Python常見面試題(持續更新 23-2-13)
參考資料
https://github.com/taizilongxu/interview_python
https://github.com/hantmac/Python-Interview-Customs-Collection
https://github.com/kenwoodjw/python_interview_question
有些來自上面(但我也做了自己的補充),有些來自網路或書籍
本文不準備寫編程題,偏重于理論一些,你要的話去刷leetcode就是了,
倒序描述,限于篇幅,可能要連載
004. 請說出下面代碼的回傳結果是什么?
參考了 https://www.liujiangblog.com/course/python/44
如有侵權,聯系洗掉
-
示例代碼1
class D: pass class C(D): pass class B(C): def show(self): print("i am B") pass class G: pass class F(G): pass class E(F): def show(self): print("i am E") pass class A(B, E): pass a = A() a.show() -
結果
i am B -
你可以整理出這樣的一個繼承關系
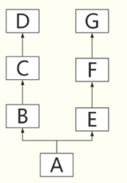
-
從執行結果看先走 是A(B,E)中左側的B這個分支:可見,在A的定義中,繼承引數的書寫有先后順序,寫在前面的被優先繼承,
-
你可以查看A的__mro__屬性
print(A.__mro__) # 你也可以這樣print(A.mro()) # 是個元組 (<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class 'object'>) -
如果你改成這樣
class A(E,B): pass print(A.__mro__) -
順序自然成了這樣
(<class '__main__.A'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>) -
繼承關系下的搜索順序
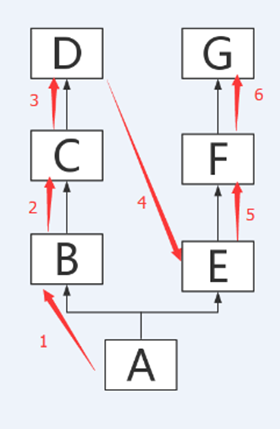
-
所以,把代碼改為這樣,輸出你應該毫無疑問了
class D: def show(self): print("i am D") pass class C(D): pass class B(C): pass class G: pass class F(G): pass class E(F): def show(self): print("i am E") pass class A(B, E): pass a = A() a.show() # i am D -
那么這樣呢?
class H: def show(self): print("i am H") pass class D(H): pass class C(D): pass class B(C): pass class G(H): pass class F(G): pass class E(F): def show(self): print("i am E") pass class A(B, E): pass a = A() a.show() -
繼承關系是這樣的
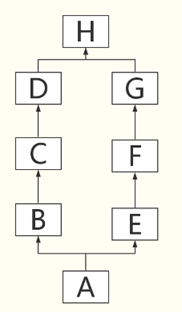
-
答案是
i am E -
看MRO
print(A.__mro__) (<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class '__main__.H'>, <class 'object'>) -
所以繼承樹的搜索順序是這樣的
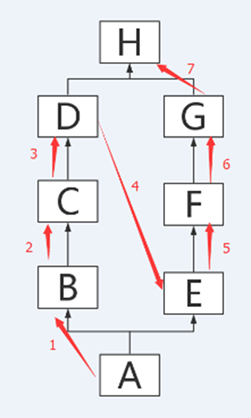
-
而所有的繼承其實都是這2種圖形的變化
-
比如這樣的代碼
class D(): pass class G(): def show(self): print("i am G") pass class F(G): pass class C(D): pass class B(C,F): pass class E(F): def show(self): print("i am E") pass class A(B, E): pass a = A() a.show() -
你先分析下應該輸出啥,繼承樹是怎樣的,MRO是如何的?
-
輸出
i am E -
繼承樹
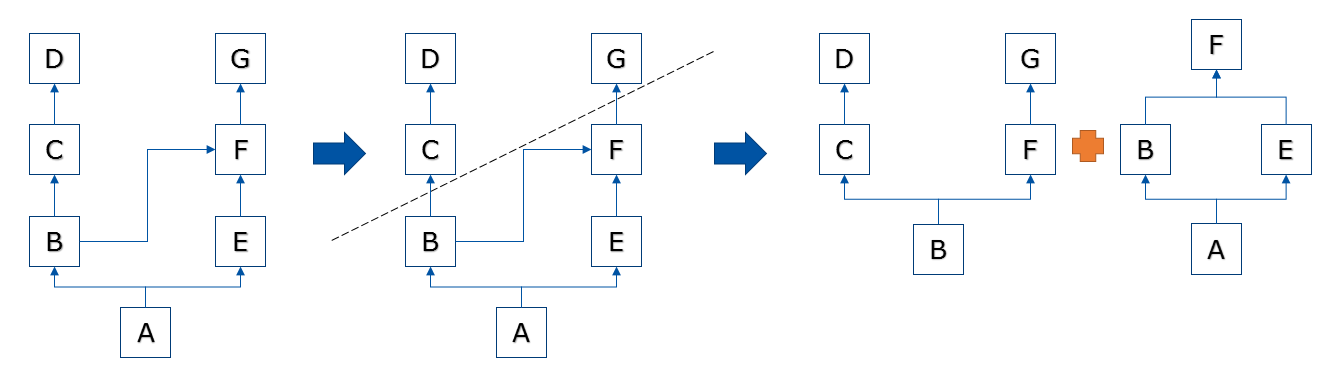
-
MRO
(<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class 'object'>)
-
關于類的繼承
- 子類在呼叫某個方法或變數的時候,首先在自己內部查找,如果沒有找到,則開始根據繼承機制在父類里查找,
- 根據父類定義中的順序,以深度優先的方式逐一查找父類!
