1、變數
- 推薦
- 駝峰體:AgeOfOldboy = 73
- 下劃線:age_of_oldboy = 73
# 變數的小高級:
age1 = 18
age2 = age1
age3 = age2
age2 = 12
print(age1,age2,age3)
18 12 18
Process finished with exit code 0
#********************************************************************************************************
# 變數的小高級:
age1 = 18
age2 = 12
age2 = age1
age3 = age2
print(age1,age2,age3)
18 18 18
Process finished with exit code 0
決議:首先從上到下執行,

2、常量
- 常量:一直不變的量,python中沒有真正的常量,為了應和其他語言的口味,全部大寫的變數稱之為常量,
- 將變數全部大寫,放在檔案的最上面,
# 常量
# 約定俗成不能改變
NAME = '太白'
print(NAME)
太白
Process finished with exit code 0
3.注釋(重點)
- 單行注釋: #
- 多行注釋: '''被注釋內容''' """被注釋內容"""
3、流程控制陳述句if
基本結構:
if 條件:
結果
1、單獨if
- 如果條件成立,就執行if陳述句中的代碼,如果條件不成立,就不執行if陳述句中的代碼,
#單獨if
if 2 < 1:
print(111)
if 2 > 1:
print(222)
222
Process finished with exit code 0
2、if else 二選一
# if else 二選一
age = input('請輸入年齡:')
if int(age) > 18:
print('恭喜你,成年了')
else:
print('小屁孩兒')
請輸入年齡:1
小屁孩兒
Process finished with exit code 0
3、if elif elif .... 多選一
- 陳述句測成立后就列印該陳述句中的代碼,下面的判斷陳述句就不執行了
num = int(input('猜點數:'))
if num == 1:
print("晚上請你吃飯")
elif num == 3:
print("一起溜達")
elif num==2:
print("請你大寶劍")
4、if elif elif .... else 多選一
- 當所有條件都不滿足,就執行else中的代碼、有一個成立了,就不會執行else中的代碼
num = int(input('猜點數:'))
if num == 1:
print("晚上請你吃飯")
elif num == 3:
print("一起溜達")
elif num==2:
print("請你大寶劍")
else:
print("太笨了")
5、嵌套的if
#思路 -----然后將pass改為對應的用戶名、密碼的條件判斷
if your_code == code:
pass
else:
print("驗證碼錯誤")
username=input("請輸入用戶名:")
password=input("請輸入密碼")
code= 'qwer'
your_code=input("請輸入驗證碼:")
if your_code == code:
if username == 'mike' and password == '123456':
print('登錄成功')
else:
print('賬號或者密碼錯誤')
else:
print("驗證碼錯誤")
4、while 回圈
1,基本結構:
while:無限回圈 for :有限回圈
while 條件:
回圈體
2,基本原理: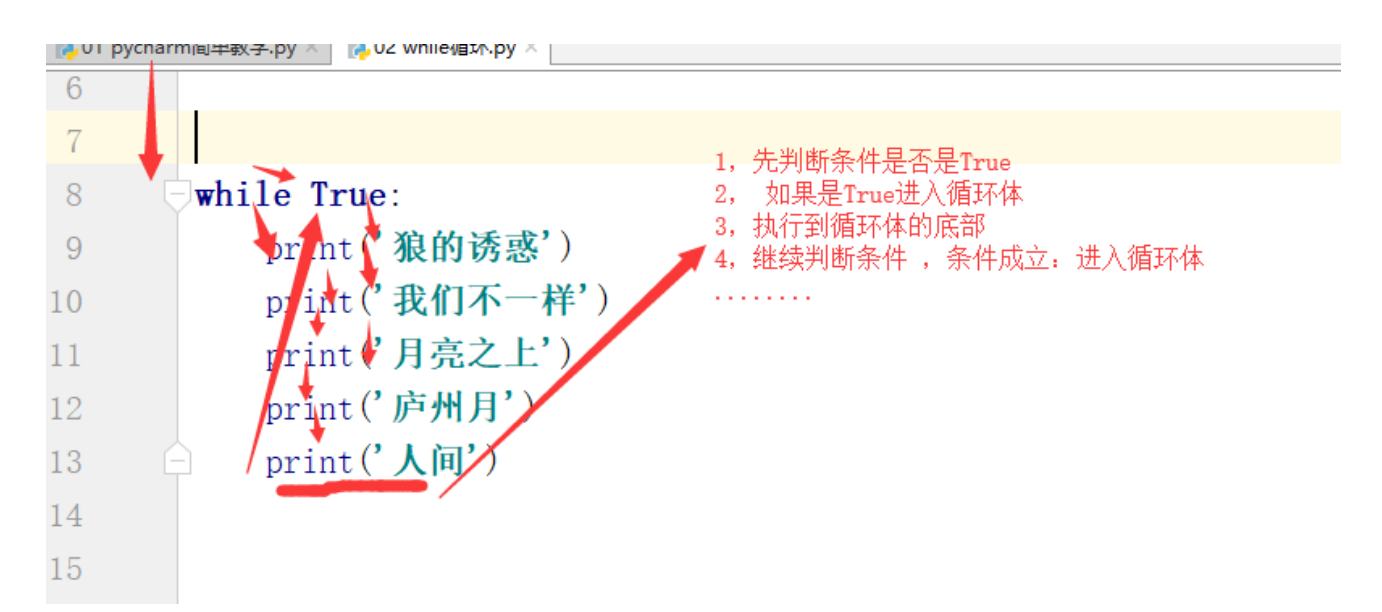
3,回圈如何終止?
1,改變條件,
flag = True
while flag:
print('狼的傭訓')
print('我們不一樣')
print('月亮之上')
flag = False
print('廬州月')
print('人間')
#加入計數器,使其達到條件后退出回圈
i=0
while True:
print('狼的傭訓')
print('我們不一樣')
print('月亮之上')
print('廬州月')
print('人間')
i=i+1
if i==2:
break
2,break
- 退出回圈
while True:
print('狼的傭訓')
print('我們不一樣')
print('月亮之上')
print('廬州月')
print('人間')
break
3,系統命令(今天不講)
4,continue
- continue : 退出本次回圈,繼續下一次回圈
# continue : 退出本次回圈,繼續下一次回圈
i=0
while True:
print('狼的傭訓')
i=i+1
if i==2:
continue
print('月亮之上')
if i == 3:
break
狼的傭訓 #i=1
月亮之上
狼的傭訓 #i=2 continue退出本次回圈 只列印了狼的傭訓
狼的傭訓 #i=3
月亮之上
Process finished with exit code 0
# while else: while 回圈如果被break打斷,則不執行else陳述句,
count = 1
while count < 5:
print(count)
if count == 2:
break
count = count + 1
else:
print(666)
優化登錄的代碼;
#有三次錯誤輸入的機會
count=1
while count<4:
username=input("請輸入用戶名:")
password=input("請輸入密碼")
code= 'qwer'
your_code=input("請輸入驗證碼:")
if your_code == code:
if username == 'mike' and password == '123456':
print('登錄成功')
else:
print('賬號或者密碼錯誤')
else:
print("驗證碼錯誤")
count=count+1
練習題:列印1~ 100 所有的數字
#第一種方案
count=1
while True:
print(count)
count=count+1
if count==101:
break
#第二種方案
count = 1
flag = True
while flag:
print(count)
count = count + 1
if count == 101:
flag = False
#第三種方案
count = 1
while count < 101:
print(count)
count = count + 1
練習題:1 + 2 + ..... 100 的最終結果
# 1 + 2 + 3 + ...... 100 的最終結果:
s = 0
count = 1
while count < 101:
s = s + count
count = count + 1
print(s)
day2:
1、代碼塊(重點)
- 代碼塊:我們所有的代碼都需要依賴代碼塊執行,
- 一個模塊,一個函式,一個類,一個檔案等都是一個代碼塊,,
- 而作為互動方式輸入的每個命令都是一個代碼塊,
而對于一個檔案中的兩個函式,也分別是兩個不同的代碼塊:

2、代碼塊的快取機制
-
兩個機制: 同一個代碼塊下,有一個機制,不同的代碼塊下,遵循另一個機制,
-
同一個代碼塊下的快取機制,
-
前提條件:同一個代碼塊內,
-
機制內容:pass
機制內容:Python在執行同一個代碼塊的初始化物件的命令時,會檢查是否其值是否已經存在,如果存在,會將其重用,換句話說:執行同一個代碼塊時,遇到初始化物件的命令時,他會將初始化的這個變數與值存盤在一個字典中,在遇到新的變數時,會先在字典中查詢記錄,如果有同樣的記錄那么它會重復使用這個字典中的之前的這個值,所以在你給出的例子中,檔案執行時(同一個代碼塊)會把i1、i2兩個變數指向同一個物件,滿足快取機制則他們在記憶體中只存在一個,即:id相同 -
適用的物件: int bool str
-
具體細則:所有的數字,bool,幾乎所有的字串,
-
優點:提升性能,節省記憶體,
-
-
不同代碼塊下的快取機制: 小資料池,
-
前提條件:不同代碼塊內,
-
機制內容:pass
Python自動將-5~256的整數進行了快取,當你將這些整數賦值給變數時,并不會重新創建物件,而是使用已經創建好的快取物件, python會將一定規則的字串在字串駐留池中,創建一份,當你將這些字串賦值給變數時,并不會重新創建物件, 而是使用在字串駐留池中創建好的物件, 其實,無論是快取還是字串駐留池,都是python做的一個優化,就是將~5-256的整數,和一定規則的字串,放在一個‘池’(容器,或者字典)中,無論程式中那些變數指向這些范圍內的整數或者字串,那么他直接在這個‘池’中參考,言外之意,就是記憶體中之創建一個 -
適用的物件: int bool str
-
具體細則:-5~256數字,bool,滿足規則的字串,
-
優點:提升性能,節省記憶體,
-
總結:
- 面試題考,
- 回答的時候一定要分清楚:同一個代碼塊下適用一個快取機制,不同的代碼塊下適用另一個快取機制(小資料池)
- 小資料池:數字的范圍是-5~256.
- 快取機制的優點:提升性能,節省記憶體,
3、深淺copy(面試會考)
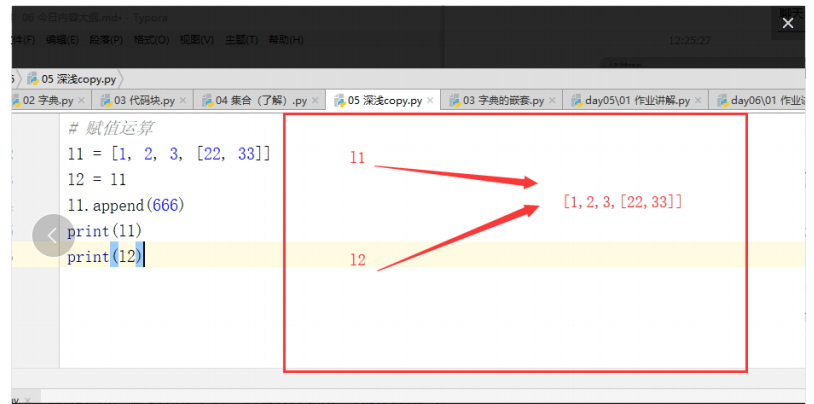
1,先看賦值運算
- 對于賦值運算來說,a1與a2指向的是同一個記憶體地址,所以他們是完全一樣的,在舉個例子,比如張三李四合租在一起,那么對于客廳來說,他們是公用的,張三可以用,李四也可以用,但是突然有一天張三把客廳的的電視換成投影了,那么李四使用客廳時,想看電視沒有了,而是投影了,對吧?a1,a2指向的是同一個串列,任何一個變數對串列進行改變,剩下那個變數在使用串列之后,這個串列就是發生改變之后的串列,
#賦值運算
a1=[1,2,3,[22,33]]
a2=a1
a1.append(666)
print(a1,id(a1))
print(a2,id(a2))
[1, 2, 3, [22, 33], 666] 1768812233480
[1, 2, 3, [22, 33], 666] 1768812233480
Process finished with exit code 0
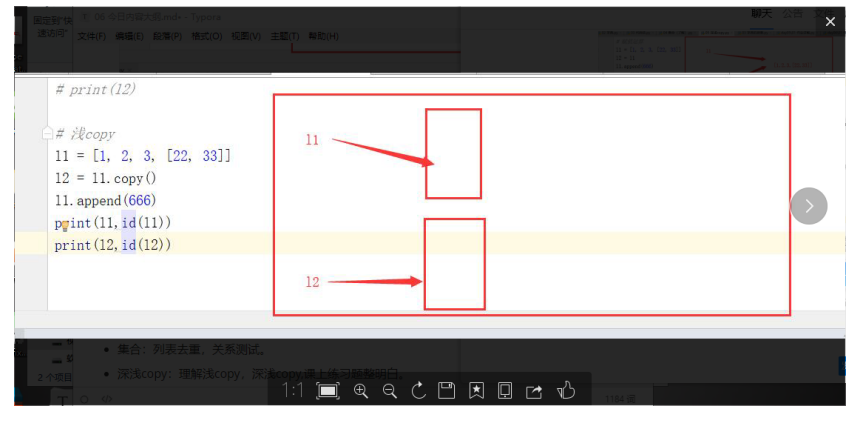
2,淺拷貝copy,
- 對于淺copy來說,只是在記憶體中重新創建了開辟了一個空間存放一個新串列,但是新串列中的元素與原串列中的元素是公用的,
所以a1 和a2的ID不同,但是內容ID相同
#淺copy
#同一代碼塊下:
a1=[1,2,3,[22,33]]
a2=a1.copy()
a1.append(666)
print(a1,id(a1))
print(a2,id(a2))
[1, 2, 3, [22, 33], 666] 1321060254472
[1, 2, 3, [22, 33]] 1321059431112
Process finished with exit code 0
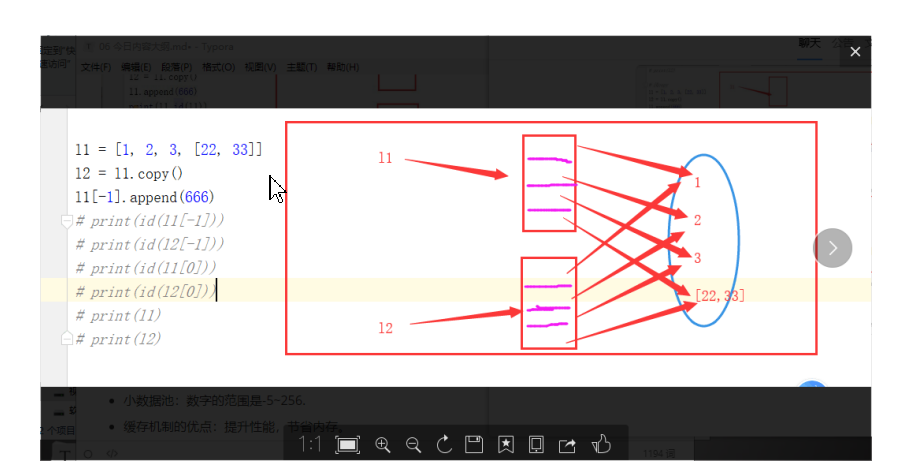
#*********************************************
# 不同代碼塊下:
a1=[1,2,3,[22,33]]
a2=a1.copy()
a1[-1].append(666)
print(a1,id(a1))
print(a2,id(a2))
#列印a1 a2中小串列的存盤ID
print(id(a1[-1]))
print(id(a2[-1]))
[1, 2, 3, [22, 33, 666]] 2332545303304
[1, 2, 3, [22, 33, 666]] 2332544479944
2332545286088
2332545286088
Process finished with exit code 0
思考1:a2 淺拷貝a1后,a1串列中的小串列添加元素后,a2的小串列為啥也添加?
---因為a1 a2 是兩個不同的大串列,但是串列里邊的元素都是公用一個,所以a1的小串列添加666 a2的小串列也添加666
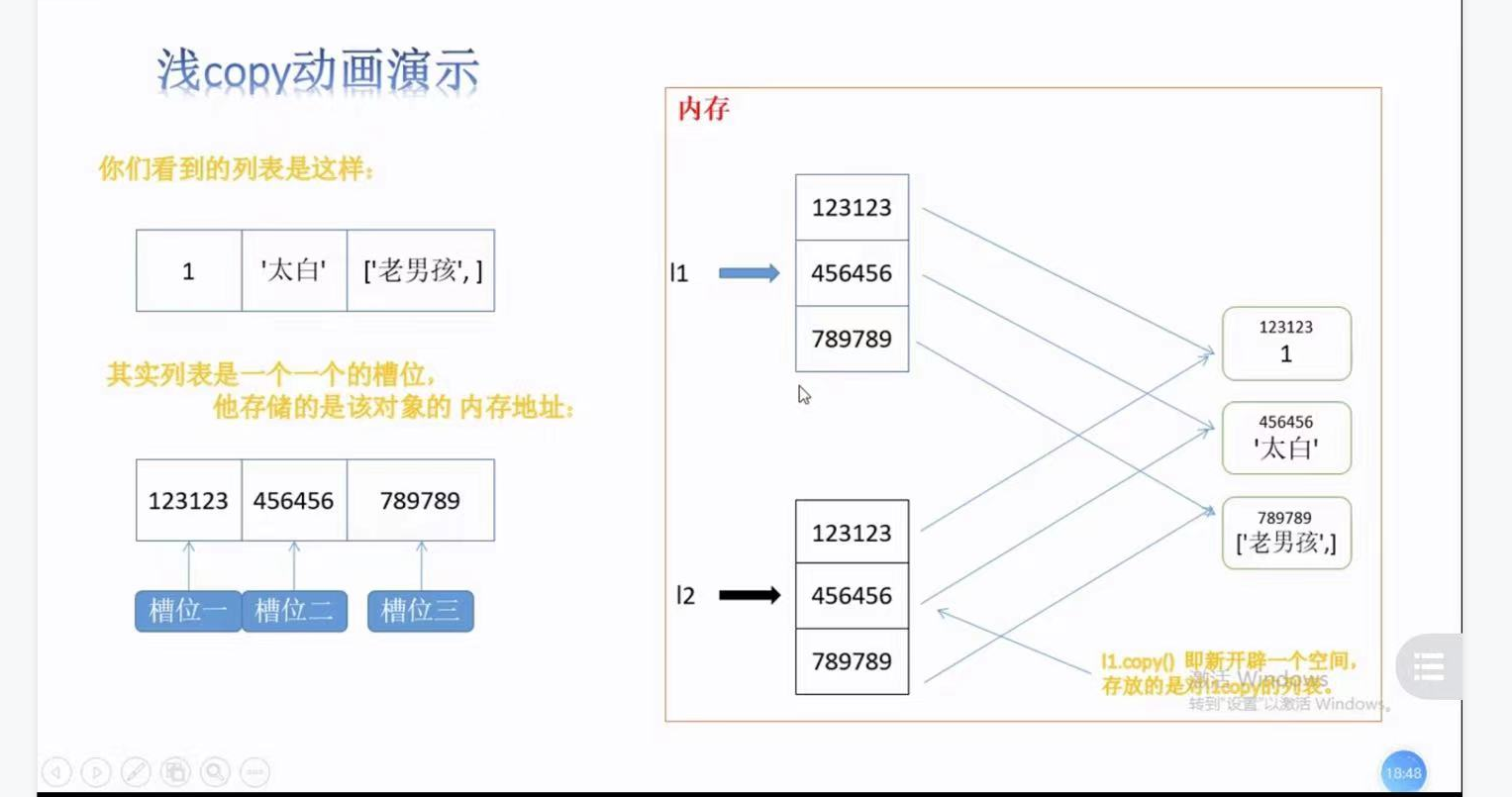
思考2:如果使a1[0]=90,此時a2[0]是否等于90? 為什么a2[0]不變?
因為之前的a1[0],a1[1],a1[3]是1,2,3 是字串,是不可變的,我改變的不是a1[0]本身,我只是改變了a1這個串列第一個槽位的記憶體關系
a1=[1,2,3,[22,33]]
a2=a1.copy()
a1[0]=90
print(a1)
print(a2)
[90, 2, 3, [22, 33]]
[1, 2, 3, [22, 33]]
Process finished with exit code 0
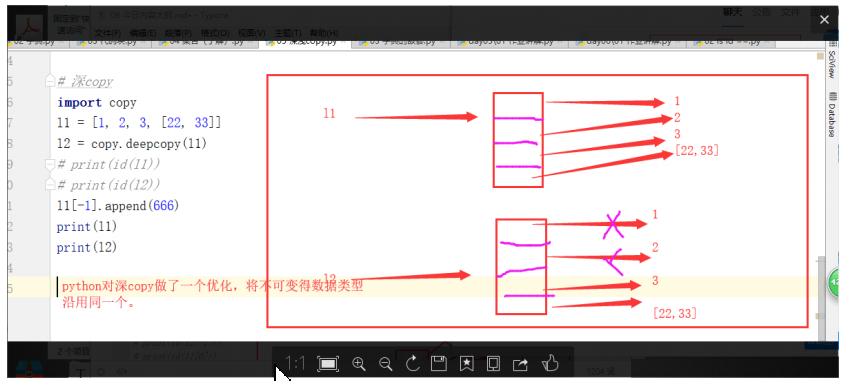
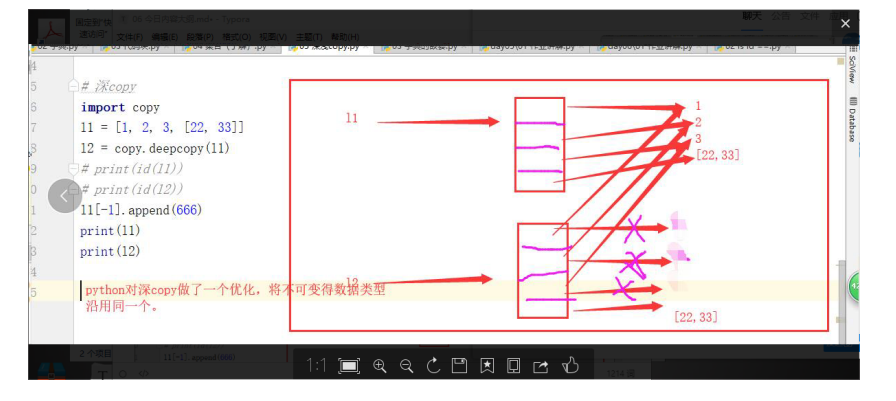
3,深拷貝deepcopy
- 深copy則會在記憶體中開辟新空間,將原串列以及串列里邊的可變的資料型別重新創建一份,不可變的資料型別則沿用之前的(即公用一個)
#深copy
import copy
a1=[1,2,3,[22,33]]
a2=copy.deepcopy(a1)
print(a1,id(a1))
print(a2,id(a2))
[1, 2, 3, [22, 33]] 1512146813512
[1, 2, 3, [22, 33]] 1512146814664
Process finished with exit code 0
示例:a1[-1].append(666)
#深copy
import copy
a1=[1,2,3,[22,33]]
a2=copy.deepcopy(a1)
a1[-1].append(666)
print(a1)
print(a2)
[1, 2, 3, [22, 33, 666]]
[1, 2, 3, [22, 33]]
Process finished with exit code 0
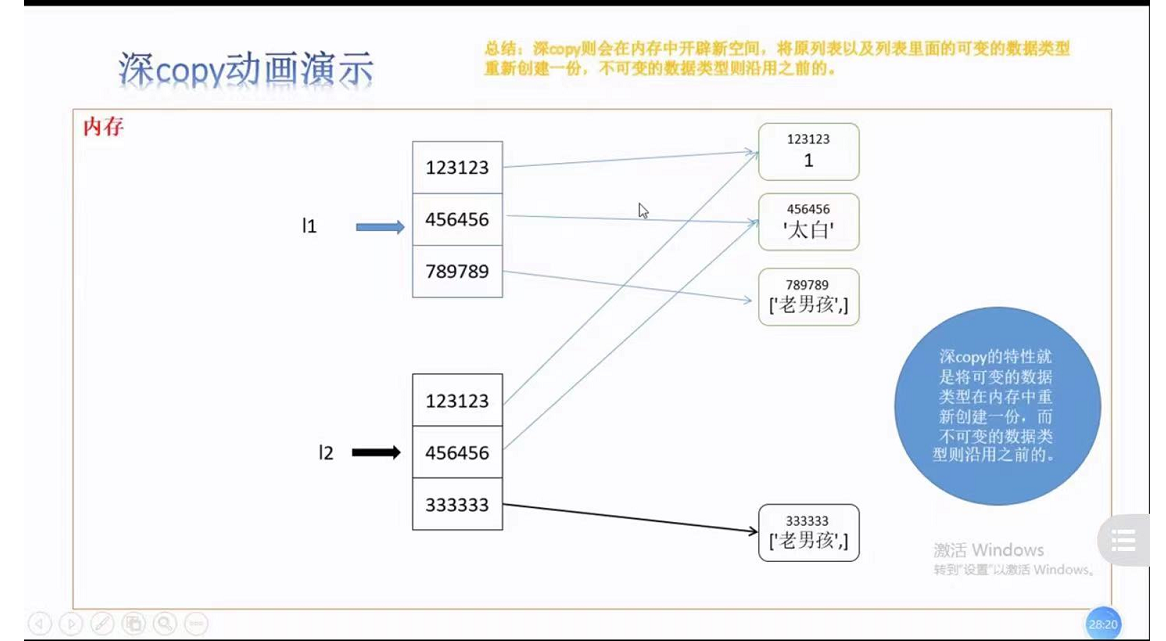
4,深淺拷貝面試題
#面試題:
# 考察的內容是:切邊是深拷貝還是淺拷貝?--淺拷貝
a1=[1,2,3,[22,33]]
a2=a1[:]
a1[-1].append(666)
print(a1)
print(a2)
# 淺copy: list dict: 嵌套的可變的資料型別是同一個,
# 深copy: list dict: 嵌套的可變的資料型別不是同一個 ,
def eat(a,b,c,d):
print('我請你吃:{},{},{},{}'.format(a,b,c,d))
eat('蒸羊羔', '蒸熊掌', '蒸鹿邑','啥訓鴨')
# 急需要一種形參,可以接受所有的實參,
# 萬能引數: *args, 約定俗稱:args,
# 函式定義時,*代表聚合, 他將所有的位置引數聚合成一個元組,賦值給了 args,
def eat(*args):
print(args)
print('我請你吃:{},{},{},{}'.format(*args))
eat('蒸羊羔', '蒸熊掌', '蒸鹿邑','啥訓鴨')
day3:
1、形參角度:(重點)
萬能引數: *args
- *的魔性用法-------在函式的定義時,表示聚合 ;在函式的呼叫時,表示打散或解包,
def eat(a,b,c,d):
print('我請你吃:{},{},{},{}'.format(a,b,c,d))
eat('蒸羊羔', '蒸熊掌', '蒸鹿邑','啥訓鴨')
# 急需要一種形參,可以接受所有的實參,
# 萬能引數: *args, 約定俗稱:args,
# 函式定義時,*代表聚合, 他將所有的位置引數聚合成一個元組,賦值給了 args,
def eat(*args):
print(args)
print('我請你吃:{},{},{},{}'.format(*args))
eat('蒸羊羔', '蒸熊掌', '蒸鹿邑','啥訓鴨')
我請你吃:蒸羊羔,蒸熊掌,蒸鹿邑,啥訓鴨
('蒸羊羔', '蒸熊掌', '蒸鹿邑', '啥訓鴨')
我請你吃:蒸羊羔,蒸熊掌,蒸鹿邑,啥訓鴨
Process finished with exit code 0
- 練習題:寫一個函式:計算你傳入函式的所有的數字的和,
#練習題:寫一個函式:計算你傳入函式的所有的數字的和,
# tu1=(1,2,3,4,5,6,7)
# count=0
# for i in tu1:
# count=count+i
# print(count)
def func(*args):
count = 0
for i in args:
count = count + i
return count
print(func(1,2,3,4,5,6,7))
28
Process finished with exit code 0
萬能引數:**kwargs
# **kwargs
# 函式的定義時: ** 將所有的關鍵字引數聚合到一個字典中,將這個字典賦值給了kwargs.
def func(**kwargs):
print(kwargs)
func(name='alex',age=73,sex='laddyboy')
{'name': 'alex', 'age': 73, 'sex': 'laddyboy'}
Process finished with exit code 0
# * **在函式的呼叫時,*代表打散---也可以說 解包
def func(*args):
print(args)
func([1,2,3],[22,33])
func(*[1,2,3],[22,33])
func(*[1,2,3],*[22,33])
([1, 2, 3], [22, 33])
(1, 2, 3, [22, 33])
(1, 2, 3, 22, 33)
Process finished with exit code 0
def func(*args,**kwargs):
print(args)
print(kwargs)
func({'name': '太白'},{'age': 18})
print('*********')
func(**{'name': '太白'},**{'age': 18})
({'name': '太白'}, {'age': 18})
{}
*********
()
{'name': '太白', 'age': 18}
Process finished with exit code 0
形參角度的引數的順序
(位置引數,默認引數,萬能引數)
- 思考?------*args的位置?
