C++初探索
前言
C++ 和 C 的區別主要在8個方面:
- 輸入和輸出
- 參考
- inline函式
- 函式默認值
- 函式多載
- 模板函式
- new 和 delete
- namespace
我僅對印象不深的地方做了總結,
目錄
- C++初探索
- 前言
- 一、參考初探索
- 1.參考的定義與區別
- 2.參考的要求
- 3.參考與指標的區別
- 4.常參考
- 5.何時使用參考
- 二、inline行內函式
- 1.行內函式的定義
- 2.行內函式的處理流程
- 3.行內函式與三者的區別
- 3.1 與普通函式的區別
- 3.2 與static函式的區別
- 3.3 與宏定義的區別
- 4.僅realese版本才會產生行內
- 5.inline函式使用的限制
- 三、函式的多載
- 四、函式模板
- 五、new和malloc
- 總結
一、參考初探索
1.參考的定義與區別
定義:型別& 參考變數的名稱 = 變數名稱
'&' 不是取地址符嗎,怎么又成為參考了呢?下面將常見的 '&' 做一個區分:
C中的 '&'
c = a && b; //此處 && 是 邏輯與
c = a & b; //此處的 & 是 按位與
int *p = &a; //此處的 & 是 取地址符
int &x = a; //此處的 & 是 參考
void fun(int &a); //此處的 & 也是參考
疑問:int &fun()這個是函式的參考嗎?
回答:不是函式的參考,表示函式的回傳值是一個參考,
2.參考的要求
- ①當定義參考時,必須初始化
//正確用法: int a = 10; int &x = a; - ② 沒有參考的參考(沒有二級參考)
//錯誤用法: int &x = a; int &&y = x; - ③ 沒有空參考
int &x; //error:不存在空參考
3.參考與指標的區別
| 參考 | 指標 |
|---|---|
| 必須初始化 | 可以不初始化 |
| 不可為空 | 可以為空 |
| 不能更換目標 | 可以更換目標 |
| 沒有二級參考 | 存在二級指標 |
-
1、參考必須初始化,而指標可以不初始化
int &s; //error:參考沒用初始化 int *p; //right:指標不強制初始化 -
2、參考不可以為空,指標可以為空
