"Writing in C or C++ is like running a chain saw with all the safety guards removed. " - Bob Gray
“用C或C++寫代碼就像是在揮舞一把卸掉所有安全防護裝置的鏈鋸,” —— 鮑勃·格雷
0x00 大綱
目錄- 0x00 大綱
- 0x01 前言
- 0x02 鏈表
- 定義
- 鏈表的分類
- 單鏈表
- 雙鏈表
- 回圈鏈表
- 普通鏈表的局限
- 0x03 通用鏈表
- 結構與資料解耦
- 更直觀的對比
- 記憶體地址偏移
- offsetof
- container_of
- 小結
0x01 前言
學生管理系統、學生成績管理系統、教師管理系統、圖書管理系統、通訊錄管理系統、進銷存管理系統……這一個個耳熟能詳的名字,正是無數C語言練習生除了唱、跳、RAP和籃球之外,必須邁過去的一道坎,無論是作為課程設計,還是期末作業,都坑倒了一大批新手,照著書上的例程修修改改就是跑不通,網上查到的代碼比自己寫的還不靠譜……畢竟老夫也是渡過此劫的魔鬼,
其中很大一部分原因就是因為XXX管理系統的核心資料結構——鏈表,沒有int、long和char這些基礎資料型別長得那么可愛單純,讓人學起來一臉辛酸,
簡單的鏈表大家都會,這邊文章要講的其實是Linux的內核鏈表,拿個舊瓶裝點新酒,
0x02 鏈表
定義
鏈表是線性表的一種,它通過指標將一系列資料節點連接成一條資料鏈,相對于靜態陣列,鏈表具有更好的動態性,建立鏈表時無需預先知道資料總量,可以隨機分配空間,可以高效地在鏈表中插入資料,
鏈表的分類
單鏈表
單鏈表是最簡單的一類鏈表,它的特點是僅有一個指標域指向后繼節點,因此,對單鏈表的遍歷只能從頭至尾順序進行,尾節點指標域通常指向NULL空指標,

雙鏈表
雙鏈表在單鏈表的基礎上增加了一個指向前驅節點的指標域,可以實作雙向遍歷,

回圈鏈表
回圈鏈表的尾節點指標域指向首節點,它的特點是從任意節點出發,都可以訪問到整個鏈表,如果在雙鏈表的基礎上實作回圈鏈表,則可以實作從任意節點雙向訪問整個鏈表,

普通鏈表的局限
鏈表的節點通常由資料域和指標域構成,以喜聞樂見的學生管理系統為例:
struct student
{
char id[48];
char name[64];
char clazz[24];
}
struct list_node
{
struct student data; // 資料域
struct list_node *next;// 指標域
}
void list_init(struct list_node *list);
void list_add(struct list_node *list, struct student *stu);
void list_del(struct list_node *list, struct student *stu);
......
可以看到,這樣的鏈表對于維護單一資料來說,比如上面的struct student,沒有任何問題,但如果在另一個程式背景關系中,我們的資料域不是struct student,而是struct teacher或者struct any_thing,顯然,我們必須為這些不同的資料型別重新定義一套鏈表的操作介面,我們的代碼沒辦法完全復用(Ctrl+C,Ctrl+V),簡而言之,我們需要一個通用的鏈表,
0x03 通用鏈表
結構與資料解耦
要實作一個通用的鏈表,我們首先要將資料和結構解耦,這也是實作任意一種抽象資料型別的基礎,很遺憾,C語言既沒有C++的模板,也沒有C#和Java的泛型,但是我們可以考慮這樣的結構:
struct list_node
{
void *data; // 資料域
struct list_node *next;// 指標域
}
void list_init(struct list_node *list);
void list_add(struct list_node *list, void *data);
void list_del(struct list_node *list, void *data);
......
無型別的指標,可以實作某種程度上的抽象資料型別,但是這意味著我們代碼會到處充斥強制轉換和回呼函式,必須時刻注意自行檢查資料型別,一個不小心就會發生記憶體錯誤,
顯然,這不是我們想要的,我們向Linux內核的鏈表實作取下經,既然是一個與資料解耦的鏈表,那這個鏈表的節點不應該包含資料域本身,像這樣:
struct list_node
{
struct list_node *next, *prev;// 僅有指標域
}
節點里面僅包含了指向前驅節點和后繼節點的指標,那么我們的資料存放在哪里呢?
