1.redis的過期鍵洗掉策略
??redis是key-value的資料庫,我們可以設定Redis中快取的key的過期時間,Redis的過期策略是指Redis中快取的key過期了,Redis如何處理
??了解redis過期洗掉策略前,先了解一下三種過期洗掉策略
??1.定時洗掉策略:
????概念:在設定鍵的過期時間的同時,創建一個定時器,讓定時器在鍵的過期時間來臨時,立即執行對鍵的洗掉操作,(創建定時器洗掉)
????優點:對記憶體最友好:通過使用定時器,可以保證過期的鍵會盡可能快地被洗掉,釋放所占記憶體
????缺點:對cpu最不友好:在過期鍵比較多的情況下,洗掉過期鍵這一行為可能會占用相當一部分cpu的時間,對服務器的回應時間和吞吐量造成影響,
??2.惰性洗掉策略:
????概念:放任鍵的過期不管,但是每次從鍵空間中獲取鍵時,都檢查取得的鍵是否過期,如果過期的話,就洗掉該鍵;如果沒有過期,就回傳該鍵,(使用的時候洗掉)
????優點:對cpu最友好:只有在取出鍵的時候才會對過期鍵進行檢查,即不需要cpu定期掃描,也不需要創建大量的定時器,
????缺點:對記憶體最不友好:如果一個鍵已經過期,但是后面不會被訪問到的話,那么就一直保留在資料庫中,如果這樣的鍵過多,無疑會占用很大的記憶體
??3.定期洗掉策略:
????概念:每隔一段時間,程式就對資料庫進行一次檢查,洗掉里面過期的鍵,至于要洗掉多少過期鍵,以及要檢查多少個資料庫,則有演算法決定,(定期掃描洗掉)
????優點:
-
- 定期洗掉每隔一段時間執行一次過期鍵操作,并通過限制洗掉操作執行的時長和頻率來減少洗掉操作對cpu時間的影響;
- 通過洗掉過期鍵,能有效的減少因為過期鍵而帶來的記憶體浪費
????缺點:難以確定洗掉操作執行的時長和頻率
-
- 如果洗掉操作執行得太頻繁,或者執行的時間太長,定期洗掉策略就會退化成定時洗掉,以至于占用太多cpu的執行時間;
- 如果洗掉操作執行的時間太少,或執行時間太短,定期洗掉策略又會和惰性洗掉一樣,出現記憶體浪費,
Redis過期洗掉策略:
??redis實際使用的過期鍵洗掉策略是定期洗掉策略和惰性洗掉策略:
??redis 會將每個設定了過期時間的 key 放入到一個獨立的字典中,以后會定時遍歷這個字典來洗掉到期的 key,除了定時遍歷之外,它還會使用惰性策略來洗掉過期的 key,所謂惰性策略就是在客戶端訪問這個 key 的時候,redis 對 key 的過期時間進行檢查,如果過期了就立即洗掉,定時洗掉是集中處理,惰性洗掉是零散處理,
通過配合使用這兩種洗掉策略,服務器可以很好地合理使用cpu時間和避免浪費記憶體空間之間取得平衡,
??1.定期洗掉
??Redis 默認會每秒進行十次過期掃描,過期掃描不會遍歷過期字典中所有的 key,而是采用了一種簡單的貪心策略,
-
- 從過期字典中隨機 20 個 key;
- 洗掉這 20 個 key 中已經過期的 key;
- 如果過期的 key 比率超過 1/4,那就重復步驟 1;
??同時,為了保證過期掃描不會出現回圈過度,導致執行緒卡死現象,演算法還增加了掃描時間的上限,默認不會超過 25ms,
??如果某一時刻,有大量key同時過期,Redis 會持續掃描過期字典,造成客戶端回應卡頓,因此設定過期時間時,就盡量避免這個問題,在設定過期時間時,可以給過期時間設定一個隨機范圍,避免同一時刻過期,?
??a. 如何配置定期洗掉執行時間間隔
????redis的定時任務默認是每秒執行10次,如果要修改這個值,可以在redis.conf中修改hz的值,
????redis.conf中,hz默認設為10,提高它的值將會占用更多的cpu,當然相應的redis將會更快的處理同時到期的許多key,以及更精確的去處理超時, hz的取值范圍是1~500,通常不建議超過100,只有在請求延時非常低的情況下可以將值提升到100,
??b. 單執行緒的redis,如何知道要運行定時任務?
????redis是單執行緒的,執行緒不但要處理定時任務,還要處理客戶端請求,執行緒不能阻塞在定時任務或處理客戶端請求上,那么,redis是如何知道何時該運行定時任務的呢?
