資料清洗
資料清洗是對一些沒有用的資料進行處理的程序,
很多資料集存在資料缺失、資料格式錯誤、錯誤資料或重復資料的情況,如果要對使資料分析更加準確,就需要對這些沒有用的資料進行處理,
在這個教程中,我們將利用 Pandas包來進行資料清洗,
處理丟失資料
-
有兩種丟失資料:
- None
- np.nan(NaN)
-
兩種丟失資料的區別

-
為什么在資料分析中需要用到的是浮點型別的空而不是物件型別?
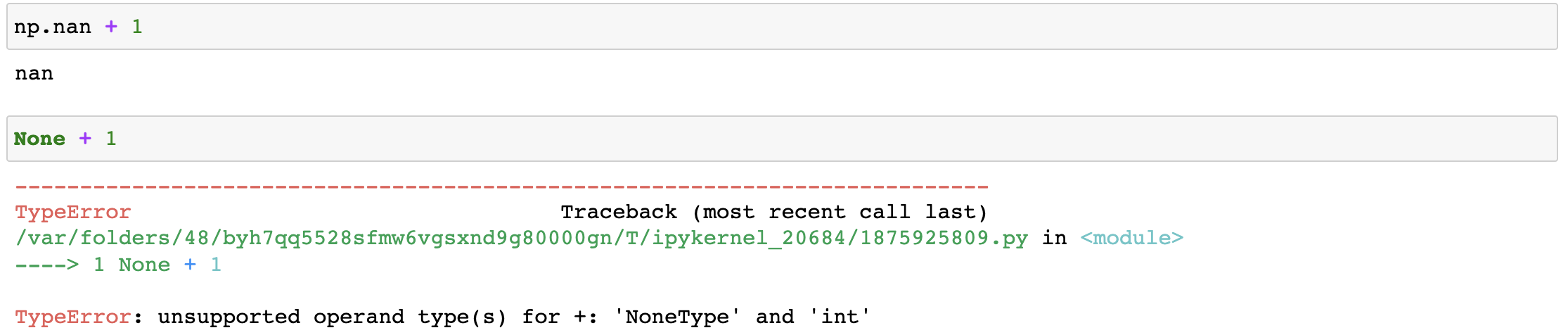
- 資料分析中會常常使用某些形式的運算來處理原始資料,如果原數資料中的空值為NAN的形式,則不會干擾或者中斷運算,
- NAN可以參與運算的
- None是不可以參與運算
-
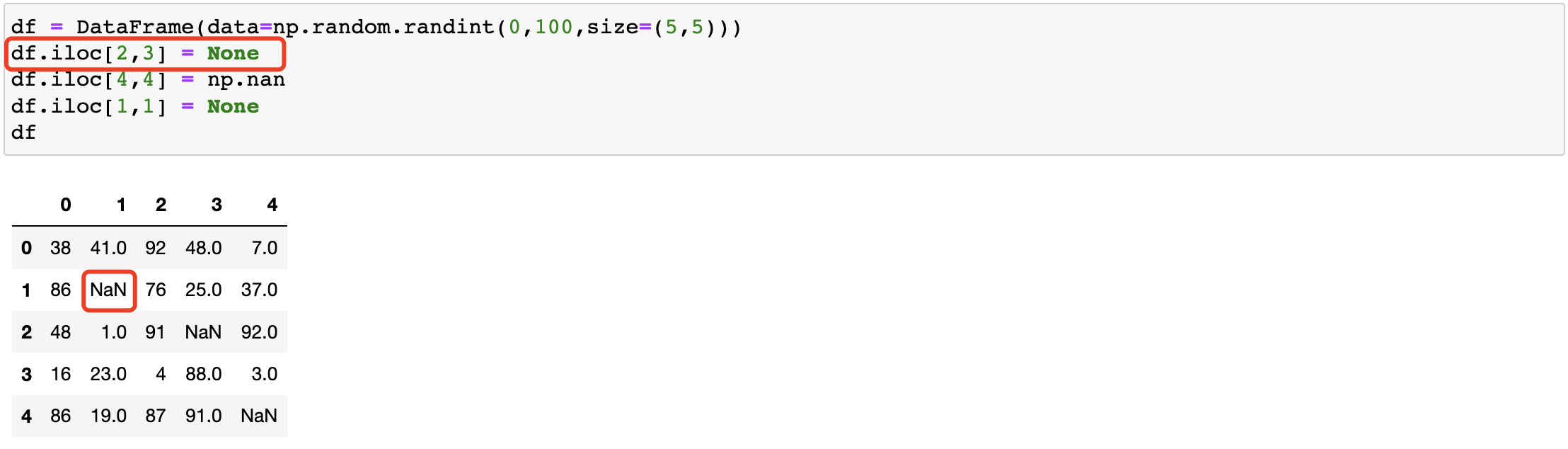
在pandas中如果遇到了None形式的空值則pandas會將其強轉成NAN的形式,
pandas處理空值操作
- isnull
- notnull
- any
- all
- dropna
- fillna
-
方式1:對空值進行過濾(洗掉空所在的行資料)
- 技術:isnull,notnull,any,all
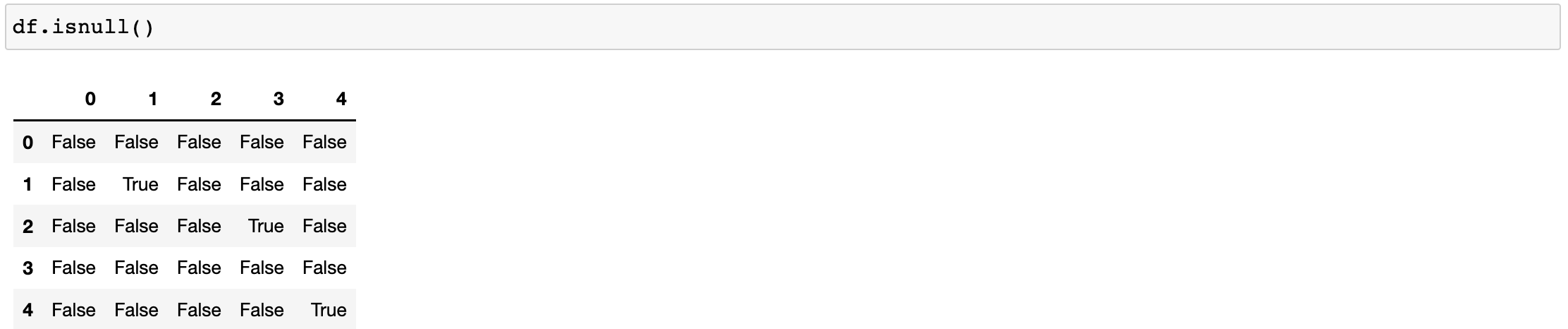
#哪些行中有空值 #any(axis=1)檢測哪些行中存有空值 df.isnull().any(axis=1) #any會作用isnull回傳結果的每一行 #true對應的行就是存有缺失資料的行
df.notnull()
df.notnull().all(axis=0) #all 只要有false,則整體就是false
#將布林值作為源資料的行索引 df.loc[df.notnull().all(axis=1)]
-
方式2:
-
dropna:可以直接將缺失的行或者列進行洗掉

