1. String
字串是 Redis 最基本的資料型別,不僅所有 key 都是字串型別,其它幾種資料型別構成的元素也是字串,注意字串的長度不能超過 512M,
1.1 編碼方式(encoding)
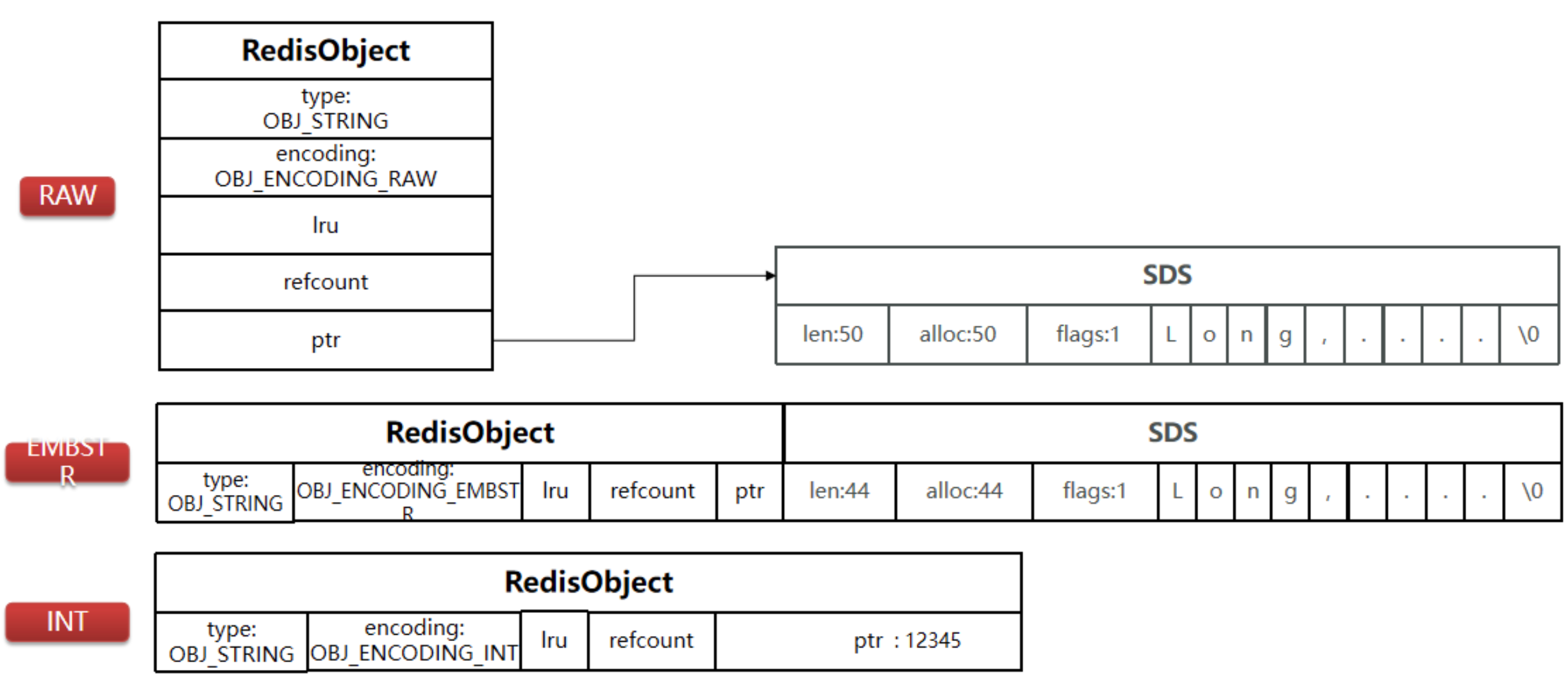
字串物件的編碼可以是 int ,raw 或者 embstr ,
- int 編碼:保存的是可以用 long 型別表示的整數值,
- embstr 編碼:保存長度小于 44 位元組的字串(redis3.2 版本之前是 39 位元組,之后是 44 位元組),
- raw 編碼:保存長度大于 44 位元組的字串(redis3.2 版本之前是 39 位元組,之后是 44 位元組),
<
int 編碼是用來保存整數值,而 embstr 是用來保存短字串,raw 編碼是用來保存長字串,
1.2 raw 編碼
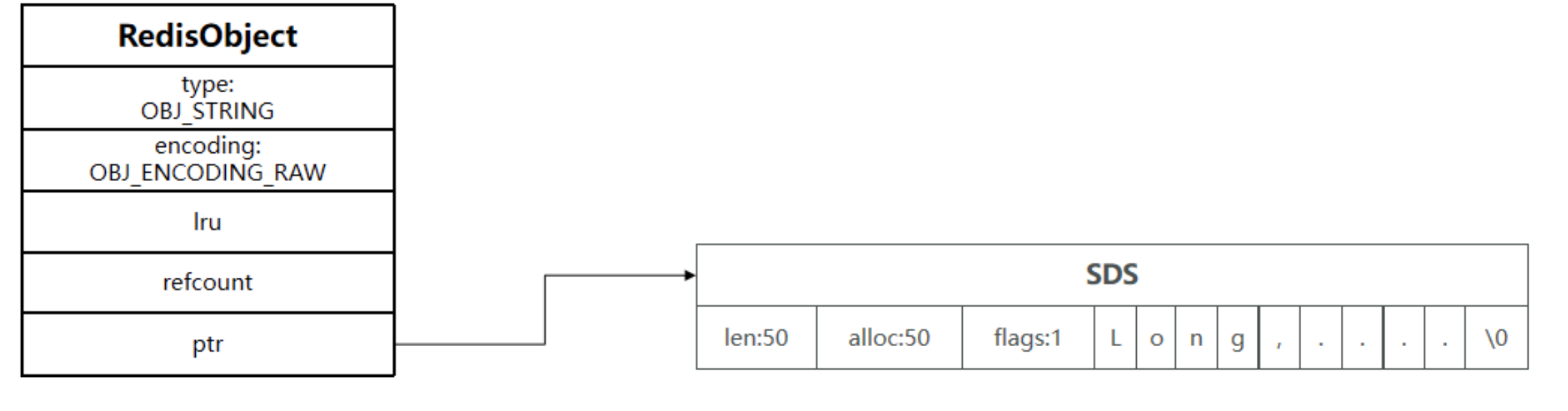
*ptr 指向實際 SDS 存盤位置,記憶體不連續
1.3 embstr 編碼

記憶體連續,意味著 redis 在申請記憶體空間時只需要呼叫一次申請記憶體函式,減少用戶態內核態交換,效率高,