????Redis 的定時任務會記錄在一個稱為最小堆的資料結構中,這個堆中,最快要執行的任務排在堆的最上方,在每個回圈周期,Redis 都會將最小堆里面已經到點的任務立即進行處理,處理完畢后,將最快要執行的任務還需要的時間記錄下來,這個時間就是接下來處理客戶端請求的最大時長,若達到了該時長,則暫時不處理客戶端請求而去運行定時任務,
??2.懶惰洗掉
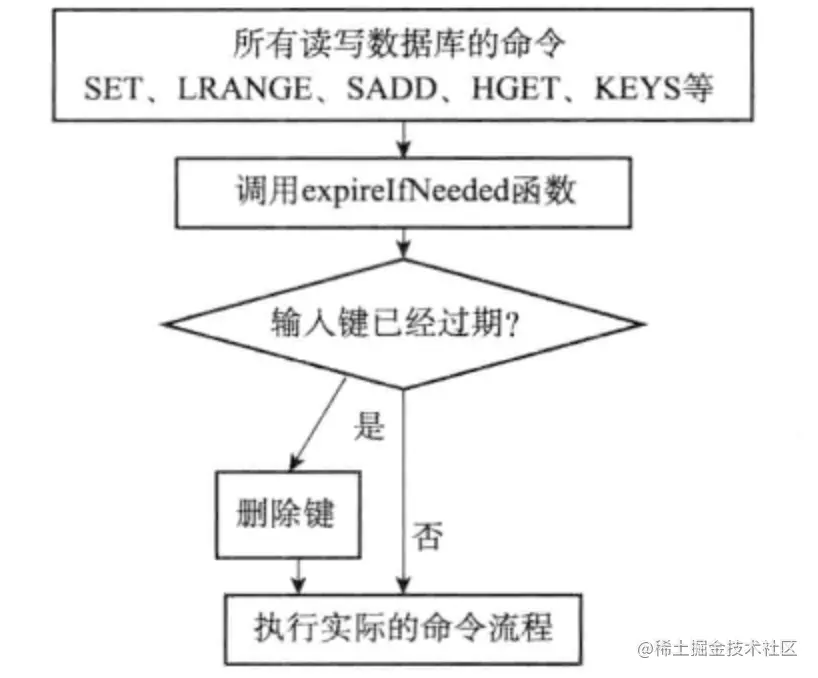
??過期鍵的惰性洗掉洗掉策略由db.c/expireIfNeeded函式實作,所有讀寫資料庫的Redis命令在執行之前都會呼叫expireIfNeed函式對輸入鍵進行檢查:
-
- 如果鍵已經過期,那么expireIfNeeded函式將鍵洗掉
- 如果鍵未過期,那么expireIfNeeded函式不做操作
??命令呼叫expireIfNeeded函式程序如下圖
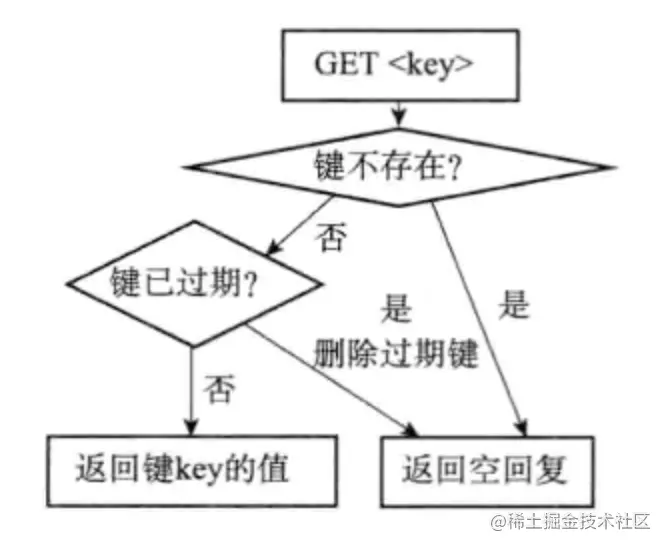
另外因為每個被訪問的鍵都可能被洗掉,所以每個命令都必須能同時處理鍵存在以及不存在的情況, 下圖表示get命令的執行程序
2. aof/rdb和復制功能對過期鍵的處理
??rdb
-
- 生成rdb檔案:生成時,程式會對鍵進行檢查,過期鍵不放入rdb檔案,
- 載入rdb檔案:載入時,如果以主服務器模式運行,程式會對檔案中保存的鍵進行檢查,未過期的鍵會被載入到資料庫中,而過期鍵則會忽略;如果以從服務器模式運行,無論鍵過期與否,均會載入資料庫中,過期鍵會通過與主服務器同步而洗掉,
-
aof
- 當服務器以aof持久化模式運行時,如果資料庫中的某個鍵已經過期,但它還沒有被洗掉,那么aof檔案不會因為這個過期鍵而產生任何影響;當過期鍵被洗掉后,程式會向aof檔案追加一條del命令來顯式記錄該鍵已被洗掉,
- aof重寫程序中,程式會對資料庫中的鍵進行檢查,已過期的鍵不會被保存到重寫后的aof檔案中,
??復制
????當服務器運行在復制模式下時,從服務器的過期洗掉動作由主服務器控制:
-
-
- 主服務器在洗掉一個過期鍵后,會顯式地向所有從服務器發送一個del命令,告知從服務器洗掉這個過期鍵;
- 從服務器在執行客戶端發送的讀命令時,即使碰到過期鍵也不會將過期鍵洗掉,而是繼續像處理未過期的鍵一樣來處理過期鍵;
