模塊
一、模塊簡介
1.什么是模塊
內部具有一定功能(代碼)的py檔案
2.python模塊的歷史
python屈辱史:
python剛出來時被瞧不起因為太簡單,寫代碼都是呼叫模塊(調包俠 貶義).
后來業務擴展很多程式員也需要使用python寫代碼,發現好用(調包俠 褒義).
python為什么好用?
因為支持python的模塊非常多還很全面.
作為python程式員將來接收到業務需求時不要一上來就想自己寫,先看看有沒有相應的模塊已經實作可以呼叫.
3.模塊的表現形式
- py檔案
- 含有多個py檔案的檔案夾
- 已被編譯為共享庫或DLL的c或c++擴展
- 使用c撰寫并鏈接到python解釋器的內置模塊
二、模塊的三大分類
1.內置模塊
python解釋器中自帶的可以直接使用的模塊 eg:import time等
2.自定義模塊
自己寫的模塊 eg:登錄、注冊
3.第三方模塊
別人寫好的
模塊檔案 在網上下載
三、匯入模塊的兩種句式
注意:
1.專案中所有py檔案名都應該是英文 沒有中文和數字
2.匯入py檔案不需要寫后綴
3.同一個py檔案中反復匯入相同的模塊 匯入的陳述句只會執行一次
1.import...句式
import time
1.先產生執行檔案的名稱空間
2.執行模塊檔案的代碼 產生模塊名空間2
3.在執行檔案的名稱空間中產生一個模塊檔案的檔案名 通過點的方式就可以使用該模塊名稱空間中的名字
【a.py】:
name = 'jason'
——————————————————————————————————
【md.py】:
import a
print(a.name) #執行檔案中用a.name即可使用,函式等同理
#結果為:jason
2.from...import...句式
from a import name
1.先產生執行文鍵的名稱空間
2.執行模塊檔案的代碼,產生模塊名稱空間
3.在執行檔案的名稱空間中產生對應的名字系結模塊名稱空間中對應的名字,通過點的方式就可以使用該模塊名稱空間中的名字
【a.py】:
name = 'jason'
——————————————————————————————————
【md.py】:
from a import name
print(name) #執行檔案中可直接使用name,函式等同理
#結果為:jason
| import...句式 | from..import..句式 | |
|---|---|---|
| 優點 | 可以通過模塊名點的方式使用到模塊內所有的名字 且不會沖突 | 指名道姓的使用需要的名字 直接就可以使用該名字 不需要模塊名去點 |
| 缺點 | 由于模塊名什么都可以點 有時候不想讓所有的名字都能夠被使用 | 容易與執行檔案中的名字產生沖突 |
四、匯入模塊的句式補充
1.起別名
當兩個模塊檔案中都有相同的變數名name時 在執行檔案中列印name 結果就是當前執行檔案中的name 如果想要使用被匯入檔案中的name 就需要as 變數名 給她起一個別名 避免沖突
【a.py】:
name = 'jason'
——————————————————————————————————
【md.py】:
from a import name
name = 'torry'
print(name) #此處列印的name是當前執行檔案中的name
#結果為:torry
from a import name as n #取別名
print(n)
#結果為:jason
2.匯入多個模塊
當有多個模塊功能相似時可以在一起匯入 不相似的盡量分開匯入
import a,b,c
from a import login,register
————————————————————————————————
import a
import b
from a import name
from a import login
3.全匯入(僅針對from...import...句式)
-
需要使用模塊中多個名字時可以用*號的方式
【a.py】: name = 'jason' age = 18 job = 'teacher' —————————————————————————————————— 【md.py】: from a import * print(name,age,job) #可以使用a模塊檔案中所有的名字 -
針對*號可以用__all__=[變數名]控制可以使用的變數名
【a.py】: name = 'jason' age = 18 job = 'teacher' __all__ = [name,age] —————————————————————————————————— 【md.py】: from a import * print(name) # 結果為:jason print(job) # 報錯
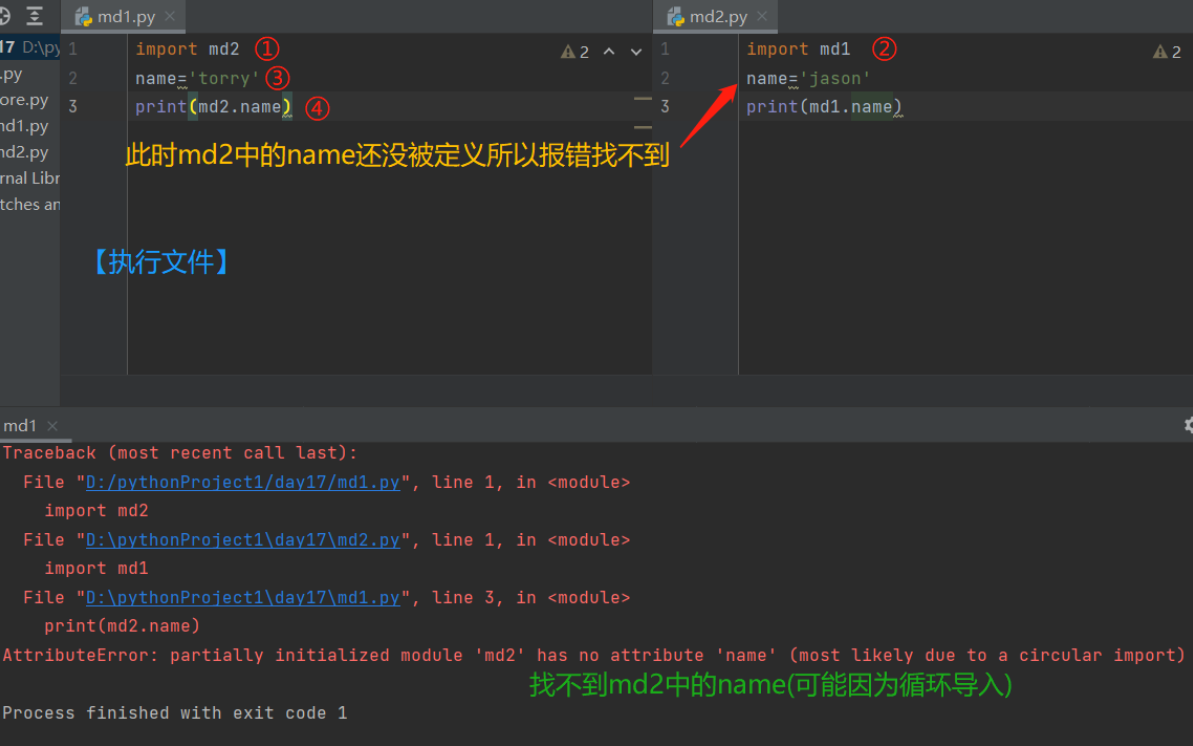
五、回圈匯入問題及解決策略
1.什么是回圈匯入
回圈匯入就是兩個檔案彼此匯入彼此 且互相使用物件名稱空間中的名字
2.如何解決回圈匯入問題
- 確保在使用各自名字前就把名字定義好
- 盡量避免寫回圈匯入的代碼
六、判斷檔案型別
所有py檔案都可以直接列印__name__判斷檔案型別
當檔案是'執行檔案'時:
print(__name__)
#結果為:__main__
當檔案是'被匯入檔案'時:
print(__name__)
#結果為:被匯入的檔案名
一般__name__主要是用于測驗自己代碼時使用:當檔案是執行檔案時才往下走子代碼
if __name__=='__main__'
print('當檔案是執行檔案時才會執行if的子代碼')
#上述腳本一般只出現在整個程式的啟動檔案中
七、模塊的查找順序
1.先去記憶體中查找
#驗證:在執行檔案中執行被匯入檔案中的函式,在執行程序中洗掉被匯入檔案發現還可以使用
import md #匯入執行md模塊
import time #匯入執行time模塊
time.sleep(15) #讓程式暫停15s再執行
'中途如果把md模塊檔案刪掉 還會繼續執行,因為洗掉的是硬碟中的,記憶體中的還在'
print(name)#結果為:jason
____________________________________________
2.再去內置中查找
#驗證:創建一個和內置模塊相同的模塊檔案名
【time.py】:
name = 'jason'
【執行檔案.py】:
from time import name
print(name)#結果會報錯
import time
print(name)#結果會報錯
_____________________________________________
3.然后去執行檔案所在的sys.path中查找 # 不是系統環境變數
需注意'所有路徑都是參照執行檔案所在的路徑去查找'
#驗證:如果執行檔案和被執行檔案在不同檔案夾下,則要把模塊所在的檔案路徑添加到執行檔案的sys.path中
import sys
# print(sys.path)#執行sys.path結果為當前執行檔案的環境變數,以串列顯示
sys.path.append(r'D:\pythonProject1\day17\aa')#將被匯入檔案的路徑添加
import md3
print(md3.name)#此時列印md3中的name就可以找到 不添加路徑則找不到
八、模塊的絕對匯入與相對匯入
只要涉及到模塊匯入就以當前執行檔案路徑為準(站在執行檔案路徑的視角去看)
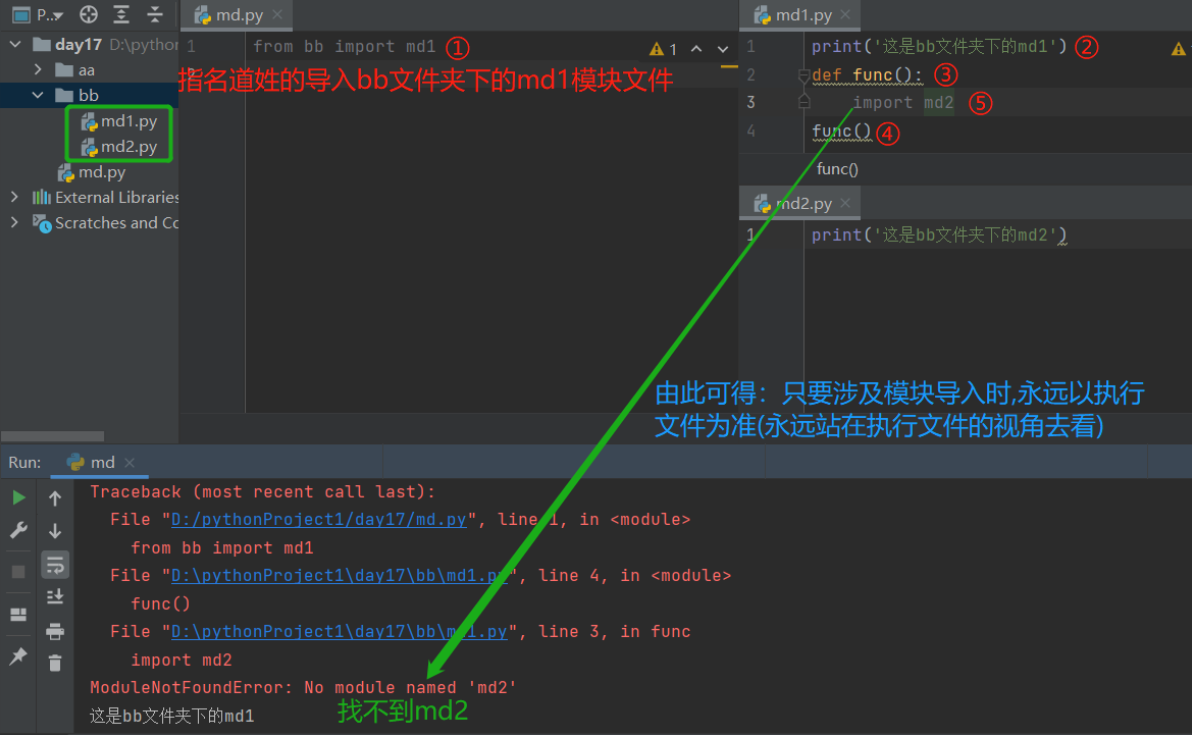
解決方式:
? 1.把bb檔案夾路徑添加到執行檔案sys.path路徑中
? 2.在md1.py檔案中把import md2 改為 from bb import md2('這就是絕對匯入')
1.絕對匯入
-
就是以執行檔案所在的sys.path為起始位置一層一層查找
from aa import md -
當涉及檔案嵌套多個檔案名時 則要在檔案名后加點和內層檔案名
from aa.bb.cc import md
2.相對匯入
#點號在相對匯入中的作用
. 在路徑中表示當前目錄
.. 在路徑中表示上一層目錄
..\.. 在路徑中表示上上一層目錄
-
相對匯入可以不參考執行檔案所在的路徑 直接以當前模塊檔案路徑為準
from . import md2
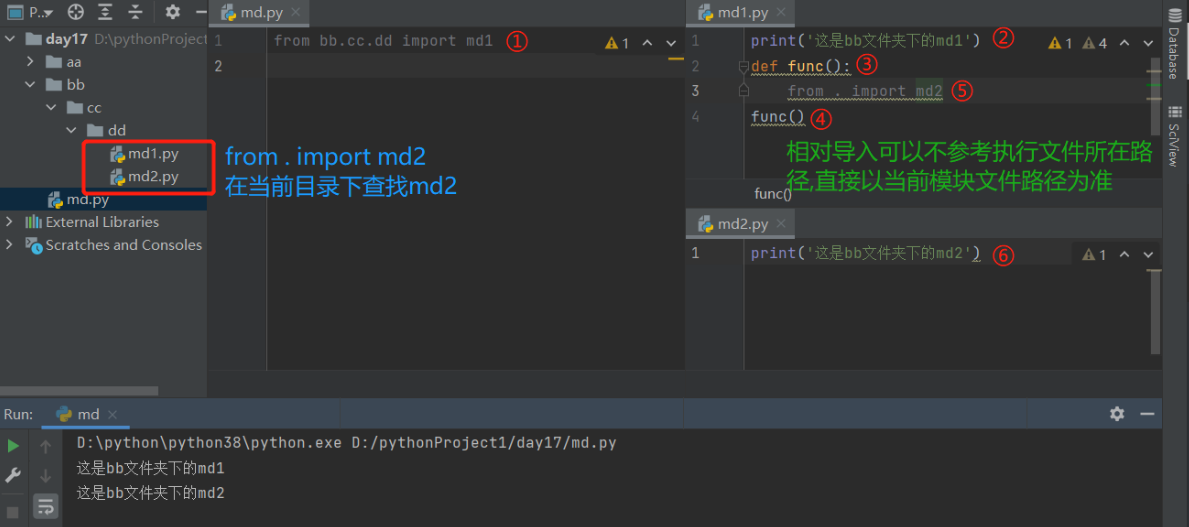