int &s = NULL; //error:參考不可以為空,右值必須是已經定義過的變數名 int *p = NULL; //right:可以定義空指標, int fun_p(int *p) { if(p != NULL) //因為指標可以為空,所以在輸出前需要判斷, { cout << *p << endl; } return *p; } int fun_s(int &s) { cout << s << endl; //參考不為空,可以直接輸出 return s; } -
3、參考不能改變目標,指標可以更換目標
int main() { int a = 20; int b = 10; int &s = a; int *p = &a; s = b; //參考只能指向初始化時的物件,如果改變,原先物件也跟著改變, p = &b; //指標可以改變指向的物件,不改變原先物件, cout << s << endl; cout << a << endl; return 0; }
4.常參考
我們可以能力收縮,不可能力擴展
//error:能力擴展
int a = 10;
int& b = a; //a b c都是一個東西
const int& c = a; //常參考
b += 10;
a += 100; //可以通過a b 去修改a 和 b
//c += 100; //error:不可通過 c 來修改 a 或者 b
//能力收縮
const int a = 100;
int& b = a; //不可編譯成功
//a += 100; //error:a 自身不可改變
b += 100;
int a = 100;
const int& x = a; //可以編譯成功
5.何時使用參考
參考可以作為函式引數
void Swap(int a, int b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 10, y = 20;
Swap(x, y); //僅僅Swap內部交換,并不能影響到實參
}
//加上參考,對a和b的改變會影響實參
void Swap(int &a, int &b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int x = 10, y = 20;
Swap(x, y); //僅僅Swap內部交換,并不能影響到實參
}
二、inline行內函式
1.行內函式的定義
為了解決一些頻繁呼叫小函式消耗大量堆疊空間的問題,引入了inline行內函式,
inline int fun(int a ,int b)
{
return a + b;
}
2.行內函式的處理流程
處理步驟