- 從服務器只有在接到主服務器發來的del命令后,才會洗掉過期鍵,
-
2.redis的執行緒模型,單執行緒為什么快
??檔案事件處理器
????redis 基于 reactor 模式開發了網路事件處理器,這個處理器叫做檔案事件處理器,file event headler,其是單執行緒的,因此 redis 才叫做單執行緒的模型,采用 IO多路復用機制同時監聽多個 socket,根據 socket 上的事件來選擇對應的事件處理器來處理這個事件,
如果被監聽的 socket 準備好執行 accept、read、write、close 等操作的時候,跟操作對應的檔案事件就會產生,這時候檔案事件處理器就會呼叫之前關聯好的事件處理器來處理這個事件,
檔案事件處理器是單執行緒模式運行的,但是通過IO多路復用機制監聽多個 sokcet,可以實作高性能的網路通信模型,又可以跟內部其他單執行緒的模塊進行對接,保證了 redis 內部的執行緒模型的簡單性,
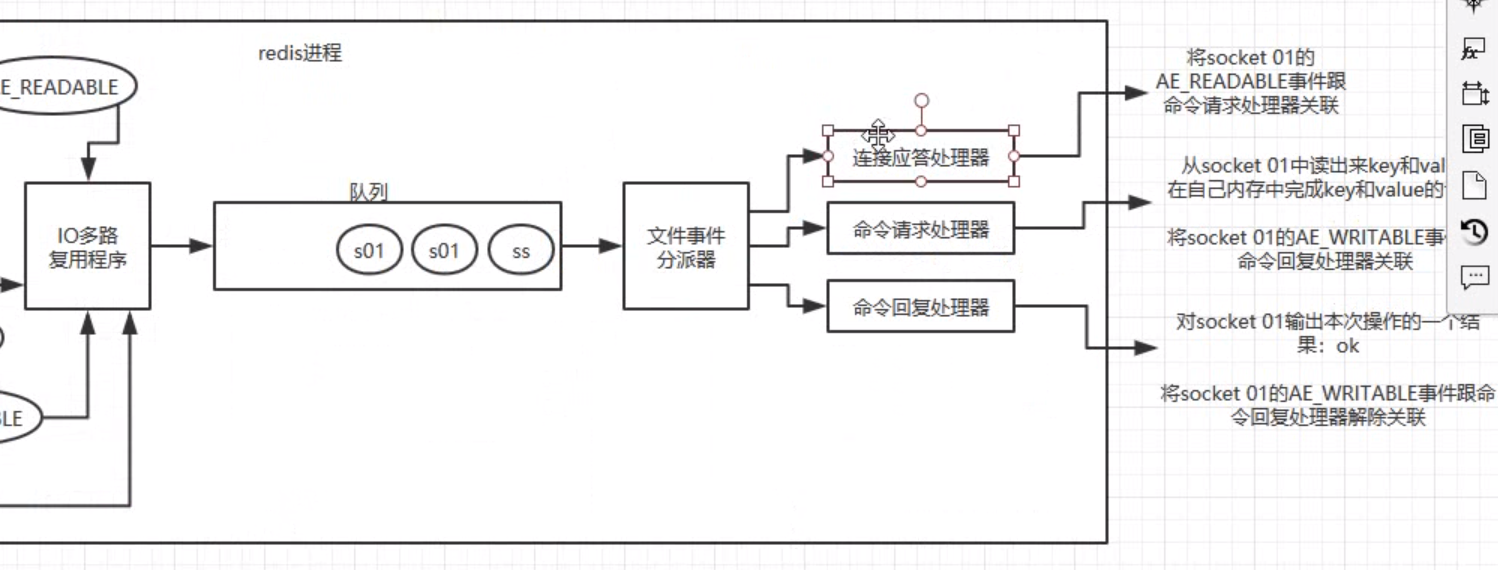
??檔案事件處理器的結構包含 4 個部分:
??1.多個socket
??2.IO多路復用程式
??3.檔案事件分派器
??4.事件處理器
????4.1命令請求處理器:寫資料到 redis
????4.2命令回復處理器:客戶端要從 redis 讀資料
????4.3連接應答處理器:客戶端要連接 redis
多個 socket 可能并發地產生不同的操作,每個操作對應不同的檔案事件,但是 IO 多路復用程式會監聽多個 sokcet,會講socket放入一個佇列中排隊,每次從佇列中取出一個 socket 給事件分派器,事件分派器再把 socket 給對應的事件處理器,
然后一個 socket 的時間處理完之后,IO多路復用程式才會將佇列中的下一個 socket 給事件分派器,檔案事件分派器會根據每個 socket 當前產生的事件,來選擇對應的事件處理器來處理,
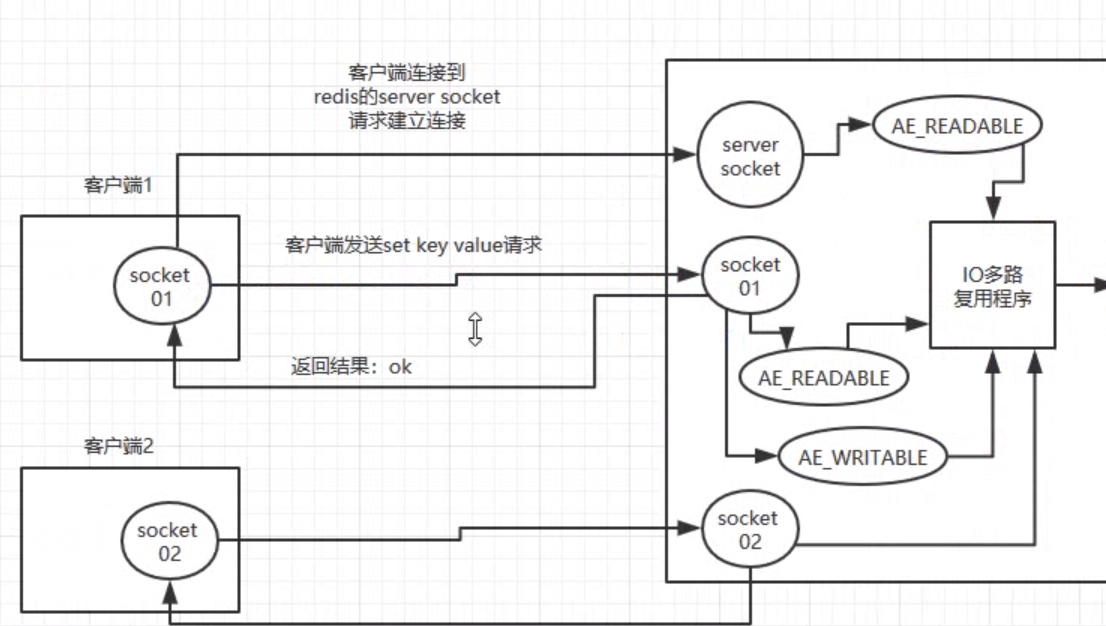
??客戶端與 redis 通信的一次流程
