淘汰策略概述
redis作為快取使用時,在添加新資料的同時自動清理舊的資料,這種行為在開發者社區眾所周知,也是流行的memcached系統的默認行為,
redis中使用的LRU淘汰演算法是一種近似LRU的演算法,
淘汰策略
針對淘汰策略,redis有一下幾種配置方案:
1、noeviction:當觸發記憶體閾值時,redis只讀不寫;
2、allkeys-lru:針對所有的key,執行LRU(最近最少使用)策略;
3、allkeys-lfu:針對所有的key,執行LFU(最低頻使用)策略;
4、volatile-lru:針對設定了過期時間的key,執行LRU(最近最少使用)策略;
5、volatile-lfu:針對設定了過期時間的key,執行LFU(最低頻使用)策略;
6、allkeys-random:針對所有key,進行隨機淘汰;
7、volatile-random:針對設定了過期時間的key,進行隨機淘汰;
8、volatile-ttl:針對設定了過期時間的key,淘汰剩余過期時間最短的;
根據應用場景選擇合適的淘汰策略是非常重要的,我們可以在程式運行時實時重置淘汰策略,并使用Redis INFO輸出來監控快取未命中和命中的數量,以優化設定,
根據以往使用慣例:
- 當你希望某些元素的子集被訪問的頻率高于其他元素,或者當你不知道怎么選擇淘汰策略時,allkeys-lru策略是一個很好的選擇;
- 當你在回圈訪問redis,且所有的key是被連續掃描時,或者你希望key過期時間均勻分布時,allkeys-random策略是一個很好的選擇;
- 如果你希望基于key不同的TTL時間篩選出哪些key可被淘汰,volatile-ttl策略是一個很好的選擇;
還有一點是為key設定過期時間會占用記憶體,因此使用allkeys-lru這樣的策略會更節省記憶體,因為在記憶體壓力下不需要對key進行過期設定,
淘汰策略如何作業
淘汰程序如下:
- 客戶端執行一條指令,需要添加一批資料;
- redis檢測快取閾值限制,如果超過閾值則執行淘汰策略;
- 執行指令等等;
因此在redis的使用程序中,我們可能不斷的超過記憶體閾值限制,然后執行淘汰策略再將記憶體恢復到閾值之下,
近似LRU演算法
redis lru演算法是一個近似lru演算法,這意味著針對整個key集合,redis在執行lru策略時可能不會很精準的淘汰掉最應該被淘汰的key,相反的是,redis會通過抽樣一小部分key,并淘汰采樣key中最該被淘汰的, 自redis3.0以來,該演算法得到了改善,能夠抽樣大批量的key進行淘汰,使其能夠更接近真實LRU演算法的行為, redis lru演算法的重要之處在于可以通過更改樣本數量來調整演算法的精度,此引數由以下配置指令控制:maxmemory-samples 5
redis不使用真正的LRU實作的原因是它需要更多的記憶體,然而,對于使用Redis的應用程式,近似lru演算法實際上是與精確lru演算法差不多的,此圖將redis使用的LRU近似值與真實LRU進行了比較,

用給定數量的key填充了Redis服務器(達到記憶體閾值)進行測驗并生成了上面的圖,從第一個到最后一個訪問key,第一個key是使用LRU演算法淘汰的最佳候選key,之后再添加50%以上的key,以強制淘汰一半的舊key,
