
?? 作者:韓信子@ShowMeAI
?? 資料分析實戰系列:https://www.showmeai.tech/tutorials/40
?? 本文地址:https://www.showmeai.tech/article-detail/411
?? 宣告:著作權所有,轉載請聯系平臺與作者并注明出處
?? 收藏ShowMeAI查看更多精彩內容
?? 引言
可視化是EDA的基礎,當面對一個新的、未知的資料集時,視覺檢查使我們能夠了解可用的資訊,繪制一些有關資料的模式,并診斷出我們可能需要解決的幾個問題,在這方面,??Pandas Profiling 一直是每個資料科學家工具箱中不可或缺的瑞士刀,可以幫助我們快速生成資料摘要報告,包括資料概覽、變數屬性、資料分布、重復值和其他指標,它能夠在可視化中呈現這些資訊,以便我們更好地理解資料集,但如果我們能夠比較兩個資料集呢,有沒有快速的方式可以實作?

在本篇博客文章中,ShowMeAI將介紹如何利用 Pandas Profiling 的比較報告功能來提升資料探索分析 (EDA) 流程,我們會介紹到如何使用 Pandas Profiling 比較報告功能來比較兩個不同的資料集,這可以幫助我們更快地對比分析資料,獲取分布差異,為后續做準備,
