摘要:本篇文章將分享影像分類原理,并介紹基于KNN、樸素貝葉斯演算法的影像分類案例,
本文分享自華為云社區《[Python影像處理] 二十六.影像分類原理及基于KNN、樸素貝葉斯演算法的影像分類案例丨【百變AI秀】》,作者:eastmount ,
一.影像分類
影像分類(Image Classification)是對影像內容進行分類的問題,它利用計算機對影像進行定量分析,把影像或影像中的區域劃分為若干個類別,以代替人的視覺判斷,影像分類的傳統方法是特征描述及檢測,這類傳統方法可能對于一些簡單的影像分類是有效的,但由于實際情況非常復雜,傳統的分類方法不堪重負,現在,廣泛使用機器學習和深度學習的方法來處理影像分類問題,其主要任務是給定一堆輸入圖片,將其指派到一個已知的混合類別中的某個標簽,
在下圖中,影像分類模型將獲取單個影像,并將為4個標簽{cat,dog,hat,mug},分別對應概率{0.6, 0.3, 0.05, 0.05},其中0.6表示影像標簽為貓的概率,其余類比,該影像被表示為一個三維陣列,在這個例子中,貓的影像寬度為248像素,高度為400像素,并具有紅綠藍三個顏色通道(通常稱為RGB),因此,影像由248×400×3個數字組成或總共297600個數字,每個數字是一個從0(黑色)到255(白色)的整數,影像分類的任務是將這接近30萬個數字變成一個單一的標簽,如“貓(cat)”,
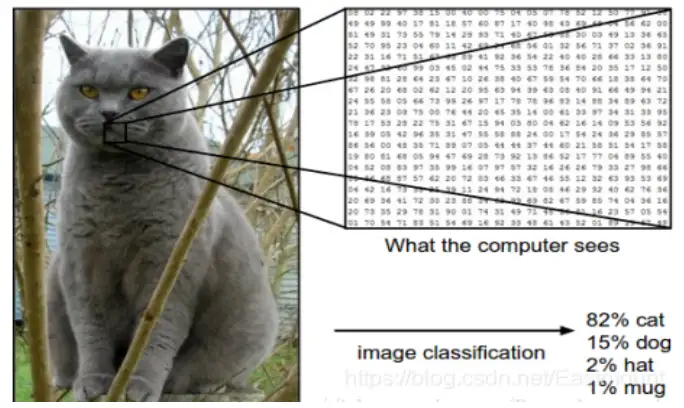
那么,如何撰寫一個影像分類的演算法呢?又怎么從眾多影像中識別出貓呢?這里所采取的方法和教育小孩看圖識物類似,給出很多影像資料,讓模型不斷去學習每個類的特征,在訓練之前,首先需要對訓練集的影像進行分類標注,如圖所示,包括cat、dog、mug和hat四類,在實際工程中,可能有成千上萬類別的物體,每個類別都會有上百萬張影像,

影像分類是輸入一堆影像的像素值陣列,然后給它分配一個分類標簽,通過訓練學習來建立演算法模型,接著使用該模型進行影像分類預測,具體流程如下:
- 輸入: 輸入包含N個影像的集合,每個影像的標簽是K種分類標簽中的一種,這個集合稱為訓練集,
- 學習: 第二步任務是使用訓練集來學習每個類的特征,構建訓練分類器或者分類模型,
- 評價: 通過分類器來預測新輸入影像的分類標簽,并以此來評價分類器的質量,通過分類器預測的標簽和影像真正的分類標簽對比,從而評價分類演算法的好壞,如果分類器預測的分類標簽和影像真正的分類標簽一致,表示預測正確,否則預測錯誤,
二.常見分類演算法
常見的分類演算法包括樸素貝葉斯分類器、決策樹、K最近鄰分類演算法、支持向量機、神經網路和基于規則的分類演算法等,同時還有用于組合單一類方法的集成學習演算法,如Bagging和Boosting等,
1.樸素貝葉斯分類演算法
樸素貝葉斯分類(Naive Bayes Classifier)發源于古典數學理論,利用Bayes定理來預測一個未知類別的樣本屬于各個類別的可能性,選擇其中可能性最大的一個類別作為該樣本的最終類別,在樸素貝葉斯分類模型中,它將為每一個類別的特征向量建立服從正態分布的函式,給定訓練資料,演算法將會估計每一個類別的向量均值和方差矩陣,然后根據這些進行預測,
樸素貝葉斯分類模型的正式定義如下:

該演算法的特點為:如果沒有很多資料,該模型會比很多復雜的模型獲得更好的性能,因為復雜的模型用了太多假設,以致產生欠擬合,
2.KNN分類演算法