1.4 int 編碼
如果存盤的字串是整數值,并且大小在 LONG_MAX 范圍內,則會采用 INT 編碼:直接將資料保存在 RedisObject 的 ptr 指標位置(剛好 8 位元組),不再需要 SDS 了,
1.5 總結
2. List
list 串列,它是簡單的字串串列,按照插入順序排序,你可以添加一個元素到串列的頭部(左邊)或者尾部(右邊),它的底層實際上是個鏈表結構,
2.1 編碼方式(encoding)
串列物件的編碼是 quicklist, (之前版本中有 linkedList 和 ziplist 這兩種編碼,進一步的,目前 Redis 定義的 10 個物件編碼方式宏名中,有兩個被完全閑置了,分別是: OBJ_ENCODING_ZIPMAP 與 OBJ_ENCODING_LINKEDLIST, 從 Redis 的演進歷史上來看,前者是后續可能會得到支持的編碼值(代碼還在), 后者則應該是被徹底淘汰了)
2.2 記憶體布局
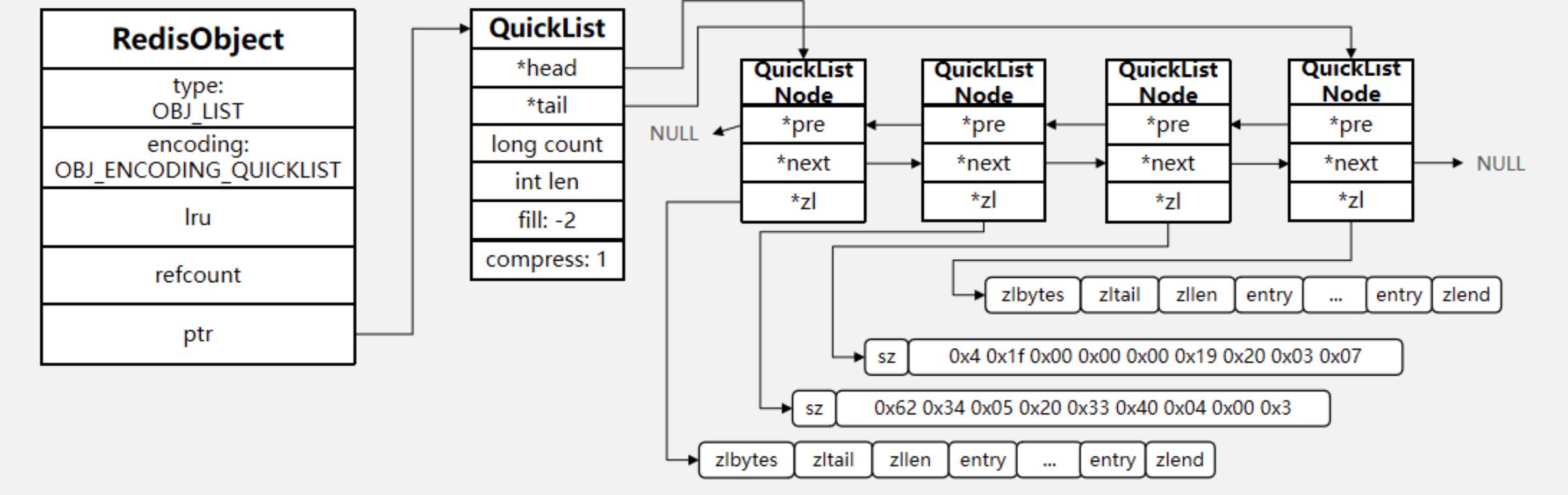
3. Set
集合物件 set 是 string 型別(整數也會轉換成 string 型別進行存盤)的無序集合,注意集合和串列的區別:集合中的元素是無序的,因此不能通過索引來操作元素;集合中的元素不能有重復,
