Nacos
Nacos體系架構
領域模型
Nacos 領域模型描述了服務與實體之間的邊界和層級關系,Nacos 的服務領域模型是以“服 務”為維度構建起來的,這個服務并不是指集群中的單個服務器,而是指微服務的服務名,
“服務”是 Nacos 中位于最上層的概念,在服務之下,還有集群和實體的概念,
-
服務
在服務這個層級上可以配置元資料和服務保護閾值等資訊,服務閾值是一個 0~1 之間的 數字,當服務的健康實體數與總實體的比例小于這個閾值的時候,說明能提供服務的機器已經 沒多少了,這時候 Nacos 會開啟服務保護模式,不再主動剔除服務實體,同時還會將不健康 的實體也回傳給消費者,
-
集群
一個服務由很多服務實體組成,在每個服務實體啟動的時候,可以設定它所屬的集群,在 集群這個層級上,也可以配置元資料,除此之外,還可以為持久化節點設定健康檢查 模式,
所謂持久化節點,是一種會保存到 Nacos 服務端的實體,即便該實體的客戶端行程沒有在運 行,實體也不會被服務端洗掉,只不過 Nacos 會將這個持久化節點狀態標記為不健康, Nacos 可以采用一種“主動探活”的方式來對持久化節點做健康檢查,
除了持久化節點以外,大部分服務節點在 Nacos 中以“臨時節點”的方式存在,它是默認的 服務注冊方式,從名字中就可以看出,這種節點不會被持久化保存在 Nacos 服務器,臨 時節點通過主動發送 heartbeat 請求向服務器報送自己的狀態,
-
實體
這里所說的實體就是指服務節點,可以在 Nacos 控制臺查看每個實體的 IP 地址和埠、 編輯實體的元資料資訊、修改它的上線 / 下線狀態或者配置路由權重等等,
在這三個層級上都有“元資料”這一資料結構,可以把它理解為一組包含了服務 描述資訊(如服務版本等)和自定義標簽的資料集合,Client 端通過服務發現技術可以獲取到 每個服務實體的元資料,可以將自定義的屬性加入到元資料并在 Client 端實作某些定制化 的業務場景,
資料模型
Nacos 的資料模型有三個層次結構,分別是 Namespace、Group 和 Service/DataId,
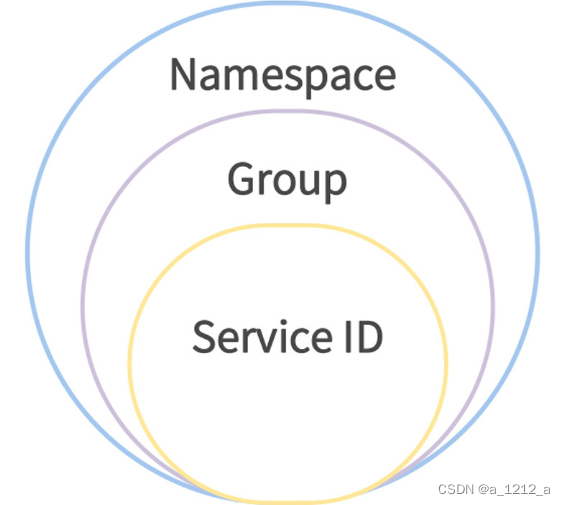
- Namespace:即命名空間,它是最頂層的資料結構,可以用它來區分開發環境、生產 環境等不同環境,默認情況下,所有服務都部署到一個叫做“public”的公共命名空間;
- Group:在命名空間之下有一個分組結構,默認情況下所有微服務都屬于 “DEFAULT_GROUP”這個分組,不同分組間的微服務是相互隔離的;
- Service/DataID:在 Group 分組之下,就是具體的微服務了,比如訂單服務、商品服務等等,
通過 Namespace + Group + Service/DataID,就可以精準定位到一個具體的微服務
Nacos 基本架構
Nacos 的核心功能有兩個,一個是 Naming Service,用來做服務發現的模塊;另 一個是 Config Service,用來提供配置項管理、動態更新配置和元資料的功能
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-OFQ0pyt6-1677596762818)(C:\Users\0\AppData\Roaming\Typora\typora-user-images\image-20230226225644390.png)]](https://img.uj5u.com/2023/03/01/340789010709512.png)
Provider APP 和 Consumer APP 通過 Open API 和 Nacos 服務 器的核心模塊進行通信,這里的 Open API 是一組對外暴露的 RESTful 風格的 HTTP 介面,
在 Nacos 和核心模塊里,Naming Service 提供了將物件和物體的“名字”映射到元資料的 功能,這是服務發現的基礎功能之一,
Nacos 還有一個相當重要的模塊:Nacos Core 模塊,它可以提供一系列的平臺基礎功能, 是支撐 Nacos 上層業務場景的基石
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-49FknCy3-1677596762818)(E:\BaiduNetdiskDownload\180SpringCloud微服務專案實戰\images\472384\d0c78d0c0f2bb72c45788a5c2d423512.jpg)]](https://img.uj5u.com/2023/03/01/340789010709513.png)