我們本次用到的資料集是 ??Kaggle 的 HCC 資料集,大家可以通過 ShowMeAI 的百度網盤地址下載,
?? 實戰資料集下載(百度網盤):公眾號『ShowMeAI研究中心』回復『實戰』,或者點擊 這里 獲取本文 [42]Pandas Profiling:使用高級EDA工具對比分析2個資料集 『HCC 資料集』
? ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub

關于更多資料自動化探索工具,可以參考ShowMeAI過往文章 ??自動化資料分析 (EDA) 工具庫大全,
?? 全自動資料EDA工具 Pandas Profiling 功能回顧
我們回顧一下 Pandas Profiling 的安裝與使用方式:
# 通過pip安裝
pip install pandas-profiling==3.5.0
如果我們需要對 hcc 資料集進行分析,參考代碼如下:
import pandas as pd
from pandas_profiling import ProfileReport
# Read the HCC Dataset
df = pd.read_csv("hcc.csv")
# Produce the data profiling report
original_report = ProfileReport(df, title='Original Data')
original_report.to_file("original_report.html")
我們會得到非常清晰的資料分析結果報告,如下是報告的頭部資訊:
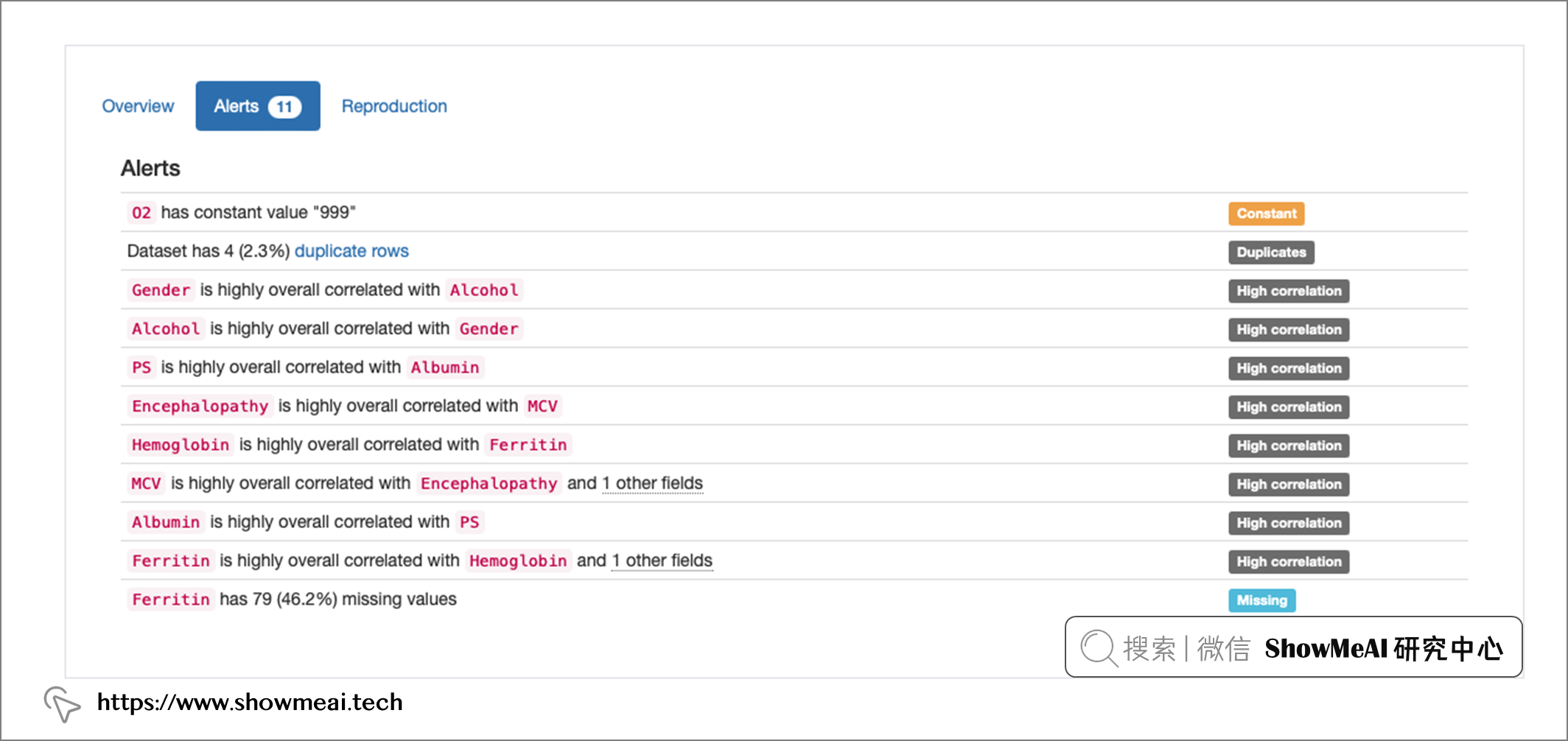
Alerts部分對資料進行分析后,給出了4種主要型別的潛在分析結果,包含可能有的風險和處理方式:
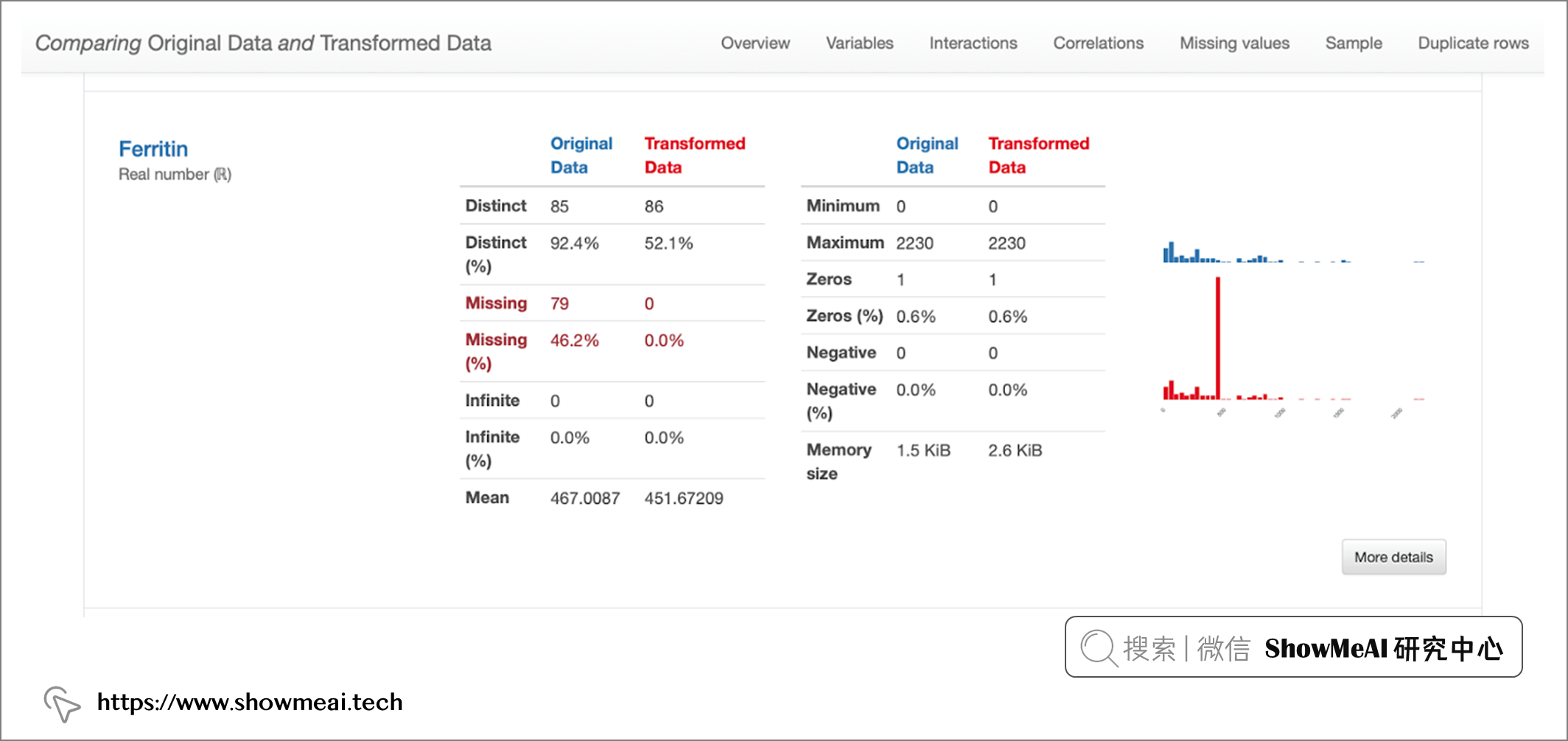
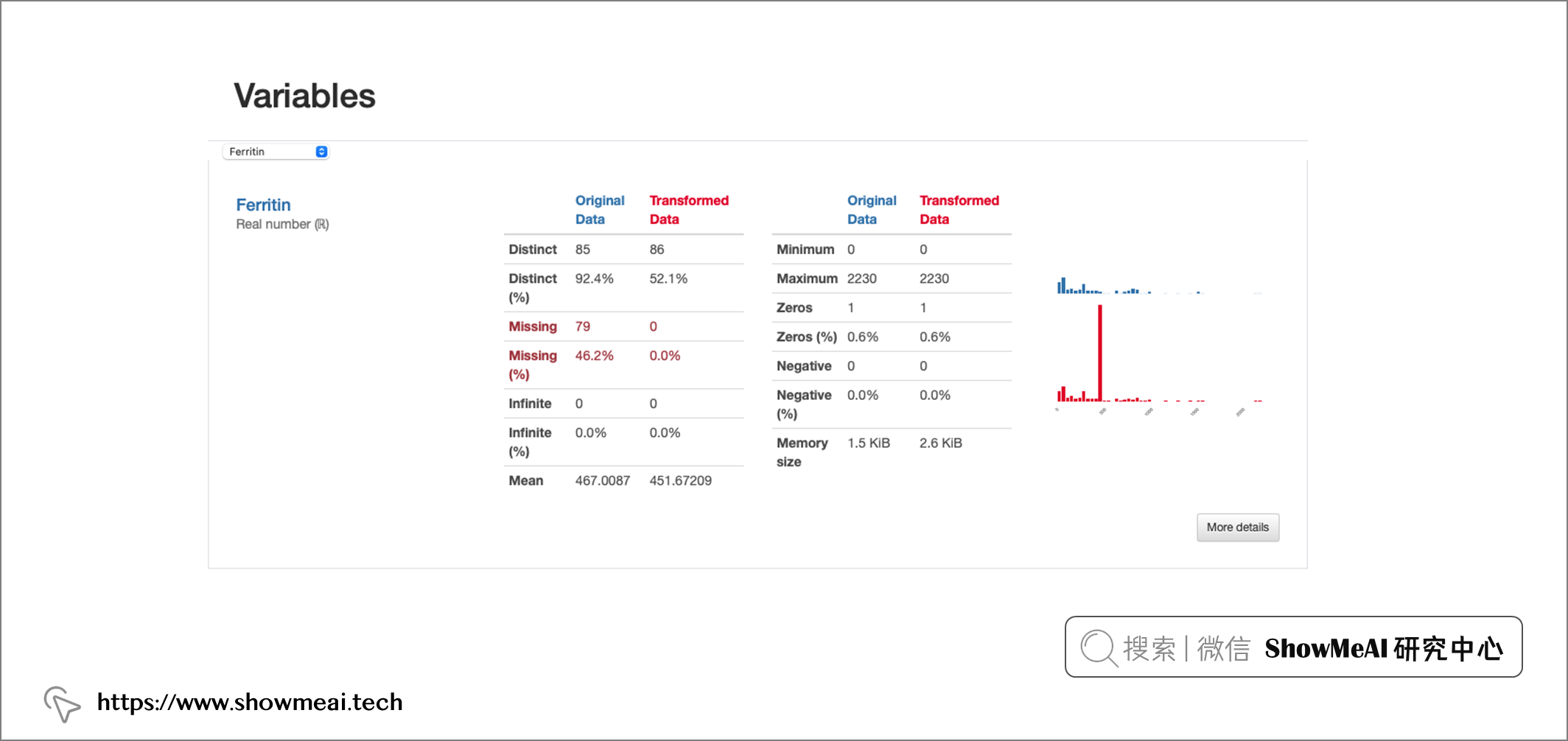
Duplicates:資料中有 4 個重復行;Constant:'O2'是常量欄位,求職999;High Correlation:有強相關性的幾個特征;Missing:“Ferritin”欄位存在缺失值,