3.1 編碼方式(encoding)
集合物件的編碼可以是 intset 或者 hashtable; 底層實作有兩種,分別是 intset 和 dict , 顯然當使用 intset 作為底層實作的資料結構時,集合中存盤的只能是數值資料,且必須是整數;而當使用 dict 作為集合物件的底層實作時,是將資料全部存盤于 dict 的鍵中,值欄位閑置不用.
3.2 記憶體布局

3.3 編碼轉換
當集合同時滿足以下兩個條件時,使用 intset 編碼:
- 集合物件中所有元素都是整數
- 集合物件所有元素數量不超過 512
不能滿足這兩個條件的就使用 hashtable 編碼,第二個條件可以通過組態檔的 set-max-intset-entries 進行配置,
4. Zset
和上面的集合物件相比,有序集合物件是有序的,與串列使用索引下標作為排序依據不同,有序集合為每個元素設定一個分數(score)作為排序依據,
4.1 編碼方式(encoding)
- SkipList & HT(Dict):SkipList 可以排序,并且可以同時存盤 score 和 ele 值(member);HT 可以鍵值存盤,并且可以根據 key 找 value
- ZipList :當 節點 entry 數量 小于 128 并且 每個節點大小小于 64kb 時采用
4.2 記憶體結構
SkipList & HT(Dict)
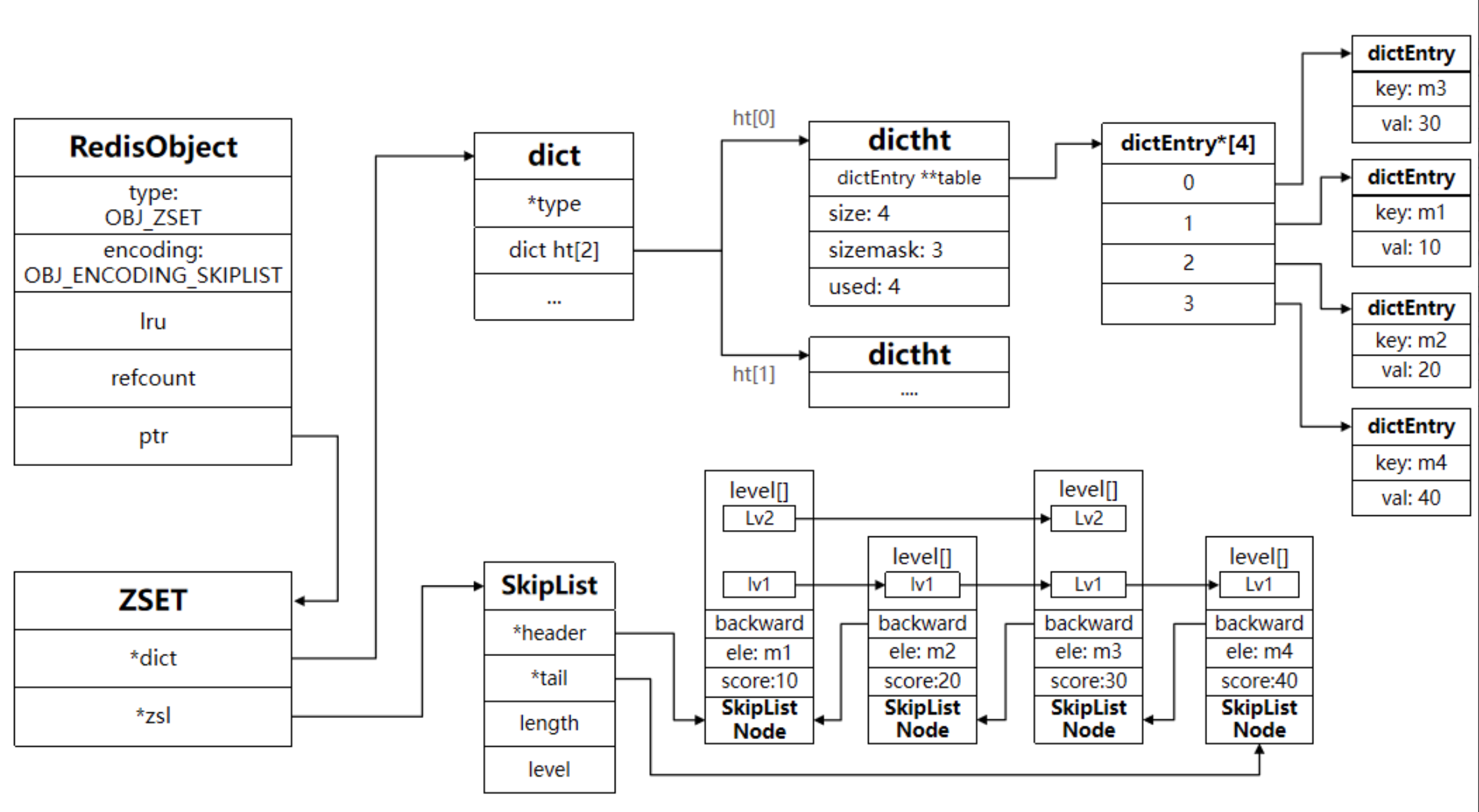
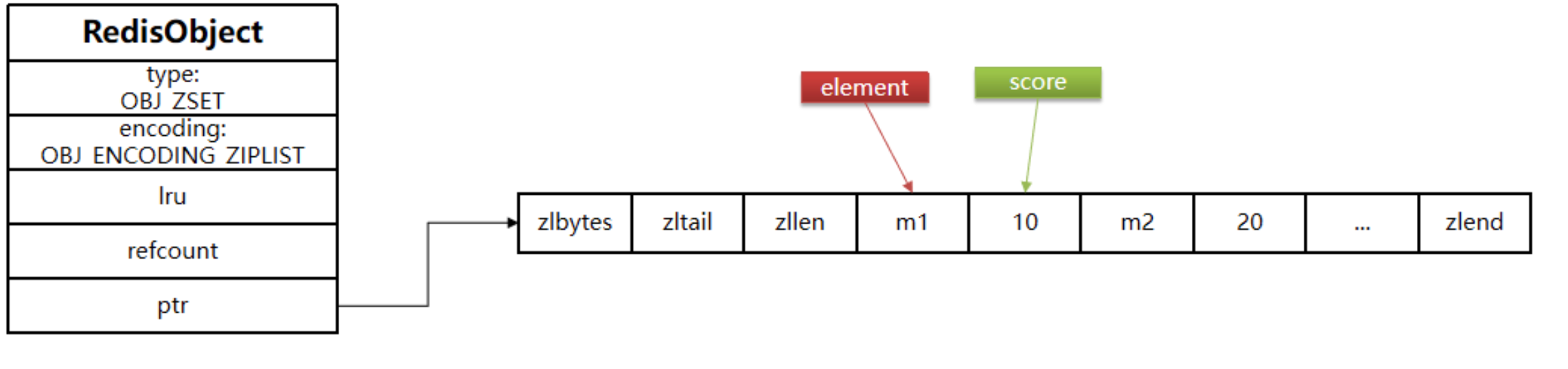
ZipList
當元素數量不多時,HT 和 SkipList 的優勢不明顯,而且更耗記憶體,因此 zset 還會采用 ZipList 結構來節省記憶體,不過需要同時滿足兩個條件:
- 元素數量小于 zset_max_ziplist_entries,默認值 128
- 每個元素都小于 zset_max_ziplist_value 位元組,默認值 64
ziplist 本身沒有排序功能,而且沒有鍵值對的概念,因此需要有 zset 通過編碼實作:
- ZipList 是連續記憶體,因此 score 和 element 是緊挨在一起的兩個 entry, element 在前,score 在后
- score 越小越接近隊首,score 越大越接近隊尾,按照 score 值升序排列
