data analysis
什么是資料分析
- 是把隱藏在一些看似雜亂無章的資料背后的資訊提煉出來,總結出所研究物件的內在規律
- 使得資料的價值最大化
- 分析用戶的消費行為
- 制定促銷活動的方案
- 制定促銷時間和粒度
- 計算用戶的活躍度
- 分析產品的回購力度
- 分析廣告點擊率
- 決定投放時間
- 制定廣告定向人群方案
- 決定相關平臺的投放
- ......
- 分析用戶的消費行為
- 使得資料的價值最大化
- 資料分析是用適當的方法對收集來的大量資料進行分析,幫助人們做出判斷,以便采取適當的行動
- 保險公司從大量賠付申請資料中判斷哪些為騙保的可能
- 支付寶通過從大量的用戶消費記錄和行為自動調整花唄的額度
- 短視頻平臺通過用戶的點擊和觀看行為資料針對性的給用戶推送喜歡的視頻
資料分析實作流程
- 提出問題
- 準備資料
- 分析資料
- 獲得結論
- 成果可視化
開發環境介紹
- anaconda
- 官網:https://www.anaconda.com/
- 集成環境:集成好了資料分析和機器學習中所需要的全部環境
- 注意:
- 安裝目錄不可以有中文和特殊符號
- 注意:
- jupyter
- jupyter就是anaconda提供的一個基于瀏覽器的可視化開發工具
- jupyter的基本使用
- 啟動:在終端中錄入:jupyter notebook的指令,按下回車
- 新建:
- python3:anaconda中的一個源檔案
- cell有兩種模式:
- code:撰寫代碼
- markdown:撰寫筆記
- 快捷鍵:
- 添加cell:a或者b
- 洗掉:x
- 修改cell的模式:
- m:修改成markdown模式
- y:修改成code模式
- 執行cell:
- shift+enter
