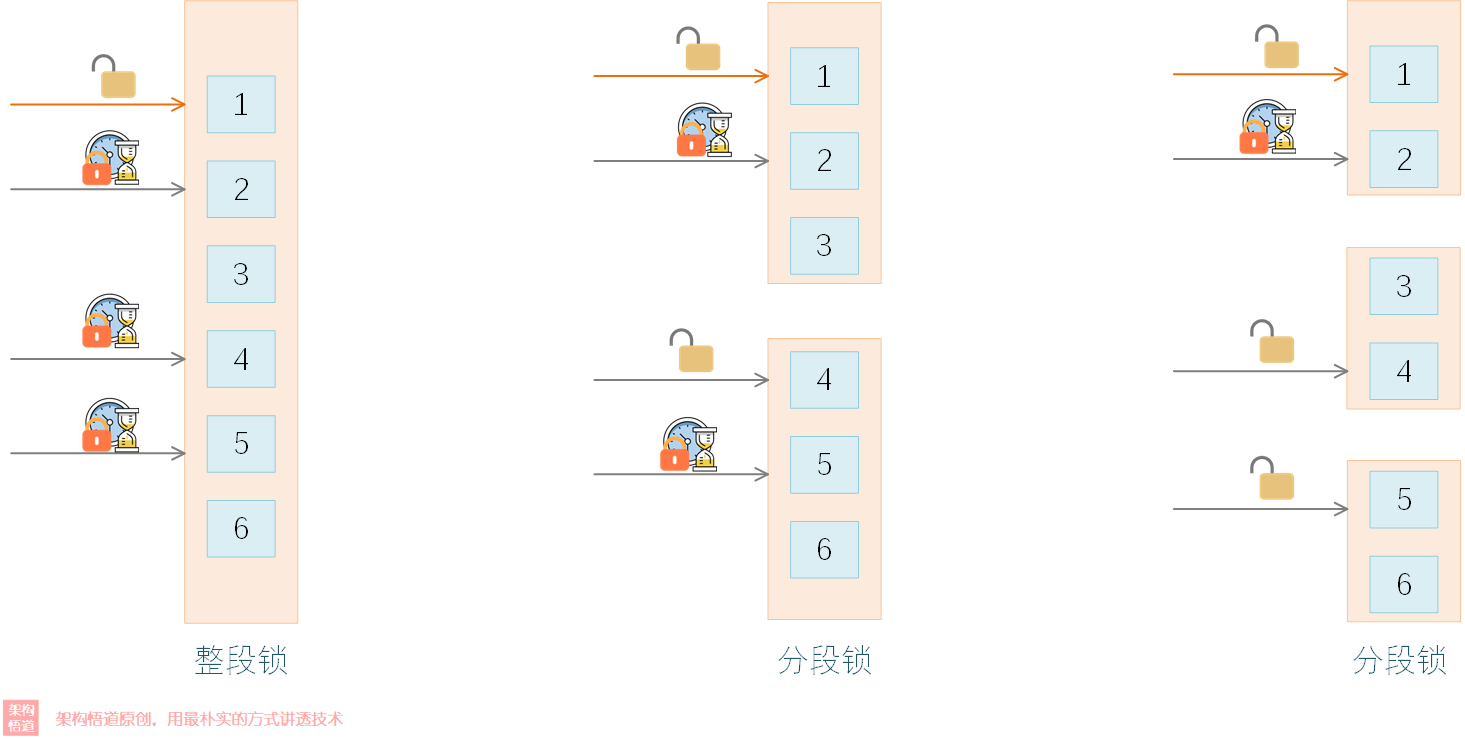
在JAVA8中,ConcurrentHashMap 廢棄分段鎖的概念,改為了synchronized+CAS的策略,借助CAS的樂觀鎖策略,大大提升了讀多寫少場景下的并發能力,
得益于JAVA8對ConcurrentHashMap的優化,使得Caffeine在多執行緒并發場景下的表現非常的出色,
淘汰演算法W-LFU的加持
常規的快取淘汰演算法一般采用FIFO、LRU或者LFU,但是這些演算法在實際快取場景中都會存在一些弊端:
| 演算法 | 弊端說明 |
|---|---|
| FIFO | 先進先出策略,屬于一種最為簡單與原始的策略,如果快取使用頻率較高,會導致快取資料始終在不停的進進出出,影響性能,且命中率表現也一般, |
| LRU | 最近最久未使用策略,保留最近被訪問到的資料,而淘汰最久沒有被訪問的資料,如果遇到偶爾的批量刷資料情況,很容易將其他快取內容都擠出記憶體,帶來快取擊穿的風險, |
| LFU | 最近少頻率策略,這種根據訪問次數進行淘汰,相比而言記憶體中存盤的熱點資料命中率會更高些,缺點就是需要維護獨立欄位用來記錄每個元素的訪問次數,占用記憶體空間, |
為了保證命中率,一般快取框架都會選擇使用LRU或者LFU策略,很少會有使用FIFO策略進行資料淘汰的,Caffeine快取的LFU采用了Count-Min Sketch頻率統計演算法(參見下圖示意,圖片來源:點此查看),由于該LFU的計數器只有4bit大小,所以稱為TinyLFU,在TinyLFU演算法基礎上引入一個基于LRU的Window Cache,這個新的演算法叫就叫做W-TinyLFU,
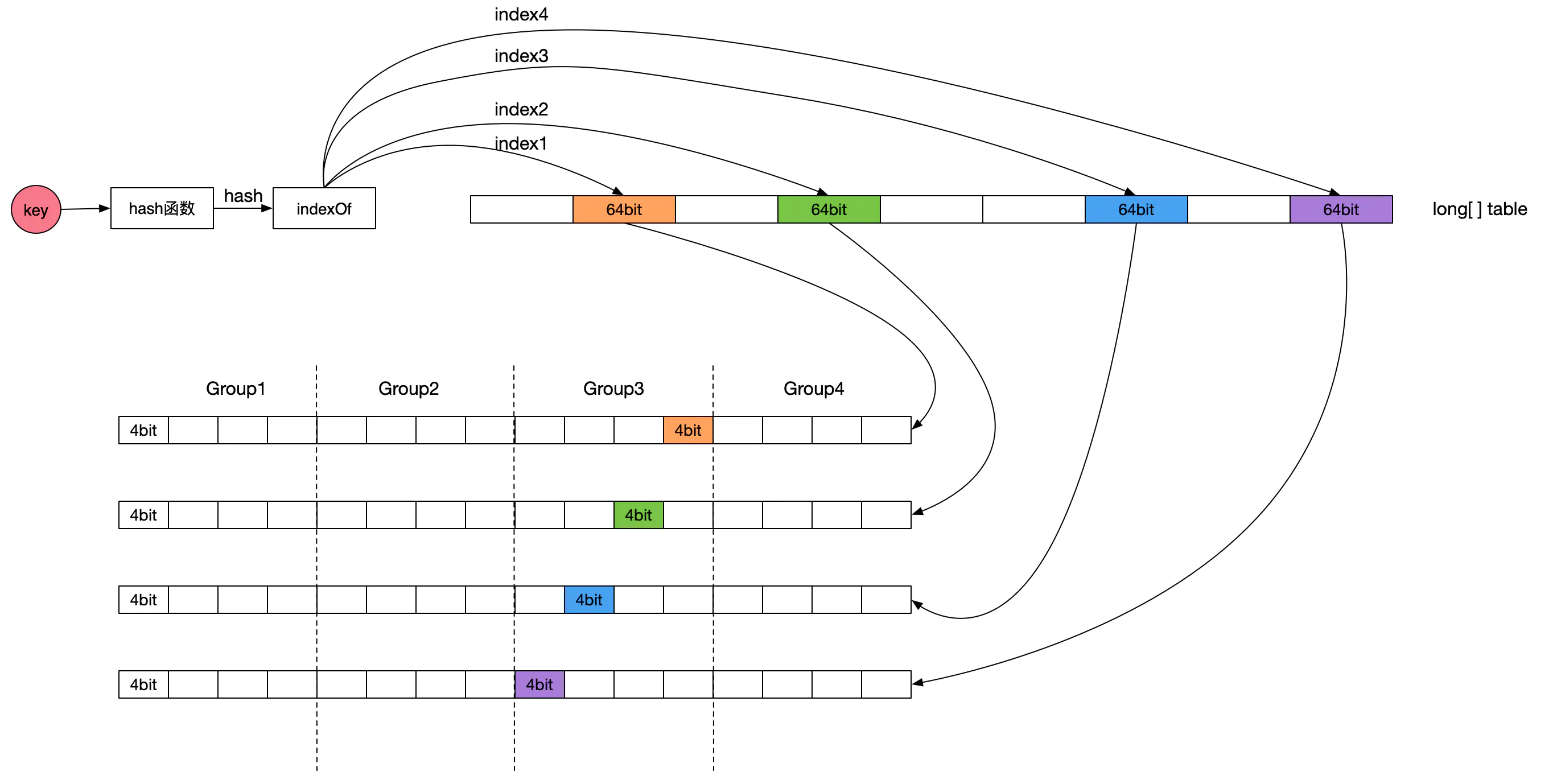
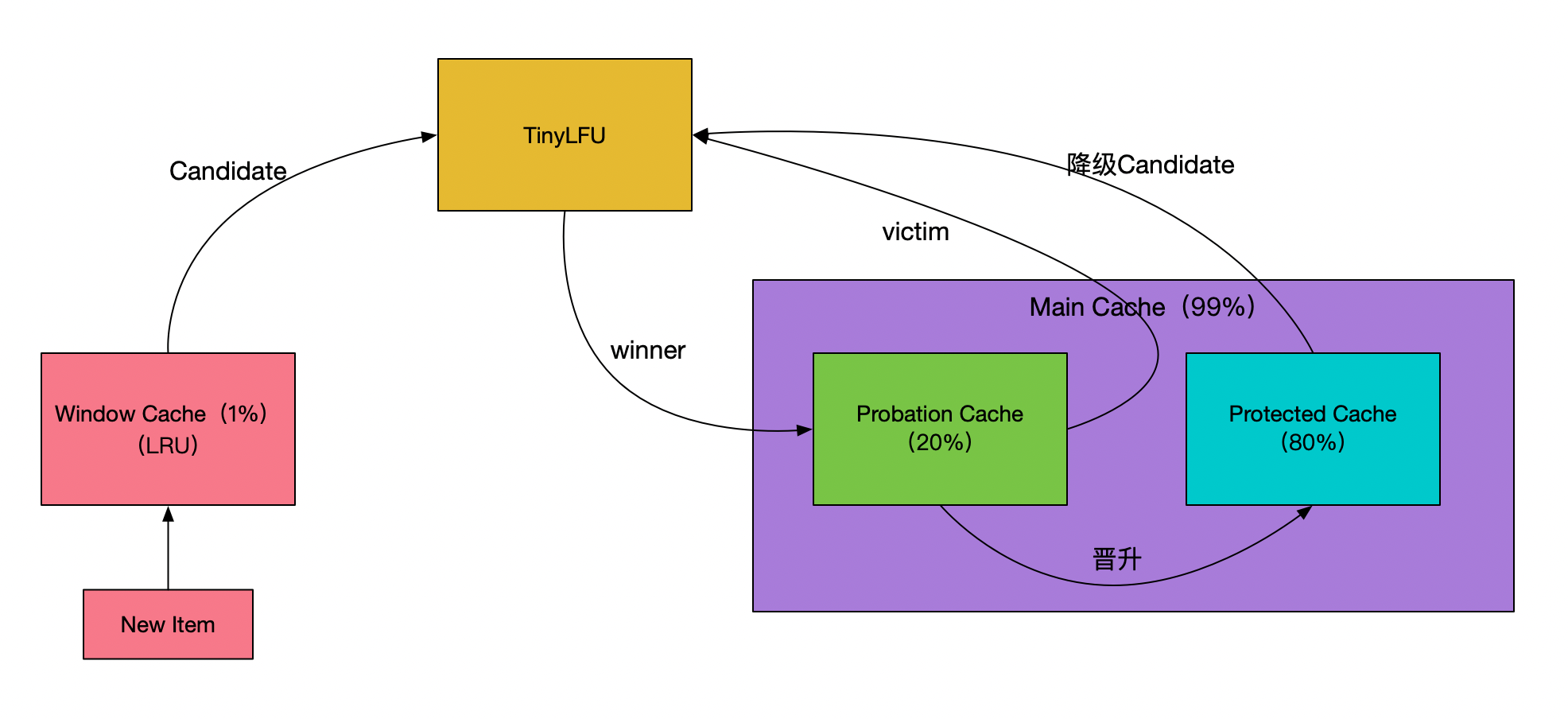
W-TinyLFU演算法有效的解決了LRU以及LFU存在的弊端,為Caffeine提供了大部分場景下近乎完美的命中率表現,
關于W-TinyLFU的具體說明,有興趣的話可以點此了解,
如何選擇
在Caffeine與Guava Cache之間如何選擇?其實Spring已經給大家做了示范,從Spring5開始,其內置的本地快取框架由Guava Cache切換到了Caffeine,應用到專案中的快取選型,可以結合專案實際從多個方面進行抉擇,
-