- 必須放在位置引數后面,默認引數前面(如果默認引數放在*args 前面,那么呼叫的時候,默認引數的值會被改變)
#形參角度的引數的順序(位置引數,默認引數,萬能引數)
# *args的位置?----必須放在位置引數后面,默認引數前面
def func(a,b,*args,sex='男'):
print(a,b)
print(sex)
print(args)
func(1,2,3,4)
1 2
男
(3, 4)
Process finished with exit code 0
- 思考?----**kwargs的位置?
- 要放在默認引數后面,
#**kwargs的位置?
def func(a,b,*args,sex='男',**kwargs):
print(a,b)
print(sex)
print(args)
print(kwargs)
func(1,2,3,4,age=12)
1 2
男
(3, 4)
{'age': 12}
Process finished with exit code 0
僅限關鍵字引數(了解)
- 放在*args和**kwargs的位置之間,類似于默認引數
def func(a,b,*args,sex='男',c,**kwargs):
print(a,b)
print(sex)
print(args)
print(c)
print(kwargs)
func(1,2,3,4,age=12,c='666')
1 2
男
(3, 4)
666
{'age': 12}
Process finished with exit code 0
形參角度最終的順序:
- 位置引數,*args,默認引數,僅限關鍵字引數,**kwargs
函式的嵌套(高階函式)
# 例1:---思考列印結果和順序
def func1():
print('in func1')
print(3)
def func2():
print('in func2')
print(4)
func1()
print(1)
func2()
print(2)
in func1
3
1
in func2
4
2
Process finished with exit code 0
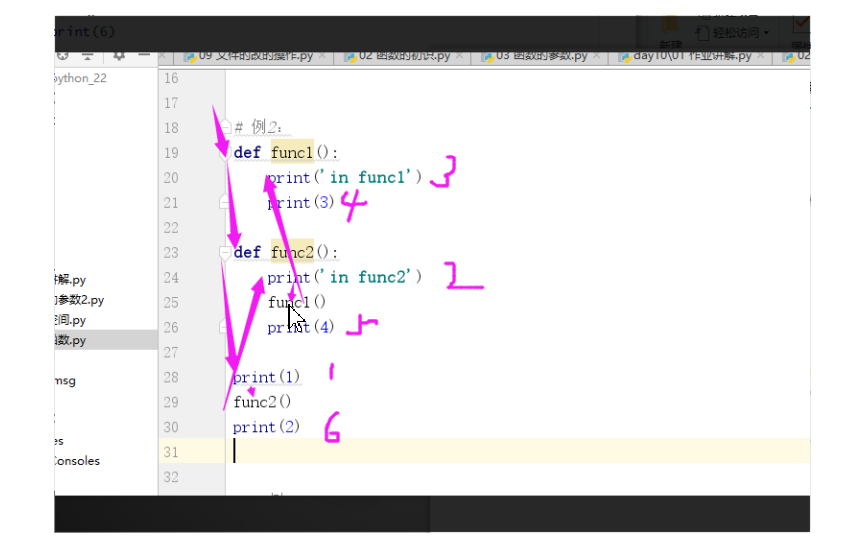
# 例2:---思考列印結果和順序
def func1():
print('in func1')
print(3)
def func2():
print('in func2')
func1()
print(4)
print(1)
func2()
print(2)
1
in func2
in func1
3
4
2
Process finished with exit code 0
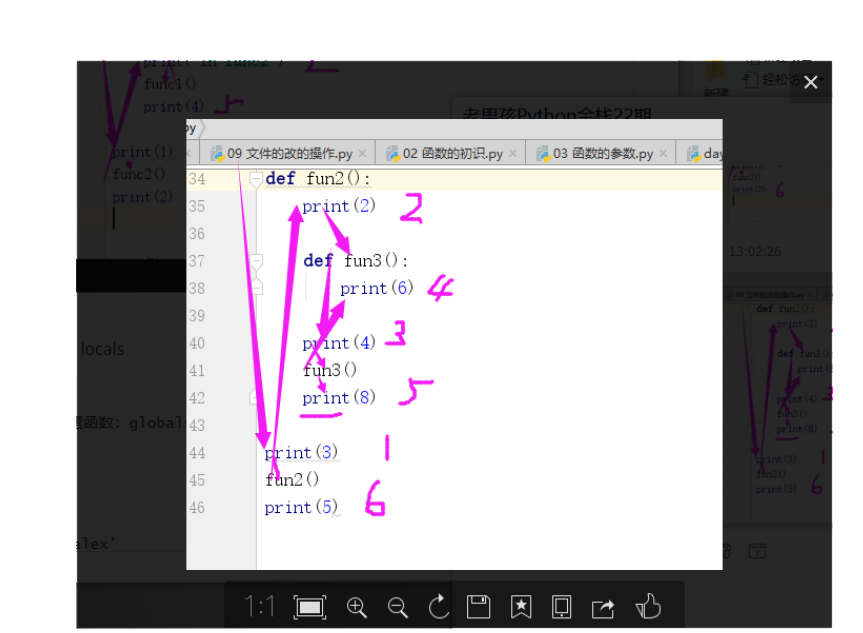
# 例3:---思考列印結果和順序
def fun2():
print(2)
def fun3():
print(6)
print(4)
fun3()
print(8)
print(3)
fun2()
print(5)
3
2
4
6
8
5
Process finished with exit code 0
day11:
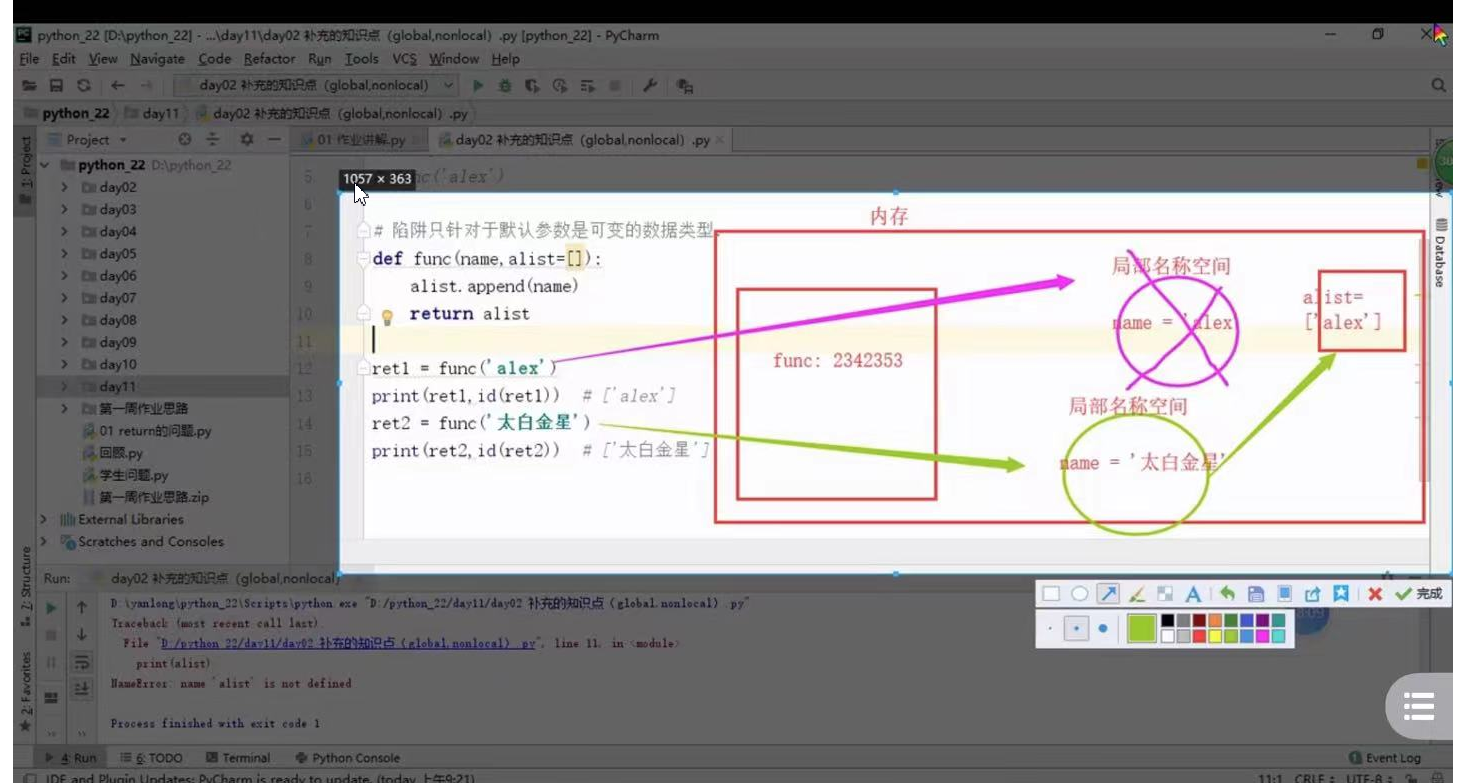
1、補充:默認引數的陷阱
- 陷阱只針對于默認引數是可變的資料型別:
- 結論:如果你的默認引數指向的是可變的資料型別,那么你無論呼叫多少次這個默認引數,都是同一個,
# 陷阱只針對于默認引數是可變的資料型別:
def func(name,alist=[]):
alist.append(name)
return alist
ret1=func("mike")
print(ret1,id(ret1)) #列印結果 ['mike']
ret2=func('太白金星')
print(ret2,id(ret2))
['mike'] 2579283148744
['mike', '太白金星'] 2579283148744
Process finished with exit code 0
- 圖形講解
面試題1:
def func(a,list=[]):
list.append(a)
return list
print(func(10))
print(func(20,[]))
print(func(100))
[10]
[20]
[10, 100]
Process finished with exit code 0
#等同于如下:
l1 = []
l1.append(10)
print(l1)
l2 = []
l2.append(20)
print(l2)
l1.append(100)
print(l1)
面試題2:
- 面試題2是 3個執行完才列印,面試題1是執行一個列印一次
def func(a,list=[]):
list.append(a)
return list
ret1=func(10)
ret2=(func(20,[]))
ret3=(func(100))
print(ret1)
print(ret2)
print(ret3)
[10, 100]
[20]
[10, 100]
Process finished with exit code 0
2、補充:區域作用域的坑:
global:
1, 在區域作用域宣告一個全域變數,
? 注意:要先呼叫函式,這樣函式里的全域變數才可以被參考
#global
#1, 在區域作用域宣告一個全域變數,
name = 'alex'
def func():
global name
name = '太白金星'
print(name)
func()
print(name)
太白金星
太白金星
Process finished with exit code 0
- 如果先呼叫區域變數中的全域變數,會報錯-----要先呼叫函式
def func():
global name
name = '太白金星'
print(name)
print(name)
func()
NameError: name 'name' is not defined
Process finished with exit code 1
2.修改一個全域變數
- 原來這樣寫會報錯

- 加入global 就可以完成參考全域變數并且修改全域變數
#2. 修改一個全域變數
count=1
def func():
global count
count=count+1
print(count)
func()
print(count)
1
2
Process finished with exit code 0
nonlocal
1.不能夠操作全域變數
count = 1
def func():
nonlocal count
count += 1
func()
SyntaxError: no binding for nonlocal 'count' found
Process finished with exit code 1
2.區域作用域:內層函式對外層函式的區域變數進行修改
# 2. 區域作用域:內層函式對外層函式的區域變數進行修改,
def wrapper():
count = 1
def inner():
nonlocal count
count += 1
print(count)
inner()
print(count)
wrapper()
3、函式名的運用
1.函式名指向的是函式的記憶體地址,
? 函式名 + ()就可以執行次函式,
def func():
print(666)
func()
# 1. 函式名指向的是函式的記憶體地址,
# 函式名 + ()就可以執行次函式,
print(func,type(func))
666
<function func at 0x0000022029A21E18> <class 'function'>
Process finished with exit code 0
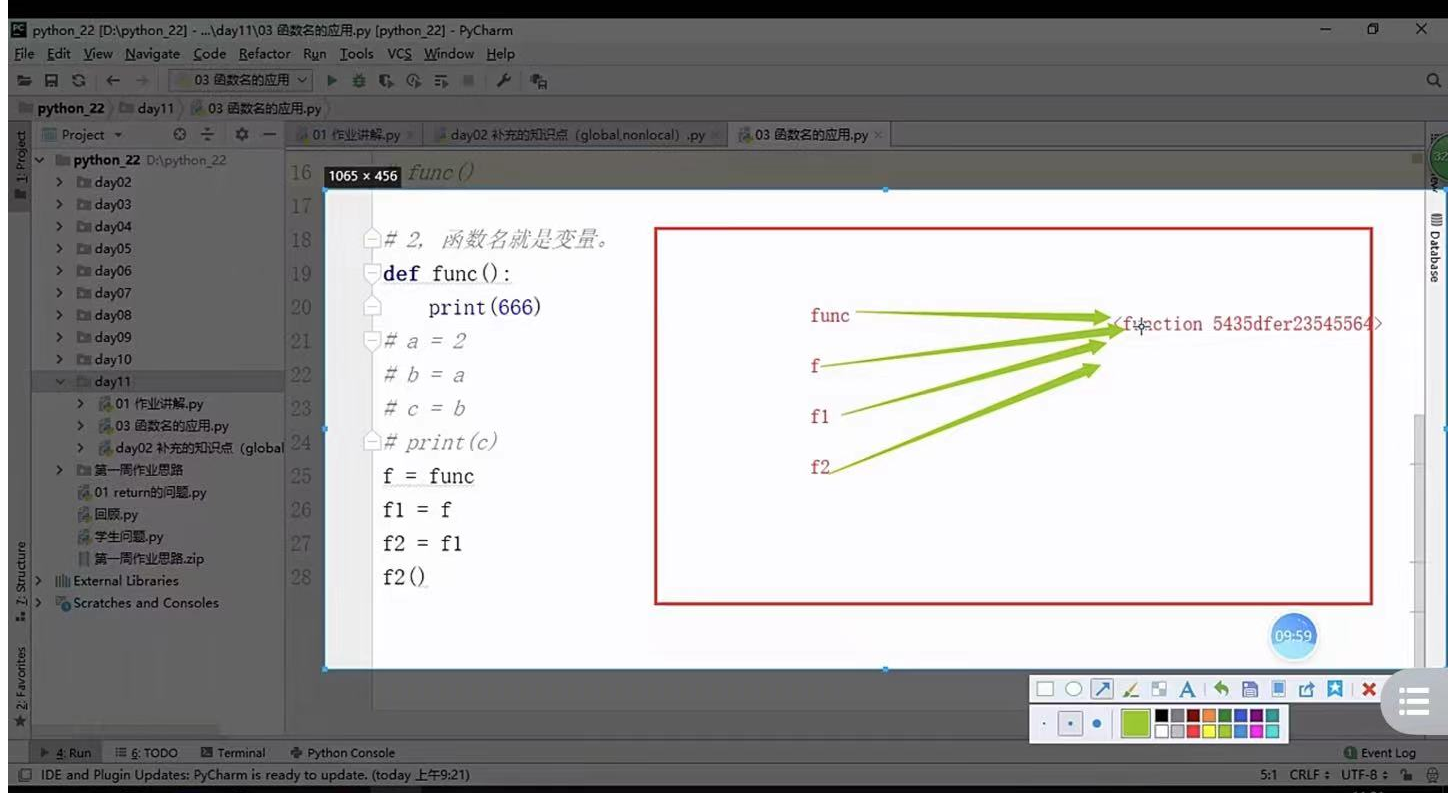
2, 函式名就是變數,
def func():
print(666)
f=func
f1=f
f2=f1
f2()
666
Process finished with exit code 0
- 圖形解釋
def func():
print('in func')
def func1():
print('in fun1')
func1=func
func1()
#列印那個結果?
#分析:類比如下
a=1
b=2
a=b
print(a)
in func
2
Process finished with exit code 0
3.函式名可以作為容器類資料型別的元素
# 3. 函式名可以作為容器類資料型別的元素
# a = 1
# b = 2
# c = 3
# l1 = [a,b,c]
# print(l1)
def func1():
print('in fun1')
def func2():
print('in fun2')
def func3():
print('in fun3')
a1=[func1,func2,func3]
for i in a1:
i()
in fun1
in fun2
in fun3
Process finished with exit code 0
4.函式名可以作為函式的引數
def func():
print('in func')
def fun1(x):
x() #相當于func()
print('in func1')
fun1(func)
in func
in func1
Process finished with exit code 0
5.函式名可以作為函式的回傳值
# 5. 函式名可以作為函式的回傳值
def func():
print('in func')
def func1(x):
print('in func1')
return x
ret=func1(func)
ret()
in func1
in func
Process finished with exit code 0
4、新特性:格式化輸出
1.舊的格式化方式
%s 和 format
#舊個格式化輸出,太麻煩了
name = '太白'
age = 18
msg = '我叫%s,今年%s' %(name,age)
print(msg)
msg1 = '我叫{},今年{}'.format(name,age)
print(msg)
我叫太白,今年18
我叫太白,今年18
Process finished with exit code 0
2.新特性:格式化輸出
# 新特性:格式化輸出
name = '太白'
age = 18
msg = f'我叫{name},今年{age}'
print(msg)
我叫太白,今年18
Process finished with exit code 0
2.1 可以加運算式
# 可以加運算式
dic = {'name':'alex','age': 73}
msg = f'我叫{dic["name"]},今年{dic["age"]}'
print(msg)
count = 7
print(f'最終結果:{count**2}')
name = 'barry'
msg = f'我的名字是{name.upper()}'
print(msg)
最終結果:49
我的名字是BARRY
Process finished with exit code 0
2.2 結合函式寫
# 結合函式寫:
def _sum(a,b):
return a + b
msg = f'最終的結果是:{_sum(10,20)}'
print(msg)
# ! , : { } ;這些標點不能出現在{} 這里面,
最終的結果是:30
Process finished with exit code 0
優點:
-
結構更加簡化,
-
可以結合運算式,函式進行使用,
-
效率提升很多,
5、迭代器:(重點)
1.可迭代物件
-
字面意思:物件?python中一切皆物件,一個實實在在存在的值,物件,
可迭代?:更新迭代,重復的,回圈的一個程序,更新迭代每次都有新的內容,
可以進行回圈更新的一個實實在在值,
專業角度:可迭代物件? 內部含有
'__iter__'方法的物件,可迭代物件,目前學過的可迭代物件?str list tuple dict set range 檔案句柄
-
獲取物件的所有方法并且以字串的形式放在串列里
語法:dir()
- 判斷一個物件是否是可迭代物件
- 用dir()獲取所有方法,如果內部含有
'__iter__'方法,就是可迭代物件
- 用dir()獲取所有方法,如果內部含有
#獲取物件的所有方法
# s1 = 'fjdskl'
# print(dir(s1))
l1=[1,2,3]
print(dir(l1))
print('__iter__' in dir(l1)) #列印結果True 就表示可迭代物件
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
True
Process finished with exit code 0
-
小結
-
字面意思:可以進行回圈更新的一個實實在在值,
-
專業角度: 內部含有
'__iter__'方法的物件,可迭代物件, -
判斷一個物件是不是可迭代物件:
'__iter__'in dir(物件) -
str list tuple dict set range
-
優點:
- 存盤的資料直接能顯示,比較直觀,
- 擁有的方法比較多,操作方便,
-
缺點:
-
占用記憶體,
-
不能直接通過for回圈,不能直接取值(索引,key),
-
-
2.迭代器的定義
- 字面意思:更新迭代,器:工具:可更新迭代的工具,
- 專業角度:內部含有
'__iter__'方法并且含有'__next__'方法的物件就是迭代器, - 可以判斷是否是迭代器:
'__iter__'and'__next__'在不在dir(物件)
3.判斷一個物件是否是迭代器
#判斷檔案是否是迭代器
with open('檔案1',encoding='utf-8',mode='w') as f1:
print(('__iter__' in dir(f1)) and ('__next__' in dir(f1)))
s1 = 'fjdag'
print('__next__' in dir(s1))
True
False
Process finished with exit code 0
4.可迭代物件如何轉化成迭代器
`iter([1,2,3])`
#或者
s1.__iter__()
s1 = 'fjdag'
obj=iter(s1)
#s1.__iter__()
print(obj)
print('__next__' in dir(obj))
<str_iterator object at 0x0000029B94D1A278>
True
Process finished with exit code 0
5.迭代器的取值
-
一個next 取一個值
-
多一個next 就會報錯
s1 = 'python'
obj=iter(s1)
print(next(obj))
print(next(obj))
print(next(obj))
print(next(obj))
print(next(obj))
print(next(obj))
p
y
t
h
o
n
Process finished with exit code 0
- 報錯結果
Traceback (most recent call last):
File "D:/PycharmProjects/zixue_python/day_01/12_迭代器.py", line 25, in <module>
print(next(obj))
StopIteration
6.要迭代器有什么用?
