
大家好,又見面了,
本文是筆者作為掘金技術社區簽約作者的身份輸出的快取專欄系列內容,將會通過系列專題,講清楚快取的方方面面,如果感興趣,歡迎關注以獲取后續更新,
上一篇文章中,我們聊了下Caffeine的同步、異步的資料回源方式,本篇文章我們再一起研討下Caffeine的多種不同的資料淘汰驅逐機制,以及對應的實際使用,

Caffeine的異步淘汰清理機制
在惰性洗掉實作機制這邊,Caffeine做了一些改進優化以提升在并發場景下的性能表現,我們可以和Guava Cache的基于容量大小的淘汰處理做個對比,
當限制了Guava Cache最大容量之后,有新的記錄寫入超過了總大小,會理解觸發資料淘汰策略,然后騰出空間給新的記錄寫入,比如下面這段邏輯:
public static void main(String[] args) {
Cache<String, String> cache = CacheBuilder.newBuilder()
.maximumSize(1)
.removalListener(notification -> System.out.println(notification.getKey() + "被移除,原因:" + notification.getCause()))
.build();
cache.put("key1", "value1");
System.out.println("key1寫入后,當前快取內的keys:" + cache.asMap().keySet());
cache.put("key2", "value1");
System.out.println("key2寫入后,當前快取內的keys:" + cache.asMap().keySet());
}
其運行后的結果顯示如下,可以很明顯的看出,超出容量之后繼續寫入,會在寫入前先執行快取移除操作,
key1寫入后,當前快取內的keys:[key1]
key1被移除,原因:SIZE
key2寫入后,當前快取內的keys:[key2]
同樣地,我們看下使用Caffeine實作一個限制容量大小的快取物件的處理表現,代碼如下:
public static void main(String[] args) {
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1)
.removalListener((key, value, cause) -> System.out.println(key + "被移除,原因:" + cause))
.build();
cache.put("key1", "value1");
System.out.println("key1寫入后,當前快取內的keys:" + cache.asMap().keySet());
cache.put("key2", "value1");
System.out.println("key2寫入后,當前快取內的keys:" + cache.asMap().keySet());
}
運行這段代碼,會發現Caffeine的容量限制功能似乎“失靈”了!從輸出結果看并沒有限制住:
key1寫入后,當前快取內的keys:[key1]
key2寫入后,當前快取內的keys:[key1, key2]
什么原因呢?
Caffeine為了提升讀寫操作的并發效率而將資料淘汰清理操作改為了異步處理,而異步處理時會有微小的延時,由此導致了上述看到的容量控制“失靈”現象,為了證實這一點,我們對上述的測驗代碼稍作修改,列印下呼叫執行緒與資料淘汰清理執行緒的執行緒ID,并且最后添加一個sleep等待操作:
public static void main(String[] args) throws Exception {
System.out.println("當前主執行緒:" + Thread.currentThread().getId());
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1)
.removalListener((key, value, cause) ->
System.out.println("資料淘汰執行執行緒:" + Thread.currentThread().getId()
+ "," + key + "被移除,原因:" + cause))
.build();
cache.put("key1", "value1");
System.out.println("key1寫入后,當前快取內的keys:" + cache.asMap().keySe());
cache.put("key2", "value1");
Thread.sleep(1000L); // 等待一段時間時間,等待異步清理操作完成
System.out.println("key2寫入后,當前快取內的keys:" + cache.asMap().keySet());
}
再次執行上述測驗代碼,發現結果變的符合預期了,也可以看出Caffeine的確是另起了獨立執行緒去執行資料淘汰操作的,
當前主執行緒:1
key1寫入后,當前快取內的keys:[key1]
資料淘汰執行執行緒:13,key1被移除,原因:SIZE
key2寫入后,當前快取內的keys:[key2]
深扒一下原始碼的實作,可以發現Caffeine在讀寫操作時會使用獨立執行緒池執行對應的清理任務,如下圖中的呼叫鏈執行鏈路 —— 這也證實了上面我們的分析,
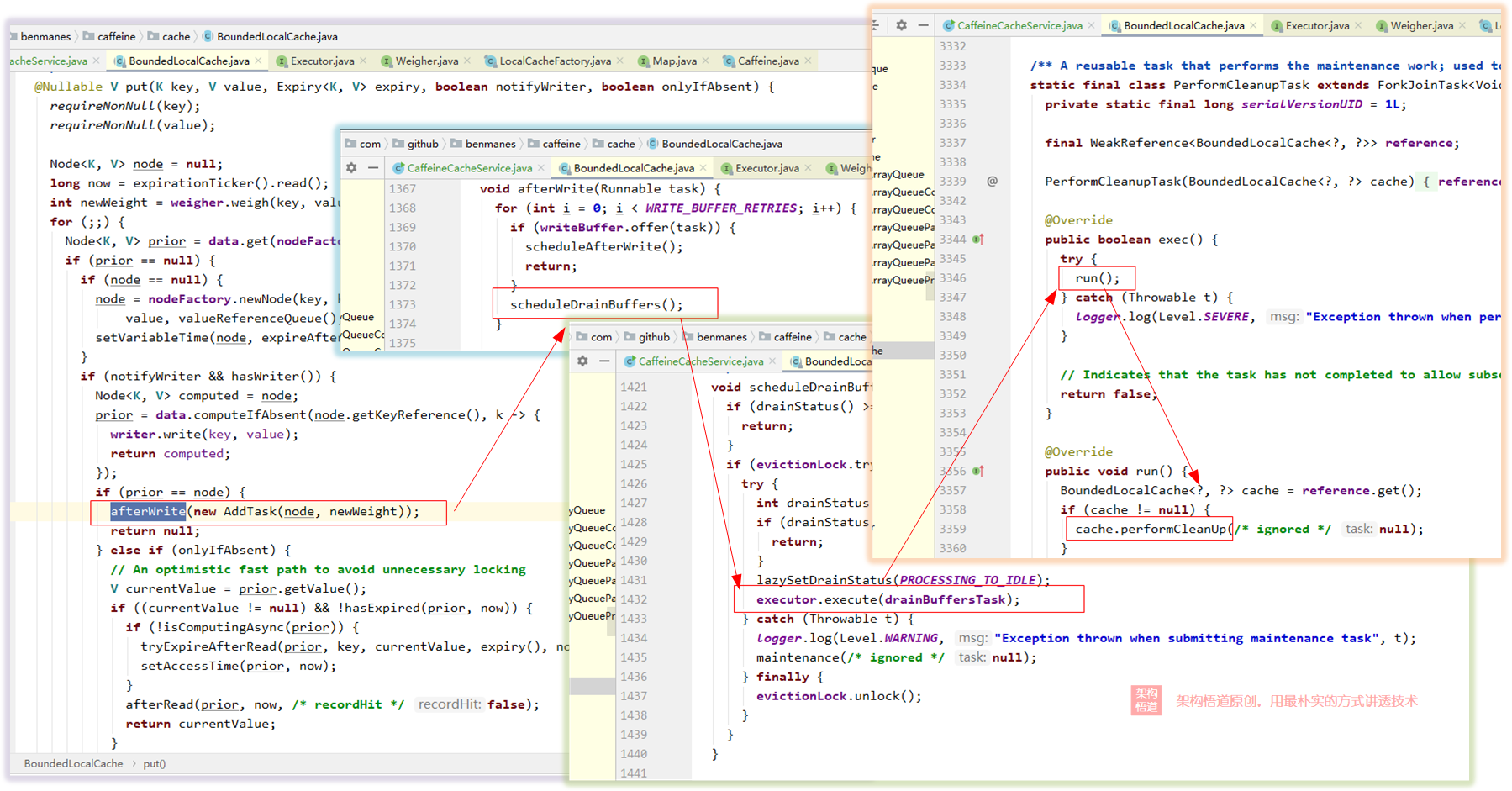
所以,嚴格意義來說,Caffeine的大小容量限制并不能夠保證完全精準的小于設定的值,會存在短暫的誤差,但是作為一個以高并發吞吐量為優先考量點的組件而言,這一點點的誤差也是可以接受的,關于這一點,如果閱讀原始碼仔細點的小伙伴其實也可以發現在很多場景的注釋中,Caffeine也都會有明確的說明,比如看下面這段從原始碼中摘抄的描述,就清晰的寫著“如果有同步執行的插入或者移除操作,實際的元素數量可能會出現差異”,
public interface Cache<K, V> {
/**
* Returns the approximate number of entries in this cache. The value returned is an estimate; the
* actual count may differ if there are concurrent insertions or removals, or if some entries are
* pending removal due to expiration or weak/soft reference collection. In the case of stale
* entries this inaccuracy can be mitigated by performing a {@link #cleanUp()} first.
