最近OpenAI的ChatGPT真的是到處都在刷屏,我想你已經看過很多關于ChatGPT的文章或者視頻了,我就不過多介紹了,
不過你碰巧還不知道的話,可以先百度一下,然后再回來繼續,

與ChatGPT對話很有趣,甚至很有啟發性,有人用它聊天,有人用它寫代碼,太多省時省力的作業,都可以由它完成,我們的內容創作部門已經將ChatGPT用于文案生成,那么對研發,ChatGPT是否有用呢?我做了一個測驗,讓ChatGPT來完成演算法研究中頻繁要做的資料清洗和處理問題,結果讓人非常滿意,以后還招啥工程師,直接找ChatGPT吧!

簡單資料處理
我們首先從簡單的任務入手,讓ChatGPT完成資料加載和簡單的清洗作業,
任務目標
- 加載資料集;
- 確保資料集中所有值均為數值型別,如果不是則嘗試將其轉換為數值型別;
- 檢查缺失值;
- 資料集分成訓練集和測驗集,
上面這4個任務是演算法執行前必須要做的常規作業,我們看一下ChatGPT的表現
輸出結果
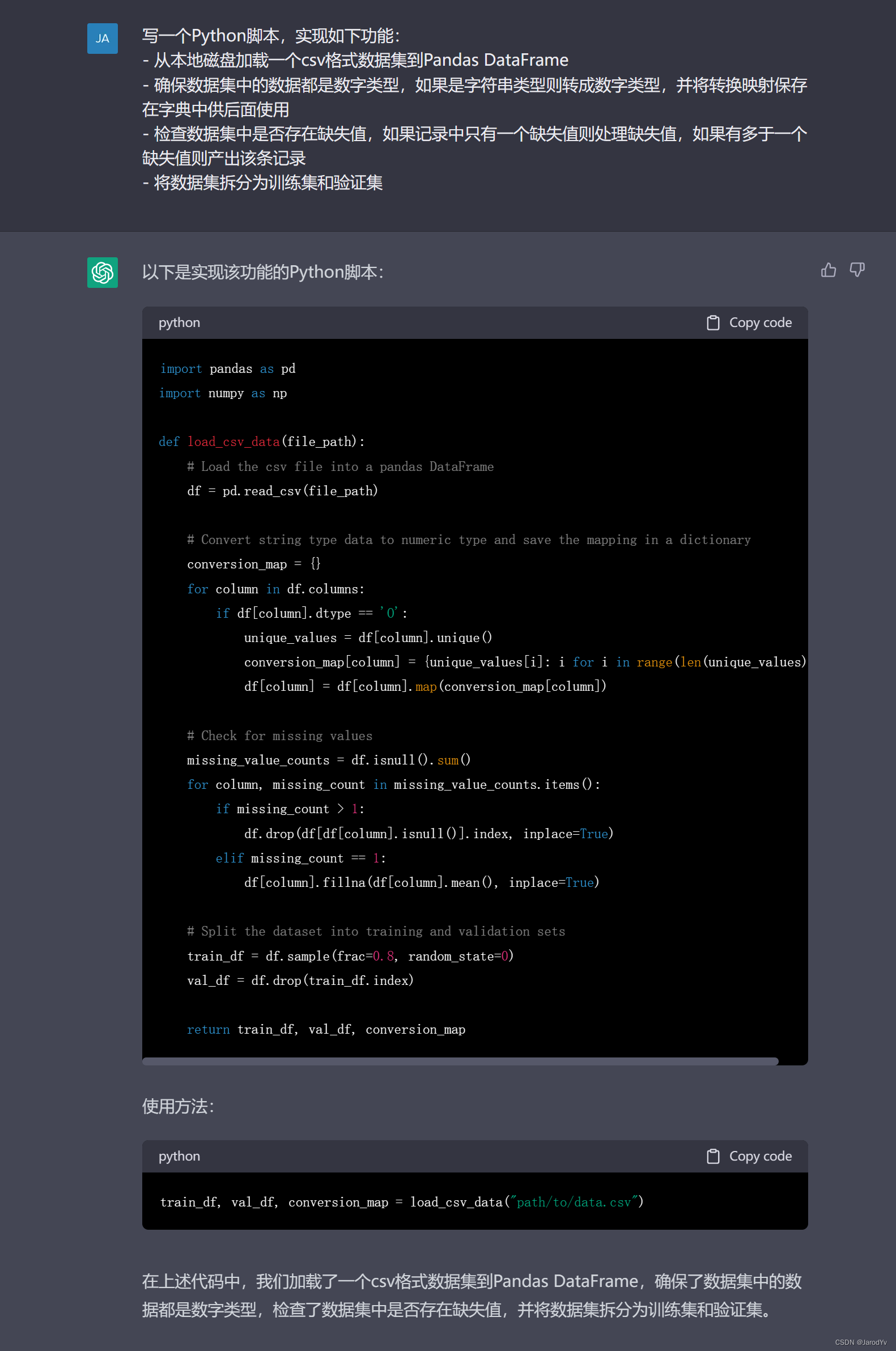
import pandas as pd import numpy as np def load_csv_data(file_path): # Load the csv file into a pandas DataFrame df = pd.read_csv(file_path) # Convert string type data to numeric type and save the mapping in a dictionary conversion_map = {} for column in df.columns: if df[column].dtype == 'O': unique_values = df[column].unique() conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))} df[column] = df[column].map(conversion_map[column]) # Check for missing values missing_value_counts = df.isnull().sum() for column, missing_count in missing_value_counts.items(): if missing_count > 1: df.drop(df[df[column].isnull()].index, inplace=True) elif missing_count == 1: df[column].fillna(df[column].mean(), inplace=True) # Split the dataset into training and validation sets train_df = df.sample(frac=0.8, random_state=0) val_df = df.drop(train_df.index) return train_df, val_df, conversion_map # 新的一年,必須卷死同學、同事,狠狠的提升一波自己的Python實力, # 這里我給大家準備了2023最新的Python學習資料、電子書、基礎視頻教程、實戰案例,直接在這個扣裙自取即可(708525271)