K最近鄰分類(K-Nearest Neighbor Classifier)演算法是一種基于實體的分類方法,是資料挖掘分類技術中最簡單常用的方法之一,該演算法的核心思想如下:一個樣本x與樣本集中的k個最相鄰的樣本中的大多數屬于某一個類別yLabel,那么該樣本x也屬于類別yLabel,并具有這個類別樣本的特性,
簡而言之,一個樣本與資料集中的k個最相鄰樣本中的大多數的類別相同,由其思想可以看出,KNN是通過測量不同特征值之間的距離進行分類,而且在決策樣本類別時,只參考樣本周圍k個“鄰居”樣本的所屬類別,因此比較適合處理樣本集存在較多重疊的場景,主要用于預測分析、文本分類、降維等處理,
該演算法在建立訓練集時,就要確定訓練資料及其對應的類別標簽;然后把待分類的測驗資料與訓練集資料依次進行特征比較,從訓練集中挑選出最相近的k個資料,這k個資料中投票最多的分類,即為新樣本的類別,KNN分類演算法的流程描述為如下圖所示,
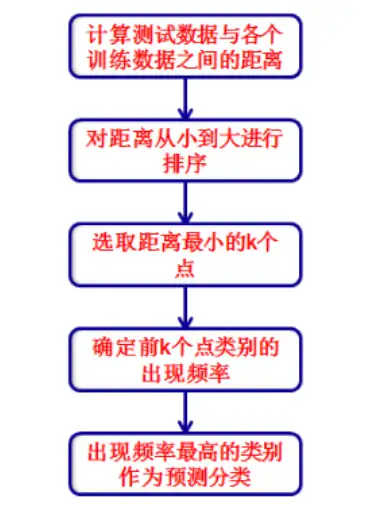
該演算法的特點為:簡單有效,但因為需要存盤所有的訓練集,占用很大記憶體,速度相對較慢,使用該方法前通常訓練集需要進行降維處理,
3.SVM分類演算法
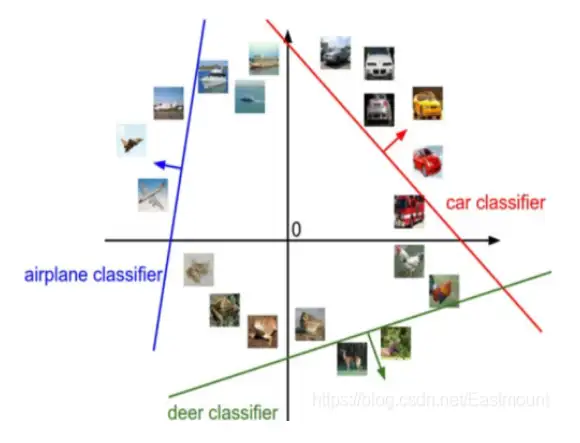
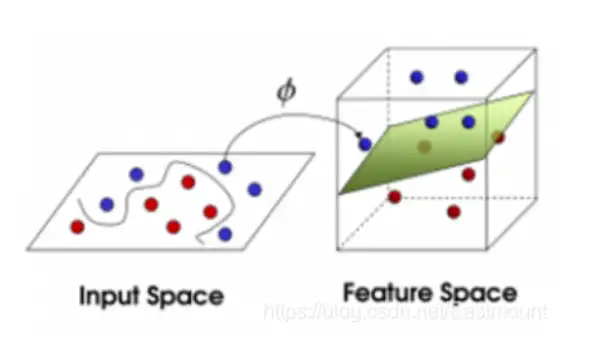
支持向量機(Support Vector Machine)是數學家Vapnik等人根據統計學習理論提出的一種新的學習方法,其基本模型定義為特征空間上間隔最大的線性分類器,其學習策略是間隔最大化,最終轉換為一個凸二次規劃問題的求解,SVM分類演算法基于核函式把特征向量映射到高維空間,建立一個線性判別函式,解最優在某種意義上是兩類中距離分割面最近的特征向量和分割面的距離最大化,離分割面最近的特征向量被稱為“支持向量”,即其它向量不影響分割面,影像分類中的SVM如下圖所示,將影像劃分為不同類別,
下面的例子可以讓讀者對SVM快速建立一個認知,給定訓練樣本,支持向量機建立一個超平面作為決策曲面,使得正例和反例的隔離邊界最大化,決策曲面的構建程序如下所示:
- 在下圖中,想象紅球和藍球為球臺上的桌球,首先需要找到一條曲線將藍球和紅球分開,于是得到一條黑色的曲線,
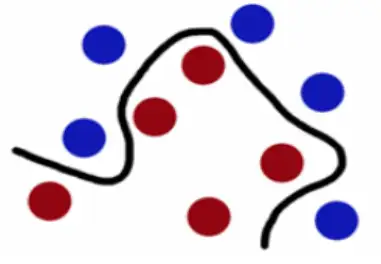
- 為了使黑色曲線離任意的藍球和紅球距離最大化,我們需要找到一條最優的曲線,如下圖所示,
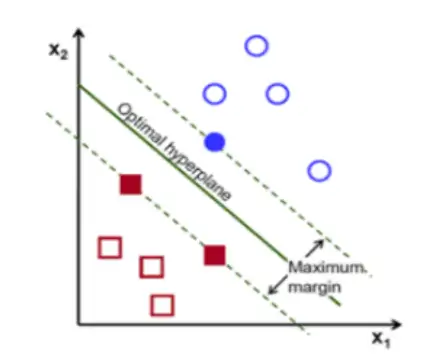
- 假設這些球不是在球桌上,而是拋在空中,但仍然需要將紅球和藍球分開,這時就需要一個曲面,而且該曲面仍然滿足所有任意紅球和藍球的間距最大化,如圖16-7所示,離這個曲面最近的紅色球和藍色球就被稱為“支持向量(Support Vector)”,
該演算法的特點為:當資料集比較小的時候,支持向量機的效果非常好,同時,SVM分類演算法較好地解決了非線性、高維數、區域極小點等問題,維數大于樣本數時仍然有效,
4.隨機森林分類演算法
隨機森林(Random Forest)是用隨機的方式建立一個森林,在森林里有很多決策樹的組成,并且每一棵決策樹之間是沒有關聯的,當有一個新樣本出現的時候,通過森林中的每一棵決策樹分別進行判斷,看看這個樣本屬于哪一類,然后用投票的方式,決定哪一類被選擇的多,并作為最終的分類結果,
隨機森林中的每一個決策樹“種植”和“生長”主要包括以下四個步驟:
- 假設訓練集中的樣本個數為N,通過有重置的重復多次抽樣獲取這N個樣本,抽樣結果將作為生成決策樹的訓練集;
- 如果有M個輸入變數,每個節點都將隨機選擇m(m<M)個特定的變數,然后運用這m個變數來確定最佳的分裂點,在決策樹的生成程序中,m值是保持不變的;
