Redis資料結構
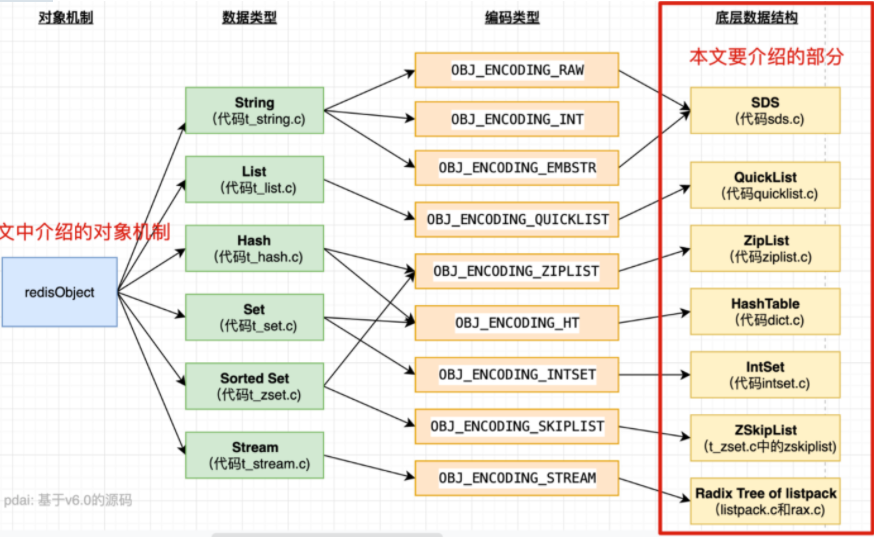
1. SDS
Redis 是用 C 語言寫的,但是對于 Redis 的字串,卻不是 C 語言中的字串(即以空字符’\0’結尾的字符陣列),它是自己構建了一種名為 簡單動態字串(simple dynamic string,SDS)的抽象型別,并將 SDS 作為 Redis 的默認字串表示
因為 C 語言字串存在很多問題:
- 獲取字串長度的需要通過運算
- 非二進制安全
- 不可修改
例如,我們執行命令:
127.0.0.1:6379> set name zhangsan
ok
那么 Redis 將在底層創建兩個 SDS,其中一個是包含 “name” 的 SDS,另一個是包含 “zhangsan” 的 SDS,
1.1 SDS 是什么
Redis 是 C 語言實作的,其中 SDS 是一個結構體,原始碼如下:

例如,一個包含字串 “name” 的 sds 結構如下:第一次分配時并不會分配多余空間
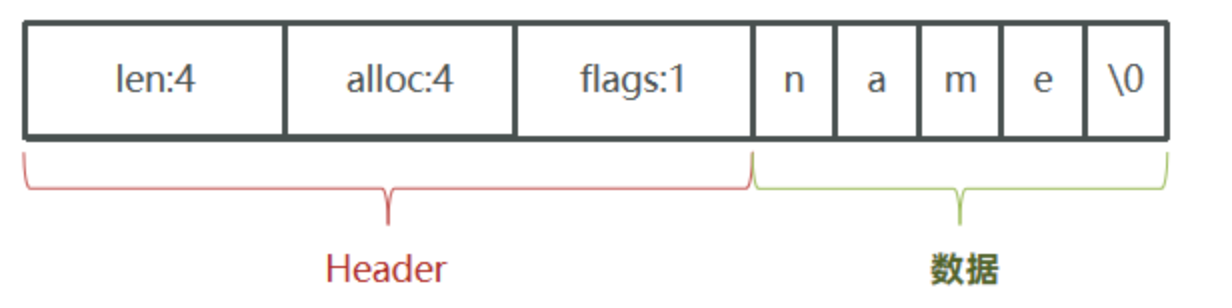
SDS 之所以叫做動態字串,是因為它具備動態擴容的能力,例如一個內容為 “hi” 的 SDS:

假如我們要給 SDS 追加一段字串 “,Amy”,這里首先會申請新記憶體空間:
如果新字串小于 1M,則新空間為擴展后字串長度的兩倍 + 1;
如果新字串大于 1M,則新空間為擴展后字串長度 + 1M+1,稱為記憶體預分配,

1.2 SDS 的優點
- 獲取字串長度的時間復雜度為 O (1)
- 支持動態擴容
- 支持記憶體預分配,減少用戶執行緒與內核執行緒互動次數
- 二進制安全
