pandas的級聯和合并
級聯操作
pd.concat,pd.append
pandas使用pd.concat函式,與np.concatenate函式類似,只是多了一些引數:
objs
axis=0
keys
join='outer' / 'inner':表示的是級聯的方式,outer會將所有的項進行級聯(忽略匹配和不匹配),而inner只會將匹配的項級聯到一起,不匹配的不級聯
ignore_index=False
-
匹配級聯
df1 = pd.DataFrame(data=https://www.cnblogs.com/ivanlee717/p/np.random.randint(0,100,size=(5,3)),columns=['A','B','C']) df2 = pd.DataFrame(data=https://www.cnblogs.com/ivanlee717/p/np.random.randint(0,100,size=(5,3)),columns=['A','D','C']) pd.concat((df1,df1),axis=1) #行列索引都一致的級聯叫做匹配級聯
-
不匹配級聯
-
不匹配指的是級聯的維度的索引不一致,例如縱向級聯時列索引不一致,橫向級聯時行索引不一致
-
有2種連接方式:
-
外連接:補NaN(默認模式)
pd.concat((df1,df2),axis=0) or pd.concat((df1,df2),axis=1, join='outer')
-
內連接:只連接匹配的項
pd.concat((df1,df2),axis=0,join='inner') #inner直把可以級聯的級聯不能級聯不處理
-
如果想要保留資料的完整性必須使用outer(外連接)
-
append函式的使用
-
-
-
-
append函式的使用
df1.append(df1)
合并操作
- merge與concat的區別在于merge需要依據某一共同列來進行合并
- 使用pd.merge()合并時,會自動根據兩者相同column名稱的那一列,作為key來進行合并,
- 注意每一列元素的順序不要求一致
df1 = DataFrame({'employee':['regina','ivanlee','baby'],
'group':['Accounting','Engineering','Engineering'],