- 每棵決策樹都最大可能地進行生長而不進行剪枝;
- 通過對所有的決策樹進行加來預測新的資料(在分類時采用多數投票,在回歸時采用平均),
該演算法的特點為:在分類和回歸分析中都表現良好;對高維資料的處理能力強,可以處理成千上萬的輸入變數,也是一個非常不錯的降維方法;能夠輸出特征的重要程度,能有效地處理預設值,
5.神經網路分類演算法
神經網路(Neural Network)是對非線性可分資料的分類方法,通常包括輸入層、隱藏層和輸出層,其中,與輸入直接相連的稱為隱藏層(Hidden Layer),與輸出直接相連的稱為輸出層(Output Layer),神經網路演算法的特點是有比較多的區域最優值,可通過多次隨機設定初始值并運行梯度下降演算法獲得最優值,影像分類中使用最廣泛的是BP神經網路和CNN神經網路,
BP神經網路
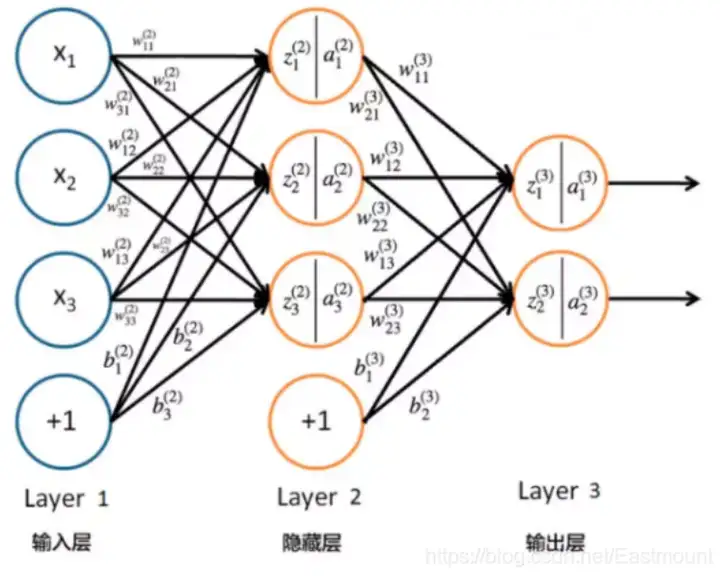
BP神經網路是一種多層的前饋神經網路,其主要的特點為:信號是前向傳播的,而誤差是反向傳播的,BP神經網路的程序主要分為兩個階段,第一階段是信號的前向傳播,從輸入層經過隱含層,最后到達輸出層;第二階段是誤差的反向傳播,從輸出層到隱含層,最后到輸入層,依次調節隱含層到輸出層的權重和偏置,輸入層到隱含層的權重和偏置,具體結構如下圖所示,
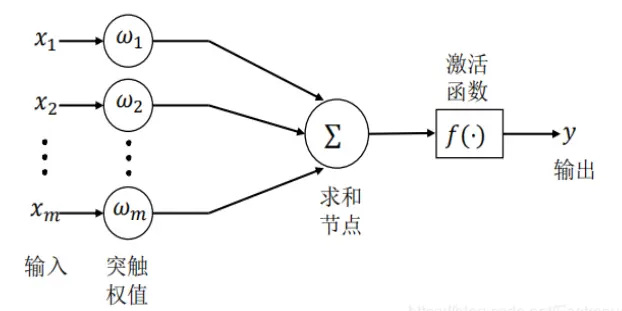
神經網路的基本組成單元是神經元,神經元的通用模型如圖所示,其中常用的激活函式有閾值函式、Sigmoid函式和雙曲正切函式等,
CNN卷積神經網路
卷積神經網路(Convolutional Neural Networks)是一類包含卷積計算且具有深度結構的前饋神經網路,是深度學習的代表演算法之一,卷積神經網路的研究始于二十世紀80至90年代,時間延遲網路和LeNet-5是最早出現的卷積神經網路,在二十一世紀后,隨著深度學習理論的提出和數值計算設備的改進,卷積神經網路得到了快速發展,并被大量應用于計算機視覺、自然語言處理等領域,
三.基于KNN演算法的影像分類
1.KNN演算法
K最近鄰分類(K-Nearest Neighbor Classifier)演算法是一種基于實體的分類方法,是資料挖掘分類技術中最簡單常用的方法之一,該演算法的核心思想是從訓練樣本中尋找所有訓練樣本X中與測驗樣本距離(歐氏距離)最近的前K個樣本(作為相似度),再選擇與待分類樣本距離最小的K個樣本作為X的K個最鄰近,并檢測這K個樣本大部分屬于哪一類樣本,則認為這個測驗樣本類別屬于這一類樣本,
假設現在需要判斷下圖中的圓形圖案屬于三角形還是正方形類別,采用KNN演算法分析如下:
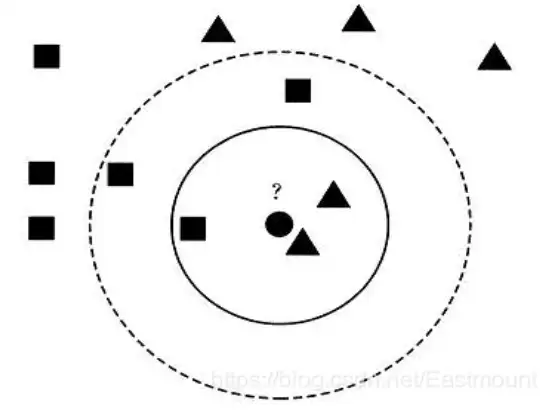
- 當K=3時,圖中第一個圈包含了三個圖形,其中三角形2個,正方形一個,該圓的則分類結果為三角形,
- 當K=5時,第二個圈中包含了5個圖形,三角形2個,正方形3個,則以3:2的投票結果預測圓為正方形類標,設定不同的K值,可能預測得到不同的結果,
簡而言之,一個樣本與資料集中的k個最相鄰樣本中的大多數的類別相同,由其思想可以看出,KNN是通過測量不同特征值之間的距離進行分類,而且在決策樣本類別時,只參考樣本周圍k個“鄰居”樣本的所屬類別,因此比較適合處理樣本集存在較多重疊的場景,主要用于預測分析、文本分類、降維等處理,
KNN在Sklearn機器學習包中,實作的類是neighbors.KNeighborsClassifier,簡稱KNN演算法,構造方法為:
KNeighborsClassifier(algorithm='ball_tree', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=3, p=2, weights='uniform')
KNeighborsClassifier可以設定3種演算法:brute、kd_tree、ball_tree,設定K值引數為n_neighbors=3,呼叫方法如下:
- from sklearn.neighbors import KNeighborsClassifier
- knn = KNeighborsClassifier(n_neighbors=3, algorithm=“ball_tree”)
它包括兩個步驟:
- 訓練:nbrs.fit(data, target)
- 預測:pre = clf.predict(data)
2.資料集
該部分主要使用Scikit-Learn包進行Python影像分類處理,Scikit-Learn擴展包是用于Python資料挖掘和資料分析的經典、實用擴展包,通常縮寫為Sklearn,Scikit-Learn中的機器學習模型是非常豐富的,包括線性回歸、決策樹、SVM、KMeans、KNN、PCA等等,用戶可以根據具體分析問題的型別選擇該擴展包的合適模型,從而進行資料分析,其安裝程序主要通過“pip install scikit-learn”實作,
實驗所采用的資料集為Sort_1000pics資料集,該資料集包含了1000張圖片,總共分為10大類,分別是人(第0類)、沙灘(第1類)、建筑(第2類)、大卡車(第3類)、恐龍(第4類)、大象(第5類)、花朵(第6類)、馬(第7類)、山峰(第8類)和食品(第9類),每類100張,如圖所示,
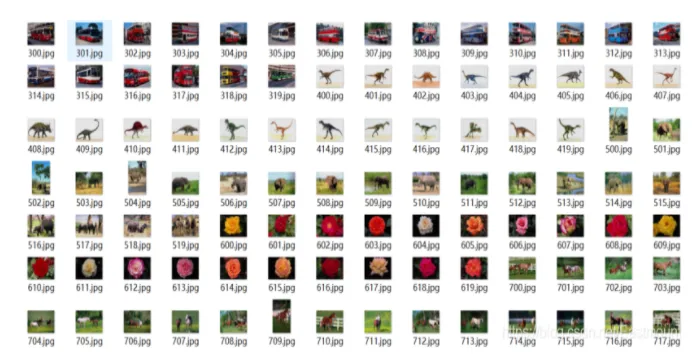
接著將所有各類影像按照對應的類標劃分至“0”至“9”命名的檔案夾中,如圖所示,每個檔案夾中均包含了100張影像,對應同一類別,

比如,檔案夾名稱為“6”中包含了100張花的影像,如下圖所示,

3.KNN影像分類
下面是呼叫KNN演算法進行影像分類的完整代碼,它將1000張影像按照訓練集為70%,測驗集為30%的比例隨機劃分,再獲取每張影像的像素直方圖,根據像素的特征分布情況進行影像分類分析,KNeighborsClassifier()核心代碼如下:
- from sklearn.neighbors import KNeighborsClassifier
- clf = KNeighborsClassifier(n_neighbors=11).fit(XX_train, y_train)
- predictions_labels = clf.predict(XX_test)
完整代碼及注釋如下:
# -*- coding: utf-8 -*- import os import cv2 import numpy as np from sklearn.cross_validation import train_test_split from sklearn.metrics import confusion_matrix, classification_report #---------------------------------------------------------------------------------- # 第一步 切分訓練集和測驗集 #---------------------------------------------------------------------------------- X = [] #定義影像名稱 Y = [] #定義影像分類類標 Z = [] #定義影像像素 for i in range(0, 10): #遍歷檔案夾,讀取圖片 for f in os.listdir("photo/%s" % i): #獲取影像名稱 X.append("photo//" +str(i) + "//" + str(f)) #獲取影像類標即為檔案夾名稱 Y.append(i) X = np.array(X) Y = np.array(Y) #隨機率為100% 選取其中的30%作為測驗集 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=1) print len(X_train), len(X_test), len(y_train), len(y_test) #---------------------------------------------------------------------------------- # 第二步 影像讀取及轉換為像素直方圖 #---------------------------------------------------------------------------------- #訓練集 XX_train = [] for i in X_train: #讀取影像 #print i image = cv2.imread(i) #影像像素大小一致 img = cv2.resize(image, (256,256), interpolation=cv2.INTER_CUBIC) #計算影像直方圖并存盤至X陣列 hist = cv2.calcHist([img], [0,1], None, [256,256], [0.0,255.0,0.0,255.0]) XX_train.append(((hist/255).flatten())) #測驗集 XX_test = [] for i in X_test: #讀取影像 #print i image = cv2.imread(i) #影像像素大小一致 img = cv2.resize(image, (256,256), interpolation=cv2.INTER_CUBIC) #計算影像直方圖并存盤至X陣列 hist = cv2.calcHist([img], [0,1], None, [256,256], [0.0,255.0,0.0,255.0]) XX_test.append(((hist/255).flatten())) #---------------------------------------------------------------------------------- # 第三步 基于KNN的影像分類處理 #---------------------------------------------------------------------------------- from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=11).fit(XX_train, y_train) predictions_labels = clf.predict(XX_test) print u'預測結果:' print predictions_labels print u'演算法評價:' print (classification_report(y_test, predictions_labels)) #輸出前10張圖片及預測結果 