在 redis 啟動初始化的時候, redis 會將連接應答處理器跟 AE_READABLE 事件關聯起來,接著如果一個客戶端跟 redis 發起連接,此時會產生一個 AE_READABLE 事件,然后由連接應答處理器來處理跟客戶端建立連接,在服務端創建客戶端對應的sokcet,同時將這個socket的 AE_READABLE 事件跟命令請求處理器關聯起來,
當客戶端向 redis 發起請求(讀、寫)的時候,首先就會在 socket 產生一個 AE_READABLE 事件,然后由對應的命令請求處理器來處理,這個命令請求處理器就會從socket中讀取請求相關資料,然后進行執行和處理,
接著 redis 準備好了給客戶端的回應資料之后,就會將 socket 的 AE_WRITEABLE 跟命令回復處理器關聯起來,當客戶端準備好讀取相應資料時,就會在 scoket 上產生一個 AE_WRITEABLE 事件,會由對應的命令回復處理器來處理,就是將準備好的相應資料寫入socket,供客戶端來讀取,
命令回復處理器寫完之后,就會洗掉這個 socket 的 AE_WRITEABLE 事件和命令回復處理器的關聯關系,
為什么 redis 單執行緒模型效率也能這么高
- IO多路復用程式不負責處理事件,只是監聽所有的socket產生的一個請求,之后將請求壓入佇列,其是非阻塞的,
- 事件處理器是基于純記憶體操作的,性能非常高
- 單執行緒反而避免了多執行緒的頻繁背景關系切換問題
3.快取雪崩,快取穿透,快取擊穿
1.快取穿透
??快取穿透是指查詢一個快取中和資料庫中都不存在的資料,導致每次查詢這條資料都會透過快取,直接查庫,最后回傳空,
??當用戶使用這條不存在的資料瘋狂發起查詢請求的時候,對資料庫造成的壓力就非常大,甚至可能直接掛掉,這種情況的流程就變成下圖這樣了:
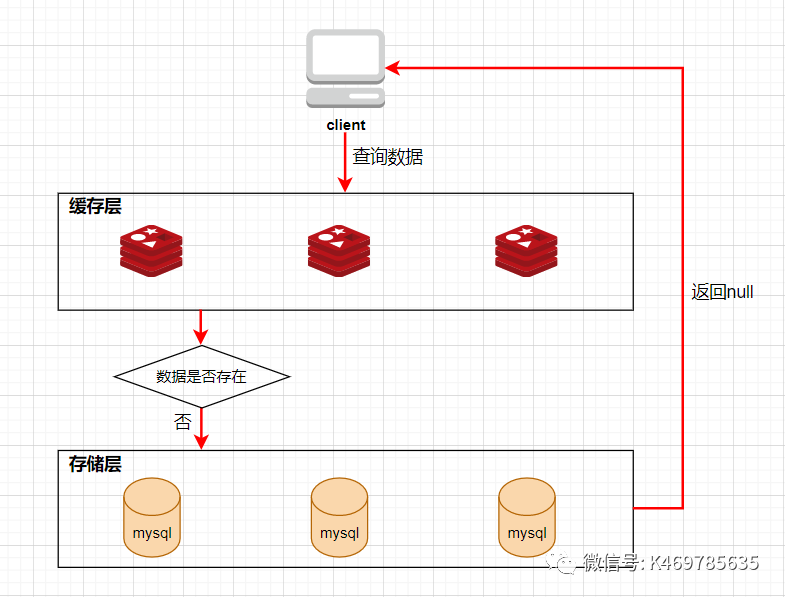
快取穿透解決方案
??方案一:快取空值(null)或默認值
??分析業務請求,如果是正常業務請求時發生快取穿透現象,可針對相應的業務資料,在資料庫查詢不存在時,將其快取為空值(null)或默認值(key-value對寫成key-null),需要注意的是,針對空值的快取失效時間不宜過長,一般設定為5分鐘之內,當資料庫被寫入或更新該key的新資料時,快取必須同時被重繪,避免資料不一致,?