- 子類永遠在父類前面,如果有多個父類,會根據它們在串列中的順序被檢查,如果對下一個類存在兩個合法的選擇,選擇第一個父類
-
MRO:即Method Resolution Order(方法決議順序)
-
從Python 2.3開始計算MRO一直是用的C3演算法
https://www.python.org/download/releases/2.3/mro/ -
C3演算法的簡單解釋可以參考碼農高天的這個視頻:https://www.bilibili.com/video/BV1V5411S7dY
003. 請說出下面的代碼回傳結果是什么?為何?如何改進?
知識點: 函式引數的型別
-
示例代碼
def f(a, L=[]): L.append(a) return L print(f(1)) print(f(1)) -
據說是國內某上市互聯網公司Python面試真題(略作改動),而實際在python的官網也有
https://docs.python.org/zh-cn/3.9/tutorial/controlflow.html#default-argument-values -
爛大街了
-
典型的錯誤答案
[1] [1] -
實際的答案
[1] [1, 2] -
因為Python函式體在被讀入記憶體的時候,默認引數a指向的空串列物件就會被創建,并放在記憶體里了,因為默認引數a本身也是一個變數,保存了指向物件[]的地址,每次呼叫該函式,往a指向的串列里添加一個A,a沒有變,始終保存的是指向串列的地址,變的是串列內的資料!
-
修改
def f(a, L=None): if L is None: L = [] L.append(a) return L print(f(1)) print(f(1))
-
官網的重要警告: 默認值只計算一次,默認值為串列、字典或類實體等可變物件時,會產生與該規則不同的結果
-
這樣的代碼
def f(a, L=[]): L.append(a) return L print(f(1)) print(f(2)) # 被我改成了1,具有欺騙性一點 print(f(3)) # 去掉了,3個放一起,你都能猜到有點貓膩了,2個雖然也....總歸好一點 -
上面的函式會累積后續呼叫時傳遞的引數
-
不想在后續呼叫之間共享默認值時,建議用None這樣的不可變物件來存盤
def f(a, L=None): if L is None: L = [] L.append(a) return L
002. 請分別說出下面的代碼回傳結果是什么?為何?
知識點: 作用域
-
示例代碼1
def func(x): print(x) print(y) func(1) -
示例代碼2
y = 1 def func(x): print(x) print(y) func(1) -
示例代碼3
y = 1 def func(x): print(x) print(y) y = 2 func(1)
-
示例代碼1的執行結果
NameError: name 'y' is not defined -
示例代碼2的執行結果
1 1 -
示例代碼3的執行結果
UnboundLocalError: local variable 'y' referenced before assignment
解釋3
- Python 編譯函式的定義體時,它判斷 b 是區域變數,依據是y=2,你對它進行了賦值,Python 會嘗試從本地環境獲取 b,
- 后面呼叫 func(1)時,func的定義體會獲取并列印區域變數x 的值,但是嘗試獲取區域變數 y 的值時,發現 y 沒有 系結值就報錯了,
- 這不是缺陷,這是設計如此(做測驗是不是經常聽到這句話)
- Python 不要求宣告變數,但是假定在函式定義體中賦值的變 量,那就認為它是區域變數
對于代碼3的處理
-
示例代碼3(更改)
y = 1 def func(x): global y print(x) print(y) y = 2 func(1) -
這樣解釋器就會把 y 當成全域變數,從而找到第一行的y=1并print出來了
從函式的位元組碼也能看出來這個程序
-
代碼1
def func(x): print(x) print(y) y = 2 from dis import dis dis(func) -
位元組碼
3 0 LOAD_GLOBAL 0 (print) # 加載全域名稱print 2 LOAD_FAST 0 (x) # 加載本地名稱x 4 CALL_FUNCTION 1 6 POP_TOP 4 8 LOAD_GLOBAL 0 (print) 10 LOAD_FAST 1 (y) # 加載本地名稱y 12 CALL_FUNCTION 1 14 POP_TOP 5 16 LOAD_CONST 1 (2) 18 STORE_FAST 1 (y) 20 LOAD_CONST 0 (None) 22 RETURN_VALUE
