目錄
- 安裝 Reuqests
- HTTP 簡介
- 什么是 HTTP
- HTTP作業原理
- HTTP的9種請求方法
- HTTP狀態碼
- requests 快速上手
- requests 發起請求的步驟
- requests 發起請求的兩種方式
- 請求引數
- 發起 GET 請求
- 發起 POST 請求
- requests 實戰
- 登錄介面的測驗
- 獲取用戶資訊介面的測驗
- 對回應結果的處理(序列化和反序列化)
Requests 是一個 Python 的一個第三方庫,通過發送 HTTP 請求獲取回應資料,一般應用于撰寫網路爬蟲和介面測驗等,
相比 urllib 庫,它語法簡單,更容易上手,
官方中文檔案地址:Requests: 讓 HTTP 服務人類
離線檔案下載地址:Requests document download
安裝 Reuqests
pip install requests
HTTP 簡介
在使用 requests 模擬發送網路請求之前,先來簡單學習一下HTTP和常見的請求方式,
什么是 HTTP
HTTP(HyperText Transfer Protocol ,超文本傳輸協議)是一個簡單的請求/回應協議,即一個客戶端與服務器建立連接后,向服務器發送一個請求;服務器接到請求后,給予相應的回應資訊,
HTTP作業原理
1.客戶端與服務器端建立連接
2.客戶端向服務器端發起請求
3.服務器接受請求,并根據請求回傳相應的內容
4.客服端與服務器端連接關閉
客戶端和服務器端之間的HTTP連接是一種一次性連接,它限制每次連接只處理一個請求,當服務器回傳本次請求的應答后便立即關閉,下次請求再重新建立連接,這樣做的好處就是讓服務器不會處于一個一直等待的狀態,及時釋放連接可極大提高服務器的執行效率,
HTTP是一種無狀態協議,意思就是服務器不保留與客戶端連接時的任何狀態,這減輕了服務器的記憶負擔,從而保持較快的回應速度,
HTTP的9種請求方法
每種請求方式規定了客戶端和服務器端之間不同的資訊交換方式,
| 請求方法 | 描述 |
|---|---|
| GET | 請求指定的頁面資訊,并回傳物體主體, |
| POST | 向指定資源提交資料進行處理請求(例如提交表單或者上傳檔案),資料被包含在請求體中,POST請求可能會導致新的資源的建立或已有資源的修改, |
| HEAD | 類似于 GET 請求,只不過回傳的回應中沒有具體的內容,用于獲取報頭 |
| PUT | 從客戶端向服務器傳送資料取代指定的檔案的內容, |
| PATCH | 是對 PUT 方法的補充,用來對已知資源進行區域更新 |
| DELETE | 請求服務器洗掉指定的頁面 |
| OPTIONS | 允許客戶端查看服務器的性能 |
| TRACE | 回顯服務器收到的請求,主要用于測驗或診斷 |
| CONNECT | HTTP/1.1 協議中預留給能夠將連接改為管道方式的代理服務器 |
請求方法GET和POST的區別:
- GET提交的資料會放在URL之后,以?分割URL和傳輸資料,引數之間以&相連,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的資料放在HTTP包的Body中
- GET提交的資料大小有限制(因為瀏覽器對URL的長度有限制),而POST方法提交的資料沒有限制
- GET方式需要使用Request.QueryString來取得變數的值,而POST方式通過Request.Form來獲取變數的值,
- GET方式提交資料,會帶來安全問題,比如一個登錄頁面,通過GET方式提交資料時,用戶名和密碼將出現在URL上,如果頁面可以被快取或者其他人可以訪問這臺機器,就可以從歷史記錄獲得該用戶的賬號和密碼
HTTP狀態碼
狀態代碼有三位數字組成,第一個數字定義了回應的類別,共分五種類別:
| 分類 | 分類描述 |
|---|---|
| 1** | 指示資訊--服務器收到請求,需要請求者繼續執行操作 |
| 2** | 成功--操作被成功接收并處理 |
| 3** | 重定向--需要進一步的操作以完成請求 |