還是以學生管理系統為例,我們把代碼調整一下,將鏈表的節點放在資料結構體內,這樣,抽象(鏈表結構)不再依賴于細節(資料型別),細節(資料型別)依賴于抽象(鏈表結構),利用依賴倒置的思想,完成了資料與結構的解耦,如下:
struct list_node
{
struct list_node *next, *prev;
}
struct student {
char id[48];
char name[64];
char clazz[24];
struct list_node list;// 鏈表節點反置于資料結構體內
}
void list_init(struct list_node *list);
void list_add(struct list_node *new_node, struct list_node *head);
void list_del(struct list_node *node);
......
可以發現,對比之前的代碼,進行調整之后,我們的鏈表操作函式中不再關心資料結構體struct student的具體細節,所有的操作都基于struct list_node鏈表節點,也就是說,我們可以輕松的將struct student替換成struct teacher,而不用修改鏈表操作的任何代碼,
更直觀的對比
用一張普通鏈表和通用鏈表的節點對比圖可以更直觀的看出兩者在結構上的差異,對于普通鏈表來說,節點本身包含了資料,對節點的操作是對資料域和指標域整體的操作;對于通用鏈表來說,則是資料本身包含了節點,對節點的操作只與區域的指標域有關,與資料域無關,
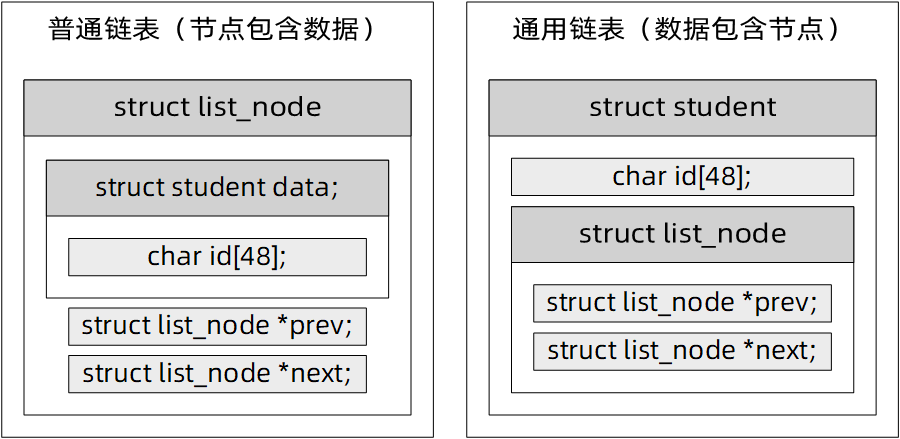
記憶體地址偏移
經過上面的調整,我們確立了通用鏈表的實作方向,但是隨之而來的是新的問題:如何通過鏈表節點list_node取得對應的資料成員struct student?我們的標題提出了解決方法,答案就是利用地址偏移,
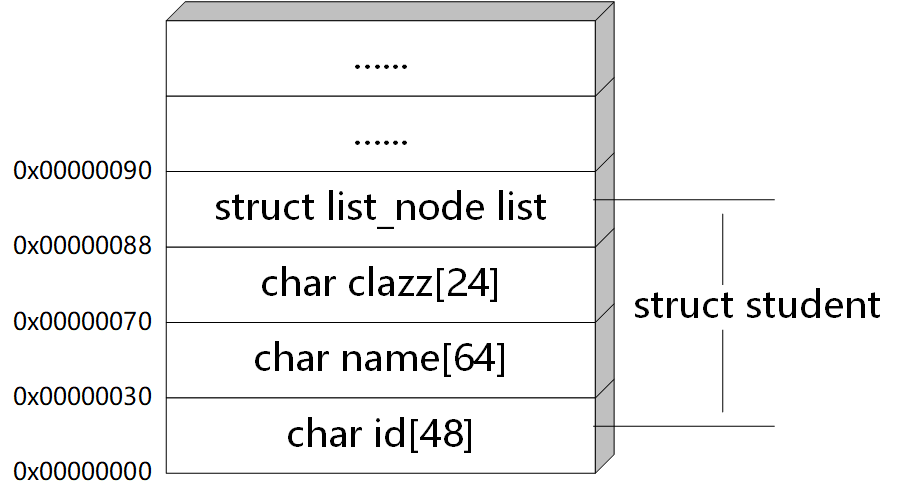
如圖,我們知道結構體的指標指向的是該結構體在記憶體中的起始地址,不妨假設結構體型別(type)為struct student的資料存盤在記憶體的 0x00000000 到 0x00000090 單元, 0x00000088 到 0x00000090 單元存盤的是型別為struct list_node的結構體成員(member)list,注意編址從下往上逐漸增大,如果已知成員的起始地址,那么該成員相對于結構體的偏移量(offset)為 0x00000088 - 0x00000000 = 136,顯然,我們可以得出以下公式:
結構體起始地址 = 成員起始地址 - 成員在結構體的偏移量
offsetof
有了上面的公式,還需要知道如何獲取成員在結構體的偏移量,offsetof 是定義在C標準庫頭檔案<stddef.h>中的一個宏,它會生成一個型別為size_t的無符號整型,代表一個結構成員相對于結構體起始的位元組偏移量(offset),一種可能的寫法為:
#define offsetof(type, member) ((size_t) &((type *)0)->member)
