分布式選舉演算法
為什么需要分布式選舉?
分布式意味著我們的應用部署在一個集群中,集群包含多個節點或者服務器,對于一個集群來說,多個節點是怎么協同作業的呢?我們需要有一個主節點來負責對其他節點的協調和管理,
分布式選舉是為了選出一個主節點,由它來協調和管理其他節點,以保證集群有序運行和節點間資料的一致性,
常見的分布式選舉演算法有哪些?
分布式選舉演算法一般會分為兩類:
- 基于序號選舉的演算法(例如Bully演算法)
- 多數派演算法(Raft,ZAB等)
Bully演算法
Bully演算法中,節點的角色有兩種:普通節點和主節點,初始化時,所有節點都是平等的,都是普通節點,并且都有成為主節點的權利,但是當選主結束后,有且僅有一個節點成為主節點,其他所有節點變為普通節點,
Bully演算法在選舉的程序中,需要使用3種訊息:
- Election訊息,用于發起選舉,
- Alive訊息,對Election訊息的應答,
- Victory訊息,競選成功的主節點向其他節點發送的宣誓主權的訊息,
Bully演算法選舉的原則是“長者為大”,它假設集群中的每個節點都知道其他節點的ID,整個選舉程序如下:
- 集群中每個節點判斷自己的ID是否為當前活著的節點中ID最大的,如果是,則直接向其他節點發送Victory訊息,宣示自己的主權,
- 如果自己不是當前活著的節點中ID最大的,則向比自己ID大的所有節點發送Election訊息,并等待其他節點的回復,
- 若在給定的時間范圍內,本節點沒有收到其他節點回復的Alive訊息,則認為自己成為主節點,并向其他節點發送Victory訊息,宣誓自己成為主節點,若接收到來自比自己ID大的節點的Alive訊息,則等待其他節點發送Victory訊息,
- 若本節點收到比自己ID小的節點發送的Election訊息,則回復一個Alive訊息,告知其他節點,我比你大,重新選舉,
Bully演算法的優點是選舉速度快、演算法復雜度低、簡單易實作,它的缺點在于需要每個節點都保存全域的節點資訊,因此額外資訊存盤比較多,其次,任意一個比當前主節點ID大的新節點或者節點故障后回復加入集群的時候,都會觸發重新選舉,成為新的主節點,如果該節點頻繁退出、加入集群,就會導致頻繁切主,
Raft演算法
Raft演算法是典型的多數派投票選舉演算法,它的核心思想是“少數服從多數”,
在Raft算中,集群節點的角色有3種:
- Leader,主節點,同一時刻只有一個Leader
- Candidate,候選者,每一個節點都可以成為Candidate,節點在該角色下才可能被選為新的Leader
- Follower,跟隨者,不可以發起選舉,
Raft選舉的流程如下:
- 初始化時,所有節點都是Follower狀態,
- 開始選主時,所有節點的狀態由Follower轉化為Candidate,并向其他節點發送選舉請求,
- 其他節點根據收到的選舉請求的先后順序,回復是否同意成為主,在每一輪選舉中,一個節點只能投出一張票,
- 如果發起選舉請求的節點獲得超過一半的投票,則成為主節點,其狀態轉化為Leader,其他節點的狀態則由Candidate變為Follower,
- Leader節點和Follower節點之間會定期發送心跳包,來檢測主節點是否正常,
- 當Leader節點的任期到了,即發現其他服務器開始下一輪選主周期時,Leader節點的狀態也會由Leader降級為Follower,進入新一輪選主,
