分布式資料存盤三要素
什么是分布式資料存盤系統?
分布式存盤系統的核心邏輯,就是將用戶需要存盤的資料根據某種規則存盤到不同的機器上,當用戶想要獲取指定資料時,再按照規則到存盤資料的機器中獲取,
分布式存盤系統的三要素:
- 資料生產者 / 資料消費者
- 資料索引
- 資料存盤
資料生產者生產資料,將資料存盤到分布式資料存盤系統中,資料消費者是從分布式資料存盤系統中獲取資料進行消費;資料索引將訪問資料的請求轉發到資料所在的存盤節點;存盤設備用來存盤資料,
分布式系統資料型別
分布式系統中存在大量不同型別的資料,根據資料的特征,我們可以將其分為三類:
- 結構化資料,指關系模型資料,特征是資料關聯較大、格式固定,一般采用分布式關系資料庫進行存盤和查詢,
- 半結構化資料,指非關系模型資料,有基本固定結構模式的資料,特征是資料之間關系比較簡單,一般采用分布式鍵值系統進行存盤和使用,
- 非結構化資料,指沒有固定模式的資料,特征是資料之間關聯不大,這種資料一般存盤到檔案中,通過ElasticSearch等進行檢索,
資料分片與資料復制
資料分片技術,是指分布式存盤系統按照一定的規則,將資料存盤到相應的存盤節點中,或者到相應的存盤節點中獲取想要的資料,這種技術一方面可以降低單個存盤節點的存盤和訪問壓力,另一方面可以通過規定好的規則快速找到資料所在的存盤節點,從而大大降低搜索延遲,提高用戶體驗,
資料分片可以采取不同的方式,包括:
- 資料特征分片
- 資料范圍分片
- 哈希分片
