本文是龔國瑋所寫,熊哥有所新增修改刪減,原文見文末,
我說我為什么抽不到SSR,原來是加權隨機演算法在作祟
閱讀本文需要做好心理準備,建議帶著深究到底的決心和毅力進行學習!
靈魂拷問
為什么有 50% 的幾率獲得金幣?
為什么有 40% 的幾率獲得鉆石?
為什么只有 9% 的幾率獲得裝備?
為什么才有 1% 的幾率獲得極品裝備?
是人性的扭曲,還是道德的淪喪,請和我一起走進今日說法 !
介紹
元素被選中的機會并不相等,而是由相對“權重”(或概率)被選中的,是偏心的,這就是加權隨機,
舉個栗子,假如現在有一個權重陣列 w = {1, 2, 4, 8},它們代表如下規則,
-
$ \frac{1}{(1+2+4+8)} = \frac{1}{15} \approx 6.6$ % 幾率選中第1個
-
$ \frac{2}{(1+2+4+8)} = \frac{2}{15} \approx 13.3$ % 幾率選中第2個
-
$ \frac{3}{(1+2+4+8)} = \frac{4}{15} \approx 26.6$ % 幾率選中第3個
-
$ \frac{1}{(1+2+4+8)} = \frac{8}{15} \approx 53.3$ % 幾率選中第4個
一個小小的概率問題,居然引出了大大的思考,
方案一、笨笨的辦法
所以要設計一個加權演算法的程式,你會怎么寫呢?
第一個方法把權重所在的位置展開,然后從該串列中隨機選擇,
假設現在有權重串列 {1, 2, 4, 8},
那我們得到的候選串列將是
{0, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3}
然后通過 rand.Intn() ,獲取一個亂數,就完成了,代碼如下,
func weightedRandomS1(weights []int) int {
if len(weights) == 0 {
return 0
}
var indexList []int
for i, weight := range weights {
cnt := 0
for weight > cnt {
indexList = append(indexList, i)
cnt++
}
}
rand.Seed(time.Now().UnixNano())
return indexList[rand.Intn(len(indexList))]
}
當權重特別大的時候,這種方案費時費力,又占空間,先別急往下看,你能想到更好的辦法嗎?
方案二、略顯聰明
由于總權重為 15(1+2+4+8),我們可以生成一個 [0,15) 的隨機整數,然后根據這個數字回傳索引,代碼如下,
func weightedRandomS2() int {
rand.Seed(time.Now().UnixNano())
r := rand.Intn(15)
if r <= 1 {
return 0
} else if 1 < r && r <= 3 {
return 1
} else if 3 < r && r <= 7 {
return 2
} else {
return 3
}
}
妙不妙!!但你以為這就是效率最高的辦法嗎?
寫那么多if else不痛苦嗎我的寶貝,
方案三、神之一手
何必將亂數和所有的范圍進行比較呢?直接遍歷亂數減去權重,如果結果小于等于零,不就是我們要的結果下標嗎?
func weightedRandomS3(weights []int) int {
rand.Seed(time.Now().UnixNano())
r := rand.Intn(len(weights))
for i, v := range weights {
r = r - v
if r <= 0 {
return i
}
}
return len(weights) - 1
}
這種方法叫放棄臨時名單,想不明白就評論問!
方案四、小小優化
對于方案三,怎么有效的減少遍歷次數呢?
當r小于等于 0 的速度越快,演算法越高效,那我們就讓 r 到達 0 更快,先排序這樣就能先減去權重大的,減少遍歷次數,
func weightedRandomS4(weights []int) int {
sort.Sort(sort.Reverse(sort.IntSlice(weights)))
....
有人就不服了,排序不是更浪費時間?
是的!雖然看起來減少遍歷次數!但排序本身就要遍歷就是更浪費時間,,,
但是一次排序,反復使用,還是能提高效率的!
方案五、不可思議!
有沒有辦法不用排序,而讓原陣列有序呢?
有人就說了,你這不是扯么?
如果每次遍歷都加上上一個權重,那整個數字就是遞增的!
再用二分就能加快速度了,時間復雜度從 $ O(n) $ 直接變為 $ O(log(n)) $,
func weightedRandomS5(weights []int) int {
rand.Seed(time.Now().UnixNano())
sum := 0
var sumWeight []int
for _, v := range weights {
sum += v
sumWeight = append(sumWeight, sum)
}
r := rand.Intn(sum)
idx := sort.SearchInts(sumWeight, r)
return weights[idx]
}
讀到這里,對原始碼沒有信心學習的朋友,可以直接撤了, 真正的高階優化要來了,
方案六、不死不休
到目前的位置,我們的解決方案已經足夠好了,但是仍然有改進的余地,
方案五中,我們使用了 Go 標準庫的二分查找演算法 sort.SearchInts() ,是封裝了通用的 sort.Search() 函式,如下,
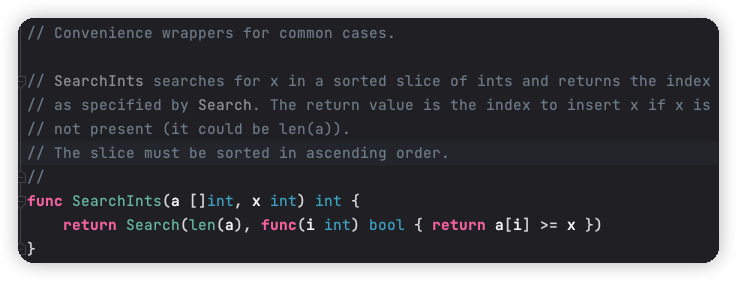
sort.Search() 的函式引數需要一個閉包函式,并且這個閉包函式是在 for 回圈中使用的,如下,
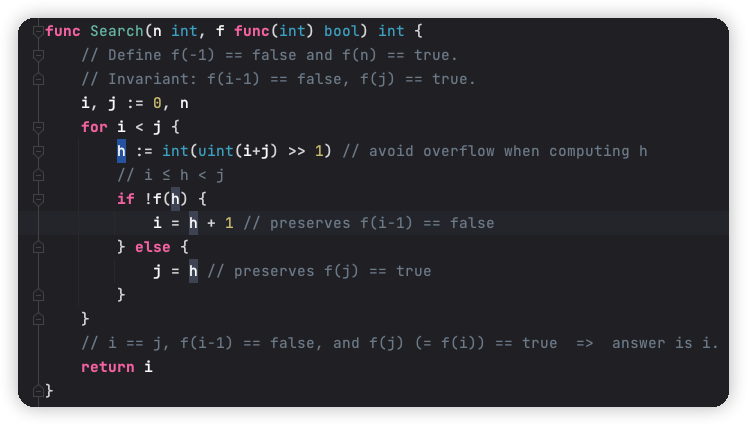
閉包函式反復呼叫,在編譯期會產生額外的開銷,因為會產生更多的跳轉,跳轉會引起壓堆疊(函式引數都是會壓堆疊的),
我們手動提出取函式,就可以減少編譯器的行內(文末會解釋),
func weightedRandomS5(weights []int) int {
...