Raft演算法的優點是選舉速度快、演算法復雜度低、易于實作,它的缺點是要求系統內每個節點都可以相互通信,其需要獲得過半的投票數才能選主成功,因此通信量大,
Kubernetes的選主采用開源組件etcd,etcd的集群管理器etcds,是一個高可用、強一致性的服務發現存盤倉庫,就是采用了Raft演算法實作選主和一致性的,
http://thesecretlivesofdata.com/raft/#election對Raft演算法做了很好的影片演示,可以很好的幫助我們理解Raft演算法的選舉程序,
ZAB演算法
ZAB選舉演算法是為ZooKeeper實作分布式協調功能而設計的,和Raft演算法相比,ZAB演算法增加了通過節點ID和資料ID作為參考進行選主,節點ID和資料ID越大,標識資料越新,優先成為主節點,
ZAB選舉演算法的核心是“少數服從多數,ID大的節點優先成為主節點”,
ZAB演算法中,集群里的每個節點擁有三種角色:
- Leader,主節點
- Follower,跟隨者節點
- Observer,觀察者,無投票權
選舉程序中,集群中的節點擁有4個狀態:
- Looking狀態,選舉狀態,當節點處于該狀態時,它會認為當前集群中沒有Leader,會進入選舉狀態,
- Leading狀態,領導者狀態,表示已經選擇出主節點,且當前節點為Leader,
- Following狀態,跟隨者狀態,集群中已經選出主節點后,其他非主節點的狀態變更為Following,
- Observing狀態,觀察者狀態,表示當前節點為Observer,持觀望態度,沒有投票權和選舉權,
投票程序中,每個節點都有一個唯一的三元組(service_id, service_zxID, epoch):
- servier_id:該節點唯一ID
- service_zxID:該節點存放的資料ID,資料ID越大,表示資料越新,選舉權重越大
- epoch:當前選舉論數,一般用邏輯時鐘表示,
選舉的原則:server_zxID最大者成為Leader,如果server_zxID相同,則service_id最大者成為Leader,
ZAB演算法性能高,對系統無特殊要求,采用廣播方式發送資訊,若集群中有n個節點,每個節點同事廣播,則集群中的資訊量為n*(n-1)個訊息,容易出現廣播風暴,而且訊息中增加了節點ID和資料ID,意味著需要知道所有節點的ID和資料ID,所以選舉時間相對較長,但是該演算法穩定性比較好,當有新節點加入或者節點故障恢復后,會觸發選主,但不一定會真正切主,除非新節點或者故障恢復后的節點資料ID和節點ID最大,且獲得投票數過半,才會切主,
ZAB演算法適合大規模分布式場景,例如ZooKeeper,
關于Bully演算法、Raft演算法和ZAB演算法,有一個比較形象的比喻:
- Bully演算法:類似于選武林盟主,誰武功最高,誰來當
- Raft演算法:類似于選總統,誰票數最高,誰來當
- ZAB演算法:類似于選優秀班干部,是班干部且票多才可以
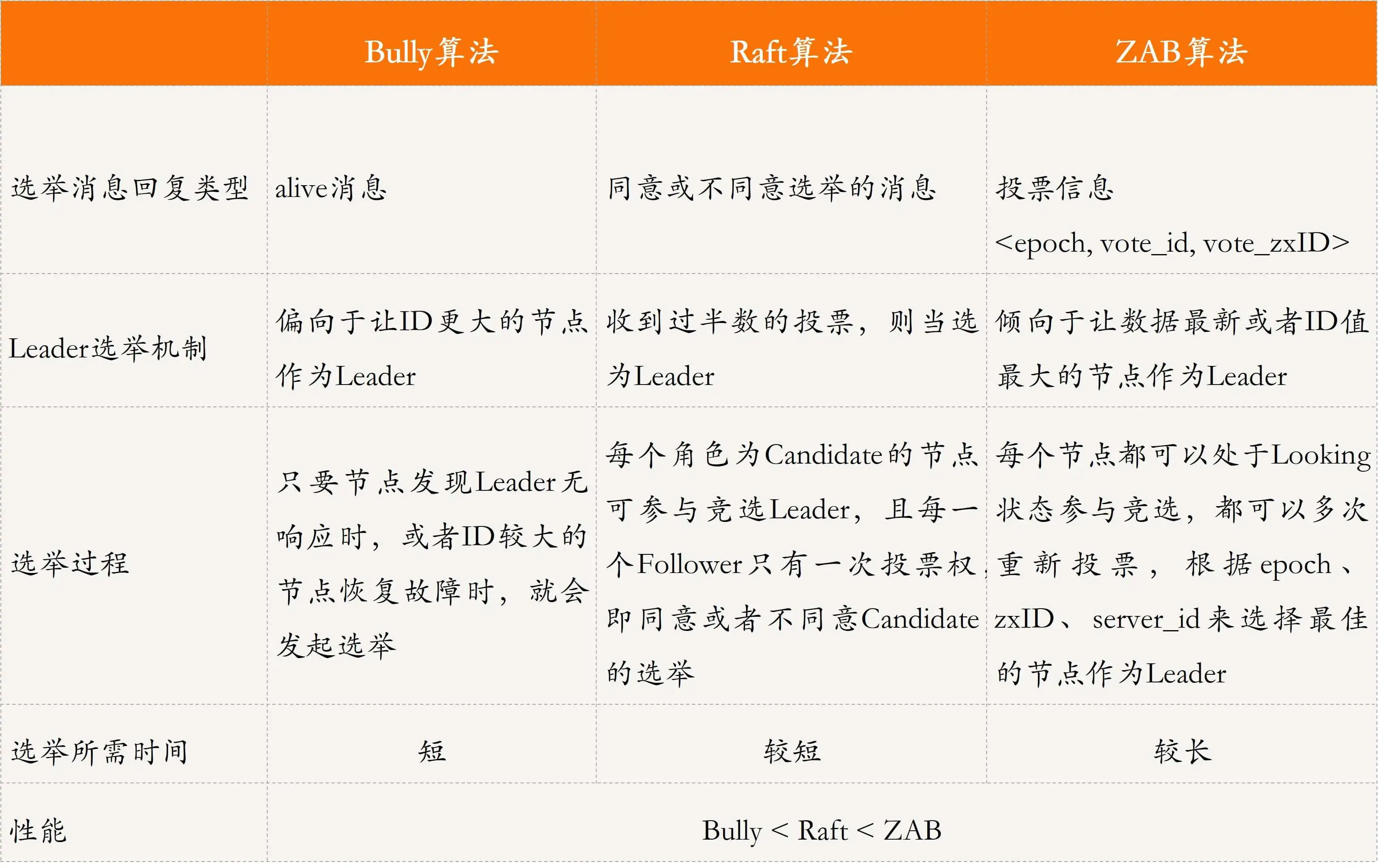
更加詳細的比較資訊如下表所示,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/543212.html
標籤:其他
上一篇:高層次綜合器Vivado HLS的概念與特點[原創www.cnblogs.com/helesheng]
下一篇:day04-視圖和視圖決議器