全新專案,閉眼選Caffeine
Java8也已經被廣泛的使用多年,現在的新專案基本上都是JAVA8或以上的版本了,如果有新的專案需要做本地快取選型,閉眼選擇Caffeine就可以,錯不了, -
歷史低版本JAVA專案
由于Caffeine對JAVA版本有依賴要求,對于一些歷史專案的維護而言,如果專案的JDK版本過低則無法使用Caffeine,這種情況下Guava Cache依舊是一個不錯的選擇,當然,也可以下定決心將專案的JDK版本升級到JDK1.8+版本,然后使用Caffeine來獲得更好的性能體驗 —— 但是對于一個歷史專案而言,升級基礎JDK版本帶來的影響可能會比較大,需要提前評估好, -
有同時使用Guava其它能力
如果你的專案里面已經有引入并使用了Guava提供的相關功能,這種情況下為了避免太多外部組件的引入,也可以直接使用Guava提供的Cache組件能力,畢竟Guava Cache的表現并不算差,應付常規場景的本都快取訴求完全足夠,當然,為了追求更加極致的性能表現,另外引入并使用Caffeine也完全沒有問題,
Caffeine使用
依賴引入
使用Caffeine,首先需要引入對應的庫檔案,如果是Maven專案,則可以在pom.xml中添加依賴宣告來完成引入,
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.1</version>
</dependency>
注意,如果你的本地JDK版本比較低,引入上述較新版本的時候可能會編譯報錯:

遇到這種情況,可以考慮升級本地JDK版本(實際專案中升級可能有難度),或者將Caffeine版本降低一些,比如使用2.9.3版本,具體的版本串列,可以點擊此處進行查詢,
這樣便大功告成啦,
容器創建
和之前我們聊過的Guava Cache創建快取物件的操作相似,我們可以通過構造器來方便的創建出一個Caffeine物件,
Cache<Integer, String> cache = Caffeine.newBuilder().build();
除了上述這種方式,Caffeine還支持使用不同的構造器方法,構建不同型別的Caffeine物件,對各種構造器方法梳理如下:
| 方法 | 含義說明 |
|---|---|
| build() | 構建一個手動回源的Cache物件 |
| build(CacheLoader) | 構建一個支持使用給定CacheLoader物件進行自動回源操作的LoadingCache物件 |
