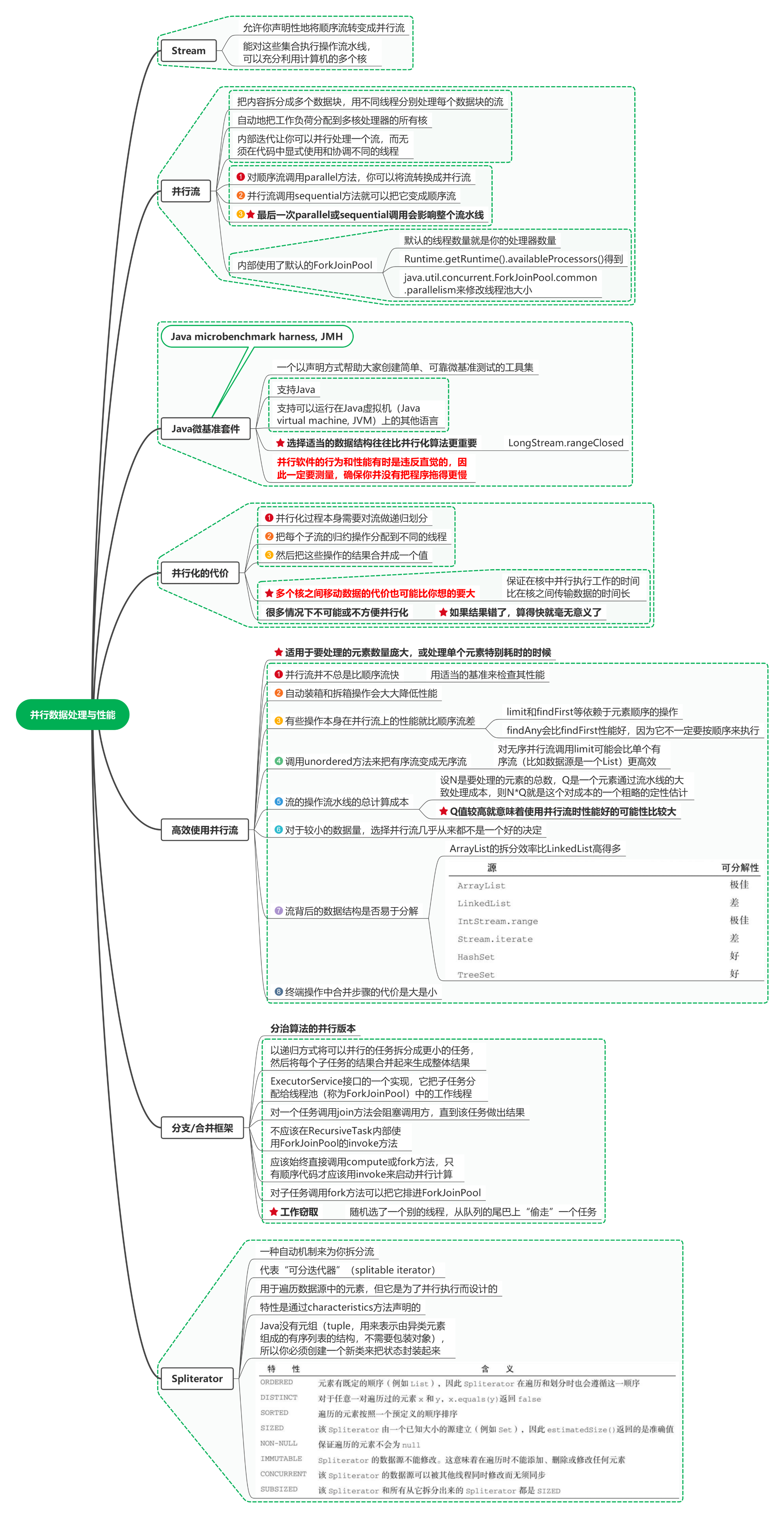
1. Stream
1.1. 允許你宣告性地將順序流轉變成并行流
1.2. 能對這些集合執行操作流水線,可以充分利用計算機的多個核
2. 并行流
2.1. 把內容拆分成多個資料塊,用不同執行緒分別處理每個資料塊的流
2.2. 自動地把作業負荷分配到多核處理器的所有核
2.3. 內部迭代讓你可以并行處理一個流,而無須在代碼中顯式使用和協調不同的執行緒
2.4. 對順序流呼叫parallel方法,你可以將流轉換成并行流
2.5. 并行流呼叫sequential方法就可以把它變成順序流
2.6. 最后一次parallel或sequential呼叫會影響整個流水線
2.7. 內部使用了默認的ForkJoinPool
2.7.1. 默認的執行緒數量就是你的處理器數量
2.7.2. Runtime.getRuntime().availableProcessors()得到
2.7.3. java.util.concurrent.ForkJoinPool.common.parallelism來修改執行緒池大小
3. Java微基準套件
3.1. Java microbenchmark harness, JMH
3.2. 一個以宣告方式幫助大家創建簡單、可靠微基準測驗的工具集
3.3. 支持Java
3.4. 支持可以運行在Java虛擬機(Java virtual machine, JVM)上的其他語言
3.5. 選擇適當的資料結構往往比并行化演算法更重要
3.5.1. LongStream.rangeClosed
3.6. 并行軟體的行為和性能有時是違反直覺的,因此一定要測量,確保你并沒有把程式拖得更慢
4. 并行化的代價
4.1. 并行化程序本身需要對流做遞回劃分
4.2. 把每個子流的歸約操作分配到不同的執行緒
4.3. 然后把這些操作的結果合并成一個值
4.4. 多個核之間移動資料的代價也可能比你想的要大
4.4.1. 保證在核中并行執行作業的時間比在核之間傳輸資料的時間長
4.5. 很多情況下不可能或不方便并行化
4.5.1. 如果結果錯了,算得快就毫無意義了
5. 高效使用并行流
5.1. 適用于要處理的元素數量龐大,或處理單個元素特別耗時的時候
5.2. 并行流并不總是比順序流快
5.2.1. 用適當的基準來檢查其性能
5.3. 自動裝箱和拆箱操作會大大降低性能