??方案二:業務邏輯前置校驗
??在業務請求的入口處進行資料合法性校驗(更嚴格的引數校驗:如id長度限制等等),檢查請求引數是否合理、是否包含非法值、是否惡意請求等,提前有效阻斷非法請求,比如,根據年齡查詢時,請求的年齡為-10歲,這顯然是不合法的請求引數,直接在引數校驗時進行判斷回傳,
??方案三:使用布隆過濾器請求白名單
在寫入資料時,使用布隆過濾器進行標記(相當于設定白名單),業務請求發現快取中無對應資料時,可先通過查詢布隆過濾器判斷資料是否在白名單內,如果不在白名單內,則直接回傳慷訓失敗,
所謂布隆過濾器,就是一種資料結構,它是由一個長度為m bit的位陣列與n個hash函陣列成的資料結構,位陣列中每個元素的初始值都是0,在初始化布隆過濾器時,會先將所有key進行n次hash運算,這樣就可以得到n個位置,然后將這n個位置上的元素改為1,這樣,就相當于把所有的key保存到了布隆過濾器中
舉個例子,比如我們一共有3個key,我們對這3個key分別進行3次hash運算,key1經過三次hash運算后的結果分別為2/6/10,那么就把布隆過濾器中下標為2/6/10的元素值更新為1,然后再分別對key2和key3做同樣操作,結果如下圖:
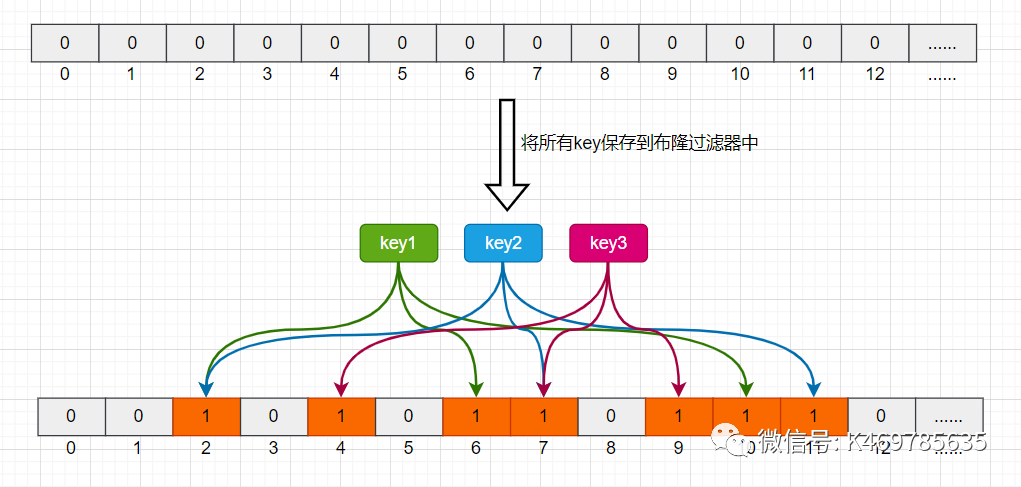