一般來說,SDS 除了保存資料庫中的字串值以外,SDS 還可以作為緩沖區(buffer):包括 AOF 模塊中的 AOF 緩沖區以及客戶端狀態中的輸入緩沖區
2. Inset
intset 是 set 集合的一種實作方式,基于整數陣列來實作,并且具備長度可變、有序等特征,
2.1 Inset是什么?
結構如下:

其中的 encoding 包含三種模式,表示存盤的整數大小不同:

為了方便查找,Redis 會將 intset 中所有的整數按照升序依次保存在 contents 陣列中,結構如圖:
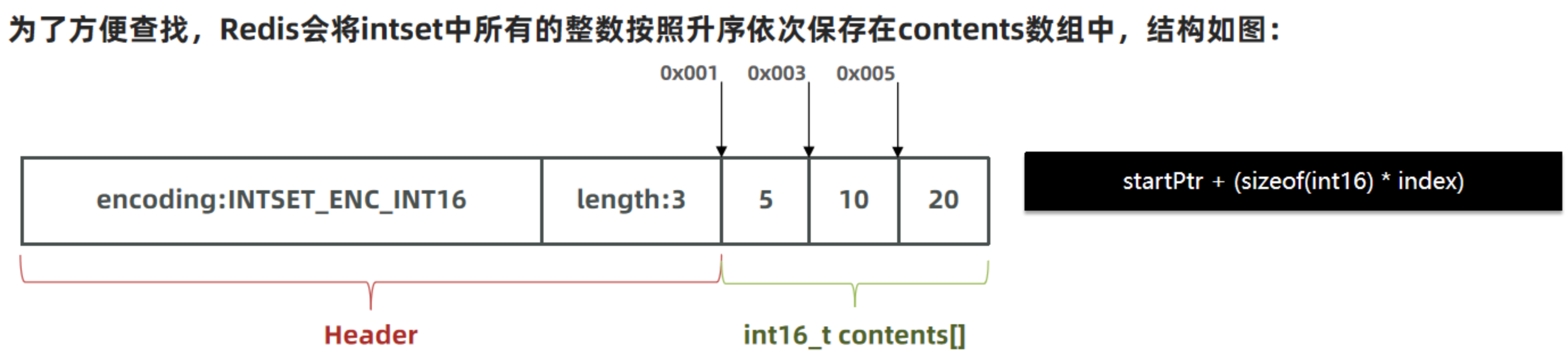
現在,陣列中每個數字都在 int16_t 的范圍內,因此采用的編碼方式是 INTSET_ENC_INT16,每部分占用的位元組大小為:
- encoding:4 位元組 (可以理解為標識每個元素的型別)
- length:4 位元組
- contents:2 位元組 * 3 = 6 位元組
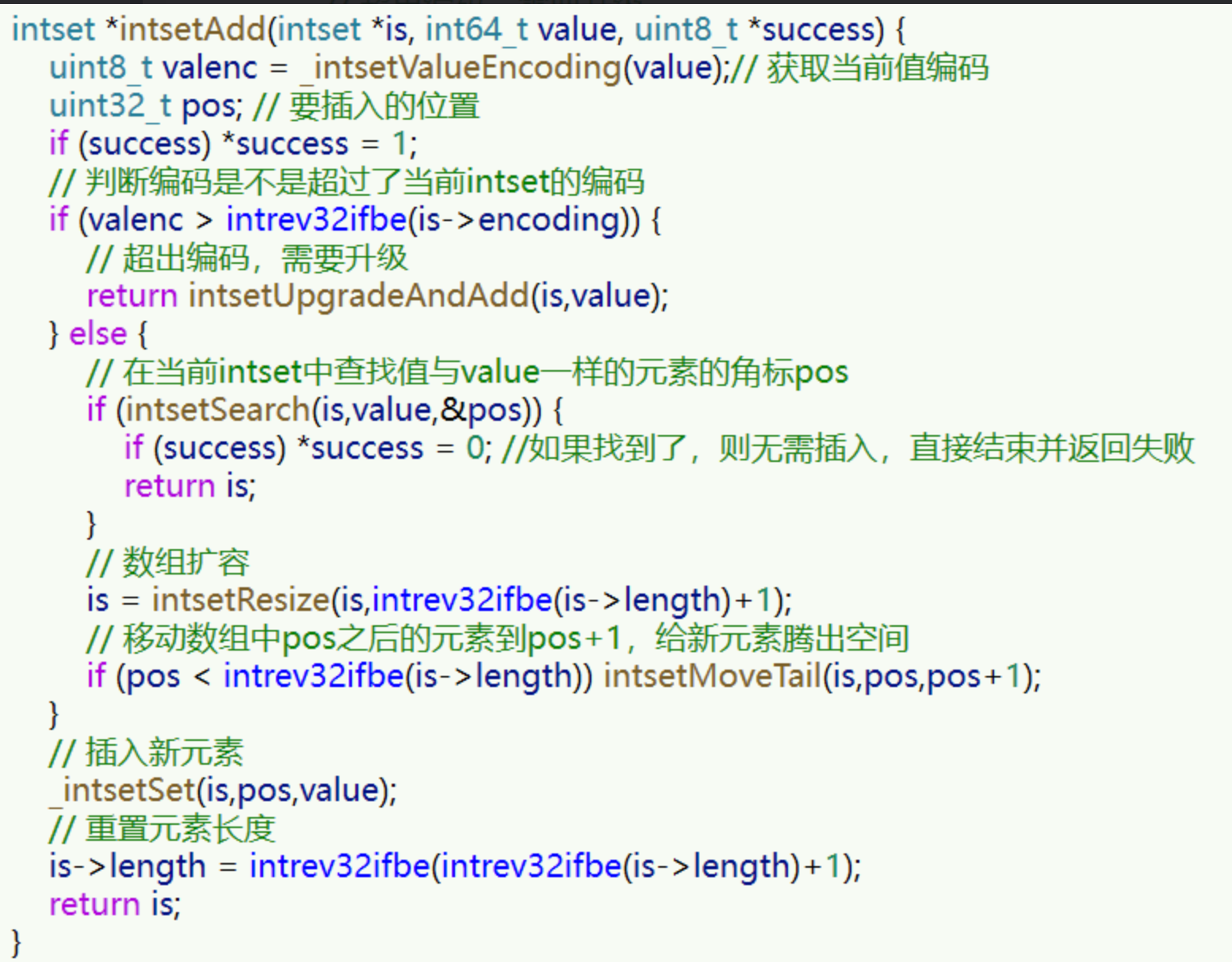
2.2 inset自動升級
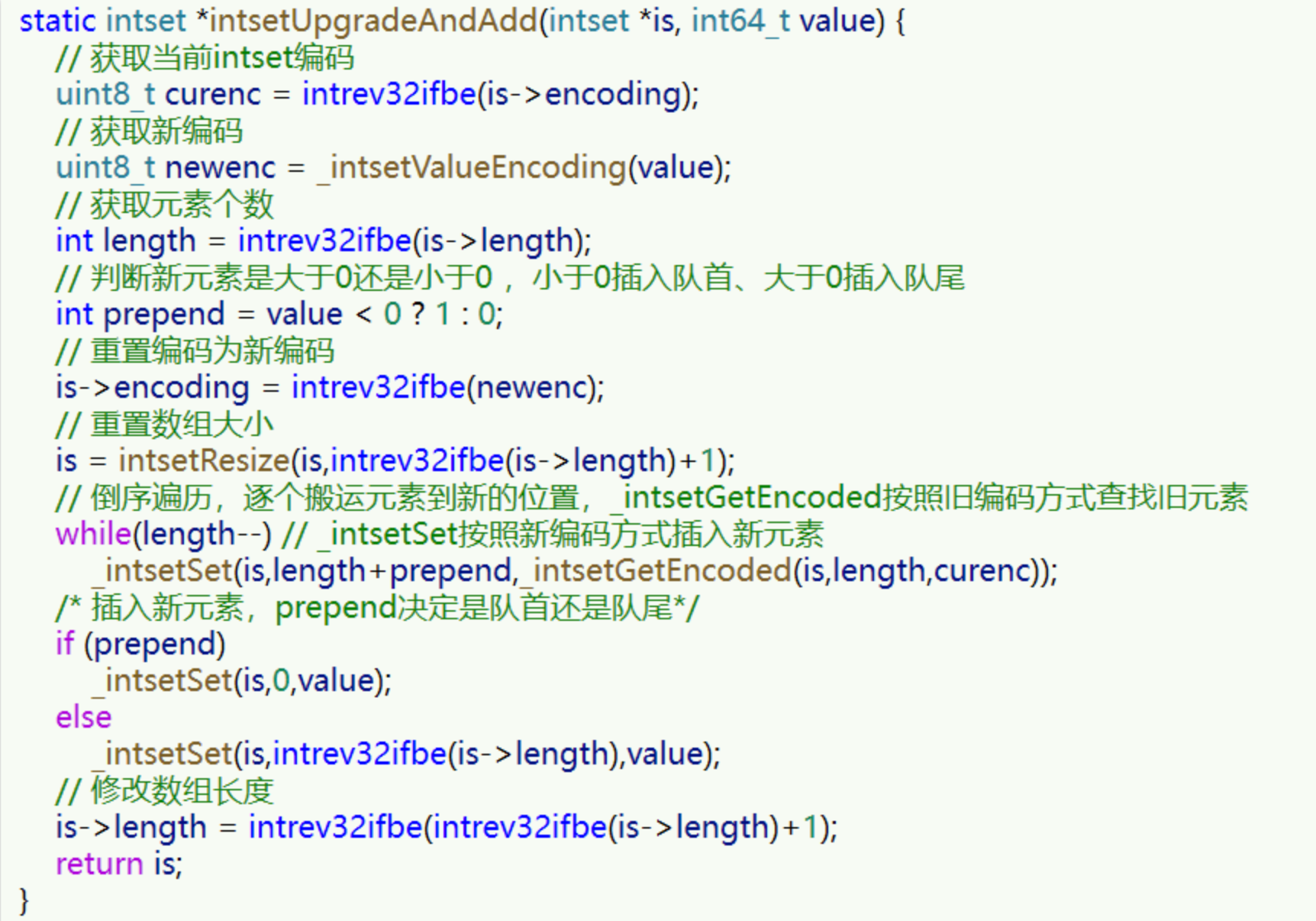
我們向該其中添加一個數字:50000,這個數字超出了 int16_t 的范圍,intset 會自動升級編碼方式到合適的大小,
以當前案例來說流程如下:
- 升級編碼為 INTSET_ENC_INT32 , 每個整數占 4 位元組,并按照新的編碼方式及元素個數擴容陣列
- 倒序依次將陣列中的元素拷貝到擴容后的正確位置
- 將待添加的元素放入陣列末尾
- 最后,將 inset 的 encoding 屬性改為 INTSET_ENC_INT32,將 length 屬性改為 4
那么如果我們洗掉掉剛加入的 int32 型別時,會不會做一個降級操作呢?
