前言
大家好,我是小卷聊開發,春暖花開即將到來,整理了13道Redis高頻面試題,有些不全面還請諒解,感謝觀看!!!
1. Redis過期鍵的洗掉策略
- 定時洗掉:在設定鍵的過期時間的同時,創建一個定時器 timer). 讓定時器在鍵 的過期時間來臨時,立即執行對鍵的洗掉操作,
- 惰性洗掉:放任鍵過期不管,但是每次從鍵空間中獲取鍵時,都檢查取得的鍵是 否過期,如果過期的話,就洗掉該鍵;如果沒有過期,就回傳該鍵,
- 定期洗掉:每隔一段時間程式就對資料庫進行一次檢查,洗掉里面的過期鍵
2. Redis的淘汰策略
redis 記憶體資料集大小上升到一定大小的時候,就會施行 資料淘汰策略 ,redis 提供6種資料淘汰策略:
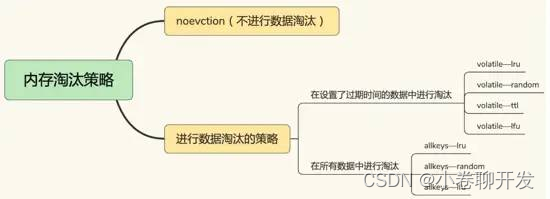
通過淘汰策略也能保證Redis中快取的都是熱點資料,
一個客戶端運行了新的命令,添加了新的資料,Redi 檢查記憶體使用情況,如果大于 maxmemory 的限制, 則根據設定好的策略進行回收,
注意這里的 6 種機制,volatile 和 allkeys 規定了是對已設定過期時間的資料集淘汰資料還是從全部資料集淘汰資料,后面的 lru、ttl 以及 random 是三種不同的淘汰策略,再加上一種 no-enviction 永不回收的策略,
使用策略規則:如果資料呈現冪律分布,也就是一部分資料訪問頻率高,一部分資料訪問頻率低,則使用 allkeys-lru;如果資料呈現平等分布,也就是所有的資料訪問頻率都相同,則使用:
allkeys-random
3. Redis分布鎖的實作
Redis的分布式快取特性使其成為了分布式鎖的一種基礎實作,通過Redis中是否存在某個鎖ID,則可以判斷是否上鎖,為了保證判斷鎖是否存在的原子性,保證只有一個執行緒獲取同一把鎖,Redis有 SETNX (即SET if Note Exists)和 GETSET (先寫新值,回傳舊值,原子性操作,可以用于分辨是不是首次操作)操作,
(1)關于setnx:
- 將 key 的值設為 value ,當且僅當 key 不存在,回傳值為1,
- 若給定的 key 已經存在,則setnx不做任何動作,回傳值為0,
(2)關于set:一般操作
- ex seconds - seconds:設定失效時長,單位秒
- px - milliseconds:設定失效時長,單位毫秒
- nx - key不存在時設定value,成功回傳OK,失敗回傳(nil)
- xx - key存在時設定value,成功回傳OK,失敗回傳(nil)
為了防止主機宕機或網路斷開之后的死鎖,Redis沒有ZK那種天然的實作方式,只能依賴設定超時時間來規避,所以如果使用setnx來實作分布式鎖,則實作步驟如下:
- 先拿 setnx 來爭搶鎖,搶到之后,再用 expire 給鎖加一個過期時間防止鎖忘記了釋放,
- 如果在 setnx 之后,執行 expire 之前行程意外 crash 或重啟維護, 那么就需要把 setnx 和 expire 合成一條指令來用,
Redis 的 setnx 命令是當 key 不存在時設定 key ,但 setnx 不能同時完成 expire 設定失效時長,不能保證 setnx 和 expire 的原子性,我們可以使用 set 命令完成 setnx 和 expire 的操作,并且這種操作是原子操作,舉個例子如下:
案例:設定name=p7+,失效時長100s,不存在時設定
1.1.1.1:6379> set name p7+ ex 100 nx
OK
1.1.1.1:6379> get name
"p7+"
1.1.1.1:6379> ttl name
(integer) 94
從上面可以看出,多個命令放在同一個 redis 連接中并且 redis 是單執行緒的,因此上面的操作可以看成 setnx 和 expire 的結合體,是原子性的,
4. Redis的Reactor模式
Redis基于Reactor模式開發了網路事件處理器,這個處理器被稱為檔案事件處理器,它的組成結構為4部分:多個套接字、IO多路復用程式、檔案事件分派器、事件處理器,
因為檔案事件分派器佇列的消費是單執行緒的,所以Redis才叫單執行緒模型,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-JKZsOe9N-1677421123886)(https://ask8088-private-1251520898.cos.ap-guangzhou.myqcloud.com/developer-images/article/10383614/8f7xo0neq1.png?q-sign-algorithm=sha1&q-ak=AKID2uZ1FGBdx1pNgjE3KK4YliPpzyjLZvug&q-sign-time=1677421109%3B1677428309&q-key-time=1677421109%3B1677428309&q-header-list=&q-url-param-list=&q-signature=1f5d9a1128deaf07af75e0fcfc8672bf9cd5e4f8)]](https://img.uj5u.com/2023/02/28/340610280652002.png)