| buildAsync() | 構建一個支持異步操作的異步快取物件 |
| buildAsync(CacheLoader) | 使用給定的CacheLoader物件構建一個支持異步操作的快取物件 |
| buildAsync(AsyncCacheLoader) | 與buildAsync(CacheLoader)相似,區別點僅在于傳入的引數型別不一樣, |
為了便于異步場景中處理,可以通過buildAsync()構建一個手動回源資料加載的快取物件:
public static void main(String[] args) {
AsyncCache<String, User> asyncCache = Caffeine.newBuilder()
.buildAsync();
User user = asyncCache.get("123", s -> {
System.out.println("異步callable thread:" + Thread.currentThread().getId());
return userDao.getUser(s);
}).join();
}
當然,為了支持異步場景中的自動異步回源,我們可以通過buildAsync(CacheLoader)或者buildAsync(AsyncCacheLoader)來實作:
public static void main(String[] args) throws Exception{
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(key -> userDao.getUser(key));
User user = asyncLoadingCache.get("123").join();
}
在創建快取物件的同時,可以指定此快取物件的一些處理策略,比如容量限制、比如過期策略等等,作為以替換Guava Cache為己任的后繼者,Caffeine在快取容器物件創建時的相關構建API也沿用了與Guava Cache相同的定義,常見的方法及其含義梳理如下:
| 方法 | 含義說明 |
|---|---|
| initialCapacity | 待創建的快取容器的初始容量大小(記錄條數) |
| maximumSize | 指定此快取容器的最大容量(最大快取記錄條數) |