| 4** | 客戶端錯誤--請求包含語法錯誤或無法完成請求 |
| 5** | 服務器錯誤--服務器在處理請求的程序中發生了錯誤 |
常見的狀態碼:
| 狀態碼 | 含義 |
|---|---|
| 200 OK | 客戶端請求成功 |
| 400 Bad Request | 客戶端請求有語法錯誤,不能被服務器理解 |
| 401 Unauthorized | 請求未經授權,這個狀態碼必須和 WWW-Authenticate 報頭域一起使用 |
| 403 Forbidden | 服務器收到請求,但是拒絕服務 |
| 404 Not Found | 請求資源不存在,eg:輸入了錯誤的URL |
| 500 Internal Server Error | 服務器發生不可預期的錯誤 |
| 503 Server Unavailable | 服務器當掐你不能處理客戶端的請求,一段時間后可能恢復 |
本節參考鏈接:
https://www.cnblogs.com/qdhxhz/p/8468913.html
https://blog.csdn.net/qq_40100414/article/details/120122782
如果你想學習關于 HTTP 的更多知識,可以關注公眾號[愿澤君],輸入"python requests"獲取高清電子書和本文 markdown 筆記,
requests 快速上手
requests 發起請求的步驟
使用 requests 的流程大致可以分為以下三步:
graph LR id1(填寫method url params等引數)-->id2(發起請求)-->id3(查看回應結果)requests 發起請求的兩種方式
使用 requests 發起請求有兩種方式,以發起post請求為例:
import requests
# 方式一:
r = requests.request("post","https://www.baidu.com")
print(r.text)
# 方式二:
r = requests.post("https://www.baidu.com")
print(r.text)
requests.request(method, url, ...)的 request 是 requests 封裝好根據 method 傳參的不同而呼叫對應的請求方法,method 引數的值可以是 get/post/put/delete/head/patch/options 等,對應我們上一節的 HTTP 請求方法,上面的示例代碼中方式一和方式二達到的效果都是一樣的,但是推薦使用方式一,因為在后面的介面自動化測驗中便于引數化,如下:
import requests
method = "get"
url = "https://www.baidu.com"
r = requests.request(method=method, url=url)
print(r.text)
請求引數
requests 發起請求時,支持傳遞的引數串列:
- method:請求的型別,格式為字串,值可以是 get\post\put\delete\files\head\patch\options
- url:請求的介面地址,格式為字串,此引數必傳
- params: get型別的介面請求的資料,格式為字典
- data:form-data 一般用于 post 型別的介面請求的資料,格式為字典/json/字串
- json: json格式的引數,格式為字典
- headers:請求頭,格式為字典
- cookies:格式為字典
- files:上傳檔案,格式為字典
- timeout:請求超時時間,float
- allow_redirects:是否支持重定向,格式為boolean
- verify:是否忽略http協議的證書錯誤,boolean:True 不忽略
在接下來的案例我們會逐一對上面的引數進行詳細講些,
發起 GET 請求
使用 Requests 模擬發送 GET 請求,以請求百度首頁為例:
# 匯入requests庫
import requests