})
df2 = DataFrame({'employee':['regina','ivanlee','baby'],
'hire_date':[2004,2008,2012],
})
pd.merge(df1,df2,on='employee')

一對多合并
df3 = DataFrame({
'employee':['regina','ivanlee'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
pd.merge(df3,df4)#on如果不寫,默認情況下使用兩表中公有的列作為合并條件

多對多合并
df5 = DataFrame({'group':['Accounting','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
how 引數默認是inner,也可以是outer,right,left
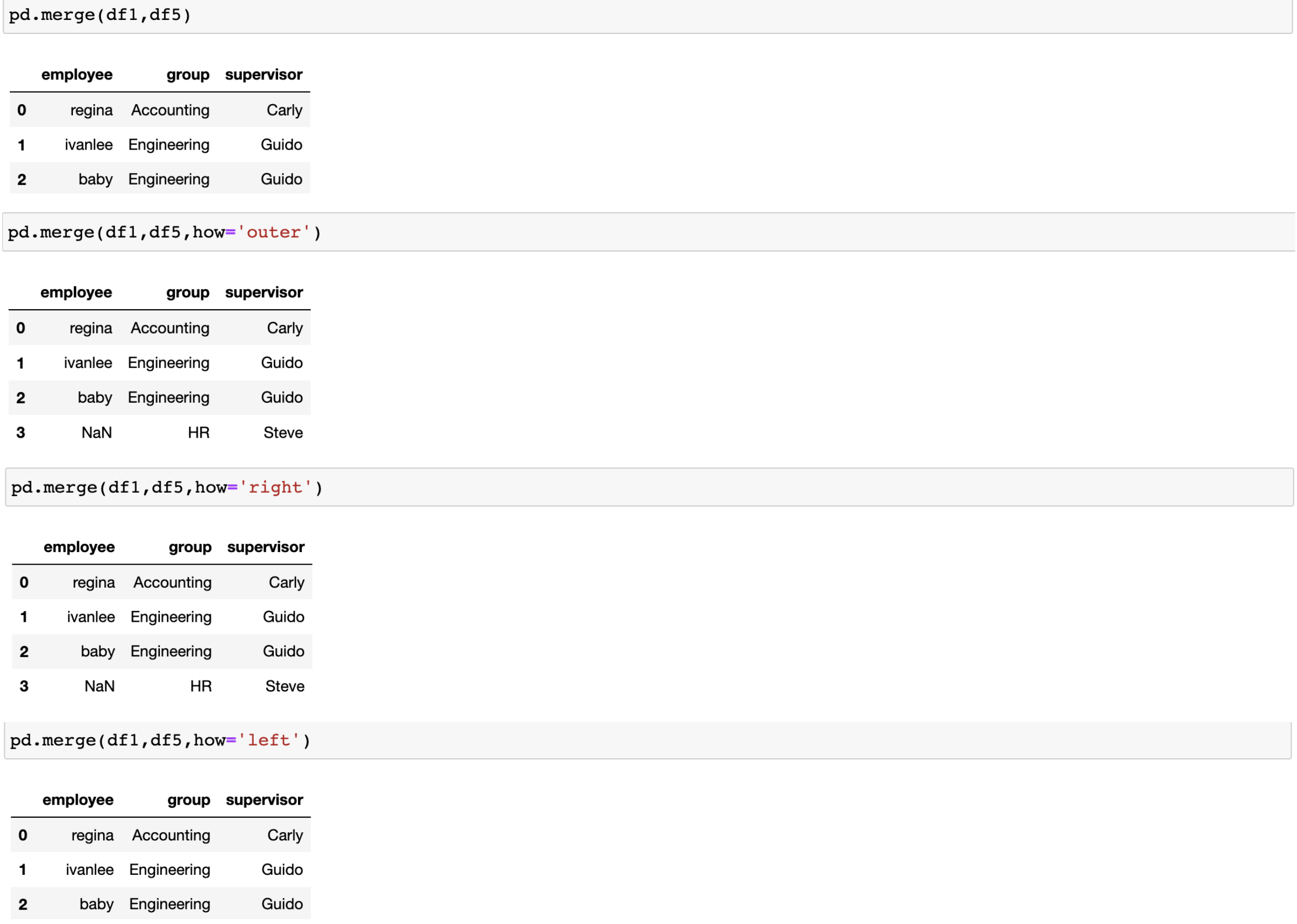
key的規范化
-
當兩張表沒有可進行連接的列時,可使用left_on和right_on手動指定merge中左右兩邊的哪一列列作為連接的列
df5 = DataFrame({'name':['ivanlee','zjr','liyifan'], 'hire_dates':[1998,2016,2007]}) pd.merge(df1,df5,left_on='employee',right_on='name')
內合并與外合并:out取并集 inner取交集
人口分析專案
- 需求:
- 匯入檔案,查看原始資料
- 將人口資料和各州簡稱資料進行合并
- 將合并的資料中重復的abbreviation列進行洗掉
- 查看存在缺失資料的列
- 找到有哪些state/region使得state的值為NaN,進行去重操作
- 為找到的這些state/region的state項補上正確的值,從而去除掉state這一列的所有NaN
- 合并各州面積資料areas
- 我們會發現area(sq.mi)這一列有缺失資料,找出是哪些行
- 去除含有缺失資料的行
- 找出2010年的全民人口資料
- 計算各州的人口密度
- 排序,并找出人口密度最高的州
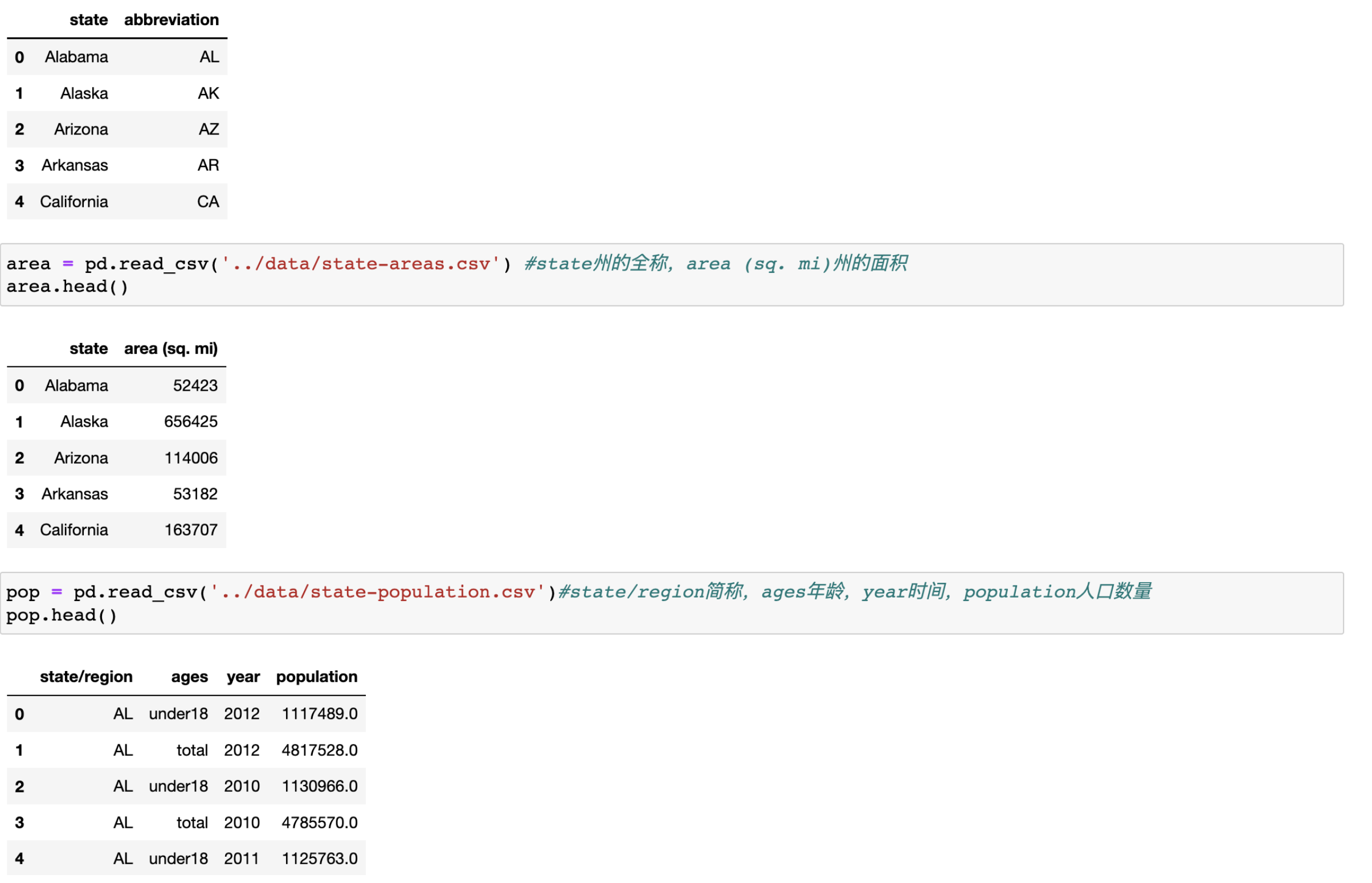
#匯入檔案,查看原始資料
