作者:京東物流 秦彪
1. 引言
排序是一個Java開發者,在日常開發程序中隨處可見的開發內容,Java中有豐富的API可以呼叫使用,在Java語言中,作為集合工具類的排序方法,必定要做到通用、高效、實用這幾點特征,使用什么樣排序演算法會比較合適,能夠做到在盡量降低時間、空間復雜度的情況下,又要兼顧保證穩定性,達到優秀的性能,可能從性能角度出發首先會想到的是快速排序,或者歸并排序,作為jdk提供的通用排序功能,使用又如此頻繁,肯定有獨特之處,一起來看學習下期中的奧秘,
文中不會過多的介紹幾大基本排序演算法的方式、由來和思想,主要精力集中在一塊探討java中排序方法所使用的演算法,以及那些是值得我們學習和借鑒的內容,文中如有理解和介紹的錯誤,一起學習,一起探討,一起進步,
2. 案例
日常使用最為頻繁的排序,莫過于如下代碼案例,給定一個現有的序列進行一定規則下的排序,配合java8的stream特性,可以很方便的對一個集合進行排序操作(排序規則只是對排序物件及排序方案的限定,不在本文討論范圍內),
List<Integer> list = Arrays.asList(10, 50, 5, 14, 16, 80);
System.out.println(list.stream().sorted().collect(Collectors.toList()));
在代碼執行的程序中SortedOps.java類中 Arrays.sort(array, 0, offset, comparator); 執行了Array集合型別的sort排序演算法,
@Override
public void end() {
Arrays.sort(array, 0, offset, comparator);
downstream.begin(offset);
if (!cancellationWasRequested) {
for (int i = 0; i < offset; i++)
downstream.accept(array[i]);
}
else {
for (int i = 0; i < offset && !downstream.cancellationRequested(); i++)
downstream.accept(array[i]);
}
downstream.end();
array = null;
}
如果使用Collections.sort() 方法如下列印 list1 和 list2 結果一樣,且呼叫的都是 Arrays 集合類中的 sort 方法,
List<Integer> list1 = Arrays.asList(10, 50, 5, 14, 16, 80);
System.out.println(list1.stream().sorted().collect(Collectors.toList()));
List<Integer> list2 = Lists.newArrayList();
list2.addAll(list1);
Collections.sort(list2);
System.out.println(list2);
// 輸出:
// [5, 10, 14, 16, 50, 80]
// [5, 10, 14, 16, 50, 80]
2. Collections.sort 方法介紹
Collections類中關于sort方法定義如下:
public static <T extends Comparable<? super T>> void sort(List<T> list) {
list.sort(null);
}
通過該方法注釋,查看到有三項值得關注的資訊,大概意思是該方法實作了穩定且默認升序排序的功能,
1. Sorts the specified list into ascending order, according to the Comparable natural ordering of its elements.
2. This sort is guaranteed to be stable equal elements will not be reordered as a result of the sort.
3. The specified list must be modifiable, but need not be resizable.
進入sort,代碼進入到List類的sort方法,發現方法將入參list先轉為了陣列Object[],之后利用Arrays.sort進行排序,
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
首先在這里思考一個問題為什么要轉為陣列,問題答案已經在方法的英文注釋中說明白了,
* The default implementation obtains an array containing all elements in
* this list, sorts the array, and iterates over this list resetting each
* element from the corresponding position in the array. (This avoids the
* n<sup>2</sup> log(n) performance that would result from attempting
* to sort a linked list in place.)