- tab:自動補全
- 代開幫助檔案:shift+tab
資料分析三劍客
- numpy
- pandas(重點)
- matplotlib
numpy
- NumPy(Numerical Python) 是 Python 語言中做科學計算的基礎庫,重在于數值計算,也是大部分Python科學計算庫的基礎,多用于在大型、多維陣列上執行的數值運算,
numpy的創建
- 使用np.array()創建
- 使用plt創建
- 使用np的routines函式創建
使用numpy創建一位陣列
>>> import numpy as np
>>> arr = np.array([1,2,3])
>>> arr
array([1, 2, 3])
使用numpy創建二維陣列
>>> arr = np.array([[1,2,3],[4,5,6]])
>>> arr
array([[1, 2, 3],
[4, 5, 6]])
陣列和串列的區別是什么?
>>> arr = np.array([1,1.27,'regina']) >>> arr array(['1', '1.27', 'regina'], dtype='<U32')
- 陣列中存盤的資料元素型別必須是統一型別
- 優先級:
- 字串 > 浮點型 > 整數
-
將外部的一張圖片讀取加載到numpy陣列中,然后嘗試改變陣列元素的數值查看對原始圖片的影響
import matplotlib.pyplot as plt img_arr = plt.imread('/Users/ivanlee/Desktop/女明星/IMG_1473.JPG') plt.imshow(img_arr) #將numpy陣列進行可視化展示
如果每一個像素塊的值減100

運用函式創建陣列
- zero()