- 缺陷:
- 只能在被匯入模塊檔案中使用 不能在執行檔案中使用
- 當專案較復雜時容易報錯 盡量不用
九、包
1.包是什么
專業角度:內部含有__init__.py檔案的檔案夾就叫包
大白話:檔案內有多個py檔案
2.不同解釋器如何理解包
python3中:檔案夾里有沒有__init__.py檔案都無所謂 都叫包
python2中:檔案夾里必須有__init__.py檔案才叫包
3.包的具體使用
雖然python3解釋器對包的要求降低了 不需要__init__.py就可以識別 但是為了兼容考慮建議不管什么版本解釋器都加上
1.如果想只用包里的某幾個模塊
from aa import md1,md2
print(md1.name)#可以使用md1中的name
2.如果直接導包名則就是包下面'__init__.py檔案',該檔案中有什么名字就可以通過包名點什么名字
import aa
print(aa.name)#可以使用aa包里__init__.py里的名字
十、編程思想的轉變
階段一:面條版本(所有代碼從上往下依次執行)
階段二:函式版本(將代碼按照功能不同封裝成不同函式)
階段三:模塊版本(根據功能不同拆分到不同的py檔案)
1.階段一可以理解為將所有檔案全部存盤到c盤且不分類
eg:'系統、視頻、圖片'
2.階段二可以理解為將檔案分類
eg:'系統檔案、視頻檔案、圖片檔案'
3.階段三可以理解為按照不同功能放在不同的盤里
eg:'C盤放系統檔案、D盤放視頻檔案、E盤放圖片檔案'
#這樣做就是為了資源的【高效管理】
十一、軟體開發目錄規范
1.bin檔案夾 'start.py'
啟動檔案
2.conf檔案 'settings.py'
組態檔
3.core檔案夾 'src.py'
核心邏輯
4.interface '介面檔案'
介面檔案
5.lib檔案 'common.py'
公共檔案
6.db檔案 'db_hardle'
存盤資訊
7.log檔案 'log.log'
日志檔案
8.readme.txt檔案
使用說明書
9.requirements.txt檔案
第三方模塊
十二、python常用內置模塊
1.collection模塊
除了基本資料型別(list、dict、tuple、set)collection模塊還提供了額外的資料型別:nametuple、deque、orderdict、counter
-
nametuple 具名元組
就是可以給一個元組命名 通過名字可以訪問到內部自定義的屬性
# 表示二維坐標系 from collections import namedtuple zuobiao = namedtuple('二維坐標', ['x', 'y']) p1 = zuobiao(1, 2) print(p1) # 二維坐標(x=1, y=2) print(p1.x) # 1 print(p1.y) # 2#可以用來做簡單撲克牌 from collections import namedtuple puke = namedtuple('撲克牌', ['花色', '點數']) res1 = puke('?', 'A') print(res1) # 撲克牌(花色='?', 點數='A') -
deque 雙端佇列
佇列:先進先出 后進后出
堆疊:先進后出 后進先出
佇列和堆疊都是:一邊只能進 另一邊只能出
pop()尾部彈出 popleft()首部彈出
append()尾部追加 appendleft()首部追加
串列里沒有首部彈出和首部追加
from collections import deque q = deque([1, 2, 3]) q.append(4) # 尾部追加4 q.appendleft(0) # 首部追加0 print(q) # deque([0, 1, 2, 3, 4]) print(q.pop()) # 4 【佇列:取出最后面的】 print(q.popleft()) # 0 【堆疊:取出最前面的】 -
OrderedDict 有序字典
使用字典時K鍵是無序的,當想對字典做迭代時沒辦法保證K鍵的順序,
如果想讓字典有順序則可以用有序字典補充了解:3.6版本解釋器后字典都變成按照插入順序來的了,
d=dict() d['name']='jason' d['age']=18 d['job']='teacher' for i in d: print(i) ______________________________ from collections import OrderedDict d=OrderedDict() d['name']='jason' d['age']=18 d['job']='teacher' for i in d: print(i) -
defaultdict 默認字典
普通洗點列印沒有的鍵會報錯 defaultdict則會回傳空
d1 = dict() from collections import defaultdict d2 = defaultdict(list) print(d1['a']) # 報錯 print(d2['a']) # [] -
Counter 計數器
主要用來統計出現的次數
#方式一: from collections import Counter c=Counter('aabbbccc') print(c) #結果為:Counter({'b':3,'c':3,'a':2})#方式二: s1 = 'aabbbccc' new_dict = {} for i in s1: if i not in new_dict: new_dict[i] = 1 else: new_dict[i] += 1 print(new_dict) #結果為:{'a':2,'b':3,'c':3}
2.time與datatime時間模塊
-
time 時間沒模塊
1.時間戳 從1970年1月1日0時0分0秒到此時此刻的秒數 2.結構化時間 給計算機看的 3.格式化時間 給人看的 time.sleep(3) 讓程式停止運行幾秒-
時間戳
#1.時間戳 import time print(time.time()) #結果為:1666174527.7080512 """ 一般用于在某個代碼前后加,用來得出該代碼執行時間 """ -
結構化時間 localtime()
#2.結構化時間 import time print(time.localtime()) #結果為:查看本地時間 print(time.gmtime()) #結果為:查看UTC時間 英國倫敦 -
格式化時間 strftime()
#3.格式化時間 import time print(time.strftime('%Y-%m-%d %H:%M:%S')) #結果為:2022-10-19 18:25:23 print(time.strftime('%Y-%m-%d')) #結果為:2022-10-19 """ %Y 年 | %m 月 | %d 日 %H 時 | %M 分 | %S 秒 """
-
-
datetime 時間模塊
datetime 年月日時分秒 data 年月日 time 時分秒#獲取今天【年月日 時分秒】 import datetime res = datetime.datetime.today() print(res) # 結果為:2022-10-19 18:48:04.737998 """ res.year 年 res.month 月 res.isoweekday() 星期幾 """ —————————————————————————————————————— #獲取今天【年月日】 import datetime res1 = datetime.date.today() print(res1) # 結果為:2022-10-19補充:
#時間間隔 t1 = datetime.date.today() # 獲取當前年月日 print(t1) # 2022-10-19 t2 = datetime.timedelta(days=3) # 定義時間間隔為3天 print(t1 + t2) # 2022-10-22 #指定日期 c = datetime.datetime(2022,5,23,12) print(c) #結果為:2022-05-23 12:00:00
3.randon亂數模塊
import random
"""隨機列印數字"""
print(random.random())#產生一個從0~1的小數
