也許每一個男子全都有過這樣的兩個女人,至少兩個,娶了紅玫瑰,久而久之,紅的變了墻上的一抹蚊子血,白的還是床前明月光;娶了白玫瑰,白的便是衣服上沾的一粒飯黏子,紅的卻是心口上一顆朱砂痣,--張愛玲《紅玫瑰與白玫瑰》
Selenium一直都是Python開源自動化瀏覽器工具的王者,但這兩年微軟開源的PlayWright異軍突起,后來者居上,隱隱然有撼動Selenium江湖地位之勢,本次我們來對比PlayWright與Selenium之間的差異,看看曾經的玫瑰花Selenium是否會變成蚊子血,
PlayWright的安裝和使用
PlayWright是由業界大佬微軟(Microsoft)開源的端到端 Web 測驗和自動化庫,可謂是大廠背書,功能滿格,雖然作為無頭瀏覽器,該框架的主要作用是測驗 Web 應用,但事實上,無頭瀏覽器更多的是用于 Web 抓取目的,也就是爬蟲,
首先終端運行安裝命令:
pip3 install playwright
程式回傳:
Successfully built greenlet
Installing collected packages: pyee, greenlet, playwright
Attempting uninstall: greenlet
Found existing installation: greenlet 2.0.2
Uninstalling greenlet-2.0.2:
Successfully uninstalled greenlet-2.0.2
Successfully installed greenlet-2.0.1 playwright-1.30.0 pyee-9.0.4
目前最新穩定版為1.30.0
隨后可以選擇直接安裝瀏覽器驅動:
playwright install
程式回傳:
Downloading Chromium 110.0.5481.38 (playwright build v1045) from https://playwright.azureedge.net/builds/chromium/1045/chromium-mac-arm64.zip
123.8 Mb [====================] 100% 0.0s
Chromium 110.0.5481.38 (playwright build v1045) downloaded to /Users/liuyue/Library/Caches/ms-playwright/chromium-1045
Downloading FFMPEG playwright build v1008 from https://playwright.azureedge.net/builds/ffmpeg/1008/ffmpeg-mac-arm64.zip
1 Mb [====================] 100% 0.0s
FFMPEG playwright build v1008 downloaded to /Users/liuyue/Library/Caches/ms-playwright/ffmpeg-1008
Downloading Firefox 108.0.2 (playwright build v1372) from https://playwright.azureedge.net/builds/firefox/1372/firefox-mac-11-arm64.zip
69.8 Mb [====================] 100% 0.0s
Firefox 108.0.2 (playwright build v1372) downloaded to /Users/liuyue/Library/Caches/ms-playwright/firefox-1372
Downloading Webkit 16.4 (playwright build v1767) from https://playwright.azureedge.net/builds/webkit/1767/webkit-mac-12-arm64.zip
56.9 Mb [====================] 100% 0.0s
Webkit 16.4 (playwright build v1767) downloaded to /Users/liuyue/Library/Caches/ms-playwright/webkit-1767
默認會下載Chromium內核、Firefox以及Webkit驅動,
其中使用最廣泛的就是基于Chromium內核的瀏覽器,最負盛名的就是Google的Chrome和微軟自家的Edge,
確保當前電腦安裝了Edge瀏覽器,讓我們小試牛刀一把:
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
browser = p.chromium.launch(channel="msedge", headless=True)
page = browser.new_page()
page.goto('http:/v3u.cn')
page.screenshot(path=f'./example-v3u.png')
time.sleep(5)
browser.close()
這里匯入sync_playwright模塊,顧名思義,同步執行,通過背景關系管理器開啟瀏覽器行程,
隨后通過channel指定edge瀏覽器,截圖后關閉瀏覽器行程:

我們也可以指定headless引數為True,讓瀏覽器再后臺運行:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(channel="msedge", headless=True)
page = browser.new_page()
page.goto('http:/v3u.cn')
page.screenshot(path=f'./example-v3u.png')
browser.close()
除了同步模式,PlayWright也支持異步非阻塞模式:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(channel="msedge", headless=False)
page = await browser.new_page()
await page.goto("http://v3u.cn")
print(await page.title())
await browser.close()