- ones()
- linspace()
- arange()
- random系列
-
ones
np.ones(shape(3,4)) array([[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]]) -
Linspace(): 一維的等引數列的陣列
>>> np.linspace(0,100,num=20) array([ 0. , 5.26315789, 10.52631579, 15.78947368, 21.05263158, 26.31578947, 31.57894737, 36.84210526, 42.10526316, 47.36842105, 52.63157895, 57.89473684, 63.15789474, 68.42105263, 73.68421053, 78.94736842, 84.21052632, 89.47368421, 94.73684211, 100. ]) -
arange():一維的等引數列
>>> np.arange(0,50,step=3) array([ 0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48]) -
Random():回傳由size決定的形狀陣列
>>> np.random.randint(0,100,size=(3,5)) array([[88, 56, 60, 56, 9], [ 9, 0, 32, 31, 32], [78, 10, 21, 78, 98]])
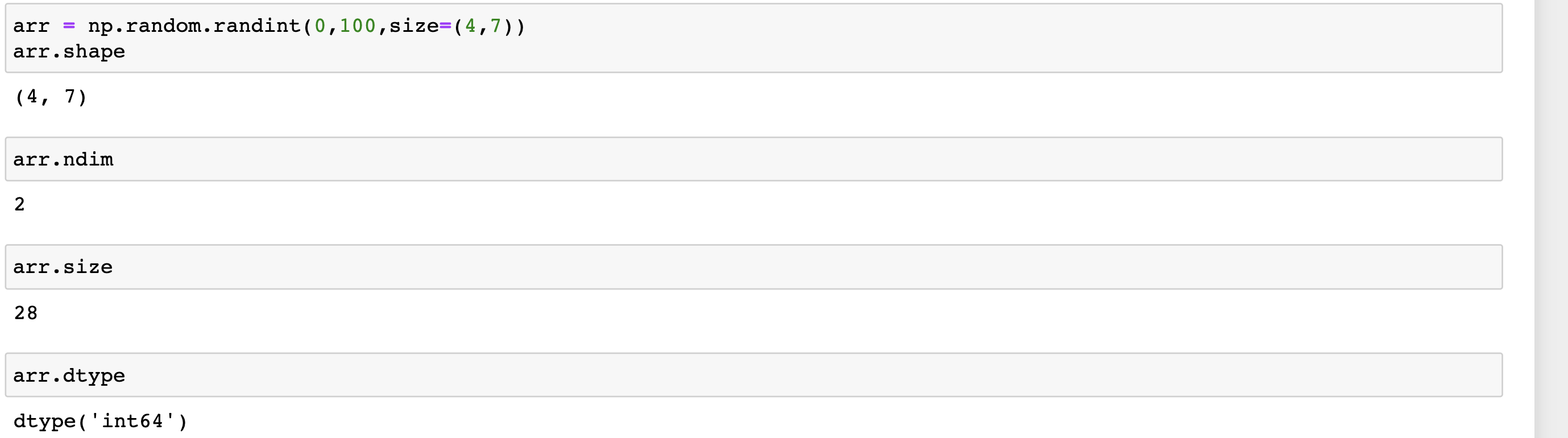
numpy的常用屬性
- shape 形狀
- ndim 維度
