
大資料時代,各行各業對資料采集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實作從易到難全方位覆寫,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為爬蟲的基本介紹,
一、爬蟲概述
爬蟲又稱網路蜘蛛、網路機器人,網路爬蟲按照系統結構和實作技術,大致可以分為以下幾種型別:
- 通用網路爬蟲(Scalable Web Crawler):抓取互聯網上所有資料,爬取物件從一些種子 URL 擴充到整個 Web,主要為門戶站點搜索引擎和大型 Web 服務提供商采集資料,是捜索引擎抓取系統(Baidu、Google、Yahoo 等)的重要組成部分,
- 聚焦網路爬蟲(Focused Crawler):抓取互聯網上特定資料,按照預先定義好的主題有選擇地進行網頁爬取的一種爬蟲,將爬取的目標網頁定位在與主題相關的頁面中,選擇性地爬取特定領域資訊,
- 增量式網路爬蟲(Incremental Web Crawler):抓取互聯網上剛更新的資料,采取增量式更新和只爬取新產生的或者已經發生變化網頁,它能夠在一定程度上保證所爬取的頁面是盡可能新的頁面,減少時間和空間上的耗費,
- 深層網路爬蟲(Deep Web Crawler):表層網頁(Surface Web)是指傳統搜索引擎可以索引的頁面,以超鏈接可以到達的靜態網頁為主構成的 Web 頁面;深層網頁(Deep Web)是指不能通過靜態鏈接獲取的、隱藏在搜索表單后的,只有用戶提交一些關鍵詞才能獲得的 Web 頁面,在互聯網中,深層頁面的數量往往比表層頁面的數量要多很多,
爬蟲程式能模擬瀏覽器請求站點的行為,把站點回傳的HTML代碼/JSON資料/二進制資料(圖片、視頻、音頻) 等爬取到本地,進而提取自己需要的資料,并存放起來使用,每一個程式都有自己的規則,網路爬蟲也不例外,它會根據人們施加的規則去采集資訊,這些規則為網路爬蟲演算法,根據使用者的目的,爬蟲可以實作不同的功能,但所有爬蟲的本質,都是方便人們在海量的互聯網資訊中找到并下載到自己要的那一類,提升資訊獲取效率,
爬蟲采集的都是正常用戶能瀏覽到的內容,而非所謂的 ”入侵服務器“,常說高水準者可 ”所見即所得“,意為只要是能看的內容就能爬取到,希望各位都能達到這個程度~
二、爬蟲的用途
現如今大資料時代已經到來,網路爬蟲技術成為這個時代不可或缺的一部分,企業需要資料來分析用戶行為、自己產品的不足之處以及競爭對手的資訊等,而這一切的首要條件就是資料的采集,網路爬蟲的價值其實就是資料的價值,在互聯網社會中,資料是無價之寶,一切皆為資料,誰擁有了大量有用的資料,誰就擁有了決策的主動權,
網路爬蟲目前主要的應用領域如:搜索引擎、資料采集、資料分析、資訊聚合、競品監控、認知智能、輿情分析等等,爬蟲業務相關的公司數不勝數,如百度、谷歌、天眼查、企查查、新榜、飛瓜等等,在大資料時代,爬蟲的應用范圍廣、需求大,簡單舉幾個貼近生活的例子:
-
求職需求:獲取各個城市的招聘資訊及薪資標準,方便篩選出適合自己的;
-
租房需求:獲取各個城市的租房資訊,以便挑選出心儀的房源;
-
美食需求:獲取各個地方的好評美食,讓吃貨不迷路;
-
購物需求:獲取各個商家同一個商品的價格及折扣資訊,讓購物更實惠;
-
購車需求:獲取心儀車輛近年的價格波動,以及不同渠道各車型的價格,助力挑選愛車,
三、URI 及 URL 的含義
URI(Uniform Resource Identifier),即統一資源標志符,URI(Uniform Resource Location),即統一資源定位符,例如 https://www.kuaidaili.com/ ,既是一個 URI,也是一個 URL,URL 是 URI 的子集,對于一般的網頁鏈接,習慣稱為 URL,一個 URL 的基本組成格式如下:
scheme://[username:password@]host[:port][/path][;parameters][?query][#fragment]
各部分含義如下:
-
scheme:獲取資源使用的協議,例如 http、https、ftp 等,沒有默認值,scheme 也被稱為 protocol;
-