5.4. 有些操作本身在并行流上的性能就比順序流差
5.4.1. limit和findFirst等依賴于元素順序的操作
5.4.2. findAny會比findFirst性能好,因為它不一定要按順序來執行
5.5. 呼叫unordered方法來把有序流變成無序流
5.5.1. 對無序并行流呼叫limit可能會比單個有序流(比如資料源是一個List)更高效
5.6. 流的操作流水線的總計算成本
5.6.1. 設N是要處理的元素的總數,Q是一個元素通過流水線的大致處理成本,則N*Q就是這個對成本的一個粗略的定性估計
5.6.2. Q值較高就意味著使用并行流時性能好的可能性比較大
5.7. 對于較小的資料量,選擇并行流幾乎從來都不是一個好的決定
5.8. 流背后的資料結構是否易于分解
5.8.1. ArrayList的拆分效率比LinkedList高得多

5.9. 終端操作中合并步驟的代價是大是小
6. 分支/合并框架
6.1. 分治演算法的并行版本
6.2. 以遞回方式將可以并行的任務拆分成更小的任務,然后將每個子任務的結果合并起來生成整體結果
6.3. ExecutorService介面的一個實作,它把子任務分配給執行緒池(稱為ForkJoinPool)中的作業執行緒
6.4. 對一個任務呼叫join方法會阻塞呼叫方,直到該任務做出結果
6.5. 不應該在RecursiveTask內部使用ForkJoinPool的invoke方法
6.6. 應該始終直接呼叫compute或fork方法,只有順序代碼才應該用invoke來啟動并行計算
6.7. 對子任務呼叫fork方法可以把它排進ForkJoinPool
6.8. 作業竊取
6.8.1. 隨機選了一個別的執行緒,從佇列的尾巴上“偷走”一個任務
7. Spliterator
7.1. 一種自動機制來為你拆分流
7.2. 代表“可分迭代器”(splitable iterator)
7.3. 用于遍歷資料源中的元素,但它是為了并行執行而設計的
7.4. 特性是通過characteristics方法宣告的
7.5. Java沒有元組(tuple,用來表示由異類元素組成的有序串列的結構,不需要包裝物件),所以你必須創建一個新類來把狀態封裝起來

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/544385.html
標籤:其他