| maximumWeight | 指定此快取容器的最大容量(最大比重值),需結合weighter方可體現出效果 |
| expireAfterWrite | 設定過期策略,按照資料寫入時間進行計算 |
| expireAfterAccess | 設定過期策略,按照資料最后訪問時間來計算 |
| expireAfter | 基于個性化定制的邏輯來實作過期處理(可以定制基于新增、讀取、更新等場景的過期策略,甚至支持為不同記錄指定不同過期時間) |
| weighter | 入參為一個函式式介面,用于指定每條存入的快取資料的權重占比情況,這個需要與maximumWeight結合使用 |
| refreshAfterWrite | 快取寫入到快取之后 |
| recordStats | 設定開啟此容器的資料加載與快取命中情況統計 |
綜合上述方法,我們可以創建出更加符合自己業務場景的快取物件,
public static void main(String[] args) {
AsyncLoadingCache<String, User> asyncLoadingCache = CaffeinenewBuilder()
.initialCapacity(1000) // 指定初始容量
.maximumSize(10000L) // 指定最大容量
.expireAfterWrite(30L, TimeUnit.MINUTES) // 指定寫入30分鐘后過期
.refreshAfterWrite(1L, TimeUnit.MINUTES) // 指定每隔1分鐘重繪下資料內容
.removalListener((key, value, cause) ->
System.out.println(key + "移除,原因:" + cause)) // 監聽記錄移除事件
.recordStats() // 開啟快取操作資料統計
.buildAsync(key -> userDao.getUser(key)); // 構建異步CacheLoader加載型別的快取物件
}
業務使用
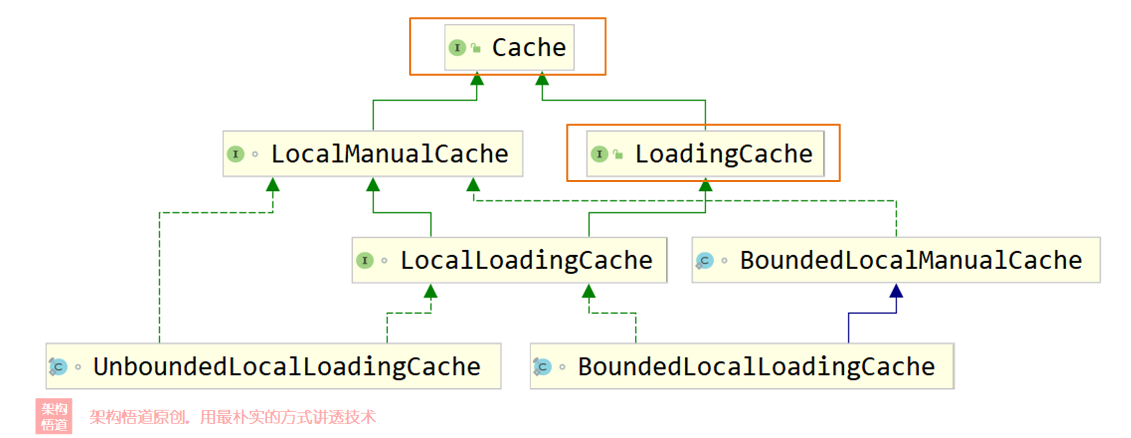
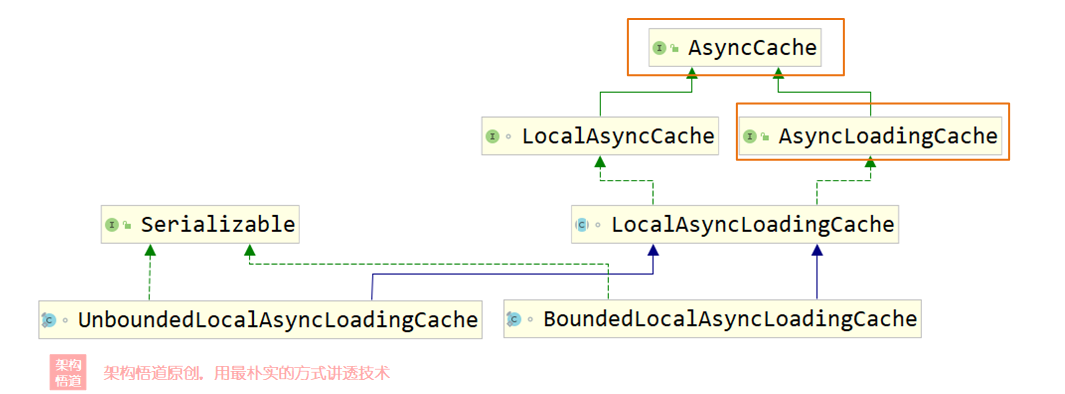