- 將 inline 函式體復制到 inline 函式呼叫點處;
- 為所用 inline 函式中的區域變數分配記憶體空間;
- 將 inline 函式的的輸入引數和回傳值映射到呼叫方法的區域變數空間中;
- 如果 inline 函式有多個回傳點,將其轉變為 inline 函式代碼塊末尾的分支(使用 GOTO),
int fun(int a,int b)
{
return a + b;
}
//普通呼叫
int main()
{
int a = 10;
int b = 20;
int c = fun(10,20);
}
//行內函式
int main()
{
int a = 10;
int b = 20;
int c = 10 + 20; //此處相當于直接展開函式
}
3.行內函式與三者的區別
3.1 與普通函式的區別
行內函式在函式的呼叫點直接展開代碼,沒有開堆疊和清堆疊的開銷,普通函式有開堆疊和清堆疊的開銷,
行內函式要求代碼簡單,不能包含復雜的結構控制陳述句,
若行內函式體過于復雜,編譯器將自動把行內函式當成普通函式來執行,
3.2 與static函式的區別
static修飾的函式處理機制只是將函式的符號變成區域符號,函式的處理機制和普通函式相同,都有函式的開堆疊和清堆疊的開銷,行內函式沒有函式的開堆疊和清堆疊的開銷,
inline函式是因為代碼直接在呼叫點展開導致函式只在本檔案可見,而static修飾的函式是因為函式法符號從全域符號變成區域符號導致函式本檔案可見,
3.3 與宏定義的區別
inline函式的處理時機是在編譯階段處理的,有安全檢查和型別檢查,而宏的處理是在預編譯階段處理的,沒有任何的檢查機制,只是簡單的文本替換,
inline函式是一種更安全的宏,
4.僅realese版本才會產生行內
代碼如下:
inline int Add_Int(int x, int y)
{
return x + y;
}
int main()
{
int a = 10, b = 20;
int c = 0;
c = Add_Int(a, b);
cout << c << endl;
return 0;
}
debug版本的反匯編:仍是以函式呼叫的形式
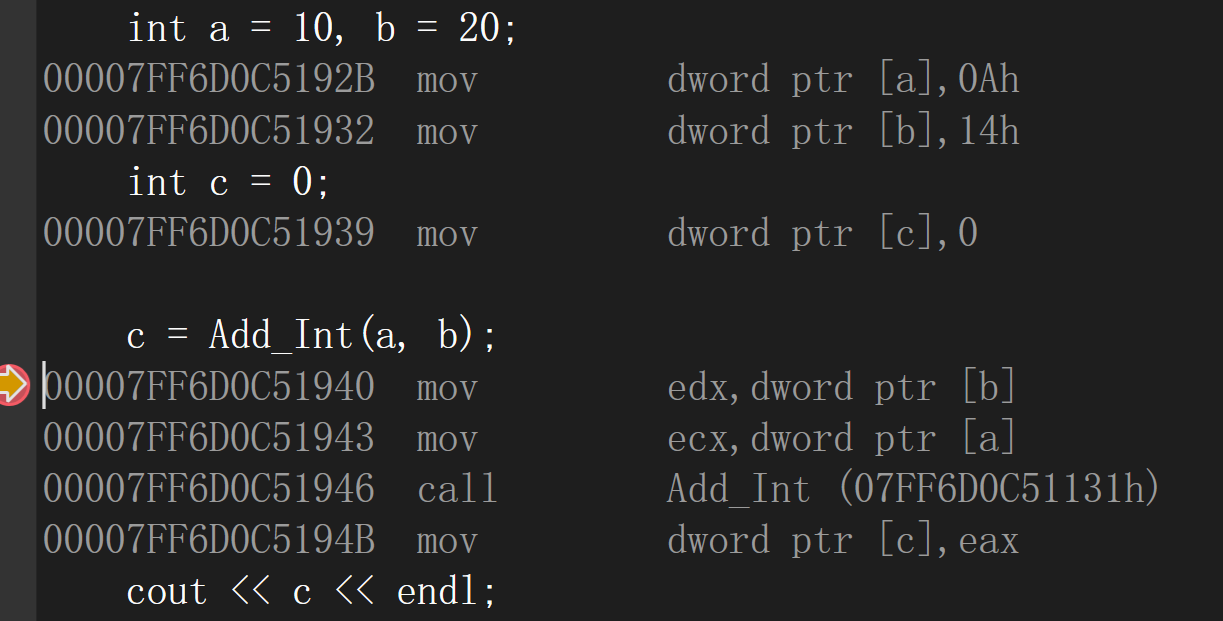
release版本的反匯編:在編譯時期展開
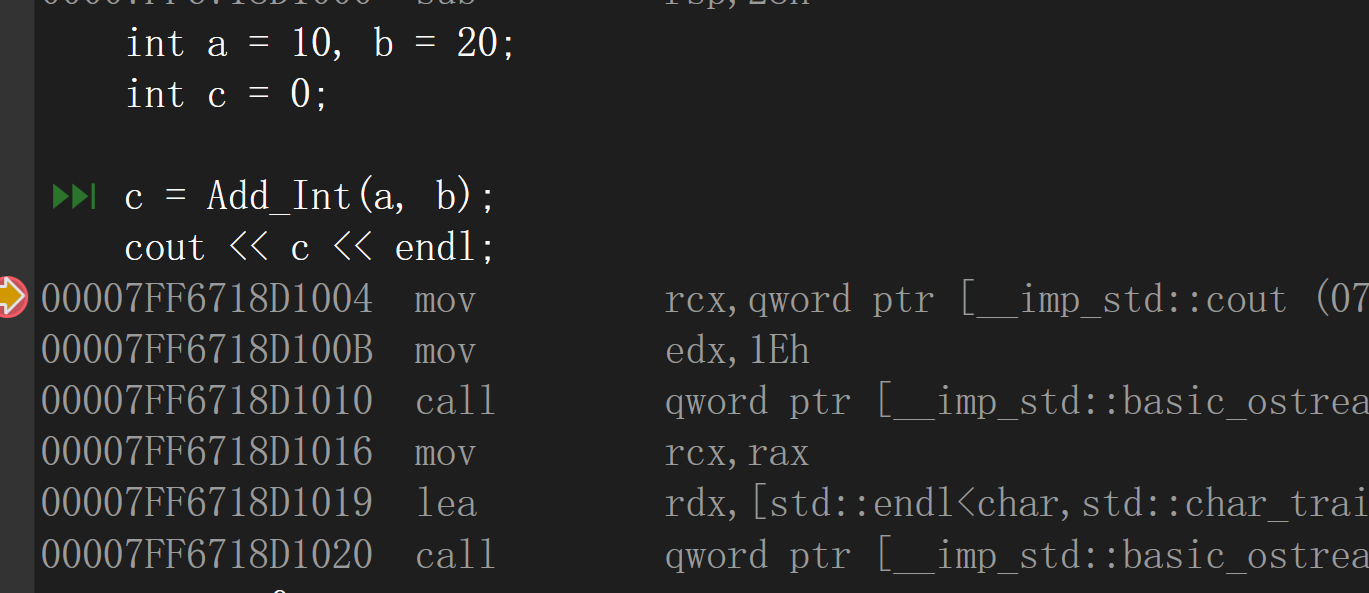
5.inline函式使用的限制
-
一般寫在頭檔案中
-
只在release版本中生效
-
