分布式ID生成方案
朱門酒肉臭,路有凍死骨,
簡介
對于單體專案,主鍵 ID 常用主鍵自動的方式進行設定,但是在分布式系統中,分庫分表之后就不行了,如果還采用簡單資料庫主鍵ID自增的方式,就會出現同一ID在不同資料庫的情況,常見分布式ID生成方案:UUID、號段模式、Redis 實作、雪花演算法(SnowFlake)、滴滴 TinyID、百度 Uidgenerator、美團 Leaf等,
1、UUID
優點
- 性能優異,本地生成ID,不需要進行遠程呼叫,
缺點
- UUID 的無序性,無法保證趨勢遞增,
- UUID 過長,不易存盤,往往用字串表示,作為主鍵建立索引查詢效率低,
2、號段模式
實作思路是從資料庫獲取一個號段范圍,比如 [1,1000],然后生成 1 到 1000 的自增 ID 加載到記憶體中,直到 ID 都用完了,再去資料庫獲取,
1 CREATE TABLE id_generator ( 2 id int(10) NOT NULL, 3 max_id bigint(20) NOT NULL COMMENT '當前最大id', 4 step int(20) NOT NULL COMMENT '號段的步長', 5 biz_type int(20) NOT NULL COMMENT '業務型別', 6 version int(20) NOT NULL COMMENT '版本號 類似MVCC', 7 PRIMARY KEY (`id`) 8 )
再次獲取號段范圍,更改最大值,
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
- 優點:方案成熟、社區使用熱度高如百度 Uidgenerator,美團 Leaf;
- 缺點:分布式ID生成依賴于資料庫,
3、Redis 實作
由于 Redis 單執行緒的特點,可以保證 ID 的唯一性和有序性,可以使用 INCR 和 INCRBY 這樣的自增原子命令實作Redis 分布式 ID ,
優點:Redis基于快取性能搞,而且可以保證唯一性和有序性;
缺點:系統需要引入 Redis 組件,增大系統維護成本和復雜度,并發請求量上來后,就需要集群,并且需要分布式鎖保證只有一個Client拿到鎖生成ID,
4、雪花演算法(SnowFlake)
雪花演算法(Snowflake)是由 Twitter 開源的分布式 ID 生成演算法,結構上:符號位+時間戳+作業行程位+序列號位,一個64bit的整數(8位元組),正好為一個long型別資料,所以 Java 程式中一般使用 Long 型別存盤,
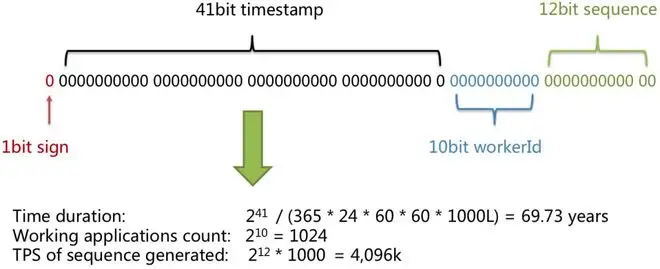
- 1bit sign:第一位占用 1 bit,始終是 0,是一個符號位,不使用;
- 41bit timestamp:第 2 位開始的 41 位是時間戳,41-bit 位可表示 241 個數,每個數代表毫秒,那么雪花演算法可用的時間年限是 (241)/(1000606024365)=69 年的時間,即從1970年開始,雪花演算法能用到2039年;
- 10bit workerId:10-bit 位可表示機器數,即 2^10 = 1024 臺機器,通常不會部署這么多臺機器;
- 12bit sequence:12-bit 位是自增序列,表示每個機房的每個機器每毫秒可以產生2^12-1(4095)個不同的ID序號,
可以自己實作雪花演算法,也可以使用一些封裝好的比如hutool,
1 <dependency> 2 <groupId>cn.hutool</groupId> 3 <artifactId>hutool-core</artifactId> 4 <version>5.1.2</version> 5 </dependency> 6 7 // 傳入機器id和資料中心id,資料范圍為:0~31 8 Snowflake snowflake = IdUtil.createSnowflake(1L, 1L); 9 System.out.println(snowflake.nextId());
優點
- 雪花演算法是目前解決分布式唯一ID的一種很好的解決方案,也是目前市面上使用較多的一種方案,
- 雪花演算法生成的 ID 是趨勢遞增,不依賴資料庫等第三方系統,
- 生成 ID 的效率非常高,穩定性好,可以根據自身業務特性分配 bit 位,比較靈活,
缺點
- 雪花演算法強依賴于機器時鐘,如果機器上時鐘回撥,會導致發號重復或者服務會處于不可用狀態,如果恰巧回退前生成過一些 ID,而時間回退后,生成的 ID 就有可能重復,
5、百度 Uidgenerator
百度 UidGenerator 是百度開源基于 Java 語言實作的唯一 ID 生成器,是在雪花演算法 Snowflake 的基礎上做了一些改進,如:
- 通過消費未來時間克服了雪花演算法的并發限制,UidGenerator提前生成ID并快取在RingBuffer中, 壓測結果顯示,單個實體的QPS能超過600萬,雪花演算法中sequence (13 bits):每秒下的并發序列,13 bits 可支持每秒 8192 個并發,
- 支持自定義 workerId 位數和初始化策略,從而適用于 docker 等虛擬化環境下實體自動重啟、漂移等場景,
6、美團 Leaf
目前主流的分布式ID生成方式大致都是基于資料庫號段模式和雪花演算法(snowflake),而美團(Leaf)剛好同時兼具了這兩種方式,用戶可以同時開啟兩種方式,也可以指定開啟某種方式,能夠根據不同業務場景靈活切換,
7、滴滴 Tinyid
Tinyid 是滴滴用 Java 開發的一款分布式 id 生成系統,基于資料庫號段演算法實作,Tinyid 擴展了 leaf-segment 演算法,支持了多db(master),同時提供了 java-client(sdk) 使 id 生成本地化,獲得了更好的性能與可用性,Tinyid 在滴滴客服部門使用,均通過 tinyid-client 方式接入,每天生成億級別的 id,
使用注意事項
- http 方式訪問時,性能取決于 http server 的能力,網路傳輸速度,
- java-client 方式訪問時,id為本地生成,號段長度(step)越長,qps越大,如果將號段設定足夠大,則qps可達1000w+,只要server有一臺存活,則理論上可用,server全掛,因為client有快取,也可以繼續使用一段時間,
- Tinyid 依賴db,當db不可用時,因為server有快取,所以還可以使用一段時間,如果配置了多個db,則只要有1個db存活,則服務可用,
- Tinyid 不適用場景:類似訂單 id 的業務(因為生成的id大部分是連續的,容易被掃庫、或者測算出訂單量)
朱門酒肉臭
路有凍死骨
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/540272.html
標籤:其他
上一篇:【QT開發問題】使用自定義的QGroupBox,重寫繪圖事件paintEvent后邊框消失的問題
下一篇:Shell 變數知多少?