是為了避免直接對List
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a);
} else {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, 0, a.length, c, null, 0, 0);
}
}
3. TimSort 演算法介紹
Timsort是一個自適應的、混合的、穩定的排序演算法,是由Tim Peter于2002年發明的,最早應用在Python中,現在廣泛應用于Python、Java、Android 等語言與平臺中,作為基礎的排序演算法使用,其中Java語言的Collection.sort在JDK1.6使用的是普通的歸并排序,歸并排序雖然時間復雜度低,但是空間復雜度要求較高,所以從JDK1.7開始就更改為了TimSort演算法,
Timsort 的時間復雜度是 O(n log n),與歸并排序的時間復雜度相同,那它的優勢是啥呢,實際上可以認為TimSort排序演算法是歸并排序演算法的優化版,從它的三個特征就可以看出,第二個特征“混合的”,沒錯,它不單純是一種演算法,而是融合了歸并演算法和二分插入排序演算法的精髓,因此能夠在排序性能上表現優異,其它兩個特征自適應和穩定性會在文章后面講到,首先從演算法性能統計上做個對比:
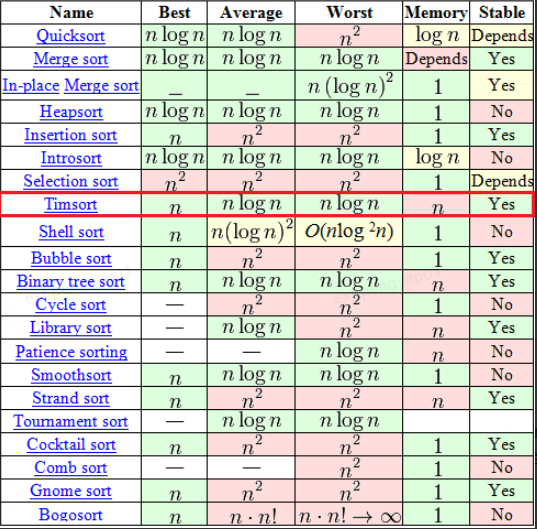
可以看出TimSort排序演算法,平均和最壞時間復雜度是O(nlogn),最好時間復雜度是O(n),空間復雜度是O(n),且穩定的一種排序演算法,在穩定演算法中,從性能效果上對比來看和二叉排序演算法一樣,
3.1 TimSort的核心思想
那TimSort演算法的核心思想是什么呢,首先原始的TimSort對于長度小于64的資料(java中是32),會直接選擇二分插入排序,效率很高,其次,TimSort演算法的初衷認為現實中的資料總是部分有序的,這句話很關鍵,怎么理解呢,比如串列[5, 2, 8, 5, 7,23, 45, 63],里面的[5, 2] 和 [8, 5] 和 [7, 23, 45,63] 各子串列中就是有序的,要么升序要么降序,這就是TimSort的基本根據,
基于此會發現待排序串列已經部分有序了,所以會在排序程序中盡量不要破壞這種順序,就可以做到減少排序時間消耗,基本思想說完了,由此引出TimSort演算法的幾個概念:run和minrun,
run是指連續升序或者連續降序的最長子序列(降序和升序可以相互轉換),而minrun是一個設定值,實際上是每個run的長度最小值,所以TimSort會對待排序序列進行劃分,找出連續有序的子序列,如果子序列長度不滿足這點要求,就將后續資料插入到前面的子序列中,
舉個例子,待排序序列[5, 2, 8, 5, 7,23, 45, 63], 如果minRun = 3,那分割后的run會有以下:[2, 5, 8]、[5,7,23,45,63] 兩個子序列,最終通過合并這兩個run得到[2,5,5,7,8,23,45,63]
是不是有個疑問: minrun怎么選擇得到的?該值是通過大量的統計計算給出的minrun長度建議是在32 ~ 64之間取值效率比較高,具體在java代碼中可能會有所不同,
接著來看,假設現在有序子序列已經拆分好了,需要進入到合并程序中了,TimSort是如何合并子序列的,對于歸并排序我們都知道,序列先歸后并,兩兩組合利用一個空陣列直接進行比較就合并了,但是在TimSort演算法中,合并程序是實時的,每次算出一個run就可能做一次合并,這個程序利用了堆疊結構,且需要遵循相鄰的run才可以合并,也就是只有相鄰的堆疊元素可以進行合并,
規則如下:假設當前有三個run子序列依次入堆疊,現在堆疊頂有三個元素從上至下依次為x3、x2、x1,它們的長度只要滿足以下兩個條件中的任何一個就進行合并:
(1)x1 <= x2 + x3
(2)x1 <= x2