inline只是一個建議,是否處理由編譯器決定
如果函式體內的代碼比較長,使得行內將導致記憶體消耗代價比較高, 如果函式體內出現回圈,那么執行函式體內代碼的時間要比函式呼叫的開銷大, -
基于實作的,不是基于宣告的
int fun(int x,int y); // 函式宣告 inline int fun(int x,int y) // 函式定義 { return x+y; } // 定義時加inline關鍵字 inline void fun1(int x) { }
三、函式的多載
在C語言中,函式名 是 函式的唯一標識
在C++中,函式原型 是 函式的標識,
函式原型
函式原型 = 函式回傳型別 + 函式名 + 形參串列(引數的型別和個數)
使用extern關鍵字指定為C語言編譯
extern"C" int Max(int a, int b)
{
return a > b ? a : b;
}
extern"C" int fun(int a, int b)
{
return a + b;
}
int main()
{
Max(10, 20);
fun(20, 30);
return 0;
}
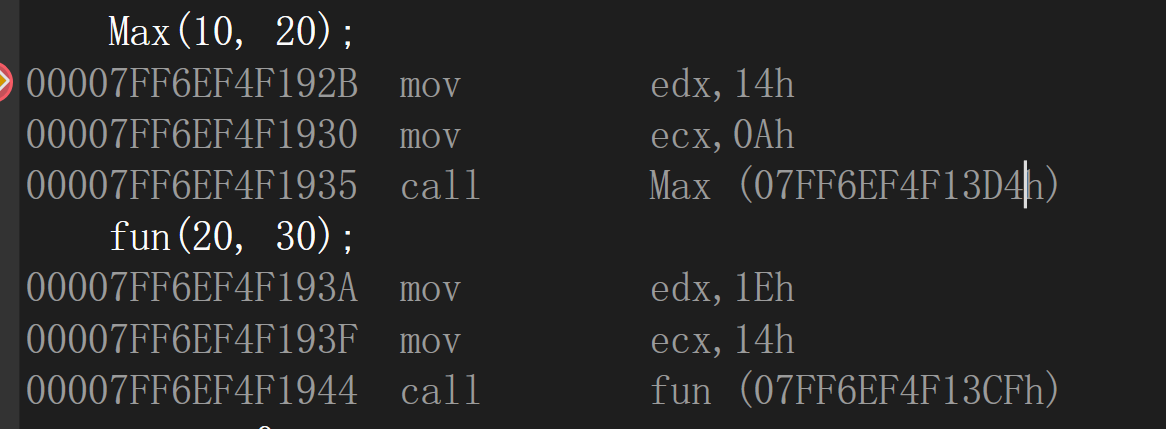
VS2022中
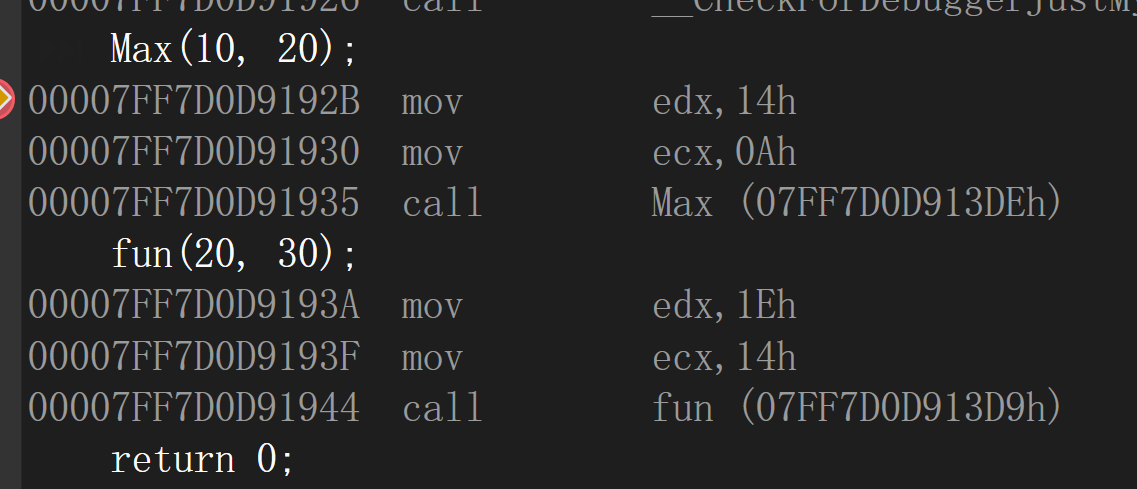
以C語言編譯:函式名仍是原來的函式名
以C++編譯:也是一樣的情況
將函式的形參型別進行修改:
int Max(int a, int b)
{
return a > b ? a : b;
}
int Max(double a, int b)
{
return a > b ? a : b;
}
int main()
{
Max(10, 20); //編譯正常
Max(10.00, 20); //編譯正常
return 0;
}
發現函式名仍是一樣,但是存放double型別的暫存器與存放int型別的暫存器不一樣
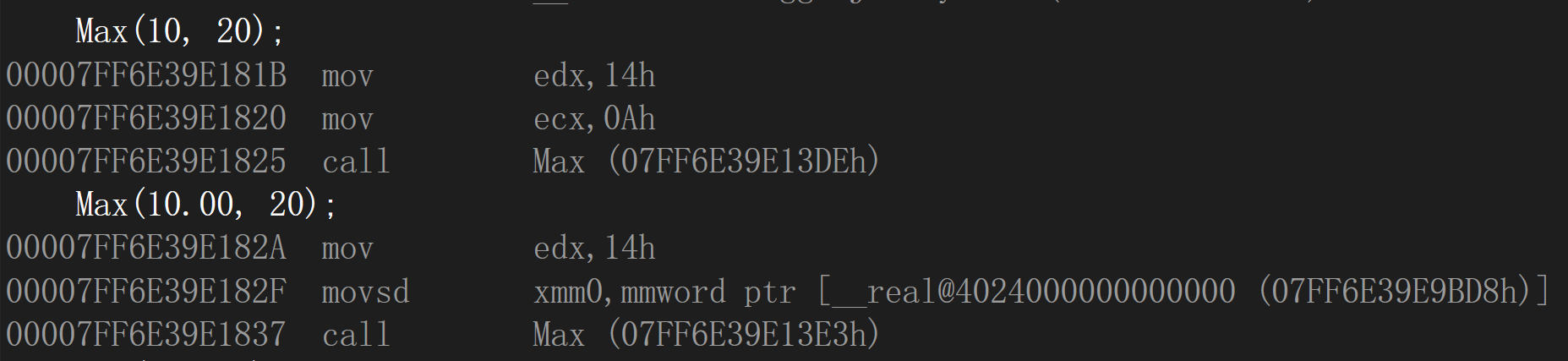
再將回傳值型別也進行修改:
int Max(int a, int b)
{
return a > b ? a : b;
}
double Max(double a, int b)
{
return a > b ? a : b;
}
int fun(int a, int b)
{
return a + b;
}
int main()
{
Max(10, 20); //編譯正常