username:password:用戶名與密碼,某些情況下 URL 需要提供用戶名和密碼才能訪問,這是個特殊的存在,一般訪問 ftp 時會用到,顯式的表明了訪問資源的用戶名與密碼,但是可以不寫,不寫的話可能會讓輸入用戶名密碼;
-
host:主機地址,可以是域名或 IP 地址,例如 www.kuaidaili.com、112.66.251.209;
-
port:埠,服務器設定的服務埠,http 協議的默認埠為 80,https 協議的默認埠為 443,例如 https://www.kuaidaili.com/ 相當于 https://www.kuaidaili.com:443;
-
path:路徑,指的是網路資源在服務器中的指定地址,通過 host:port 我們能找到主機,但是主機上檔案很多,通過 path 則可以定位具體檔案,例如 https://www.baidu.com/file/index.html,path 為 /file/index.html,表示我們訪問 /file/index.html 這個檔案;
-
parameters:引數,用來指定訪問某個資源時的附加資訊,主要作用就是像服務器提供額外的引數,用來表示本次請求的一些特性,例如 https://www.kuaidaili.com/dps;kspider,kspider 即引數,現在用的很少,大多數將 query 部分作為引數;
-
query:查詢,由于查詢某類資源,若多個查詢,則用 & 隔開,通過 GET 方式請求的引數,例如:https://www.kuaidaili.com/dps/?username=kspider&type=spider,query 部分為 username=kspider&type=spider,指定了 username 為 kspider,type 為 spider;
-
fragment:片段,對資源描述的部分補充,用來標識次級資源,例如 https://www.kuaidaili.com/dps#kspider,kspider 即為 fragment 的值:
-
應用:單頁面路由、HTML 錨點;
-
#有別于?,?后面的查詢字串會被網路請求帶上服務器,而 fragment 不會被發送的服務器; -
fragment 的改變不會觸發瀏覽器重繪頁面,但是會生成瀏覽歷史;
-
fragment 會被瀏覽器根據檔案媒體型別(MIME type)進行對應的處理;
-
默認情況下 Google 的搜索引擎會忽略
#及其后面的字串,如果想被瀏覽引擎讀取,需要在#后緊跟一個!,Google 會自動將其后面的內容轉成查詢字串_escaped_fragment_的值,如 https://www.kuaidaili.com/dps#!kspider,轉換后為 https://www.kuaidaili.com/dps?escaped_fragment=kspider,
-
由于爬蟲的目標是獲取資源,而資源都存盤在某個主機上,所以爬蟲爬取資料時必須要有一個目標的 URL 才可以獲取資料,因此,URL 是爬蟲獲取資料的基本依據,準確理解 URL 的含義對爬蟲學習有很大幫助,
四、爬蟲的基本流程
- 發起請求:通過 URL 向服務器發起 Request 請求(同打開瀏覽器,輸入網址瀏覽網頁),請求可以包含額外的 headers、cookies、proxies、data 等資訊,Python 提供了許多庫,幫助我們實作這個流程,完成 HTTP 請求操作,如 urllib、requests 等;
- 獲取回應內容:如果服務器正常回應,會接收到 Response,Response 即為我們所請求的網頁內容,包含 HTML(網頁源代碼),JSON 資料或者二進制的資料(視頻、音頻、圖片)等;
- 決議內容:接收到回應內容后,需要對其進行決議,提取資料內容,如果是 HTML(網頁源代碼),則可以使用網頁決議器進行決議,如正則運算式(re)、Beautiful Soup、pyquery、lxml 等;如果是 JSON 資料,則可以轉換成 JSON 物件進行決議;如果是二進制的資料,則可以保存到檔案進行進一步處理;
- 保存資料:可以保存到本地檔案(txt、json、csv 等),或者保存到資料庫(MySQL,Redis,MongoDB 等),也可以保存至遠程服務器,如借助 SFTP 進行操作等,
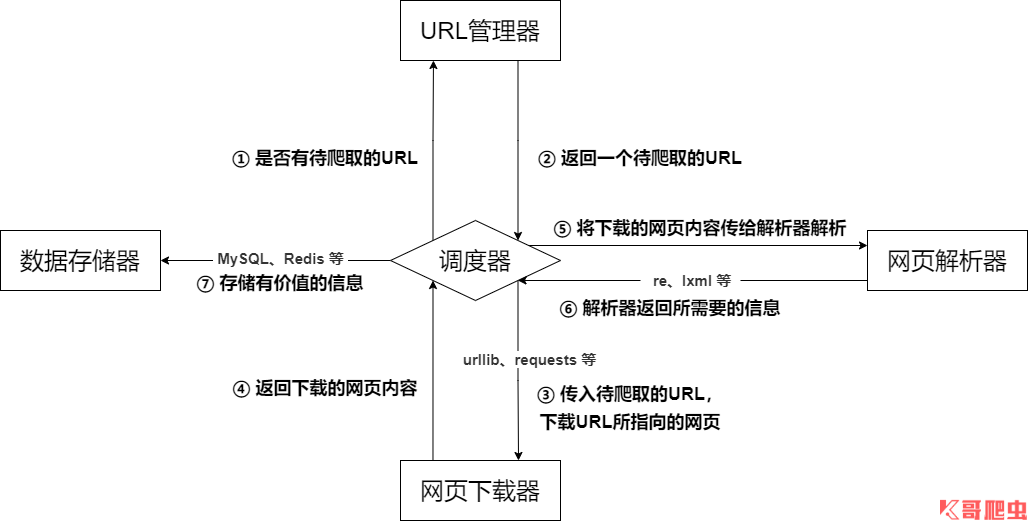
五、爬蟲的基本架構