*
* @return the estimated number of mappings
*/
@NonNegative
long estimatedSize();
// 省略其余內容...
}
同樣道理,不管是基于大小、還是基于過期時間或基于參考的資料淘汰策略,由于資料淘汰處理是異步進行的,都會存在短暫的不夠精確的情況,
多種淘汰機制
上面提到并演示了Caffeine基于整體容量進行的資料驅逐策略,除了基于容量大小之外,Caffeine還支持基于時間與基于參考等方式來進行資料驅逐處理,
基于時間
Caffine支持基于時間進行資料的淘汰驅逐處理,這部分的能力與Guava Cache相同,支持根據記錄創建時間以及訪問時間兩個維度進行處理,
資料的過期時間在創建快取物件的時候進行指定,Caffeine在創建快取物件的時候提供了3種設定過期策略的方法,
| 方式 | 具體說明 |
|---|---|
| expireAfterWrite | 基于創建時間進行過期處理 |
| expireAfterAccess | 基于最后訪問時間進行過期處理 |
| expireAfter | 基于個性化定制的邏輯來實作過期處理(可以定制基于新增、讀取、更新等場景的過期策略,甚至支持為不同記錄指定不同過期時間) |
下面逐個看下,
expireAfterWrite
expireAfterWrite用于指定資料創建之后多久會過期,使用方式舉例如下:
Cache<String, User> userCache =
Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
.build();
userCache.put("123", new User("123", "張三"));
當記錄被寫入快取之后達到指定的時間之后,就會被過期淘汰(惰性洗掉,并不會立即從記憶體中移除,而是在下一次操作的時候觸發清理操作),
expireAfterAccess
expireAfterAccess用于指定快取記錄多久沒有被訪問之后就會過期,使用方式與expireAfterWrite類似:
Cache<String, User> userCache =
Caffeine.newBuilder()
.expireAfterAccess(1, TimeUnit.SECONDS)
.build();
userCache.get("123", s -> userDao.getUser(s));
這種是基于最后一次訪問時間來計算資料是否過期,如果一個資料一直被訪問,則其就不會過期,比較適用于熱點資料的存盤場景,可以保證較高的快取命中率,同樣地,資料過期時也不會被立即從記憶體中移除,而是基于惰性洗掉機制進行處理,
expireAfter
上面兩種設定過期時間的策略與Guava Cache是相似的,為了提供更為靈活的過期時間設定能力,Caffeine提供了一種全新的的過期時間設定方式,也即這里要介紹的expireAfter方法,其支持傳入一個自定義的Expiry物件,自行實作資料的過期策略,甚至是針對不同的記錄來定制不同的過期時間,
先看下Expiry介面中需要實作的三個方法:
| 方法名稱 | 含義說明 |
|---|---|
| expireAfterCreate | 指定一個過期時間,從記錄創建的時候開始計時,超過指定的時間之后就過期淘汰,效果類似expireAfterWrite,但是支持更靈活的定制邏輯, |
| expireAfterUpdate | 指定一個過期時間,從記錄最后一次被更新的時候開始計時,超過指定的時間之后就過期,每次執行更新操作之后,都會重新計算過期時間, |
| expireAfterRead | 指定一個過期時間,從記錄最后一次被訪問的時候開始計時,超過指定時間之后就過期,效果類似expireAfterAccess,但是支持更高級的定制邏輯, |
比如下面的代碼中,定制了expireAfterCreate方法的邏輯,根據快取key來決定過期時間,如果key以字母A開頭則設定1s過期,否則設定2s過期:
public static void main(String[] args) {
try {
LoadingCache<String, User> userCache = Caffeine.newBuilder()
.removalListener((key, value, cause) -> {