Max(10.10, 20); //編譯正常
return 0;
}
發現并沒有任何問題,呼叫的也并非是同一個函式
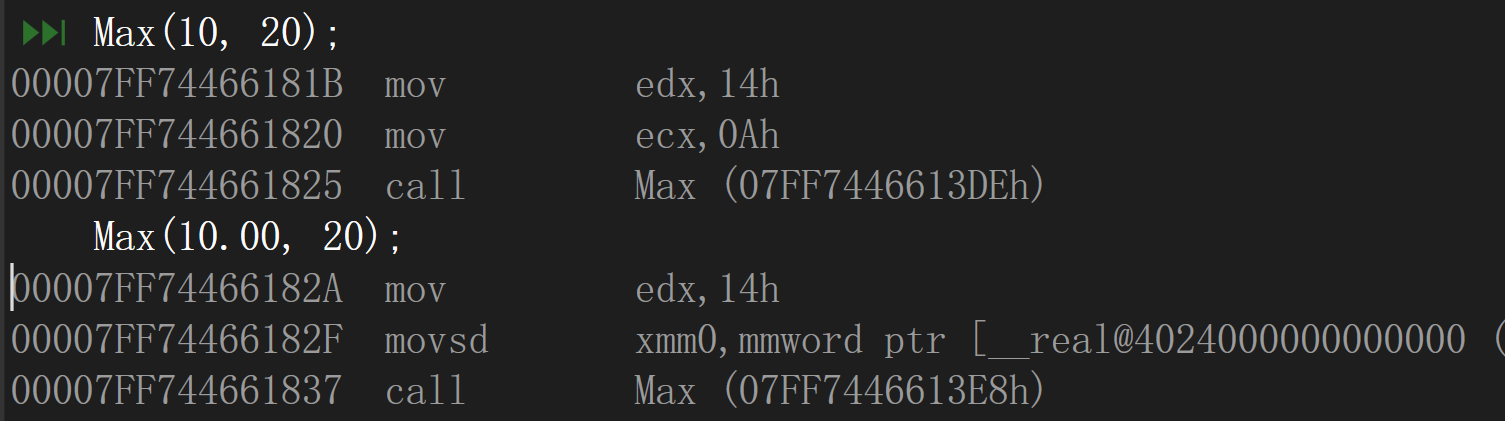
在VS2019中:
以C語言編譯:函式名前加 _ ,_fun 和 _Max

以C++編譯:沒有下劃線,與VS2022中C++編譯相同
在VC6.0中:
int Max(int a, int b)
{
return a > b ? a : b;
}
double Max(double a, double b)
{
return a > b ? a : b;
}
char Max(char a, char b)
{
return a > b ? a : b;
}
int main()
{
Max(10, 20);
Max(10.0, 10.0);
Max('a','b');
return 0;
}
回傳值為int 型別的Max函式:
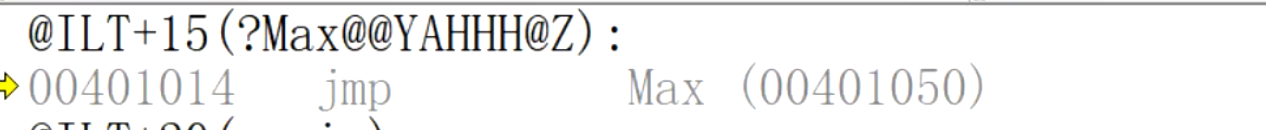
回傳值為double型別的Max函式:
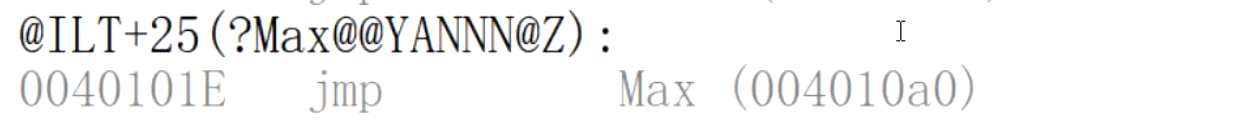
回傳值為char型別的Max函式:
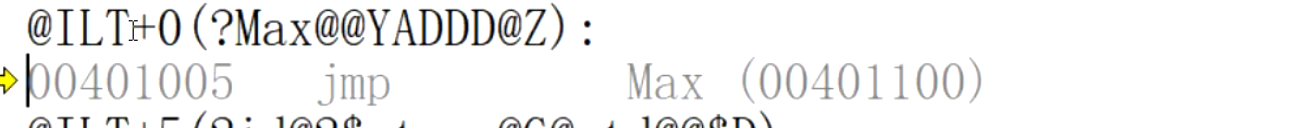
為什么函式名發生了如此大的改變?
這個就是名字粉碎技術
四、函式模板
模板的定義:
template <模板引數名>
回傳型別 函式名(形式引數表)
{
//函式體
}
<模板引數表> 尖括號中不能為空,引數可以有多個,用,隔開
template<class Type>
void Swap(Type& a, Type& b)
{
Type tmp = a;
a = b;
b = tmp;
}
注意1:<>中只能以C++的方式寫,不能出現如 template <struct Type>
注意2:下面呼叫Swap不是簡單的替換(宏替換),是重命名規則
//普通型別
template <class Type> typedef int Type;
void Swap(Type &a ,Type &b) void Swap<int>(Type &a,Type &b)
{ {
Type tmp = a; Type tmp = a;
a = b; a = b;
b = tmp; b = tmp;
} }
int main()
{
int a = 10, b = 20;
Swap(a, b); //此處的呼叫如同右邊函式
}
//指標型別