爬蟲的基本架構主要由五個部分組成,分別是爬蟲調度器、URL 管理器、網頁下載器、網頁決議器、資訊采集器:
- 爬蟲調度器:相當于一臺電腦的 CPU,主要負責調度 URL 管理器、下載器、決議器之間的協調作業,用于各個模塊之間的通信,可以理解為爬蟲的入口與核心,爬蟲的執行策略在此模塊進行定義;
- URL 管理器:包括待爬取的 URL 地址和已爬取的 URL 地址,防止重復抓取 URL 和回圈抓取 URL,實作 URL 管理器主要用三種方式,通過記憶體、資料庫、快取資料庫來實作;
- 網頁下載器:負責通過 URL 將網頁進行下載,主要是進行相應的偽裝處理模擬瀏覽器訪問、下載網頁,常用庫為 urllib、requests 等;
- 網頁決議器:負責對網頁資訊進行決議,可以按照要求提取出有用的資訊,也可以根據 DOM 樹的決議方式來決議,如正則運算式(re)、Beautiful Soup、pyquery、lxml 等,根據實際情況靈活使用;
- 資料存盤器:負責將決議后的資訊進行存盤、顯示等資料處理,
六、robots 協議
robots 協議也稱爬蟲協議、爬蟲規則等,是指網站可建立一個 robots.txt 檔案來告訴搜索引擎哪些頁面可以抓取,哪些頁面不能抓取,而搜索引擎則通過讀取 robots.txt 檔案來識別這個頁面是否允許被抓取,但是,這個robots協議不是防火墻,也沒有強制執行力,搜索引擎完全可以忽視 robots.txt 檔案去抓取網頁的快照, 如果想單獨定義搜索引擎的漫游器訪問子目錄時的行為,那么可以將自定的設定合并到根目錄下的 robots.txt,或者使用 robots 元資料(Metadata,又稱元資料),
robots 協議并不是一個規范,而只是約定俗成的,所以并不能保證網站的隱私,俗稱 “君子協議”,
robots.txt 檔案內容含義:
- User-agent:, 這里的 * 代表的所有的搜索引擎種類, 是一個通配符
- Disallow: /admin/, 這里定義是禁止爬取 admin 目錄下面的目錄
- Disallow: /require/, 這里定義是禁止爬取 require 目錄下面的目錄
- Disallow:/ABC/, 這里定義是禁止爬取 ABC 目錄下面的目錄
- Disallow:
/cgi-bin/*.htm, 禁止訪問 /cgi-bin/ 目錄下的所有以 ".htm" 為后綴的 URL(包含子目錄) - Disallow:
/*?*, 禁止訪問網站中所有包含問號 (?) 的網址 - Disallow:/.jpg$, 禁止抓取網頁所有的 .jpg 格式的圖片
- Disallow:/ab/adc.html, 禁止爬取 ab 檔案夾下面的 adc.html 檔案
- Allow:/cgi-bin/, 這里定義是允許爬取 cgi-bin 目錄下面的目錄
- Allow:/tmp, 這里定義是允許爬取 tmp 的整個目錄
- Allow: .htm$, 僅允許訪問以 ".htm" 為后綴的 URL
- Allow: .gif$, 允許抓取網頁和 gif 格式圖片
- Sitemap:網站地圖, 告訴爬蟲這個頁面是網站地圖
查看網站 robots 協議,網站 url 加上后綴 robotst.txt 即可,以快代理為例:
https://www.kuaidaili.com/

- 禁止所有搜索引擎訪問網站的任何部分
- 禁止爬取 /doc/using/ 目錄下面的目錄
- 禁止爬取 /doc/dev 目錄下面所有以 sdk 開頭的目錄及檔案
七、爬蟲與法律
近年來,與網路爬蟲相關的法律案件和新聞報道層出不窮,推薦觀看:K哥爬蟲普法專欄,不論是不是爬蟲行業的可能都聽說過一句 “爬蟲學的好,牢飯吃到飽”,甚至不少人覺得爬蟲本身就是有問題的,處于灰色地帶,抗拒以致不敢學爬蟲,但實際并不是這樣,爬蟲作為一種計算機技術,其技術本身是具有中立性的,法律也并沒禁止爬蟲技術,當今互聯網很多技術是依賴于爬蟲技術而發展的,公開資料、不做商業目的、不涉及個人隱私、不要把對方服務器爬崩、不碰黑產及黃賭毒就不會違法,技術無罪,有罪的是人,切記不要觸碰法律的紅線!

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/543512.html
標籤:其他
下一篇:kafka單機安裝