19 | 分布式環境下如何快速定位問題?
分布式環境下定位問題有什么難點?
分布式環境下定位問題的難點在于,各子應用、子服務之間有復雜的依賴關系,我們有時很難確定是哪個服務的哪個環節出現的問題,如果要通過日志來排查問題,就需要對每個子應用、子服務逐一進行排查,很難一步到位,
在分布式環境下如何快速定位問題?
有兩種方式:
- 借助合理封裝的例外資訊
- 借助分布式鏈路跟蹤
RPC框架列印的例外資訊中,需要包含定位問題所需要的例外資訊的,比如哪些例外引起的問題(如序列化問題或網路超時問題),是呼叫端還是服務端出現的例外,呼叫端與服務端的IP是多少,以及服務介面與服務分組是什么等等,
例外的示意圖如下所示,

一款優秀的RPC框架要對例外進行詳細地封裝,還要對各類例外進行分類,每類例外都要有明確的例外標識碼,并整理成一份簡明的檔案,適用房可以快速地通過例外標識碼在檔案中查閱,從而快速定位問題,找到原因,并且例外資訊中藥包含排查問題時所需要的重要資訊,比如服務介面名、服務分組、呼叫端和服務端的IP,以及產生例外的原因,總之,要讓適用房在復雜的分布式應用系統重,根據例外資訊快速地定位到問題,
分布式鏈路跟蹤可以讓我們快速的知道整個服務呼叫的鏈路資訊以及被呼叫的各個服務是否存在問題,例如服務A呼叫下游服務B,服務B又呼叫了B依賴的下游服務,如果服務A可以清楚的知道整個呼叫鏈路,并且能準確的直到呼叫鏈路中個服務的狀態,那么就可以快速的定位問題,
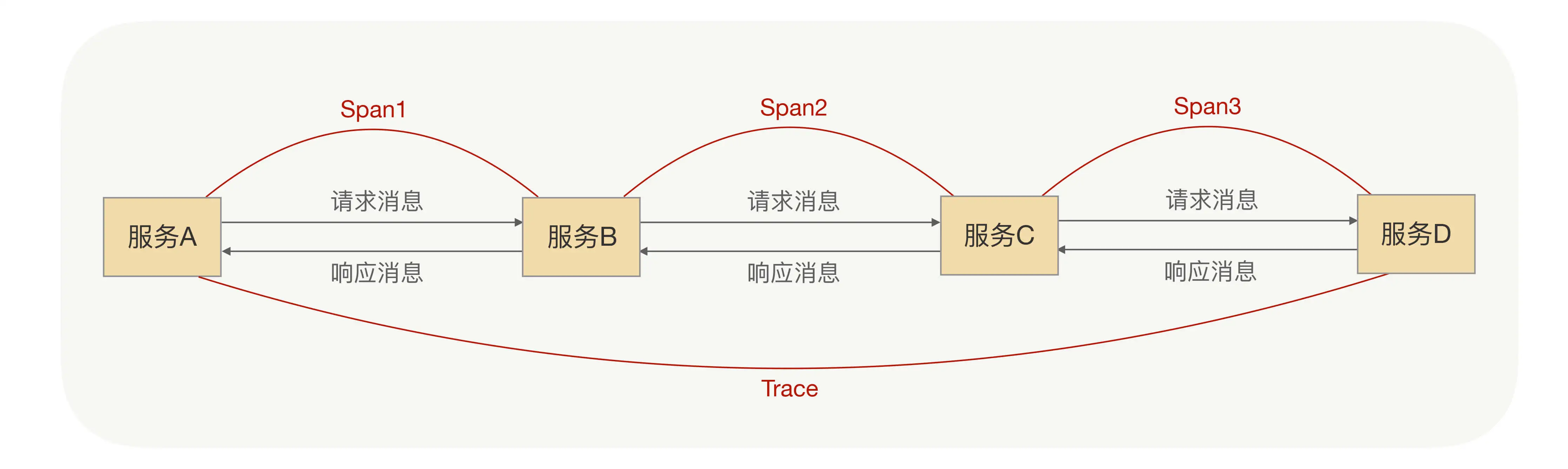
分布式鏈路跟蹤有Trace和Span兩個關鍵概念:
- Trace:代表整個鏈路,每次分布式都會產生一個Trace,每個Trace都有它的唯一標識,即TraceId,在分布式鏈路跟蹤系統重,就是通過TraceId來區分每個Trace的,
- Span:代表了整個鏈路的一段鏈路,也就說Trace是由多個Span組成的,在一個Trace下,每個Span也有唯一的標識SpanId,而Span之間是存在父子關系的,
Trace和Span的關系如下圖所示,
RPC在整合分布式鏈路跟蹤所需要做的核心事情有2件:
- 埋點:分布式鏈路跟蹤系統要想獲得一次分布式呼叫的完整鏈路資訊,就必須對這次分布式呼叫進行資料采集,而采集這些資料的方法就是通過RPC框架對分布式鏈路跟蹤進行埋點,RPC呼叫端在訪問服務端時,在發送請求訊息前會觸發分布式跟蹤埋點,在接收到服務端回應時,也會觸發分布式跟蹤埋點,并且在服務端也會有類似的埋點,這些埋點最終可以記錄一個完整的Span,而這個鏈路的源頭會記錄一個完整的Trace,最終Trace資訊也會上報給分布式鏈路跟蹤系統,
- 傳遞:上游呼叫端將Trace資訊與父Span資訊傳遞給下游服務的服務端,由下游觸發埋點,對這些資訊進行處理,在分布式鏈路跟蹤系統重,每個子Span都存有父Span的相關資訊以及Trace的相關資訊,
20 | 詳解時鐘輪在RPC中的應用
RPC中的定時任務應該如何處理?
- 針對有定時需求的請求,建立額外的執行緒,使用Thread.sleep方法來處理,
- 建立一個單獨的執行緒,來持續掃描有定時需求的請求,判斷是否到時間了,
- 使用時鐘輪方法
在時鐘輪機制中,有時間槽和時鐘輪的概念,時間槽相當于時鐘的刻度,時鐘輪箱單與秒針與分針等跳動的一個周期,我們會將每個人物放到相應的時間槽位上,
時鐘輪的運行機制和生活中的時鐘是一樣的,每隔固定的單位時間,就會從一個時間槽位調到下一個時間槽位,這就相當于我們的秒針跳動了一次;時鐘輪可以分為多層,下一層時鐘輪中每個槽位的單位時間是當前時間輪整個周期的時間,這就相當于1分鐘等于60秒鐘;當時鐘輪將一個周期的所有槽位都跳動完后,就會從下一層時鐘輪中取出一個槽位的任務,重新分不到當前的時鐘輪中,當前時鐘輪則從第0槽位開始重新跳動,這就相當于下一分鐘的第1秒,
在RPC框架中哪些功能會用到時鐘輪?
- 呼叫端請求超時處理,我們每發一次請求,都創建一個處理請求超時的定時任務放到時鐘輪里,在高并發、高訪問量的情況下,時鐘輪每次只輪詢一個時間槽位中的任務,這樣會節省大量的CPU,
- 心跳檢測,對于這種需要重復執行的定時任務,我們可以在定時任務執行邏輯的最后,重設這個任務的執行時間,把它重新丟回到時鐘輪里面,
在使用時間輪時,我們需要注意兩件事情:
- 時間槽位的單位時間越短,時間輪觸發任務的時間就越精確,
- 時間輪的槽位越多,那么一個任務唄重復掃描的概率就越小,因為只有在多層時鐘輪中的任務才會被重復掃描,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/542675.html
標籤:Java
上一篇:java執行緒基礎
下一篇:day15-宣告式事務