template<class Type> typedef int Type
void fun(Type p) void fun<int *>(Type p)
{ {
Type a, b; Type a, b;
} }
int main()
{
int x = 10;
int* ip = &x;
fun(ip);
return 0;
}
注意3:編譯時進行重命名,非運行時,
五、new和malloc
//C語言與C++申請空間:
int main()
{
int n = 10;
//C:malloc free
int* ip = (int*)malloc(sizeof(int) * n);
//地址空間與NULl進行對比,判斷是否申請失敗
if (NULL == ip) exit(1);
free(ip);
ip = NULL;
//C++:new delete
ip = new int;
*ip = 100;
delete ip;
ip = NULL;
}
//new申請連續空間
int main()
{
//new申請連續空間,要釋放連續空間
ip = new int[n];
//此處的delete不是把ip洗掉,而是將ip指向堆區的空間換給系統
delete[]ip;
}
new申請失敗時候的處理:
//錯誤處理:
ip = new int;
if (ip == NULL) exit(1);
delete ip;
ip == NULL;
//new 如果分配記憶體失敗,默認是拋出例外的,
//分配成功時,那么并不會執行 if (ip == NULL)
//若分配失敗,也不會執行 if (ip == NULL)
//分配失敗時,new 就會拋出例外跳過后面的代碼,
//正確處理1:強制不拋出例外
int *ip = new (std::nothrow) int[n];
if (ip == NULL)
{
cout << "error" << endl;
}
//正確處理2:捕捉例外
try
{
int* ip = new int[SIZE];
}
catch (const bad_alloc& e)
{
return -1;
}
總結
仍遺留下很多問題:
- new和malloc的區別
- 命名空間
- 參考的深入
- const
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/541434.html
標籤:其他
上一篇:idea的簡單介紹
下一篇:1.Maven入門