不會,主要還是減少開銷的權衡

原始碼如下:
2.3 總結:
Intset 可以看做是特殊的整數陣列,具備一些特點:
- Redis 會確保 Intset 中的元素唯一、有序
- 具備型別升級機制,可以節省記憶體空間
- 底層采用二分查找方式來查詢
3. Dict
我們知道 Redis 是一個鍵值型(Key-Value Pair)的資料庫,我們可以根據鍵實作快速的增刪改查,而鍵與值的映射關系正是通過 Dict 來實作的,是 set 和 hash 的實作方式之一
3.1 Dict是什么?
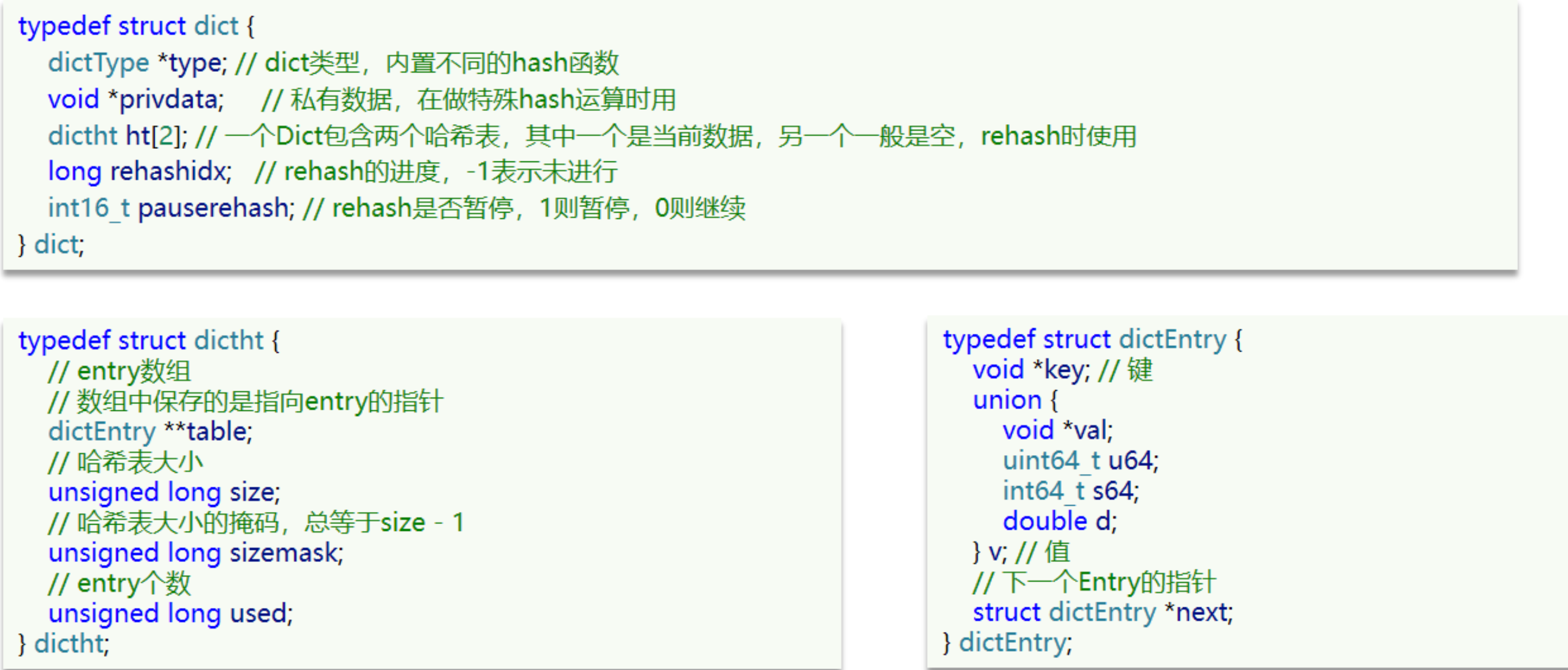
Dict 由三部分組成,分別是:哈希表(DictHashTable)、哈希節點(DictEntry)、字典(Dict)

當我們向 Dict 添加鍵值對時,Redis 首先根據 key 計算出 hash 值(h),然后利用 h & sizemask 來計算元素應該存盤到陣列中的哪個索引位置,我們存盤 k1=v1,假設 k1 的哈希值 h =1,則 1&3 =1,因此 k1=v1 要存盤到陣列角標 1 位置,
注意這里還有一個指向下一個哈希表節點的指標,我們知道哈希表最大的問題是存在哈希沖突,如何解決哈希沖突,有開放地址法和鏈地址法,這里采用的便是鏈地址法,通過 next 這個指標可以將多個哈希值相同的鍵值對連接在一起,用來解決哈希沖突,

Dict 由三部分組成,分別是:哈希表(DictHashTable)、哈希節點(DictEntry)、字典(Dict)
3.2 深入理解
- 哈希演算法:Redis 計算哈希值和索引值方法如下:
#1、使用字典設定的哈希函式,計算鍵 key 的哈希值
hash = dict->type->hashFunction(key);
#2、使用哈希表的sizemask屬性和第一步得到的哈希值,計算索引值
index = hash & dict->ht[x].sizemask;
-
解決哈希沖突:這個問題上面我們介紹了,方法是鏈地址法,通過字典里面的 *next 指標指向下一個具有相同索引值的哈希表節點,
-
擴容和收縮:當哈希表保存的鍵值對太多或者太少時,就要通過 rerehash (重新散列)來對哈希表進行相應的擴展或者收縮,具體步驟:
- 計算新 hash 表的 realeSize,值取決于當前要做的是擴容還是收縮:
- 如果是擴容,則新 size 為第一個大于等于 dict.ht [0].used + 1 的 2^n
- 如果是收縮,則新 size 為第一個小于等于 dict.ht [0].used 的 2^n (不得小于 4)
- 按照新的 realeSize 申請記憶體空間,創建 dictht ,并賦值給 dict.ht [1]
- 設定 dict.rehashidx = 0,標示開始 rehash
- 將 dict.ht [0] 中的每一個 dictEntry 都 rehash 到 dict.ht [1]
- 將 dict.ht [1] 賦值給 dict.ht [0],給 dict.ht [1] 初始化為空哈希表,釋放原來的 dict.ht [0] 的記憶體
- 將 rehashidx 賦值為 - 1,代表 rehash 結束
- 在 rehash 程序中,新增操作,則直接寫入 ht [1],查詢、修改和洗掉則會在 dict.ht [0] 和 dict.ht [1] 依次查找并執行,這樣可以確保 ht [0] 的資料只減不增,隨著 rehash 最終為空
- 觸發擴容的條件:
- 服務器目前沒有執行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且負載因子大于等于 1,
- 服務器目前正在執行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且負載因子大于等于 5,