print(random.randint(1,5))#產生一個從1~5的小數
print(random.randrange(1,10,2))#產生一個從1~10的奇數
"""從資料集中隨機列印資料"""
print(random.choice([1,2,3]))#隨機列印一個串列中的資料值
print(random.choices([1,2,3]))#隨機列印一個串列中的資料值并組成串列
print(random.sample([1,2,3],2))#隨機列印兩個串列中的資料值并組成串列
"""打亂資料集順序"""
l1=[1,2,3,4,5]
random.shuffle(l1)#把串列中的資料隨機打亂順序
print(l1)
def func(n):
yzm=''
for i in range(n):
#1.先產生隨機的大小寫字母、數字
random_upper=chr(random.randint(65,90))
random_lower=chr(random.randint(97,122))
random_int=str(random.randint(0,9))#字串不能和整數相加,所以轉換成字串
#2.把隨機生成的字符三選一
temp=random.choice([random_upper,random_lower,random_int])
yzm+=temp
return yzm
res=func(4)
print(res)
4.os模塊
import os
os 模塊主要是當前程式與所在的作業系統打交道
-
創建目錄
在執行檔案所在的路徑下創建目錄 mkedirs()創建目錄 1.創建多級目錄 os.makedirs(r'xxx') #單級目錄 os.makedirs(r'xxx\yyy')#多級目錄 2.創建單級目錄 os.mkdir(r'xxx') -
洗掉目錄
1.os.rmdir(r'xxx') #洗掉空的單級目錄 目錄下不能有任何檔案 2.os.removedirs(r'xxx\yyy') #洗掉空的多級目錄 從內到外洗掉 直到某目錄下有其他檔案為止 -
列舉指定路徑下所有檔案、目錄名(結果會以串列的形式展示)
print(os.listdir(r'xxx\yyy')) #列舉路徑下所有檔案、目錄名 不寫路徑則是執行檔案路徑下所有檔案、目錄名 -
重命名檔案
os.rename(r'xxx.py',r'yyy.py') #給某檔案重命名 os.rename(r'zzz',r'aaa') #給某目錄重命名 -
洗掉檔案
os.remove(r'xxx.py') #洗掉某檔案 -
獲取、切換當前作業路徑
print(getcwd()) #獲取當前作業路徑 D:\pythonProject1\day19 os.chdir('..') #切換到上一級目錄 print(getcwd()) #獲取當前作業路徑 D:\pythonProject -
動態獲取專案路徑
1.動態獲取 專案根路徑 print(os.path.dirname(__file__)) #D:/pythonProject1/day19 2.動態獲取專案 根路徑的上一級路徑 print(os.path.dirname(os.path.dirname(__file__))) #D:/pythonProject1 3.動態獲取執行檔案的絕對路徑 print(os.path.abspath(__file__)) #D:\pythonProject1\day19\run.py -
判斷路徑是否存在
exists() 判斷路徑是否存在 isdir() 判斷路徑是否是目錄 isfile() 判斷路徑是否是檔案 '結果為布林值' 1.判斷路徑是否存在 print(os.path.exists(r'路徑')) #可以是詳細的檔案夾或py檔案 2.判斷路徑是否是目錄 print(os.path.isdir(r'路徑')) 3.判斷路徑是否是檔案 print(os.path.isfile(r'路徑')) -
拼接路徑
join()
a=r'D:\aa' b=r'a.txt' new_path=os.path.join(a,b) #將a和b拼接 print(new_path) # D:\aa\a.txt -
獲取檔案大小
大小單位是:bytes位元組
print(os.path.getsize(r'a.txty'))
5.sys模塊
import sys
sys模塊主要是當前程式與python解釋器打交道
(1)獲取執行檔案的環境變數
print(sys.path)
(2)獲取最大遞回深度 與 修改最大遞回深度
print(sys.getrecursionlimit()) # 1000
sys.setrecursionlimit(2000) # 修改解釋器最大遞回深度
print(sys.getrecursionlimit()) # 2000
(3)獲取當前解釋器版本資訊
print(sys.version)
#3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)]
(4)獲取當前平臺資訊
print(sys.platform) # win32
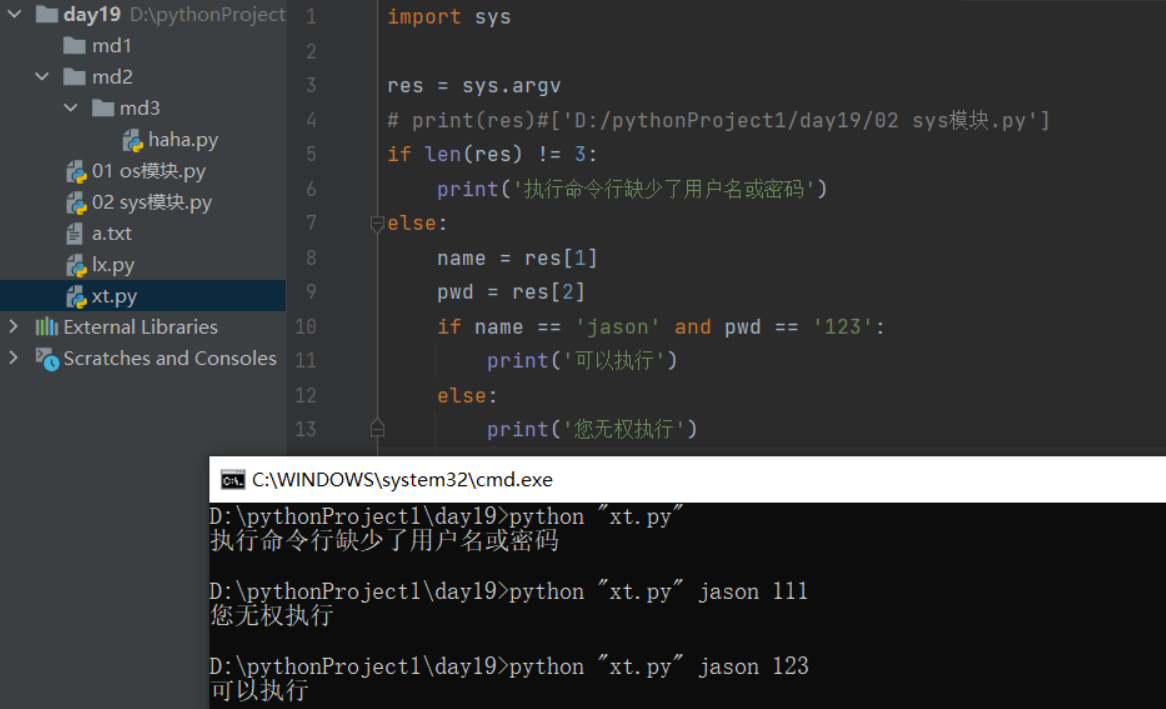
(5)實作從程式外向程式內傳遞引數
sys.argv #如下圖
6.json模塊
-
json模塊也被稱為:序列化模塊 可以讓不同的編程語言之間互動
-
系列化:將字典、串列等內容轉換成一個字串的程序就叫序列化
-
json格式資料屬于什么型別:由于資料基于網路傳輸只能用二進制 python中只有字串可以呼叫encode編碼轉二進制 所以json格式的資料也屬于字串
-
json格式資料特征:字串且引號是雙引號
#針對資料 json.dumps() 將其他資料型別轉成json格式字串 json.loads() 將json格式字串轉換成對應資料型別 #針對檔案 json.dump() 將其他資料型別以json格式字串寫入檔案 json.load() 將檔案中json格式字串讀取出來并轉換成對應的資料型別
7.正則運算式
正則運算式是一門獨立的技術 所有編程語言都可以使用
-
正則運算式含義:
正則運算式就是用一些特殊符號的組合產生特殊含義去字串中篩選符合條件的資料 也可以直接寫需要查找的具體字符 主要用于 篩選 匹配資料 正則運算式線上測驗網站:http://tool.chinaz.com/regex/ -
正則運算式前戲:注冊手機號校驗
案例:京東注冊手機號校驗 需求:手機號必須是11位 手機號必須以13、14、15、17、18、19開頭 卻必須是純數字
"""純python代碼實作""" while True: phone_num = input('輸入您的手機號:').strip() if len(phone_num) == 11: if phone_num.isdigit(): if phone_num.startswith('13') or phone_num.startswith('14') or phone_num.startswith( '15') or phone_num.startswith('17') or phone_num.startswith('18') or phone_num.startswith('19'): print('手機號碼輸入合法') else: print('手機號碼格式錯誤') else: print('手機號碼必須是純數字') else: print('手機號碼必須11位') ———————————————————————————————————————————— """使用正則運算式實作""" import re while True: phone_num=input('輸入您的手機號:').strip() if re.match('^(13|14|15|17|18|19)[0-9]{9}$',phone_num): print('手機號合法') else: print('手機號不合法') -
正則運算式 -- 字符組
-
1.字符組默認匹配方式是:一個一個的匹配(一個符號一次匹配一個內容)
-
2.字符組內所有的資料默認都是或的關系
字符組簡寫 字符組全稱 含義 [0-9] [0123456789] 匹配0-9任意一個數字 [A-Z] [ABCDE...Z] 匹配A-Z任意一個字母 [a-z] [abcde...z] 匹配a-z任意一個字母 [0-9a-zA-Z] 匹配0-9、a-z、A-Z任意一個字母或數字