在上一章節創建快取物件的時候,Caffeine支持創建出同步快取與異步快取,也即Cache與AsyncCache兩種不同型別,而如果指定了CacheLoader的時候,又可以細分出LoadingCache子型別與AsyncLoadingCache子型別,對于常規業務使用而言,知道這四種型別的快取型別基本就可以滿足大部分場景的正常使用了,但是Caffeine的整體快取型別其實是細分成了很多不同的具體型別的,從下面的UML圖上可以看出一二,
- 同步快取
- 異步快取
業務層面對快取的使用,無外乎往快取里面寫入資料、從快取里面讀取資料,不管是同步還是異步,常見的用于操作快取的方法梳理如下:
| 方法 | 含義說明 |
|---|---|
| get | 根據key獲取指定的快取值,如果沒有則執行回源操作獲取 |
| getAll | 根據給定的key串列批量獲取對應的快取值,回傳一個map格式的結果,沒有命中快取的部分會執行回源操作獲取 |
| getIfPresent | 不執行回源操作,直接從快取中嘗試獲取key對應的快取值 |
| getAllPresent | 不執行回源操作,直接從快取中嘗試獲取給定的key串列對應的值,回傳查詢到的map格式結果, 異步場景不支持此方法 |
| put | 向快取中寫入指定的key與value記錄 |
| putAll | 批量向快取中寫入指定的key-value記錄集,異步場景不支持此方法 |
| asMap | 將快取中的資料轉換為map格式回傳 |
針對同步快取,業務代碼中操作使用舉例如下:
public static void main(String[] args) throws Exception {
LoadingCache<String, String> loadingCache = buildLoadingCache();
loadingCache.put("key1", "value1");
String value = https://www.cnblogs.com/softwarearch/p/loadingCache.get("key1");
System.out.println(value);
}
同樣地,異步快取的時候,業務代碼中操作示意如下:
public static void main(String[] args) throws Exception {
AsyncLoadingCache<String, String> asyncLoadingCache = buildAsyncLoadingCache();