abb = pd.read_csv('../data/state-abbrevs.csv') #state(州的全稱)abbreviation(州的簡稱)
area = pd.read_csv('../data/state-areas.csv') #state州的全稱,area (sq. mi)州的面積
pop = pd.read_csv('../data/state-population.csv')#state/region簡稱,ages年齡,year時間,population人口數量
#將人口資料和各州簡稱資料進行合并
abb_pop = pd.merge(abb,pop,left_on='abbreviation',right_on='state/region',how='outer') 必須保證資料完整
abb_pop.head()

#將合并的資料中重復的abbreviation列進行洗掉
abb_pop.drop(labels='abbreviation',axis=1,inplace=True)
#查看存在缺失資料的列
#方式1:isnull,notll,any,all
abb_pop.isnull().any(axis=0)
#state,population這兩列中是存在空值

#1.將state中的空值定位到
abb_pop['state'].isnull()
#2.將上述的布林值作為源資料的行索引
abb_pop.loc[abb_pop['state'].isnull()]#將state中空對應的行資料取出
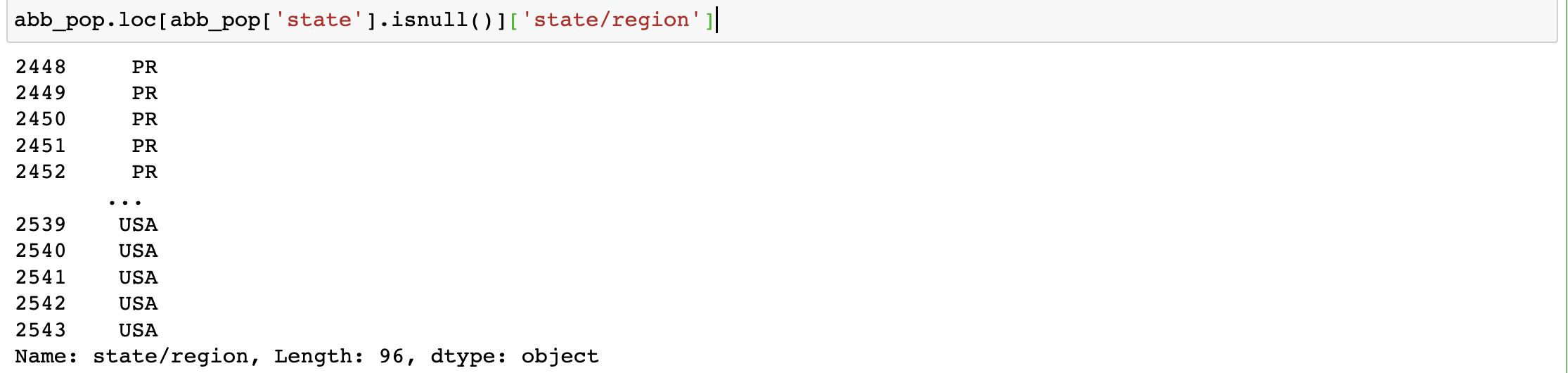
#3.將簡稱取出
abb_pop.loc[abb_pop['state'].isnull()]['state/region']
#4.對簡稱去重
abb_pop.loc[abb_pop['state'].isnull()]['state/region'].unique()
#結論:只有PR和USA對應的全稱資料為空值
#為找到的這些state/region的state項補上正確的值,從而去除掉state這一列的所有NaN
#思考:填充該需求中的空值可不可以使用fillna?
# - 不可以,fillna可以使用空的緊鄰值做填充,fillna(value='https://www.cnblogs.com/ivanlee717/p/xxx')使用指定的值填充空值
# 使用給元素賦值的方式進行填充!
#1.先給USA的全稱對應的空值進行批量賦值