滿足這個條件的三個序列,像漢諾塔一樣長度由下往上依次減小,剛才提到合并run的程序是實時的,也就是每產生一個run就進行一次合并操作,舉例說明下,當前假設待排序序列[2,6,8,4,2,5,7,9,10,11,4,25,64,32,78,99],其中再假設minrun=3是合理的,合并程序是這樣的,注意這里的壓堆疊和彈堆疊不一定需要對子序列本身進行操作,不是真的將子序列放入堆疊中,而只需要run標識以及長度即可,因為堆疊元素比較的是run長度,
(1)首先第一個run0是[2,6,8],而第二個run1是[2,4,5],此時依次將其放入堆疊中,發現滿足第二個條件,這兩個run進行合并,合并后將舊序列從堆疊中彈出,得到新的run0是[2,2,4,5,6,8],再次壓入堆疊中,
(2)繼續從原序列中找到新的run1是[7,9,10,11],壓入堆疊中,此時run0和run1不滿足條件不需要合并,繼續從原序列中找到run2是[4,25,64],壓入堆疊中,此時滿足第一個條件,這里的run1和run2需要進行合并,合并后將舊序列從堆疊中彈出,新run1是[4,7,9,10,11,25,64],壓入堆疊中,
(3)此時發現run0和run1滿足第二個條件,繼續合并彈出舊序列,得到新run0是[2,2,4,4,5,6,7,8,9,10,11,25,64],壓入堆疊中,
(4)繼續從原序列中找到新的run1是[32,78,99],壓入堆疊中,此時發現沒有更多元素,而條件是不滿足的,依然進行一次合并,彈出舊序列,壓入合并后的新子序列run0是[2,2,4,4,5,6,7,8,9,10,11,25,32,64,78,99]
(5)此時將run0拷貝到原序列就完成了排序
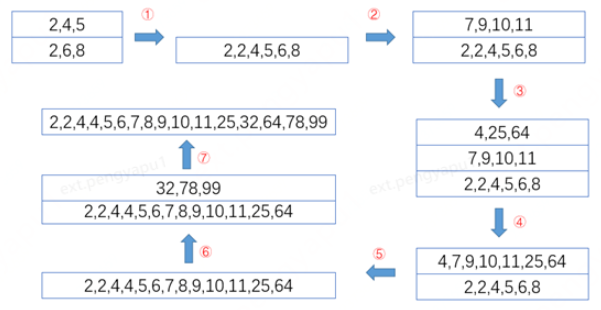
為什么要設定這么兩個合并run的嚴格條件,直接壓堆疊合并豈不更好?目的是為了避免一個較長的有序片段和一個較小的有序片段進行歸并,在合并長度上做到均衡效率才高,
在合并run的程序中會用到一種所謂的gallop(飛奔)模式,能夠減少參與歸并的資料長度,主要程序如下:假設有待歸并的子序列x和y,如果x的前n個元素都是比y首元素小的,那這n個元素實際上就不用參與歸并了,原因就是這n個元素本來已經有序了,歸并后還是在原來的位置,同理而言,如果y的最后幾個元素都比x最后一個元素小,那y的最后這n個元素也就不必參與歸并操作了,這樣就可以減少歸并長度,減少來回復制多余資料的開銷,
3.2 Java原始碼
探討完TimSort的核心思想及其排序程序,現在來看下java代碼是如何實作的,Java1.8中的TimSort類位置在java.util.TimSort
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c,
T[] work, int workBase, int workLen) {
assert c != null && a != null && lo >= 0 && lo <= hi && hi <= a.length;
int nRemaining = hi - lo;
if (nRemaining < 2)
return;
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);
binarySort(a, lo, hi, lo + initRunLen, c);
return;
}
TimSort<T> ts = new TimSort<>(a, c, work, workBase, workLen);
int minRun = minRunLength(nRemaining);
do {
int runLen = countRunAndMakeAscending(a, lo, hi, c);
if (runLen < minRun) {
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen, c);
runLen = force;
}
ts.pushRun(lo, runLen);