-
-
正則運算式 -- 特殊符號
-
1.字符組默認匹配方式是:一個一個的匹配
特殊符號 含義 . 匹配除換行符外的任意字符 \w 匹配數字、字母、下劃線 \W 匹配非數字、非字母、非下劃線 \d 匹配數字 ^ 匹配字串的開頭 $ 匹配字串的結尾 ^資料$ 兩者使用可以精確限制匹配的內容 a|b 匹配a或b () 給正則運算式分組 不影響運算式匹配 [] 字符組內部填寫的內容默認都是獲得關系 [^] 取反操作 匹配除了字符組內填寫的其他字符
-
-
正則運算式 -- 量詞
-
正則運算式默認情況下都是貪婪匹配(盡可能多的匹配)
-
量詞不能單獨使用 必須結合運算式一起 且只能影響左邊第一個運算式
量詞 含義 ***** 匹配0次或者多次 默認是多次 + 匹配1次或者多次 默認是多次 ? 匹配0次或者是1次 默認是1次 重復n次 寫幾次就是幾次 重復n次或者更多次 默認是多次 重復n到m次 默認是m次 -
正則運算式練習題
#正則運算式 待匹配字符 結果 海. 海燕海嬌海東 海燕 海嬌 海東 ^海. 海燕海嬌海東 海燕 海.$ 海燕海嬌海東 海東 李.? 李杰和李蓮英和李二棍子 李杰 李蓮 李二 李.* 李杰和李蓮英和李二棍子 李杰和李蓮英和李二棍子 李.+ 李杰和李蓮英和李二棍子 李杰和李蓮英和李二棍子 李.{1,2} 李杰和李蓮英和李二棍子 李杰和 李蓮英 李二棍 李[杰蓮英二棍子]* 李杰和李蓮英和李二棍子 李杰 李蓮英 李二棍子 李[^和]* 李杰和李蓮英和李二棍子 李杰 李蓮英 李二棍子 [\d] 456bdha3 4 5 6 3 [\d]+ 456bdha3 456 3
-
-
貪婪匹配與非貪婪匹配
-
1.所有的量詞匹配的都是貪婪匹配 非貪婪匹配要在后面加?
-
2.貪婪匹配與非貪婪匹配結束是由左右兩邊添加的運算式決定的
待匹配的文本: <script>alert(123)</script> 正則: <.*> # 貪婪匹配 結果: <script>alert(123)</script> ———————————————————————————————————————— 待匹配的文本: <script>alert(123)</script> 正則: <.*?> # 非貪婪匹配 結果: <script> </script>
-
-
轉義符
"""斜杠與字母的組合有時候有特殊含義""" \n 匹配的是換行符 \\n 匹配的是文本\n \\\\n 匹配的是文本\\n #在python中 可以在字串前加r取消轉義 -
正則運算式實戰建議
1.撰寫校驗用戶身份證號的正則 \d{17}[\d|x]|\d{15} 2.撰寫校驗郵箱的正則 \w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14} 3.撰寫校驗用戶手機號的正則 0?(13|14|15|17|18|19)[0-9]{9} 4.撰寫校驗用戶電話號的正則 [0-9-()()]{7,18} 5.撰寫校驗用戶qq號的正則 [1-9]([0-9]{5,11}) #很多時候有的正則已經有人幫我們做好了,只需要百度查到即可
8.re模塊
在python中使用正則 re 模塊是選擇之一
-
re模塊基本使用
-
1.findall 查找所有符合正則運算式要求的資料 結果是一個串列
# 在文本中篩選出符合a的所有內容,結果為串列 import re res=re.findall('a','abcabca') print(res) # ['a', 'a', 'a'] -
2.finditer 查找所有符合正則運算式要求的資料 結果直接是一個迭代器物件
import re res=re.finditer('a','abcabca') print(res) # <callable_iterator object at 0x000001FFA8AD7220> print(res.__next__()) # <re.Match object; span=(0, 1), match='a'> print(res.__next__().group()) # a -
3.search 匹配到一個符合條件的資料就立刻停止
import re res=re.search('a','abcabca') print(res) # <re.Match object; span=(0, 1), match='a'> print(res.group()) #a -
4.match 從頭開始匹配 如果頭不符合就結束
import re res=re.match('a','abcabca') print(res) # <re.Match object; span=(0, 1), match='a'> res1=re.match('b','abcabca') print(res1) # None -
5.compile 提前準備好正則 后續可以反復使用減少代碼冗余
import re obj=re.compile('a') print(re.findall(obj,'abcabca')) # ['a', 'a', 'a'] print(re.findall(obj,'asssdaada')) # ['a', 'a', 'a', 'a'] print(re.findall(obj,'ddffee123a')) # ['a'] -
6.split 分割
1.按照a分割得到''和'bcd' res = re.split('[a]','abcd') print(res) # ['', 'bcd'] #res后可以跟索引,索引0為空(不是None),索引1為bcd 2.按照a分割得到''和'bcd',再對''和'bcd'按照b分割得到''和'cd' res = re.split('[a,b]','abcd') print(res) # ['', '', 'cd'] -
7.sub 替換
1.把數字全部替換成'H' res = re.sub('\d','H','abc123') print(res) # abcHHH 2.把某個數字替換成'H' res = re.sub('1','H','abc123123') print(res) # abcH23H23 -
8.subn 替換
1.把數字替換成'H',并回傳元組#(替換的結果,替換的次數) res = re.subn('\d','H','abc1231') print(res) # ('abcHHHH', 4)
-
-
re模塊補充使用
-
1.分組優先
-
findall分組優先展示:優先展示括號內正則運算式匹配到的內容
res=re.findall('www.(baidu|4399).com','www.4399.com') print(res) # ['4399'] -
取消分組優先展示(?:)
res=re.findall('www.(?:baidu|4399).com','www.4399.com') print(res) # ['www.4399.com'] -
search和match針對分組()里的正則運算式不影響
res=re.search('www.(baidu|4399).com','www.4399.com') print(res.group()) # www.4399.com res=re.match('www.(baidu|4399).com','www.4399.com') print(res.group()) # www.4399.com
-
-
2.分組別名
res=re.search('www.(?P<mingzi1>baidu|4399)(?P<mingzi2>.com)','www.4399.com') print(res) # <re.Match object; span=(0, 12), match='www.4399.com'> print(res.group()) # www.4399.com print(res.group(0)) # www.4399.com print(res.group(1)) # 4399 print(res.group(2)) # .com print(res.group('mingzi1')) # 4399 print(res.group('mingzi2')) # .com
-
十三、網路爬蟲
1.什么是互聯網?