- 當資料很大的時候,我要考慮把這些大批量資料存盤起來,需要節省記憶體,所以要考慮迭代器
-
節省記憶體,
-
自己理解如何節省記憶體:比如定義一個串列,那根據記憶體機制,內置中會保存這個串列中所有資料,然后分配記憶體地址(即id)
如果把這個串列轉換為迭代器,這時候next一次,取一個值,然后存盤這個值
-
-
惰性機制,next一次,取一個值,
7.while回圈模擬for回圈機制
l1 = [11,22,33,44,55,66,77,88,99,1111,1133,15652]
# 將可迭代物件轉化成迭代器,
obj = iter(l1)
while 1:
try:
print(next(obj))
except StopIteration:
break
8.可迭代物件與迭代器的對比
- 可迭代物件是一個操作方法比較多,比較直觀,存盤資料相對少(幾百萬個物件,8G記憶體是可以承受的)的一個資料集,
- 當你側重于對于資料可以靈活處理,并且記憶體空間足夠,將資料集設定為可迭代物件是明確的選擇,
- 是一個非常節省記憶體,可以記錄取值位置,可以直接通過回圈+next方法取值,但是不直觀,操作方法比較單一的資料集,
- 當你的資料量過大,大到足以撐爆你的記憶體或者你以節省記憶體為首選因素時,將資料集設定為迭代器是一個不錯的選擇,
day12:
1、生成器(重點)
- 生成器:python社區,生成器與迭代器看成是一種,生成器的本質就是迭代器,唯一的區別:生成器是我們自己用python代碼構建的資料結構,迭代器都是提供的,或者轉化得來的
1.獲取生成器的三種方式:
- 生成器函式,
- 生成器運算式,
- python內置函式或者模塊提供,
- (其實1,3兩種本質上差不多,都是通過函式的形式生成,只不過1是自己寫的生成器函式,3是python提供的生成器函式而已)
2.獲取迭代器的方式:
- python提供的,比如檔案句柄
- 通過 iter 轉化的
3.生成器函式 獲得生成器:
- 將函式中的return換成yield,這樣func就不是函式了,而是一個生成器函式
- 讀取生成器的內容是,一個next 對應一個yield
#函式
# def func():
# print(111)
# print(222)
# return 3
#
# ret=func()
# print(ret)
#生成器
def func():
print(111)
print(222)
yield 3
a=1
b=2
c=a+b
print(c)
yield 4
ret=func()
print(ret)
print(next(ret))
print(next(ret))
#一個next 對應一個yield
<generator object func at 0x000002974F4E60A0>
111
222
3
3
4
Process finished with exit code 0
面試題:return 和 yield 的區別?
- return:函式中只存在一個return結束函式,并且給函式的執行者回傳值,
- yield:只要函式中有yield那么它就是生成器函式而不是函式了,生成器函式中可以存在多個yield,yield不會結束生成器函式,一個yield對應一個next,
練習題:吃包子
- 需求:老男孩向樓下賣包子的老板訂購了5000個包子.包子鋪老板非常實在,一下就全部都做出來了
def func():
l1=[]
for i in range(1,5001):
l1.append(f'{i}號包子')
return l1
ret=func()
print(ret)
- 這樣做沒有問題,但是我們由于學生沒有那么多,只吃了2000個左右,剩下的8000個,就只能占著一定的空間,放在一邊了,如果包子鋪老板效率夠高,我吃一個包子,你做一個包子,那么這就不會占用太多空間存盤了,完美,(用生成器做)
def eat_func():
for i in range(1,5001):
yield f'{i}號包子'
ret=eat_func()
for i in range(200):
print(next(ret))
思考:這兩者的區別:
第一種是直接把包子全部做出來,占用記憶體,
第二種是吃一個生產一個,非常的節省記憶體,而且還可以保留上次的位置,
4.yield from
- 比如我yield 一個串列,我不想回傳一個串列,想回傳串列里的內容,就用yield from,將這個串列變成了迭代器回傳
#yield from
def func():
l1=[1,2,3,4,5]
yield l1
ret=func()
print(next(ret))
#得到的是一個串列
#但是我不希望是一個串列 ----(1)yield from (2)用*解包
#(1)yield from
def func():
l1=[1,2,3,4,5]
yield from l1
#將l1這個串列變成了迭代器回傳
ret=func()
print(next(ret))
# (2)用*解包
def func():
l1=[1,2,3,4,5]
return l1
ret=func()
print(*ret)
[1, 2, 3, 4, 5]
1
1 2 3 4 5
Process finished with exit code 0
2.串列推導式,生成器運算式
-
串列推導式:用一行代碼構建一個比較復雜有規律的串列
-
串列推導式:
- 回圈模式:[變數(加工后的變數) for 變數 in iterable]
- 篩選模式:[變數(加工后的變數) for 變數 in iterable if 條件]
1,串列推導式練習題:
#需求:創建一個有規律的串列,如1-10
#(1).常規方法:
l1=[]
for i in range(1,11):
l1.append(i)
print(l1)
#(2).用串列推導式:
l2=[i for i in range(1,11)]
print(l2)
#用串列推導式(兩種模式)
#1.回圈模式
#需求1:將10以內所有整數的平方寫入串列
l3=[i**2 for i in range(1,11)]
print(l3)
#需求2:將100以內所有偶數寫入串列
l4=[i for i in range(2,101,2) ]
print(l4)
#需求3:從python1期到python100期寫入串列
l5=[f'python{i}期' for i in range(1,101)]
print(l5)
#2.篩選模式 (在回圈模式后面加上 if條件)
#需求1:將100以內所有偶數寫入串列
l6=[i for i in range(1,101) if i%2 == 0]
print(l6)
#需求2:將30以內能被3整取的數寫入串列
l7=[i for i in range(1,31) if i%3 ==0]
print(l7)
#需求3:過濾掉長度小于3的字串串列,并將剩下的轉換成大寫字母
l8 = ['wusir', 'laonanhai', 'aa', 'b', 'taibai']
print([i.upper() for i in l8 if len(i)>3 ])
#需求4:找到嵌套串列中名字含有兩個‘e’的所有名字(有難度)
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
#傳統方法:
l9=[]
for i in names:
for name in i:
if name.count('e')==2:
l9.append(name)
print(l9)
#串列推導式:篩選模式
l10=[name for i in names for name in i if name.count('e')==2]
print(l10)
2,生成器運算式
-
生成器運算式和串列推導式的語法上一模一樣,只是把[]換成()就行了,
比如將十以內所有數的平方放到一個生成器運算式中
l11=(i for i in range(1,11))
print(l11)
print(next(l11))
print(next(l11))
<generator object <genexpr> at 0x00000264FE056048>
1
2
Process finished with exit code 0
- 生成器運算式也可以進行篩選
# 獲取1-100內能被3整除的數
gen = (i for i in range(1,100) if i % 3 == 0)
for num in gen:
print(num)
3.生成器運算式和串列推導式區別:
- 串列推導式比較耗記憶體,所有資料一次性加載到記憶體,而.生成器運算式遵循迭代器協議,逐個產生元素,
- 得到的值不一樣,串列推導式得到的是一個串列.生成器運算式獲取的是一個生成器
- 串列推導式一目了然,生成器運算式只是一個記憶體地址
3,內置函式
- 函式就是以功能為導向,一個函式封裝一個功能,那么Python將一些常用的功能(比如len)給我們封裝成了一個一個的函式,供我們使用
- python 提供了68個內置函式
一帶而過:
all() any() bytes() callable() chr() complex() divmod() eval() exec() format() frozenset() globals() hash() help() id() input() int() iter() locals() next() oct() ord() pow() repr() round()
重點講解:
abs() enumerate() filter() map() max() min() open() range() print() len() list() dict() str() float() reversed() set() sorted() sum() tuple() type() zip() dir()
未來會講:
classmethod() delattr() getattr() hasattr() issubclass() isinstance() object() property() setattr() staticmethod() super()
eval() ---掌握
- 執行字串型別的代碼(外衣),并回傳最終結果
#-----如將字串型別轉化為數字型別
s1='1+3'
print(s1)
print(type(s1))
print(eval(s1))
print(type(eval(s1)))
1+3
<class 'str'>
4
<class 'int'>
Process finished with exit code 0
#-----如將字串型別轉化為字典型別
s2='{"name":"mike"}'
print(s2,type(s2))
print(eval(s2),type(eval(s2)))
{"name":"mike"} <class 'str'>
{'name': 'mike'} <class 'dict'>
Process finished with exit code 0
exec()
- 與eval幾乎一樣 ,執行字串型別的代碼
msg="""
list=[]
for i in range(10):
list.append(i)
print(list)
"""
print(msg)
exec(msg)
#**************************************************************************
list=[]
for i in range(10):
list.append(i)
print(list)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Process finished with exit code 0
hash()
- hash:獲取一個物件(可哈希物件:int,str,Bool,tuple)的哈希值,
- 加密演算法需要哈希值
print(hash('123456'))
4362549678203584146
Process finished with exit code 0
#使用python 進行 MD5加密介面測驗:
import hashlib
password='123456'
obj=hashlib.md5(password.encode())
passwordmd5=obj.hexdigest()
print(passwordmd5)
e10adc3949ba59abbe56e057f20f883e
Process finished with exit code 0
help() ---掌握
- help:函式用于查看函式或模塊用途的詳細說明,
print(help(str.split))
Help on method_descriptor:
split(...)
S.split(sep=None, maxsplit=-1) -> list of strings
Return a list of the words in S, using sep as the
delimiter string. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified or is None, any
whitespace string is a separator and empty strings are
removed from the result.
None
Process finished with exit code 0
callable() ---重點
- callable:函式用于檢查一個物件是否是可呼叫的,如果回傳True,object仍然可能呼叫失敗;但如果回傳False,呼叫物件ojbect絕對不會成功,
s1='12332312'
def func():
pass
print(callable(s1))
print(callable(func))
False
True
Process finished with exit code 0
bytes() ---重點
-
把字串轉換成bytes(位元組)型別
#bytes s1='太白' b=s1.encode('utf-8') print(b) #或者用bytes將字串轉換為位元組 b=bytes(s1,encoding='utf-8') print(b) # 將位元組轉換成字串 c= str(b,encoding='utf-8') print(c) 太白 b'\xe5\xa4\xaa\xe7\x99\xbd' b'\xe5\xa4\xaa\xe7\x99\xbd' Process finished with exit code 0
print() 螢屏輸出
int():pass
str():pass
bool():pass
set(): pass
**list() **
-
將一個可迭代物件轉換成串列
l1='qweqeqweqweqweaaddff' l2=list(l1) print(l2) ['q', 'w', 'e', 'q', 'e', 'q', 'w', 'e', 'q', 'w', 'e', 'q', 'w', 'e', 'a', 'a', 'd', 'd', 'f', 'f'] Process finished with exit code 0
**tuple() **
將一個可迭代物件轉換成元組
tu1 = tuple('abcd')
print(tu1)
# ('a', 'b', 'c', 'd')
**dict() **
-
通過相應的方式創建字典
#dict #創建字典的方式 #1.直接創建 dic=dict([(1,'one'),(2,'two')]) print(dic) #2.元組的解構 dic=dict(one=1,twe=2) print(dic) #3.fromkeys #4.update #5.字典的推導式 {1: 'one', 2: 'two'} {'one': 1, 'twe': 2} Process finished with exit code 0
**abs() **
- 回傳絕對值
i = -5
print(abs(i)) # 5
reversed()與reverse() ---重點
-
**reversed() ** 將一個序列翻轉, 回傳翻轉序列的迭代器 ---
-
reverse() 對原串列進行倒序,翻轉
l1=[i for i in range(10)] print(l1) l1.reverse() # 對原串列進行倒序,翻轉 print(l1) l2=[i for i in range(10)] print(l2) obj=reversed(l2) print(obj) print(next(obj)) print(list(obj)) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] <list_reverseiterator object at 0x000002409D57A1D0> 9 [8, 7, 6, 5, 4, 3, 2, 1, 0] Process finished with exit code 0
zip() 拉鏈方法 ---重點
-
函式用于將可迭代的物件作為引數,將物件中對應的元素打包成一個個元組,然后回傳由這些元祖組成的內容,如果各個迭代器的元素個數不一致,則按照長度最短的回傳
lst1 = [1,2,3] lst2 = ['a','b','c','d'] lst3 = (11,12,13,14,15) obj=zip(lst1,lst2,lst3) print(obj) for i in zip(lst1,lst2,lst3): print(i) <zip object at 0x00000244D015A648> (1, 'a', 11) (2, 'b', 12) (3, 'c', 13) Process finished with exit code 0
以下方法最最要:
min( ),max()
l1=[33,2,1,54,7,-1,-9]
print(min(l1))
#以絕對值的方式取最小值
#(1)第一種方法
l2=[]
def func(a):
return abs(a)
for i in l1:
l2.append(func(i))
print(l2)
print(min(l2))
#(2)第二種方法
l1=[33,2,1,54,7,-1,-9]
#print(min(l1,key=abs))
def abss(a):
return abs(a)
'''
第一次:a = 33 以絕對值取最小值 33
第二次:a = 2 以絕對值取最小值 2
第三次:a = 3 以絕對值取最小值 2
......
第六次:a = -1 以絕對值取最小值 1
'''
print(min(l1,key=abss))
#凡是可以加key的:它會自動的將可迭代物件中的每個元素按照順序傳入key對應的函式中
1
Process finished with exit code 0
練習題:
dic={'a':3,
'b':2,
'c':1}
#求出值最小的鍵值
print(min(dic)) #a min默認會按照字典的鍵去比較大小,
#
# def func(i):
# return dic[i]
# print(min(dic,key=func))
#優化下函式--使用匿名函式
print(min(dic,key=lambda i:dic[i]))
a
c
Process finished with exit code 0
sorted() 排序函式
-
[?s??t?d] sou 太d
-
排序函式, 不是對原串列進行排序,回傳的是一個新串列,默認從低到高
l1=[22,33,1,2,8,7,6,5] l2=sorted(l1) print(l1) print(l2) [22, 33, 1, 2, 8, 7, 6, 5] [1, 2, 5, 6, 7, 8, 22, 33] Process finished with exit code 0l2=[('太白',18),('alex',73),('wu',35),('口天吳',41)] print(sorted(l2)) #想按照成績去排序 print(sorted(l2,key=lambda x:x[1])) #回傳的是一個串列 ,默認從低到高 print(sorted(l2,key=lambda x:x[1],reverse=True)) #設定從高到底 [('alex', 73), ('wu', 35), ('口天吳', 41), ('太白', 18)] [('太白', 18), ('wu', 35), ('口天吳', 41), ('alex', 73)] [('alex', 73), ('口天吳', 41), ('wu', 35), ('太白', 18)] Process finished with exit code 0
filter()
-
篩選過濾(類似于串列推導式的帥選模式) 回傳的是迭代器
-
語法: filter(function,iterable) function: 用來篩選的函式,在filter中會自動的把iterable中的元素傳遞給function,然后根據function回傳的True或者False來判斷是否保留此項資料 iterable:可迭代物件# filter 篩選過濾 l1=[2,3,4,1,6,7,8] #把小于3的元素剔除 #(1)串列推導式篩選 print([i for i in l1 if i>3]) #回傳的是串列 #(2)使用 filter ret=filter(lambda x:x>3,l1) #回傳的是迭代器 print(ret) print(list(ret)) [4, 6, 7, 8] <filter object at 0x00000181997B9828> [4, 6, 7, 8] Process finished with exit code 0
map()
- 會根據提供的函式對指定的序列做映射,(相當于串列推導式的回圈模式)
- 通俗地講就是以引數序列中的每個元素分別呼叫引數中的函式(func()),把每次呼叫后回傳的結果保存到回傳值中
映射函式
語法: map(function,iterable) 可以對可迭代物件中的每一個元素進映射,分別取執行function
>>> def square(x):
>>> return x ** 2
>>> map(square,[1,2,3,4,5])
<map at 0xbd26f28>
>>> list(map(square,[1,2,3,4,5]))
[1, 4, 9, 16, 25]
#map()
#計算串列中每個元素的平方,回傳新串列
lst = [1,2,3,4,5]
#(1)串列推導式的回圈模式
print([i**2 for i in lst])
#(2)map()
ret=map(lambda x:x**2,lst)
print(ret)
print(list(ret))
[1, 4, 9, 16, 25]
<map object at 0x000001DF48669080>
[1, 4, 9, 16, 25]
Process finished with exit code 0
4、匿名函式
語法:
函式名 = lambda 引數:回傳值
fun1=lambda a,b:a+b
- 此函式不是沒有名字,他是有名字的,他的名字就是你給其設定的變數,比如func.
- lambda 是定義匿名函式的關鍵字,相當于函式的def.
- lambda 后面直接加形參,形參加多少都可以,只要用逗號隔開就行,
- 回傳值在冒號之后設定,回傳值和正常的函式一樣,可以是任意資料型別,
- 匿名函式不管多復雜.只能寫一行.且邏輯結束后直接回傳資料
def func(a,b):
return a+b
#構建匿名函式
fun1=lambda a,b:a+b
print(fun1(1,2))
接下來做幾個匿名函式的小題:
寫匿名函式:接收一個可切片的資料,回傳索引為0與2的對應的元素(元組形式),
fun2=lambda a:(a[0],a[2])
print(fun2([22,33,44,55]))
(22, 44)
Process finished with exit code 0
5、閉包
5.1閉包的定義:
-
閉包是嵌套在函式中的函式,
-
閉包必須是內層函式對外層函式的變數(非全域變數)的參考,
閉包的現象:
-
被參考的非全域變數也稱作自由變數,這個自由變數會與內層函式產生一個系結關系,
-
自由變數不會再記憶體中消失,
-
''' 由于閉包這個概念比較難以理解,尤其是初學者來說,相對難以掌握,所以我們通過示例去理解學習閉包, 給大家提個需求,然后用函式去實作:完成一個計算不斷增加的系列值的平均值的需求, 例如:整個歷史中的某個商品的平均收盤價,什么叫平局收盤價呢?就是從這個商品一出現開始,每天記錄當天價格,然后計算他的平均值:平均值要考慮直至目前為止所有的價格, 比如大眾推出了一款新車:小白轎車, 第一天價格為:100000元,平均收盤價:100000元 第二天價格為:110000元,平均收盤價:(100000 + 110000)/2 元 第三天價格為:120000元,平均收盤價:(100000 + 110000 + 120000)/3 元 ........ ''' # 封閉的東西: 保證資料的安全, # 方案一: # l1=[] #全域變數 # def make_averager(new_value): # l1.append(new_value) # total=sum(l1) # average=total/len(l1) # return average # # print(make_averager(100000)) # print(make_averager(110000)) # print(make_averager(120000)) # 方案二: 資料安全,l1不能是全域變數, # def make_averager(new_value): # l1 = [] # l1.append(new_value) # total = sum(l1) # averager = total/len(l1) # return averager # print(make_averager(100000)) # print(make_averager(110000)) # 此方案不行 因為每次執行的時候,l1串列都會重新賦值成空串列[] # 方案三: 閉包 def make_averager(): l1 = [] def averager(new_value): l1.append(new_value) total = sum(l1) averager1 = total/len(l1) return averager1 return averager avg=make_averager() #avg這個變數得到是 averager這個函式名 print(avg(100000)) #相當于執行---averager(100000) print(avg(110000)) #思考:avg=make_averager() 這句代碼執行完,理論上l1這個串列消失了,可是為什么沒有消失? #因為產生了閉包 100000.0 105000.0 Process finished with exit code 0
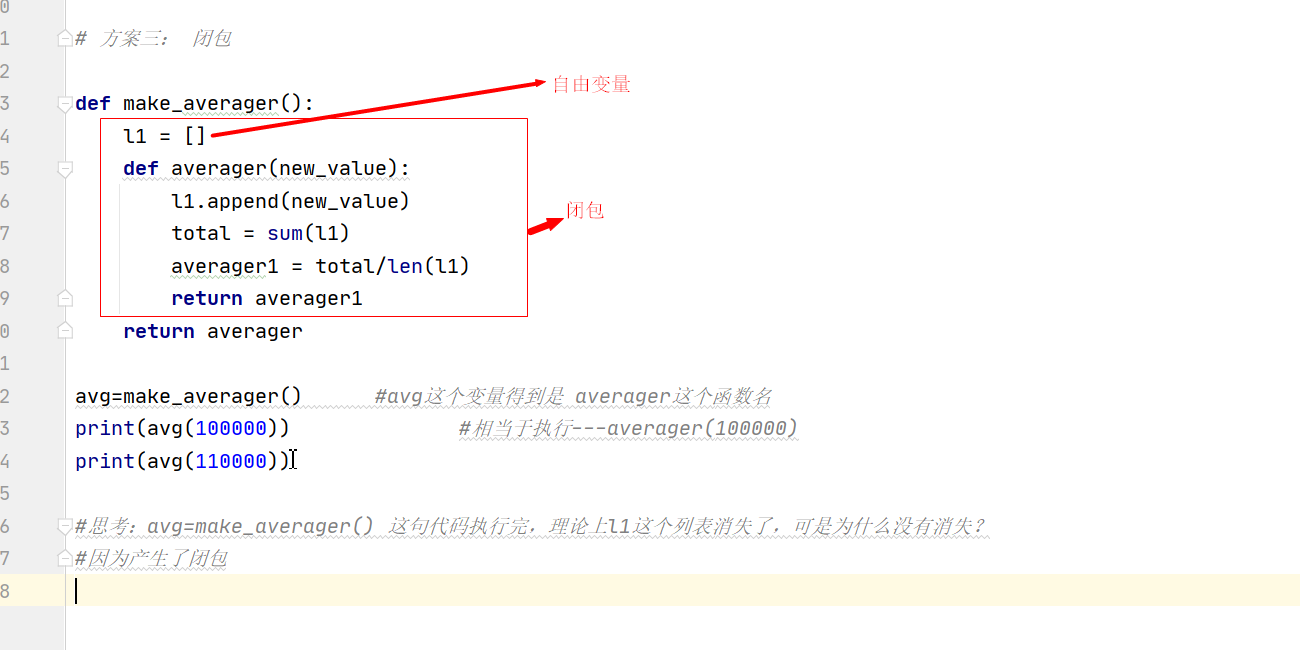
5.2閉包的作用:
- 保存區域資訊不被銷毀,保證資料的安全性
5.3如何判斷一個嵌套函式是不是閉包
- 1,閉包只能存在嵌套函式中
- 2, 內層函式對外層函式非全域變數的參考(使用),就會形成閉包,
# 例一:
def wrapper():
a = 1
def inner():
print(a)
return inner
ret = wrapper()
#例一是閉包
# 例二:
a = 2
def wrapper():
def inner():
print(a)
return inner
ret = wrapper()
#例二不是閉包
# 例三:
def wrapper(a,b):
def inner():
print(a)
print(b)
return inner
a = 2
b = 3
ret = wrapper(a,b)
#也是閉包
5.4如何用代碼判斷閉包?
- 查看這個函式有沒有自由變數就行了
# 函式名.__code__.co_freevars 查看函式的自由變數
print(avg.__code__.co_freevars) # ('series',)
# 函式名.__code__.co_varnames 查看函式的區域變數
print(avg.__code__.co_varnames) # ('new_value', 'total')
# 函式名.__closure__ 獲取具體的自由變數物件,也就是cell物件,
# (<cell at 0x0000020070CB7618: int object at 0x000000005CA08090>,)
# cell_contents 自由變數具體的值
print(avg.__closure__[0].cell_contents) # []
上面例三最難判斷是不是閉包,為了進一步確認,用代碼判斷閉包
# 例三:
def wrapper(a,b):
def inner():
print(a)
print(b)
return inner
a = 2
b = 3
ret = wrapper(a,b)
#如何用代碼判斷閉包?
print(ret.__code__.co_freevars)
('a', 'b')
Process finished with exit code 0
5.5閉包的應用:
- 可以保存一些非全域變數但是不易被銷毀、改變的資料,
- 裝飾器,
5.6閉包面試題怎么問?