# 要請求的地址
url = "http://www.baidu.com"
# 發起 GET 請求,并將回應結果存盤在 res 中,res是一個 responses 物件
res = requests.get(url)
print(res.request.headers) # 查看請求頭資訊
print(res.request.body) # 查看請求正文
print(res.request.url) # 查看請求url
print(res.request.method) # 查看請求方法
print(res.content) # 回應結果的位元組碼格式,一般用于圖片,視頻資料等
print(res.encoding) # 查看回應正文的編碼格式
print(res.text) # 回應結果的字串格式,非位元組碼
print(res.status_code) # 回應結果狀態碼,200 表示成功
print(r.reason) # 回應狀態碼的描述資訊,如 OK,NotFound 等
print(res.cookies) # 獲取 cookies
print(res.headers) # 查看回應的回應頭
print(res.url) # 查看回應的url
如果回應內容中文顯示是亂碼,在此提供2種解決方案:
import requests
url = "http://www.baidu.com"
res = requests.get(url)
# 方案1:
res.encoding="utf-8" # 如果 res.text 中有中文亂碼,修改編碼格式為 "utf-8"
print(res.text)
# 方案2:
res.content.decode("utf-8") # 將回應結果的位元組碼格式轉換為 "utf-8" 格式
print(res.text)
1)發起攜帶引數的 GET 請求
來看一下 Request 中 get 方法的定義:
def get(url, params=None, **kwargs):
return request("get", url, params=params, **kwargs)
這意味著發起 GET 請求時,允許我們使用 params 關鍵字引數,引數的型別為字典(dict),接下來看一個案例:
慕課網(https://www.imooc.com/)首頁搜索 "python",按 F12 --> 點擊 NetWork 抓包獲取其介面,
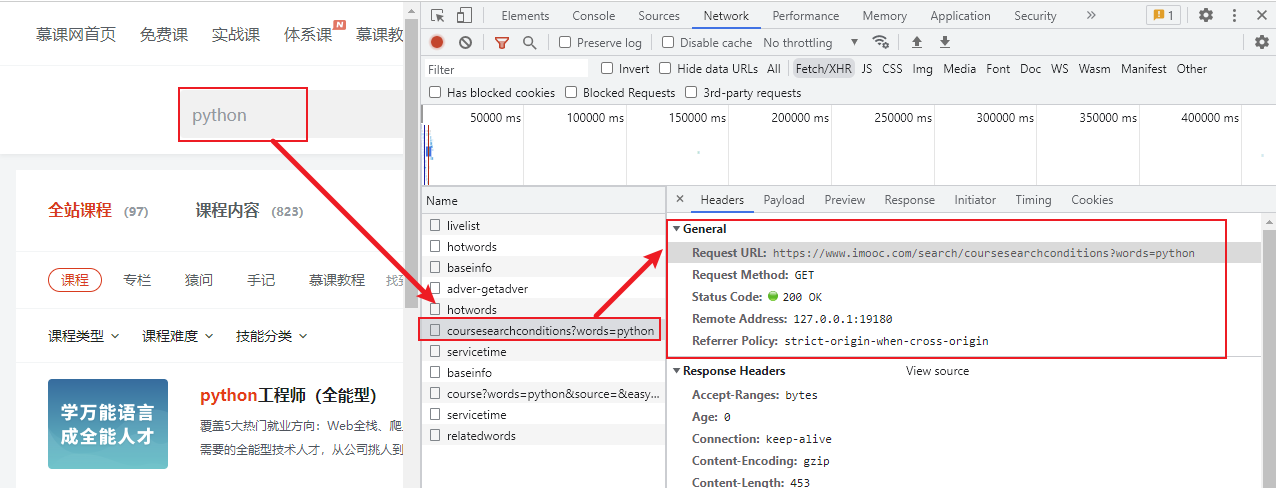
我們得到的介面部分資訊如下:
請求方式:get
請求url:https://www.imooc.com/search/coursesearchconditions?words=python
?words=python問號后面的 word=python 就是我們在發起 get 請求時的要提供的引數,接下來使用 requests 來發起請求:
import requests
# 慕課網首頁課程查詢介面
url = "https://www.imooc.com/search/coursesearchconditions"
# 查詢時攜帶的引數
payload = {
'words': 'python'
}
res = requests.get(url, params=payload) # 發起攜帶引數的 get 請求
print(res.json()) # 回應內容是 json 格式的字串,我們使用 res.json() 方法進行解碼
2)定制請求頭
如果你想為請求添加 HTTP 頭部,只需要傳遞一個字典(dict)給 headers 引數即可,例如,我們發起請求時要傳遞一個 UA(User-Agent),User-Agent 中文名為用戶代理,是Http協議中的一部分,它可以向訪問網站提供你所使用的瀏覽器型別及版本、作業系統及版本、瀏覽器內核、等資訊的標識,通過這個標 識,用戶所訪問的網站可以顯示不同的排版從而為用戶提供更好的體驗或者進行資訊統計,
為什么要添加 UA?