abb_pop.loc[abb_pop['state/region'] == 'USA']#將usa對應的行資料取出
#1.2將USA對應的全稱空對應的行索引取出
indexs = abb_pop.loc[abb_pop['state/region'] == 'USA'].index
abb_pop.iloc[indexs]
abb_pop.loc[indexs,'state'] = 'United States'
#2.可以將PR的全稱進行賦值
abb_pop['state/region'] == 'PR'
abb_pop.loc[abb_pop['state/region'] == 'PR'] #PR對應的行資料
indexs = abb_pop.loc[abb_pop['state/region'] == 'PR'].index
abb_pop.loc[indexs,'state'] = 'PPPRRR'
#合并各州面積資料areas
abb_pop_area = pd.merge(abb_pop,area,how='outer')
#我們會發現area(sq.mi)這一列有缺失資料,找出是哪些行
abb_pop_area['area (sq. mi)'].isnull()
abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()] #空對應的行資料
indexs = abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()].index
#找出2010年的全民人口資料(基于df做條件查詢)
abb_pop_area.query('ages == "total" & year == 2010')
#計算各州的人口密度(人口除以面積)
abb_pop_area['midu'] = abb_pop_area['population'] / abb_pop_area['area (sq. mi)']
abb_pop_area
#排序,并找出人口密度最高的州
abb_pop_area.sort_values(by='midu',axis=0,ascending=False).iloc[0]['state']
