哈嘍兄弟們,今天給大家帶來最新版如何實作 百度文庫VIP內容獲取
??需求如下:
對于這類的檔案, 我們想要點擊下載, 都是需要 “氪金” 才行, 但是作為咱們這類人來說, 能白嫖就白嫖!
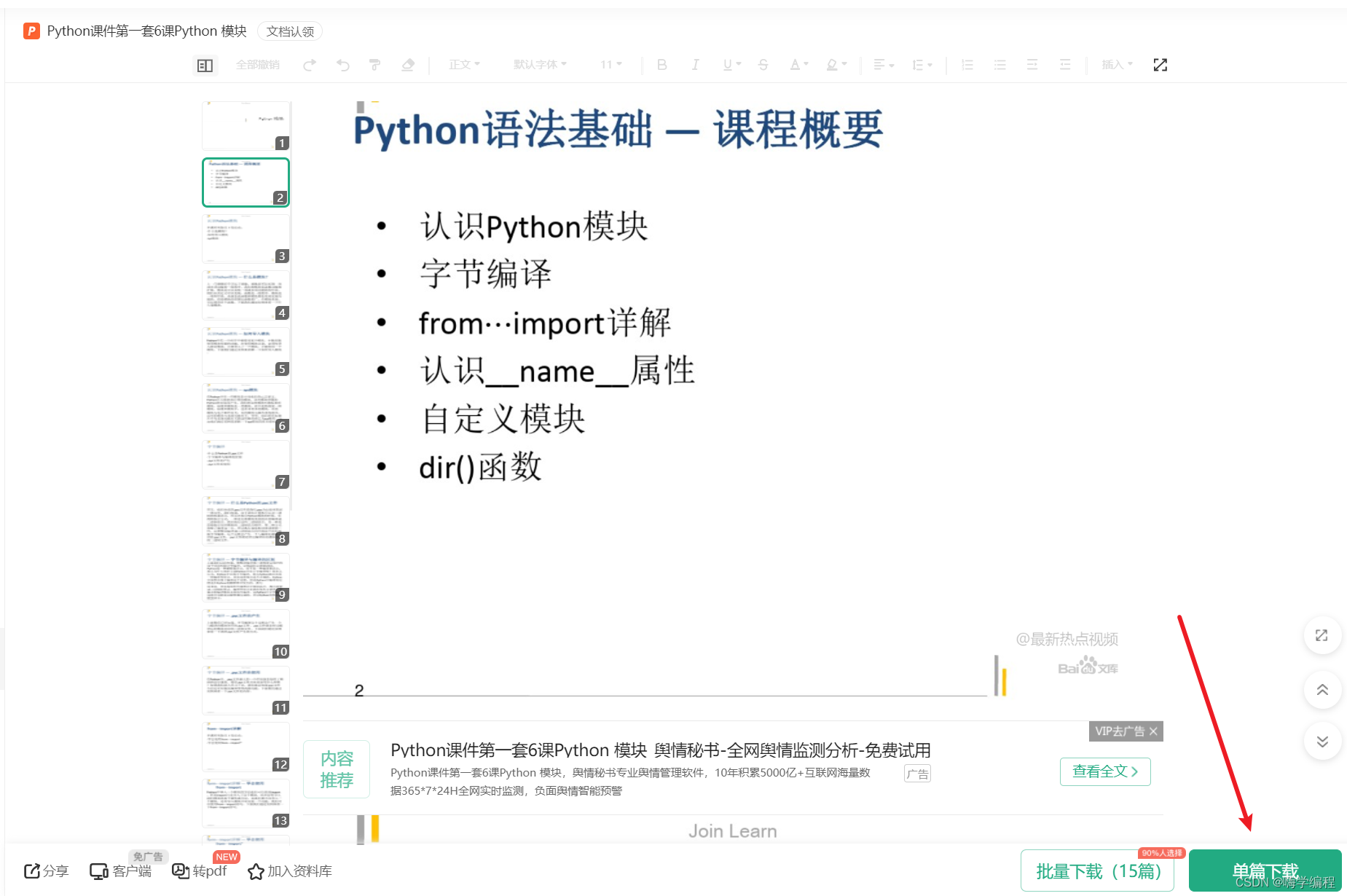
??找資料源:
通過開發者工具抓包, 可以看到資料都是圖片的形式存在, 那我們可以獲取它所有的資料內容, 然后保存下載下來, 以PPT的形式保存
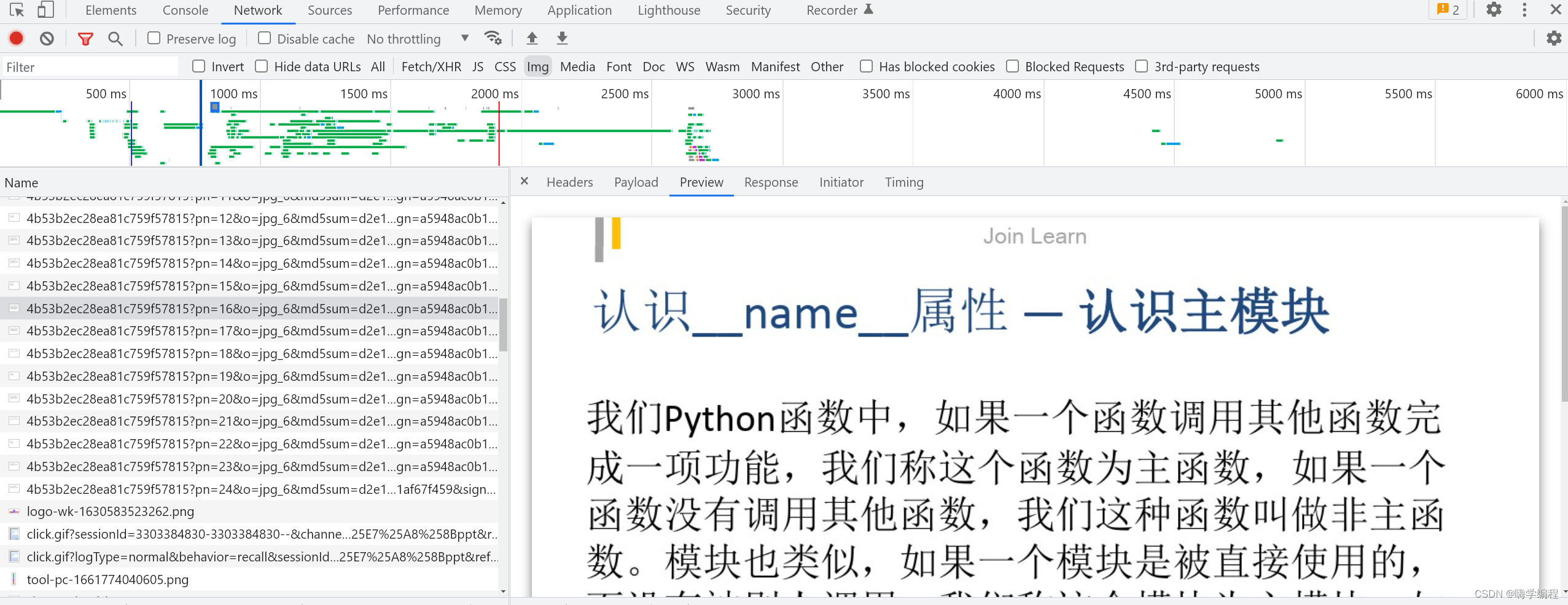
??代碼如下:
# 匯入資料請求模塊 import requests # 匯入ppt模塊 from pptx import Presentation # 匯入ppt模塊 設定邊距 from pptx.util import Cm # 匯入檔案操作模塊 import os # 給大家準備了數百本Python電子書、各種原始碼、實戰視頻教程、基礎視頻講解 # 直接在這個摳裙 708525271 自取 # 請求鏈接 url = 'https://wenku.baidu.com/ndocview/readerinfo' # 請求引數 data =https://www.cnblogs.com/hahaa/p/ { 'docId': '5330607f541810a6f524ccbff121dd36a32dc482', 