Nacos集群環境搭建
Nacos Server 的安裝包可以從 Alibaba 官方 GitHub 中的Release 頁面下載,
下載完成后,可以在本地將 Nacos Server 壓縮包解壓,并將解壓后的目錄名改為“nacos-cluster1”,再復制一份同樣的檔案到 nacos-cluster2,以此來模擬一個由兩臺 Nacos Server 組成的集群,
修改啟動項引數
Nacos Server 的啟動項位于 conf 目錄下的 application.properties 檔案里,需要修改服務啟動埠和資料庫連接
Nacos Server 的啟動埠由 server.port 屬性指定,默認埠是 8848,在 nacos-cluster1 中仍然使用 8848 作為默認埠,需要把 nacos-cluster2 中的埠號改為 8948
在默認情況下,Nacos Server 會使用 Derby 作為資料源,用于保存配置管理資料,將 Nacos Server 的資料源遷移到更加穩定的 MySQL 資料庫中,需要修改三處 Nacos Server 的資料庫配置,
指定資料源:spring.datasource.platform=mysql 將這行注釋放開;
指定 DB 實體數:放開 db.num=1 這一行的注釋;
修改 JDBC 連接串:db.url.0 指定了資料庫連接字串,db.user.0 和 db.password.0 分別指定了連接資料庫的用戶名和密碼
創建資料庫表
Nacos 已經把建表陳述句放在解壓后的 Nacos Server 安裝目錄中下的 conf 檔案夾里
添加集群機器串列
Nacos Server 可以從一個本地組態檔中獲取所有的 Server 地址資訊,從而實作服務器之 間的資料同步,
在 Nacos Server 的 conf 目錄下創建 cluster.conf 檔案,并將 nacos-cluster1 和 nacos-cluster2 這兩臺服務器的 IP 地址 + 埠號添加到檔案中,
## 注意,這里的IP不能是localhost或者127.0.0.1
192.168.1.100:8848
192.168.1.100:8948
啟動 Nacos Server
通過 -m standalone 引數,可以單機模式啟動,
Nacos 的啟動腳本位于安裝目錄下的 bin 檔案夾,其中 Windows 作業系統對應的啟動腳本和關閉腳本分別是 startup.cmd 和 shutdown.cmd, Mac 和 Linux 系統對應的啟動和關閉腳本是 startup.sh 和 shutdown.sh,
登錄 Nacos 控制臺
使用 Nacos 默認創建好的用戶 nacos 登錄系統,用戶名和密碼都是 nacos,
為了驗證集群環境處于正常狀態,可以在左側導航欄中打開“集群管理”下的“節點串列” 頁面,在這個頁面上顯示了集群環境中所有的 Nacos Server 節點以及對應的狀態,它們的節點狀態都是綠色的“UP”,這表示搭建的集群環境一切正常,
在實際的專案中,如果某個微服務 Client 要連接到 Nacos 集群做服務注冊,并不會把 Nacos 集群中的所有服務器都配置在 Client 中,否則每次 Nacos 集群增加或洗掉了節點, 都要對所有 Client 做一次代碼變更并重新發布,
常見的一個做法是提供一個 VIP URL 給到 Client,VIP URL 是一個虛擬 IP 地址,可以把 真實的 Nacos 服務器地址串列“隱藏”在虛擬 IP 后面,客戶端只需要連接到虛 IP 即可,由 提供虛 IP 的組件負責將請求轉發給背后的服務器串列,這樣一來,即便 Nacos 集群機器數量 發生了變動,也不會對客戶端造成任何感知,
提供虛 IP 的技術手段有很多,比如通過搭建 Nginx+LVS 或者 keepalived 技術實作高可用集群,
將服務提供者注冊到 Nacos 服務器
添加 Nacos 依賴項
Spring Boot、Spring Cloud 和 Spring Cloud Alibaba 三者之間有嚴格的版本匹配關系
版本說明: link
將 Spring Cloud Alibaba 和 Spring Cloud 的依賴項版本添加到頂層專案下的 pom.xml 檔案中,