System.out.println(key + "移除,原因:" + cause);
})
.expireAfter(new Expiry<String, User>() {
@Override
public long expireAfterCreate(@NonNull String key, @NonNullUser value, long currentTime) {
if (key.startsWith("A")) {
return TimeUnit.SECONDS.toNanos(1);
} else {
return TimeUnit.SECONDS.toNanos(2);
}
}
@Override
public long expireAfterUpdate(@NonNull String key, @NonNullUser value, long currentTime,
@NonNegative longcurrentDuration) {
return Long.MAX_VALUE;
}
@Override
public long expireAfterRead(@NonNull String key, @NonNull Uservalue, long currentTime,
@NonNegative long currentDuration){
return Long.MAX_VALUE;
}
})
.build(key -> userDao.getUser(key));
userCache.put("123", new User("123", "123"));
userCache.put("A123", new User("A123", "A123"));
Thread.sleep(1100L);
System.out.println(userCache.get("123"));
System.out.println(userCache.get("A123"));
} catch (Exception e) {
e.printStackTrace();
}
}
執行代碼進行測驗,可以發現,不同的key擁有了不同的過期時間:
User(userName=123, userId=123, departmentId=null)
A123移除,原因:EXPIRED
User(userName=A123, userId=A123, departmentId=null)
除了根據key來定制不同的過期時間,也可以根據value的內容來指定不同的過期時間策略,也可以同時定制上述三個方法,搭配來實作更復雜的過期策略,
按照這種方式來定時過期時間的時候需要注意一點,如果不需要設定某一維度的過期策略的時候,需要將對應實作方法的回傳值設定為一個非常大的數值,比如可以像上述示例代碼中一樣,指定為Long.MAX_VALUE值,
基于大小
除了前面提到的基于訪問時間或者創建時間來執行資料過期淘汰的方式之外,Caffeine還支持針對快取總體容量大小進行限制,如果容量滿的時候,基于W-TinyLFU演算法,淘汰最不常被使用的資料,騰出空間給新的記錄寫入,
Caffeine支持按照Size(記錄條數)或者按照Weighter(記錄權重)值進行總體容量的限制,關于Size和Weighter的區別,之前的文章中有介紹過,如果不清楚的小伙伴們可以查看下《重新認識下JVM級別的本地快取框架Guava Cache(2)——深入解讀其容量限制與資料淘汰策略》,
maximumSize
在創建Caffeine快取物件的時候,可以通過maximumSize來指定允許快取的最大條數,
比如下面這段代碼:
Cache<Integer, String> cache = Caffeine.newBuilder()
.maximumSize(1000L) // 限制最大快取條數
.build();
maximumWeight
在創建Caffeine快取物件的時候,可以通過maximumWeight與weighter組合的方式,指定按照權重進行限制快取總容量,比如一個字串value值的快取場景下,我們可以根據字串的長度來計算權重值,最后根據總權重大小來限制容量,
代碼示意如下:
Cache<Integer, String> cache = Caffeine.newBuilder()
.maximumWeight(1000L) // 限制最大權重值