- size 總共個數
- dtype 元素型別
numpy的資料型別
- array(dtype=?):可以設定資料型別
- arr.dtype = '?':可以修改資料型別
| 名稱 | 描述 |
|---|---|
| bool_ | 布爾型資料型別(True 或者 False) |
| int_ | 默認的整數型別(類似于 C 語言中的 long,int32 或 int64) |
| intc | 與 C 的 int 型別一樣,一般是 int32 或 int 64 |
| intp | 用于索引的整數型別(類似于 C 的 ssize_t,一般情況下仍然是 int32 或 int64) |
| int8 | 位元組(-128 to 127) |
| int16 | 整數(-32768 to 32767) |
| int32 | 整數(-2147483648 to 2147483647) |
| int64 | 整數(-9223372036854775808 to 9223372036854775807) |
| uint8 | 無符號整數(0 to 255) |
| uint16 | 無符號整數(0 to 65535) |
| uint32 | 無符號整數(0 to 4294967295) |
| uint64 | 無符號整數(0 to 18446744073709551615) |
| float_ | float64 型別的簡寫 |
| float16 | 半精度浮點數,包括:1 個符號位,5 個指數位,10 個尾數位 |
| float32 | 單精度浮點數,包括:1 個符號位,8 個指數位,23 個尾數位 |
| float64 | 雙精度浮點數,包括:1 個符號位,11 個指數位,52 個尾數位 |