你可以在圖中看到三種點,形成了三個不同的區域:
- 淺灰色區域是被淘汰的物件
- 灰色區域是未被淘汰的物件
- 綠色區域是新加的物件
在理論LRU實作中(theoretical LRU),我們預計舊key集合中的前一半將會被淘汰,與之相反,redis lru演算法實作中,舊key集合中也只是會離散性的淘汰其中某些key,
正如您所看到的那樣,與Redis 2.8相比,Redis 3.0在同樣抽樣數為5個時做得更好,但是大多數最新增加的key仍然被Redis 2.8保留,在Redis 3.0中使用10的樣本大小,近似值非常接近Redis 3.0的理論性能,
在模擬中,我們發現使用冪律訪問模式(類似20%的key承擔了80%的訪問),真實LRU和Redis近似LRU之間的差異極小或根本不存在,
使用CONFIG SET maxmemory samples<count>命令在生產中使用不同的樣本大小值進行實驗非常簡單,
新的LFU模式
從redis4.0開始,可以在某些特定場景下使用低頻淘汰策略,在選用LFU策略后,redis會跟蹤key的訪問頻率,所以低頻的key將被淘汰,這意味著經常訪問的key有很大的機會一直留在記憶體中,
要配置LFU模式,可以使用以下策略:
- volatile-lfu:針對設定了過期時間的key,使用近似lfu淘汰;
- allkeys-lfu:針對所有key,使用近似lfu淘汰;
LFU近似于LRU:它使用一個稱為Morris的概率計數器來估計key訪問頻率,計數器中每個key只占用幾個bit,并且計數器功能附加衰減周期,這樣計數器統計的key訪問頻率就會隨著時間的推移而降低(如果一段時間內一個key訪問頻率低于計數器衰減速度,最終這個key會被淘汰),直至某一刻,我們不再將一些key視為頻繁訪問的key,即使它們在過去是被頻繁訪問的,以便演算法能夠適應訪問模式的變化,
該資訊的采樣方式與LRU(如本檔案前一節所述)選擇淘汰key的情況類似,
然而,與LRU不同的是,LFU具有某些可調引數:例如,如果一個頻繁key不再被訪問,那么它的訪問頻率級別應該降低多少?還可以調整Morris計數器范圍,以更好地使演算法適應特定的場景,
默認情況下,Redis配置為:
- 在大約100萬次請求時讓計數器飽和;
- 每一分鐘使計數器衰減一次;
這些配置應該是合理的,并且經過了實驗測驗,但用戶可能希望使用這些配置設定來選擇最佳值,
有關如何調整這些引數的說明,可以在源發行版的示例redis.conf檔案中找到,簡而言之,它們是:
lfu-log-factor 10 lfu-decay-time 1
衰減時間是最明顯的一個,它是計數器在采樣時應該衰減的分鐘數,特殊值0表示:永遠不會衰減計數器,
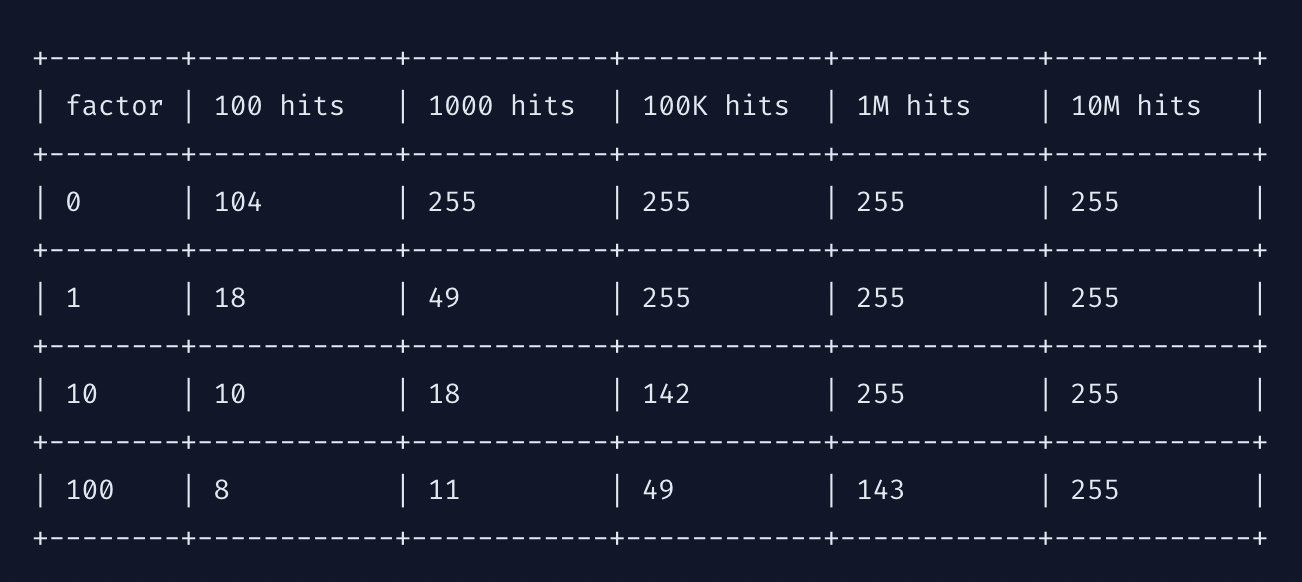
計數器對數因子決定了使頻率計數器達到飽和需要的key命中次數,頻率計數器剛好在0-255范圍內,系數越高,需要更多的訪問才能達到最大值;系數越低,低頻訪問計數器的解析度越好,如下表所示:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/542253.html
標籤:Java