5. Hash
哈希物件的鍵是一個字串型別,值是一個鍵值對集合,
5.1 編碼方式(encoding)
哈希物件的編碼可以是 ziplist 或者 hashtable;對應的底層實作有兩種,一種是 ziplist, 一種是 dict,
5.2 記憶體布局
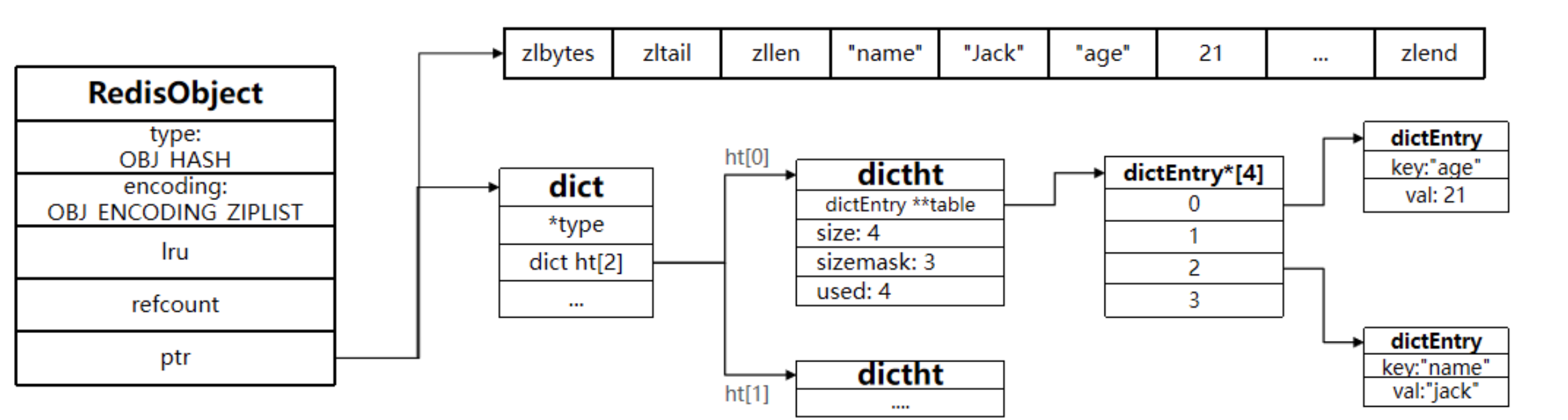
Hash 結構與 Redis 中的 Zset 非常類似:
- 都是鍵值存盤
- 都需求根據鍵獲取值
- 鍵必須唯一
區別如下:
- zset 的鍵是 member,值是 score;hash 的鍵和值都是任意值
- zset 要根據 score 排序;hash 則無需排序
當 Hash 中資料項比較少的情況下,Hash 底層才?壓縮串列 ziplist 進?存盤資料,隨著資料的增加,底層的 ziplist 就可能會轉成 dict,具體配置如下:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/539756.html
標籤:其他
上一篇:軟工綜合實踐課設——員工招聘系統(參考BOSS直聘);Pyhton實作
下一篇:每日演算法之把陣列排成最小的數