.weigher((key, value) -> (String.valueOf(value).length() / 1000) + 1)
.build();
使用注意點
需要注意一點:如果創建的時候指定了weighter,則必須同時指定maximumWeight值,如果不指定、或者指定了maximumSize,會報錯(這一點與Guava Cache一致):
java.lang.IllegalStateException: weigher requires maximumWeight
at com.github.benmanes.caffeine.cache.Caffeine.requireState(Caffeine.java:201)
at com.github.benmanes.caffeine.cache.Caffeine.requireWeightWithWeigher(Caffeine.java:1215)
at com.github.benmanes.caffeine.cache.Caffeine.build(Caffeine.java:1099)
at com.veezean.skills.cache.caffeine.CaffeineCacheService.main(CaffeineCacheService.java:254)
基于參考
基于參考回收的策略,核心是利用JVM虛擬機的GC機制來達到資料清理的目的,當一個物件不再被參考的時候,JVM會選擇在適當的時候將其回收,Caffeine支持三種不同的基于參考的回收方法:
| 方法 | 具體說明 |
|---|---|
| weakKeys | 采用弱參考方式存盤key值內容,當key物件不再被參考的時候,由GC進行回收 |
| weakValues | 采用弱參考方式存盤value值內容,當value物件不再被參考的時候,由GC進行回收 |
| softValues | 采用軟參考方式存盤value值內容,當記憶體容量滿時基于LRU策略進行回收 |
下面逐個介紹下,
weakKeys
默認情況下,我們創建出一個Caffeine快取物件并寫入key-value映射資料時,key和value都是以強參考的方式存盤的,而使用weakKeys可以指定將快取中的key值以弱參考(WeakReference)的方式進行存盤,這樣一來,如果程式運行時沒有其它地方使用或者依賴此快取值的時候,該條記錄就可能會被GC回收掉,
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.weakKeys()
.build(key -> userDao.getUser(key));
小伙伴們應該都有個基本的認知,就是兩個物件進行比較是否相等的時候,要使用equals方法而非==,而且很多時候我們會主動去覆寫hashCode方法與equals方法來指定兩個物件的相等判斷邏輯,但是基于參考的資料淘汰策略,關注的是參考地址值而非實際內容值,也即一旦使用weakKeys指定了基于參考方式回收,那么查詢的時候將只能是使用同一個key物件(記憶體地址相同)才能夠查詢到資料,因為這種情況下查詢的時候,使用的是==判斷是否為同一個key,
看下面的例子:
public static void main(String[] args) {
Cache<String, String> cache = Caffeine.newBuilder()
.weakKeys()
.build();
String key1 = "123";
cache.put(key1, "value1");
System.out.println(cache.getIfPresent(key1));
String key2 = new String("123");
System.out.println("key1.equals(key2) : " + key1.equals(key2));
System.out.println("key1==key2 : " + (key1==key2));
System.out.println(cache.getIfPresent(key2));
}
執行之后,會發現使用存入時的key1進行查詢的時候是可以查詢到資料的,而使用key2去查詢的時候并沒有查詢到記錄,雖然key1與key2的值都是字串123!