樣,當客戶端查詢時,也對查詢的key做3次hash運算得到3個位置,然后看布隆過濾器中對應位置元素的值是否為1,如果所有對應位置元素的值都為1,就證明key在庫中存在,則繼續向下查詢;如果3個位置中有任意一個位置的值不為1,那么就證明key在庫中不存在,直接回傳客戶端空即可,如下圖:
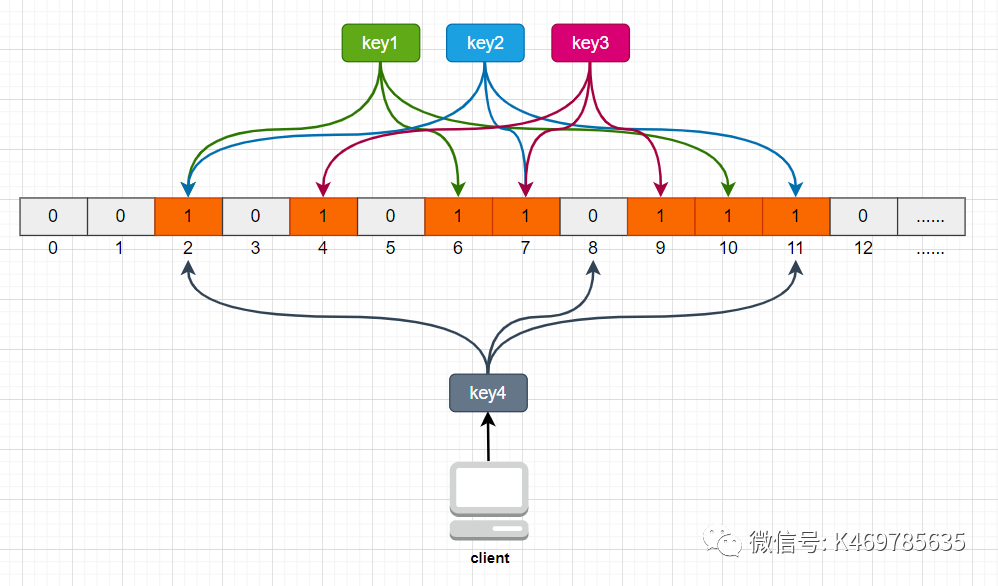
當客戶端查詢key4時,key4的3次hash運算中,有一個位置8的值為0,就說明key4在庫中不存在,直接回傳客戶端空即可,
所以,布隆過濾器就相當于一個位于客戶端與快取層中間的攔截器一樣,負責判斷key是否在集合中存在,如下圖:
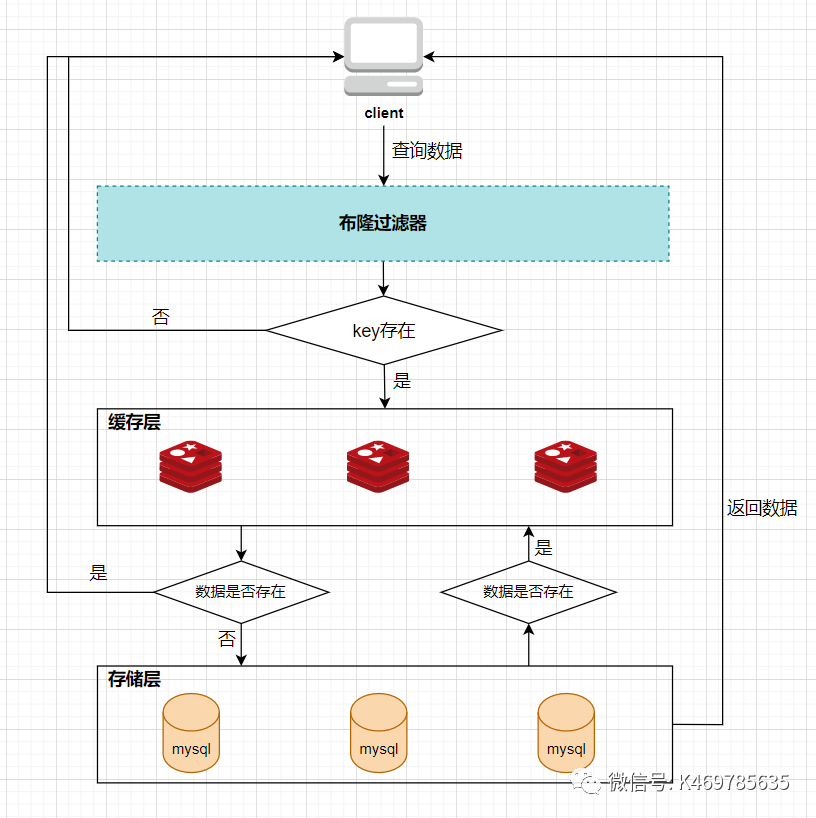
布隆過濾器的好處就是解決了第一種快取空值的不足
但布隆過濾器也存在缺陷,首先,它有誤判的可能,比如在上面客戶端查詢key4的圖中,假如key4經過3次hash運算得到的位置分別是2/4/6,由于這3個位置的值都是1,所以,布隆過濾器就認為key4在庫中存在,進而繼續向下查詢了,所以,布隆過濾器判斷存在的key實際上可能是不存在的,但布隆過濾器判斷不存在的key是一定不存在的,
它的第二個缺點就是洗掉元素比較難,比如現在要洗掉key2這個元素,那么需要將2/7/11三個位置的元素值改為0,但這樣就會影響到key1和key3的判斷,
2.快取雪崩?