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2020.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
<!-- 省略部分代碼 -->
</dependencyManagement>
定義了組件的大版本之后,就可以直接把 Nacos 的依賴項加入到兩個子模塊的 pom.xml 檔案中
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
在添加完依賴項之后,就可以通過配置項開啟 Nacos 的服務治理功能了,Spring Cloud 各個組件都采用了自動裝配器實作了輕量級的組件集成功能,只需要幾行配置,剩下的初始化作業都可以交給背后的自動裝配器來實作,
Nacos 自動裝配原理
在 Spring Cloud 稍早一些的版本中,需要在啟動類上添加 @EnableDiscoveryClient 注 解開啟服務治理功能,而在新版本的 Spring Cloud 中,這個注解不再是一個必須的步驟, 們只需要通過配置項就可以開啟 Nacos 的功能,
們將 Nacos 依賴項添加到專案中,同時也引入了 Nacos 自帶的自動裝配器,比如下面這幾 個被引入的自動裝配器就掌管了 Nacos 核心功能的初始化任務,
NacosDiscoveryAutoConfiguration:服務發現功能的自動裝配器,它主要做兩件事 兒:加載 Nacos 配置項,宣告 NacosServiceDiscovery 類用作服務發現;
NacosServiceAutoConfiguration:宣告核心服務治理類 NacosServiceManager,它可以通過 service id、group 等一系列引數獲取已注冊的服務串列;
NacosServiceRegistryAutoConfiguration:Nacos 服務注冊的自動裝配器,
添加 Nacos 配置項
spring:
cloud:
nacos:
discovery:
# Nacos的服務注冊地址,可以配置多個,逗號分隔
server-addr: localhost:8848
# 服務注冊到Nacos上的名稱,一般不用配置
service: coupon-customer-serv
# nacos客戶端向服務端發送心跳的時間間隔,時間單位其實是ms
heart-beat-interval: 5000
# 服務端沒有接受到客戶端心跳請求就將其設為不健康的時間間隔,默認為15s
# 注:推薦值該值為15s即可,如果有的業務線希望服務下線或者出故障時希望盡快被發現,可以適
heart-beat-timeout: 20000
# 元資料部分 - 可以自己隨便定制
metadata:
mydata: abc
# 客戶端在啟動時是否讀取本地配置項(一個檔案)來獲取服務串列
# 注:推薦該值為false,若改成true,則客戶端會在本地的一個
# 檔案中保存服務資訊,當下次宕機啟動時,會優先讀取本地的配置對外提供服務,
naming-load-cache-at-start: false
# 命名空間ID,Nacos通過不同的命名空間來區分不同的環境,進行資料隔離,
namespace: dev
# 創建不同的集群
cluster-name: Cluster-A
# [注意]兩個服務如果存在上下游呼叫關系,必須配置相同的group才能發起訪問
group: myGroup
# 向注冊中心注冊服務,默認為true
# 如果只消費服務,不作為服務提供方,倒是可以設定成false,減少開銷
register-enabled: true
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-ri6Gpvkn-1677596762819)(E:\BaiduNetdiskDownload\180SpringCloud微服務專案實戰\images\473988\bd3383d12b43a35cfc3c240386c3e0f8.jpg)]](https://img.uj5u.com/2023/03/01/340789010709514.png)
Namespace 可以用作環境隔離或者多租戶隔離,其中:
環境隔離:比如設定三個命名空間 production、pre-production 和 dev,分別表示生產 環境、預發環境和開發環境,如果一個微服務注冊到了 dev 環境,那么他無法呼叫其他環 境的服務,因為服務發現機制只會獲取到同樣注冊到 dev 環境的服務串列,如果未指定 namespace 則服務會被注冊到 public 這個默認 namespace 下,
多租戶隔離:即 multi-tenant 架構,通過為每一個用戶提供獨立的 namespace 以實作租 戶與租戶之間的環境隔離,
Group 的使用場景非常靈活,列舉幾個:
環境隔離:在多租戶架構之下,由于 namespace 已經被用于租戶隔離,為了實作同一個租 戶下的環境隔離,可以使用 group 作為環境隔離變數,
線上測驗:對于涉及到上下游多服務聯動的場景,將線上已部署的待上下游測服務的 group 設定為“group-A”,由于這是一個新的獨立分組,所以線上的用戶流量不會導向 到這個 group,這樣一來,開發人員就可以在不影響線上業務的前提下,通過發送測驗請 求到“group-A”的機器完成線上測驗,
什么是單元封閉呢?為了保證業務的高可用性,通常會把同一個服務部署在 不同的物理單元(比如張北機房、杭州機房、上海機房),當某個中心機房出現故障的時 候,可以在很短的時間內把用戶流量切入其他單元機房,由于同一個單元內的服務器資 源通常部署在同一個物理機房,因此本單元內的服務呼叫速度最快,而跨單元的服務呼叫將 要承擔巨大的網路等待時間,這種情況下,可以為同一個單元的服務設定相同的 group,使微服務呼叫封閉在當前單元內,提高業務回應速度,
服務呼叫
服務消費者添加Nacos依賴項和配置資訊
<!-- Nacos服務發現組件 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- 負載均衡組件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!-- webflux服務呼叫 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
- spring-cloud-starter-loadbalancer:Spring Cloud御用負載均衡組件Loadbalancer,用來代替已經進入維護狀態的Netflix Ribbon組件,會在下一課帶深入了解Loadbalancer的功能,今天只需要簡單了解下它的用法就可以了;
- spring-boot-starter-webflux:Webflux是Spring Boot提供的回應式編程框架,回應式編程是基于異步和事件驅動的非阻塞程式,Webflux實作了Reactive Streams規范,內置了豐富的回應式編程特性,今天將用Webflux組件中一個叫做WebClient的小工具發起遠程服務呼叫,
Nacos服務發現底層實作
Nacos Client通過一種 主動輪詢 的機制從Nacos Server獲取服務注冊資訊,包括地址串列、group分組、cluster名稱等一系列資料,簡單來說,Nacos Client會開啟一個本地的定時任務,每間隔一段時間,就嘗試從Nacos Server查詢服務注冊表,并將最新的注冊資訊更新到本地,這種方式也被稱之為“Pull”模式,即客戶端主動從服務端拉取的模式,
負責拉取服務的任務是UpdateTask類,它實作了Runnable介面,Nacos以開啟執行緒的方式呼叫UpdateTask類中的run方法,觸發本地的服務發現查詢請求,
UpdateTask這個類是HostReactor的一個內部類,
在UpdateTask的原始碼中,它通過呼叫updateService方法實作了服務查詢和本地注冊表更新,在每次任務執行結束的時候,在結尾處它通過finally代碼塊設定了下一次executor查詢的時間,周而復始回圈往復,
OpenFeign
OpenFeign提供了一種宣告式的遠程呼叫介面,它可以大幅簡化遠程呼叫的編程體驗,
OpenFeign使用了一種“動態代理”技術來封裝遠程服務呼叫的程序,遠程服務呼叫的資訊被寫在了FeignClient介面中
OpenFeign的動態代理
在專案初始化階段,OpenFeign會生成一個代理類,對所有通過該介面發起的遠程呼叫進行動態代理,
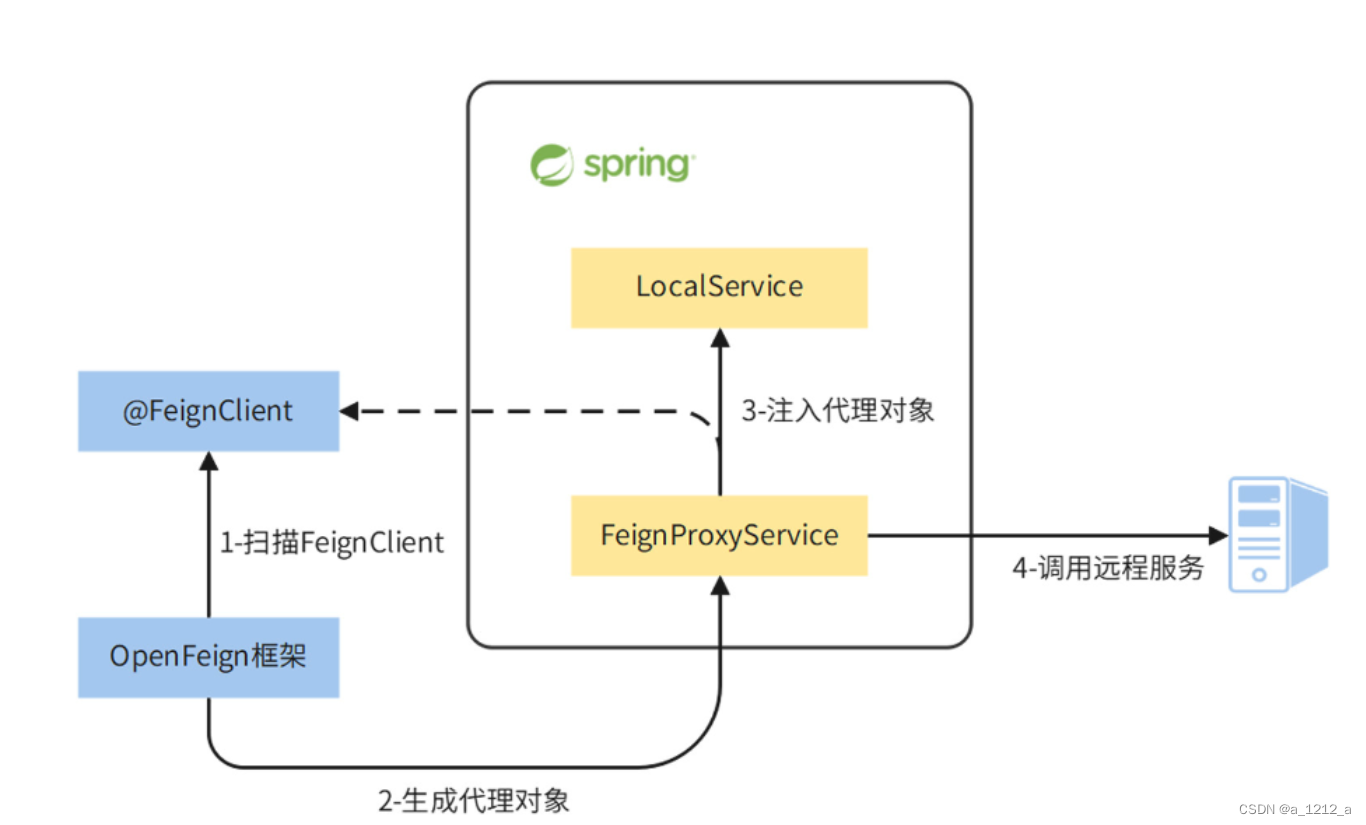