asyncio.run(main())
可以通過原生協程庫asyncio進行呼叫,PlayWright內置函式只需要添加await關鍵字即可,非常方便,與之相比,Selenium原生庫并不支持異步模式,必須安裝三方擴展才可以,
最炫酷的是,PlayWright可以對用戶的瀏覽器操作進行錄制,并且可以轉換為相應的代碼,在終端執行以下命令:
python -m playwright codegen --target python -o 'edge.py' -b chromium --channel=msedge
這里通過codegen命令進行錄制,指定瀏覽器為edge,將所有操作寫入edge.py的檔案中:
與此同時,PlayWright也支持移動端的瀏覽器模擬,比如蘋果手機:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
iphone_13 = p.devices['iPhone 13 Pro']
browser = p.webkit.launch(headless=False)
page = browser.new_page()
page.goto('https://v3u.cn')
page.screenshot(path='./v3u-iphone.png')
browser.close()
這里模擬Iphone13pro的瀏覽器訪問情況,
當然了,除了UI功能測驗,我們當然還需要PlayWright幫我們干點臟活累活,那就是爬蟲:
from playwright.sync_api import sync_playwright
def extract_data(entry):
name = entry.locator("h3").inner_text().strip("\n").strip()
capital = entry.locator("span.country-capital").inner_text()
population = entry.locator("span.country-population").inner_text()
area = entry.locator("span.country-area").inner_text()
return {"name": name, "capital": capital, "population": population, "area (km sq)": area}
with sync_playwright() as p:
# launch the browser instance and define a new context
browser = p.chromium.launch()
context = browser.new_context()
# open a new tab and go to the website
page = context.new_page()
page.goto("https://www.scrapethissite.com/pages/simple/")
page.wait_for_load_state("load")
# get the countries
countries = page.locator("div.country")
n_countries = countries.count()
# loop through the elements and scrape the data
data = https://www.cnblogs.com/v3ucn/p/[]
for i in range(n_countries):
entry = countries.nth(i)
sample = extract_data(entry)
data.append(sample)
browser.close()
這里data變數就是抓取的資料內容:
[
{'name': 'Andorra', 'capital': 'Andorra la Vella', 'population': '84000', 'area (km sq)': '468.0'},
{'name': 'United Arab Emirates', 'capital': 'Abu Dhabi', 'population': '4975593', 'area (km sq)': '82880.0'},
{'name': 'Afghanistan', 'capital': 'Kabul', 'population': '29121286', 'area (km sq)': '647500.0'},
{'name': 'Antigua and Barbuda', 'capital': "St. John's", 'population': '86754', 'area (km sq)': '443.0'},
{'name': 'Anguilla', 'capital': 'The Valley', 'population': '13254', 'area (km sq)': '102.0'},
...
]
基本上,該有的功能基本都有,更多功能請參見官方檔案:https://playwright.dev/python/docs/library
Selenium
Selenium曾經是用于網路抓取和網路自動化的最流行的開源無頭瀏覽器工具之一,在使用 Selenium 進行抓取時,我們可以自動化瀏覽器、與 UI 元素互動并在 Web 應用程式上模仿用戶操作,Selenium 的一些核心組件包括 WebDriver、Selenium IDE 和 Selenium Grid,
關于Selenium的一些基本操作請移玉步至:python3.7爬蟲:使用Selenium帶Cookie登錄并且模擬進行表單上傳檔案,這里不作過多贅述,
如同前文提到的,與Playwright相比,Selenium需要第三方庫來實作異步并發執行,同時,如果需要錄制動作視頻,也需要使用外部的解決方案,
就像Playwright那樣,讓我們使用 Selenium 構建一個簡單的爬蟲腳本,
首先匯入必要的模塊并配置 Selenium 實體,并且通過設定確保無頭模式處于活動狀態option.headless = True:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# web driver manager: https://github.com/SergeyPirogov/webdriver_manager