k = 0 while k<10: #讀取影像 print X_test[k] image = cv2.imread(X_test[k]) print predictions_labels[k] #顯示影像 cv2.imshow("img", image) cv2.waitKey(0) cv2.destroyAllWindows() k = k + 1
代碼中對預測集的前十張影像進行了顯示,其中“818.jpg”影像如圖所示,其分類預測的類標結果為“8”,表示第8類山峰,預測結果正確,

下圖展示了“452.jpg”影像,其分類預測的類標結果為“4”,表示第4類恐龍,預測結果正確,

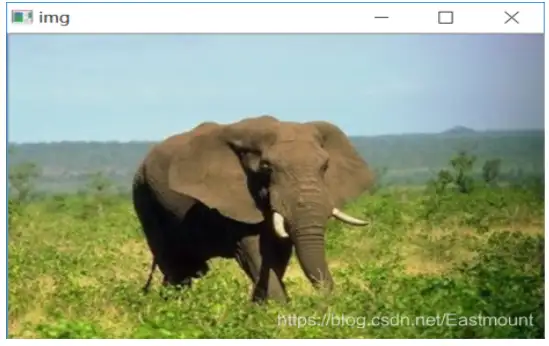
下圖展示了“507.jpg”影像,其分類預測的類標結果為“7”,錯誤地預測為第7類恐龍,其真實結果應該是第5類大象,
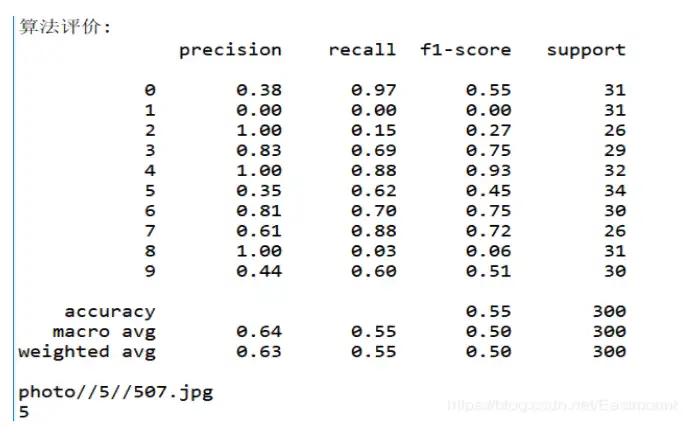
使用KNN演算法進行影像分類實驗,最后演算法評價的準確率(Precision)、召回率(Recall)和F值(F1-score)如圖所示,其中平均準確率為0.64,平均召回率為0.55,平均F值為0.50,其結果不是非常理想,那么,如果采用CNN卷積神經網路進行分類,通過不斷學習細節是否能提高準確度呢?
四.基于樸素貝葉斯演算法的影像分類
下面是呼叫樸素貝葉斯演算法進行影像分類的完整代碼,呼叫sklearn.naive_bayes中的BernoulliNB()函式進行實驗,它將1000張影像按照訓練集為70%,測驗集為30%的比例隨機劃分,再獲取每張影像的像素直方圖,根據像素的特征分布情況進行影像分類分析,
# -*- coding: utf-8 -*- import os import cv2 import numpy as np from sklearn.cross_validation import train_test_split from sklearn.metrics import confusion_matrix, classification_report #---------------------------------------------------------------------------------- # 第一步 切分訓練集和測驗集 #---------------------------------------------------------------------------------- X = [] #定義影像名稱 Y = [] #定義影像分類類標 Z = [] #定義影像像素 for i in range(0, 10): #遍歷檔案夾,讀取圖片 for f in os.listdir("photo/%s" % i): #獲取影像名稱 X.append("photo//" +str(i) + "//" + str(f)) #獲取影像類標即為檔案夾名稱 Y.append(i) X = np.array(X) Y = np.array(Y) #隨機率為100% 選取其中的30%作為測驗集 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=1) print len(X_train), len(X_test), len(y_train), len(y_test) #---------------------------------------------------------------------------------- # 