將全世界的計算機連接到一起組成的網路
2.互聯網發明的目的是什么?
讓連接到互聯網的計算機資料彼此共享
3.上網的本質是什么?
基于互聯網訪問其他人計算機上共享資料
4.爬蟲的本質是什么?
通過撰寫代碼模擬計算機瀏覽器朝目標網站發送請求獲取資料并篩選出想要的資料
5.有的網頁存在防爬機制 資料無法直接拷貝獲取(頁面會校驗是頁面發送的請求還是代碼發送的)
6.在做爬蟲時有可能會被發現導致ip短暫拉黑 不要爬用戶資料!
十四、第三方模塊
第三方模塊簡介
第三方模塊就是別人寫好的模塊 一般功能很強大
想用第三方模塊必須要下載
第三方模塊的下載
-
cmd命令列下載
1.下載必須借助pip工具(每個解釋器都有)如果電腦里面有多個版本的解釋器 要給pip加上版本號 以便區分
python27 pip2.7
python36 pip3.6
python38 pip3.8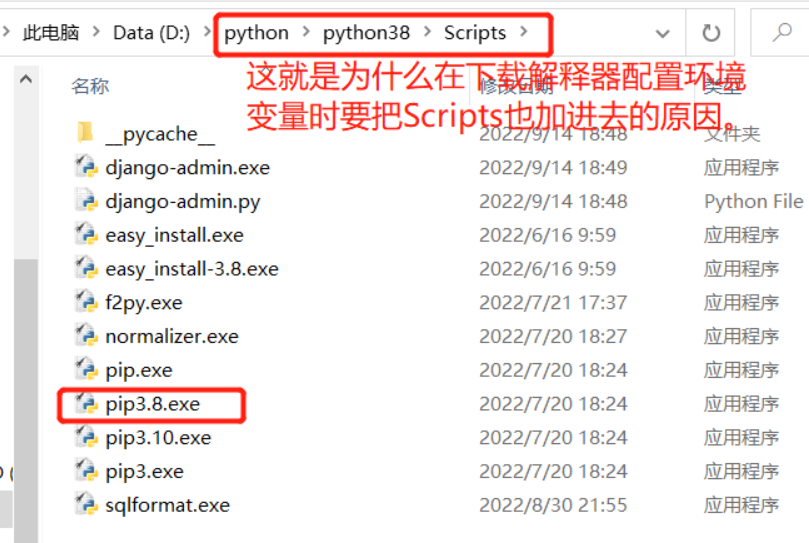
2.下載第三方模塊的句式
pip install 模塊名 pip3.8 install 模塊名3.下載第三方模塊臨時切換鏡像源地址
pip install 模塊名 -i 鏡像源地址 pip3.8 install 模塊名 -i 鏡像源地址4.下載第三方模塊指定版本
pip install 模塊名==版本號 -i 鏡像源地址 pip3.8 install 模塊名==版本號 -i 鏡像源地址 -
pycharm提供快捷下載方式
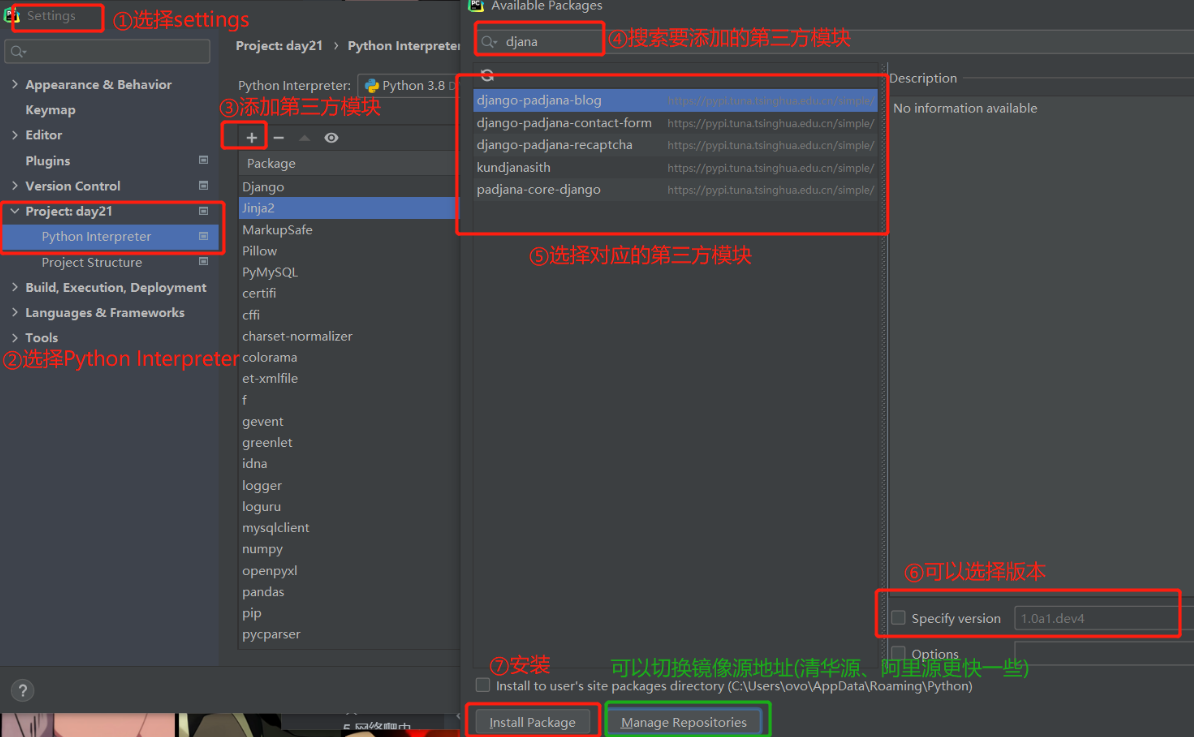
第三方模塊下載報錯
(1)報錯并有警告資訊
eg:
WARNING: You are using pip version 20.2.1;
#這種是因為pip工具版本過低,拷貝后面的執行命令更新即可:
python38 -m pip install --upgrade pip
——————————————————————————————————————————————
(2)報錯并有Timeout關鍵字
#說明當前計算機網路不穩定 只需要換網或者重新執行幾次即可
——————————————————————————————————————————————
(3)報錯并沒有關鍵字
#有可能是需要配置特定環境自行百度即可
——————————————————————————————————————————————
(4)下載速度慢
#pip默認下載的鏡像源地址是國外的地址可切換以下地址,
"""
清華大學 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中國科學技術大學 :http://pypi.mirrors.ustc.edu.cn/simple/
華中科技大學:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
騰訊源:http://mirrors.cloud.tencent.com/pypi/simple
華為鏡像源:https://repo.huaweicloud.com/repository/pypi/simple/
"""
1.request模塊(網路爬蟲模塊)
request模塊看可以模擬瀏覽器發送網路請求
超指定網址發送請求獲取頁面資料(等同于瀏覽器地址欄輸入網址按回車訪問)
import request
res = requests.get('http://www.redbull.com.cn/about/branch')
# print(res.content) # 獲取bytes二進制型別的網頁資料
print(res.text) # 獲取字串型別的網頁資料
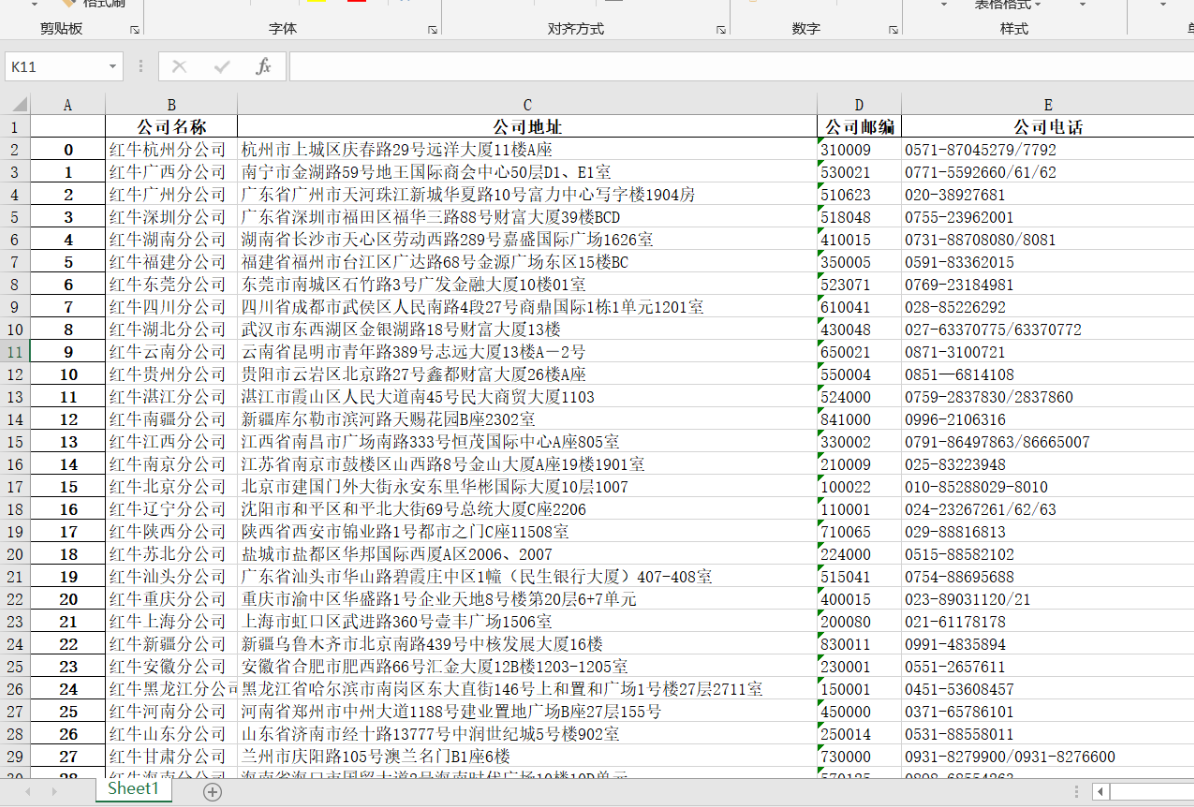
2.網路爬蟲實戰
爬紅牛分公司資料
http://www.redbull.com.cn/about/branch
import re
import requests
# 1.朝目標地址發送網路請求
# res = requests.get('http://www.redbull.com.cn/about/branch')
# print(res.content)#獲取二進制型別資料
# print(res.text)#獲取文本型別資料
# 2.將二進制資料保存在html頁面中
# with open(r'redbull.html', 'wb')as f:
# f.write(res.content)
# 3.獲取頁面字串資料
with open(r'redbull.html', 'r', encoding='utf8')as f:
data = https://www.cnblogs.com/lzy199911/p/f.read()
# 4.用正則篩選出需要的資料
comp_name_list = re.findall('<h2>(.*?)</h2>', data)
comp_address_list = re.findall("<p class='mapIco'>(.*?)</p>", data)
comp_email_list = re.findall("<p class='mailIco'>(.*?)</p>", data)
comp_phone_list = re.findall("<p class='telIco'>(.*?)</p>", data)