- 什么是閉包? 閉包有什么作用,
day14:
1、開放封閉原則:
裝飾器:裝飾,裝修,房子就可以住,如果裝修,不影響你住,而且體驗更加,讓你生活中增加了很多功能:洗澡,看電視,沙發,
器:工具,
開放封閉原則:
開放:對代碼的拓展開放的, 更新地圖,加新槍,等等,
封閉:對原始碼的修改是封閉的,閃躲用q,就是一個功能,一個函式, 別人赤手空拳打你,用機槍掃你,扔雷.....這個功能不會改變,
裝飾器:完全遵循開放封閉原則,
所以裝飾器最終最完美的定義就是: 在不改變原函式的代碼以及呼叫方式的前提下,為其增加新的功能,
裝飾器就是一個函式,(裝飾器就是一個閉包)
2、裝飾器的初識:
-
版本一: Mike 寫一些代碼,測驗一下index()函式的執行效率,
# import time #print(time.time()) # 格林威治時間, def index(): '''有很多代碼.....''' time.sleep(2) # 模擬的網路延遲或者代碼效率 print('歡迎登錄博客園首頁') def dariy(): '''有很多代碼.....''' time.sleep(3) # 模擬的網路延遲或者代碼效率 print('歡迎登錄日記頁面') start_time=time.time() index() end_time=time.time() print(end_time-start_time) start_time=time.time() dariy() end_time=time.time() print(end_time-start_time) 歡迎登錄博客園首頁 2.0008764266967773 歡迎登錄日記頁面 3.0002834796905518 Process finished with exit code 0
版本一的問題:如果測驗別人的代碼,必須重新復制粘貼,
-
版本二:利用函式,解決代碼重復使用的問題(解決版本一問題)
#版本二:利用函式,解決代碼重復使用的問題(解決版本一問題) import time def index(): '''有很多代碼.....''' time.sleep(2) # 模擬的網路延遲或者代碼效率 print('歡迎登錄博客園首頁') def dariy(): '''有很多代碼.....''' time.sleep(3) # 模擬的網路延遲或者代碼效率 print('歡迎登錄日記頁面') def timmer(f): start_time = time.time() f() end_time = time.time() print(f'測驗本函式的執行效率:{end_time-start_time}') timmer(index) #版本二還是有問題: 原來index函式原始碼沒有變化,給原函式添加了一個新的功能測驗原函式的執行效率的功能, #滿足開放封閉原則么?原函式的呼叫方式改變了, 歡迎登錄博客園首頁 測驗本函式的執行效率:2.0008556842803955 Process finished with exit code 0 -
版本三:不能改變原函式的呼叫方式,
#版本三:不能改變原函式的呼叫方式, import time def index(): '''有很多代碼.....''' time.sleep(2) # 模擬的網路延遲或者代碼效率 print('歡迎登錄博客園首頁') def timmer(f): # f = index (funciton index123) def inner(): # inner :(funciton inner123) start_time = time.time() f() #index() (funciton index123) end_time = time.time() print(f'測驗本函式的執行效率:{end_time-start_time}') return inner # (funciton inner123) # ret=timmer(index) # ret() #相當于inner() index=timmer(index) # inner (funciton inner123) index() # inner() -
版本四:具體研究(裝飾器的本質就是閉包)
import time def index(): '''有很多代碼.....''' time.sleep(2) # 模擬的網路延遲或者代碼效率 print('歡迎登錄博客園首頁') def timmer(f): f = index # f = <function index at 0x0000023BA3E8A268> def inner(): start_time = time.time() f() end_time = time.time() print(f'測驗本函式的執行效率{end_time-start_time}') return inner index = timmer(index) index() -
版本五:python做了一個優化;提出了一個語法糖的概念, 標準版的裝飾器
(@timmer #等于index = timmer(index))
#版本五:python做了一個優化;提出了一個語法糖的概念, 標準版的裝飾器 import time #timmer裝飾器 def timmer(f): def inner(): start_time = time.time() f() end_time = time.time() print(f'測驗本函式的執行效率:{end_time-start_time}') return inner @timmer #等于index = timmer(index) def index(): '''有很多代碼.....''' time.sleep(2) # 模擬的網路延遲或者代碼效率 print('歡迎登錄博客園首頁') @timmer def dariy(): '''有很多代碼.....''' time.sleep(3) # 模擬的網路延遲或者代碼效率 print('歡迎登錄日記頁面') # index = timmer(index) # index() # # dariy = timmer(dariy) # dariy() index() dariy() -
版本六:被裝飾函式帶回傳值
#版本六:被裝飾函式帶回傳值 import time #timmer裝飾器 def timmer(f): def inner(): start_time = time.time() r=f() #print(f'這個是f():{f()}!!!') end_time = time.time() print(f'測驗本函式的執行效率:{end_time-start_time}') return r return inner @timmer #等于index = timmer(index) def index(): '''有很多代碼.....''' time.sleep(0.6) # 模擬的網路延遲或者代碼效率 print('歡迎登錄博客園首頁') return 666 # 加上裝飾器不應該改變原函式的回傳值,所以666 應該回傳給我下面的ret, # 但是下面的這個ret實際接收的是inner函式的回傳值,而666回傳給的是裝飾器里面的 # f() 也就是 r,我們現在要解決的問題就是將r給inner的回傳值, ret=index() print(ret) 歡迎登錄博客園首頁 測驗本函式的執行效率:0.6006889343261719 666 Process finished with exit code 0 -
版本七:被裝飾函式帶引數
#版本七:被裝飾函式帶引數 import time #timmer裝飾器 def timmer(f): def inner(*args,**kwargs): # 函式的定義:* 聚合 args = ('李舒淇',18) start_time = time.time() r=f(*args,**kwargs) # 函式的執行:* 打散:f(*args) --> f(*('李舒淇',18)) --> f('李舒淇',18) #print(f'這個是f():{f()}!!!') end_time = time.time() print(f'測驗本函式的執行效率:{end_time-start_time}') return r return inner @timmer def index(name): '''有很多代碼.....''' time.sleep(0.6) # 模擬的網路延遲或者代碼效率 print(f'歡迎{name}登錄博客園首頁') return 666 @timmer def dariy(name,age): '''有很多代碼.....''' time.sleep(0.5) # 模擬的網路延遲或者代碼效率 print(f'歡迎{age}歲{name}登錄日記頁面') dariy('李舒淇',18) # inner('李舒淇',18) index('吳亦凡') #相當于 inner('吳亦凡') 歡迎18歲李舒淇登錄日記頁面 測驗本函式的執行效率:0.5007114410400391 歡迎吳亦凡登錄博客園首頁 測驗本函式的執行效率:0.6006894111633301 Process finished with exit code 0
標準版的裝飾器;
def wrapper(f):
def inner(*args,**kwargs): # 函式的定義:* 聚合 args = ('李舒淇',18)
'''添加額外的功能:執行被裝飾函式之前的操作'''
ret = f(*args,**kwargs) #* 打散:f(*args) --> f(*('李舒淇',18)) --> f('李舒淇',18)
''''添加額外的功能:執行被裝飾函式之后的操作'''
return ret
return inner
3、裝飾器的執行程序(步驟詳解)
- 圖片詳解:
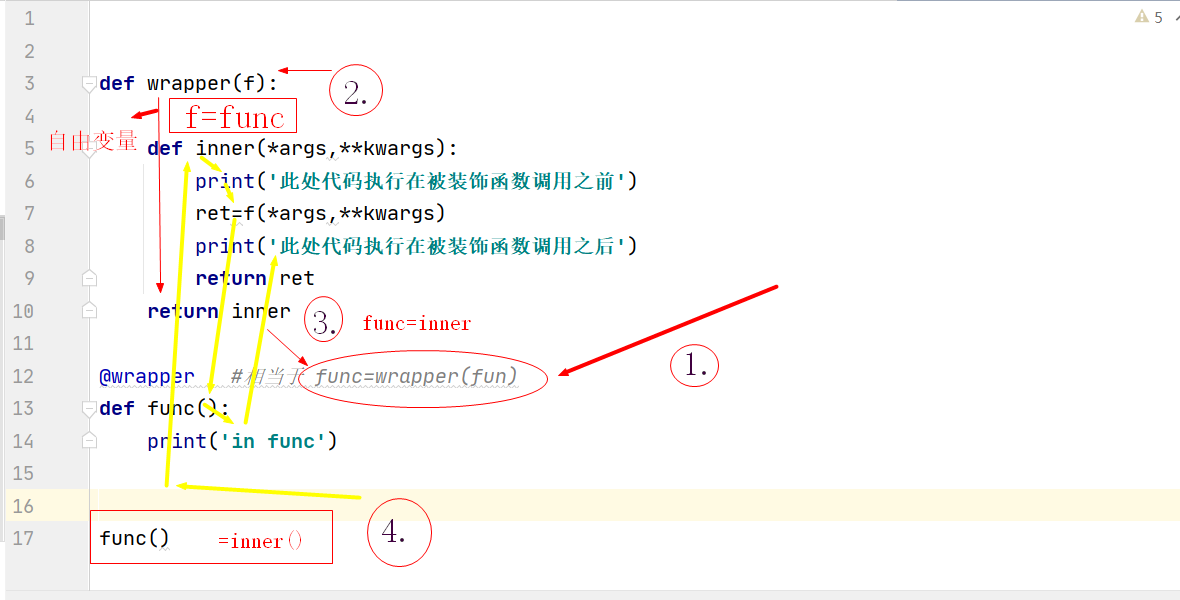
- 文字詳解:
1.第一步執行@wrapper裝飾器,相當于執行 func=wrapper(func);
2.第二步把被裝飾函式的函式名當做引數,帶入到裝飾器引數,即f=func,執行裝飾器;
3.第三步回傳 inner ,即wrapper(fun)的結果是得到 inner 即func=inner ;
4.第三步執行func(),等同于執行inner(),所以會執行裝飾器的的內嵌函式,先執行print('此處代碼執行在被裝飾函式呼叫之前'),然后執行被裝飾函式func(),執行print('in func'),在執行print('此處代碼執行在被裝飾函式呼叫之后'),并且把被裝飾函式的執行結果(print('in func'))回傳給執行者func()
- 具體代碼:
def wrapper(f):
def inner(*args,**kwargs):
print('此處代碼執行在被裝飾函式呼叫之前')
ret=f(*args,**kwargs)
print('此處代碼執行在被裝飾函式呼叫之后')
return ret
return inner
@wrapper #相當于 func=wrapper(fun)
def func():
print('in func')
func()
此處代碼執行在被裝飾函式呼叫之前
in func
此處代碼執行在被裝飾函式呼叫之后
Process finished with exit code 0
4、python 中多個裝飾器的執行順序:
- 裝飾器函式在被裝飾函式定義好后立即執行,多個裝飾器的呼叫順序是自下往上的,
- 被裝飾函式執行時,裝飾器的執行順序是從上往下的,
def wrapper1(f1):
print('in wrapper1')
def inner1(*args,**kwargs):
print('in inner1')
ret = f1(*args,**kwargs)
return ret
return inner1
def wrapper2(f2):
print('in wrapper2')
def inner2(*args,**kwargs):
print('in inner2')
ret = f2(*args,**kwargs)
return ret
return inner2
def wrapper3(f3):
print('in wrapper3')
def inner3(*args,**kwargs):
print('in inner3')
ret = f3(*args,**kwargs)
return ret
return inner3
@wrapper1
@wrapper2
@wrapper3
def func():
print('in func')
func()
# in wrapper3
# in wrapper2
# in wrapper1
# in inner1
# in inner2
# in inner3
# in func
#裝飾器函式在被裝飾函式定義好后立即執行,多個裝飾器的呼叫順序是自下往上的,
# 被裝飾函式執行時,裝飾器的執行順序是從上往下的,
分析:
分析:
func = wrapper3(func) ---> 先列印'in wrapper3', func = inner3 ,f3 = func
func = wrapper2(func) --->即 inner3 = wrapper2(inner3) ---> 先列印'in wrapper2', inner3 = inner2 ,f2 = inner3 --> func = inner2
func = wrapper1(func) --->即 inner2 = wrapper1(inner2) --->先列印'in wrapper1', inner2 = inner1 ,f1 = inner2 --> func = inner1
執行 func() 即執行執行 inner1() ,先列印 'in inner1',再執行 f1(),即執行inner2()
即執行inner2() ,先列印 'in inner2',再執行 f2(),即執行inner3()
即執行inner3() ,先列印 'in inner3',再執行 f3(),即執行func(),列印 'in func '
5、裝飾器的應用
# 裝飾器的應用:登錄認證
# 這周的周末作業:模擬博客園登錄的作業,裝飾器的認證功能,
- 基本框架
def login():
pass
def register():
pass
status_dict={
'username':None,
'status':False
}
def auth(f):
'''
你的裝飾器完成:訪問被裝飾函式之前,寫一個三次登錄認證的功能,
登錄成功:讓其訪問被裝飾得函式,登錄沒有成功,不讓訪問,
:param f:
:return:
'''
def inner(*args,**kwargs):
'''訪問函式之前的操作,功能'''
ret = f(*args,**kwargs)
'''訪問函式之后的操作,功能'''
return ret
return inner
def article():
print('歡迎訪問文章頁面')
def comment():
print('歡迎訪問評論頁面')
def dariy():
print('歡迎訪問日記頁面')
article()
comment()
dariy()
def login():
dic = {}
username = input('請輸入用戶名').strip()
password = input('請輸入密碼').strip()
if username in register() and password == register()[username]:
dic[username] = password
print('登錄成功')
else:
print('用戶名或者密碼錯誤')
return dic
def register():
dic_1 = {}
with open('a',encoding='utf-8') as f:
for line in f:
a,b = line.strip().split()
dic_1[a] = b
return dic_1
status_dict = {'username':None,'status':False}
def auth(f):
def inner(*args,**kwargs):
if status_dict['status']:
ret = f(*args,**kwargs)
return ret
else:
status_dict['username'] = login()
status_dict['status'] = True
ret = f(*args, **kwargs)
return ret
return inner
day:15
1、自定義模塊:
什么是模塊:本質就是.py檔案,封裝陳述句的最小單位,
- 多個模塊對應包,在代碼中包就是一個檔案夾
自定義模塊:實際上就是定義.py,其中可以包含:變數定義,可執行陳述句,for回圈,函式定義等等,他們統稱模塊的成員,
2、模塊的運行方式:
-
腳本方式:直接用解釋器執行,或者PyCharm中右鍵運行,
-
模塊方式:被其他的模塊匯入,為匯入它的模塊提供資源(變數,函式定義,類定義等),
''' 測驗自定義模塊的匯入 ''' #自定義模塊被其他模塊匯入時,其中的可執行陳述句會路基執行 import a [2, 11, 15, 7] Process finished with exit code 0 #******************************************************* #a.py nums=[2,11,15,7] def fun(nums): print(nums) fun(nums)
思考:自定義模塊被其他模塊匯入時,其中的可執行陳述句會路基執行,如何控制可執行陳述句不執行?
-----python中提供一種可以判斷自定義模塊是屬于開發階段還是使用階段:
? __name__
就是通過 if __name__ == '__main__': 來實作
把可執行陳述句放在主函式main中執行,
自定義模塊在右鍵運行時,print(__name__) 的屬性值 __main__,但是在以模塊方式被匯入時,在其他腳本中右鍵運行,print(__name__) 的屬性值就是模塊名了 如a ,
所以通過if __name__ == '__main__': 可以控制被呼叫的模塊中的可執行陳述句不被執行,
3、__name__屬性的使用:
- 在腳本方式運行時(右鍵執行),
__name__是固定的字串:__main__
nums=[2,11,15,7]
def fun(nums):
print(nums)
fun(nums)
print(__name__)
[2, 11, 15, 7]
__main__
Process finished with exit code 0
- 在以模塊方式被匯入時,
__name__就是本模塊的名字, - 在自定義模塊中對
__name__進行判斷,決定是否執行可執行陳述句:開發階段,就執行,使用階段就不執行,
#開發階段--會執行
nums=[2,11,15,7]
def fun(nums):
print(nums)
#__name__
if __name__ == '__main__':
fun(nums)
[2, 11, 15, 7]
Process finished with exit code 0
#**********************************************************
#使用階段(呼叫階段)---不執行
import a
#右鍵執行
Process finished with exit code 0
4、系統匯入模塊的路徑
- 記憶體中:如果之前成功匯入過某個模塊,直接使用已經存在的模塊
- 內置路徑中:安裝路徑下:Lib
- PYTHONPATH:import時尋找模塊的路徑,
- sys.path:是一個路徑的串列,
如果上面都找不到,就報錯,
通過動態修改sys.path的方式將自定義模塊添加到sys.path中,
os.path.dirname():獲取某個路徑的父路徑,通常用于獲取當前模塊的相對路徑
#使用相對路徑找到aa檔案夾
#print(__file__) #當前檔案的絕對路徑
#使用os模塊獲取一個路徑的父路徑
#os.path.dirname()
#添加 a.py所在的路徑到 sys.path 中
#sys.path.append()
import sys
import os
sys.path.append(os.path.dirname(__file__) + '/aa')
5、匯入模塊的多種方式:
- import xxx:匯入一個模塊的所有成員
- import aaa,bbb:一次性匯入多個模塊的成員,不推薦這種寫法,分開寫,
- from xxx import a:從某個模塊中匯入指定的成員,
- from xxx import a,b,c:從某個模塊中匯入多個成員,
- from xxx import *:從模塊中匯入所有成員,
5.1、import xxx 和 from xxx import * 的區別:
第一種方式在使用其中成員時,必須使用模塊名作為前綴,不容易產生命名沖突,
第二種方式在使用其中成員時,不用使用模塊名作為前綴,直接使用成員名即可,但是容易產生命名沖突,在后定義的成員生效(把前面的覆寫了,)
5.2、怎么解決名稱沖突的問題?
- 改用import xxx這種方式匯入,
- 自己避免使用同名
- 使用別名解決沖突
5.3、使用別名:alias
給成員起別名,避免名稱沖突,
from my_module import age as a
給模塊起別名,目的簡化書寫,
import my_module as m
5.4、from xxx import * 控制成員被匯入
默認情況下,所有的成員都會被匯入,
__all__是一個串列,用于表示本模塊可以被外界使用的成員,元素是成員名的字串,
注意:
__all__只是對from xxx import *這種匯入方式生效,其余的方式都不生效,
5.5、相對匯入
針對某個專案中的不同模塊之間進行匯入,稱為相對匯入,
只有一種格式:
from 相對路徑 import xxx
相對路徑:包含了點號的一個相對路徑,
. 表示的是當前的路徑,
..表示的是父路徑,
...表示的是父路徑的父路徑,
# 相對匯入同專案下的模塊
# from ..z import zz # 容易向外界暴露zz模塊
from ..z.zz import *
# 不使用相對匯入的方式,匯入本專案中的模塊
# 通過當前檔案的路徑找到z的路徑
import os
import sys
sys.path.append(os.path.dirname(os.path.dirname(__file__)) + '/z')
from zz import *
6、內置模塊
random
此模塊提供了和亂數獲取相關的方法:
- random.random():獲取 [0.0,1.0) 范圍內的浮點數
- random.randint(a,b):獲取 [a,b] 范圍內的一個整數
- random.uniform(a,b):獲取 [a,b) 范圍內的浮點數
- random.shuffle(x):把引數指定的資料中的元素打亂,引數必須是一個可變的資料型別,
- random.sample(x,k):從x中隨機抽取k個資料,組成一個串列回傳,
import random
#random.random():獲取 **[0.0,1.0)** 范圍內的浮點數
l1=random.random()
print(l1)
#random.uniform(a,b):獲取 **[a,b)** 范圍內的浮點數
l2=random.uniform(3,5)
print(l2)
#random.randint(a,b):獲取 **[a,b]** 范圍內的一個整數
l3=random.randint(1,3)
print(l3)
#random.shuffle(x):把引數指定的資料中的元素打亂,引數必須是一個可變的資料型別,
l4=list(range(10))
print(l4)
random.shuffle(l4)
print(l4)
#random.sample(x,k):從x中隨機抽取k個資料,組成一個串列回傳
l5=(1,2,3)
l6=random.sample(l5,2)
print(l6)
0.41410924095974666
4.725643623367955
2
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[5, 4, 2, 6, 7, 8, 1, 0, 3, 9]
[1, 3]
Process finished with exit code 0
time:和時間相關
封裝了獲取時間戳和字串形式的時間的一些方法,
- time.time():獲取時間戳
- time.gmtime([seconds]):獲取格式化時間物件:是九個欄位組成的
- time.localtime([seconds]):獲取格式化時間物件:是九個欄位組成的
- time.mktime(t):時間物件 -> 時間戳
- time.strftime(format[,t]):把時間物件格式化成字串
- time.strptime(str,format):把時間字串轉換成時間物件
import time
#(1)獲取時間戳 #時間戳:從時間元年(1970 1 1 00:00:00)到現在經過的秒數,
l1=time.time()
print(l1)
#(2)獲取格式化時間物件:是九個欄位組成的,
print(time.gmtime()) #GMT
print(time.localtime())
# 默認引數是當前系統時間的時間戳,
print(time.gmtime(1)) # 時間元年過一秒后,對應的時間物件
#(3)格式化時間物件 轉換為 字串
s=time.strftime("year:%Y %m %d %H:%M:%S")
print(s)
#(4)把時間字串 轉換成 時間物件
time_obj = time.strptime('2010 10 10','%Y %m %d')
print(time_obj)
#(5)時間物件 -> 時間戳
t1 = time.localtime() # 時間物件
t2 = time.mktime(t1) # 獲取對應的時間戳
print(t2)
print(time.time())
1663252449.9508088
time.struct_time(tm_year=2022, tm_mon=9, tm_mday=15, tm_hour=14, tm_min=34, tm_sec=9, tm_wday=3, tm_yday=258, tm_isdst=0)
time.struct_time(tm_year=2022, tm_mon=9, tm_mday=15, tm_hour=22, tm_min=34, tm_sec=9, tm_wday=3, tm_yday=258, tm_isdst=0)
time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=1, tm_wday=3, tm_yday=1, tm_isdst=0)
year:2022 09 15 22:34:09
time.struct_time(tm_year=2010, tm_mon=10, tm_mday=10, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=283, tm_isdst=-1)
1663252859.0
1663252859.9694235
Process finished with exit code 0
time模塊三大物件之間的轉換關系:

其他方法:
- time.sleep(x):休眠x秒.
datetime:日期時間相關
封裝了一些和日期,時間相關的類,主要有:
- date: 需要年,月,日三個引數
- time: 需要時,分,秒三個引數
- datetime: 需要年,月,日,時,分,秒六個引數.
- timedelta: 需要一個時間段.可以是天,秒,微秒
獲取以上型別的物件,主要作用是和時間段進行數學運算.
timedelta可以和以下三個類進行數學運算:
- datetime.time,datetime.datetime,datetime.timedelta
import datetime
#(1):date類: 需要年,月,日三個引數
d=datetime.date(2010,10,10) #把年月日三個引數轉換成一個物件
print(d)
#獲取date物件的各個屬性
print(d.year)
print(d.month)
print(d.day)
#(2):time類: 需要時,分,秒三個引數
t=datetime.time(10,58,59)
print(t)
#獲取time物件的各個屬性
print(t.hour)
print(t.minute)
print(t.second)
#(3):datetime 類: 需要年,月,日,時,分,秒六個引數.
dt=datetime.datetime(2022,9,15,23,58,59)
print(dt)
#獲取datetime物件的各個屬性
#(4):timedelta類: 理解:時間的變化量 需要一個時間段.可以是天,秒,微秒
td=datetime.timedelta(days=1)
print(td)
#參與數學運算
#創建時間物件:
l1=datetime.date(2010,10,10)
res=l1+td
print(res)
2010-10-10
2010
10
10
10:58:59
10
58
59
2022-09-15 23:58:59
1 day, 0:00:00
2010-10-11
Process finished with exit code 0
練習:
- 顯示當前日期前三天是什么時間.
#練習:顯示當前日期前三天是什么時間.
year=int(input("輸入年份:"))
month=int(input("輸入年份:"))
day=int(input("輸入年份:"))
#創建指定年月日的date物件
d=datetime.date(year,month,day)
# 創建三天 的時間段
td = datetime.timedelta(days=3)
res = d - td
print(res)
輸入年份:2020
輸入年份:10
輸入年份:4
2020-10-01
Process finished with exit code 0
- 顯示任意一年的二月份有多少天.
#練習:計算某一年的二月份有多少天?
# 普通演算法:根據年份計算是否是閏年.是:29天,否:28
# 用datetime模塊. # 首先創建出指定年份的3月1號.然后讓它往前走一天.
year=int(input("輸入年份:"))
# 創建指定年份的date物件
d=datetime.date(year,3,1)
# 創建一天 的時間段
td = datetime.timedelta(days=1)
res = d - td
print(res.day)
輸入年份:2014
28
Process finished with exit code 0
os:作業系統介面
此模塊提供了靈活的和作業系統相關的函式.
1、洗掉:
- os.remove(file_path) : 洗掉檔案
- os.rmdir(dir_path) : 洗掉空檔案夾
- 洗掉非空檔案夾使用另一個模塊 : shutil
- shutil.rmtree(path)
- os.removedirs(name) : 遞回洗掉空檔案夾,先洗掉最里面的目錄 然后繼續洗掉父級
2、重命名
- os.rename(src, dst) : 檔案,目錄重命名,目標不能事先存在.
#os:作業系統介面
import os
#和檔案操作相關(重命名,洗掉等)
#洗掉
#os.remove(r'a.txt')
#洗掉目錄,必須時空目錄
#os.removedirs('aa') #OSError: [WinError 145] 目錄不是空的,: 'aa'
#使用shutil模塊可以洗掉待內容的目錄
import shutil
shutil.rmtree('aa')
#重命名
#os.rename('a.txt','b.txt')
3、和路徑相關的屬性,更多相關的操作被封裝在os.path這個模塊中.
- os.curdir : 當前路徑
- os.sep : 路徑分隔符
- os.altsep : 備用的分隔符
- os.extsep : 擴展名分隔符
- os.pathsep : 路徑分隔符
- os.linesep : 行分隔符,不要在寫檔案的時候,使用這個屬性
os.path 模塊
此模塊實作了一些在路徑操作上的方法.
-
os.path.dirname(path) : 回傳一個路徑中的父目錄部分
如果只是一個盤符,或者是以路徑分隔符結尾的字串,則整體回傳.
否則回傳的是路徑中的父目錄部分.
樣例:
import os
print(os.path.dirname('.')) #
print(os.path.dirname('/aa/')) # /aa
print(os.path.dirname('D:/test')) # D:/
print(os.path.dirname('D:/')) # D:/
-
os.path.basename(path) : 回傳path指定的路徑的最后一個內容.
如果只是一個盤符,或者是以路徑分隔符結尾的字串,則回傳空;
否則回傳的是路徑中的最后一部分內容.
樣例:
import os print(os.path.basename('.')) # .
print(os.path.basename('/aa')) # aa
print(os.path.basename('/aa/')) #
print(os.path.basename('D:/test')) # test
-
os.path.split(path) : 把路徑中的路徑名和檔案名切分開 ,結果是元祖
回傳一個元組,第二個元素表示的是最后一部分的內容,第一個元素表示的是剩余的內容.
如果只是一個盤符或者是以路徑分隔符結尾的字串,則第二個元素為空.
否則第二個元素就是最后一部分的內容.
如果path中不包含路徑分隔符,則第一個元素為空.
樣例:
import os
print(os.path.split('D:/')) # ('D:/', '')
print(os.path.split('.')) # ('', '.')
print(os.path.split('/aa')) # ('/', 'aa')
-
os.path.join(path,*paths) : 連接若干個路徑為一個路徑.
如果路徑中有絕對路徑,則在這個路徑之前的路徑都會被丟棄,而從這個路徑開始往后拼接.
Windows中盤符一定要帶,否則不認為是一個盤符.
樣例:
res = os.path.join('aa','bb','cc')
print(res) # aa\bb\cc
res2 = os.path.join('D:/','test')
print(res2) # D:/test
-
os.path.abspath(path) :回傳一個路徑的絕對路徑.
如果引數路徑是相對的路徑,就把當前路徑和引數路徑的組合字串當成結果回傳.
如果引數路徑已經是絕對路徑,就直接把引數回傳.