替換操作
-
替換操作可以同步作用于Series和DataFrame中
-
單值替換
- 普通替換: 替換所有符合要求的元素:to_replace=15,valuhttps://www.cnblogs.com/ivanlee717/p/e='e'
- 按列指定單值替換: to_replace={列標簽:替換值} https://www.cnblogs.com/ivanlee717/p/value='value'
-
多值替換
- 串列替換:
to_replace=[] value=https://www.cnblogs.com/ivanlee717/p/[] - 字典替換(推薦)
to_replace={to_replace:value,to_replace:value}
- 串列替換:

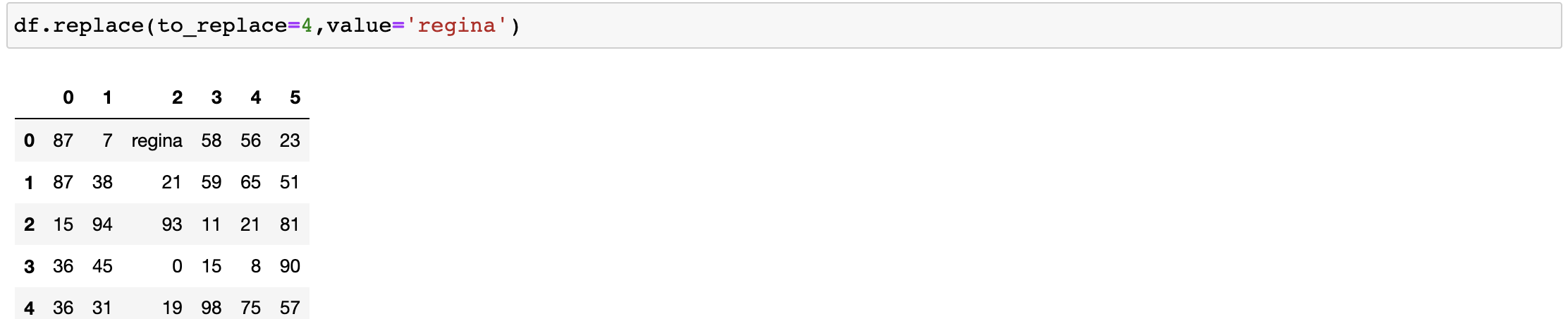
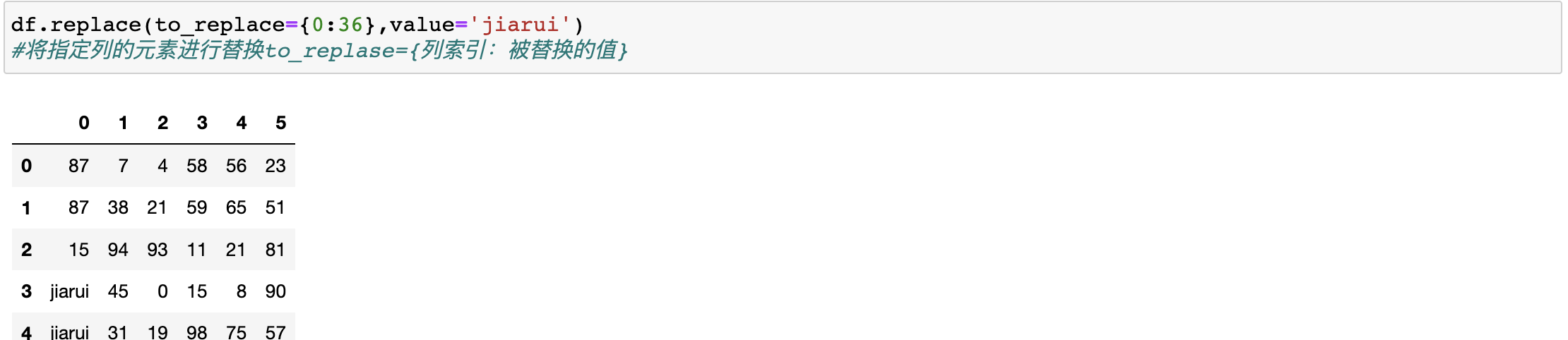
我們要替換某列當中的數值
df.replace(to_replace={0,36},value='https://www.cnblogs.com/ivanlee717/p/jiarui')
#將指定列的元素進行替換to_replase={列索引:被替換的值}
映射操作
-
概念:創建一個映射關系串列,把values元素和一個特定的標簽或者字串系結(給一個元素值提供不同的表現形式)
-
創建一個df,兩列分別是姓名和薪資,然后給其名字起對應的英文名
dic = {
'name':['regina','ivanlee','regina'],
'salary':[15000,20000,15000]
}
df = DataFrame(data=https://www.cnblogs.com/ivanlee717/p/dic)

先指定給regina映射為zhangjiarui,首先建立一張映射關系表
#映射關系表
dic = {
'regina':'zhangjiarui',
'ivanlee':'liyifan'
}
df['e_name'] = df['name'].map(dic)

map是Series的方法,只能被Series呼叫
運算工具
-
超過3000部分的錢繳納50%的稅,計算每個人的稅后薪資