idx := sort.SearchInts(sumWeight, r)
return weights[idx]
}
func searchInts(a []int, x int) int {
i, j := 0, len(a)
for i < j {
h := int(uint(i+j) >> 1)
if a[h] < x {
i = h + 1
} else {
j = h
}
}
return i
}
通過基準測驗可以看到吞吐量提升了 33% 以上,對于大型資料集,優勢越明顯,
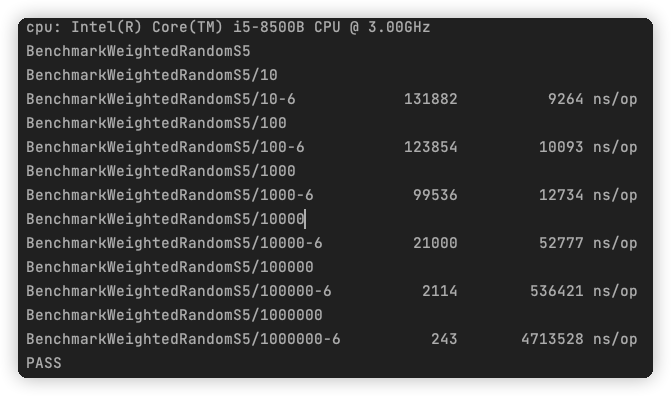
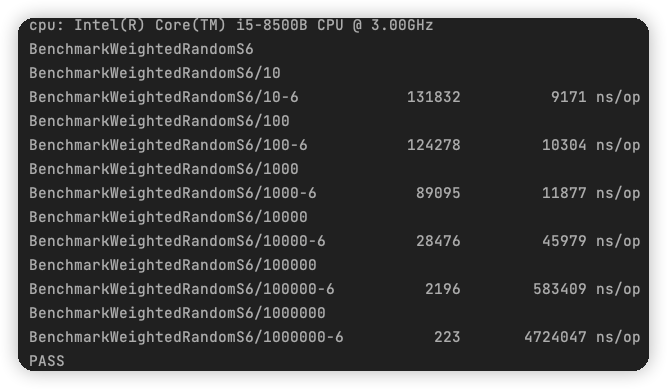
方案七,“偷雞”取巧--輪盤賭
目前為止我們所有的方案都有一個共同點 —— 生成一個介于 0 和“權重之和”之間的亂數,并找出它屬于哪個“切片”,
還有一種不同的方法,
func weightedRandomS7(weights []float64) int {
var sum float64
var winner int
rand.Seed(time.Now().UnixNano())
for i, v := range weights {
sum += v
f := rand.Float64()
if f*sum < v {
winner = i
}
}
return winner
}
- 從命中的角度去考慮,
- 權重越大,命中率自然越大了,
- 既然是隨機,多次隨機和單次隨機而言都是隨機的,
這個演算法的一個有趣的特性是你不需要提前知道權重的數量就可以使用它,所以說,它或許可以用于某種流,
盡管這種方案很酷,但它比其他方案慢得多,相對于方案一,它也快了 25% ,
小結
- 下標直接展開到串列里,隨機長度取值,
if else取值,- 遍歷亂數減去權重,結果小于等于零時,
- 先排序,再用方法三,
- 免排序,直接加和,再二分,
- 優化原始碼中的二分法,
- 輪盤賭演算法,每次都去賭,
行內:編譯器的一個名詞,我們的代碼最終都是經過編譯系統轉換成可執行二進制檔案,匯編階段讀取的是詞法、語法單元輸出的結果,而行內是編譯器對詞法、語法分析器對源代碼做出的分析,然后產生二進制代碼這個程序叫行內,
源代碼
https://github.com/guowei-gong/weighted-random
原文:加權隨機設計與實作
一起進步
你好,我是小熊,是一個愛技術但是更愛錢的程式員,上進且佛系自律的人,喜歡發小秘密/臭屁又愛炫耀,
奮斗的大學,激情的現在,賺了錢買了房,寫了書出了名,當過面試官,帶過徒弟搬過轉,
大廠外來務工人員,是我,我是小熊,是不一樣的煙火歡迎圍觀,
我的博客 機智的程式員小熊 歡迎收藏
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/544673.html
標籤:Go
下一篇:演算法21:折紙問題