ps:負載因子 = 哈希表已保存節點數量 / 哈希表大小,
- 漸進式rehash
什么叫漸進式 rehash?也就是說擴容和收縮操作不是一次性、集中式完成的,而是分多次、漸進式完成的,如果保存在 Redis 中的鍵值對只有幾個幾十個,那么 rehash 操作可以瞬間完成,但是如果鍵值對有幾百萬,幾千萬甚至幾億,那么要一次性的進行 rehash,勢必會造成 Redis 一段時間內不能進行別的操作,所以 Redis 采用漸進式 rehash, 這樣在進行漸進式 rehash 期間,字典的洗掉查找更新等操作可能會在兩個哈希表上進行,第一個哈希表沒有找到,就會去第二個哈希表上進行查找,但是進行 增加操作,一定是在新的哈希表上進行的,
3.3 總結:
Dict 的結構:
- 類似 java 的 HashTable,底層是陣列加鏈表來解決哈希沖突
- Dict 包含兩個哈希表,ht [0] 平常用,ht [1] 用來 rehash
Dict 的伸縮:
- 當 LoadFactor 大于 5 或者 LoadFactor 大于 1 并且沒有子行程任務時,Dict 擴容
- 當 LoadFactor 小于 0.1 時,Dict 收縮
- 擴容大小為第一個大于等于 used + 1 的 2n
- 收縮大小為第一個大于等于 used 的 2n
- Dict 采用漸進式 rehash,每次訪問 Dict 時執行一次 rehash
- rehash 時 ht [0] 只減不增,新增操作只在 ht [1] 執行,其它操作在兩個哈希表
4. ZipList
ZipList 是一種特殊的 “雙端鏈表” ,由一系列特殊編碼的連續記憶體塊組成,可以在任意一端進行壓入 / 彈出操作,并且該操作的時間復雜度為 O (1),
4.1 ZipList 是什么?
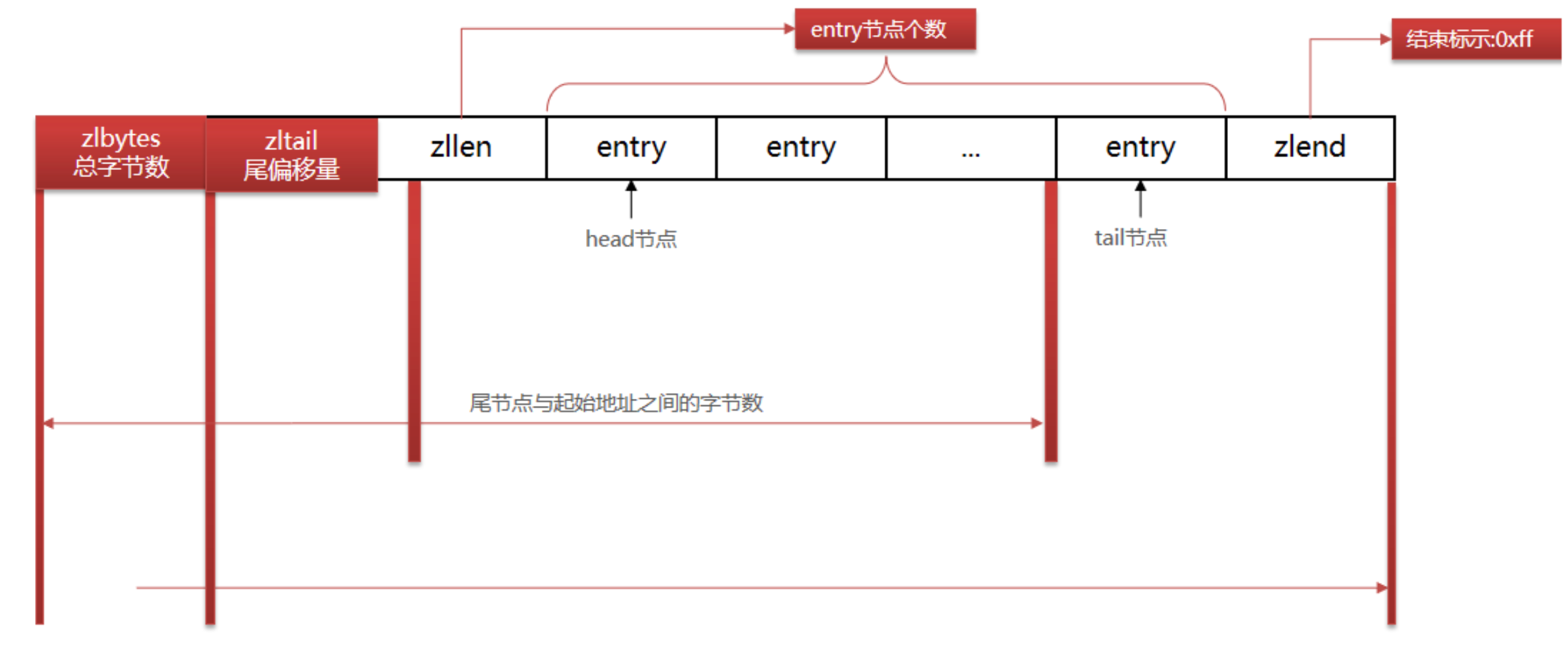

zlbytes : 欄位的型別是 uint32_t , 這個欄位中存盤的是整個 ziplist 所占用的記憶體的位元組數
zltail : 欄位的型別是 uint32_t , 它指的是 ziplist 中最后一個 entry 的偏移量,用于快速定位最后一個 entry, 以快速完成 pop 等操作
zllen : 欄位的型別是 uint16_t , 它指的是整個 ziplit 中 entry 的數量,這個值只占 2bytes(16 位): 如果 ziplist 中 entry 的數目小于 65535 (2 的 16 次方), 那么該欄位中存盤的就是實際 entry 的值,若等于或超過 65535, 那么該欄位的值固定為 65535, 但實際數量需要一個個 entry 的去遍歷所有 entry 才能得到,
zlend 是一個終止位元組,其值為全 F, 即 0xff. ziplist 保證任何情況下,一個 entry 的首位元組都不會是 255
4.2 ZipListEntry
ZipList 中的 Entry 并不像普通鏈表那樣記錄前后節點的指標,因為記錄兩個指標要占用 16 個位元組,浪費記憶體,而是采用了下面的結構:

- previous_entry_length:前一節點的長度,占 1 個或 5 個位元組,
- 如果前一節點的長度小于 254 位元組,則采用 1 個位元組來保存這個長度值
- 如果前一節點的長度大于 254 位元組,則采用 5 個位元組來保存這個長度值,第一個位元組為 0xfe,后四個位元組才是真實長度資料
- encoding:編碼屬性,記錄 content 的資料型別(字串還是整數)以及長度,占用 1 個、2 個或 5 個位元組
- contents:負責保存節點的資料,可以是字串或整數
第一種情況:一般結構
? prevlen:前一個 entry 的大小,編碼方式見下文;
? encoding:不同的情況下值不同,用于表示當前 entry 的型別和長度;