5. Redis支持事務回滾嗎?
“ 不支持回滾動作,redis是支持簡單事務模式,只能discard,不能rollback ”
Redis在執行事務命令的時候,在命令入隊的時候, Redis 就會檢測事務的命令是否正確,如果不正確則會產生錯誤,無論之前和之后的命令都會被事務所回滾,就變為什么都沒有執行,
當命令格式正確,而因為操作資料結構引起的錯誤 ,則該命令執行出現錯誤,而其之前和之后的命令都會被正常執行,這點和資料庫很不一樣,這是需注意的地方,
對于一些重要的操作,我們必須通程序式去檢測資料的正確性,以保證 Redis 事務的正確執行,避免出現資料不一致的情況, Redis 之所以保持這樣簡易的事務,完全是為了保證移動互聯網的核心問題一性能,
6. Redis事務機制及CAS
watch指令在redis事物中提供了CAS的行為,為了檢測被watch的keys在是否有多個clients同時改變引起沖突,這些keys將會被監控,如果至少有一個被監控的key在執行exec命令前被修改,整個事物將會回滾,不執行任何動作,從而保證原子性操作,并且執行exec會得到null的回復,
7. Redis和Memcached的區別
Redis的特性:
- 速度快,因為資料存在記憶體中,類似于HashMap,HashMap的優勢就是查找和操作的時間復雜度都是O(1)
- 支持豐富資料型別,支持字串、鏈表、哈希、集合和有序集合
- 支持事務,操作都是原子性,所謂的原子性就是對資料的更改要么全部執行,要么全部不執行
- 豐富的特性:可用于快取,訊息,按key設定過期時間,過期后將會自動洗掉
與Memcached的區別在于:
- 存盤方式 Memecache把資料全部存在記憶體之中,斷電后會掛掉,資料不能超過記憶體大小,Redis有部分存在硬碟上,這樣能保證資料的持久性,
- 資料支持型別 Memcache對資料型別支持相對簡單,Redis有復雜的資料型別,
- 使用底層模型不同 它們之間底層實作方式 以及與客戶端之間通信的應用協議不一樣,
Redis直接自己構建了VM(Virtual Memory)機制 ,因為一般的系統呼叫系統函式的話(例如java呼叫自己的API),會浪費一定的時間去移動和請求,
8. 快取穿透、快取擊穿和快取雪崩
(1)快取穿透
查詢不存在的資料,快取中沒有資料,資料庫也沒有資料,因此所有的請求都訪問到了資料庫,給資料庫造成了壓力,解決方法如下:
采用布隆過濾器,將所有可能存在的資料,哈希到一個很大的 bitmap 中,一個一定不存在的資料會被 bitmap 攔截調,從而避免了對資料庫的查詢壓力,
如果查詢的資料為空,那么直接將空資料也快取起來并設定較短的過期時間,這樣下次訪問的時候,就直接回傳空值,
(2)快取擊穿
快取擊穿是指快取過期之后,瞬時間并發客戶端特別多查詢同一條資料的情況下,導致資料庫壓力過大,業界比較常用的做法,是使用mutex,簡單地來說,就是在快取失效的時候(判斷拿出來的值為空),不是立即去load db,
而是先使用快取工具的某些帶成功操作回傳值的操作(比如Redis的SETNX或者Memcache的ADD)去set一個mutex key,當操作回傳成功時,
再進行load db的操作并回設快取;否則,就重試整個get快取的方法,類似下面的代碼:
public String get(String key) {
String value = https://www.cnblogs.com/smallroll/p/redis.get(key);
if (value == null) { // 代表快取值過期
// 設定3min的超時,防止del操作失敗的時候,下次快取過期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { // 代表設定成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
}
// 這個時候代表同時候的其他執行緒已經load db并回設到快取了,
// 這時候重試獲取快取值即可
else {
sleep(50);
get(key); // 重試
}
} else {
return value;
}
}
(3)快取雪崩
雪崩就是指快取中大批量熱點資料過期后系統涌入大量查詢請求,因為大部分資料在Redis層已經失效,請求滲透到資料庫層,大批量請求猶如洪水一般涌入,引起資料庫壓力造成查詢堵塞甚至宕機,