ts.mergeCollapse();
lo += runLen;
nRemaining -= runLen;
} while (nRemaining != 0);
assert lo == hi;
ts.mergeForceCollapse();
assert ts.stackSize == 1;
}
變數nRemaining記錄的是待排序串列中剩余元素個數, MIN_MERGE就是前文中提到的java中的minrun值是32,如果nRemaining<32,用countRunAndMakeAscending(…)方法得到連續升序的最大個數,里面涉及到升序降序調整,可以看到如果待排序串列小于32長度,就進行二分插入排序binarySort(…),
如果待排序串列長度大于32,呼叫TimSort物件的minRunLength(nRemaining) 計算minRun,這里就體現了動態自適應,具體來看代碼中是如何做的,r為取出長度n的二進制每次右移的一個溢位位值,n每次右移1位,直到長度n小于32,n+r最終結果就是保留長度n的二進制的高5位再加上1個移除位,根據注釋可以看出:
- 如果待排序陣列長度為2的n次冪,比如1024,則minRun = 32/2 = 16
- 其它情況的時候,逐位右移,直到找到介于16<=k<=32的值,
假如待排序串列長度是7680,二進制是1111000000000,按照操作后是11110十進制是30,再加上移除位0是30,所以minRun=30
private static int minRunLength(int n) {
assert n >= 0;
int r = 0; // Becomes 1 if any 1 bits are shifted off
while (n >= MIN_MERGE) {
r |= (n & 1);
n >>= 1;
}
return n + r;
}
接下來在回圈中進行處理:
(1) 計算最小升序的run長度,如果小于minRun,使用二分插入排序將run的長度補充到minRun要求的長度,
(2) ts.pushRun(lo, runLen) ,通過堆疊記錄每個run的長度,這里lo是run的第一個元素的索參考來標記操作的是哪個run,runLen是run的長度,
private void pushRun(int runBase, int runLen) {
this.runBase[stackSize] = runBase;
this.runLen[stackSize] = runLen;
stackSize++;
}
(3)ts.mergeCollapse(); 通過計算前面提到的兩個run合并的限定條件,分別是:
- runLen[n-1] <= runLen[n] + runLen[n+1]
- runLen[n] <= runLen[n + 1]
private void mergeCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
if (n > 0 && runLen[n-1] <= runLen[n] + runLen[n+1]) {
if (runLen[n - 1] < runLen[n + 1])
n--;
mergeAt(n);
} else if (runLen[n] <= runLen[n + 1]) {
mergeAt(n);
} else {
break; // Invariant is established
}
}
}
(4) 這里的mergeAt(n) 歸并排序程序,之前有提到是經過優化后所謂gallop模式的歸并排序,具體表現在方法中的gallopRight和gallopLeft方法,
int k = gallopRight(a[base2], a, base1, len1, 0, c);
assert k >= 0;
base1 += k;
len1 -= k;
if (len1 == 0)
return;
