索引(index)是幫助MySQL高效獲取資料的資料結構(有序),在資料之外,資料庫系統還維護著滿足 特定查找演算法的資料結構,這些資料結構以某種方式參考(指向)資料, 這樣就可以在這些資料結構 上實作高級查找演算法,這種資料結構就是索引,

優缺點:
優點:
- 提高資料檢索效率,降低資料庫的IO成本
- 通過索引列對資料進行排序,降低資料排序的成本,降低CPU的消耗
缺點:
- 索引列也是要占用空間的
- 索引大大提高了查詢效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
索引結構
| 索引結構 | 描述 |
|---|---|
| B+Tree | 最常見的索引型別,大部分引擎都支持B+樹索引 |
| Hash | 底層資料結構是用哈希表實作,只有精確匹配索引列的查詢才有效,不支持范圍查詢 |
| R-Tree(空間索引) | 空間索引是 MyISAM 引擎的一個特殊索引型別,主要用于地理空間資料型別,通常使用較少 |
| Full-Text(全文索引) | 是一種通過建立倒排索引,快速匹配檔案的方式,類似于 Lucene, Solr, ES |
- 上述是MySQL中所支持的所有的索引結構,接下來,我們再來看看不同的存盤引擎對于索引結構的支持 情況,
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
注意: 我們平常所說的索引,如果沒有特別指明,都是指B+樹結構組織的索引,
二叉樹
假如說MySQL的索引結構采用二叉樹的資料結構,比較理想的結構如下:
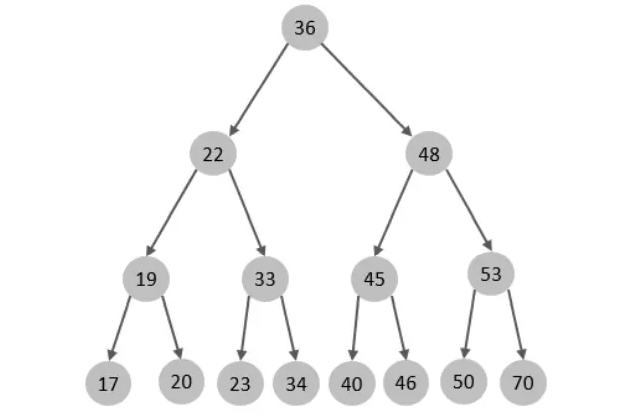
如果主鍵是順序插入的,則會形成一個單向鏈表,結構如下:
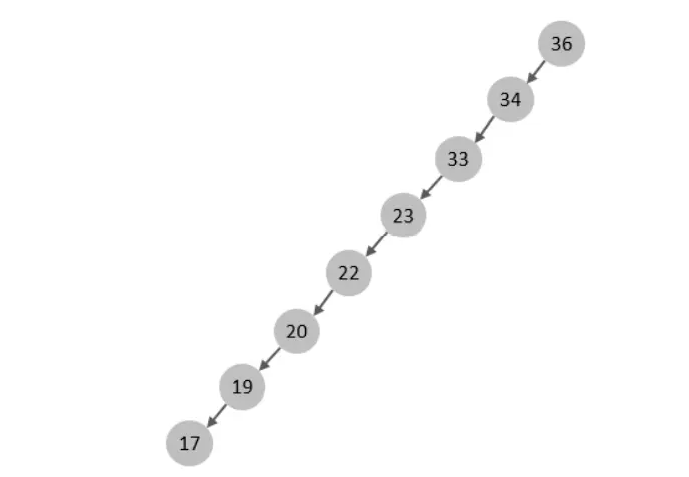
所以,如果選擇二叉樹作為索引結構,會存在以下缺點:
- 順序插入時,會形成一個鏈表,查詢性能大大降低,
- 大資料量情況下,層級較深,檢索速度慢,
此時大家可能會想到,我們可以選擇紅黑樹,紅黑樹是一顆自平衡二叉樹,那這樣即使是順序插入資料,最終形成的資料結構也是一顆平衡的二叉樹,結構如下:
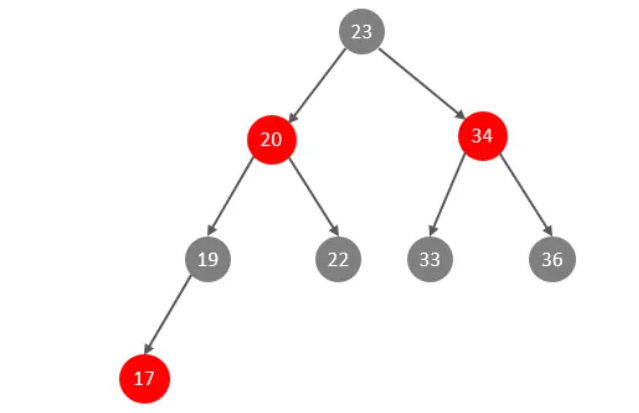
但是,即使如此,由于紅黑樹也是一顆二叉樹,所以也會存在一個缺點:
- 大資料量情況下,層級較深,檢索速度慢,
所以,在MySQL的索引結構中,并沒有選擇二叉樹或者紅黑樹,而選擇的是B+Tree,那么什么是B+Tree呢?在詳解B+Tree之前,先來介紹一個B-Tree,
B-Tree