# 5.匯入pandas模塊將資料保存在excel表格中
import pandas
d1 = {
'公司名稱': comp_name_list,
'公司地址': comp_address_list,
'公司郵編': comp_email_list,
'公司電話': comp_phone_list
}
df = pandas.DataFrame(d1) # 將字典轉成pandas里面的DataFrame資料結構
df.to_excel('readbull.xlsx') # 保存為excel檔案
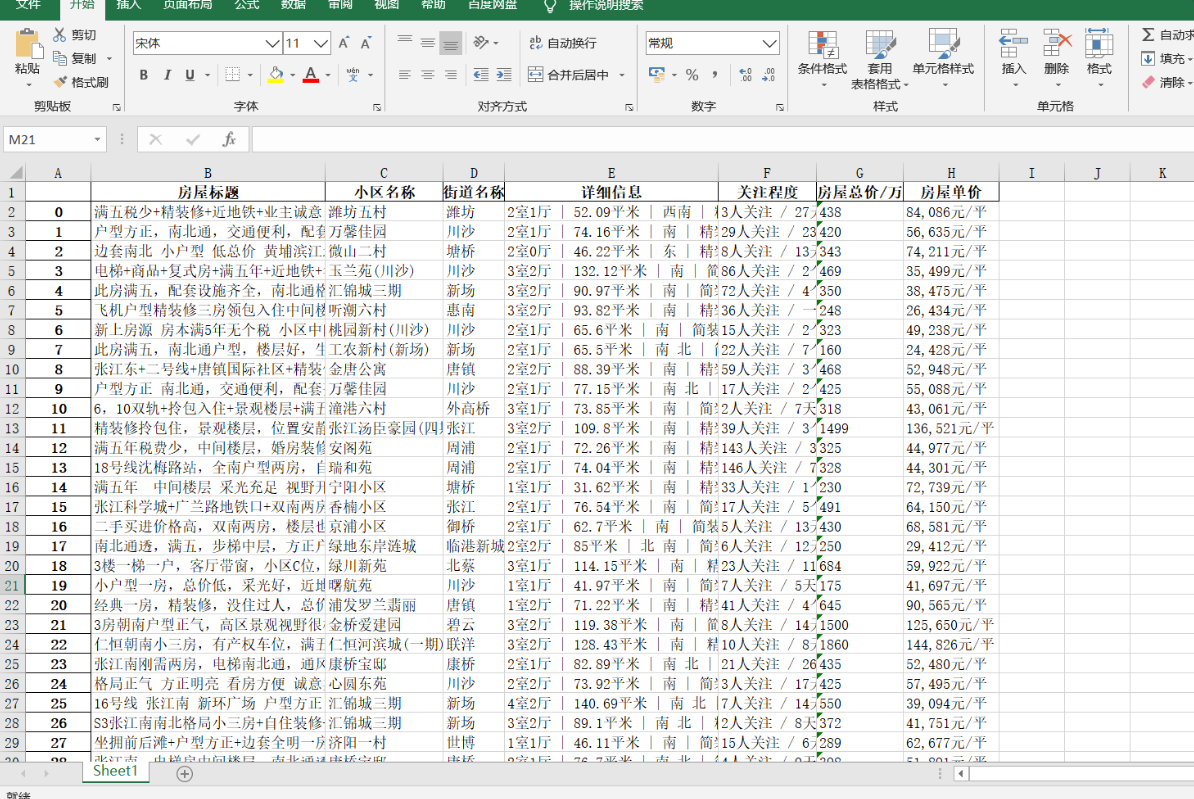
爬鏈家二手房資料
https://sh.lianjia.com/ershoufang/pudong/
import re
import requests
# 1.朝目標地址發送網路請求
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/')
data = https://www.cnblogs.com/lzy199911/p/res.text
ljhome_title_list = re.findall('<a href="https://www.cnblogs.com/lzy199911/p/.*?" target="_blank" data-log_index=".*?" data-el="ershoufang" data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>',data)
ljhome_name_list = re.findall('<a href="https://www.cnblogs.com/lzy199911/p/.*?" target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>', data)
ljhome_street_list = re.findall('<div ><span ></span><a href="https://www.cnblogs.com/lzy199911/p/.*?" target="_blank" data-log_index=".*?" data-el="region">.*? </a> - <a href="https://www.cnblogs.com/lzy199911/p/.*?" target="_blank">(.*?)</a> </div>',data)
ljhome_info_list = re.findall('<div ><span ></span>(.*?)</div>', data)
ljhome_watch_list = re.findall('<div ><span ></span>(.*?)</div>', data)
ljhome_total_price_list = re.findall('<div ><i> </i><span >(.*?)</span><i>萬</i></div>', data)
ljhome_unit_price_list = re.findall('<div data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div>', data)
import pandas
d1 = {
'房屋標題': ljhome_title_list,
'小區名稱': ljhome_name_list,
'街道名稱': ljhome_street_list,
'詳細資訊': ljhome_info_list,
'關注程度': ljhome_watch_list,
'房屋總價/萬': ljhome_total_price_list,
'房屋單價': ljhome_unit_price_list,
}
df = pandas.DataFrame(d1)
df.to_excel('ljhome.xlsx')
3.openpyxl模塊(自動辦公)
主要用于操作excel表格 也是pandas模塊底層操作表格的模塊
1.excel檔案的后綴問題
excel2003版本之前后綴名為:**.xls**
excel2003版本之后后綴名為:**.xlsx**
2.可以操作excel表格的第三方模塊
**openpyxl**是近幾年比較火的操作excel表格模塊
但是針對03版本前的excel檔案兼容較差
**xlwt**(往表格中寫資料)、**xlrd**(從表格中讀資料)
兼容所有版本的excel檔案,但是使用方法沒openpyxl簡單
還有很多可以操作excel表格的模塊:如**pandas**涵蓋了上述模塊的模塊
3.創建檔案、寫入資料、保存資料操作
當該excel檔案打開時不能任何修改 不要忘記保存檔案
1.創建excel檔案
from openpyxl import Workbook # 匯入模塊,Workbook是用來創建檔案的
# 創建一個excel檔案
wb = Workbook()
# 在excel檔案中創建作業薄
wb1 = wb.create_sheet('學生名單')
# 在excel檔案中創建作業薄 并 讓該作業薄位置在最前面
wb2 = wb.create_sheet('老師名單', 0)