value1
key1.equals(key2) : true
key1==key2 : false
null
在實際使用的時候,這一點務必需要注意,對于新手而言,很容易踩進坑里,
weakValues
與weakKeys類似,我們可以在創建快取物件的時候使用weakValues指定將value值以弱參考的方式存盤到快取中,這樣當這條快取記錄的物件不再被參考依賴的時候,就會被JVM在適當的時候回收釋放掉,
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.weakValues()
.build(key -> userDao.getUser(key));
實際使用的時候需要注意weakValues不支持在AsyncLoadingCache中使用,比如下面的代碼:
public static void main(String[] args) {
AsyncLoadingCache<String, User> cache = Caffeine.newBuilder()
.weakValues()
.buildAsync(key -> userDao.getUser(key));
}
啟動運行的時候,就會報錯:
Exception in thread "main" java.lang.IllegalStateException: Weak or soft values cannot be combined with AsyncLoadingCache
at com.github.benmanes.caffeine.cache.Caffeine.requireState(Caffeine.java:201)
at com.github.benmanes.caffeine.cache.Caffeine.buildAsync(Caffeine.java:1192)
at com.github.benmanes.caffeine.cache.Caffeine.buildAsync(Caffeine.java:1167)
at com.veezean.skills.cache.caffeine.CaffeineCacheService.main(CaffeineCacheService.java:297)
當然咯,很多時候也可以將weakKeys與weakValues組合起來使用,這樣可以獲得到兩種能力的綜合加成,
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(key -> userDao.getUser(key));
softValues
softValues是指將快取內容值以軟參考的方式存盤在快取容器中,當記憶體容量滿的時候Caffeine會以LRU(least-recently-used,最近最少使用)順序進行資料淘汰回收,對比下其與weakValues的差異:
| 方式 | 具體描述 |
|---|---|
| weakValues | 弱參考方式存盤,一旦不再被參考,則會被GC回收 |
| softValues | 軟參考方式存盤,不會被GC回收,但是在記憶體容量滿的時候,會基于LRU策略資料回收 |
具體使用的時候,可以在創建快取物件的時候進行指定基于軟參考方式資料淘汰:
LoadingCache<String, User> loadingCache = Caffeine.newBuilder()
.softValues()
.build(key -> userDao.getUser(key));
與weakValues一樣,需要注意softValues也不支持在AsyncLoadingCache中使用,此外,還需要注意softValues與weakValues兩者也不可以一起使用,
public static void main(String[] args) {
LoadingCache<String, User> cache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.softValues()
.build(key -> userDao.getUser(key));
}
啟動運行的時候,也會報錯:
Exception in thread "main" java.lang.IllegalStateException: Value strength was already set to WEAK
at com.github.benmanes.caffeine.cache.Caffeine.requireState(Caffeine.java:201)
at com.github.benmanes.caffeine.cache.Caffeine.softValues(Caffeine.java:572)
at com.veezean.skills.cache.caffeine.CaffeineCacheService.main(CaffeineCacheService.java:297)
小結回顧
好啦,關于Caffeine Cache的資料淘汰驅逐策略的實作原理與使用方式的闡述,就介紹到這里了,至此呢,關于Caffeine相關的內容就全部結束了,通過與Caffeine相關的這三篇文章,我們介紹完了Caffeine的整體情況、與Guava Cache相比的改進點、Caffeine的專案中使用,以及Caffeine在資料回源、資料驅逐等方面的展開探討,關于Caffeine Cache,你是否有自己的一些想法與見解呢?歡迎評論區一起交流下,期待和各位小伙伴們一起切磋、共同成長,
說起JAVA的本地快取,除了此前提及的Guava Cache和這里介紹的Caffeine,還有一個同樣無法被忽視的存在 —— Ehcache!作為被Hibernate選中的默認快取實作框架,它究竟有什么魅力?它與Caffeine又有啥區別呢?接下來的文章中,我們就一起來認識下Ehcache,嘗試找尋出答案,
?? 補充說明1 :
本文屬于《深入理解快取原理與實戰設計》系列專欄的內容之一,該專欄圍繞快取這個宏大命題進行展開闡述,全方位、系統性地深度剖析各種快取實作策略與原理、以及快取的各種用法、各種問題應對策略,并一起探討下快取設計的哲學,
如果有興趣,也歡迎關注此專欄,
?? 補充說明2 :
- 關于本文中涉及的演示代碼的完整示例,我已經整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點贊 + 關注讓我感受到您的支持,也可以關注下我的公眾號【架構悟道】,獲取更及時的更新,
期待與你一起探討,一起成長為更好的自己,

本文來自博客園,作者:架構悟道,歡迎關注公眾號[架構悟道]持續獲取更多干貨,轉載請注明原文鏈接:https://www.cnblogs.com/softwarearch/p/16927947.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/540577.html
標籤:Java
下一篇:LeetCode刷題第七周