- 一致性哈希分片
資料復制是指將資料進行備份,使得多個節點存盤該資料,它可以通過主備方式存盤的方式,提高分布式系統的可用性和可靠性,
在實際的分布式存盤系統中,資料分片和資料復制通常是共存的:
- 資料通過分片方式存盤到不同的節點上,以減少單節點的性能瓶頸問題,
- 資料的存盤通過主備方式保證可靠性,即對每個節點上存盤的分片資料,采用主備方式存盤,來保證資料可靠性,其中主備節點上資料一致,是通過資料復制技術實作的,
資料存盤
根據上述三種不同的資料型別,常采用的資料存盤選型方案如下:
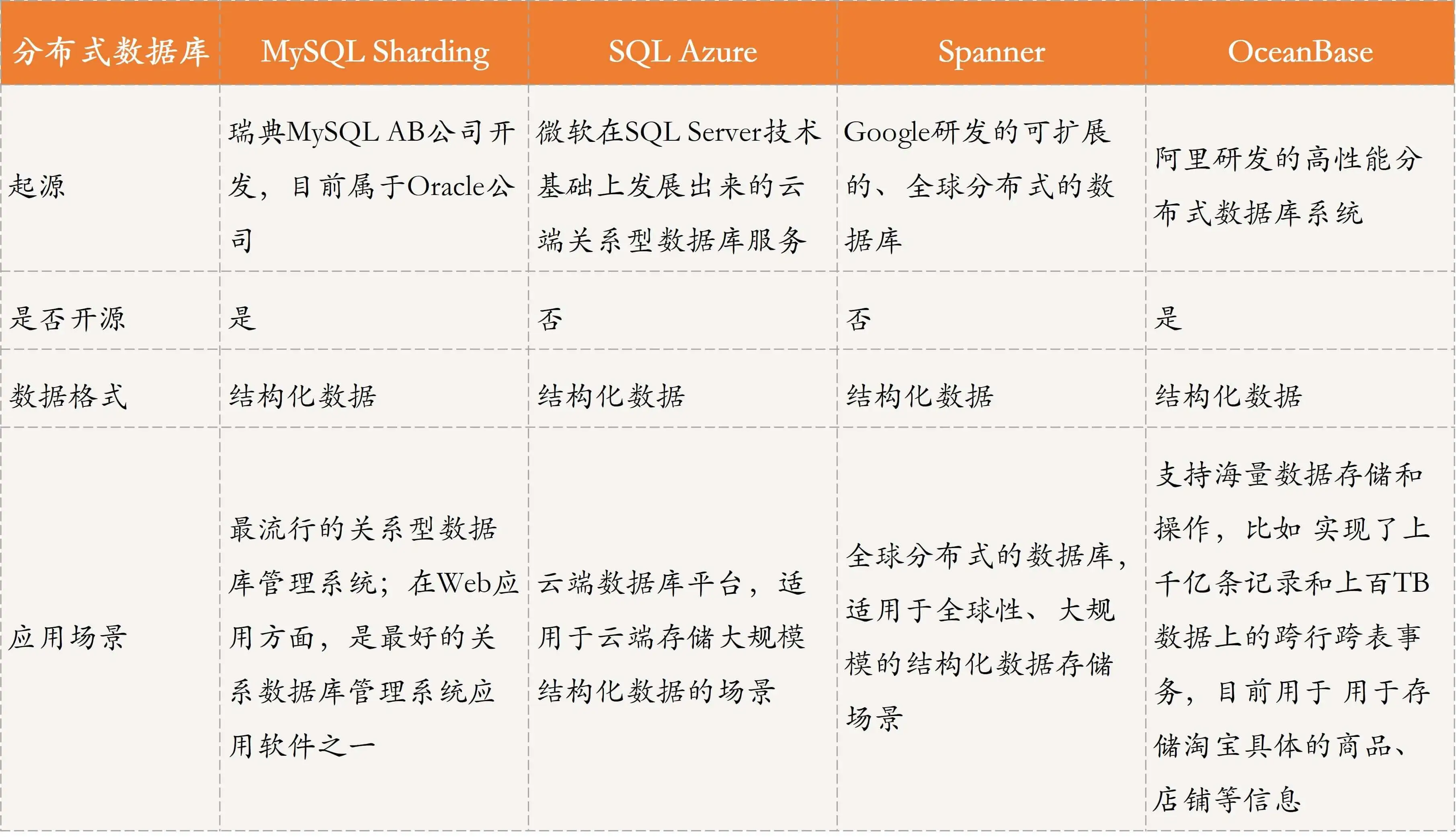
- 分布式資料庫,通過表格來存盤結構化資料,方便查找,常見的方案包括:MySQL Sharding、Microsoft SQL Azure、Google Spanner、Alibaba OceanBase等,
- 分布式鍵值系統,通過兼職對來存盤半結構化資料,常見的方案包括:Redis、Memcache等,
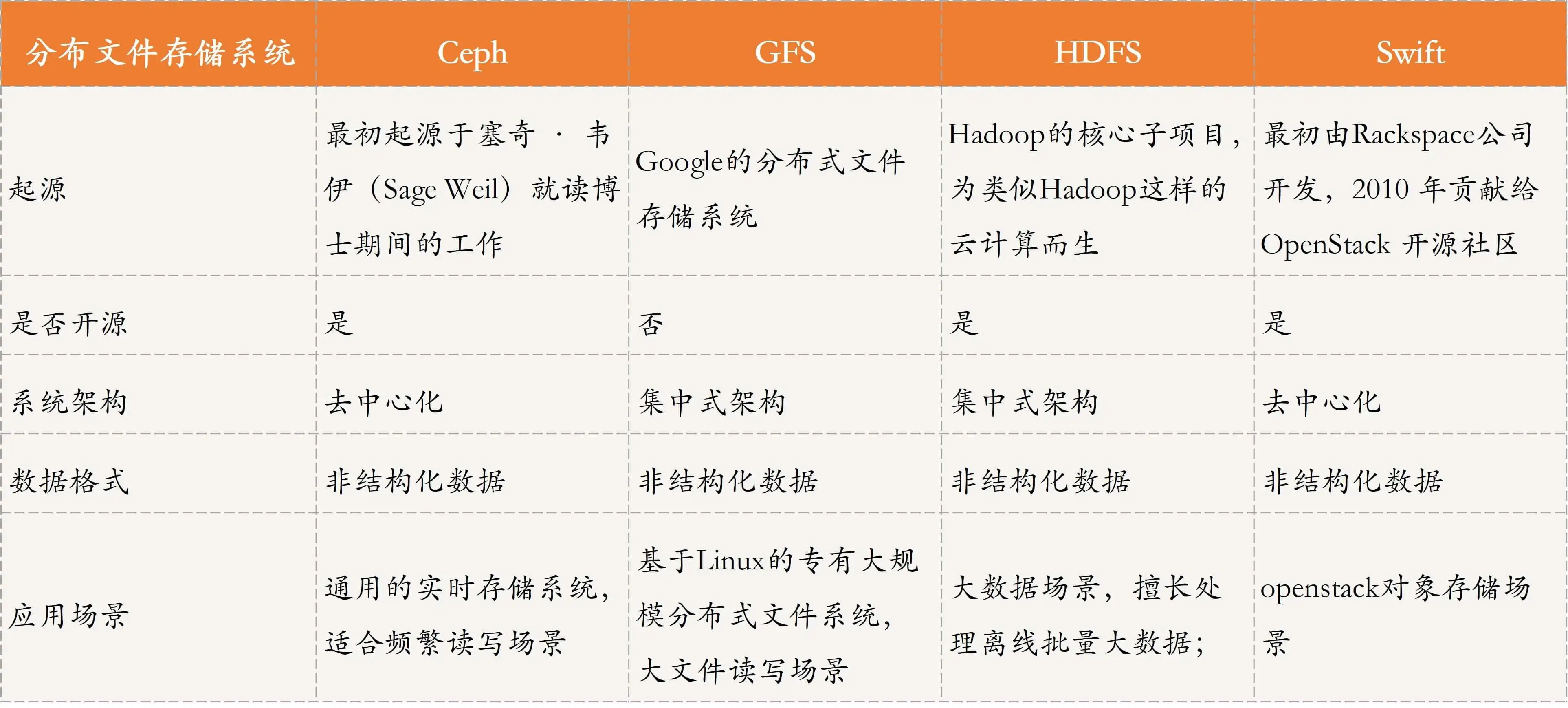
- 分布式存盤系統,通過檔案、塊、物件等來存盤非結構化資料,常見的方案包括:Ceph、GFS、HDFS、Swift等,
詳細的分布式資料庫比較如下,
詳細的分布式存盤系統比較如下,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/544935.html
標籤:其他