len2 = gallopLeft(a[base1 + len1 - 1], a, base2, len2, len2 - 1, c);
assert len2 >= 0;
if (len2 == 0)
return;
假設有X序列[4,9,21,23], Y序列[5,7,12,13,14,15,17],由于X中4小于Y序列最小元素5,所以合并后4必然是第一個元素;而Y序列中尾元素17比X中的[21,23]小,所以X中的[21,23]必然是合并最后兩元素,
4. DivalQuickSort 演算法介紹
前文案例中提到SortedOps.java類,該類中對于基本型別的排序呼叫 Arrays.sort(ints); 或 Arrays.sort(longs); 再或 Arrays.sort(doubles); 使用了DivalQuickSort排序演算法,
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
4.1 DivalQuickSort 核心思想
快速排序使用的是在排序序列中選擇一個數作為磁區點pivot,也就是所謂的軸,然后以此軸將資料分為左右兩部分,大于該值的為一個區,小于該值的為一個區,利用分治和遞回思想實作,如下假設選擇19為pivot值,
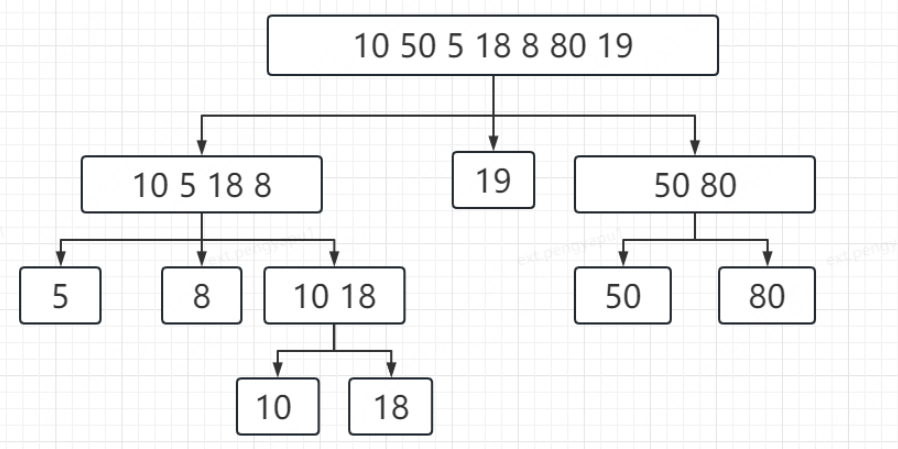
雙軸快排,如其名字所示,就是會選取兩個數作為pivot,這樣就會劃分出三個區間,實際在執行中會有4個區間,分別是小于等于pivot1區間;pivot1和pivot2之間區間,待處理區間; 大于等于pivot2區間,如下假設選擇10和19為兩個pivot值,
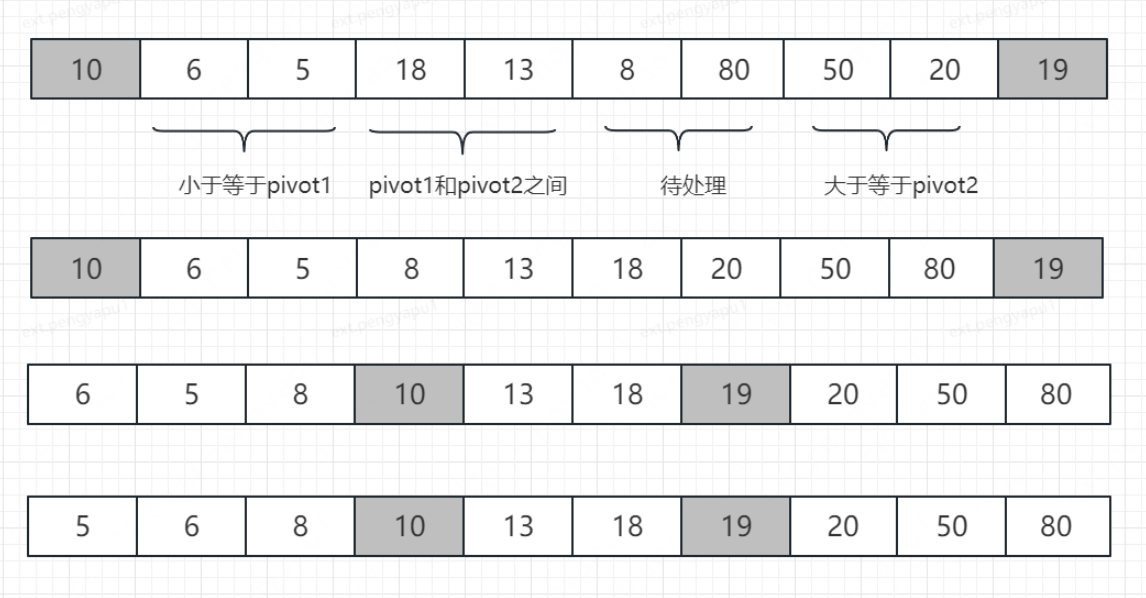
每次遞回迭代時遍歷待處理的區域資料,然后比較它應該放的位置,并進行交換操作,逐漸壓縮待處理區域的資料長度,處理掉待處理區域的元素資料;執行完畢一輪資料后交換pivot數值,然后各自區間再進行遞回排序即可,
4.2 Java原始碼
static void sort(int[] a, int left, int right,
int[] work, int workBase, int workLen) {
if (right - left < QUICKSORT_THRESHOLD) {
sort(a, left, right, true);
return;
}
int[] run = new int[MAX_RUN_COUNT + 1];
int count = 0; run[0] = left;
for (int k = left; k < right; run[count] = k) {
if (a[k] < a[k + 1]) { // ascending
while (++k <= right && a[k - 1] <= a[k]);
} else if (a[k] > a[k + 1]) { // descending
while (++k <= right && a[k - 1] >= a[k]);
for (int lo = run[count] - 1, hi = k; ++lo < --hi; ) {
int t = a[lo]; a[lo] = a[hi]; a[hi] = t;
}
} else { // equal
for (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k]; ) {
if (--m == 0) {
sort(a, left, right, true);
return;
}
}
}
if (++count == MAX_RUN_COUNT) {
sort(a, left, right, true);
return;
}
}
if (run[count] == right++) {
run[++count] = right;
} else if (count == 1) {
return;
}