# will help us automatically download the web driver binaries
# then we can use `Service` to manage the web driver's state.
from webdriver_manager.chrome import ChromeDriverManager
def extract_data(row):
name = row.find_element(By.TAG_NAME, "h3").text.strip("\n").strip()
capital = row.find_element(By.CSS_SELECTOR, "span.country-capital").text
population = row.find_element(By.CSS_SELECTOR, "span.country-population").text
area = row.find_element(By.CSS_SELECTOR, "span.country-area").text
return {"name": name, "capital": capital, "population": population, "area (km sq)": area}
options = webdriver.ChromeOptions()
options.headless = True
# this returns the path web driver downloaded
chrome_path = ChromeDriverManager().install()
# define the chrome service and pass it to the driver instance
chrome_service = Service(chrome_path)
driver = webdriver.Chrome(service=chrome_service, options=options)
url = "https://www.scrapethissite.com/pages/simple"
driver.get(url)
# get the data divs
countries = driver.find_elements(By.CSS_SELECTOR, "div.country")
# extract the data
data = https://www.cnblogs.com/v3ucn/p/list(map(extract_data, countries))
driver.quit()
資料回傳:
[
{'name': 'Andorra', 'capital': 'Andorra la Vella', 'population': '84000', 'area (km sq)': '468.0'},
{'name': 'United Arab Emirates', 'capital': 'Abu Dhabi', 'population': '4975593', 'area (km sq)': '82880.0'},
{'name': 'Afghanistan', 'capital': 'Kabul', 'population': '29121286', 'area (km sq)': '647500.0'},
{'name': 'Antigua and Barbuda', 'capital': "St. John's", 'population': '86754', 'area (km sq)': '443.0'},
{'name': 'Anguilla', 'capital': 'The Valley', 'population': '13254', 'area (km sq)': '102.0'},
...
]
性能測驗
在資料抓取量一樣的前提下,我們當然需要知道到底誰的性能更好,是PlayWright,還是Selenium?
這里我們使用Python3.10內置的time模塊來統計爬蟲腳本的執行速度,
PlayWright:
import time
from playwright.sync_api import sync_playwright
def extract_data(entry):
name = entry.locator("h3").inner_text().strip("\n").strip()
capital = entry.locator("span.country-capital").inner_text()
population = entry.locator("span.country-population").inner_text()
area = entry.locator("span.country-area").inner_text()
return {"name": name, "capital": capital, "population": population, "area (km sq)": area}
start = time.time()
with sync_playwright() as p:
# launch the browser instance and define a new context
browser = p.chromium.launch()
context = browser.new_context()
# open a new tab and go to the website
page = context.new_page()
page.goto("https://www.scrapethissite.com/pages/")
# click to the first page and wait while page loads
page.locator("a[href='https://www.cnblogs.com/pages/simple/']").click()
page.wait_for_load_state("load")
# get the countries
countries = page.locator("div.country")
n_countries = countries.count()
data = https://www.cnblogs.com/v3ucn/p/[]
for i in range(n_countries):
entry = countries.nth(i)
sample = extract_data(entry)
data.append(sample)
browser.close()
end = time.time()
print(f"The whole script took: {end-start:.4f}")
Selenium:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# web driver manager: https://github.com/SergeyPirogov/webdriver_manager