-
示例代碼2
y = 1 def func(x): print(x) print(y) from dis import dis dis(func) -
位元組碼
3 0 LOAD_GLOBAL 0 (print) 2 LOAD_FAST 0 (x) 4 CALL_FUNCTION 1 6 POP_TOP 4 8 LOAD_GLOBAL 0 (print) 10 LOAD_GLOBAL 1 (y) # 看這里的變化,是全域變數了 12 CALL_FUNCTION 1 14 POP_TOP 16 LOAD_CONST 0 (None) 18 RETURN_VALUE 行程已結束,退出代碼為 0
-
示例代碼3
y = 1 def func(x): print(x) print(y) y = 2 from dis import dis dis(func) -
位元組碼
3 0 LOAD_GLOBAL 0 (print) 2 LOAD_FAST 0 (x) 4 CALL_FUNCTION 1 6 POP_TOP 4 8 LOAD_GLOBAL 0 (print) 10 LOAD_FAST 1 (y) # 又變成了本地 12 CALL_FUNCTION 1 14 POP_TOP 5 16 LOAD_CONST 1 (2) 18 STORE_FAST 1 (y) 20 LOAD_CONST 0 (None) 22 RETURN_VALUE -
示例代碼3(更改)
y = 1 def func(x): global y print(x) print(y) y = 2 from dis import dis dis(func) -
位元組碼
4 0 LOAD_GLOBAL 0 (print) 2 LOAD_FAST 0 (x) 4 CALL_FUNCTION 1 6 POP_TOP 5 8 LOAD_GLOBAL 0 (print) 10 LOAD_GLOBAL 1 (y) 12 CALL_FUNCTION 1 14 POP_TOP 6 16 LOAD_CONST 1 (2) 18 STORE_GLOBAL 1 (y) 20 LOAD_CONST 0 (None) 22 RETURN_VALUE
看不懂位元組碼不要緊的,當然非要,你可以去參考https://docs.python.org/zh-cn/3/library/dis.html
作用域LEGB相關知識單獨考慮弄個博文
001. is和==有什么區別
-
==是物件的值的比較,也就是物件保存的資料,
-
is比較的是物件的標識,
-
示例代碼1
a = [1,2,3] b = [1,2,3] print(a == b) # True print(a is b) # False -
is的背后是id,is比較為True,說明2個id的回傳是一樣的
-
在 CPython 中,id() 回傳物件的記憶體地址, 但是在其他 Python 解釋器中可能是別的值,關鍵是,ID 一定是唯一的數值標注,而且在 物件的生命周期中絕不會變,
上面的話引自 <流暢的python> 8.2 標識、相等性、別名
這些知識涉及物件的參考,相關的面試題如淺拷貝/深拷貝、多載運算子(==)等
淺拷貝也考慮單獨剝離弄個博文或主題
-
示例代碼2
>>> a = 257 >>> b = 257 >>> a is b False >>> a == b True # 但是這個呢? >>> c = d = 256 >>> c is d True -
這是因為出于對性能優化的考慮,Python內部會對-5到256的整型維持一個陣列,起到一個快取 的作用,這樣,每次你試圖創建一個-5到256范圍內的整型數字時,Python都會從這個陣列中回傳相對應的參考,而不是重新開辟一塊新的記憶體空間,
-
但是,如果整型數字超過了這個范圍,比如上述例子中的257,Python則會為兩個257開辟兩塊 記憶體區域,因此a和b的ID不一樣,a is b就會回傳False了,
-
比較運算子'is'的速度效率,通常要優于'==',因為'is'運算子不能被多載,這 樣,Python就不需要去尋找,程式中是否有其他地方多載了比較運算子,并去呼叫,執行比較運算子'is',就僅僅是比較兩個變數的ID而已,
-
但是'=='運算子卻不同,執行a == b相當于是去執行a.__eq__(b),而Python大部分的資料型別都 會去多載__eq_這個函式,其內部的處理通常會復雜一些,比如,對于串列,__eq_函式會去 遍歷串列中的元素,比較它們的順序和值是否相等,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/543727.html
標籤:Python