| complex_ | complex128 型別的簡寫,即 128 位復數 |
| complex64 | 復數,表示雙 32 位浮點數(實數部分和虛數部分) |
| complex128 | 復數,表示雙 64 位浮點數(實數部分和虛數部分) |
numpy 的數值型別實際上是 dtype 物件的實體,并對應唯一的字符,包括 np.bool_,np.int32,np.float32,等等,

numpy的索引和切片操作(重點)
-
索引操作和串列同理
>>> arr = np.random.randint(1,100,size=(5,6)) >>> arr array([[49, 26, 2, 75, 91, 93], [68, 49, 40, 40, 51, 54], [39, 49, 16, 93, 45, 2], [13, 43, 67, 52, 2, 46], [74, 20, 9, 73, 91, 21]]) >>> arr[1] array([68, 49, 40, 40, 51, 54]) >>> arr[[1,3,4]] array([[68, 49, 40, 40, 51, 54], [13, 43, 67, 52, 2, 46], [74, 20, 9, 73, 91, 21]]) -
切片操作
-
切出前兩行資料
>>> arr[0:2] array([[49, 26, 2, 75, 91, 93], [68, 49, 40, 40, 51, 54]]) -
切出前兩列資料
>>> arr[:,0:2] array([[49, 26], [68, 49], [39, 49], [13, 43], [74, 20]]) -
切出前兩行的前兩列的資料
>>> arr[0:2,0:2] array([[49, 26], [68, 49]]) -