如果引數路徑以/開始,則把當前盤符和引數路徑連接起來組成字串回傳.
注意:
此方法只是簡單的將一個拼接好的字串回傳,并不會去檢查這個字串表示的檔案是否存在.
樣例:
import os
print(os.path.abspath('aa')) # D:\PycharmProjects\test03\test01\aa
print(os.path.abspath('D:/test/aa')) # D:\test\aa
print(os.path.abspath('/bb')) # D:\bb
判斷功能
os.path.exists(path) : 判斷路徑是否真正存在.
os.path.isabs(path) : 判斷是否是絕對路徑
os.path.isfile(path) : 判斷是否是檔案
os.path.isdir(path) : 判斷是否是目錄
sys:和python解釋器相關
提供了解釋器使用和維護的變數和函式.
-
sys.argv :當以腳本方式執行程式時,從命令列獲取引數.
argv[0]表示的是當前正在執行的腳本名.argv[1]表示第一個引數,以此類推.
樣例:
有腳本 test.py 內容如下:
import sys print('腳本名稱:',sys.argv[0])
print('第一個引數是:',sys.argv[1])
print('第二個引數是:',sys.argv[2])
使用命令列方式運行該腳本: python test.py hello world

解釋器去尋找模塊的路徑
-
sys.path :系統尋找模塊的路徑.可以通過PYTHONPATH來進行初始化.
由于是在程式執行的時候進行初始化的,所以,路徑的第一項path[0]始終是呼叫解釋器的腳本所在的路徑.如果
是動態呼叫的腳本,或者是從標準輸入讀取到腳本命令,則path[0]是一個空字串.程式中可以隨時對這個路徑
進行修改.以達到動態添加模塊路徑的目的.
json模塊
JSON : JavaScript Object Notation ------Java腳本物件標記語言.
已經成為一種簡單的資料交換格式.
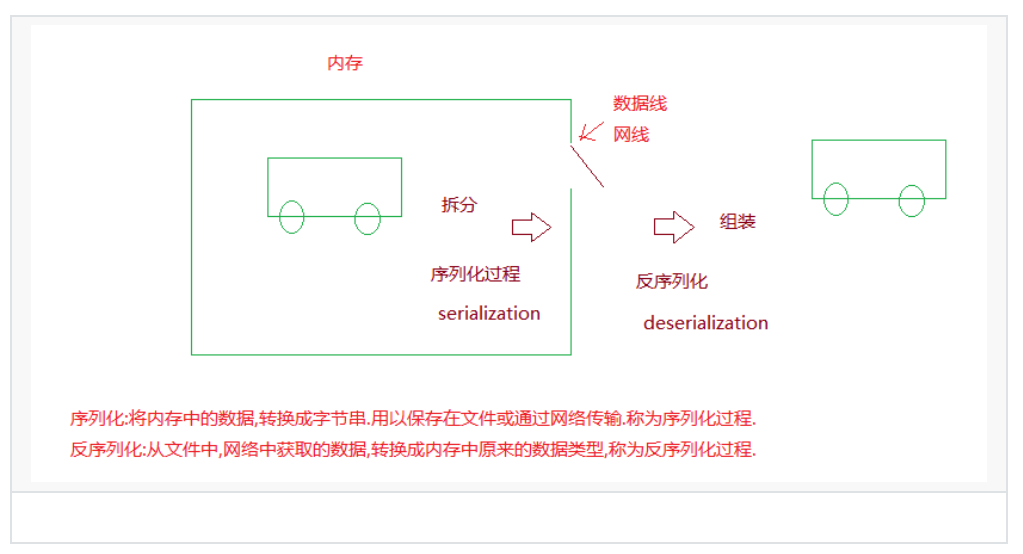
序列化和反序列化
序列化 : 將其他資料格式轉換成json字串的程序.
反序列化 : 將json字串轉換其他資料型別的程序.

涉及到的方法:
-
json.dumps(obj) : 將obj轉換成json字串回傳到記憶體中. (dumps是從記憶體到記憶體)
-
json.dump(obj,fp) : 將obj轉換成json字串并保存在fp指向的檔案中.
-
json.loads(s) : 將記憶體中的json字串轉換成對應的資料型別物件
-
json.load(f) : 從檔案中讀取json字串,并轉換回原來的資料型別.
注意:
-
json并不能序列化所有的資料型別:例如:set.
-
元組資料型別經過json序列化后,變成串列資料型別.
-
json檔案通常是一次性寫入,一次性讀取.但是可以利用檔案本身的方式實作:一行存盤一個序列化json字串,在反序列化時,按行反序列化即可.
記憶體中的資料:結構化的資料:
磁盤上的資料:線性資料:

序列化比喻:
以下是Python中的可以被序列化的資料型別:
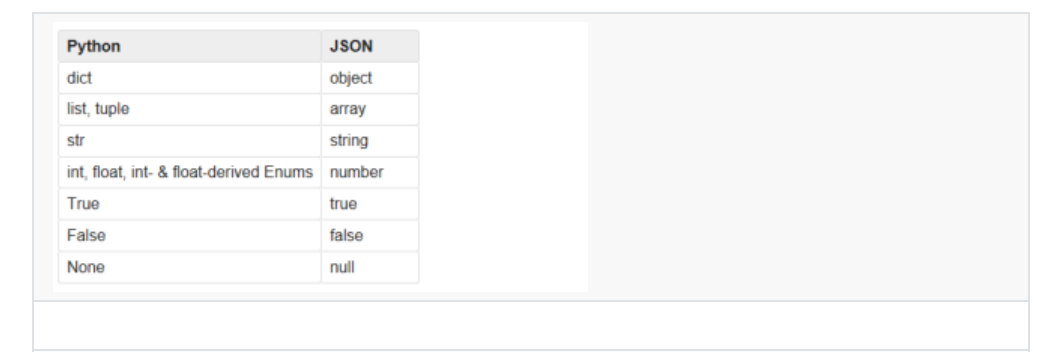
補充:寫入檔案必須要字串
#t---text
#b---binary 位元組
#a---append 追加寫
#w---write 覆寫寫
#r---read
#默認是 rt
#寫入檔案必須要字串
with open('a.txt',mode='wt',encoding='utf-8')as f :
f.write(10)
TypeError: write() argument must be str, not int
Process finished with exit code 1
序列化案例:
1、考察 json.dumps
import json
s=json.dumps([1,2,3]) #把指定的物件轉換成json格式的字串,并保存在記憶體中
print(type(s))
print(s)
s2=json.dumps((1,2,3)) #元祖序列化后變成串列
print(type(s2))
print(s2)
s3=json.dumps(10)
print(type(s3))
print(s3)
s4=json.dumps({'name':'andy','age':10})
print(type(s4))
print(s4)
<class 'str'>
[1, 2, 3]
<class 'str'>
[1, 2, 3]
<class 'str'>
10
<class 'str'>
{"name": "andy", "age": 10}
Process finished with exit code 0
2、考察 json.dump-----將json 結果寫入檔案中
#將json 結果寫入檔案中
with open('a.txt',mode='at',encoding='utf-8')as f:
json.dump([1,2,3],f)
反序列化案例:
3、考察json.loads
#反序列化
s1=json.dumps([1,2,3])
s2=json.loads(s1)
print(type(s2))
print(s2)
<class 'list'>
[1, 2, 3]
Process finished with exit code 0
4、考察 json.load
#如何從檔案中反序列化
with open('a.txt',encoding='utf-8')as f:
res=json.load(f)
print(type(res))
print(res)
<class 'list'>
[1, 2, 3]
Process finished with exit code 0
pickle 序列化
python專用的序列化模塊. (屁寇)
pickle:
將python中所有的資料型別,轉化成位元組串 序列化程序
將位元組串,轉化成python中的資料型別 反序列化程序
pickle模塊中的方法基本和json模塊中的方法一樣.只是適用的資料型別范圍比json更廣泛.
-
將其他資料型別序列化成位元組
-
將位元組反序列化成其他資料型別
-
將其他資料型別序列化成位元組并寫入檔案
-
從檔案中讀取位元組并反序列化成其他資料型別
區別在于:
json:
1.不是所有的資料型別都可以序列化.結果是字串.
2.不能多次對同一個檔案序列化.
3.json資料可以跨語言
pickle:
1.所有python型別都能序列化,結果是位元組串.
2.可以多次對同一個檔案序列化
3.不能跨語言.
案例:
1.在記憶體中序列化和反序列化
import pickle
#序列化串列型別
bys=pickle.dumps([1,2,3])
print(type(bys)) #<class 'bytes'>
print(bys) #b'\x80\x03]q\x00(K\x01K\x02K\x03e.'
#序列化元祖型別
s1=pickle.dumps((1,2,3))
print(s1) #b'\x80\x03K\x01K\x02K\x03\x87q\x00.'
#反序列化后,保存了元祖的資料型別 (json不行,json反序列化元祖后,型別是串列)
res=pickle.loads(s1)
print(type(res)) #<class 'tuple'>
#序列化集合型別
s2=pickle.dumps(set('abc'))
res=pickle.loads(s2)
print(type(res)) #<class 'set'>
2、在檔案中序列化和反序列化
#把pickle 序列化內容寫入檔案中
with open('c.txt',mode='wb')as f:
pickle.dump([1,2,3,4],f)
#從檔案中反序列化pickle資料
with open('c.txt',mode='rb')as f:
q=pickle.load(f)
print(type(q))
print(q)
<class 'list'>
[1, 2, 3, 4]
Process finished with exit code 0
**hashlib: **加密模塊
封裝一些用于加密的類.
md5()等
import hashlib
print(dir(hashlib))
['md5', 'new', 'pbkdf2_hmac', 'sha1', 'sha224', 'sha256', 'sha384', 'sha3_224', 'sha3_256', 'sha3_384', 'sha3_512', 'sha512', 'shake_128', 'shake_256']
加密的目的:用于判斷和驗證,而并非解密.
特點:
- 把一個大的資料,切分成不同塊,分別對不同的塊進行加密,再匯總的結果,和直接對整體資料加密的結果是一致的.
- 單向加密,不可逆.
- 原始資料的一點小的變化,將導致結果的非常大的差異,'雪崩'效應.
使用摘要演算法加密一個資料的三大步驟:
-
獲取一個加密演算法物件.
-
呼叫加密物件的update方法給指定的資料加密.
-
呼叫加密物件的digest或者是hexdigest獲取加密后的結果.
樣例:
import hashlib
#獲取一個加密物件
m=hashlib.md5()
#使用加密物件的update,進行加密
m.update('abc中文'.encode('utf-8')) # 對引數進行加密,引數必須是位元組型別
#或 m.update(b'abc')
# 通過hexdigest獲取加密后的字串
res=m.hexdigest()
print(res)
# 位元組形式的結果
print(m.digest())
1af98e0571f7a24468a85f91b908d335
b'\x1a\xf9\x8e\x05q\xf7\xa2Dh\xa8_\x91\xb9\x08\xd35'
Process finished with exit code 0
簡化寫法
加密物件的update方法可以呼叫多次,意味著在在前一次的update結果之上,再次進行加密.如果只是一次更新的話,
還可以直接把資料當成引數傳遞給構造方法.
例如:
m = md5()
m.update(data)
res = m.hexdigest()
和下面的陳述句是等價的:
res = md5(data).hexdigest()
這種在創建加密物件的時候,就指定初始化的資料,稱為 salt (鹽).
目的就是為了讓加密的結果更加復雜.
練習:
需求:
把用戶名和密碼資訊加密后,通過序列化的方式存盤到本地檔案中.
并通過控制臺輸入資訊進行驗證.
import hashlib
#注冊,登錄程式:
#加密方法
def get_md5(username,password):
m=hashlib.md5()
m.update(username.encode('utf-8'))
m.update(password.encode('utf-8'))
return m.hexdigest()
#注冊方法
def register(username,password):
#加密
res=get_md5(username,password)
#寫入檔案
with open('login',mode='at',encoding='utf-8') as f :
f.write(res)
f.write('\n')
#登錄方法:
def login(username,password):
# 獲取當前登錄資訊的加密結果
res = get_md5(username, password)
# 讀檔案,和其中的資料進行對比
with open('login', mode='rt', encoding='utf-8') as f:
for line in f:
if res == line.strip():
return True
else:
return False
while True:
op = int(input("1.注冊 2.登錄 3.退出 ----請輸入:"))
if op == 3:
break
elif op == 1 :
username=input("請輸入用戶名:")
password=input("請輸入密碼:")
register(username,password)
elif op == 2 :
username=input("請輸入用戶名:")
password=input("請輸入密碼:")
res=login(username,password)
if res:
print('登錄成功')
else:
print('登錄失敗')
day20:
1、遞回函式
- 遞回函式:在一個函式里在呼叫這個函式本身
- 遞回的最大深度:998
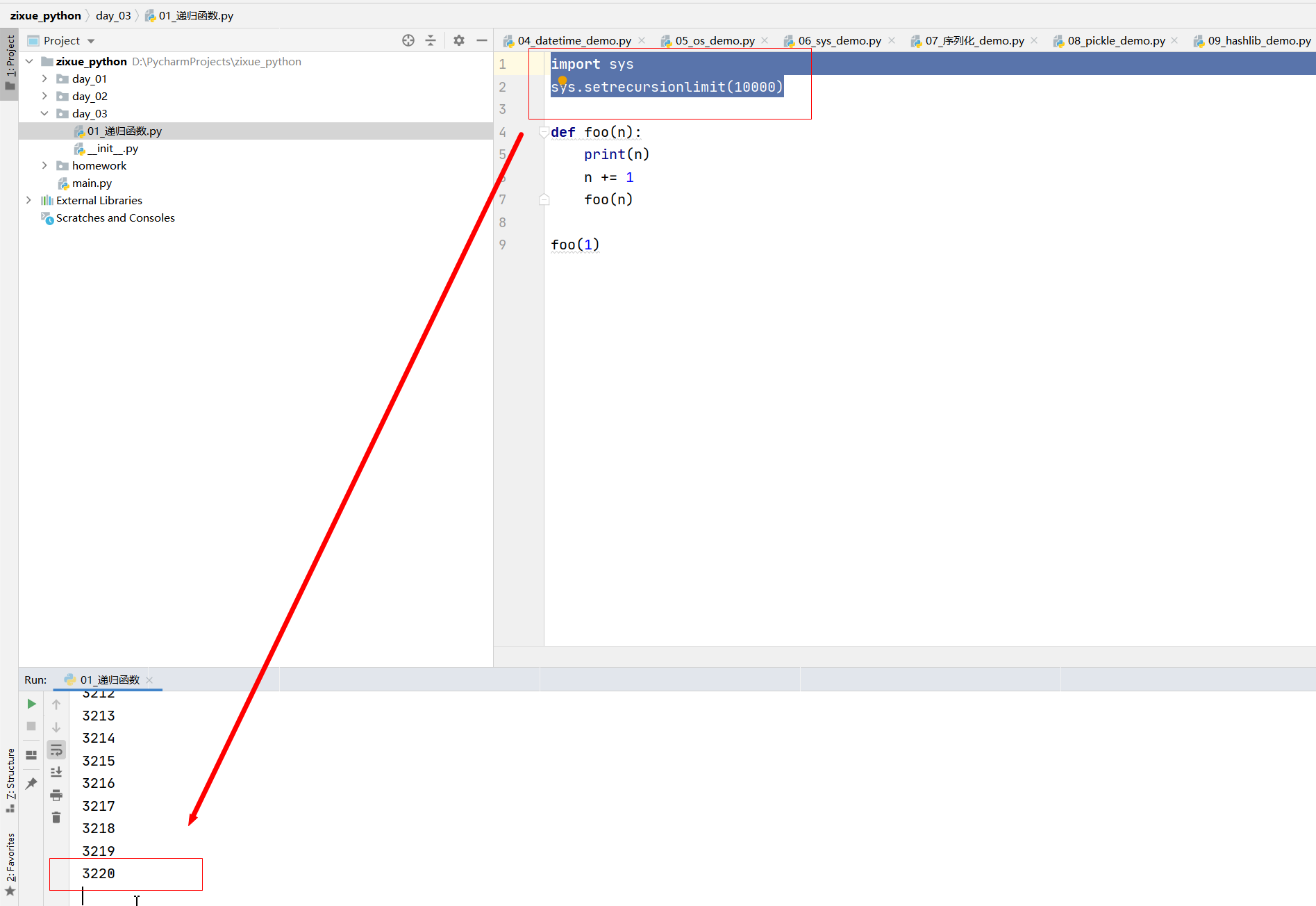
def foo(n):
print(n)
n += 1
foo(n)
foo(1)
998Traceback (most recent call last):

面試題:可以修改遞回函式的最大深度嗎?--可以
import sys
sys.setrecursionlimit(10000)
看電腦性能,最大深度
1.1、遞回示例講解
例一:
現在你們問我,alex老師多大了?我說我不告訴你,但alex比 egon 大兩歲,
你想知道alex多大,你是不是還得去問egon?egon說,我也不告訴你,但我比武sir大兩歲,
你又問武sir,武sir也不告訴你,他說他比太白大兩歲,
那你問太白,太白告訴你,他18了,
這個時候你是不是就知道了?alex多大?
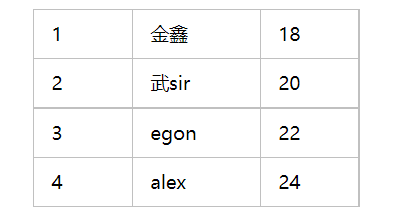
def age(n):
if n == 1:
return 18
else:
return age(n-1)+2
print(age(4))
24
Process finished with exit code 0
day:22 面向物件
一:創建\呼叫類和類實體化
1.類名()----會自動呼叫類中的 init 方法
2.類中直接寫個列印陳述句,不用實體化類物件,直接運行可以列印
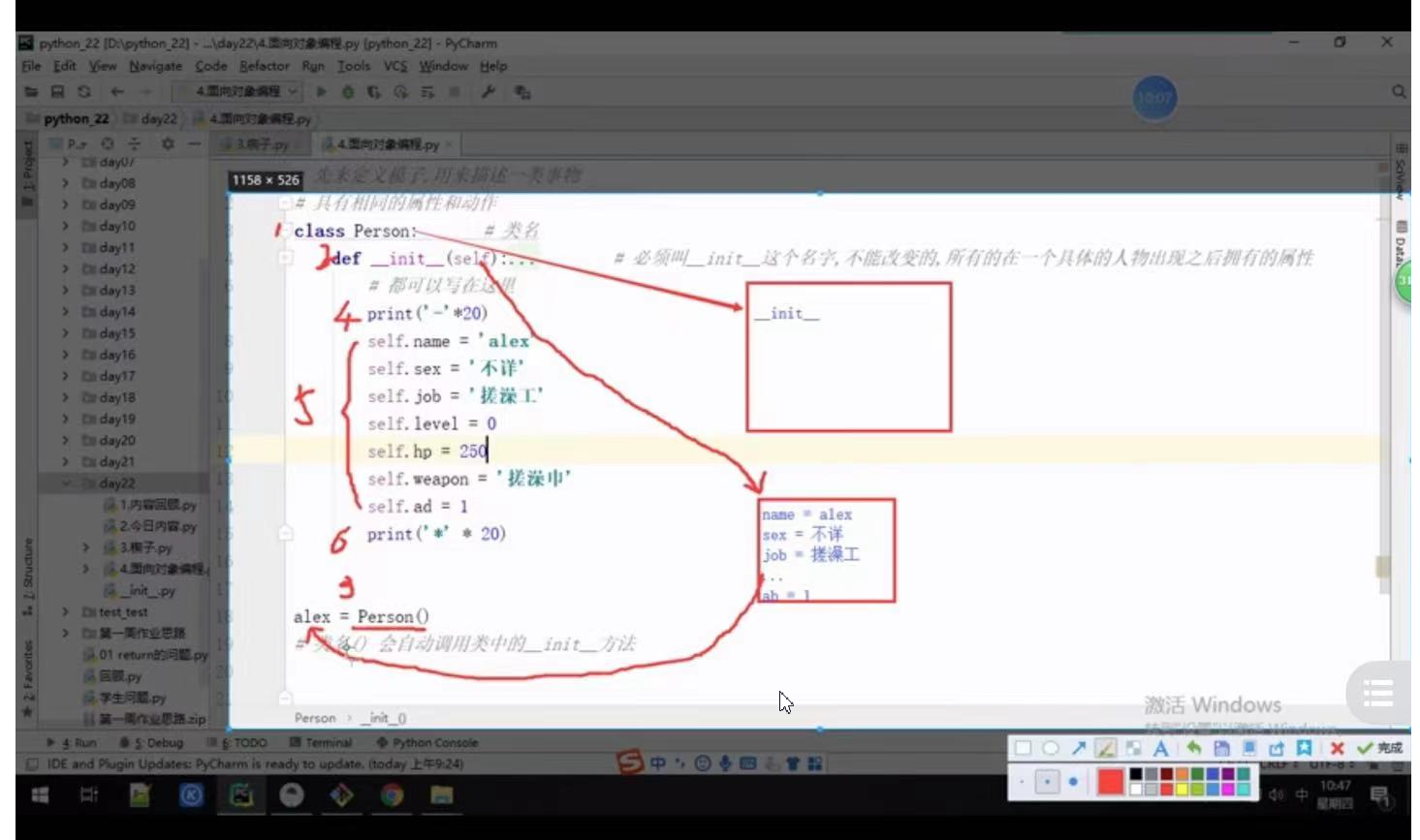
class Person:
print(123)
def __init__(self):
print('-'*20)
self.name='mike'
print('*' * 20)
print(456)
123
456
Process finished with exit code 0
3、類的實體化
其實實體化一個物件總共發生了三件事:
1,在記憶體中開辟了一個物件空間,
2,自動執行類中的__init__方法,并將這個物件空間(記憶體地址)傳給了__init__方法的第一個位置引數self,
3,在__init__ 方法中通過self給物件空間添加屬性,
alex=Person() #alex就是物件,Alex=Person()的程序,是通過類獲取一個物件的程序,叫類的實體化
4、類呼叫執行 init 方法的程序
class Person:
print(123)
def __init__(self):
print('-'*20)
self.name='mike'
self.sex='不詳'
self.job='搓澡工'
self.level=0
self.hp=250
self.weapon='搓澡巾'
self.ad=1
print('*' * 20)
print(456)
alex=Person() #alex就是物件,Alex=Person()的程序,是通過類獲取一個物件的程序,叫類的實體化
123
456
--------------------
********************
Process finished with exit code 0
- 圖片決議
5、類和物件之間的關系?
- 類 是一個大范圍,是一個模子,它約束了事務有哪些屬性,但是不能約束具體的值
- 物件 是一個具體的內容,是模子的產物,它遵循了類的約束,同時給屬性賦上具體的值
6、查看類中的所有內容
-
類名.__dict__方式
class Person: def __init__(self,name,sex,job,hp,weapon,ad,): print('-'*20) self.name=name self.sex=sex self.job=job self.level=0 self.hp=hp self.weapon=weapon self.ad=ad print('*' * 20) print(self.__dict__) alex=Person('alex','不詳','搓澡工',250,'搓澡巾',1) print(alex.__dict__) print(Person.__dict__) -------------------- ******************** {'name': 'alex', 'sex': '不詳', 'job': '搓澡工', 'level': 0, 'hp': 250, 'weapon': '搓澡巾', 'ad': 1} {'name': 'alex', 'sex': '不詳', 'job': '搓澡工', 'level': 0, 'hp': 250, 'weapon': '搓澡巾', 'ad': 1} {'__module__': '__main__', '__init__': <function Person.__init__ at 0x0000025A970999D8>, '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None} Process finished with exit code 0
7、self 是什么?
-
類有一個空間,存盤的是定義在class中所有名字
-
每一個物件又擁有自己的空間,通過物件名.__dict__方法就可以查看這個物件的屬性和值
-
類中的方法一般都是通過物件執行的(除去類方法,靜態方法外),并且物件執行這些方法都會自動將物件空間傳給方法中的第一個引數self.