- 專案加載:在專案的啟動階段, EnableFeignClients注解 扮演了“啟動開關”的角色,它使用Spring框架的 Import注解 匯入了FeignClientsRegistrar類,開始了OpenFeign組件的加載程序,
- 掃包: FeignClientsRegistrar 負責FeignClient介面的加載,它會在指定的包路徑下掃描所有的FeignClients類,并構造FeignClientFactoryBean物件來決議FeignClient介面,
- 決議FeignClient注解: FeignClientFactoryBean 有兩個重要的功能,一個是決議FeignClient介面中的請求路徑和降級函式的配置資訊;另一個是觸發動態代理的構造程序,其中,動態代理構造是由更下一層的ReflectiveFeign完成的,
- 構建動態代理物件:ReflectiveFeign 包含了OpenFeign動態代理的核心邏輯,它主要負責創建出FeignClient介面的動態代理物件,ReflectiveFeign在這個程序中有兩個重要任務,一個是決議FeignClient介面上各個方法級別的注解,將其中的遠程介面URL、介面型別(GET、POST等)、各個請求引數等封裝成元資料,并為每一個方法生成一個對應的MethodHandler類作為方法級別的代理;另一個重要任務是將這些MethodHandler方法代理做進一步封裝,通過Java標準的動態代理協議,構建一個實作了InvocationHandler介面的動態代理物件,并將這個動態代理物件系結到FeignClient介面上,這樣一來,所有發生在FeignClient介面上的呼叫,最終都會由它背后的動態代理物件來承接,
MethodHandler的構建程序涉及到了復雜的元資料決議,OpenFeign組件將FeignClient介面上的各種注解封裝成元資料,并利用這些元資料把一個方法呼叫“翻譯”成一個遠程呼叫的Request請求,
那么上面說到的“元資料的決議”是如何完成的呢?它依賴于OpenFeign組件中的Contract協議決議功能,Contract是OpenFeign組件中定義的頂層抽象介面,它有一系列的具體實作,
專門用來決議Spring MVC標簽的SpringMvcContract類的繼承結構是SpringMvcContract->BaseContract->Contract,
OpenFeign的作業流程的重點是 動態代理機制,OpenFeing通過Java動態代理生成了一個“代理類”,這個代理類將介面呼叫轉化成為了一個遠程服務呼叫,
FeignClientsRegistrar是OpenFeign初始化的起點
實作服務間呼叫功能
把依賴項spring-cloud-starter-OpenFeign添加到子模塊內的pom.xml檔案中,
<!-- OpenFeign組件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
在介面上宣告了一個FeignClient注解,它專門用來標記被OpenFeign托管的介面,
@FeignClient(value = "https://www.cnblogs.com/ccvc/archive/2023/02/28/coupon-template-serv", path = "/template")
public interface TemplateService {
// 讀取優惠券
@GetMapping("/getTemplate")
CouponTemplateInfo getTemplate(@RequestParam("id") Long id);
// 批量獲取
@GetMapping("/getBatch")
Map<Long, CouponTemplateInfo> getTemplateInBatch(@RequestParam("ids") Collection<Long> ids);
}
在FeignClient注解中宣告的value屬性是目標服務的名稱,需要確保這里的服務名稱和Nacos服務器上顯示的服務注冊名稱是一樣的,
配置OpenFeign的加載路徑
@EnableFeignClients(basePackages = {"com.xxx"})
public class Application {
}