# 修改作業簿名稱
wb2.title = '學生成績單'
# 修改作業薄顏色
wb2.sheet_properties.tabColor = '1072BA'
"""
這里放寫入資料的操作
"""
# 保存該excel檔案
wb.save(r'學生資訊.xlsx')
2.在excel作業簿中寫入資料
寫入后記得保存
1)第一種寫入方式:
wb2['A1'] = '張三' # 在A1單元格中寫入'張三'
2)第二種寫入方式:
wb2.cell(row=2,column=1,value='https://www.cnblogs.com/lzy199911/p/李四') # 在單元格第2行,第1列,寫入'李四'
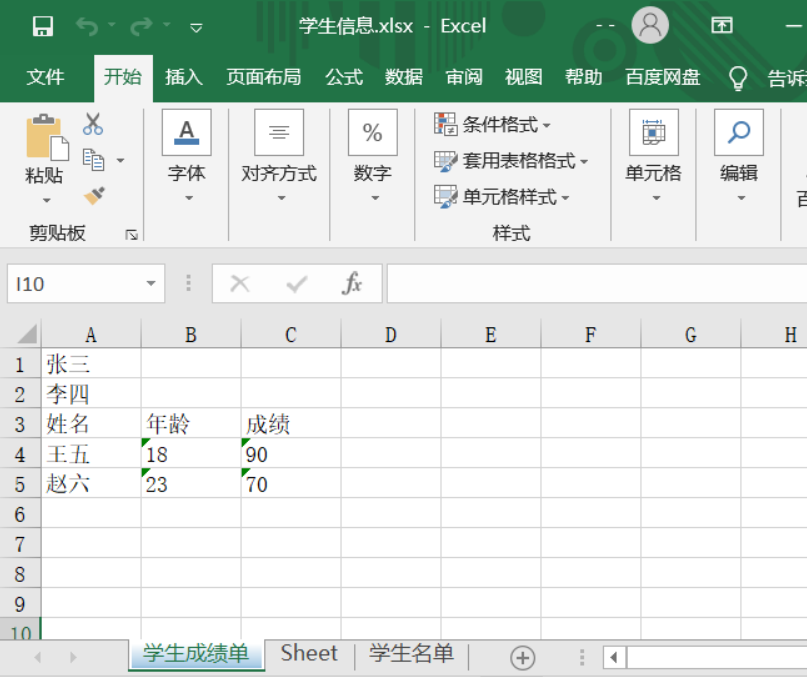
3)第三種寫入方式:(批量寫入)
#在單元格中最上方分別寫入資料(如果有資料則在資料下一行寫入)
wb2.append(['姓名','年齡','成績'])
wb2.append(['王五','18','90'])
3.填寫數學公式
wb2['A5']='=sum(A1:A4)' # 在A5單元格寫入sum公式
wb2.cell(row=5,column=1,value='https://www.cnblogs.com/lzy199911/p/=sum(A1:A4)') # 在第5行,第1列寫入sum公式
4.pandas 模塊也可以是實作資料寫入
使用pandas模塊時需要注意字典里面的v值必須是串列的形式
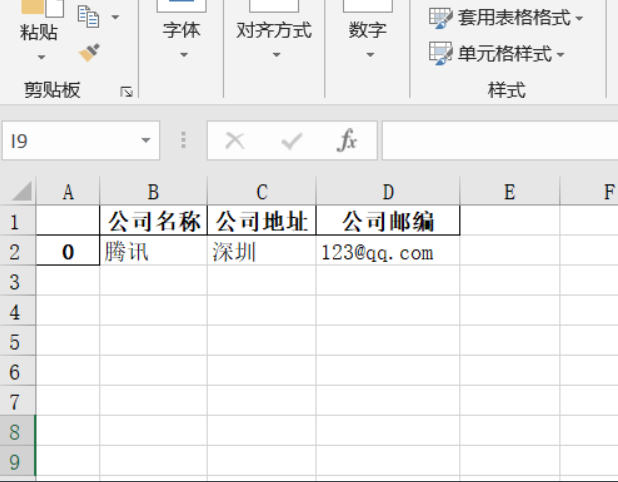
import pandas
company_name='騰訊'
company_address='深圳'
company_email='[email protected]'
data=https://www.cnblogs.com/lzy199911/p/{'公司名稱':[company_name,],
'公司地址':[company_address,],
'公司郵編':[company_email,],
}
df = pandas.DataFrame(data)#將字典轉成pandas里面的DataFrame資料結構
df.to_excel('a.xlsx')#保存為excel檔案
4.讀取資料操作
openpyxl時讀寫分離的(寫與讀是兩個不同的模塊 需要在后面在加一個load_workbook)
"""
openpyxl不擅長讀資料,所以有些模塊優化了讀取的方式:pandas模塊
一般在公司會有專門的人負責讀,python程式員只負責寫出來
"""
#【創建寫入資料】
from openpyxl import Workbook,load_workbook
# 創建一個excel檔案
wb=Workbook()
# 創建sheet頁
wb1=wb.create_sheet('第一個sheet頁',0)
wb2=wb.create_sheet('第二個sheet頁',1)
# 批量寫入資料
wb1.append(['姓名','年齡'])
wb1.append(['jason','18'])
wb1.append(['torry','20'])
# 保存檔案
wb.save('ipenpyxl寫讀練習.xlsx')
___________________________________________________________
#【讀取資料】
# 1.查看檔案中所有作業簿名稱
print(wb.sheetnames) # ['第一個sheet頁', '第二個sheet頁', 'Sheet']
# 2.1.查看某作業簿中有幾行資料,空資料默認為1行
print(wb1.max_row) # 3
# 2.2查看某作業簿中有幾列資料,空資料默認為1列
print(wb1.max_column) # 2
# 3.1.讀取wb1中A1單元格的資料
print(wb1['A1'].value) # 姓名
# 3.2.讀取wb1中第2行第1列的資料
print(wb1.cell(row=2,column=1).value) # jason
# 4.讀取整行資料并組成串列
for i in wb1.rows:
print([j.value for j in i]) # ['姓名', '年齡'] ['jason', '18'] ['torry', '20']
# 5.讀取整列資料并組成串列
for i in wb1.columns:
print([j.value for j in i]) # ['姓名', 'jason', 'torry'] ['年齡', '18', '20']
4.pandas模塊
封裝了openyxl模塊的模塊 主要也是操作表格的 如上面的爬蟲爬渠道的資料后用pandas保存到excel表中
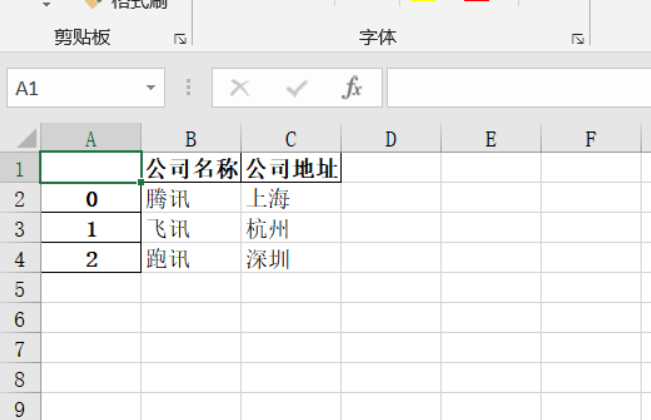
import pandas
d1 = {
'公司名稱': ['騰訊', '飛訊', '跑訊'],
'公司地址': ['上海', '杭州', '深圳'],
}
df = pandas.DataFrame(d1) # 將字典轉成pandas里面的DataFrame資料結構
df.to_excel(r'公司資訊.xlsx') # 保存為excel檔案
5.hashilib加密模塊
1.什么是加密?