'clientType': '1', 'powerId': '2', 'pn': '1', 'rn': '100', 'bizName': 'mainPc', 'edtDocSrc': '0', 'bdQuery': '百度文庫', 'wkQuery': 'python編程ppt', } # 偽裝 headers = { # 用戶代理 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36', } # 發送請求 response = requests.get(url=url, params=data, headers=headers) # 回圈次數 page = 1 # for 回圈遍歷 for index in response.json()['data']['htmlUrls']: # 獲取圖片資料 img_content = requests.get(url=index, headers=headers).content # 保存資料 with open('img\\' + str(page) + '.jpg', mode='wb') as f: # 寫入資料 f.write(img_content) print(index) # 每次回圈+1 page += 1 # 實體化物件 prs = Presentation() # 使用第7個模塊 blank_slide_layout = prs.slide_layouts[6] # 讀取檔案 files = os.listdir('img\\') # 遍歷檔案名 for file in files: # 檔案路徑 filename = f'img\\{file}' # 添加圖片 # slide.shapes.add_picture(圖片路徑, 距離左邊,距離頂端, 寬度,高度) slide = prs.slides.add_slide(blank_slide_layout) slide.shapes.add_picture(filename, Cm(0), Cm(0), Cm(25.40), Cm(19.06)) # 保存ppt prs.save('python編程.pptx')
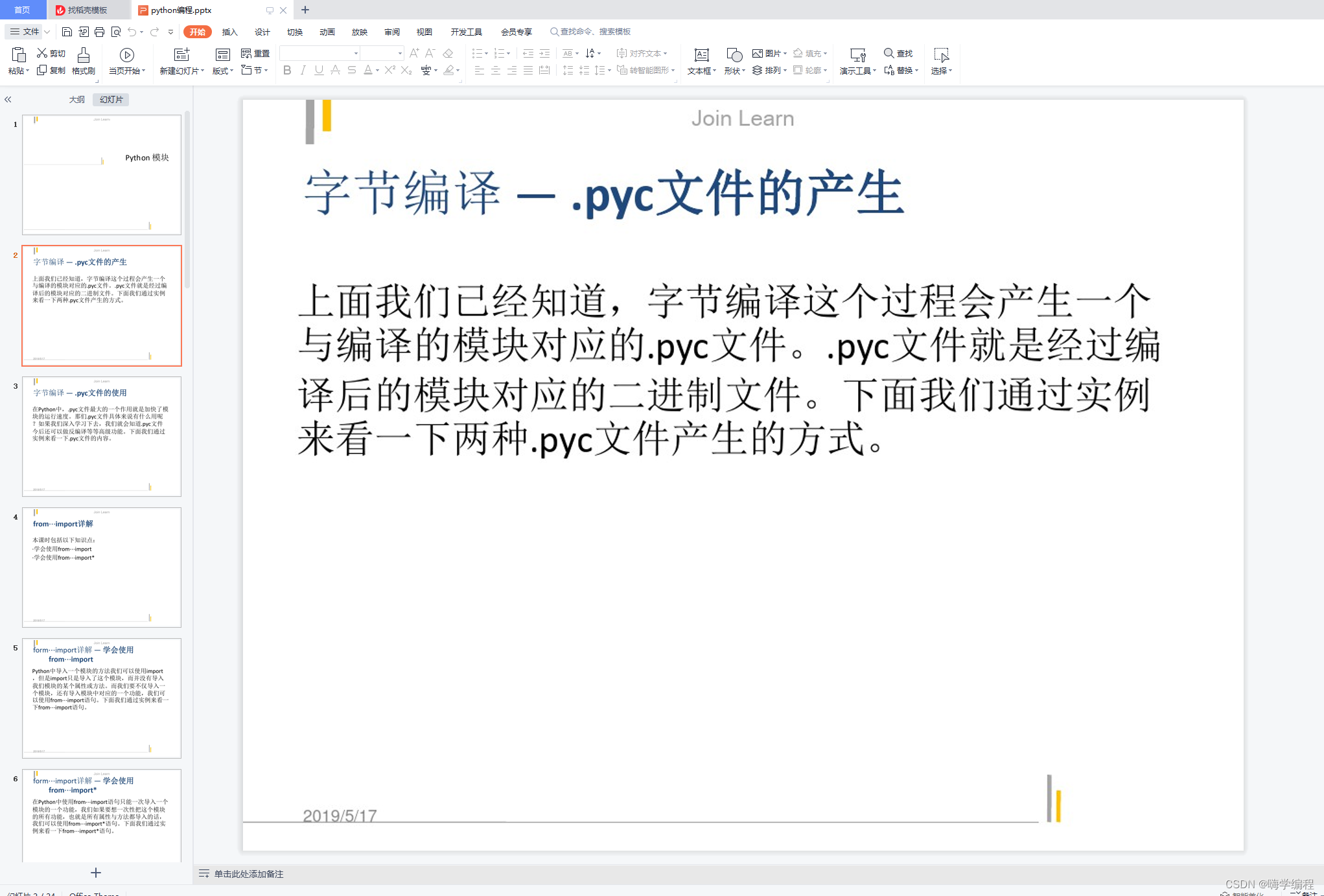
??采集效果:
??總結:
今天的分享就到這結束了,下期大家想看什么,可以在評論區留下你想看的內容名字,隨機抽取幸運觀眾 ,有什么不明白的地方也可以留言,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/544692.html
標籤:Python