B-Tree,B樹是一種多路衡查找樹,相對于二叉樹,B樹每個節點可以有多個分支,即多叉,以一顆最大度數(max-degree)為5(5階)的b-tree為例,那這個B樹每個節點最多存盤4個key,5個指標:
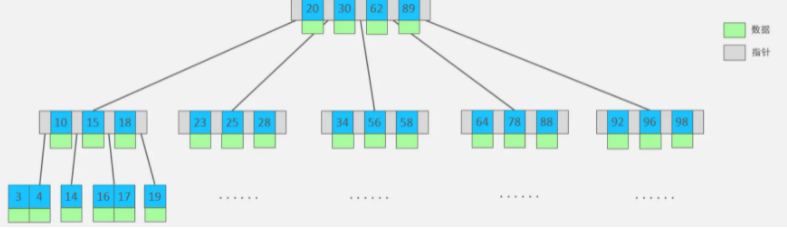
樹的度數指的是一個節點的子節點個數,
我們可以通過一個資料結構可視化的網站來簡單演示一下,B-Tree Visualization (usfca.edu)(opens new window)

插入一組資料: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88 120 268 250 ,然后觀察一些資料插入程序中,節點的變化情況,
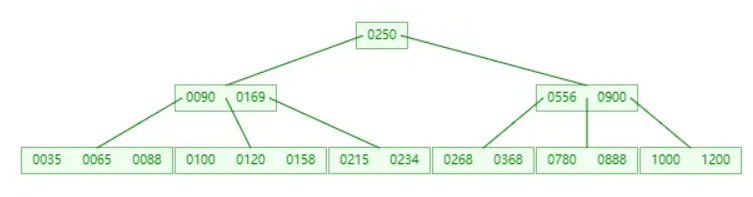
特點:
- 5階的B樹,每一個節點最多存盤4個key,對應5個指標,
- 一旦節點存盤的key數量到達5,就會裂變,中間元素向上分裂,
- 在B樹中,非葉子節點和葉子節點都會存放資料,
B+Tree
B+Tree是B-Tree的變種,我們以一顆最大度數(max-degree)為4(4階)的b+tree為例,來看一下其結構示意圖:
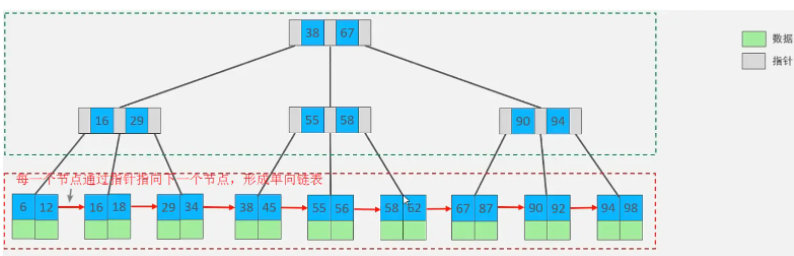
我們可以看到,兩部分:
- 綠色框框起來的部分,是索引部分,僅僅起到索引資料的作用,不存盤資料,
- 紅色框框起來的部分,是資料存盤部分,在其葉子節點中要存盤具體的資料,
我們可以通過一個資料結構可視化的網站來簡單演示一下,B+ Tree Visualization (usfca.edu)(opens new window)

插入一組資料: 100 65 169 368 900 556 780 35 215 1200 234 888 158 90 1000 88 120 268 250 ,然后觀察一些資料插入程序中,節點的變化情況,

最終我們看到,B+Tree 與 B-Tree相比,主要有以下三點區別:
- 所有的資料都會出現在葉子節點,
- 葉子節點形成一個單向鏈表,
- 非葉子節點僅僅起到索引資料作用,具體的資料都是在葉子節點存放的,
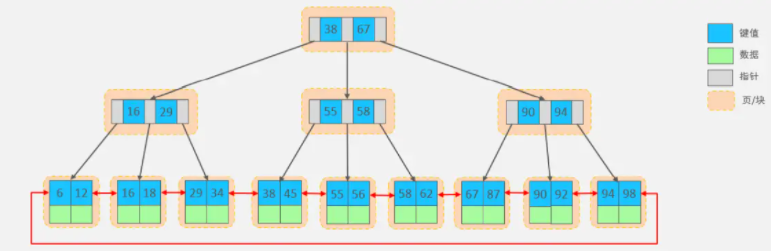
上述我們所看到的結構是標準的B+Tree的資料結構,接下來,我們再來看看MySQL中優化之后的B+Tree,
MySQL索引資料結構對經典的B+Tree進行了優化,在原B+Tree的基礎上,增加一個指向相鄰葉子節點的鏈表指標,就形成了帶有順序指標的B+Tree,提高區間訪問的性能,利于排序,
Hash