將明文資料經過處理后變成密文資料的程序就是加密
2.為什么要加密?
不想讓敏感資料輕易泄露
3.如何判斷當前資料是否已加密?
一般加密的都是遺傳沒有規則的字母、數字、符號的組合
4.加密演算法就是對銘文資料采用的加密策略
不同的加密演算法復雜程度也不同 得出的密文長度也不同 一般密文越長說明就越復雜
5.常見的加密演算法
md5、sha系列、hmac、base64
6.代碼實操
import hashlib
# 選擇加密演算法
md5 = hashlib.md5()
# 傳入明文資料(傳入的必須是二進制)
md5.update(b'hello')
# 獲取加密密文
res = md5.hexdigest()
print(res) # 202cb962ac59075b964b07152d234b70
————————————————————————————————————————————————————
import hashlib
# 獲取用戶輸入密碼
password = input('輸入密碼:').strip()
# 選擇加密演算法
md5 = hashlib.md5()
# 傳入明文資料(傳入的必須是二進制)
md5.update(password.encode('utf8'))
# 獲取加密密文
res = md5.hexdigest()
print(res)
7.注意事項
1.相同內容不管分幾次傳結果都是一樣的
加密演算法不變 內容相同 結果肯定相同
import hashlib
# 選擇加密演算法
md5 = hashlib.md5()
# 傳入明文資料
# md5.update(b'aa~bb~')
md5.update(b'aa~')
md5.update(b'bb~')
# 獲取加密密文
res = md5.hexdigest()
print(res)
#發現只要是相同的明文,不管是一次性傳入還是分多次傳入結果都一樣
2.加密后的結果無法反向解密
只能從銘文到密文正向推導 不能從密文到銘文反向推導
常見的解密其實是提前預測了很多結果去一對一匹配
3.加鹽處理
在明文中額外加一些干擾項
import hashlib
md5 = hashlib.md5()
md5.update('加鹽'.encode('utf8')) # '加鹽'為干擾項
md5.update(b'123456')
res = md5.hexdigest()
print(res)
4.動態加鹽
干擾項可以隨機變化的(當前時間、用戶名)
5.加密實際應用場景
1.用戶加密
注冊存盤的是密文,'登錄校驗時也是在對比密文'
2.檔案安全性內容加密校驗
正規的軟體程式寫完都會做一個'內容加密',用戶下載完軟體后會'先對比加密后的密文是否一致',不一致可能被植入了病毒,一致則運行軟體
3.大檔案內容加密
當一個檔案特別大時,一次性加密效率太低
所以會采用'截取一部分來加密'
#os.path.getsize() 獲取檔案大小
6.subprocess模塊
模擬作業系統終端 執行系統命令并獲取結果
import subprocess
cmd = input('輸入cmd指令:').strip()
res = subprocess.Popen(
cmd, # 獲取用戶要執行的指令
shell=True, # 固定配置
stdin=subprocess.PIPE, # 輸入指令
stdout=subprocess.PIPE, # 輸出結果
)
# 獲取作業系統執行命令后的正確結果
print('正確結果:', res.stdout.read().decode('gbk'))
# 獲取作業系統執行命令后的錯誤結果
print('錯誤結果:', res.stderr)
7.loggin 日志模塊
1.如何處理日志
簡單的理解就是記錄行為舉止的操作
2.日志的五種級別
import logging
logging.debug('debug等級') # 10 默認不顯示
logging.info('info等級') # 20 默認不顯示
logging.warning('警告的') # 30 默認從warning級別開始記錄
logging.error('已經發生的') # 40
logging.critical('災難性的') # 50
3.日志模塊的要求與基本使用
無需掌握 了解怎么用即可
import logging
# 產生一個日志檔案,檔案叫x1.log,用a追加模式,編碼為utf8
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf8',)
logging.basicConfig(
# 日志格式
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# 年月日 時分秒 上午下午
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
# ERROR級別
level=logging.ERROR)
logging.error('你好')
4.日志的四個組成部分
-
logger物件:產生日志
-
fifter物件:過濾日志
-
handler物件:輸出日志
-
format物件:日志格式
import logging # 1.日志的產生(準備原材料) logger物件 logger = logging.getLogger('購物車記錄') # 2.日志的過濾(剔除不良品) filter物件>>>:可以忽略 不用使用 # 3.日志的產出(成品) handler物件 # hd1~hd3三選一 hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 輸出到a1.log檔案中 hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 輸出到a1.log檔案中 hd3 = logging.StreamHandler() # 輸出到終端 # 4.日志的格式(包裝) formmat物件 # fm1與fm2格式復雜度二選一即可 fm1 = logging.Formatter( fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', ) fm2 = logging.Formatter( fmt='%(asctime)s - %(name)s: %(message)s', datefmt='%Y-%m-%d', ) # 5.給logger物件系結handler物件 logger.addHandler(hd1) logger.addHandler(hd2) logger.addHandler(hd3) # 6.給handler系結formate物件 hd1.setFormatter(fm1) hd2.setFormatter(fm2) hd3.setFormatter(fm1) # 7.設定日志等級 logger.setLevel(10) # debug # 8.記錄日志 logger.debug('寫了半天 好累啊 好熱啊')
5.日志配字典
import logging
import logging.config
# 定義日志輸出格式 開始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name為getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定義檔案路徑
logfile_path = 'a3.log'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 過濾日志
'handlers': {
# 列印到終端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 列印到螢屏
'formatter': 'simple'
},
# 列印到檔案的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到檔案
'formatter': 'standard',
'filename': logfile_path, # 日志檔案
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志檔案的編碼,再也不用擔心中文log亂碼了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 這里把上面定義的兩個handler都加上,即log資料既寫入檔案又列印到螢屏
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)傳遞
}, # 當鍵不存在的情況下 (key設為空字串)默認都會使用該k:v配置
# '購物車記錄': {
# 'handlers': ['default','console'], # 這里把上面定義的兩個handler都加上,即log資料既寫入檔案又列印到螢屏
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)傳遞
# }, # 當鍵不存在的情況下 (key設為空字串)默認都會使用該k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自動加載字典中的配置
# logger1 = logging.getLogger('購物車記錄')
# logger1.warning('尊敬的VIP客戶 晚上好 您又來啦')
# logger1 = logging.getLogger('注冊記錄')
# logger1.debug('jason注冊成功')
logger1 = logging.getLogger('紅浪漫顧客消費記錄')
logger1.debug('慢男 猛男 騷男')
6.日志模塊實戰應用
1.#【start.py】 先找到根目錄路徑 添加到sys.path中(為了兼容讓任何人打開都可以找到根目錄)
import os
import sys
base_dir=os.path.dirname(os.path.dirname(__file__))
sys.path.append(base_dir)
if __name__ == '__main__':
from ATM.core import src
src.run()
2.#【settings.py】 將日志代碼寫在組態檔中
import os
# 定義日志輸出格式 開始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name為getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定義檔案路徑
#logfile_path = 'a3.log'
BASE_DIR=os.path.dirname(os.path.dirname(__file__))
LOG_DIR=os.path.join(BASE_DIR,'log')
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
logfile_path=os.path.join(LOG_DIR,'log.log') # 【可以起一個日志名字.log】
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 過濾日志
'handlers': {
# 列印到終端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 列印到螢屏
'formatter': 'simple'
},
# 列印到檔案的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到檔案
'formatter': 'standard',
'filename': logfile_path, # 日志檔案
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5, # 最多保存5份5M的檔案,個數夠了就刪第一個
'encoding': 'utf-8', # 日志檔案的編碼,再也不用擔心中文log亂碼了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 這里把上面定義的兩個handler都加上,即log資料既寫入檔案又列印到螢屏
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)傳遞
}, # 當鍵不存在的情況下 (key設為空字串)默認都會使用該k:v配置
},
}
3.#【common.py】 公共功能檔案中創建一個函式,誰用誰調
import logging
import logging.config
from conf import settings
def get_my_logger(name):
logging.config.dictConfig(settings.LOGGING_DIC) # 自動加載字典中的配置
logger1 = logging.getLogger(name)
return logger1
4.#【user_interface.py】 介面層呼叫公共檔案里的日志函式
from ATM.lib import common
my_log = common.get_my_logger('用戶相關記錄') # 【給該日志起名】
def register_interface():
my_log.info('xxx注冊成功') # 【info級別記錄日志內容】
def login_interface():
my_log.debug('xxx登錄成功') # 【debug級別記錄日志內容】
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/542407.html
標籤:Python
上一篇:淺談PHP設計模式的組合模式
下一篇:Python內置函式