在EnableFeignClients注解的basePackages屬性中定義了一個com.xxx的包名,這個注解就會告訴OpenFeign在啟動專案的時候做一件事兒:找到所有位于com.xxx包路徑(包括子package)之下使用FeignClient修飾的介面,然后生成相關的代理類并添加到Spring的背景關系中,這樣才能夠在專案中用Autowired注解注入OpenFeign介面,
日志資訊列印
服務請求的入參和出參是分析和排查問題的重要線索,為了獲得服務請求的引數和回傳值,經常使用的一個做法就是 列印日志
首先,需要在組態檔中 指定FeignClient介面的日志級別為Debug,這樣做是因為OpenFeign組件默認將日志資訊以debug模式輸出,而默認情況下Spring Boot的日志級別是Info
接下來,還需要在應用的背景關系中使用代碼的方式 宣告Feign組件的日志級別,這里的日志級別并不是傳統意義上的Log Level,它是OpenFeign組件自定義的一種日志級別,用來控制OpenFeign組件向日志中寫入什么內容,
@Bean
Logger.Level feignLogger() {
return Logger.Level.FULL;
}
OpenFeign總共有四種不同的日志級別
- NONE:不記錄任何資訊,這是OpenFeign默認的日志級別;
- BASIC:只記錄服務請求的URL、HTTP Method、回應狀態碼(如200、404等)和服務呼叫的執行時間;
- HEADERS:在BASIC的基礎上,還記錄了請求和回應中的HTTP Headers;
- FULL:在HEADERS級別的基礎上,還記錄了服務請求和服務回應中的Body和metadata,FULL級別記錄了最完整的呼叫資訊,
超時判定
超時判定是一種保障可用性的手段,
為了隔離下游介面呼叫超時所帶來的的影響,可以在程式中設定一個 超時判定的閾值,一旦下游介面的回應時間超過了這個閾值,那么程式會自動取消此次呼叫并回傳一個例外,
feign:
client:
config:
# 全域超時配置
default:
# 網路連接階段1秒超時
connectTimeout: 1000
# 服務請求回應階段5秒超時
readTimeout: 5000
# 針對某個特定服務的超時配置
coupon-template-serv:
connectTimeout: 1000
readTimeout: 2000
降級
降級邏輯是在遠程服務呼叫發生超時或者例外(比如400、500 Error Code)的時候,自動執行的一段業務邏輯,
OpenFeign實作Client端的服務降級相比于Sentinel而言 更加輕量級且容易實作, 足以滿足一些簡單的服務降級業務需求,
OpenFeign對服務降級的支持是借助Hystrix組件實作的,由于Hystrix已經從Spring Cloud組件庫中被移除,所以要在pom檔案中手動添加hystrix專案的依賴,
<!-- hystrix組件,專門用來演示OpenFeign降級 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.2.10.RELEASE</version>
<exclusions>
<!-- 移除Ribbon負載均衡器,避免沖突 -->
<exclusion>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-ribbon</artifactId>
</exclusion>
</exclusions>
</dependency>
OpenFeign支持兩種不同的方式來指定降級邏輯,一種是定義fallback類,另一種是定義fallback工廠,
通過fallback類實作降級是最為簡單的一種途徑,如果想要為FeignClient介面指定一段降級流程,可以定義一個降級類并實作介面,并在介面中指定為降級類,
@FeignClient(value = "https://www.cnblogs.com/ccvc/archive/2023/02/28/coupon-template-serv", path = "/template",
// 通過fallback指定降級邏輯
fallback = TemplateServiceFallback.class)
如果想要在降級方法中獲取到 例外的具體原因,那么就要借助 fallback工廠 的方式來指定降級邏輯了,按照OpenFeign的規范,自定義的fallback工廠需要實作FallbackFactory介面