陣列行翻轉
>>> arr[::-1] array([[74, 20, 9, 73, 91, 21], [13, 43, 67, 52, 2, 46], [39, 49, 16, 93, 45, 2], [68, 49, 40, 40, 51, 54], [49, 26, 2, 75, 91, 93]]) -
陣列列翻轉
>>> arr[::,::-1] array([[93, 91, 75, 2, 26, 49], [54, 51, 40, 40, 49, 68], [ 2, 45, 93, 16, 49, 39], [46, 2, 52, 67, 43, 13], [21, 91, 73, 9, 20, 74]]) -
練習:將一張圖片上下左右進行翻轉操作
import matplotlib.pyplot as plt img_arr = plt.imread('/Users/ivanlee/Desktop/女明星/IMG_1473.JPG') plt.imshow(img_arr) #將numpy陣列進行可視化展示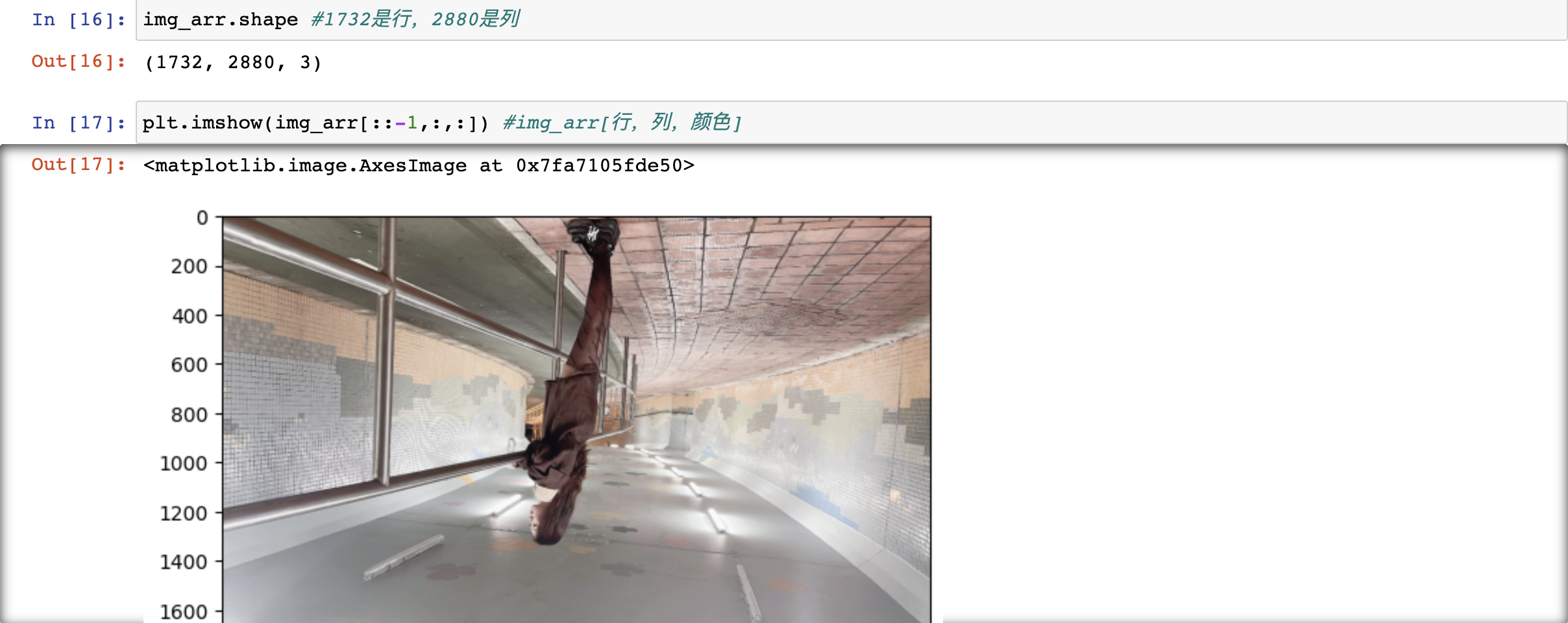

-
練習:將圖片進行指定區域的裁剪
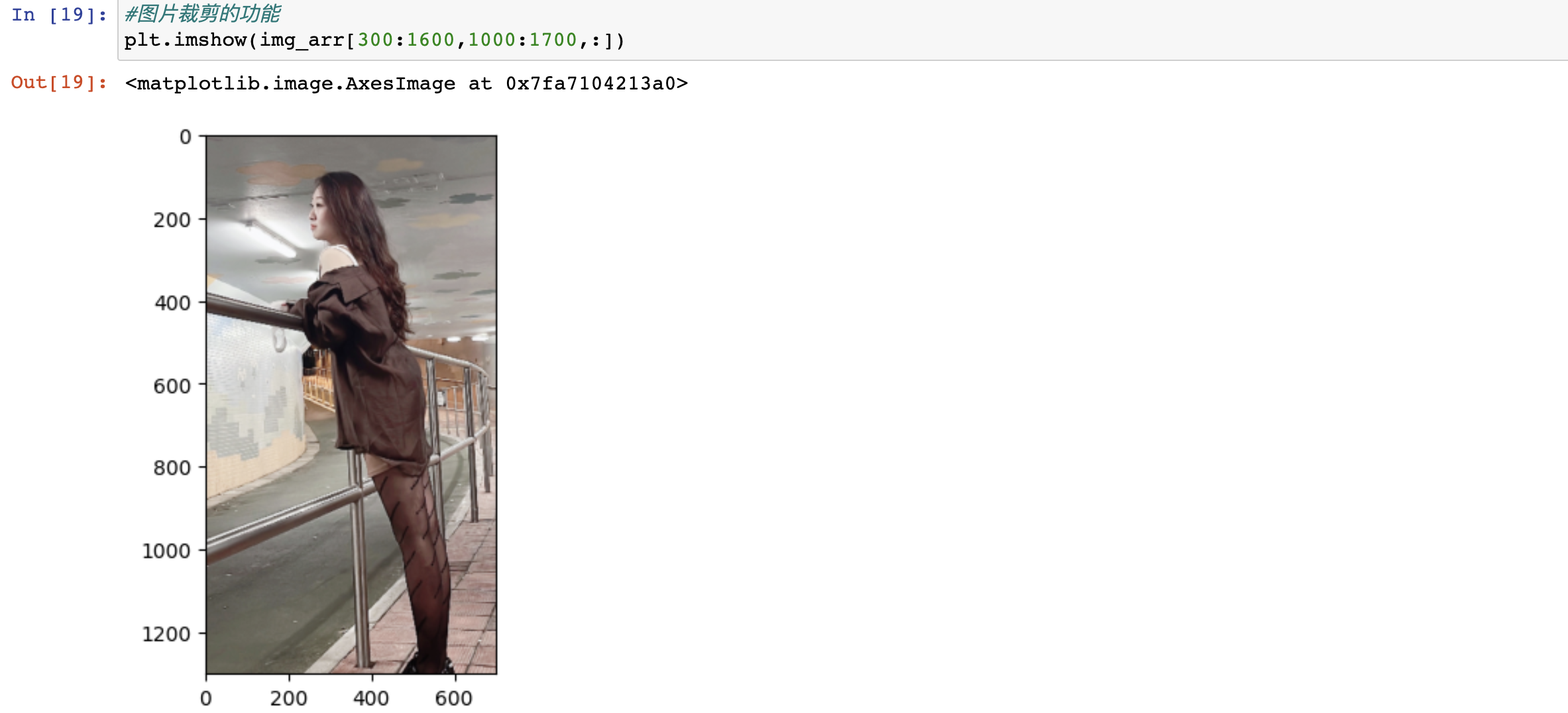
-
numpy變形
-
reshape操作
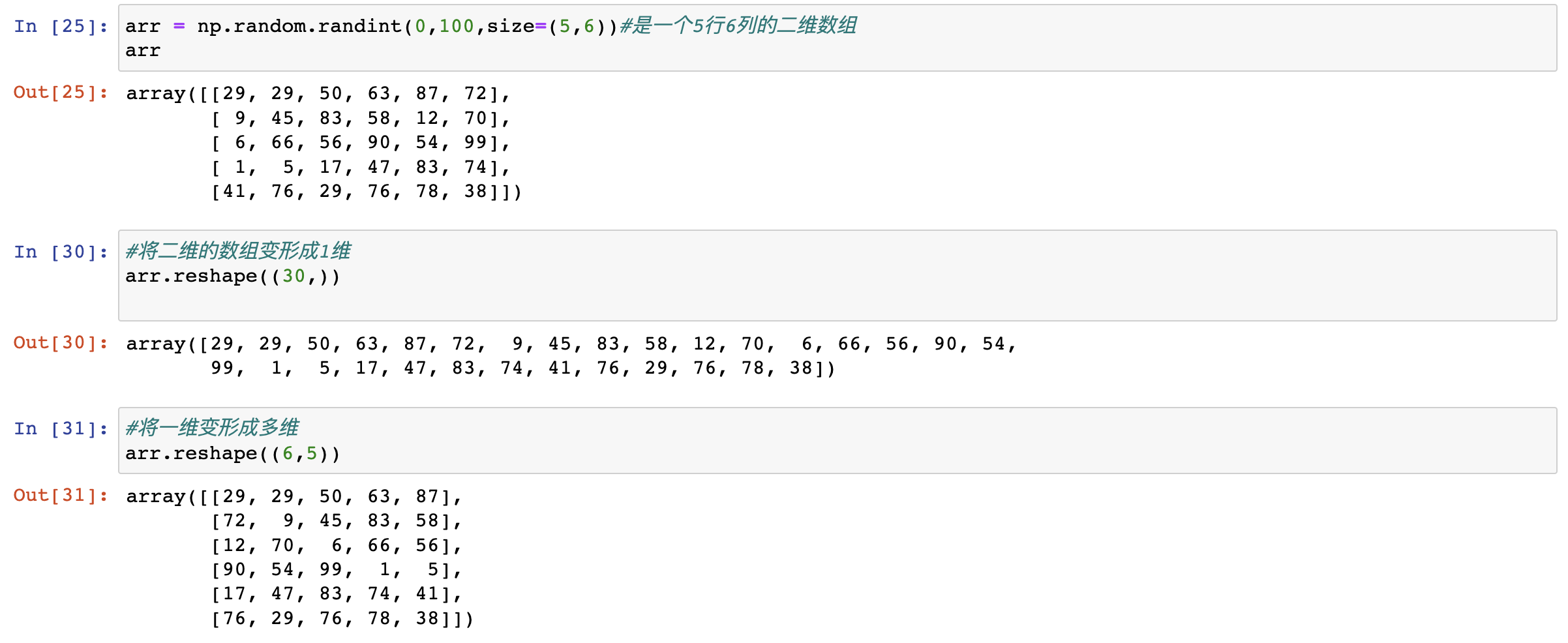
級聯操作
- 將多個numpy陣列進行橫向或者縱向的拼接
-
axis軸向的理解
- 0:列
- 1:行
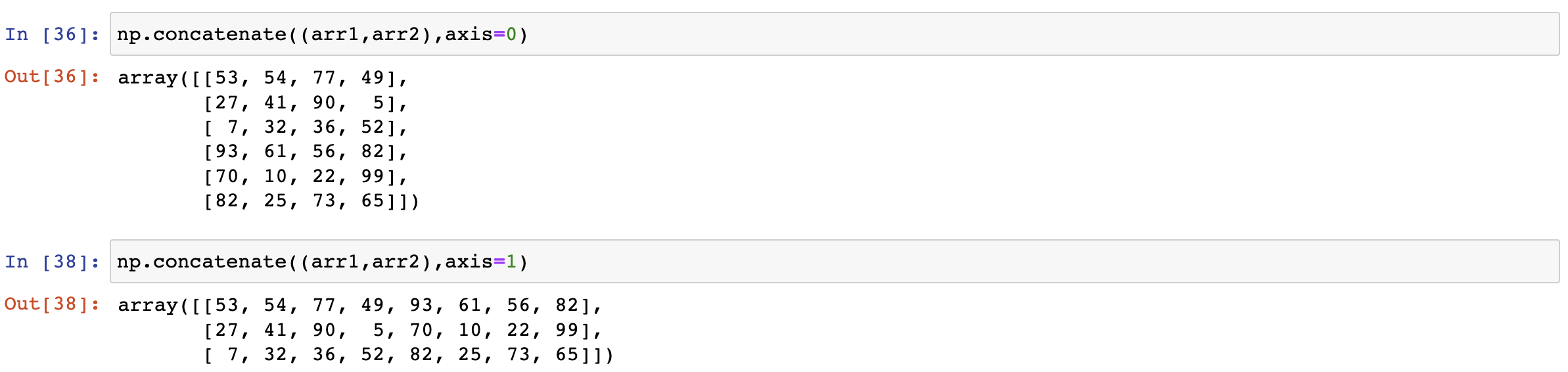
-
問題:
-
級聯的兩個陣列維度一樣,但是行列個數不一樣會如何?