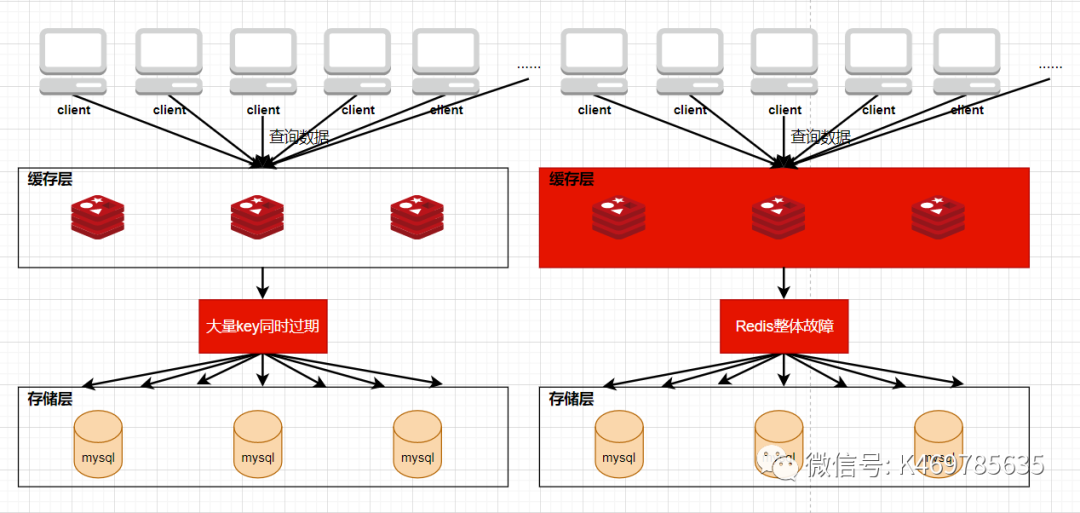
??快取雪崩是指快取同一時間大面積的失效,所以,后面所有的請求會落在資料庫上,造成資料庫短時間內承受大量的請求而崩掉,
??快取雪崩的場景通常有兩個:
-
-
大量熱點key同時過期;
-
快取服務故障;
-
??解決方案:
-
通常的解決方案是將key的過期時間后面加上一個
亂數(比如隨機1-5分鐘),讓key均勻的失效, -
熱點資料可以考慮不失效,后臺異步更新快取,適用于不嚴格要求快取一致性的場景,
-
雙key策略,主key設定過期時間,備key不設定過期時間,當主key失效時,直接回傳備key值,
-
構建快取高可用集群(針對快取服務故障情況),
- 當快取雪崩發生時,服務熔斷、限流、降級等措施保障
快取擊穿
??快取雪崩是指只大量熱點key同時失效的情況,如果是單個熱點key,在不停的扛著大并發,在這個key失效的瞬間,持續的大并發請求就會擊破快取,直接請求到資料庫,好像蠻力擊穿一樣,這種情況就是快取擊穿(Cache Breakdown)
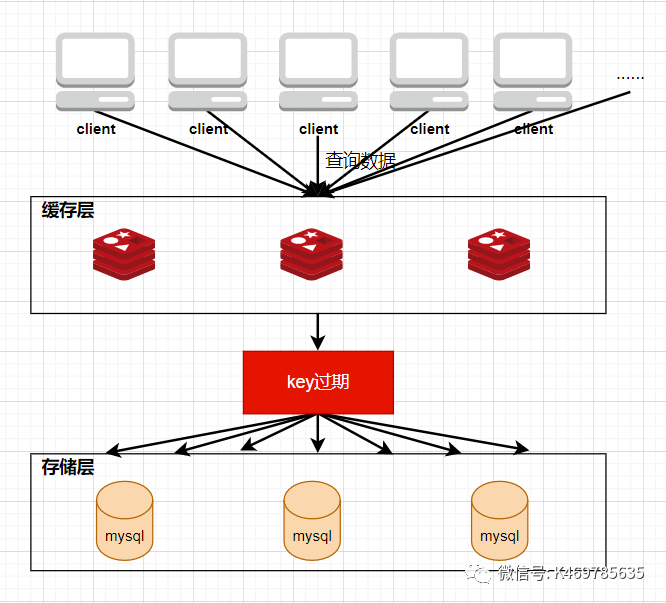
從定義上可以看出,快取擊穿和快取雪崩很類似,只不過是快取擊穿是一個熱點key失效,而快取雪崩是大量熱點key失效,因此,可以將快取擊穿看作是快取雪崩的一個子集
解決方案
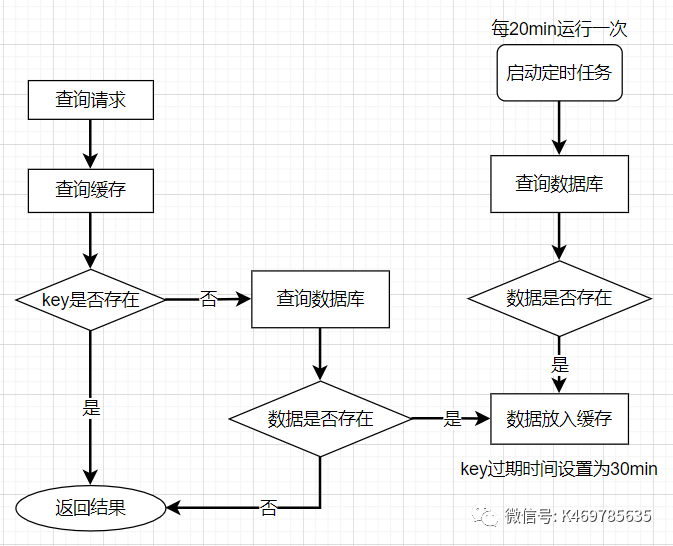
??第一種方式:在設定熱點key的時候,不給key設定過期時間即可,不過還有另外一種方式也可以達到key不過期的目的,就是正常給key設定過期時間,不過在后臺同時啟一個定時任務去定時地更新這個快取,