#該函式是我們指定的一個運演算法則 def after_sal(s):#計算s對應的稅后薪資 return s - (s-3000)*0.5 df['after_sal'] = df['salary'].map(after_sal)#可以將df['salary']這個Series中每一個元素(薪資)作為引數傳遞給s
排序實作的隨機抽樣
- take()
- np.random.permutation()
df = DataFrame(data=https://www.cnblogs.com/ivanlee717/p/np.random.randint(0,100,size=(100,3)),columns=['A','B','C'])
#生成亂序的隨機序列
np.random.permutation(10)
#將原始資料打亂
df.take([2,0,1],axis=1)
df.take(np.random.permutation(3),axis=1)
資料的分類處理
- 資料分類處理的核心:
- groupby()函式
- groups屬性查看分組情況
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]})

#想要水果的種類進行分析
df.groupby(by='item')
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7fac66bd1b20>
#查看詳細的分組情況
df.groupby(by='item').groups

-
分組聚合
#計算出每一種水果的平均價格 df.groupby(by='item')['price'].mean() out: item Apple 3.00 Banana 2.75 Orange 3.50 Name: price, dtype: float64#計算每一種顏色對應水果的平均重量 df.groupby(by='color')['weight'].mean() out: color green 31.333333 red 12.000000 yellow 35.000000 Name: weight, dtype: float64dic = df.groupby(by='color')['weight'].mean().to_dict() #將計算出的平均重量匯總到源資料 df['mean_w'] = df['color'].map(dic)
高級資料聚合