? entry-data:真是用于存盤 entry 表示的資料;
第二種情況:在 entry 中存盤的是 int 型別時,encoding 和 entry-data 會合并在 encoding 中表示,此時沒有 entry-data 欄位;
redis 中,在存盤資料時,會先嘗試將 string 轉換成 int 存盤,節省空間;此時 entry 結構:
- prevlen編碼
當前一個元素長度小于 254(255 用于 zlend)的時候,prevlen 長度為 1 個位元組,值即為前一個 entry 的長度,如果長度大于等于 254 的時候,prevlen 用 5 個位元組表示,第一位元組設定為 254,后面 4 個位元組存盤一個小端的無符號整型,表示前一個 entry 的長度;
<prevlen from 0 to 253> <encoding> <entry> //長度小于254結構
0xFE <4 bytes unsigned little endian prevlen> <encoding> <entry> //長度大于等于254
- encoding 編碼
encoding 的長度和值根據保存的是 int 還是 string,還有資料的長度而定;
前兩位用來表示型別,當為 “11” 時,表示 entry 存盤的是 int 型別,其它表示存盤的是 string;
存盤string時:
|00xxxxxx| :此時 encoding 長度為 1 個位元組,該位元組的后六位表示 entry 中存盤的 string 長度,因為是 6 位,所以 entry 中存盤的 string 長度不能超過 63;
|01xxxxxx|xxxxxxxx| 此時 encoding 長度為兩個位元組;此時 encoding 的后 14 位用來存盤 string 長度,長度不能超過 16383;
|10000000|xxxxxxxx|xxxxxxxx|xxxxxxxx|xxxxxxxx| 此時 encoding 長度為 5 個位元組,后面的 4 個位元組用來表示 encoding 中存盤的字串長度,長度不能超過 2^32 - 1;
存盤int時:
|11000000| encoding 為 3 個位元組,后 2 個位元組表示一個 int16;
|11010000| encoding 為 5 個位元組,后 4 個位元組表示一個 int32;
|11100000| encoding 為 9 個位元組,后 8 位元組表示一個 int64;
|11110000| encoding 為 4 個位元組,后 3 個位元組表示一個有符號整型;
|11111110| encoding 為 2 位元組,后 1 個位元組表示一個有符號整型;
|1111xxxx| encoding 長度就只有 1 個位元組,xxxx 表示一個 0 - 12 的整數值;
|11111111| zlend
4.3 ZipList 的連鎖更新問題
- ZipList 的每個 Entry 都包含 previous_entry_length 來記錄上一個節點的大小,長度是 1 個或 5 個位元組:
- 如果前一節點的長度小于 254 位元組,則采用 1 個位元組來保存這個長度值
- 如果前一節點的長度大于等于 254 位元組,則采用 5 個位元組來保存這個長度值,第一個位元組為 0xfe,后四個位元組才是真實長度資料
- 現在,假設我們有 N 個連續的、長度為 250~253 位元組之間的 entry,因此 entry 的 previous_entry_length 屬性用 1 個位元組即可表示,如圖所示:

ZipList 這種特殊情況下產生的連續多次空間擴展操作稱之為連鎖更新(Cascade Update),新增、洗掉都可能導致連鎖更新的發生,雖然發生的條件非常苛刻,但不代表不會發生
4.4 總結:
ZipList 特性:
- 壓縮串列的可以看做一種連續記憶體空間的” 雙向鏈表”