在使用 Python 的 Requests 模擬瀏覽器向服務器發送 Http 請求時,于某些網站會設定對 User-Agent 反爬蟲機制,因此我們發送 Http 請求時有必要的加上 User-Agent 來將爬蟲程式的UA偽裝成某一款瀏覽器的身份標識,
import requests
url = "https://www.imooc.com/search/coursesearchconditions"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'}
# 查詢時攜帶的引數
payload = {
'words': 'python'
}
res = requests.get(url, params=payload, headers=headers)
print(res.json()) # 回應內容是 json 格式的字串,我們使用 res.json() 方法進行解碼
print(res.request.headers) # 查看請求頭
關于 Header 偽裝策略的更多知識請參考以下博文:
- https://blog.csdn.net/weixin_38950569/article/details/105231122
- https://blog.csdn.net/ShyLoneGirl/article/details/117297325
發起 POST 請求
1)傳遞 data 引數
當我們要向網頁上的一些表單(form)傳遞資料時,經常需要發起 post 請求,使用 requests 發起 post 請求的方法也非常簡單,只需要傳遞一個字典給 data 引數,
import requests
url = 'http://httpbin.org/post'
payload = {'name': 'joy', 'phone': '400-7865-6666'}
r = requests.post(url=url, data=https://www.cnblogs.com/keepcode/p/payload)
print(r.text)
運行結果:
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
還可以為 data 引數傳入一個元組串列,例如表單中多個元素使用同一個 key 時,可以像下面這樣做:
import requests
url = 'http://httpbin.org/post'
payload = (('course', 'Python'), ('course', 'Java'))
r = requests.post(url=url, data=https://www.cnblogs.com/keepcode/p/payload)
print(r.text)
回應結果:
{
...
"form": {
"course": [
"Python",
"Java"
]
},
...
}
當你想用 data 引數去接收 json 格式的資料,那么需要把請求的資料轉換成 json 格式,并且要將請求頭設定為 application/json,
import requests, json
url = 'https://api.github.com/some/endpoint'
data = https://www.cnblogs.com/keepcode/p/json.dumps({"some": "data"
})
headers = {"Content-Type":"application/json"}
r = requests.post(url, data=https://www.cnblogs.com/keepcode/p/data, headers=headers)
print(r.text)
2) 傳遞json引數
可以使用 json 引數直接傳遞,然后它就會被自動編碼
import requests, json
url = "http://119.45.233.102:6677/testgoup/test/json"
data = https://www.cnblogs.com/keepcode/p/{'name': 'jay',
'age': 23
}
r = requests.post(url,json=data)
print(r.text)
這里科普一下 json 和 dict(字典)的區別:
(1)字典是一種資料結構,是python中的一種資料型別;它是一種可變型別,可以存盤任意型別的數值,以 key:value 的形式存盤資料,但是 key 可以是任意可hash的物件 ,在一個字典中不允許出現兩個相同的key值,如果出現,后面一個key值會覆寫前面的key值,
(2)Json是一種打包的資料格式,本質上是字串,也是按照 key:value 來存盤資料,key 只能時字串,且可以有序、重復;必須使用雙引號作為key或者值的邊界符,不能使用單引號,使用單引號或者不使用引號會使決議錯誤,可以被決議為字典或者其他形式,
(3)json.loads函式的使用,將字串轉化為字典
import json a = {'a': '1', 'b': '2', 'c': '3' } print(type(a)) # 輸出 <class 'dict'> b = json.loads('{"age": "12"}') # 引數是str行,loads之后,變成dict字典了 print(b) # 輸出 {'age': '12'} print(type(b)) # 輸出 <class 'dict'>(4)json.dumps()函式的使用,將字典轉化為字串