其中member表示的是結構體成員的名稱,type表示的是結構體的型別,這里我們以struct student為例,如果要得到成員list相對于結構體struct student的偏移量:
// 注意list必須與在結構體中定義的變數名稱一致
int offset = offsetof(struct student, list);
// 將宏展開得到
int offset = ((size_t) &((struct student *)0)->list);
把運算式分解一下,可以得到:
(1)(struct student *)0,將0強制轉換為struct student結構體指標型別,可以理解為將該結構體指標偏移到0地址
(2)((struct student *)0)->list),通過指標訪問結構體成員list
(3)&((struct student *)0)->list),對結構體成員member進行取地址運算,獲得結構體成員的地址
(4)(size_t) &((struct student *)0)->list,將結構體地址強制轉換為無符號整型表示的數值
由于我們將結構體起始地址偏移到了0地址,所以成員list的地址數值上就等于list相對于結構體起始地址的偏移量,這是一個常量,它在編譯期間就可以被替換為具體的數值,而不用在運行時動態計算,因此,在某些編譯器中,它會被定義為編譯器內建實作,比如GCC編譯器<stddef.h>中offsetof宏的定義如下:
#define offsetof(TYPE, MEMBER) __builtin_offsetof (TYPE, MEMBER)
它們得到的結果是一致的,這不會影響我們對原理的理解,
container_of
我們將求取成員偏移量的offsetof宏代入上面的公式,得到另一個宏cotainer_of:
#define container_of(ptr, type, member) \
((type *)((char *)(ptr) - offsetof(type,member)))
cotainer_of回傳的是結構體成員所在結構體的起始地址(指標),其中ptr為指向結構體成員的指標(相當于成員的起始地址),type表示的是結構體的型別,member表示的是結構體成員的名稱,老規矩,繼續以struct student為例,便于理解:
......
struct student *ptr_of_stu;
// 通過成員list的指標ptr_of_list_node獲取結構體指標ptr_of_stu
ptr_of_stu = container_of(ptr_of_list_node, struct student, list);
// 將宏展開后得到(offsetof前面已經分析過,這里就不贅述了)
ptr_of_stu = ((struct student *)((char *)(ptr_of_list_node) - offsetof(struct student,list)));
......
ptr_of_stu->id = "996";
......