- 串列的節點之間不是通過指標連接,而是記錄上一節點和本節點長度來尋址,記憶體占用較低
- 如果串列資料過多,導致鏈表過長,可能影響查詢性能
- 增或刪較大資料時有可能發生連續更新問題
5. QuickList
5.1 QuickList 是什么?
ZipList 雖然節省記憶體,但申請記憶體必須是連續空間,但是我們要存盤大量資料,記憶體中碎片比較多,很難找到一塊大的連續空間,于是 ,大資料量下,記憶體申請效率低成了 ziplist 的最大問題,而 quickList 就是為了幫助 zipList 擺脫困境的,
- 為了緩解記憶體申請效率低的問題,QuickList 提供了可限制 ZipList 的最大節點數 和 每個 entry 的大小的方式,
- 那么對于大資料量 ,我們可以采用分片的思想,存盤在多個 ZipList 中 ,而 QuickList 可以將這些 ZipList 作為節點連接起來,
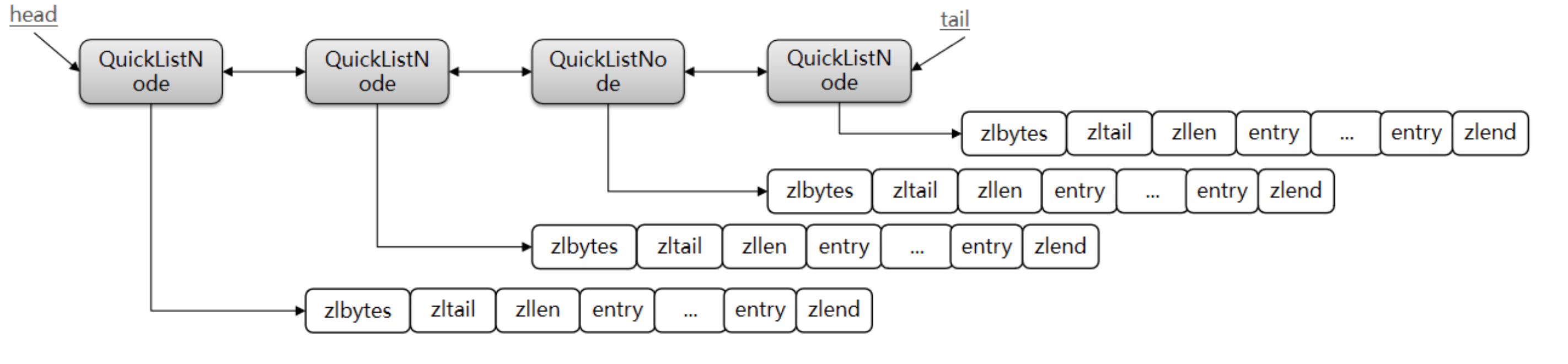
為了避免 QuickList 中的每個 ZipList 中 entry 過多,Redis 提供了一個配置項:list-max-ziplist-size 來限制,
- 如果值為正,則代表 ZipList 的允許的 entry 個數的最大值
- 如果值為負,則代表 ZipList 的最大記憶體大小,分 5 種情況:
- -1:每個 ZipList 的記憶體占用不能超過 4kb
- -2:每個 ZipList 的記憶體占用不能超過 8kb
- -3:每個 ZipList 的記憶體占用不能超過 16kb
- -4:每個 ZipList 的記憶體占用不能超過 32kb
- -5:每個 ZipList 的記憶體占用不能超過 64kb
其默認值為 -2:

以下是 QuickList 的和 QuickListNode 的結構原始碼:
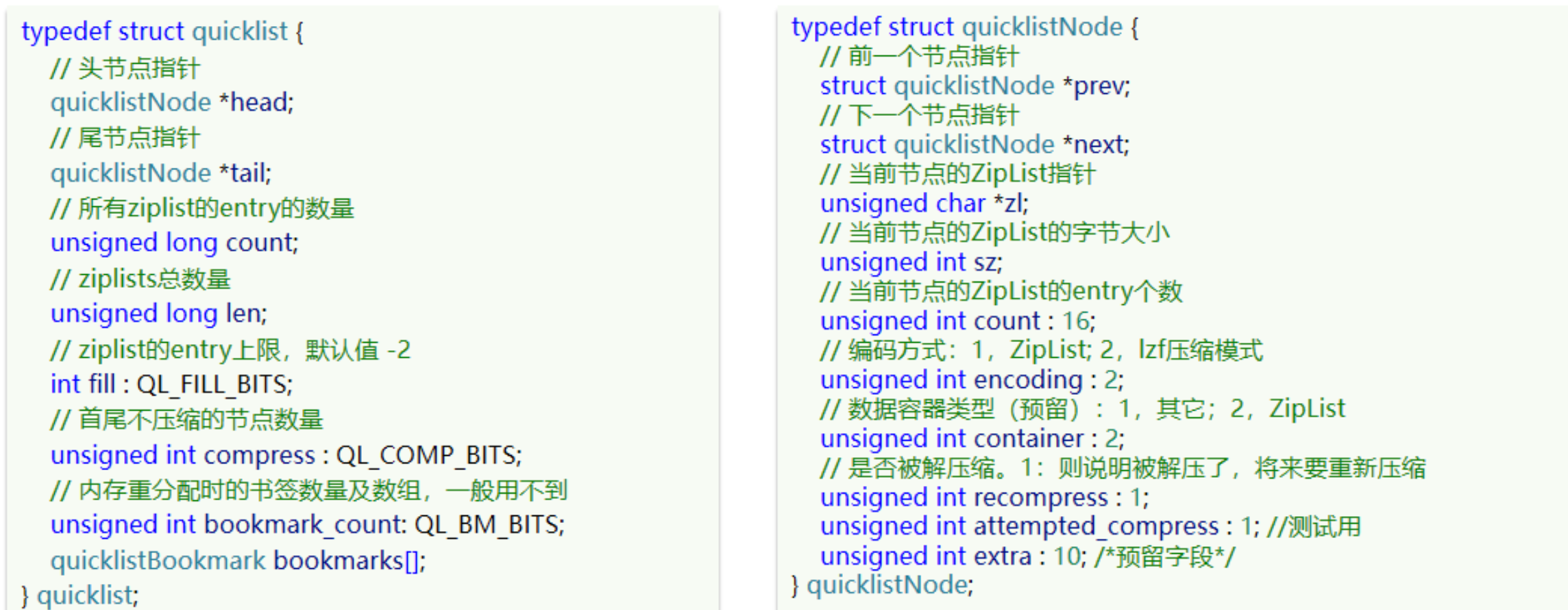
5.2 QuickList 記憶體布局
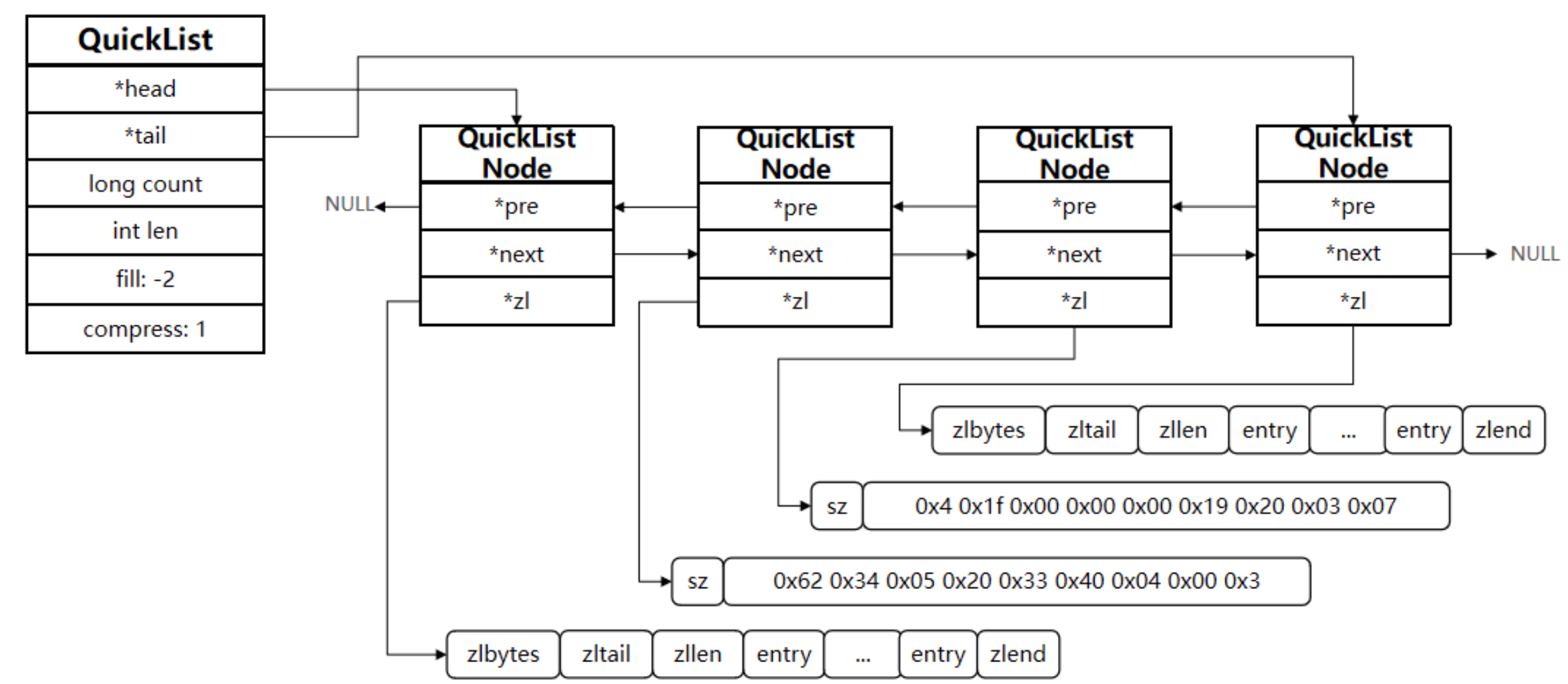