分析
上面代碼可以完美完成目標任務,從csv檔案中加載資料集,并以80/20的比例將資料集拆分為測驗集和訓練集,關鍵邏輯還加上了注釋,ChatGPT甚至貼心的給出了函式使用方法,
ChatGPT生成上面代碼總共用時116秒,同時我們的資料工程師撰寫同樣功能的代碼用時225秒,二者的代碼差異不大,但是我們的資料工程師沒寫注釋,
上面的任務是資料工程師幾乎天天都要寫的代碼,他們很熟練,我又找了一個大學剛畢業還在實習期的資料助理來寫,居然半個小時才完成,由于對介面不熟悉,大量時間花在了百度上[捂臉],
第一輪比試,從各個維度上,都是ChatGPT勝,
重構代碼
在上一輪的比試中,我發現我們的資料工程師有“偷雞”行為——由于平時經常需要完成上面作業,他將很多功能封裝成了獨立的函式,用的時候直接引入或拷貝,使用函式按照邏輯組織代碼,不僅能夠促進代碼復用,還有利于代碼維護,所以我們接下來試著讓ChatGPT重構一下自己的代碼,
任務目標
將上面的代碼按照功能合理地拆分成若干函式,
輸出結果
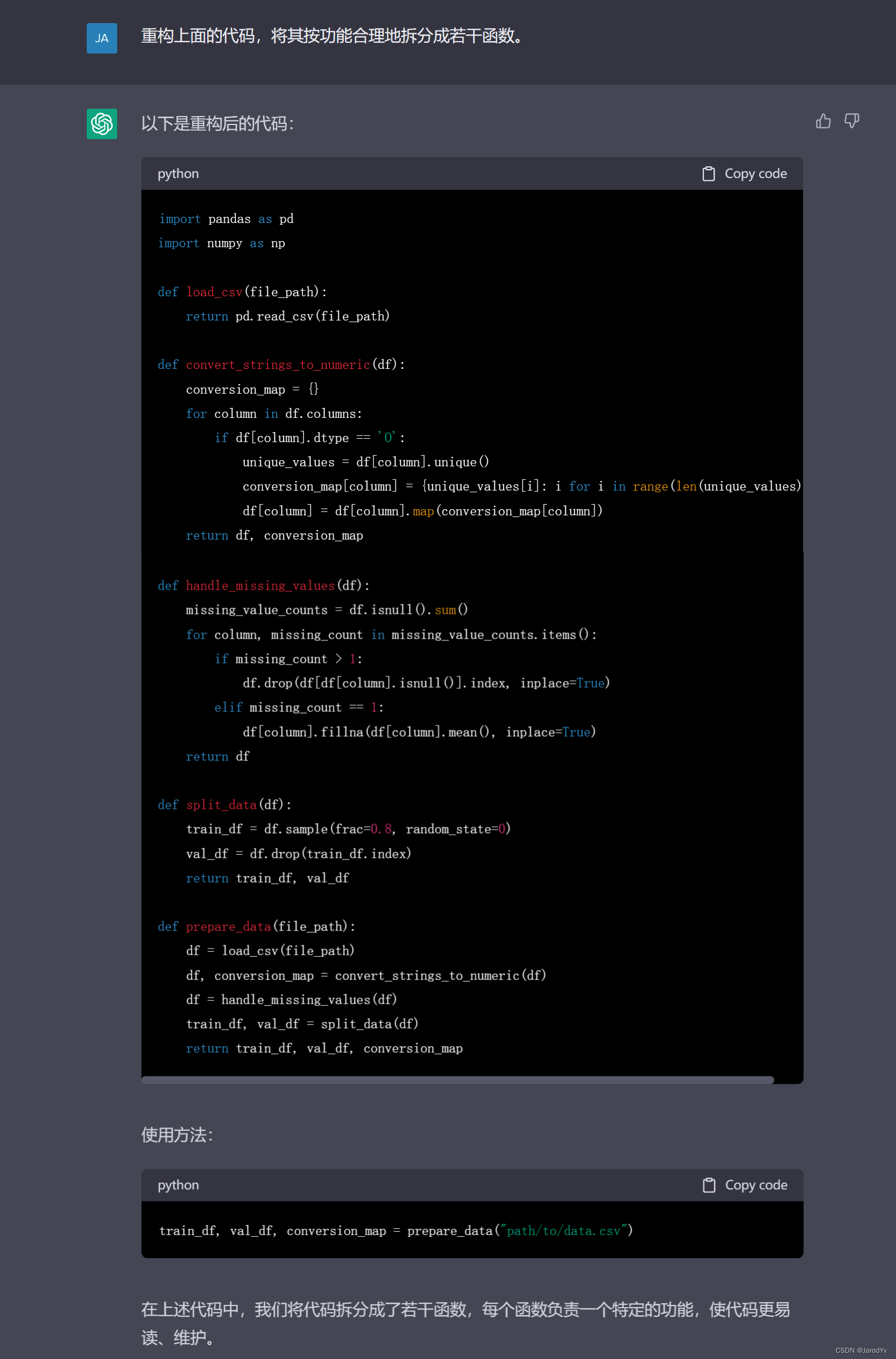
import pandas as pd import numpy as np def load_csv(file_path): return pd.read_csv(file_path) def convert_strings_to_numeric(df): conversion_map = {} for column in df.columns: if df[column].dtype == 'O': unique_values = df[column].unique() conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))} df[column] = df[column].map(conversion_map[column]) return df, conversion_map def handle_missing_values(df): missing_value_counts = df.isnull().sum() for column, missing_count in missing_value_counts.items(): if missing_count > 1: df.drop(df[df[column].isnull()].index, inplace=True) elif missing_count == 1: df[column].fillna(df[column].mean(), inplace=True) return df def split_data(df): train_df = df.sample(frac=0.8, random_state=0) val_df = df.drop(train_df.index) return train_df, val_df def prepare_data(file_path): df = load_csv(file_path) df, conversion_map = convert_strings_to_numeric(df) df = handle_missing_values(df) train_df, val_df = split_data(df) return train_df, val_df, conversion_map