答:不一樣就無法拼接
-
-
對圖進行拼接
arr_3 = np.concatenate((img_arr,img_arr,img_arr),axis=0) plt.imshow(arr_3)
arr_3 = np.concatenate((img_arr,img_arr,img_arr),axis=1) plt.imshow(arr_3)
常用的聚合操作
-
sum,max,min,mean
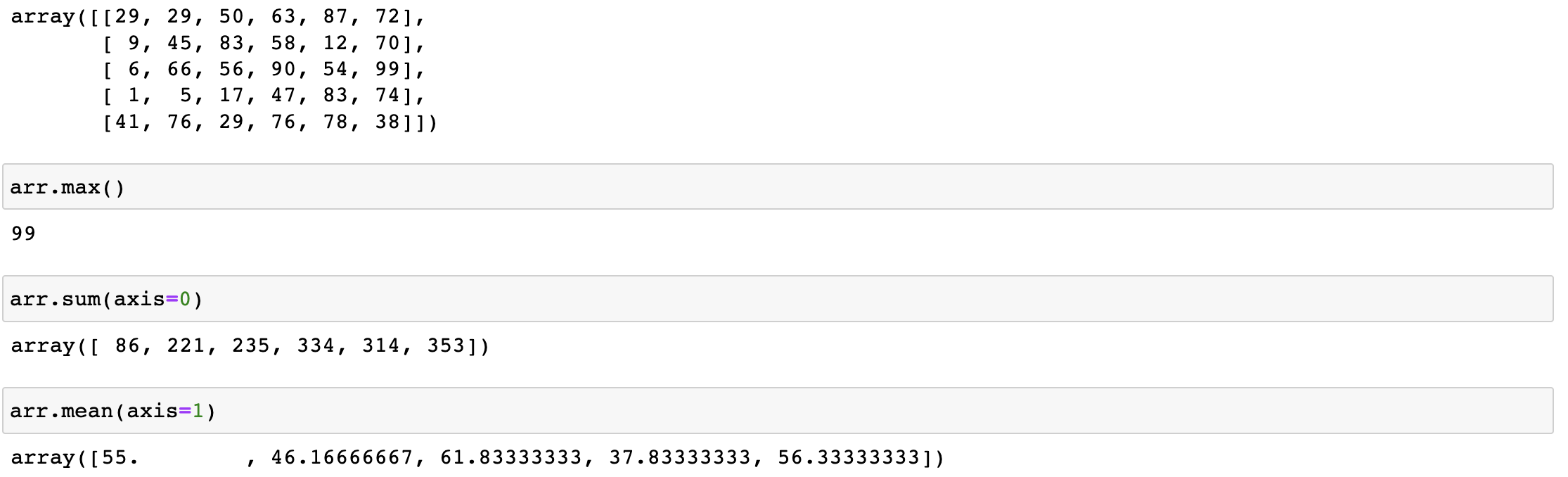
常用的數學函式
- NumPy 提供了標準的三角函式:sin()、cos()、tan()
- numpy.around(a,decimals) 函式回傳指定數字的四舍五入值,
- 引數說明:
- a: 陣列
- decimals: 舍入的小數位數, 默認值為0, 如果為負,整數將四舍五入到小數點左側的位置
- 引數說明:
常用的統計函式
- numpy.amin() 和 numpy.amax(),用于計算陣列中的元素沿指定軸的最小、最大值,
- numpy.ptp():計算陣列中元素最大值與最小值的差(最大值 - 最小值),
- numpy.median() 函式用于計算陣列 a 中元素的中位數(中值)
- 標準差std():標準差是一組資料平均值分散程度的一種度量,
- 公式:
std = sqrt(mean((x - x.mean())**2)) - 如果陣列是 [1,2,3,4],則其平均值為 2.5, 因此,差的平方是 [2.25,0.25,0.25,2.25],并且其平均值的平方根除以 4,即 sqrt(5/4) ,結果為 1.1180339887498949,
- 公式:
- 方差var():統計中的方差(樣本方差)是每個樣本值與全體樣本值的平均數之差的平方值的平均數,即 mean((x - x.mean())** 2),換句話說,標準差是方差的平方根

矩陣相關
-
NumPy 中包含了一個矩陣庫 numpy.matlib,該模塊中的函式回傳的是一個矩陣,而不是 ndarray 物件,一個 的矩陣是一個由行(row)列(column)元素排列成的矩形陣列,
-
numpy.matlib.identity() 函式回傳給定大小的單位矩陣,單位矩陣是個方陣,從左上角到右下角的對角線(稱為主對角線)上的元素均為 1,除此以外全都為 0,
eye回傳一個標準的單位矩陣
np.eye(6)

T 轉置

矩陣相乘
- numpy.dot(a, b, out=None)
- a : ndarray 陣列
- b : ndarray 陣列

本文來自博客園,作者:ivanlee717,轉載請注明原文鏈接:https://www.cnblogs.com/ivanlee717/p/16985422.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/539988.html
標籤:Python
上一篇:Python編程:從入門到實踐為什么帶你快速入門Python并在學習中避坑
下一篇:小程式開發環境搭建