import json # json.dumps()函式的使用,將字典轉化為字串 dict1 = {"age": "12"} json_info = json.dumps(dict1) print("dict1的型別:"+str(type(dict1))) print("通過json.dumps()函式處理:") print("json_info的型別:"+str(type(json_info)))本部分參考來源:字典和Json的區別
3)傳遞 from-data 引數:
注意,requests默認是不支持from-data的請求資料的格式的,所以我們要傳from-data格式,我們需要安裝一個requests的插件:
pip install requests_toolbelt -i https://pypi.douban.com/simple
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
method = "post"
url = "http://119.45.233.102:6677/testgoup/test/data"
data = https://www.cnblogs.com/keepcode/p/MultipartEncoder({"name":"張三",
"age":"23"
})
headers = {"Content-Type":data.content_type}
r = requests.request(method,url,data=https://www.cnblogs.com/keepcode/p/data,headers=headers)
print(r.text)
4)傳遞 auth 引數
auth是一種對介面進行鑒權的方式,和cookies和token的作用差不多的,格式:元組,比如:(“賬號”,“密碼”)
import requests
url = "http://119.45.233.102:6677/testgoup/test/auth"
method = "post"
auth = ("admin","123456")
r = requests.request(method,url,auth=auth)
print(r.text)
5)傳遞 timeout 引數
timeout用于控制回應的時間,如果超過了timeout規定的時間,那么會直接拋出連接失敗的錯誤資訊,timeout格式是整數,單位是秒,
import requests
method = "post"
url = "http://119.45.233.102:6677/testgoup/test/json"
data = https://www.cnblogs.com/keepcode/p/{"name":"張三",
"age":23
}
r = requests.request(method,url,json=data,timeout=10)
print(r.text)
6)傳遞 allow_redirects 引數
是否允許介面重定向,格式:布林值
7)傳遞 proxies 引數
在撰寫爬蟲程式時,同一個IP頻繁對網站進行訪問,可能會被封IP,為了避免這種情況我們就需要用到 proxies 引數來設定代理,proxies 引數可以將代理地址替換為你的IP地址,隱藏自身IP,
proxies 引數型別
proxies = { '協議':'協議://IP:埠號' }
proxies = {
'http':'http://IP:埠號',
'https':'https://IP:埠號',
}
可以去網上搜索免費的代理IP網站中查找免費代理IP(注意:如果獲取到的免費IP地址無效就會報錯):
# 使用免費普通代理IP訪問測驗網站: http://httpbin.org/get
import requests
url = 'http://httpbin.org/get'
headers = {'User-Agent':'Mozilla/5.0'}
# 定義代理,在代理IP網站中查找免費代理IP
proxies = {
'http':'http://182.116.239.37:9999',
'https':'https://182.116.239.37:9999'
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
這里推薦幾個免費代理網站,可自行嘗試:
- http://www.66ip.cn/
- https://www.kuaidaili.com/free/inha
本部分參考來源:關于代理引數-proxies那些事
8)傳遞 verify 引數
當我們請求https協議的介面的時候,如果它的證書過期了,我們就可以使用這個引數verify,設定為Fasle不檢查證書,忽略證書的問題,繼續請求,
本部分參考來源:requests從入門到精通
requests 實戰
登錄介面的測驗
TGU登錄介面測驗,登錄介面資訊如下:
地址:http://119.45.233.102:2244/testgoup/login
型別:post
請求頭:application/json
請求引數:{
"phone": "133********",
"password": "e10adc3949ba59abbe56e057f20f883e",
"type": 1
}
回傳值:{
"code": 1,
"data": {
"nickName": "liuyanzu666",
"token": "eyJ..."
},
"message": "登錄成功!"