@FeignClient(value = "https://www.cnblogs.com/ccvc/archive/2023/02/28/coupon-template-serv", path = "/template",
// 通過抽象工廠來定義降級邏輯
fallbackFactory = TemplateServiceFallbackFactory.class)
配置中心
分布式配置中心在配置管理方面發揮的作用
高可用性: 微服務組件的高可用性是首要目標,配置中心并不是一個中心化的單點應用,而是一個通過集群對外提供服務的組件,在一致性演算法的基礎上,集群中各個節點之間會互相同步配置資料,或者從統一資料源讀取配置資料,即便個別節點掛掉,也不影響整個集群的可用性;
環境隔離特性:Nacos支持通過Namespace屬性指定當前配置項所在的環境,可以為自己的應用系統創建開發環境、預發環境和生產環境,不同環境之間的組態檔是相互隔離的;
多格式支持:Nacos支持多種不同格式的配置內容,可以使用純文本、JSON、XML、YAML和Properties多種檔案后綴;
訪問控制:Nacos實作了權限管理功能,可以在控制臺創建用戶賬號和權限組,限制某個賬號可以訪問哪些命名空間,并配置賬號的讀寫權限(只讀、只寫、讀寫),通過這種方式,可以保障敏感資訊(如資料庫用戶名和密碼)的安全;
職責分離:配置項從jar包中抽離了出來,修改配置項再也不需要重新編譯打包應用程式了,完美實作了配置項管理與業務代碼之間的職責分離;
版本控制和審計功能:配置項也是一種代碼,而且配置bug往往比代碼中的bug造成的影響更大,因此,在微服務架構中需要確保配置中心具備完善的版本控制和審計功能
Nacos還可以支持 多檔案源讀取以及運行期配置變更,尤其是 動態變更推送,更是微服務架構下不可或缺的配置管理能力,
添加依賴項
<!-- 添加Nacos Config配置項 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- 讀取bootstrap檔案 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
Nacos配置中心的連接資訊需要配置在bootstrap檔案,而非application.yml檔案中,在Spring Cloud 2020.0.0版本之后,bootstrap檔案不會被自動加載,需要主動添加依賴項,來開啟bootstrap的自動加載流程,
為什么集成Nacos配置中心必須用到bootstrap組態檔呢?為了保證其他應用能夠正常啟動,必須 在其它組件初始化之前從Nacos讀到所有配置項,之后再將獲取到的配置項用于后續的初始化流程,
添加本地Nacos Config配置項
需要在bootstrap.yml檔案中添加一些Nacos Config配置項
spring:
# 必須把name屬性從application.yml遷移過來,否則無法動態重繪
application:
name: coupon-customer-serv
cloud:
nacos:
config:
# nacos config服務器的地址
server-addr: localhost:8848
file-extension: yml
# prefix: 檔案名前綴,默認是spring.application.name
# 如果沒有指定命令空間,則默認命令空間為PUBLIC
namespace: dev
# 如果沒有配置Group,則默認值為DEFAULT_GROUP
group: DEFAULT_GROUP
# 從Nacos讀取配置項的超時時間
timeout: 5000
# 長輪詢超時時間
config-long-poll-timeout: 10000
# 輪詢的重試時間
config-retry-time: 2000
# 長輪詢最大重試次數
max-retry: 3
# 開啟監聽和自動重繪
refresh-enabled: true
# Nacos的擴展配置項,數字越大優先級越高
extension-configs:
- dataId: redis-config.yml
group: EXT_GROUP
# 動態重繪
refresh: true
- dataId: rabbitmq-config.yml
group: EXT_GROUP
refresh: true
長輪詢機制 的作業原理