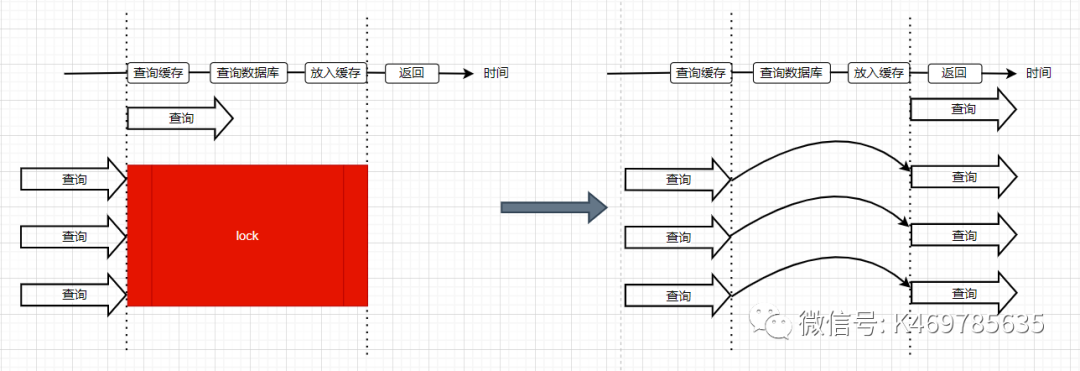
??第二種方式:使用了加鎖的方式,鎖的物件就是key,這樣,當大量查詢同一個key的請求并發進來時,只能有一個請求獲取到鎖,然后獲取到鎖的執行緒查詢資料庫,然后將結果放入到快取中,然后釋放鎖,此時,其他處于鎖等待的請求即可繼續執行,由于此時快取中已經有了資料,所以直接從快取中獲取到資料回傳,并不會查詢資料庫,
??單機通過synchronized或lock來處理,分布式環境采用分布式鎖
4.Redis的事務實作
https://blog.csdn.net/weixin_44743841/article/details/108204218
5.Redis常見的集群部署模式
https://www.cnblogs.com/ricklz/p/15916014.html
6.Redis的主從復制原理(重要)??
搞清楚下面兩種(https://www.cnblogs.com/ricklz/p/15916014.html)
??1.全量同步
??2.增量同步
https://www.cnblogs.com/ricklz/p/15916014.html
https://blog.csdn.net/weixin_48967543/article/details/118358944
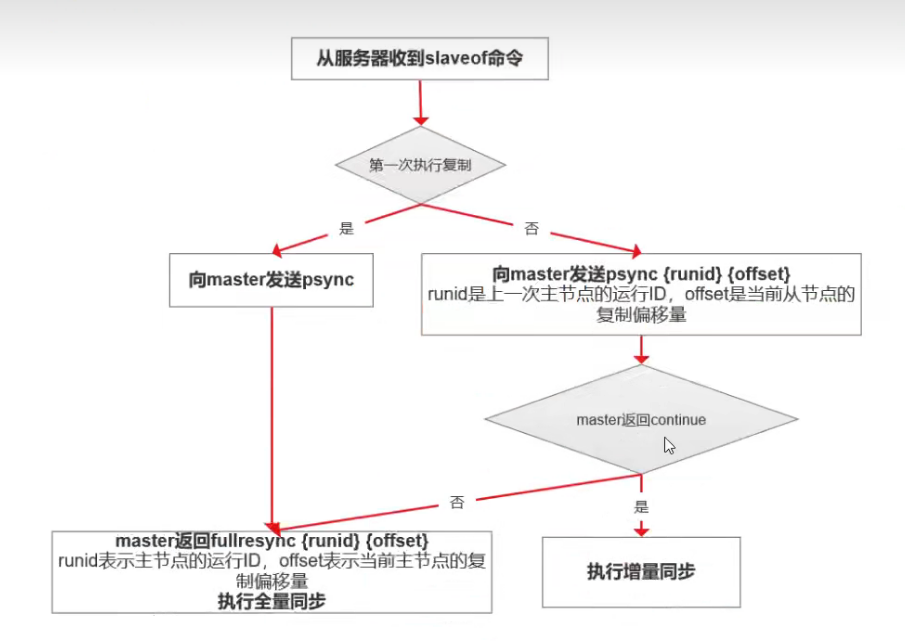
圖的話結合上面連接中的內容和自己的redis筆記理解!
7.高并發的分布式鎖
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/543845.html
標籤:Java