MySQL中除了支持B+Tree索引,還支持一種索引型別---Hash索引,
- 結構
哈希索引就是采用一定的hash演算法,將鍵值換算成新的hash值,映射到對應的槽位上,然后存盤在hash表中,
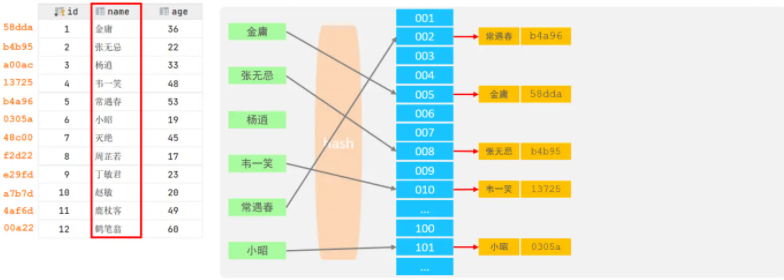
如果兩個(或多個)鍵值,映射到一個相同的槽位上,他們就產生了hash沖突(也稱為hash碰撞),可以通過鏈表來解決,
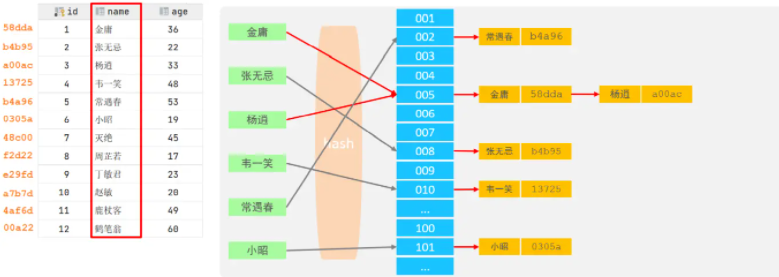
- 特點
- Hash索引只能用于對等比較(=,in),不支持范圍查詢(between,>,< ,...)
- 無法利用索引完成排序操作
- 查詢效率高,通常(不存在hash沖突的情況)只需要一次檢索就可以了,效率通常要高于B+tree索引
- 存盤引擎支持
在MySQL中,支持hash索引的是Memory存盤引擎, 而InnoDB中具有自適應hash功能,hash索引是 InnoDB存盤引擎根據B+Tree索引在指定條件下自動構建的,
思考題: 為什么InnoDB存盤引擎選擇使用B+tree索引結構?
- 相對于二叉樹,層級更少,搜索效率高;
- 對于B-tree,無論是葉子節點還是非葉子節點,都會保存資料,這樣導致一頁中存盤的鍵值減少,指標跟著減少,要同樣保存大量資料,只能增加樹的高度,導致性能降低;
- 相對Hash索引,B+tree支持范圍匹配及排序操作;
索引的分類
在MySQL資料庫,將索引的具體型別主要分為以下幾類:主鍵索引、唯一索引、常規索引、全文索引,
| 分類 | 含義 | 特點 | 關鍵字 |
|---|---|---|---|
| 主鍵索引 | 針對于表中主鍵創建的索引 | 默認自動創建,只能有一個 | PRIMARY |
| 唯一索引 | 避免同一個表中某資料列中的值重復 | 可以有多個 | UNIQUE |
| 常規索引 | 快速定位特定資料 | 可以有多個 | |
| 全文索引 | 全文索引查找的是文本中的關鍵詞,而不是比較索引中的值 | 可以有多個 | FULLTEXT |
在 InnoDB 存盤引擎中,根據索引的存盤形式,又可以分為以下兩種:
| 分類 | 含義 | 特點 |
|---|---|---|
| 聚集索引(Clustered Index) | 將資料存盤與索引放一塊,索引結構的葉子節點保存了行資料 | 必須有,而且只有一個 |
| 二級索引(Secondary Index) | 將資料與索引分開存盤,索引結構的葉子節點關聯的是對應的主鍵 | 可以存在多個 |
聚集索引選取規則:
- 如果存在主鍵,主鍵索引就是聚集索引