byte odd = 0;
for (int n = 1; (n <<= 1) < count; odd ^= 1);
int[] b;
int ao, bo;
int blen = right - left;
if (work == null || workLen < blen || workBase + blen > work.length) {
work = new int[blen];
workBase = 0;
}
if (odd == 0) {
System.arraycopy(a, left, work, workBase, blen);
b = a;
bo = 0;
a = work;
ao = workBase - left;
} else {
b = work;
ao = 0;
bo = workBase - left;
}
for (int last; count > 1; count = last) {
for (int k = (last = 0) + 2; k <= count; k += 2) {
int hi = run[k], mi = run[k - 1];
for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) {
if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) {
b[i + bo] = a[p++ + ao];
} else {
b[i + bo] = a[q++ + ao];
}
}
run[++last] = hi;
}
if ((count & 1) != 0) {
for (int i = right, lo = run[count - 1]; --i >= lo;
b[i + bo] = a[i + ao]
);
run[++last] = right;
}
int[] t = a; a = b; b = t;
int o = ao; ao = bo; bo = o;
}
}
通過看代碼可以看出,java中的雙軸快排在片段資料長度及一定條件的情況下,還使用了其它諸如歸并、插入等排序演算法,
由于DivalQuickSort演算法實作內容比較復雜,文中重點講解了TimSort演算法,待筆者研究透徹后進行補充,
5. 相同環境排序時間對比
想要真正模擬一模一樣運行環境,是困難的,這里只是模擬相同的資料集,在相同機器上,其實就是平時辦公的機器,統計不同排序演算法排序程序中耗費的時間,這里的結果僅供參考,
模擬資料:隨機得到1億個范圍在0到100000000內的整型元素構成陣列,分別基于快速排序、普通歸并排序、TimSort的排序演算法得到耗時結果如下,單位ms,
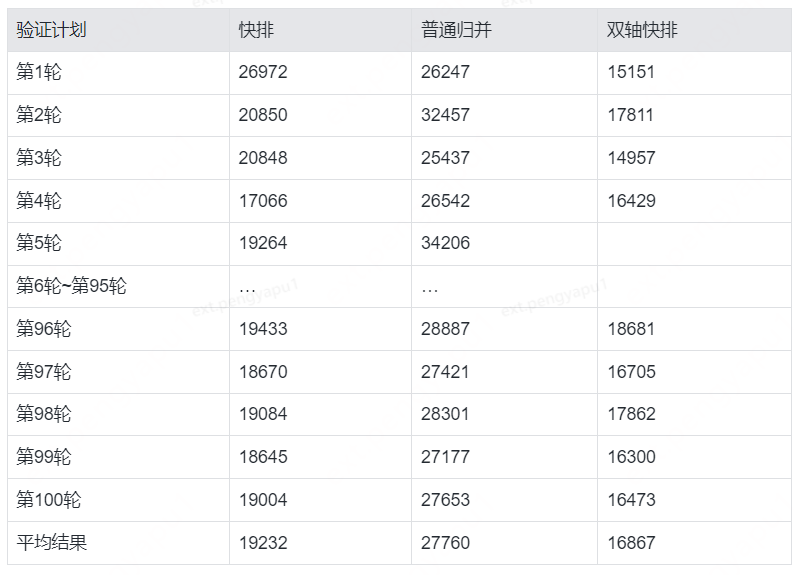
通過測驗驗證結果來看,在當前資料集規模下,雙軸快排DivalQuickSort表現優異,注:Java中TimSort主要運用參考型別的集合排序中,本次資料驗證并未加入比較,
5. 總結與探討
由于Java提供了很方便的排序API,所以在平時的需求使用程序中一般都是短短幾行代碼呼叫使用完整排序作業,這也是Java作為一門流行語言最基本的職責所在,當然也會導致我們開發者容易忽視其原理,不能夠學習到里面的精髓,
文中一起了解學習了TimSort演算法和DivalQuickSort的排序思想與java實作,作為基本排序實作被廣泛的應用,肯定有其值得學習與借鑒的地方,可以得知工業用排序演算法,通常都不是一種演算法,而是根據特定條件下的多種演算法混合而成,實際上平時很多使用的經典資料結構都不是一種型別或者一種方式,比如HashMap中隨著資料量大小有鏈表與紅黑樹的轉化,再比如Redis中的各種資料結構不都是一種實作,這些經典優秀的實作都用到了諸如此類的思想,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/544401.html
標籤:Java
下一篇:分布式事務