所以self 是什么?
self其實就是類中方法(函式)的第一個位置引數,只不過解釋器會自動將呼叫這個函式的物件傳給self,所以咱們把類中的方法的第一個引數約定俗成設定成self, 代表這個就是物件,
8、實體化所經歷的程序
- 1.類名()之后的第一件事:開辟一塊記憶體空間,用來存放物件
- 2.呼叫__init__方法(或者類中其他方法),把空間的記憶體地址作為self引數,傳遞到函式內部
- 3.所有的著一個物件需要使用的屬性都需要和self關聯起來
- 4.執行完init中的邏輯后,self變數會自動的被回傳到呼叫處(發送實體化的地方,方便這個類實體化下一個物件)
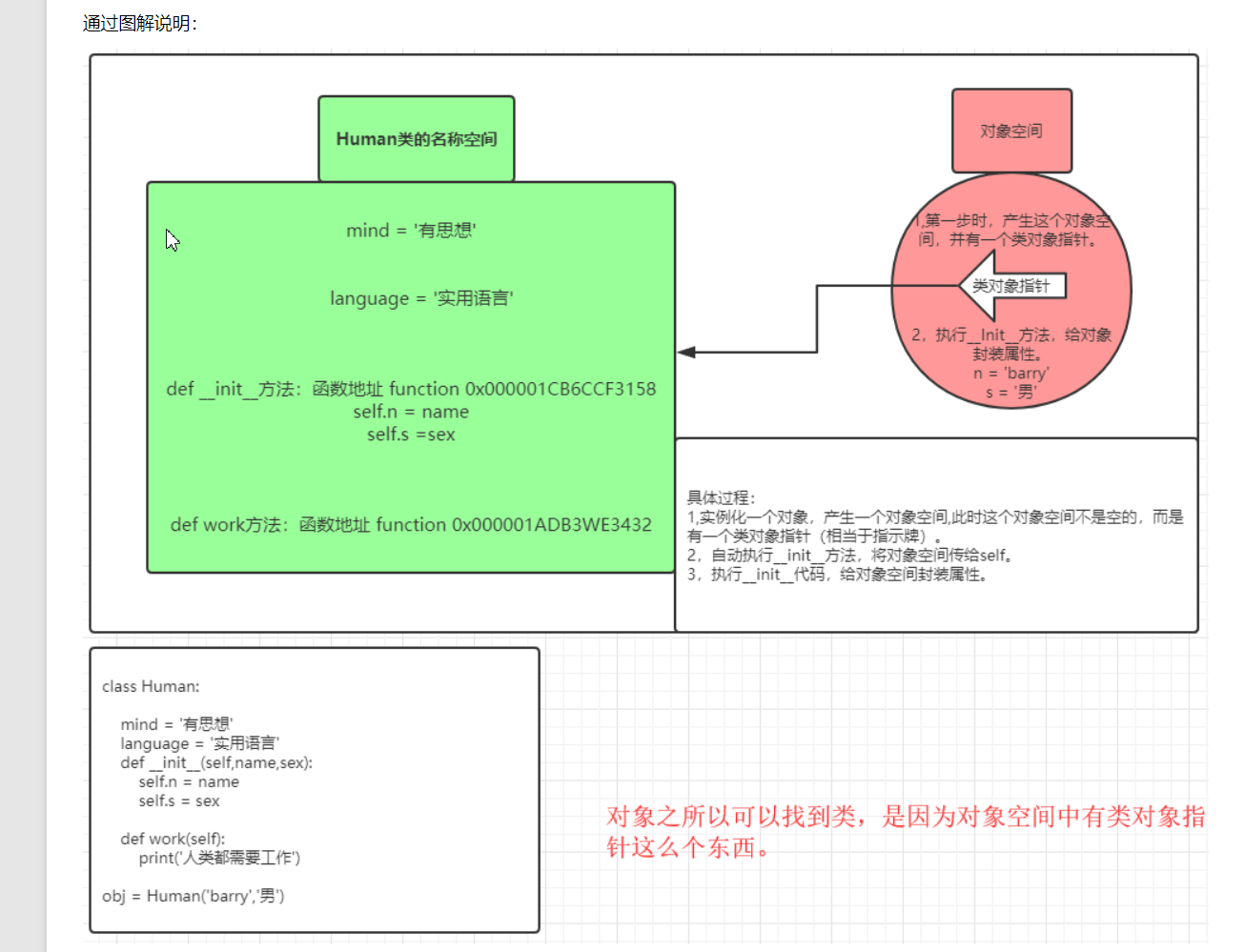
物件查找屬性的順序:先從物件空間找 ------> 類空間找 ------> 父類空間找 ------->.....
類名查找屬性的順序:先從本類空間找 -------> 父類空間找--------> ........
9、屬性的增,刪,改,查
修改 串列/字典/物件 中 的某一個值,都不會影響這個 串列/字典/物件 所在的記憶體空間地址
class Person:
def __init__(self,name,sex,job,hp,weapon,ad,):
print('-'*20)
self.name=name
self.sex=sex
self.job=job
self.level=0
self.hp=hp
self.weapon=weapon
self.ad=ad
print('*' * 20)
alex=Person('alex','不詳','搓澡工',250,'搓澡巾',1)
#屬性的增加
alex.momey=1000
#屬性的洗掉
del alex.money
#屬性的修改
alex.name='qweewqew'
#屬性的查看
print(alex.name)
二、類中定義方法和呼叫方法
1、案例:人狗大戰
需求:
人搓狗,狗掉血,狗掉的血是人的攻擊力
狗舔人,人掉血,人掉的血是狗的攻擊力
class Person:
def __init__(self,name,sex,job,hp,weapon,ad,):
self.name=name
self.hp=hp
self.ad=ad
def 搓(self,dog):
#人搓狗,狗掉血,狗掉的學是人的攻擊力
dog.dog_hp=dog.dog_hp-self.ad
print('{}給{}搓了澡,{}掉了{}點血,{}當前血量是{}'.format(self.name,dog.dog_name,dog.dog_name,self.ad,dog.dog_name,dog.dog_hp))
class Dog:
def __init__(self,name,blood,ad,kind):
self.dog_name = name
self.dog_hp=blood
self.dog_ad=ad
def 舔(self,person):
#狗舔人,人掉血 人掉的血是狗的攻擊力
if person.hp >= self.dog_ad :
person.hp=person.hp-self.dog_ad
else:
person.hp=0
print('{}舔了{},{}掉了{}點血,{}當前血量是{}'.format(self.dog_name,person.name,person.name,self.dog_ad,person.name,person.hp))
alex=Person('alex','不詳','搓澡工',250,'搓澡巾',1)
小白=Dog('小白',5000,249,'柴犬')
#人攻擊狗
alex.搓(小白)
#狗攻擊人
小白.舔(alex)
小白.舔(alex)
alex給小白搓了澡,小白掉了1點血,小白當前血量是4999
小白舔了alex,alex掉了249點血,alex當前血量是1
小白舔了alex,alex掉了249點血,alex當前血量是0
Process finished with exit code 0
2、當通過 類名.方法名() 呼叫類的方法時,會報錯,要穿一個引數進入才行
class A:
country='中國'
def __init__(self):
pass
def fun1(self):
print(11)
A.fun1()
TypeError: fun1() missing 1 required positional argument: 'self'
Process finished with exit code 1
class A:
country='中國'
def __init__(self):
pass
def fun1(self):
print(11)
A.fun1(2)
11
Process finished with exit code 0
3、所以通常我們 先實體化一個物件,用物件.方法名 去呼叫就不會報錯
#類:
class A:
country='中國'
def __init__(self):
pass
def fun1(self):
print(11)
obj=A()
obj.fun1() #=A.func1(a)
11
Process finished with exit code 0
4、思考:類和物件的命名空間講解
print(obj.country) 和 print(A.country) 的區別?
---為什么 print(obj.country) 列印的是'印度';而 print(A.country) 列印的是 '中國'?
前置說明:創建類的時候會創建一塊類的空間,用來存放 類里面的屬性,方法,和init方法 等等;
實體化類的物件時,會創建一塊物件的空間,存放一個類指標(用來指對應的類空間地址),然后物件名作為init方法的第一個位置引數(self),傳遞給init方法,init方法通過self給物件的空間添加屬性(即name='mike',age=83,country='印度'),
解答;
print(obj.country)先在obj物件的空間中找有沒有country屬性,結果有,并且是'印度',所以列印'印 度'---(如果物件的空間中沒有country屬性,那在去類的空間去找,這時候列印的就是'中國'了)
print(A.country) 先在A類的空間中找有沒有country屬性,結果有,并且是'中國',所以列印'中國'
class A:
country='中國'
def __init__(self,name,age,q):
self.name=name
self.age=age
self.country=q
obj=A('mike',83,'印度')
print(obj.country)
print(A.country)
印度
中國
Process finished with exit code 0
- 圖片決議:
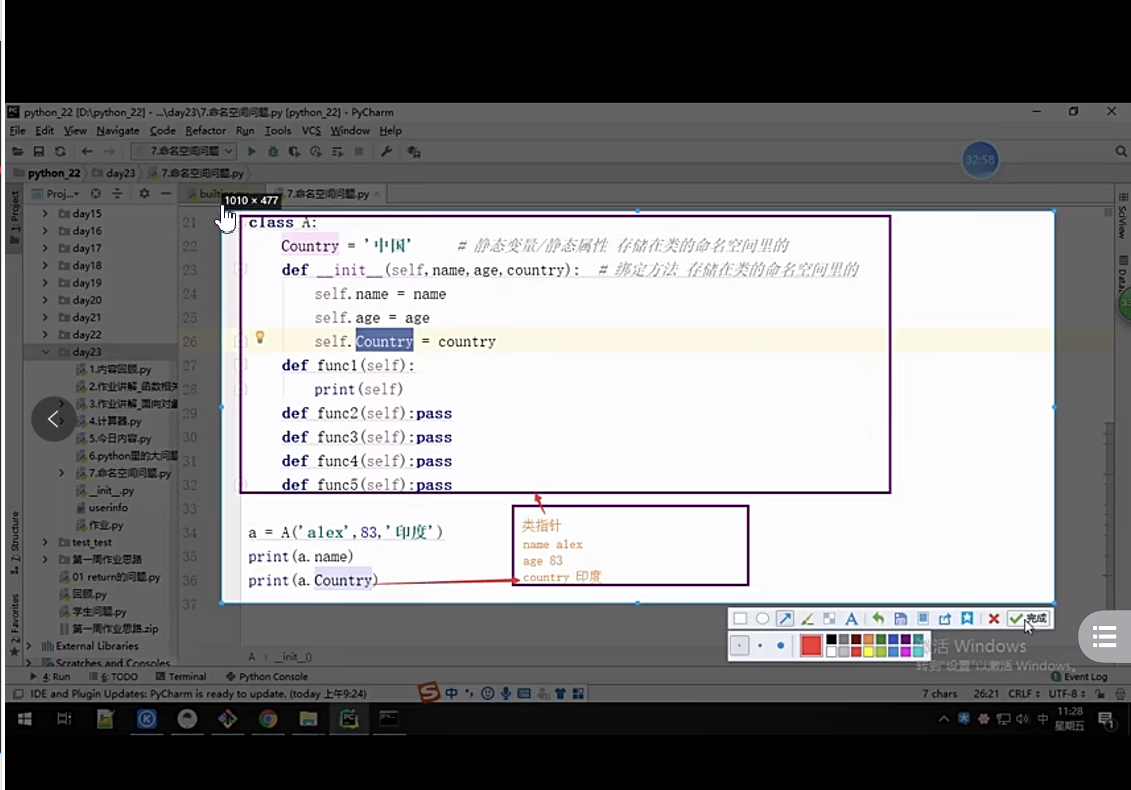
- 拓展:列印結果是?
class A:
country='中國'
def __init__(self,name,age,q):
self.name=name
self.age=age
self.country=q
a=A('mike',83,'印度')
b=A('wusir',73,'日本')
a.country='泰國'
print(a.country)
print(b.country)
print(A.country)
泰國
日本
中國
Process finished with exit code 0
5、總結
-
類中的變數是靜態變數
-
物件中的變數只輸入物件本身,每個物件有屬于自己的空間來存放物件的變數
-
當使用物件名去呼叫某一個屬性的時候會優先在自己的空間中尋找,找不到再去對應的類中尋找
-
如果自己沒有就去類空間去找,如果類也沒有就報錯
-
對于類來說,類中的變數,所有的物件都是可以讀取的,并且讀取的是同一個變數
三、組合:一個類的物件是另一個類物件的屬性
- 物件變成一個屬性
- 或者說物件變成另一個物件的引數了
#組合:一個類的物件是另一個類物件店的屬性
#需求:想查看大壯所在班級的開班日期是多少?
#學生類
#屬性:姓名,性別,年齡,學號,班級,手機號
#班級資訊類
#班級名字
#開班時間
#當前講師
class student:
def __init__(self,name,sex,age,number,class_name,phone):
self.name=name
self.sex=sex
self.age = age
self.number = number
self.class_name = class_name
self.phone = phone
class banji:
def __init__(self,cname,ctime,teacher):
self.cname=cname
self.ctime = ctime
self.teacher = teacher
py22=banji('python全站22期','2019-4-26','小白')
py23=banji('python全站23期','2019-5-26','寶元')
大壯=student('大壯','male',23,10086,py22,13812345678)
雪飛=student('雪飛','male',18,10088,py23,13812345670)
#想查看大壯所在班級的開班日期是多少?
print(大壯.class_name.ctime)
2019-4-26
Process finished with exit code 0
示例2
#班級類
#屬性:課程
#課程:
#課程名稱
#周期
#價格
#需求:
#創建兩個班級 linux57 python22
#查看linux57期的班級所學課程的價格
#查看python22期的班級所學課程的周期、
class banji:
def __init__(self,kcheng):
self.kcheng=kcheng
class kecheng:
def __init__(self,name,zhouqi,jiage):
self.name=name
self.zhouqi=zhouqi
self.jiage=jiage
#查看linux57期的班級所學課程的價格
linux57_課程=kecheng('mike','6個月',18000)
linux57=banji(linux57_課程)
print(linux57.kcheng.jiage)
#查看python22期的班級所學課程的周期、
python22_課程=kecheng('anuo','3個月',20000)
python22=banji(python22_課程)
print(python22.kcheng.zhouqi)
18000
3個月
Process finished with exit code 0
四、三大特性:繼承,封裝,多型
(1)繼承
1、繼承時實體化的程序
class animal:
def __init__(self,name):
self.name=name
def eat(self):
print("{}吃".format(self.name))
class cat(animal):
def pashu(self):
print("{}爬樹".format(self.name))
cat('小白')
# 先開辟空間,空間里有一個類指標-->指向Cat
# 呼叫init,物件在自己的空間中找init沒找到,到Cat類中找init也沒找到,
# 找父類Animal中的init
- 圖片決議
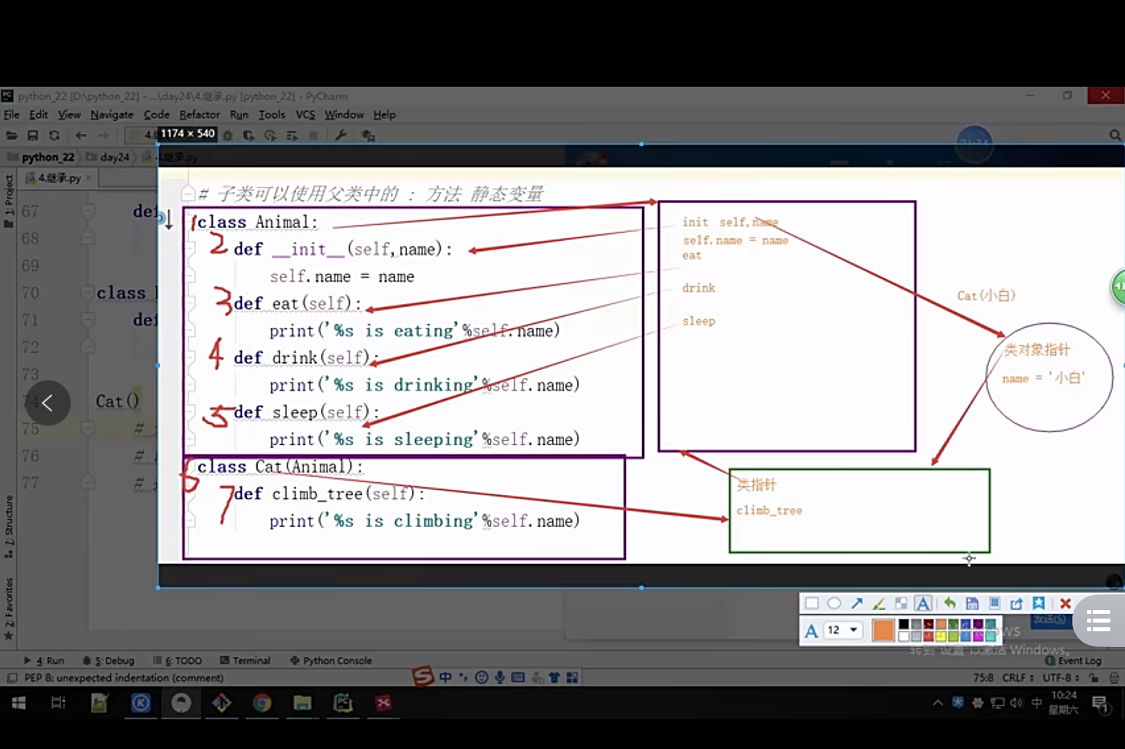
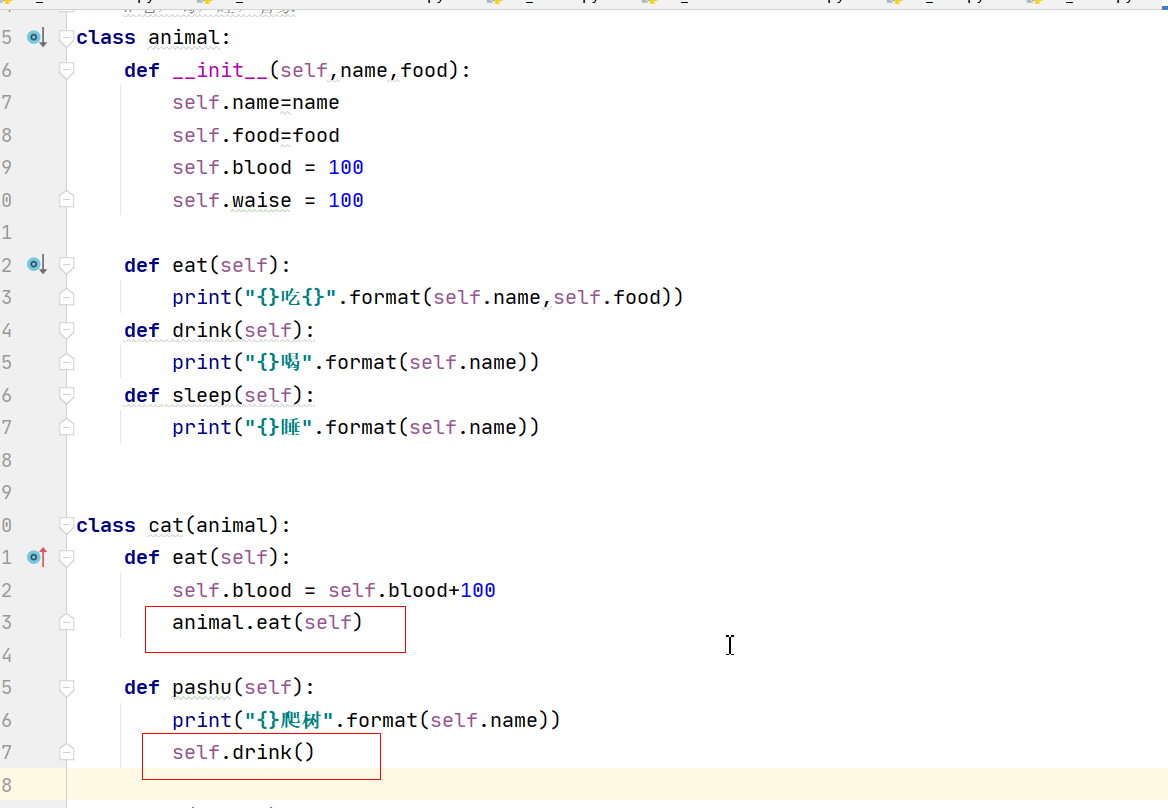
2、子類想要呼叫父類的方法的同時還想執行自己的同名方法?
# 子類想要呼叫父類的方法的同時還想執行自己的同名方法
# 貓和狗在呼叫eat的時候既呼叫自己的也呼叫父類的,
# ---在子類的方法中呼叫父類的方法 :父類名.方法名(self)
animal.eat(self)
class animal:
def __init__(self,name,food):
self.name=name
self.food=food
self.blood = 100
self.waise = 100
def eat(self):
print("{}吃{}".format(self.name,self.food))
def drink(self):
print("{}喝".format(self.name))
def sleep(self):
print("{}睡".format(self.name))
class cat(animal):
def eat(self):
self.blood = self.blood+100
animal.eat(self)
def pashu(self):
print("{}爬樹".format(self.name))
class dog(animal):
def eat(self):
self.waise = self.waise+100
def kanjia(self):
print("{}看家".format(self.name))
小貓 = cat('小白','貓糧')
小狗 = dog('小黑','狗糧')
小貓.eat()
小狗.eat()
print(小貓.__dict__,小貓.blood)
print(小狗.__dict__,小狗.waise)
小白吃貓糧
{'name': '小白', 'food': '貓糧', 'blood': 200, 'waise': 100} 200
{'name': '小黑', 'food': '狗糧', 'blood': 100, 'waise': 200} 200
Process finished with exit code 0
- 圖片講解呼叫程序
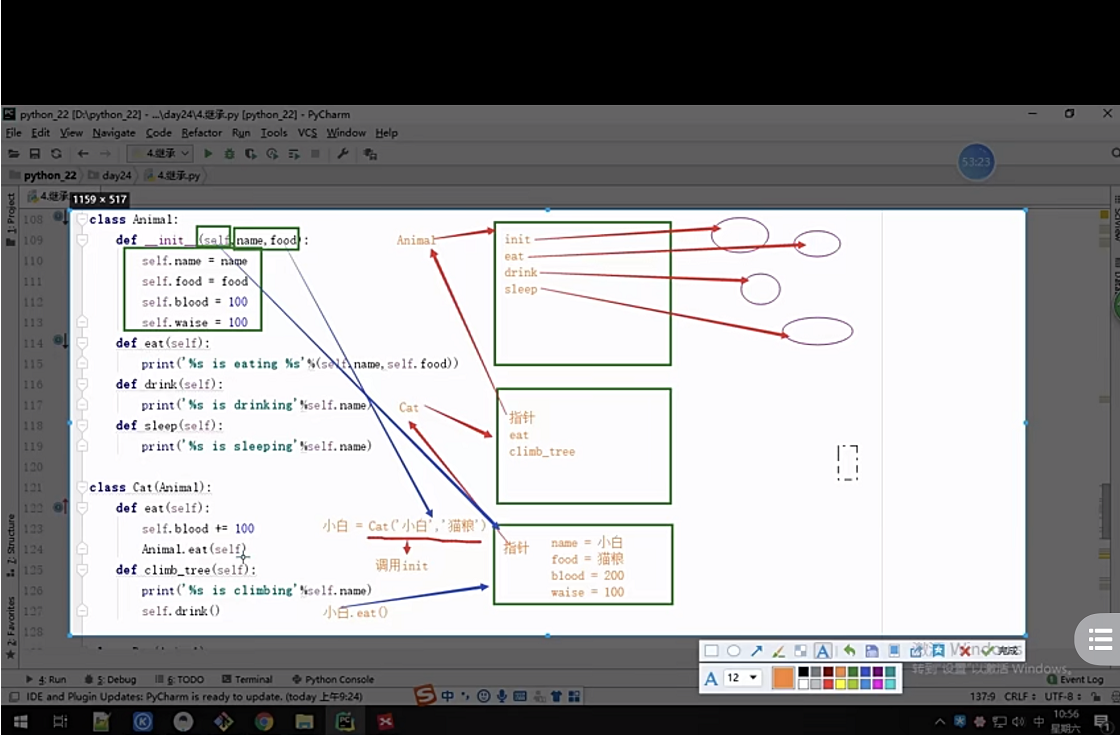
3、父類和子類方法的選擇
# 繼承語法
class 子類名(父類名):pass
# 父類和子類方法的選擇:
# 子類的物件,如果去呼叫方法
# 永遠優先呼叫自己的
# 如果自己有 用自己的
# 自己沒有 用父類的
# 如果自己有 還想用父類的:直接在子類方法中調父類的方法 父類名.方法名(self)--animal.eat(self)
# 如果有 父類沒有的 想在自己獨有的方法內呼叫父類的方法 : 直self.方法名()---self.drink()
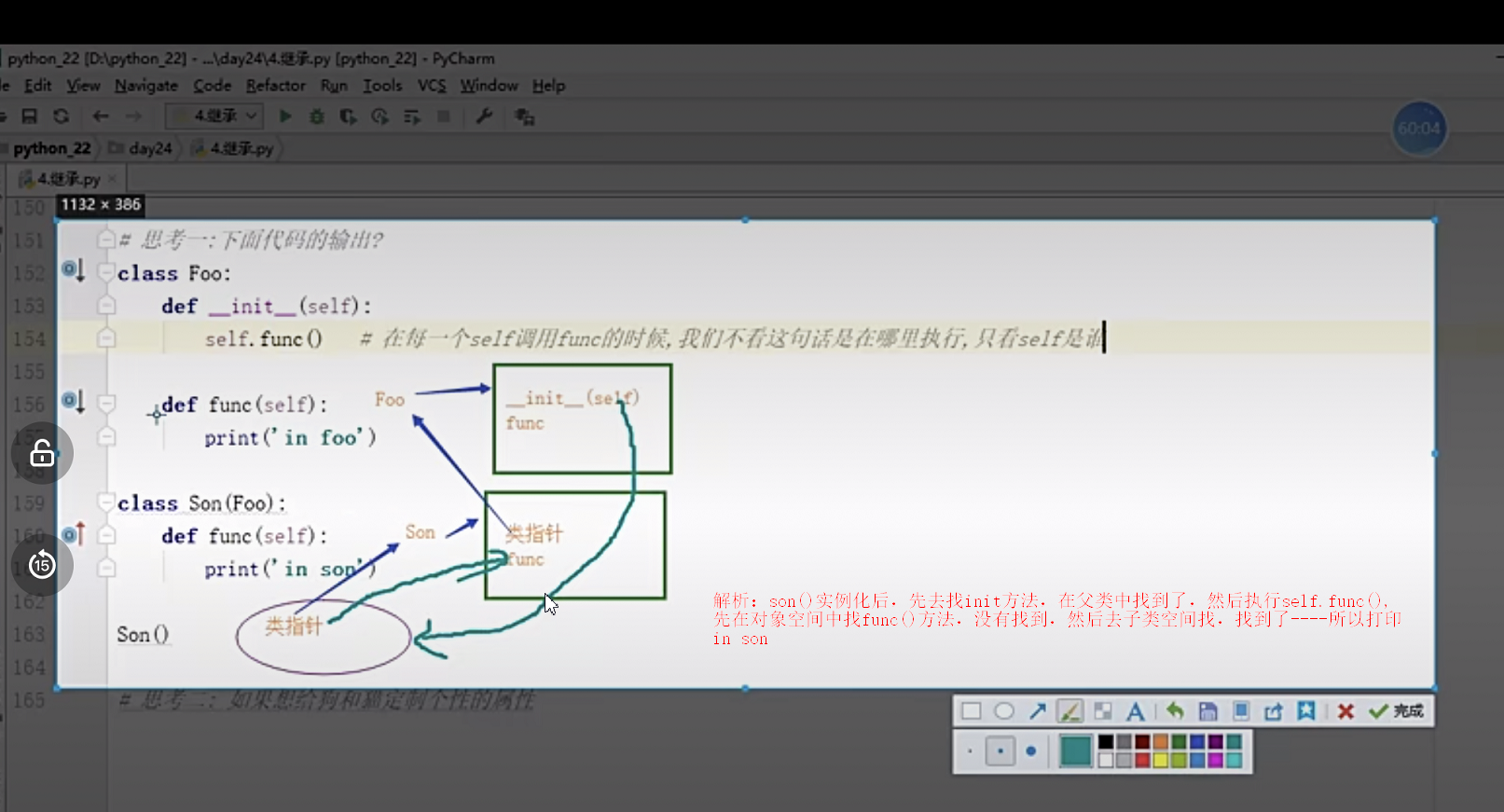
4、思考一:下面代碼的輸出?