分析
ChatGPT拆分出5個函式:
- load_csv(file_path) 負責從csv檔案中加載資料集,回傳DataFrame;
- convert_strings_to_numeric(df) 負責將DataFrame中的非數值型別資料轉換為數值型別,并記錄轉換映射表;
- handle_missing_values(df) 負責處理缺失值;
- split_data(df) 負責將資料集拆分為訓練集和測驗集;
- prepare_data(file_path) 將上面4給函式串起來,構成一個pipeline,
不得不說,ChatGPT有一次完美地完成了任務!并且函式名起得非常好,看函式名就能知道函式的功能,比很多中國程式員用拼音或縮寫命名函式友好多了,
擴展代碼
重構后的代碼結構已經非常清晰了,但是還是有缺陷,那就是不夠靈活,很多規則都是寫死的,為了讓代碼更靈活、可擴展性更強,我們一般會將變數以引數的形式傳入,
任務目標
重構上面的代碼,以引數的形式從命令列傳入以下內容:
- csv格式資料集的路徑
- 拆分訓練集和驗證集的大小
- 閾值,缺失值大于此閾值則洗掉記錄,小于等于此閾值則處理缺失值
輸出結果
import pandas as pd import numpy as np import argparse def load_csv(file_path): return pd.read_csv(file_path) def convert_strings_to_numeric(df): conversion_map = {} for column in df.columns: if df[column].dtype == 'O': unique_values = df[column].unique() conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))} df[column] = df[column].map(conversion_map[column]) return df, conversion_map def handle_missing_values(df, threshold): missing_value_counts = df.isnull().sum() for column, missing_count in missing_value_counts.items(): if missing_count > threshold: df.drop(df[df[column].isnull()].index, inplace=True) elif missing_count <= threshold: df[column].fillna(df[column].mean(), inplace=True) return