5.3 總結:
QuickList 的特點:
- 是一個節點為 ZipList 的雙端鏈表
- 節點采用 ZipList ,解決了傳統鏈表的記憶體占用問題
- 控制了 ZipList 大小,解決連續記憶體空間申請效率問題
- 中間節點可以壓縮,進一步節省了記憶體
6. SkipList
跳躍表結構在 Redis 中的運用場景只有一個,那就是作為有序串列 (Zset) 的使用,跳躍表的性能可以保證在查找,洗掉,添加等操作的時候在對數期望時間內完成,這個性能是可以和平衡樹來相比較的,而且在實作方面比平衡樹要優雅,這就是跳躍表的長處,跳躍表的缺點就是需要的存盤空間比較大,屬于利用空間來換取時間的資料結構
6.1 SkipList 是什么?
SkipList(跳表)首先是鏈表,但與傳統鏈表相比有幾點差異:
- 元素按照升序排列存盤
- 節點可能包含多個指標,指標跨度不同,
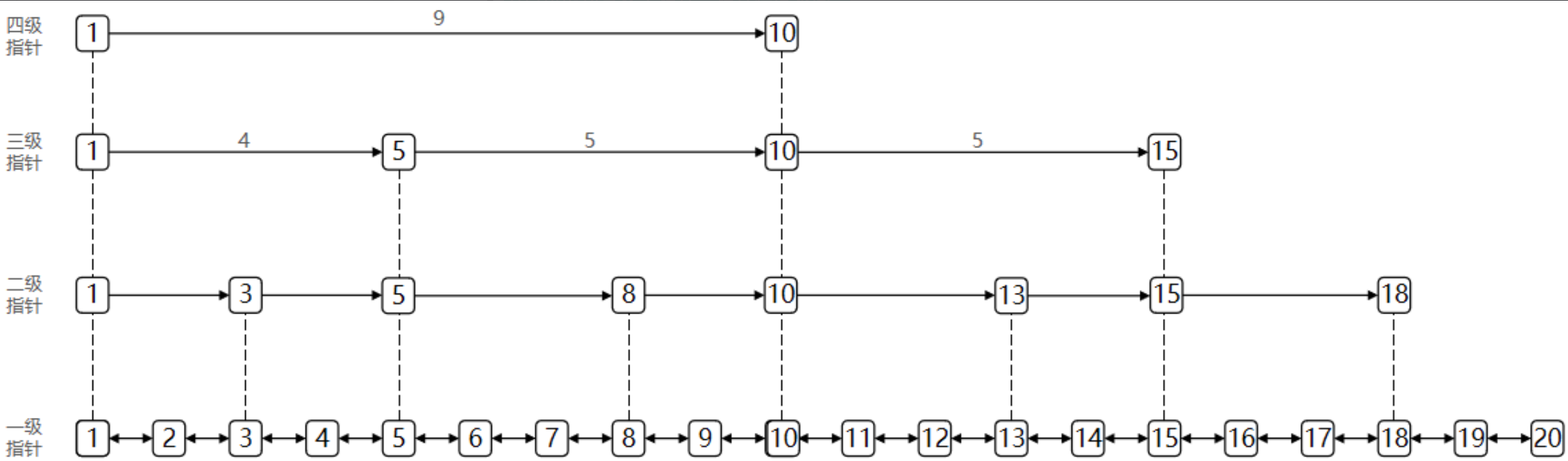
6.2 SkipListNode 結構
- ele 欄位,持有資料,是 sds 型別
- score 欄位,其標示著結點的得分,結點之間憑借得分來判斷先后順序,跳躍表中的結點按結點的得分升序排列.
- backward 指標,這是原版跳躍表中所沒有的,該指標指向結點的前一個緊鄰結點.
- level 欄位,用以記錄所有結點 (除過頭節點外);每個結點中最多持有 32 個 zskiplistLevel 結構,實際數量在結點創建時,按冪次定律隨機生成 (不超過 32). 每個 zskiplistLevel 中有兩個欄位
- forward 欄位指向比自己得分高的某個結點 (不一定是緊鄰的), 并且,若當前 zskiplistLevel 實體在 level [] 中的索引為 X, 則其 forward 欄位指向的結點,其 level [] 欄位的容量至少是 X+1. 這也是上圖中,為什么 forward 指標總是畫的水平的原因.
- span 欄位代表 forward 欄位指向的結點,距離當前結點的距離,緊鄰的兩個結點之間的距離定義為 1.