?? 資料處理
這對這些問題我們可以做一些處理,
?? 洗掉重復行
在資料集中,有些特征非常具體,涉及到個人的生物測量值,比如血紅蛋白、MCV、白蛋白等,所以,很難有多個患者報告所有特征的相同精確值,因此,我們可以從資料中洗掉這些重復項,
# Drop duplicate rows
df_transformed = df.copy()
df_transformed = df_transformed.drop_duplicates()
?? 洗掉不相關的特征
在資料分析程序中,有些特征可能不具有太多價值,比如 O2 常數值,洗掉這些特征將有助于模型的開發,
# Remove O2
df_transformed = df_transformed.drop(columns='O2')
?? 缺失資料插補
資料插補是用于處理缺失資料的方法,它允許我們在不洗掉觀察值的情況下填補缺失值,均值插補是最常見和最簡單的統計插補技術,它使用特征的均值來填充缺失值,我們將使用均值插補來處理 HCC 資料集中的缺失資料,
# Impute Missing Values
from sklearn.impute import SimpleImputer
mean_imputer = SimpleImputer(strategy="mean")
df_transformed['Ferritin'] = mean_imputer.fit_transform(df_transformed['Ferritin'].values.reshape(-1,1))
?? 資料并行對比分析
下面我們就進入高級功能部分了!我們在對1份資料分析后,如果希望有另外一份資料能夠比對分析,怎么做呢,下面我們以處理前后的資料為例,來講解這個分析的實作方式:
transformed_report = ProfileReport(df_transformed, title="Transformed Data")
comparison_report = original_report.compare(transformed_report)
comparison_report.to_file("original_vs_transformed.html")
最后的對比報告如下:
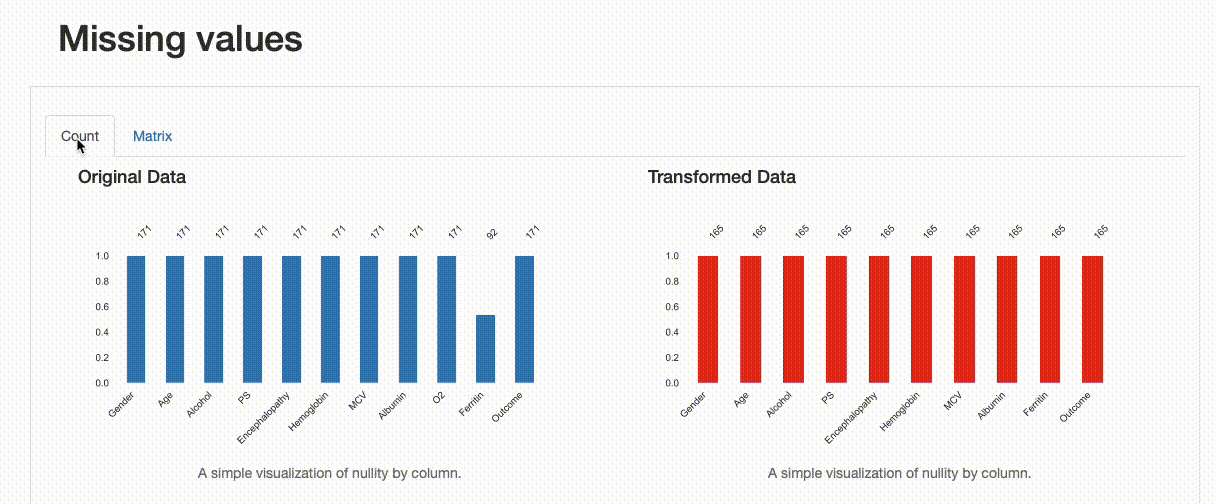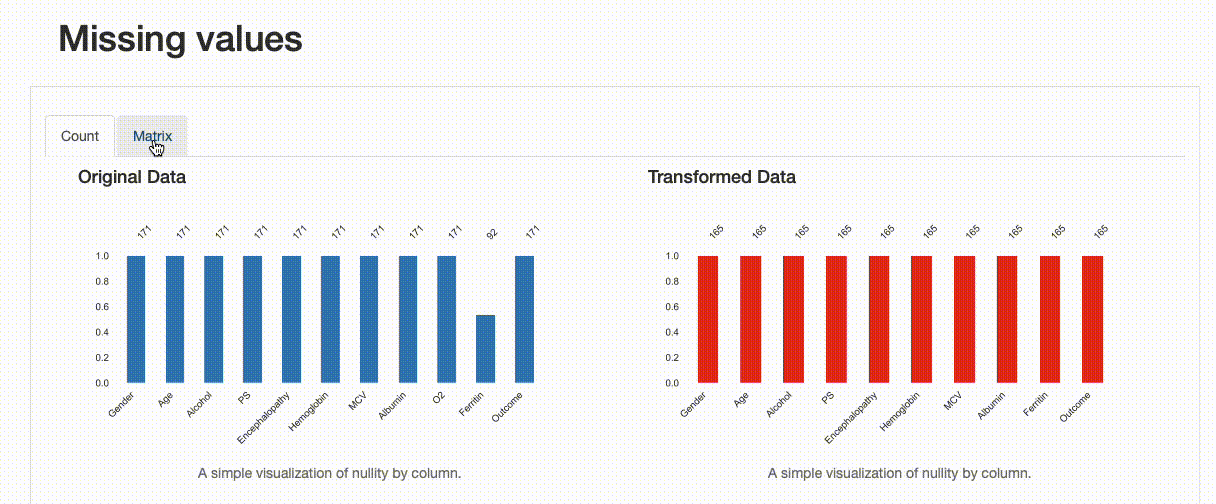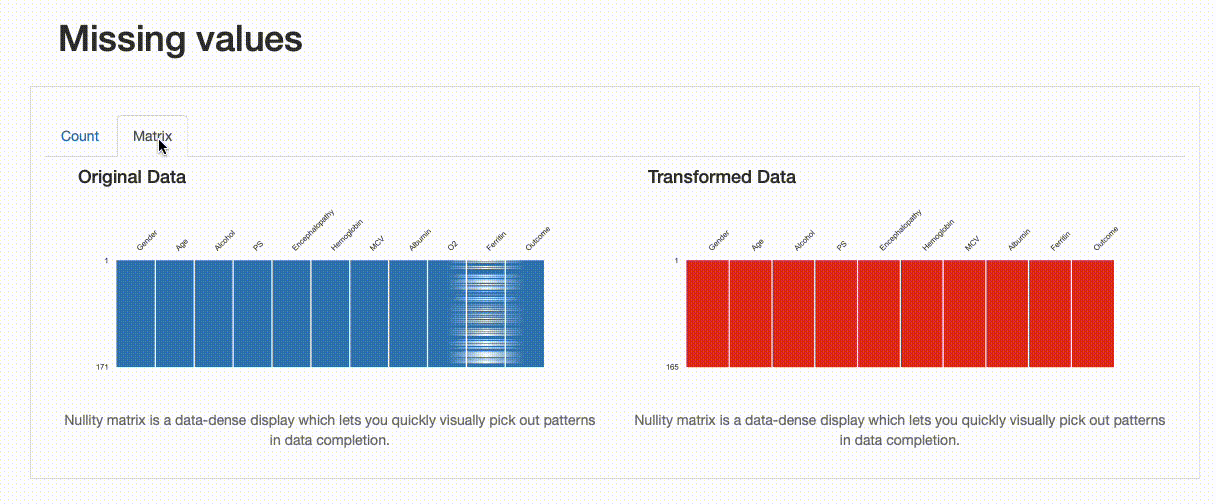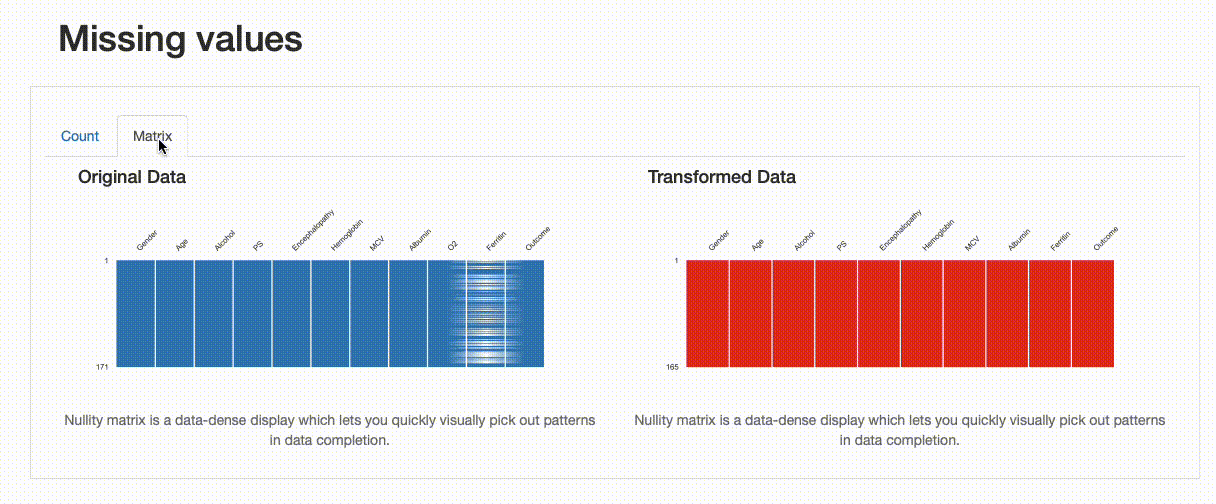
我們可以從資料集概述中立即了解什么?
- 轉換后的資料集包含更少的分類特征("O2"已被洗掉)
- 165個觀察值(而原來的171個包括重復項)
- 沒有缺失值(與原始資料集中的79個缺失觀察值形成對比)
這種轉變如何影響我們的資料質量?這些決定是否很好?我們發現在洗掉重復記錄方面,沒有特別的影響,資料缺失和資料分布有一些變化,如下圖所示:
 |
從上述圖解中,可以看出一些資訊,比如對于“鐵蛋白”欄位,插補資料的均值估算值導致原始資料分布被扭曲,這樣處理可能是有問題的,我們應該避免使用均值估算來替換缺失值,在這種情況下,應該使用其他方法來處理缺失值,例如洗掉缺失值或使用其他統計方法來估算缺失值,
也可以通過相互作用和相關性的可視化來觀察到這一點,在“鐵蛋白”與其他特征之間的關系中,會出現不一致的相互作用模式和更高的相關值,