// 寫入快取記錄(value值為異步獲取)
asyncLoadingCache.put("key1", CompletableFuture.supplyAsync(() -> "value1"));
// 異步方式獲取快取值
CompletableFuture<String> completableFuture = asyncLoadingCache.get("key1");
String value = https://www.cnblogs.com/softwarearch/p/completableFuture.join();
System.out.println(value);
}
小結回顧
好啦,關于Caffeine Cache的具體使用方式、核心的優化改進點相關的內容,以及與Guava Cache的比較,就介紹到這里了,不知道小伙伴們是否對Caffeine Cache有了全新的認識了呢?而關于Caffeine Cache與Guava Cache的差別,你是否有自己的一些想法與見解呢?歡迎評論區一起交流下,期待和各位小伙伴們一起切磋、共同成長,
下一篇文章中,我們將深入講解下Caffeine同步、異步回源操作的各種不同實作,以及對應的實作與底層設計邏輯,如有興趣,歡迎關注后續更新,
?? 補充說明1 :
本文屬于《深入理解快取原理與實戰設計》系列專欄的內容之一,該專欄圍繞快取這個宏大命題進行展開闡述,全方位、系統性地深度剖析各種快取實作策略與原理、以及快取的各種用法、各種問題應對策略,并一起探討下快取設計的哲學,
如果有興趣,也歡迎關注此專欄,
?? 補充說明2 :
- 關于本文中涉及的演示代碼的完整示例,我已經整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點贊 + 關注讓我感受到您的支持,也可以關注下我的公眾號【架構悟道】,獲取更及時的更新,
期待與你一起探討,一起成長為更好的自己,

本文來自博客園,作者:架構悟道,歡迎關注公眾號[架構悟道]持續獲取更多干貨,轉載請注明原文鏈接:https://www.cnblogs.com/softwarearch/p/16927942.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/539300.html
標籤:Java
下一篇:Spring框架之IOC入門