6.3 skiplist 與平衡樹、哈希表的比較
skiplist 和各種平衡樹(如 AVL、紅黑樹等)的元素是有序排列的,而哈希表不是有序的,因此,在哈希表上只能做單個 key 的查找,不適宜做范圍查找,所謂范圍查找,指的是查找那些大小在指定的兩個值之間的所有節點,
在做范圍查找的時候,平衡樹比 skiplist 操作要復雜,在平衡樹上,我們找到指定范圍的小值之后,還需要以中序遍歷的順序繼續尋找其它不超過大值的節點,如果不對平衡樹進行一定的改造,這里的中序遍歷并不容易實作,而在 skiplist 上進行范圍查找就非常簡單,只需要在找到小值之后,對第 1 層鏈表進行若干步的遍歷就可以實作,
平衡樹的插入和洗掉操作可能引發子樹的調整,邏輯復雜,而 skiplist 的插入和洗掉只需要修改相鄰節點的指標,操作簡單又快速,
從記憶體占用上來說,skiplist 比平衡樹更靈活一些,一般來說,平衡樹每個節點包含 2 個指標(分別指向左右子樹),而 skiplist 每個節點包含的指標數目平均為 1/(1-p),具體取決于引數 p 的大小,如果像 Redis 里的實作一樣,取 p=1/4,那么平均每個節點包含 1.33 個指標,比平衡樹更有優勢,
查找單個 key,skiplist 和 平衡樹 的時間復雜度都為 O (log n),大體相當;而哈希表在保持較低的哈希值沖突概率的前提下,查找時間復雜度接近 O (1),性能更高一些,所以我們平常使用的各 Map 或 dictionary 結構,大都是基于哈希表實作的,
從演算法實作難度上來比較,skiplist 比平衡樹要簡單得多,
6.4 總結:
SkipList 的特點:
- 跳躍表是一個雙向鏈表,每個節點都包含 score 和 ele 值
- 節點按照 score 值排序,score 值一樣則按照 ele 字典排序
- 每個節點都可以包含多層指標,層數是 1 到 32 之間的亂數
- 不同層指標到下一個節點的跨度不同,層級越高,跨度越大
- 增刪改查效率與紅黑樹基本一致,實作卻更簡單
7. RedisObject
7.1 RedisObject 是什么?
Redis 中的任意資料型別的鍵和值都會被封裝為一個 RedisObject,也叫做 Redis 物件
從 Redis 的使用者的角度來看,?個 Redis 節點包含多個 database(非 cluster 模式下默認是 16 個,cluster 模式下只能是 1 個),而一個 database 維護了從 key space 到 object space 的映射關系,這個映射關系的 key 是 string 型別,? value 可以是多種資料型別,比如:string, list, hash、set、sorted set 等,我們可以看到,key 的型別固定是 string ,而 value 可能的型別是多個,
?從 Redis 內部實作的?度來看,database 內的這個映射關系是用?個 dict 來維護的,dict 的 key 固定用?種資料結構來表達就夠了,這就是動態字串 sds,而 value 則比較復雜,為了在同?個 dict 內能夠存盤不同型別的 value,這就需要?個通?的資料結構,這個通用的資料結構就是 robj,全名是 redisObject,
!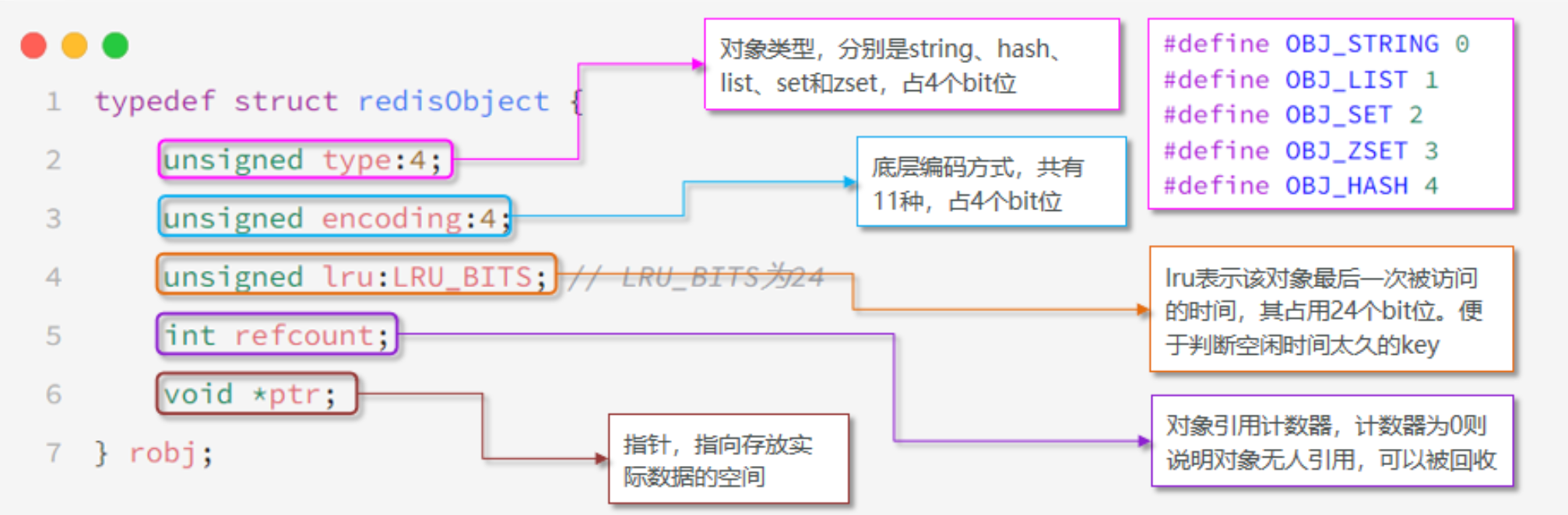
- type : 占 4bit , 五個取值型別,表示物件型別 String , Hash , List , set , zset,
- encoding : 占 4bit ,十一種編碼方式
- lru : 占用 3 位元組,記錄最后一次被訪問的時間,主要用于 lru 演算法,最近最少使用
- refcount :占用 4 位元組,參考計數器,無人用就回收
- *ptr:占用 8 位元組 ,只想存放實際資料的空間
redis 的頭部占用 16 位元組
7.2 encoding 取值:
Redis 中會根據存盤的資料型別不同,選擇不同的編碼方式,共包含 11 種不同型別:
| 編號 | 編碼方式 | 說明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw 編碼動態字串 |
| 1 | OBJ_ENCODING_INT | long 型別的整數的字串 |
| 2 | OBJ_ENCODING_HT | hash 表(字典 dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已廢棄 |
| 4 | OBJ_ENCODING_LINKEDLIST | 雙端鏈表 |
| 5 | OBJ_ENCODING_ZIPLIST | 壓縮串列 |
| 6 | OBJ_ENCODING_INTSET | 整數集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr 的動態字串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速串列 |
| 10 | OBJ_ENCODING_STREAM | Stream 流 |
7.3 五種資料結構
Redis 中會根據存盤的資料型別不同,選擇不同的編碼方式,每種資料型別的使用的編碼方式如下:
| 資料型別 | 編碼方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList 和 ZipList (3.2 以前)、QuickList(3.2 以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/539314.html
標籤:其他
上一篇:時針分針與秒針