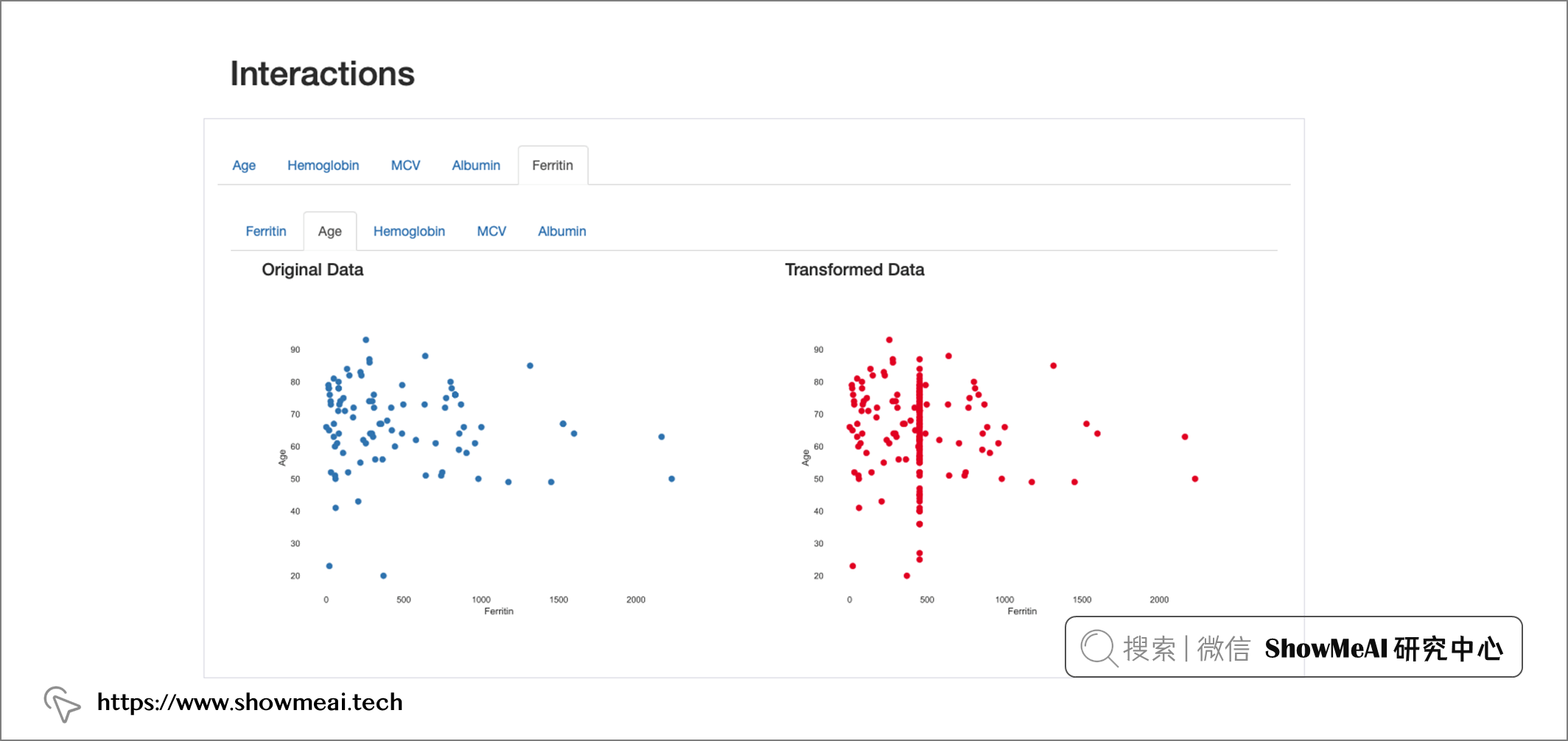
上圖為鐵蛋白與年齡之間的相互作用,估算值顯示在對應于平均值的垂直線上,
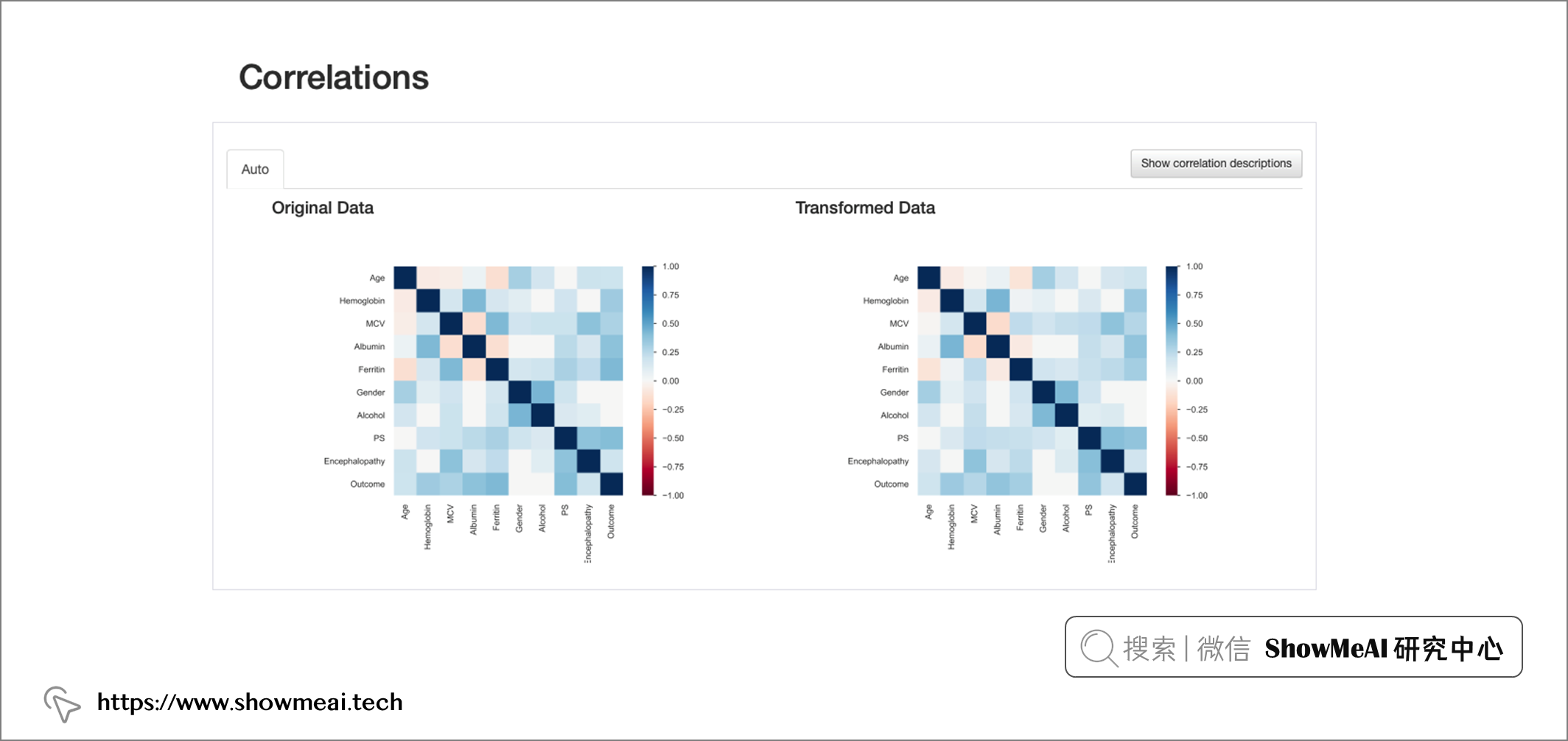
上圖為相關性情況對比,鐵蛋白相關值似乎在資料插補后增加,
?? 總結
在本篇內容中,ShowMeAI講解了 pandas-profiling 工具對不同資料進行對比分析的方法,我們用處理前后的資料做了一個簡單的講解,實際這個方法也可以用到訓練集和測驗集的對比中,用于發現資料漂移等問題,

關于資料漂移,可以參考ShowMeAI的文章 ??機器學習資料漂移問題與解決方案,
參考資料
- ?? Pandas Profiling
- ?? 自動化資料分析 (EDA) 工具庫大全:https://showmeai.tech/article-detail/284
- ?? 機器學習資料漂移問題與解決方案:https://showmeai.tech/article-detail/331
推薦閱讀
?? 資料分析實戰系列:https://www.showmeai.tech/tutorials/40
?? 機器學習資料分析實戰系列:https://www.showmeai.tech/tutorials/41
?? 深度學習資料分析實戰系列:https://www.showmeai.tech/tutorials/42
?? TensorFlow資料分析實戰系列:https://www.showmeai.tech/tutorials/43
?? PyTorch資料分析實戰系列:https://www.showmeai.tech/tutorials/44
?? NLP實戰資料分析實戰系列:https://www.showmeai.tech/tutorials/45
?? CV實戰資料分析實戰系列:https://www.showmeai.tech/tutorials/46
?? AI 面試題庫系列:https://www.showmeai.tech/tutorials/48
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/540108.html
標籤:Python
上一篇:資料分析之pandas的使用