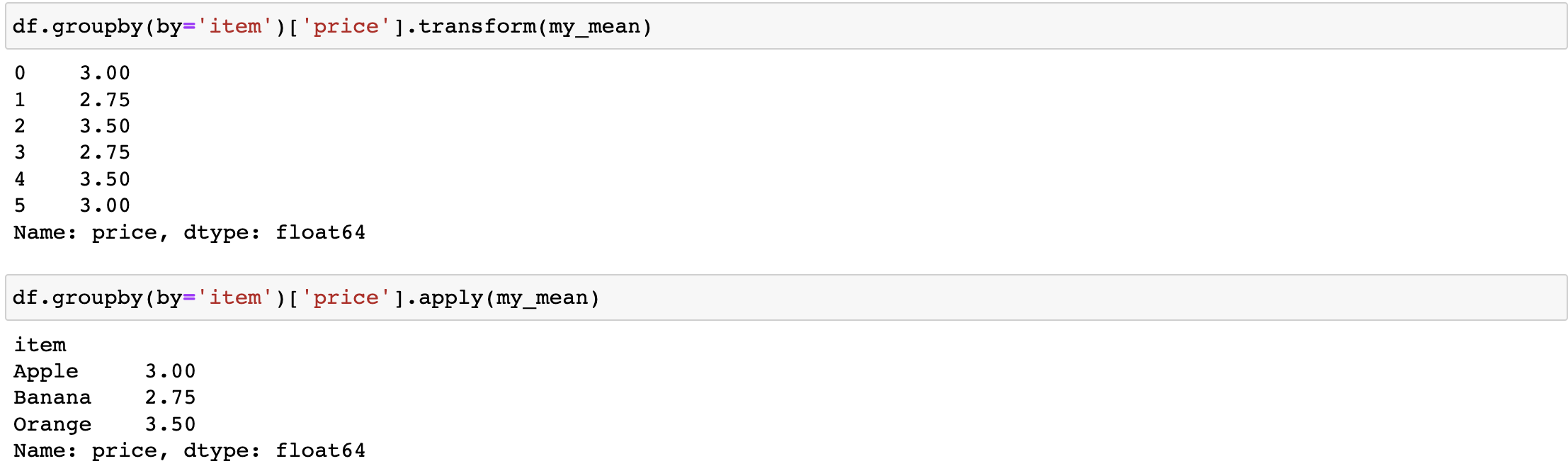
- 使用groupby分組后,也可以使用transform和apply提供自定義函式實作更多的運算
df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)- transform和apply都會進行運算,在transform或者apply中傳入函式即可
- transform和apply也可以傳入一個lambda運算式
def my_mean(s):
m_sum = 0
for i in s:
m_sum += i
return m_sum / len(s)
可以通過自定義的方式設計一個聚合操作
df.groupby(by='item')['price'].transform(my_mean) #經過映射
df.groupby(by='item')['price'].apply(my_mean) #不經過映射
資料加載
-
讀取type-.txt檔案資料
 第一行被認成了列索引
第一行被認成了列索引 -
將檔案中每一個詞作為元素存放在DataFrame中
pd.read_csv('../data/type-.txt',header=None,sep='-') 原始的第一句話就不再是列索引
-
讀取資料庫中的資料
#連接資料庫,獲取連接物件 import sqlite3 as sqlite3 conn = sqlite3.connect('../data/weather_2012.sqlite') #讀取庫表中的資料值 sql_df=pd.read_sql('select * from weather_2012',conn)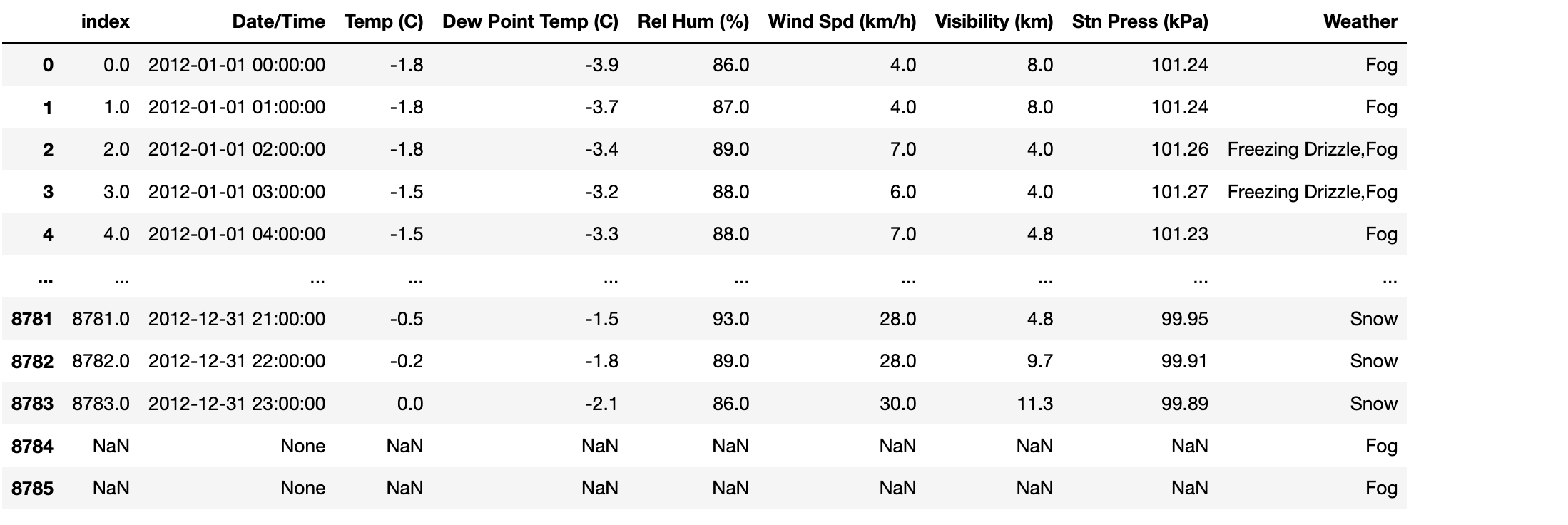
#將一個df中的資料值寫入存盤到db df.to_sql('sql_data456',conn)
透視表
-
透視表是一種可以對資料動態排布并且分類匯總的表格格式,或許大多數人都在Excel使用過資料透視表,也體會到它的強大功能,而在pandas中它被稱作pivot_table,
-
透視表的優點:
- 靈活性高,可以隨意定制你的分析計算要求
- 脈絡清晰易于理解資料
- 操作性強,報表神器
pivot_table有四個最重要的引數index、values、columns、aggfunc
-