class Foo:
def __init__(self):
self.func()
# 在每一個self呼叫func的時候,我們不看這句話是在哪里執行,只看self是誰(這里self指向son()這個物件的)
def func(self):
print('in foo')
class Son(Foo):
def func(self):
print('in son')
Son()
in son
Process finished with exit code 0
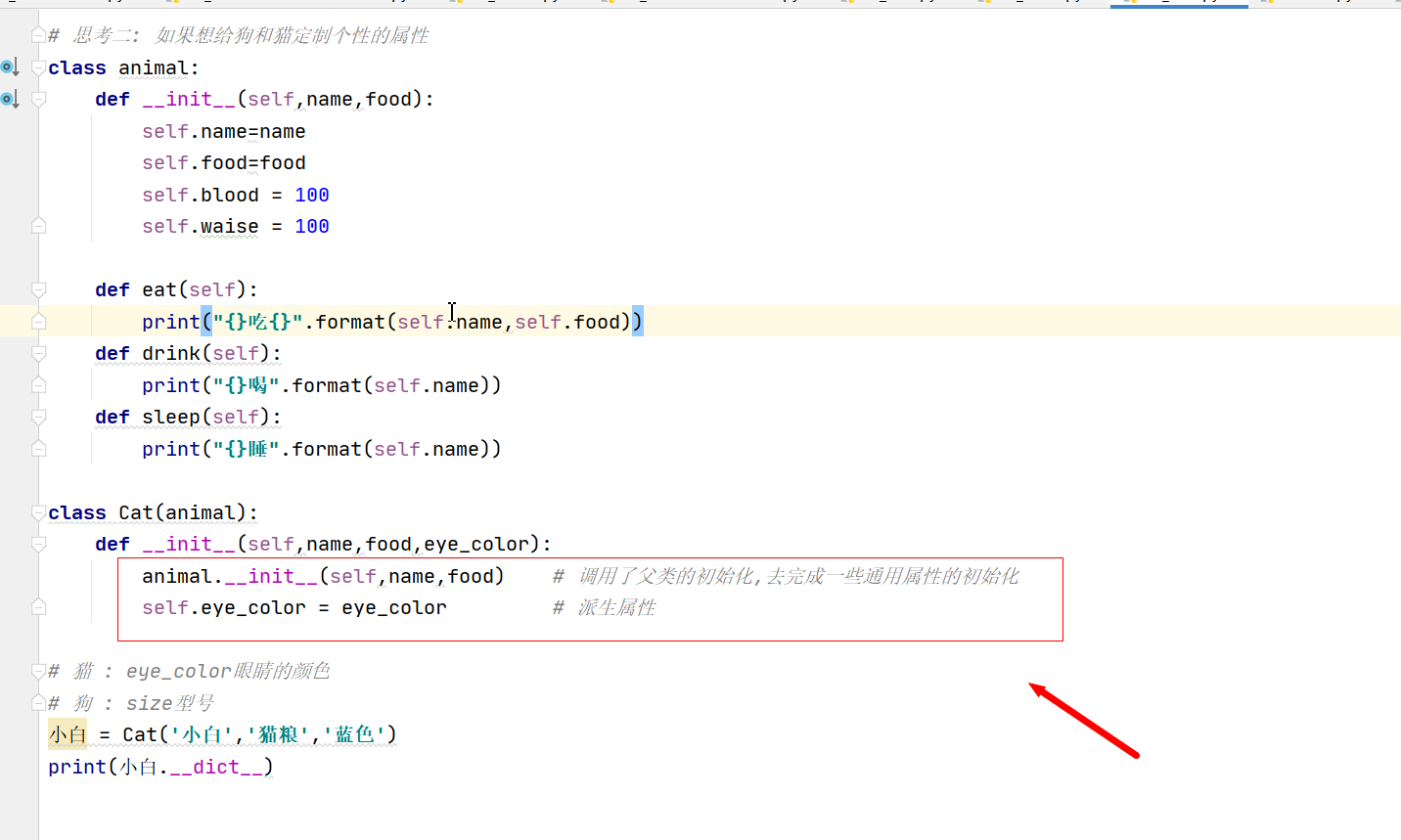
5、派生屬性
class Cat(animal):
def __init__(self,name,food,eye_color):
animal.__init__(self,name,food) # 呼叫了父類的初始化,去完成一些通用屬性的初始化
self.eye_color = eye_color # 派生屬性
6、單繼承
- 當一個子類只有一個父類時稱為單繼承
語法:
class 子類名(父類名):
#B繼承A A繼承C C繼承D B-A-C-D
class D:
def func(self):
print('in D')
class C(D):pass
class A(C):
def func(self):
print('in A')
class B(A):pass
B().func()
in A
Process finished with exit code 0
7、多繼承
- 多繼承指一個子類可以有多個父類,它繼承了多個父類的特性,多繼承可以看作是對單繼承的擴展
語法:
class 子類名(父類名1,父類名2…):
7.1:多繼承時,呼叫多個父類中同名方法時,那個優先級高?
---看那個父類離子類近
class C(B,A):pass ------優先B
class C(A,B):pass ------優先A
舉例:
class B:
def func(self):
print('in B')
class A:
def func(self):
print('in A')
class C(B,A):pass
C().func()
in B
Process finished with exit code 0
#*********************************************
class C(A,B):pass
C().func()
in A
Process finished with exit code 0
8、object類
- 類祖宗,所有在python3當中的類都是繼承object類的
9、類的繼承順序
- 背誦
- 只要繼承object類就是新式類
- 不繼承object類的都是經典類
python3 所有的類都繼承object類,都是新式類
在py2中 不繼承object的類都是經典類,繼承object類的就是新式類了
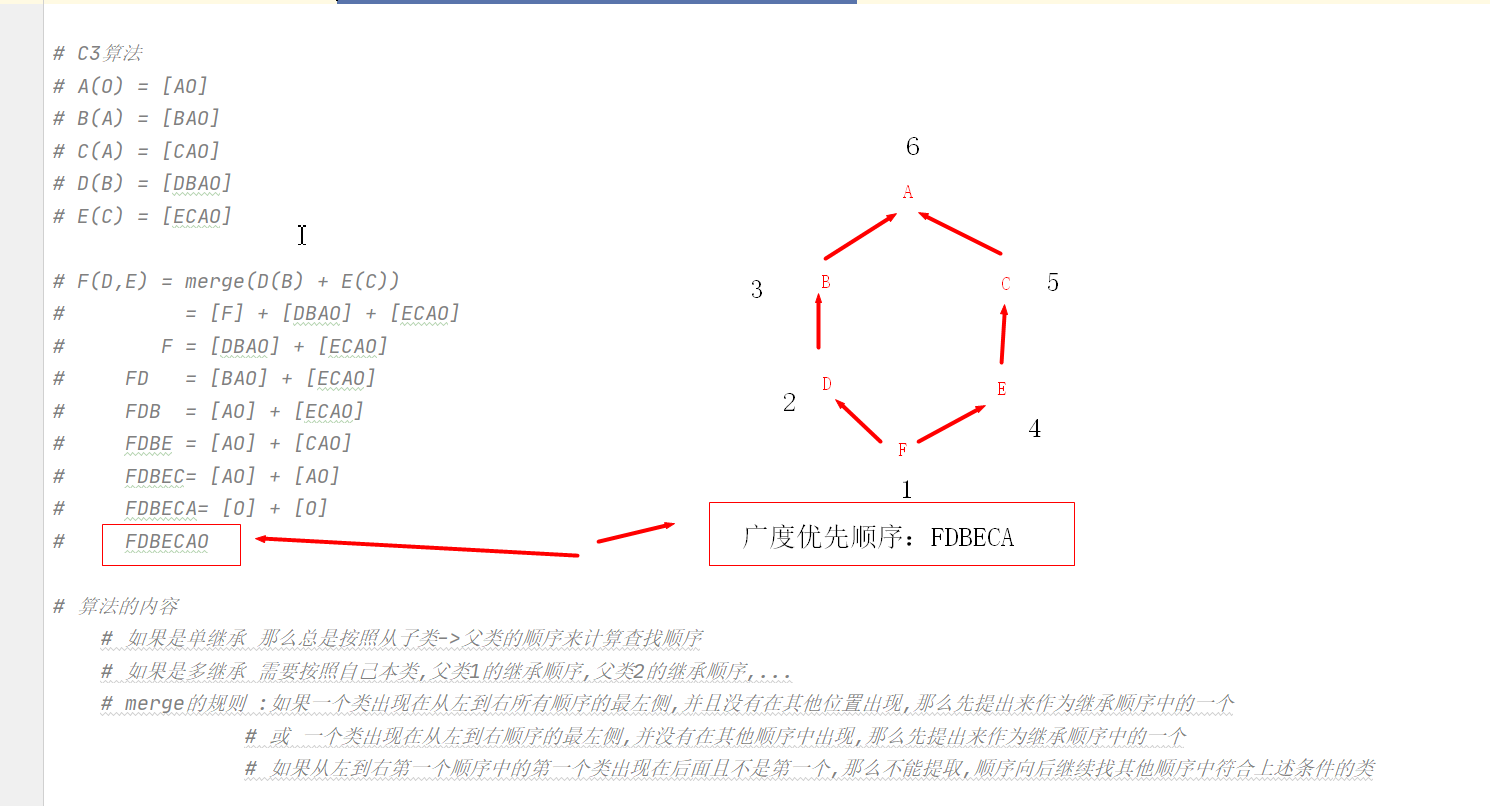
# 演算法的內容
# 如果是單繼承 那么總是按照從子類->父類的順序來計算查找順序
# 如果是多繼承 需要按照自己本類,父類1的繼承順序,父類2的繼承順序,...
# merge的規則 :如果一個類出現在從左到右所有順序的最左側,并且沒有在其他位置出現,那么先提出來作為繼承順 序中的一個
# 或 一個類出現在從左到右順序的最左側,并沒有在其他順序中出現,那么先提出來作為繼承順序中 的一個
# 如果從左到右第一個順序中的第一個類出現在后面且不是第一個,那么不能提取,順序向后繼續找其他順序中符合上述條件的類
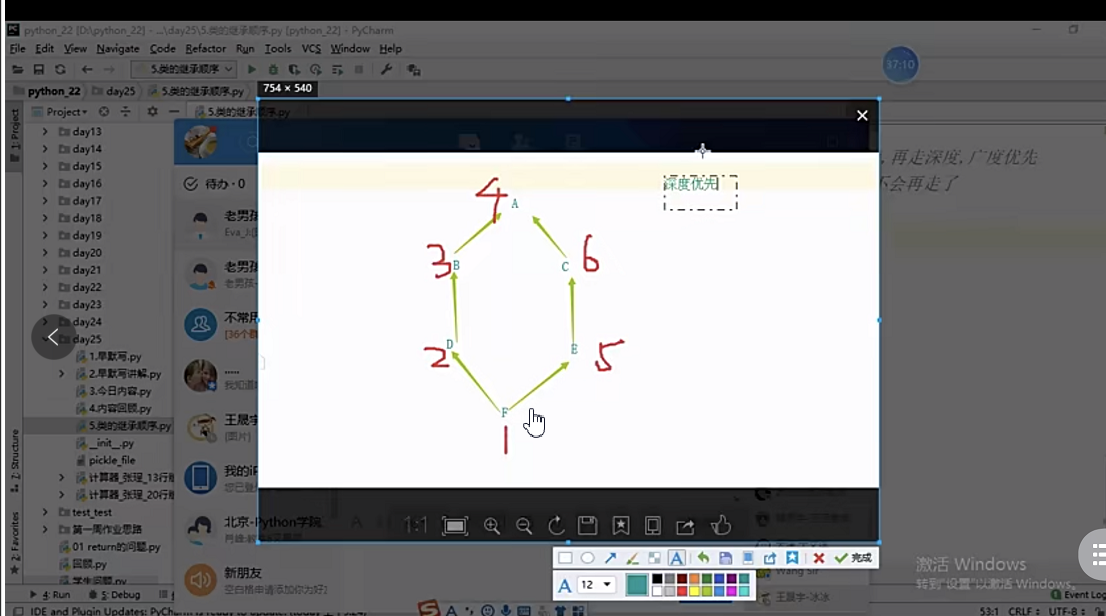
# 經典類 - 深度優先 (總是在一條路走不通之后再換一條路,走過的點不會再走了)
#新式類 - 廣度優先
# 深度優先要會看,自己能搞出順序來
# 廣度優先遵循C3演算法,要會用mro,會查看順序
# 經典類沒有mro,但新式類有
9.1、C3演算法:
在代碼中列印呼叫順序(mro方法)
語法: 類名.mro()
print(F.mro()) # 只在新式類中有,經典類沒有的
class A:
def func(self):
pass
class B(A):
def func(self):
pass
class C(A):
def func(self):
pass
class D(B):
def func(self):
pass
class E(C):
def func(self):
pass
class F(D,E):
def func(self):
pass
print(F.mro())
F-D-B-E-C-A-object
[<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
Process finished with exit code 0
9.2、深度優先(經典類)
9.3、廣度優先(新式類)
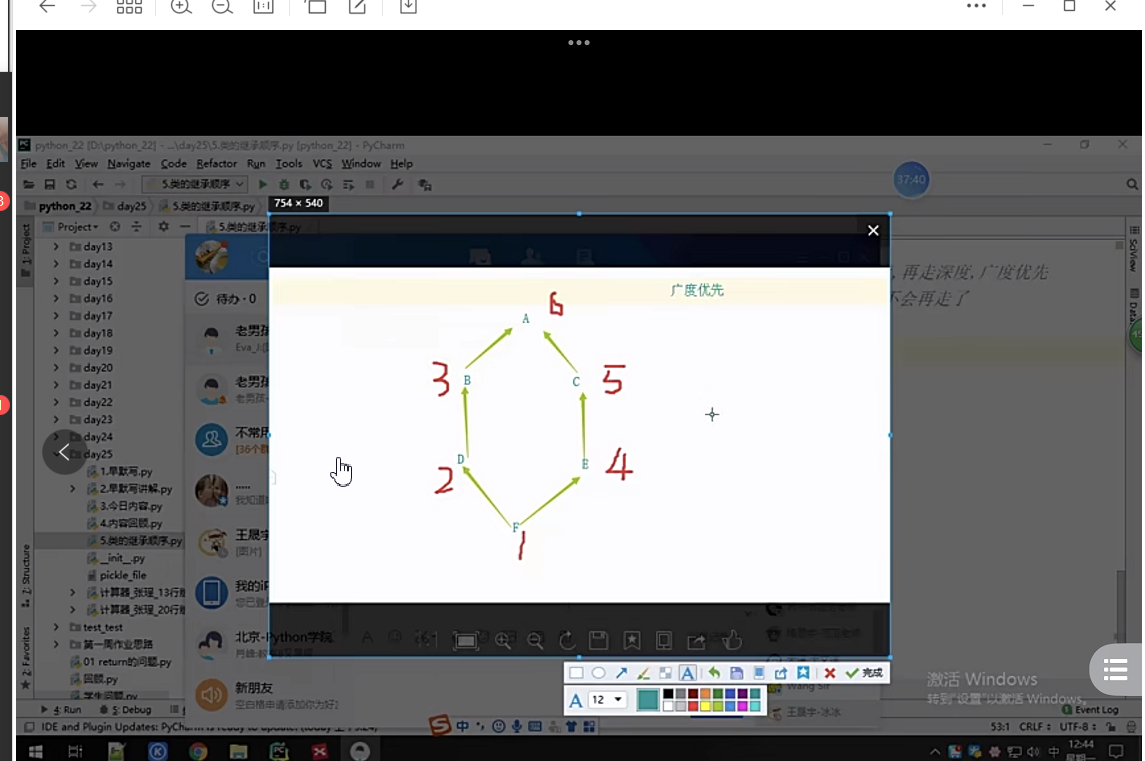
10、繼承總結:
# 單繼承
# 調子類的 : 子類自己有的時候
# 調父類的 : 子類自己沒有的時候
# 調子類和父類的 :子類父類都有,在子類中呼叫父類的
# 多繼承
# 一個類有多個父類,在呼叫父類方法的時候,按照繼承順序,先繼承的就先尋找
10.1、復習實體化物件的程序
1--.前面是什么--就在對應的空間去找(如 A.role 表示在類A的空間中去找role;
如 a=A() a.l 表示在物件的空間中去找l)
2--實體化的時候總是先開空間,再呼叫init, 呼叫init的時候總是把新開的的空間作為引數傳遞給self
(即self 等于物件,比如 self.l 表示在物件的空間中去找l )
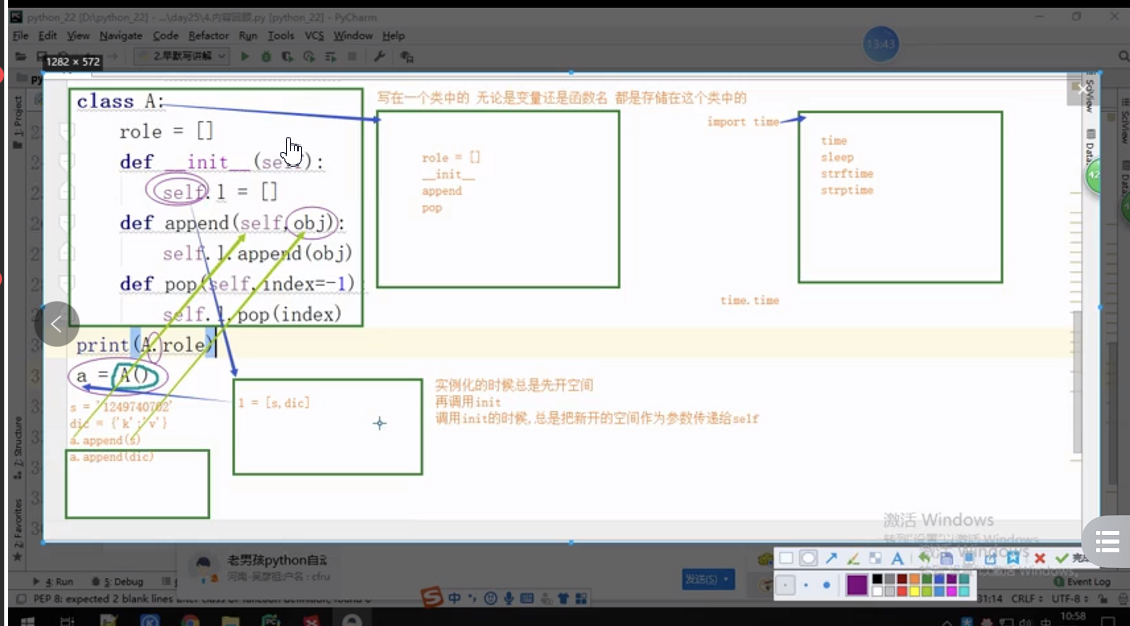
3--分析 a=A() a.append(1) 的呼叫程序?
解答:先在物件a空間中去找append方法,發現沒有,再通過類指標去A類中找append方法,找到了,然后執行 self.l.append(obj)--首先self.l 是保存在物件空間中的一個空串列[],然后append(1),表示物件空 間的 self.l 空串列添加了一個元素1 (補充:此時A().l 是空串列[],沒有1)
代碼:
class A:
role = []
def __init__(self):
self.l = []
def append(self,obj):
self.l.append(obj)
def pop(self,index=-1):
self.l.pop(index)
print(A.role)
a=A()
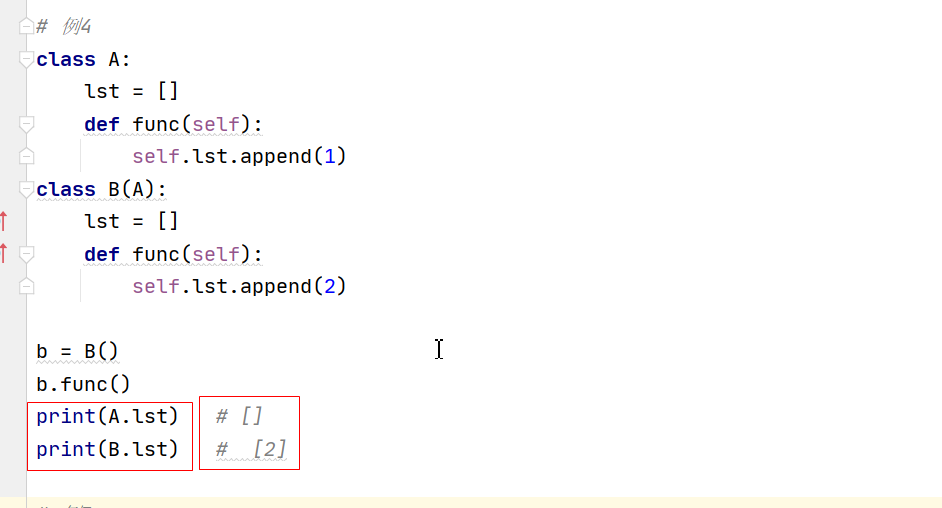
10.2、復習繼承
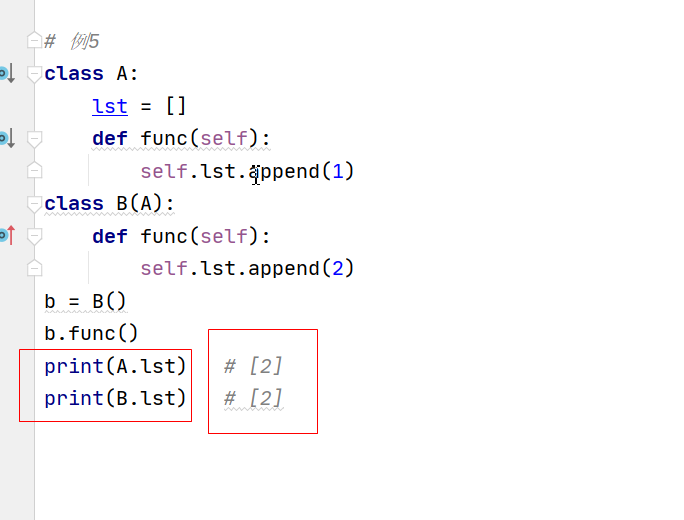
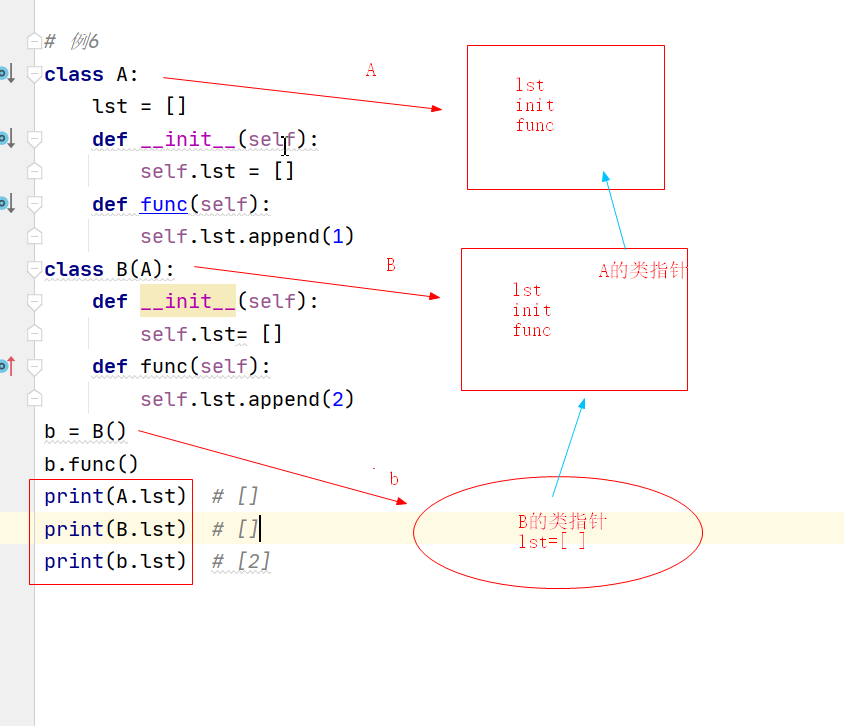
重點案例:繼承的呼叫程序
(2)多型
一個型別表現出來的多種狀態(多型,同一個物件,多種形態)
# 一個型別表現出來的多種狀態
# 支付 表現出的 微信支付和蘋果支付這兩種狀態
# 在java情況下: 一個引數必須制定型別
# 所以如果想讓兩個型別的物件都可以傳,那么必須讓這兩個類繼承自一個父類,在制定型別的時候使用父類來指定
# 多型
# 什么是多型? : 一個類表現出的多種形態,實際上是通過繼承來完成的
# 如果狗類繼承動物類,貓類也繼承動物類
# 那么我們就說貓的物件也是動物型別的
# 狗的物件也是動物型別的
# 在這一個例子里,動物這個型別表現出了貓和狗的形態
# java中的多型是什么樣
# def eat(動物型別 貓的物件/狗的物件,str 食物):
# print('動物型別保證了貓和狗的物件都可以被傳遞進來')
# python中的多型是什么樣 : 處處是多型
# 鴨子型別
# 子類繼承父類,我們說子類是父型別別的(貓類繼承動物,我們說貓也是動物)
# 在python中,一個類是不是屬于某一個型別
# 不僅僅可以通過繼承來完成
# 還可以是不繼承,但是如果這個類滿足了某些型別的特征條件
# 我們就說它長得像這個型別,那么他就是這個型別的鴨子型別
0、多型是什么?