-
對缺失值進行覆寫
- fillna
df.fillna(value=https://www.cnblogs.com/ivanlee717/p/999) #使用指定值將源資料中所有的空值進行填充
#使用空的近鄰值進行填充 #method=ffill向前填充,bfill向后填充 df.fillna(axis=0,method='bfill')
-
-
什么時候用dropna什么時候用fillna
- 盡量使用dropna,如果洗掉成本比較高,則使用fillna
-
使用空值對應列的均值進行空值填充
for col in df.columns: #檢測哪些列中存有空值 if df[col].isnull().sum() > 0:#說明df[col]中存有空值 mean_value = https://www.cnblogs.com/ivanlee717/p/df[col].mean() df[col] = df[col].fillna(value=mean_value)
面試題
- 資料說明:
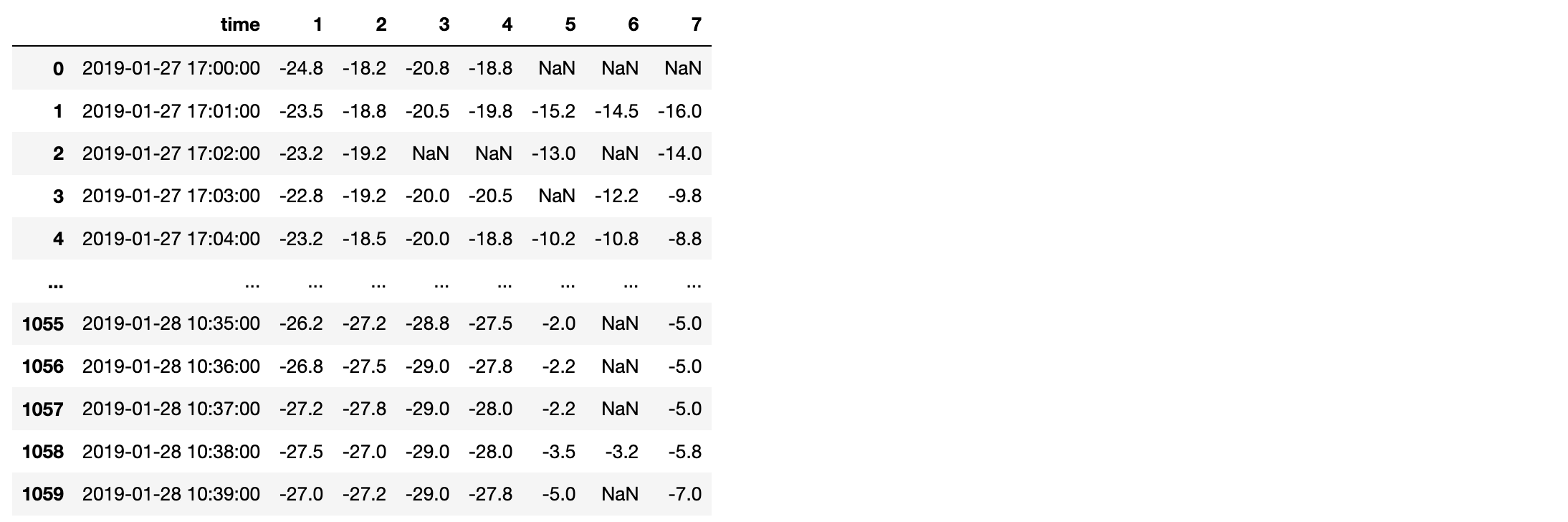
- 資料是1個冷庫的溫度資料,1-7對應7個溫度采集設備,1分鐘采集一次,
- 資料處理目標:
- 用1-4對應的4個必須設備,通過建立冷庫的溫度場關系模型,預估出5-7對應的資料,
- 最后每個冷庫中僅需放置4個設備,取代放置7個設備,
- f(1-4) --> y(5-7)
- 資料處理程序:
- 1、原始資料中有丟幀現象,需要做預處理;
- 2、matplotlib 繪圖;
- 3、建立邏輯回歸模型,
- 無標準答案,按個人理解操作即可,請把自己的操作程序以文字形式簡單描述一下,謝謝配合,
- 測驗資料為testData.xlsx
Data:

- 丟幀預處理:
清洗掉none,none1列df.drop(label=['none','none1'],axis=1)
-
刪掉空值所在的行
#洗掉空對應的行資料 data.dropna(axis=0)
處理重復資料

#檢測哪些行存有重復的資料
df.duplicated(keep='first')

第1行之所以是false,是因為keep保留了第一個出現的資料,但是3,5行就不保留了,如果keep=last,則保留最后一行資料;keep=false則洗掉所有資料
df.drop_duplicates(keep='first')洗掉重復資料

處理例外資料
-
自定義一個1000行3列(A,B,C)取值范圍為0-1的資料源,然后將C列中的值大于其兩倍標準差的例外值進行清洗
df = DataFrame(data=https://www.cnblogs.com/ivanlee717/p/np.random.random(size=(1000,3)),columns=['A','B','C'])
-
判定條件:c值大于本列的方差的2倍,則為例外資料
#制定判定例外值的條件 twice_std = df['C'].std() * 2 twice_stddf['C'] > twice_std --> 例外值所在列 ~df['C'] > twice_std --> 取反操作 df.loc[~(df['C'] > twice_std)] --> 通過定位非例外值索引來獲取正常值
本文來自博客園,作者:ivanlee717,轉載請注明原文鏈接:https://www.cnblogs.com/ivanlee717/p/16993650.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/540337.html
標籤:Python
上一篇:day06-功能實作05