最近在寫一個基于代理池的高并發爬蟲,目標是用單機從某網站 API 爬取十億級別的JSON資料,
代理池
有兩種方式能夠實作爬蟲對代理池的充分利用:
- 搭建一個 Tunnel Proxy 服務器維護代理池
- 在爬蟲專案內部自動切換代理
所謂 Tunnel Proxy 實際上是將切換代理的操作交給了代理服務器,很多市面上的代理軟體都有此類功能,
如果要自行搭建可參考以下專案:
-
GitHub - urdr-gungnir/TunnelProxy
-
GitHub - pingc0y/go_proxy_pool
考慮到高并發,在爬蟲專案內部切換代理更加靈活一些,代理池選一個能用的就行:GitHub - jhao104/proxy_pool
記得加上匿名校驗:能否設定代理池只獲取高匿IP · Issue #169 · jhao104/proxy_pool · GitHub
代理切換策略
如果簡單的在多執行緒中對每個 requests.get() 使用不同的代理,那么一定會遇到記憶體泄露的問題:
- 記憶體泄露問題 · Issue #522 · jhao104/proxy_pool · GitHub
- Requests memory leak · Issue #4601 · psf/requests · GitHub
- Memory Leak in Python requests - GeeksforGeeks
即便寫成:
session = requests.session()
response = session.get(url, headers=headers, proxies=proxies)
response.close()
session.close()
甚至在加上 gc.collect() 也無濟于事,
因此需要控制創建 session 物件的數量,只在請求失敗后切換代理和創建新的 session,
作業流程
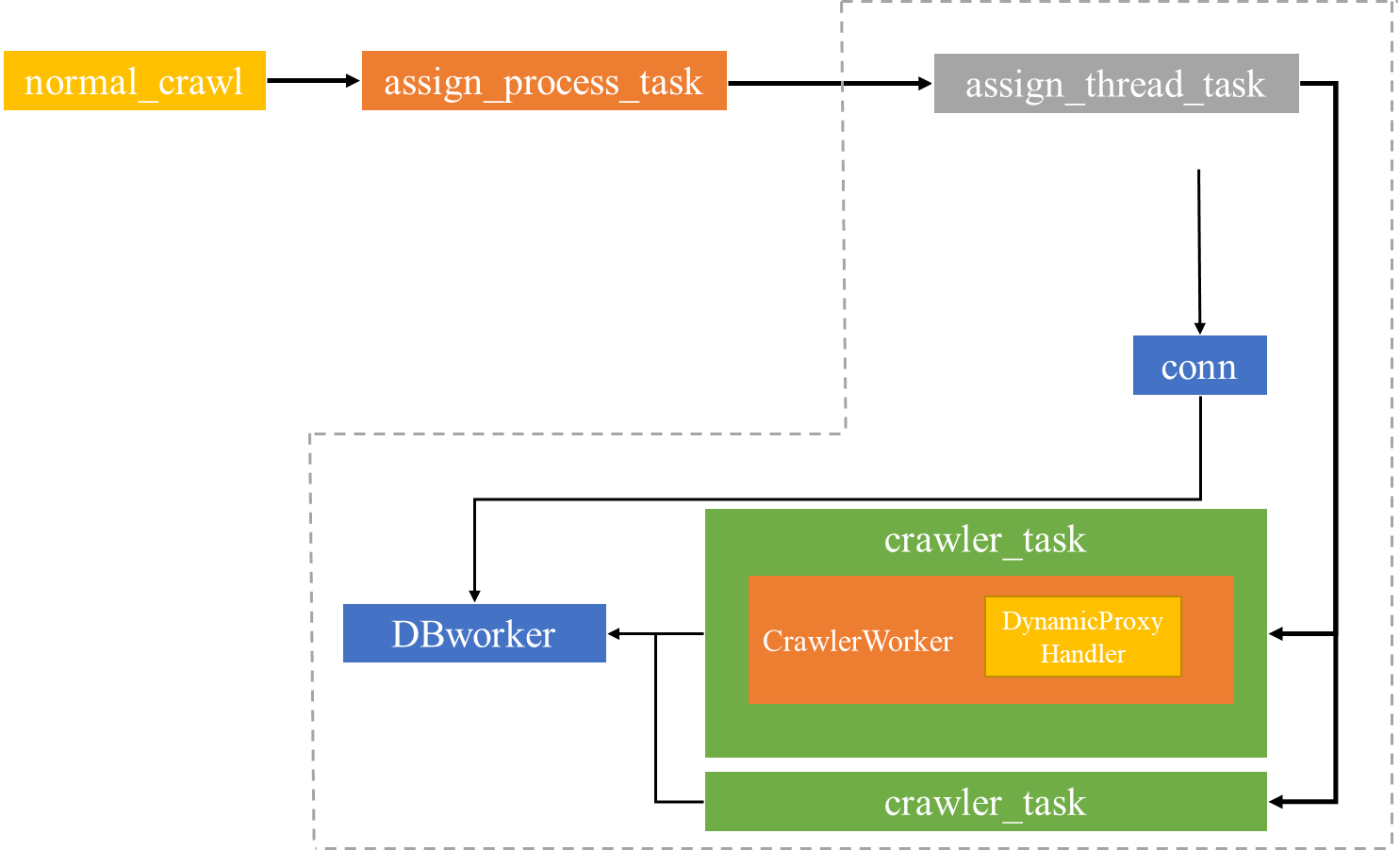
① 主執行緒根據 URL 數量動態創建子行程,虛線框內為子行程任務
② crawler_task 為執行緒任務,執行發送請求和決議JSON
插入策略
每個子行程維護一個 url_queue 和 insert_queue,
執行緒會從 url_queue 取出URL執行爬取任務,由于JSON資料占用的空間不大,所以執行緒會先將每個 response 經過簡單決議后存到串列中,
等到 url_queue 為空時(不要使用不安全的 queue.empty() 判斷),get 方法會觸發 Timeout 例外,然后執行緒會將串列插入到 insert_queue 中,
所有執行緒任務結束后,子行程再執行 executemany 將資料批量插入到 MySQL,
其他
爬取JSON資料產生的流量不大,但需要考慮 PPS(packet per second),如果網路設施不到位的話可能嚴重影響爬取效率,
網路上獲取的免費代理大多是透明代理,如果使用開源專案 Proxy_Pool 作為代理池并加入匿名校驗,可能會間歇性導致代理池沒有可用代理,(所以最好還是從一些網路空間測繪引擎上通過特征抓取)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/542583.html
標籤:其他
下一篇:rust寫一個im聊天服務