df def split_data(df, split_ratio): train_df = df.sample(frac=split_ratio, random_state=0) val_df = df.drop(train_df.index) return train_df, val_df if __name__ == "__main__": parser = argparse.ArgumentParser(description='Prepare data for machine learning.') parser.add_argument('file_path', help='Path to the csv file.') parser.add_argument('--split-ratio', type=float, default=0.8, help='Ratio of the training set size.') parser.add_argument('--threshold', type=int, default=1, help='Threshold for handling missing values.') args = parser.parse_args() df = load_csv(args.file_path) df, conversion_map = convert_strings_to_numeric(df) df = handle_missing_values(df, args.threshold) train_df, val_df = split_data(df, args.split_ratio)
分析
ChatGPT很好地理解了我們的意圖,引入了argparse模塊來管理和決議命令列引數,關鍵是引數名起的也非常合理,引數說明也非常準確(盡管是英文的),引數都正確地傳入了所屬的函式,又一次完美的完成了任務,
總結
ChatGPT根據我們提供的規范,在創建、重構、擴展一個簡單的資料預處理Python腳本方面做得非常出色,每一步的結果都符合要求,雖然這不是一個復雜任務,確實日常作業中最常見的基本作業,ChatGPT的表現確實驚艷了眾人,預示著它朝著成為真正有用的編程助手邁出重要的一步,
最終我們從如下幾個方面將ChatGPT和我們的資料工程師做了對比:
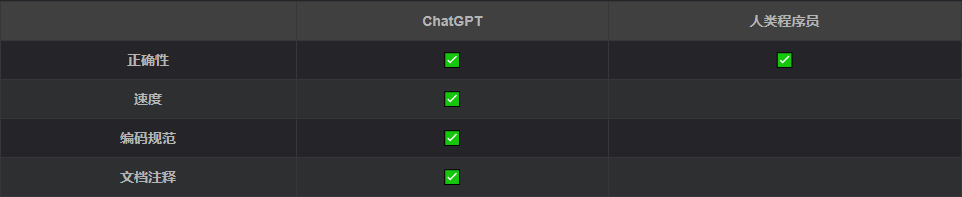
可見ChatGPT在編碼速度和編碼習慣上都完勝人類工程師,這讓我不得不開始擔心程式員未來的飯碗,是的,你沒有看錯!程式員這個曾經被認為是最不可能被AI取代的職業,如今將面臨來自ChatGPT的巨大挑戰,根據測驗,ChatGPT已經通過Google L3級工程師測驗,這意味著大部分基礎coding的作業可以由ChatGPT完成,盡管ChatGPT在涉及業務的任務上表現不佳,但未來更可能的作業方式是架構師或設計師于ChatGPT協同完成作業,不再需要編碼的碼農,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/544571.html
標籤:其他
上一篇:關于MRP運行的BADIs