第二步 影像讀取及轉換為像素直方圖 #---------------------------------------------------------------------------------- #訓練集 XX_train = [] for i in X_train: #讀取影像 #print i image = cv2.imread(i) #影像像素大小一致 img = cv2.resize(image, (256,256), interpolation=cv2.INTER_CUBIC) #計算影像直方圖并存盤至X陣列 hist = cv2.calcHist([img], [0,1], None, [256,256], [0.0,255.0,0.0,255.0]) XX_train.append(((hist/255).flatten())) #測驗集 XX_test = [] for i in X_test: #讀取影像 #print i image = cv2.imread(i) #影像像素大小一致 img = cv2.resize(image, (256,256), interpolation=cv2.INTER_CUBIC) #計算影像直方圖并存盤至X陣列 hist = cv2.calcHist([img], [0,1], None, [256,256], [0.0,255.0,0.0,255.0]) XX_test.append(((hist/255).flatten())) #---------------------------------------------------------------------------------- # 第三步 基于樸素貝葉斯的影像分類處理 #---------------------------------------------------------------------------------- from sklearn.naive_bayes import BernoulliNB clf = BernoulliNB().fit(XX_train, y_train) predictions_labels = clf.predict(XX_test) print u'預測結果:' print predictions_labels print u'演算法評價:' print (classification_report(y_test, predictions_labels)) #輸出前10張圖片及預測結果 k = 0 while k<10: #讀取影像 print X_test[k] image = cv2.imread(X_test[k]) print predictions_labels[k] #顯示影像 cv2.imshow("img", image) cv2.waitKey(0) cv2.destroyAllWindows() k = k + 1
代碼中對預測集的前十張影像進行了顯示,其中“368.jpg”影像如下圖所示,其分類預測的類標結果為“3”,表示第3類大卡車,預測結果正確,

下圖展示了“452.jpg”影像,其分類預測的類標結果為“4”,表示第4類恐龍,預測結果正確,

使用樸素貝葉斯演算法進行影像分類實驗,最后預測的結果及演算法評價準確率(Precision)、召回率(Recall)和F值(F1-score)如圖所示,

五.總結