}
使用requests測驗登錄介面:
import requests
loginUrl = 'http://119.45.233.102:2244/testgoup/login'
method='post'
data = https://www.cnblogs.com/keepcode/p/{"phone": "133********",
"password": "e10adc3949ba59abbe56e057f20f883e",
"type": 1
}
r = requests.request(method=method, url=loginUrl, json=data)
print(r.text)
獲取用戶資訊介面的測驗
由于需要登錄后才能獲取到用戶資訊,在獲取用戶資訊時需要傳入登錄后回傳的token,完整代碼如下:
import requests
loginUrl = 'http://119.45.233.102:2244/testgoup/login'
method='post'
data = https://www.cnblogs.com/keepcode/p/{"phone": "133********",
"password": "e10adc3949ba59abbe56e057f20f883e",
"type": 1
}
#登錄介面
r = requests.request(method=method, url=loginUrl, json=data)
# print(r.text)
token = r.json()['data']['token']
# 獲取用戶資訊介面
userinfoUrl = 'http://119.45.233.102:2244/testgoup/user/getUserInfo'
headers = {'token': token}
r = requests.request(method='get', url=userinfoUrl, headers=headers)
print(r.text)
上述實戰代碼均在 TestGoUp 網站開展測驗,并對賬號進行了加密,可自行注冊獲取自己的賬號進行測驗,
對回應結果的處理(序列化和反序列化)
上面代碼中的 token = r.json()['data']['token'] 里有一個細節這里要展開敘述一下,來看一下登錄介面回傳的回應結果,也就是 print(r.text) 的值:
{
"code": 1,
"data": {
"nickName": "liuyanzu666",
"token": "eyJhbGci..." # token太長了,這里刪掉部分資料
},
"message": "登錄成功!"
}
咋一看這是一個python字典型別的資料,有的同學可能說這是 json 型別的資料,到底是字典還是json型別的資料,我們使用 type() 方法對 r.text 進行判斷即可,
print(type(r.text)) # 回傳結果是 <class 'str'>
回傳結果居然是 str 型別的資料,現在我們要從 r.text 中獲取 token 值,如果我們將它從 str 型別轉換成字典型別,那么就可以通過 token 鍵獲取對應的 toekn 值了,這里就引出了我們要講的知識點:
Python序列化和反序列化
序列化:將Python中字典型別的資料轉換成json格式的字串,以便進行存盤和傳輸,
反序列化:將json格式的字串轉換成Python的字典型別資料,便于對其分析和處理,
我們可以使用 json 模塊來實作序列化和反序列化:
import json
# 字典型別的資料
data = https://www.cnblogs.com/keepcode/p/{"name": "張三",
"age": 18
}
# 使用 json.dumps() 進行序列化:字典-->字串
res = json.dumps(data)
print(res) # 輸出結果:{"name": "\u5f20\u4e09", "age": 18}
print(type(res)) # 輸出結果:<class 'str'>
# 使用 json.loads() 進行反序列化:字串-->字典
res2 = json.loads(res)
print(res2) # 輸出結果:{'name': '張三', 'age': 18}
print(type(res2)) # 輸出結果:<class 'dict'>
上面闡述了使用 python 進行序列化和反序列化的方法,但是在登錄介面中獲取token值的時候 ,我們并沒有使用 json.loads() 進行反序列化,而是使用 ``token = r.json()['data']['token'],也就是r.json()` 方法,
也就是說在上面的代碼中,獲取token我們可以使用兩種方法:
...
r = requests.request(method=method, url=loginUrl, json=data)
方法一:
token = json.loads(r.text)['data']['token']
方法二:
token = r.json()['data']['token']
...
至此,關于 Python Requests 的介紹就告一段落了,感謝您的閱讀,如果本文對您有幫助,請幫我點個贊吧~如果想獲取本文的 markdown 筆記、電子書和相關源代碼,請關注我的WX公眾號[愿澤君],發送 "python requests" 即可,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/544323.html
標籤:Python
上一篇:跟著廖雪峰學python 005