# will help us automatically download the web driver binaries
# then we can use `Service` to manage the web driver's state.
from webdriver_manager.chrome import ChromeDriverManager
def extract_data(row):
name = row.find_element(By.TAG_NAME, "h3").text.strip("\n").strip()
capital = row.find_element(By.CSS_SELECTOR, "span.country-capital").text
population = row.find_element(By.CSS_SELECTOR, "span.country-population").text
area = row.find_element(By.CSS_SELECTOR, "span.country-area").text
return {"name": name, "capital": capital, "population": population, "area (km sq)": area}
# start the timer
start = time.time()
options = webdriver.ChromeOptions()
options.headless = True
# this returns the path web driver downloaded
chrome_path = ChromeDriverManager().install()
# define the chrome service and pass it to the driver instance
chrome_service = Service(chrome_path)
driver = webdriver.Chrome(service=chrome_service, options=options)
url = "https://www.scrapethissite.com/pages/"
driver.get(url)
# get the first page and click to the link
first_page = driver.find_element(By.CSS_SELECTOR, "h3.page-title a")
first_page.click()
# get the data div and extract the data using beautifulsoup
countries_container = driver.find_element(By.CSS_SELECTOR, "section#countries div.container")
countries = driver.find_elements(By.CSS_SELECTOR, "div.country")
# scrape the data using extract_data function
data = https://www.cnblogs.com/v3ucn/p/list(map(extract_data, countries))
end = time.time()
print(f"The whole script took: {end-start:.4f}")
driver.quit()
測驗結果:
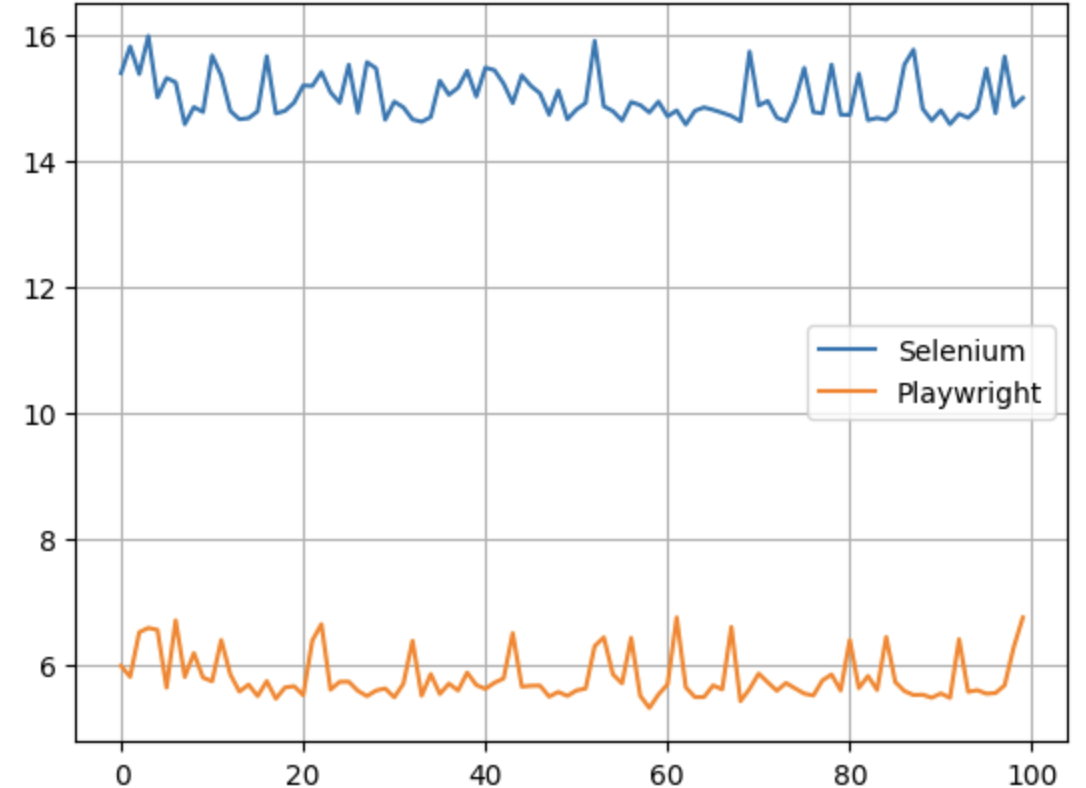
Y軸是執行時間,一望而知,Selenium比PlayWright差了大概五倍左右,
紅玫瑰還是白玫瑰?
不得不承認,Playwright 和 Selenium 都是出色的自動化無頭瀏覽器工具,都可以完成爬蟲任務,我們還不能斷定那個更好一點,所以選擇那個取決于你的網路抓取需求、你想要抓取的資料型別、瀏覽器支持和其他考慮因素:
Playwright 不支持真實設備,而 Selenium 可用于真實設備和遠程服務器,
Playwright 具有內置的異步并發支持,而 Selenium 需要第三方工具,
Playwright 的性能比 Selenium 高,
Selenium 不支持詳細報告和視頻錄制等功能,而 Playwright 具有內置支持,
Selenium 比 Playwright 支持更多的瀏覽器,
Selenium 支持更多的編程語言,
結語
如果您看完了本篇文章,那么到底誰是最好的無頭瀏覽器工具,答案早已在心間,所謂強中強而立強,只有弱者才害怕競爭,相信PlayWright的出現會讓Selenium變為更好的自己,再接再厲,再創輝煌,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/544925.html
標籤:Python
上一篇:Python工具箱系列(二十六)