本篇文章主要講解Python環境下的影像分類演算法,首先普及了常見的分類演算法,包括樸素貝葉斯、KNN、SVM、隨機森林、神經網路等,接著通過樸素貝葉斯和KNN分別實作了1000張影像的影像分類實驗,希望對讀者有一定幫助,也希望這些知識點為讀者從事Python影像處理相關專案實踐或科學研究提供一定基礎,
參考文獻:
[1]岡薩雷斯著. 數字影像處理(第3版)[M]. 北京:電子工業出版社,2013.
[2]楊秀璋, 顏娜. Python網路資料爬取及分析從入門到精通(分析篇)[M]. 北京:北京航天航空大學出版社, 2018.
[3]gzq0723. 干貨——影像分類(上)[EB/OL]. (2018-08-28). https://blog.csdn.net/gzq0723/
[4]article/details/82185832.
[5]sinat_34430765. OpenCV分類器學習心得[EB/OL]. (2016-08-03). https://blog.csdn.net/sinat_34430765/article/details/52103189.
[6]baidu_28342107. 機器學習之貝葉斯演算法影像分類[EB/OL]. (2018-10-10). https://blog.csdn.net/baidu_28342107/article/details/82999249.
[7]baidu_28342107. 機器學習之KNN演算法實作影像分類[EB/OL]. (2018-09-28). https://blog.csdn.net/baidu_28342107/article/details/82870436.
[8]normol. svm實作圖片分類(python)[EB/OL]. (2018-11-19). https://blog.csdn.net/normol/article/details/84230890.
[9]wfjiang. SVM-支持向量機原理詳解與實踐[EB/OL]. (2017-03-14). https://www.cnblogs.com/spoorer/p/6551220.html.
[10]快樂的小飛熊. 隨機森林原理[EB/OL]. (2017-03-05). https://www.jianshu.com/p/57e862d695f2.
[11]燁楓_邱. 深入理解BP神經網路[EB/OL]. (2018-06-01). https://www.jianshu.com/p/6ab6f53874f7.
[12]smilejiasmile. 卷積神經網路(CNN)及其實踐[EB/OL]. (2018-06-20). https://blog.csdn.net/smilejiasmile/article/details/80752889.
[13] 誓天斷發. 機器學習之BP神經網路演算法實作影像分類[EB/OL]. (2018-10-23). https://blog.csdn.net/baidu_28342107/article/details/83307633.
[14] 楊秀璋. [Python人工智能] 十.Tensorflow+Opencv實作CNN自定義影像分類案例及與機器學習KNN影像分類演算法對比[EB/OL]. https://blog.csdn.net/Eastmount/article/details/103757386.
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/539433.html
標籤:其他
上一篇:分數與小數