- 如果不存在主鍵,將使用第一個唯一(UNIQUE)索引作為聚集索引,
- 如果表沒有主鍵,或沒有合適的唯一索引,則InnoDB會自動生成一個rowid作為隱藏的聚集索 引,
聚集索引和二級索引的具體結構如下:
演示圖:
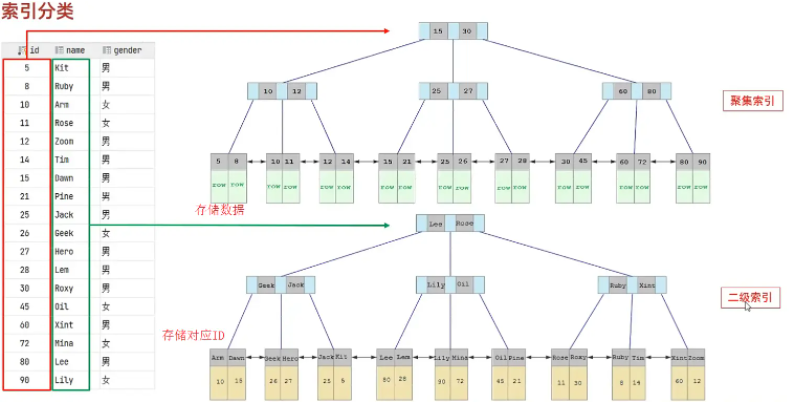
- 聚集索引的葉子節點下掛的是這一行的資料 ,
- 二級索引的葉子節點下掛的是該欄位值對應的主鍵值,
接下來,我們來分析一下,當我們執行如下的SQL陳述句時,具體的查找程序是什么樣子的,
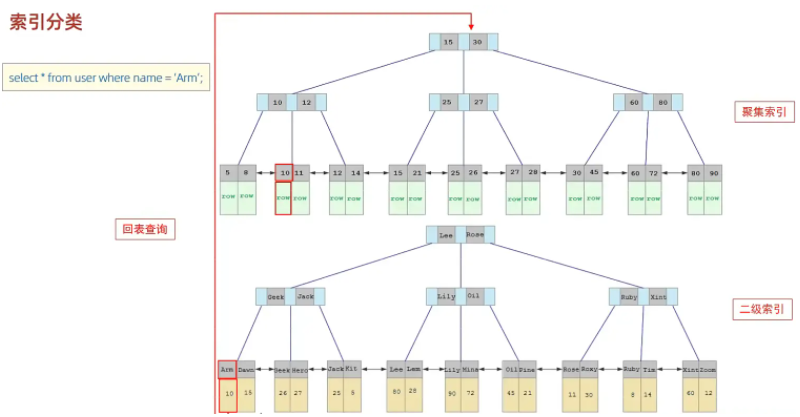
具體程序如下:
- 由于是根據name欄位進行查詢,所以先根據name='Arm'到name欄位的二級索引中進行匹配查 找,但是在二級索引中只能查找到 Arm 對應的主鍵值 10,
- 由于查詢回傳的資料是*,所以此時,還需要根據主鍵值10,到聚集索引中查找10對應的記錄,最 終找到10對應的行row,
- 最終拿到這一行的資料,直接回傳即可,
回表查詢: 這種先到二級索引中查找資料,找到主鍵值,然后再到聚集索引中根據主鍵值,獲取 資料的方式,就稱之為回表查詢,
思考題:
以下兩條SQL陳述句,那個執行效率高? 為什么?
A. select * from user where id = 10 ;
B. select * from user where name = 'Arm' ;
備注: id為主鍵,name欄位創建的有索引;
解答:
- A 陳述句的執行性能要高于B 陳述句,
- 因為A陳述句直接走聚集索引,直接回傳資料, 而B陳述句需要先查詢name欄位的二級索引,然后再查詢聚集索引,也就是需要進行回表查詢,
思考題:
- InnoDB主鍵索引的B+tree高度為多高呢?
答:假設一行資料大小為1k,一頁中可以存盤16行這樣的資料,InnoDB 的指標占用6個位元組的空間,主鍵假設為bigint,占用位元組數為8. 可得公式:
n * 8 + (n + 1) * 6 = 16 * 1024,其中 8 表示 bigint 占用的位元組數,n 表示當前節點存盤的key的數量,(n + 1) 表示指標數量(比key多一個),算出n約為1170,如果樹的高度為2,那么他能存盤的資料量大概為:
1171 * 16 = 18736; 如果樹的高度為3,那么他能存盤的資料量大概為:1171 * 1171 * 16 = 21939856,另外,如果有成千上萬的資料,那么就要考慮分表,涉及運維篇知識
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/542763.html
標籤:其他