把運算式分解一下,可以得到:
(1)offsetof(struct student,list),獲得成員list在結構體struct student中的偏移量
(2)(char *)(ptr_of_list_node),將節點指標強制轉換為字符型指標,保證計算結果正確,當指標變數進行運算時,會前進或后移相應型別資料的寬度,之所以進行轉換是要確保我們的偏移量都是按位元組計算的偏移量
(3)(char *)(ptr_of_list_node) - offsetof(struct student,list)),用成員變數指標(起始地址)減去成員的結構體偏移量,得到結構體的指標(起始地址),也即是公式的體現
(4)(struct student *)((char *)(ptr_of_list_node) - offsetof(struct student,list)),將計算得到的指標強制轉換為struct student型別指標
到這里,我們就解決了如何通過鏈表節點list_node取得對應的資料成員struct student的問題,接下來只需要將鏈表的常用操作封裝起來,就能夠得到一個與具體資料型別無關的通用鏈表,
小結
我們似憾訓了很大的功夫去調整鏈表的節點,不禁要問,why? 像教科書例程一樣簡單粗暴地定義結構體型別和指標不好嗎?好,但是也不好,好的地方是,代碼直觀,容易理解和操作,不好的地方呢?假設我們要寫一個“教務管理系統”,它需要同時維護兩種資訊:學生資訊和教師資訊,我們用鏈表存盤他們的所有資料,那么以插入資料為例:
struct student
{
char id[48];
}
struct teacher
{
char id[48];
}
struct student_node
{
struct student *data;// 普通鏈表,資料放在節點內
struct student_node *prev;
struct student_node *next;
}
struct teacher_node
{
struct teacher *data;// 普通鏈表,資料放在節點內
struct teacher_node *prev;
struct teacher_node *next;
}
// 普通鏈表插入一個節點
void list_add_student(struct student_node *head, struct student *data)
{
struct student_node *entry = (struct student_node *)malloc(sizeof(struct student_node));
entry->data = https://www.cnblogs.com/mylibs/archive/2022/12/07/data;
head->next->prev = entry;
entry->next = head->next;
entry->prev = head;
head->next = entry;
}
// 普通鏈表插入一個節點
void list_add_teacher(struct teacher_node *head, struct teacher *data)
{
// 為節點申請記憶體
struct teacher_node *entry = (struct teacher_node *)malloc(sizeof(struct teacher_node));
entry->data = data;
head->next->prev = entry;
entry->next = head->next;
entry->prev = head;
head->next = entry;
}
// 插入操作
struct student_node *student_head; // 假設鏈表已經初始化
struct teacher_node *teacher_head; // 假設鏈表已經初始化
struct student new_student; // 省略結構體成員賦值
struct teacher new_teacher; // 省略結構體成員賦值
list_add_student(student_head, &new_student);
list_add_teacher(teacher_head, &new_teacher);
看到了嗎,每增加一種資料型別,就必須多定義一套操作函式,代碼成倍增加不說,還必須注意型別不能混用,否則分分鐘一個大大的記憶體錯誤扔給你,我們看看通用鏈表可以怎么做:
struct list_node
{
struct list_node *next, *prev;
}
struct student
{
char id[48];
struct list_node; // 通用鏈表,節點放置在資料結構體內
}
struct teacher
{
char id[48];
struct list_node; // 通用鏈表,節點放置在資料結構體內
}
// 通用鏈表插入一個節點
void list_add(struct list_node *new_node, struct list_node *head)
{
// 由于節點隨著資料結構體一起被分配,這里不需要再動態申請記憶體
head->next->prev = entry;
entry->next = head->next;
entry->prev = head;
head->next = entry;
}
// 插入操作
struct list_node *student_head; // 假設鏈表已經初始化
struct list_node *teacher_head; // 假設鏈表已經初始化
struct student new_student; // 省略結構體成員賦值
struct student new_teacher; // 省略結構體成員賦值
list_add(student_head, &new_student.list_node);
list_add(teacher_head, &new_teacher.list_node);
注意,上述的代碼只是為了對比和說明普通鏈表與通用鏈表的泛用性,省略了很多初始化和檢查代碼,不能直接使用,從代碼可以知道,通用鏈表的list_add函式只需要被定義一次,就可以被用于任意資料型別,只需要在資料結構體內包含list_node結構體,該結構體型別便可以作為鏈表節點進行管理,
對于通用鏈表的各種基本操作和代碼示例,將在下一篇文章中進行展開和說明,期待與你下次再見,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/539410.html
標籤:其他