解決辦法:
將快取失效時間分散開,比如每個key的過期時間是隨機,防止同一時間大量資料過期現象發生,這樣不會出現同一時間全部請求都落在資料庫層,如果快取資料庫是分布式部署,將熱點資料均勻分布在不同Redis和資料庫中,有效分擔壓力,別一個人扛,
讓Redis資料永不過期(如果業務準許),
9.Redis的資料傾斜
1、存在bigkey: 業務層避免創建bigkey,把集合型別的bigkey拆分成多個小集合,分散保存bigkey 保存了大量集合元素(集合型別),會導致這個實體的資料量增加,記憶體資源消耗也相應增加,bigkey 的操作一般都會造成實體 IO 執行緒阻塞,如果 bigkey 的訪問量比較大,就會影響到這個實體上的其它請求被處理的速度,
2、slot手工分配不均勻: 避免把較多的slot分配到一個實體上,進行槽的遷移
3、存在熱點資料: 采用帶有不同key前綴的多副本方法, 我們把熱點資料復制多份,在每一個資料副本的 key 中增加一個隨機前綴,讓它和其它副本資料不會被映射到同一個 Slot 中,這樣一來, 熱點資料既有多個副本可以同時服務請求,同時,這些副本資料的 key 又不一樣,會被映射到不同的 Slot 中,在給這些 Slot 分配實體時, 我們也要注意把它們分配到不同的實體上,那么,熱點資料的訪問壓力就被分散到不同的實體上了, 熱點資料多副本方法只能針對只讀的熱點資料,如果熱點資料是有讀有寫的話,就不適合采用多副本方法了,因為要保證多副本間的資料一致性,會帶來額外的開銷,
10.為什么Redis單執行緒模型也能效率這么高?
- 純記憶體操作;
- 核心是基于非阻塞的IO多路復用機制;
- 底層使用C語言實作,一般來說,C 語言實作的程式"距離"作業系統更近,執行速度相對會更快;
- 單執行緒同時也避免了多執行緒的背景關系頻繁切換問題,預防了多執行緒可能產生的競爭問題,
11.Redis做異步和延時佇列?
一般使用 list 結構作為佇列,rpush 生產訊息,lpop 消費訊息,當 lpop 沒有訊息的時候,要適當 sleep 一會再重試,如果對方追問可不可以不用 sleep 呢?list 還有個指令叫 blpop,在沒有訊息的時候,它會阻塞住直到訊息到來,如果對 方追問能不能生產一次消費多次呢?使用 pub/sub 主題訂閱者模式,可以實作 1:N 的訊息佇列,
使用 zset(有序集合),拿時間戳作為score,訊息內容作為 key 呼叫 zadd 來生產訊息,消費者用 zrangebyscore 指令獲取 N 秒之前的資料輪詢進行處理,
12.Redis的集群策略
(1)Redis主從同步Redis的主從結構一主一從,一主多從或級聯結構,復制型別可以根據是否是全量而分為全量同步和增量同步,
(2)Redis哨兵 在主從復制實作之后,如果想對master進行監控,Redis提供了一種哨兵機制,哨兵的含義就是監控Redis系統的運行狀態,并做相應的回應,Redis Sentinal 著眼于高可用,在 master 宕機時會自動將 slave 提升為master,繼續提供服務,
(3)Redis Cluster 著眼于擴展性,在單個 redis 記憶體不足時,使用 Cluster 進行分片存盤,在redis-cluster架構中,redis-master節點一般用于接收讀寫,而redis-slave節點則一般只用于備份,其與對應的master擁有相同的slot集合,若某個redis-master意外失效,則再將其對應的slave進行升級為臨時redis-master,
13.Redis的同步機制
Redis 可以使用主從同步,從從同步,第一次同步時,主節點做一次 bgsave,并同時將后續修改操作記錄到記憶體 buffer,待完成后將 rdb 檔案全量同步到復制節點,復制節點接受完成后將 rdb 鏡像加載到記憶體,加載完成后,再通知主節點
將期間修改的操作記錄同步到復制節點進行重放就完成了同步程序,
總結
如果覺得文章不錯點贊收藏轉發好評噢!!!創作不易,你的支持是我創作的最大動力!!!
本文來自博客園,作者:SmallRoll(小卷),轉載請注明原文鏈接:https://www.cnblogs.com/smallroll/p/17159038.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/545162.html
標籤:Java