多型 :不同的 子類物件呼叫 相同的 父類方法,產生 不同的 執行結果,
- 多型以 繼承 和 重寫 父類方法 為前提
- 多型是呼叫方法的技巧,不會影響到類的內部設計
class animal:
def sleep(self):
print("animal睡")
class dog(animal):
def sleep(self):
print("dog睡覺")
class cat(animal):
def sleep(self):
print("cat睡覺")
class pig(animal):
pass
#不同的子類
dog = dog()
cat = cat()
pig = pig()
#呼叫相同的父類的同名方法,產生 不同的 執行結果
dog.sleep()
cat.sleep()
pig.sleep()
dog睡覺
cat睡覺
animal睡
Process finished with exit code 0
1、多型是什么?
- 同一事件在不同物件上產生不同的相應
- 同一事件:即呼叫相同函式
- 不同物件:被呼叫函式的引數是不同的實體
- 不同的相應:輸出結果不同
舉例分析:
分析:
同一事件:呼叫 func 函式
不同物件:三個物件本質都是Animal型別的不同實體
不同相應:輸出結果不同,輸出如下圖:
代碼:
class animal:
def sleep(self):
print("animal睡")
class dog(animal):
def sleep(self):
print("dog睡覺")
class cat(animal):
def sleep(self):
print("cat睡覺")
#呼叫函式
def func(x) :
x.sleep()
#創建3個實體,本質都是Animal型別
animal = animal()
dog = dog()
cat = cat()
#重點重點重點
func(animal)
func(dog)
func(cat)
animal睡
dog睡覺
cat睡覺
Process finished with exit code 0
2、Python中【多型】的作用?
- 讓具有不同功能的函式可以使用相同的函式名,這樣就可以用一個函式名呼叫不同功能(內容)的函式,
3、Python中多型的特點
1、只關心物件的實體方法是否同名,不關心物件所屬的型別;
2、物件所屬的類之間,繼承關系可有可無;
3、多型的好處可以增加代碼的外部呼叫靈活度,讓代碼更加通用,兼容性比較強;
4、多型是呼叫方法的技巧,不會影響到類的內部設計,
4、多型的應用場景?
4.1、 物件所屬的類之間沒有繼承關系
- 呼叫同一個函式
fly(), 傳入不同的引數(物件),可以達成不同的功能
class Duck(object): # 鴨子類
def fly(self):
print("鴨子沿著地面飛起來了")
class Swan(object): # 天鵝類
def fly(self):
print("天鵝在空中翱翔")
class Plane(object): # 飛機類
def fly(self):
print("飛機隆隆地起飛了")
def fly(obj): # 實作飛的功能函式
obj.fly()
duck = Duck()
fly(duck)
swan = Swan()
fly(swan)
plane = Plane()
fly(plane)
鴨子沿著地面飛起來了
天鵝在空中翱翔
飛機隆隆地起飛了
Process finished with exit code 0
4.2、 物件所屬的類之間有繼承關系(應用更廣)
class gradapa(object):
def __init__(self, money):
self.money = money
def p(self):
print("this is gradapa")
class father(gradapa):
def __init__(self, money, job):
super().__init__(money)
self.job = job
def p(self):
print("this is father,我重寫了父類的方法")
class mother(gradapa):
def __init__(self, money, job):
super().__init__(money)
self.job = job
def p(self):
print("this is mother,我重寫了父類的方法")
return 100
# 定義一個函式,函式呼叫類中的p()方法
def fc(obj):
return obj.p()
gradapa1 = gradapa(3000)
father1 = father(2000, "工人")
mother1 = mother(1000, "老師")
fc(gradapa1) # 這里的多型性體現是向同一個函式,傳遞不同引數后,可以實作不同功能.
fc(father1)
print(fc(mother1))
this is gradapa
this is father,我重寫了父類的方法
this is mother,我重寫了父類的方法
100
拓展:函式中 return 的理解
def func():
print('in func')
return 100
def func1(x):
print('in func1')
x() #沒有使用return x()
print(func1(func)) #結果沒有列印100 列印None --這是因為 func1 這個方法的記憶體地址里沒有存盤100
加上 return
def func():
print('in func')
return 100
def func1(x):
print('in func1')
return x() #加上return x()
print(func1(func)) #結果了列印100 --這是因為return 后,100這個值就回傳到 func1 這個方法的記憶體地 址里 所有才可以列印出來
super()方法
-
su po
-
在單繼承中,super就是找父類
-
在多繼承中,super就是按照mro順序,去找當前類的下一個類
class User:
def __init__(self,name):
self.name = name
class VIPUser(User):
def __init__(self,name,level,strat_date,end_date):
# User.__init__(self,name)
super().__init__(name) # 推薦的
# super(VIPUser,self).__init__(name)
self.level = level
self.strat_date = strat_date
self.end_date = end_date
太白 = VIPUser('太白',6,'2019-01-01','2020-01-01')
print(太白.__dict__)
{'name': '太白', 'level': 6, 'strat_date': '2019-01-01', 'end_date': '2020-01-01'}
Process finished with exit code 0
(3)封裝
1、什么是封裝?
- 把 屬性 和 方法 裝到一個類中,然后通過 物件 直接或者 self 間接獲取被封裝的內容
廣義 :把屬性和方法裝起來,外面不能直接呼叫了,要通過類的名字來呼叫
狹義 :把屬性和方法藏起來,外面不能呼叫,只能在內部偷偷呼叫(私有屬性,私有方法)
2、私有屬性和私有方法
- 對于私有屬性和私有方法,只能在類的內部訪問,類的外部無法訪問
- 在定義屬性或?法時,在屬性名或者?法名前 增加兩個下劃線,定義的就是私有屬性或方法
私有屬性:
class User:
def __init__(self,name,passwoed):
self.name=name
self.__passwoed=passwoed
def get_passwoed(self):
return self.__passwoed #只有在類內部才可以通過 self__passwoed 的形式訪問到
obj=User('mike','123345')
#print(obj.__passwoed) #類的外部訪問不了私有屬性,報錯
print(obj.get_passwoed()) #類的內部可以呼叫私有屬性,
思考:既然類的外部訪問不了了,那為什么我還有在類的內部定義一個 def get_passwoed(self) 方法呢?
----因為有時候我想讓你看的私有屬性 ,但是我不想讓你該我的私有屬性
私有方法:
import hashlib
class User:
def __init__(self,name,passwd):
self.usr = name
self.__pwd = passwd # 私有的實體變數
def __get_md5(self): # 私有的系結方法
md5 = hashlib.md5(self.usr.encode('utf-8'))
md5.update(self.__pwd.encode('utf-8'))
return md5.hexdigest()
def getpwd(self):
return self.__get_md5()
alex = User('alex','sbsbsb')
print(alex.getpwd())
d6170374823ac53f99e7647bab677b92
Process finished with exit code 0
3、使用私有屬性或/方法的三種場景?
# 使用私有的三種情況
# 不想讓你看也不想讓你改
# 可以讓你看 但不讓你改
# 可以看也可以改 但是要求你按照我的規則改
# 所有的私有化都是為了讓用戶不在外部呼叫類中的某個名字
# 如果完成私有化 那么這個類的封裝度就更高了 封裝度越高各種屬性和方法的安全性也越高 但是代碼越復雜
4、加了雙下劃線的名字為啥不能從類的外部呼叫了?
class User:
__Country = 'China' # 私有的類屬性
__Role = '法師'
def func(self):
print(self.__Country) #在內的類別使用的時候,自動的吧當前這句話所在的類的名字拼在私有變數前面,來完成呼叫
print(User.__dict__)
#非要取私有屬性?--可以
print(User._User__Country)
{'_User__Country': 'China', '_User__Role': '法師'}
China
Process finished with exit code 0
5、私有的內容能不能被子類使用呢?
--- 不能,原因看面試題2
面試題1:列印什么結果?
class Foo(object):
def __init__(self):
self.func()
def func(self):
print('in Foo')
class Son(Foo):
def func(self):
print('in Son')
Son()
in Son
Process finished with exit code 0
- 影像決議:
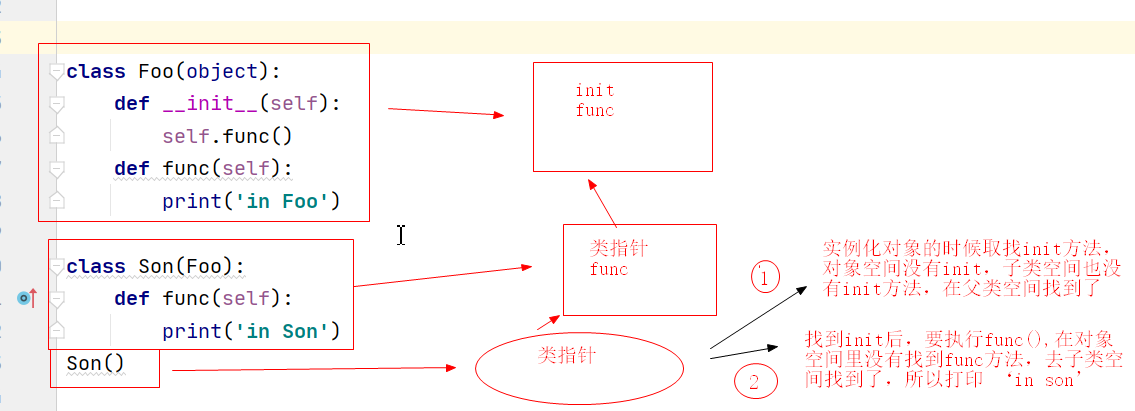
面試題2:列印什么結果?
class Foo(object):
def __init__(self):
self.__func()
def __func(self):
print('in Foo')
class Son(Foo):
def __func(self):
print('in Son')
Son()
in Foo
Process finished with exit code 0
- 圖片決議
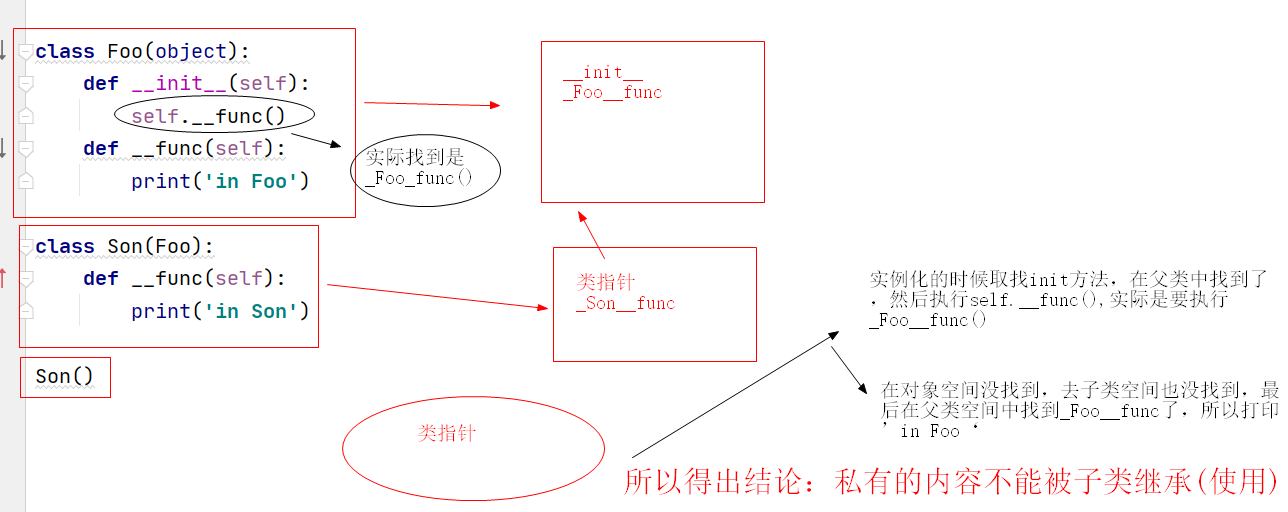
面試題3:列印什么結果?
---會報錯,因為找不到 _son__func() 方法
class Foo(object):
def __func(self):
print('in Foo')
class Son(Foo):
def __init__(self):
self.__func()
Son()
AttributeError: 'Son' object has no attribute '_Son__func'
Process finished with exit code 1
6、類中的三個裝飾器(內置函式)
6.1、@property
- pao po t
- 把一個方法偽裝成一個屬性,在呼叫這個方法的時候不需要加 () 就可以直接得到回傳值
#(1)property
#例子:計算圓得面積
from math import pi
class Circle:
def __init__(self,r):
self.r = r
@property # 把一個方法偽裝成一個屬性,在呼叫這個方法的時候不需要加()就可以直接得到回傳值
def area(self):
return pi * self.r**2
c1=Circle(5)
print(c1.r)
#print(c1.area()) #area()面積是一個方法,但是其實叫屬性會好點,所以參考@property 裝飾器
print(c1.area)
# 變數的屬性和方法?
# 屬性 :圓形的半徑\圓形的面積
# 方法 :登錄 注冊
-
用@property裝飾的這個方法 不能有引數
--可以理解屬性沒發傳引數,方法在可以傳引數
import time
class Person:
def __init__(self,name,birth):
self.name = name
self.birth = birth
@property
def age(self): # 用@property裝飾的這個方法 不能有引數
return time.localtime().tm_year - self.birth
太白 = Person('太白',1995)
print(太白.age)
- @property的第二個應用場景 : 和私有的屬性合作的
# property的第二個應用場景 : 和私有的屬性合作的
class User:
def __init__(self,usr,pwd):
self.usr = usr
self.__pwd = pwd
@property
def pwd(self):
return self.__pwd
alex = User('alex','sbsbsb')
print(alex.pwd)
sbsbsb
Process finished with exit code 0
class Goods:
discount = 0.8
def __init__(self,name,origin_price):
self.name = name
self.__price = origin_price
@property
def price(self):
return self.__price * self.discount
apple = Goods('apple',5)
#print(apple.price()) #很變扭,因為蘋果的價格應該是屬性,叫方法很變扭
print(apple.price)
- @property進階
# property進階 ---想把蘋果的價格該一下?怎么辦?
class Goods:
discount = 0.8
def __init__(self,name,origin_price):
self.name = name
self.__price = origin_price
@property
def price(self):
return self.__price * self.discount
@price.setter
def price(self,new_value):
if isinstance(new_value,int): #約束new_value的值是int型別 才執行
self.__price = new_value
apple = Goods('apple',5)
print(apple.price) # 呼叫的是被@property裝飾的price
apple.price = 10 # 呼叫的是被setter裝飾的price
print(apple.price)
6.2、@classmethod(類方法)
普通方法可以訪問類方法/類屬性,類方法不能訪問普通方法,因為訪問普通方法需要物件
被裝飾的方法會成為一個靜態方法(類方法)
- 用@classmethod 修飾的方法為類方法;
- 類方法的引數為 cls (不是self),在類方法內部通過 cls.類屬性 或者 cls.類方法 來訪問同一個類中的其他類屬性和類方法(類方法不能訪問普通方法,因為訪問普通方法需要物件)
- 類方法不需要實體化就可以呼叫 (可以通過類名或者物件名呼叫),類方法只能訪問同一個類中的類屬性和類方法,
# classmethod 被裝飾的方法會成為一個靜態方法
class Goods:
__discount = 0.8
def __init__(self):
self.__price = 5
self.price = self.__price * self.__discount
# 想修改折扣0.6====v1.0(不用類方法)
# def change_discount(self,new_discount):
# #self.__discount #這個地方不能用self 這樣的話 相當于在self這個空間里創建了__discount
# Goods.__discount=new_discount
# 想修改折扣0.6====v2.0(用類方法)
@classmethod # 把一個物件系結的方法 修改成一個 類方法
def change_discount(cls,new_discount):
cls.__discount=new_discount #用Goods.__discount也可以,考慮到 類名可能會改
# apple=Goods()
# print(apple.price)
# #想修改折扣0.6
# apple.change_discount(0.6)
# apple2=Goods()
# print(apple2.price)
Goods.change_discount(0.6)
apple=Goods()
print(apple.price)
什么時候用@classmethod?
# 1.定義了一個方法,默認傳self,但這個self沒被使用
# 2.并且你在這個方法里用到了當前的類名,或者你準備使用這個類的記憶體空間中的名字的時候
6.3、@staticmethod
幫助我們把一個普通的函式挪到類中直接使用,制造靜態方法使用
# @staticmethod 被裝飾的方法會成為一個靜態方法
class User:
pass
@staticmethod
def login(a,b): # 本身是一個普通的函式,被挪到類的內部執行,那么直接給這個函式添加 @staticmethod裝飾器就可以了
print('登錄的邏輯',a,b)
# 在函式的內部既不會用到self變數,也不會用到cls類
#用類名呼叫
User.login(1,2)
#用物件名呼叫
obj = User()
obj.login(3,4)
7、反射
python面向物件中的反射:通過字串的形式操作物件相關的屬性,python中的一切事物都是物件(都可以使用反射)
- 用字串資料型別的名字 來操作這個名字對應的 函式\實體變數\系結方法\各種方法
語法:
getatter(物件名,'屬性名') ==> 物件名.屬性名
7.1、反射的應用:
- 應用場景:現在讓我們打開瀏覽器,訪問一個網站,你單擊登錄就跳轉到登錄界面,你單擊注冊就跳轉到注冊界面,等等,其實你單擊的其實是一個個的鏈接,每一個鏈接都會有一個函式或者方法來處理
沒學反射之前的解決方式:
class User:
def login(self):
print('歡迎來到登錄頁面')
def register(self):
print('歡迎來到注冊頁面')
def save(self):
print('歡迎來到存盤頁面')
while 1:
choose = input('>>>').strip()
if choose == 'login':
obj = User()
obj.login()
elif choose == 'register':
obj = User()
obj.register()
elif choose == 'save':
obj = User()
obj.save()
學了反射之后解決方式:
class User:
def login(self):
print('歡迎來到登錄頁面')
def register(self):
print('歡迎來到注冊頁面')
def save(self):
print('歡迎來到存盤頁面')
user = User()
while 1:
choose = input('>>>').strip()
if hasattr(user, choose):
func = getattr(user, choose)
func()
else:
print('輸入錯誤,,,,')
8、封裝總結
8.1、類的成員
屬性的成員:
類屬性:定義在類的里面,方法的外面(不用實體化就可以【類名.類屬性名】直接呼叫)
普通屬性:定義在初始化init方法中
私有屬性:定義在類的里面,方法的外面,前面加上兩個下劃線,只能在類的內部訪問,類的外部無法訪問
class a:
company_name = '老男孩教育' # 類屬性
__iphone = '1353333xxxx' # 私有屬性
def __init__(self,age):
self.age=age #普通屬性
def func(self,hight):
self.hight =hight #普通屬性
return self.hight
#類屬性 可以直接列印,不用實體化物件
print(a.company_name)
#列印普通屬性
mike=a(18)
print(mike.age)
print(mike.func(180))
#列印使有屬性 使用屬性外部無法訪問,除非用 _類名__私有屬性名
print(a._a__iphone)
老男孩教育
18
180
1353333xxxx
Process finished with exit code 0
方法的成員:
普通方法:定義在類里的方法
私有方法:定義在類里的方法,前面加上兩個下劃線,只能在類的內部訪問,類的外部無法訪問(不能被繼承)
類方法:定義在類里的方法,用@classmethod 修飾,類方法的引數為 cls (不是self),類方法不需要實體化就可 以呼叫,類方法只能訪問同一個類中的類屬性和類方法(訪問普通方法要先實體化),
class b:
def __init__(self): #普通方法
pass
def func1(self):
print("普通方法") #普通方法
#self.__func2() #普通方法中呼叫私有方法
#self.func3() #普通方法中呼叫類方法
def __func2(self): #私有方法
print('私有方法')
@classmethod
def func3(cls):
print('類方法') #類方法
# c=b() #類方法中呼叫普通方法 需要實體化
# c.func1()
# d=b() #類方法中呼叫私有方法 需要實體化
# d.__func2()
#呼叫普通方法
mike=b()
mike.func1()
#呼叫私有方法 外部不能呼叫,只能內部訪問
#呼叫類方法 不用實體化
b.func3()
普通方法
類方法
Process finished with exit code 0
python大作業---學生選課系統
需求分析:
- 從“學生選課系統” 這幾個字就可以看出來,我們最核心的功能其實只有 選課,
角色:
- 學生、管理員
功能:
- 登陸 : 管理員和學生都可以登陸,且登陸之后可以自動區分身份
- 選課 : 學生可以自由的為自己選擇課程
- 創建用戶 : 選課系統是面向本校學生的,因此所有的用戶都應該由管理員完成
- 查看選課情況 :每個學生可以查看自己的選課情況,而管理員應該可以查看所有學生的資訊
作業流程:
登陸 :用戶輸入用戶名和密碼
判斷身份 :在登陸成果的時候應該可以直接判斷出用戶的身份 是學生還是管理員
學生用戶 :對于學生用戶來說,登陸之后有三個功能
1、查看所有課程
2、選擇課程
3、查看所選課程
4、退出程式
管理員用戶:管理員用戶除了可以做一些查看功能之外,還有很多創建作業
1、創建課程
2、創建學生學生賬號
3、查看所有課程
4、查看所有學生
5、查看所有學生的選課情況
6、退出程式
程式設計:
- 對于復雜的功能,我們首先就應該想到面向物件編程,而要想將面向物件的程式開發好,就應該做好類和物件的分析作業,
選課系統簡單的劃分其實只有兩個角色:管理員和學生,
仔細思考,你會發現有很多想不通的地方,比如學生選課,課從哪里來?
這樣一想就會發現,其實課程應該可以由管理員創造出來,那么課程又會有很多屬性:價格、周期、課程名、授課老師等等
那么課程也應該是一個類,
綜上,本程式最基礎的分析已經完畢,接下來我們要把所有的類以及其中的屬性、方法設計出來
(1)、課程:
屬性:課程名、價格、周期、老師
*課程并沒有什么動作,所以我們只設計屬性不設計方法,其實這里還可以設計很多屬性,比如課程的開始時間、結束時間、教室等等,只要你需要,這些都可以記錄下來,但是這里我們為了簡化代碼,就先不設計這些了
(2)、學生:
屬性:姓名、所選課程
方法:查看可選課程、選擇課程、查看所選課程、退出程式
(3)、管理員
屬性:姓名
方法:創建課程、創建學生學生賬號、查看所有課程、查看所有學生、查看所有學生的選課情況、退出程式
流程圖:
采分點:
1.類的創建和規劃 30分
2.登陸自動識別身份 10分
3.管理員創建各種資訊 20分
4.學生選課 20分
5.將記憶體中的資料保存到檔案中 10分
6.代碼簡潔、調理清晰10分
技術講解:
1、enumerate()使用介紹
- enumerate() 函式用于將一個可遍歷的資料物件(如串列、元組或字串)組合為一個索引序列,同時列出資料和資料下標,一般用在 for 回圈當中,
語法:
enumerate(sequence, [start=0])
例如: enumerate(Manager.opt_list,1)
sequence – 一個序列、迭代器或其他支持迭代物件,
start – 下標起始位置的值,
1.enumerate()是python的內置函式
2.enumerate在字典上是列舉、列舉的意思
3.對于一個可迭代的(iterable)/可遍歷的物件(如串列、字串),enumerate將其組成一個索引序列,利用它可以同時獲得索引和值
4.enumerate多用于在for回圈中得到計數
5.enumerate()回傳的是一個enumerate物件
舉例:
opt_list = [('創建課程', 'create_course'), ('創建學生', 'create_student'),
('查看課程', 'show_courses'), ('查看學生', 'show_student'),
('查看學生和已選課程', 'show_stu_course'), ('退出', 'exit')]
for index,i in enumerate(opt_list,1):
print(index,i)
1 ('創建課程', 'create_course')
2 ('創建學生', 'create_student')
3 ('查看課程', 'show_courses')
4 ('查看學生', 'show_student')
5 ('查看學生和已選課程', 'show_stu_course')
6 ('退出', 'exit')
Process finished with exit code 0
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/545095.html
標籤:Python
上一篇:odoo Actions學習總結
下一篇:解決habbybase 操作hbase報錯TTransportException(type=4,message=’TSocket read 0 bytes)