index引數:分類匯總的分類條件
- 每個pivot_table必須擁有一個index,如果想查看對陣每個隊伍的得分則需要對每一個隊進行分類并計算其各類得分的平均值:
-
想看看對陣同一對手在不同主客場下的資料,分類條件為對手和主客場
df.pivot_table(index=['對手','主客場'])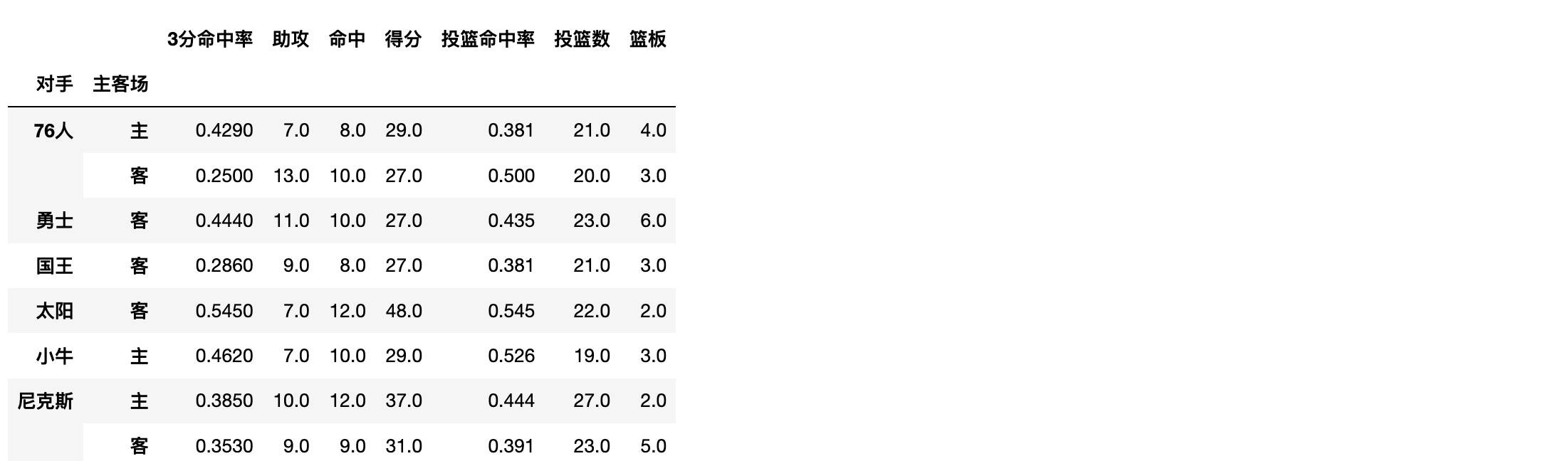
-
values引數:需要對計算的資料進行篩選
-
如果我們只需要在主客場和不同勝負情況下的得分、籃板與助攻三項資料:
df.pivot_table(index=['主客場','勝負'],values=['得分','籃板','助攻'])
-
-
Aggfunc引數:設定我們對資料聚合時進行的函式操作
- 當我們未設定aggfunc時,它默認aggfunc='mean'計算均值,
- 還想獲得主客場和不同勝負情況下的總得分、總籃板、總助攻時:
df.pivot_table(index=['主客場','勝負'],values=['得分','籃板','助攻'],aggfunc='sum')

-
Columns:可以設定列層次欄位
- 對values欄位進行分類
#獲取所有隊主客場的總得分 df.pivot_table(index='主客場',values='得分',aggfunc='sum')
#獲取每個隊主客場的總得分(在總得分的基礎上又進行了對手的分類) df.pivot_table(index='主客場',values='得分',columns='對手',aggfunc='sum',fill_value=https://www.cnblogs.com/ivanlee717/p/none)
交叉表
- 是一種用于計算分組的特殊透視圖,對資料進行匯總
pd.crosstab(index,colums)- index:分組資料,交叉表的行索引
- columns:交叉表的列索引

#求出不同性別的抽煙人數
pd.crosstab(df.smoke,df.sex)

本文來自博客園,作者:ivanlee717,轉載請注明原文鏈接:https://www.cnblogs.com/ivanlee717/p/16995432.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/540347.html
標籤:Python