當Client向Nacos Config服務端發起一個配置查詢請求時,服務端并不會立即回傳查詢結果,而是會將這個請求hold一段時間,如果在這段時間內有配置項資料的變更,那么服務端會觸發變更事件,客戶端將會監聽到該事件,并獲取相關配置變更;如果這段時間內沒有發生資料變更,那么在這段“hold時間”結束后,服務端將釋放請求,
采用長輪詢機制可以降低多次請求帶來的網路開銷,并降低更新配置項的延遲,
動態配置推送
使用@Value注解將Nacos配置中心里的屬性注入進來,給屬性設定一個默認值,這樣做的目的是加一層容錯機制,即便Nacos Config連接例外無法獲取配置項,應用程式也可以使用默認值完成啟動加載,
最后,在類頭上添加一個RefreshScope注解,有了這個注解,Nacos Config中的屬性變動就會動態同步到當前類的變數中,如果不添加RefreshScope注解,即便應用程式監聽到了外部屬性變更,那么類變數的值也不會被重繪,
RefreshScope注解
為了實作動態重繪配置,主要就是想辦法達成以下兩個核心目標:
- 讓Spring容器重新加載Environment環境配置變數
- Spring Bean重新創建生成
@RefreshScope主要就是基于@Scope注解的作用域代理的基礎上進行擴展實作的,加了@RefreshScope注解的類,在被Bean工廠創建后會加入自己的refresh scope 這個Bean快取中,后續會優先從Bean快取中獲取,當配置中心發生了變更,會把變更的配置更新到spring容器的Environment中,并且同事bean快取就會被清空,從而就會從bean工廠中創建bean實體了,而這次創建bean實體的時候就會繼續經歷這個bean的生命周期,使得@Value屬性值能夠從Environment中獲取到最新的屬性值,這樣整個程序就達到了動態重繪配置的效果,
Sentinel
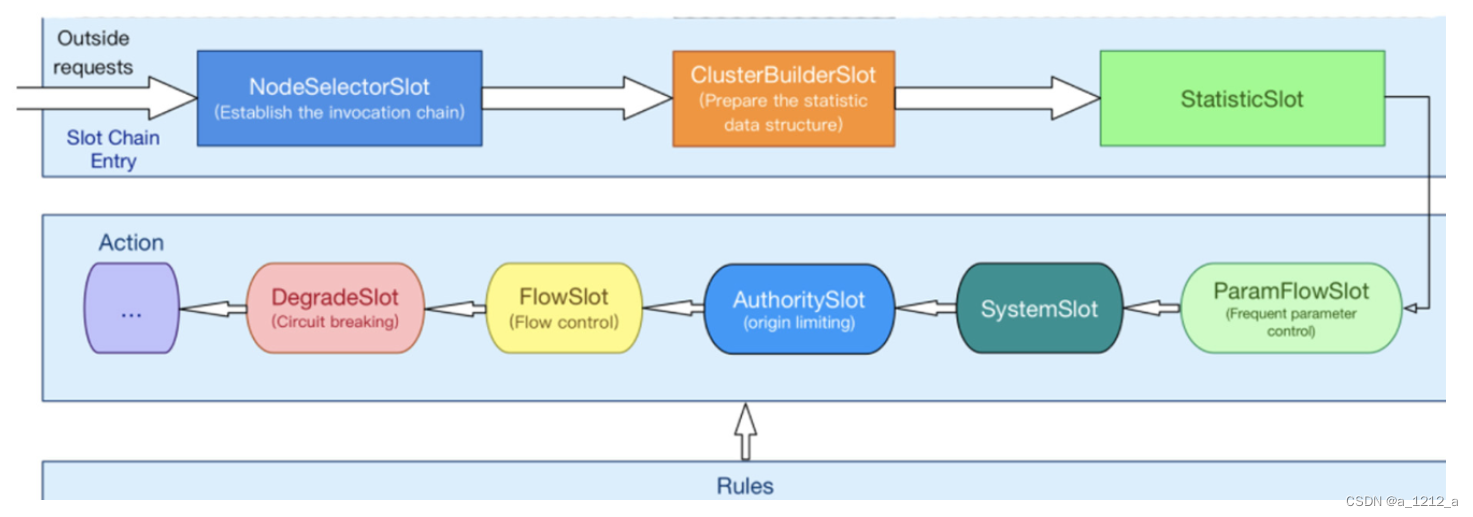
在Sentinel的世界中,萬物都是可以被保護的“資源”,當一個外部請求想要訪問Sentinel的資源時,便會創建一個Entry物件,經過Slot鏈路的層層考驗最終完成自己的業務,可以把Slot當成是一類完成特定任務的“Filter”, 這是一種典型的職責鏈設計模式,
在這些Slot中,有幾個是被專門用來 收集資料 的,比如:
NodeSelectorSlot 被用來構建當前請求的訪問路徑,它將上下游呼叫鏈串聯起來,形成了一個服務呼叫關系的樹狀結構,
ClusterBuilderSlot 和 StatisticSlot 這兩個Slot會從多個維度統計一些運行期資訊,比如介面回應時間、服務QPS、當前執行緒數等等,
由這幾個Slot統計出來的結果,會為后續的限流降級等Sentinel策略提供資料支持,
Sentinel還有很多被用作“規則判斷”的Slot,比如:
FlowSlot 被用來做流控規則的判定, DegradeSlot 被用來做降級熔斷判定,這兩個Slot是平時在專案中使用頻率最高的服務容錯功能,
ParamFlowSlot 可以根據請求引數做精細粒度的流控,它經常被用來在大型應用中控制熱點資料所帶來的突發流量,
AuthoritySlot 可以針對特定資源設定黑白名單,限制某些應用對資源的訪問,
除此之外,Sentinel的Slot機制也具備一定的擴展性,如果想要添加一個自定義的Slot,可以通過實作ProcessorSlot介面來完成,而且還可以通過優先級調整各個Slot之間的執行順序,
運行Sentinel控制臺
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.2.jar
將微服務接入到Sentinel控制臺
首先,需要把Sentinel的依賴項引入到專案里
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
然后,需要做一些基本的配置
spring:
cloud:
sentinel:
transport:
# sentinel api埠,默認8719
port: 8719
# dashboard地址
dashboard: localhost:8080
Sentinel會為Controller中的API生成一個默認的資源名稱,這個名稱就是URL的路徑,也可以使用特定的注解為資源打上一個指定的名稱標記,
@SentinelResource(value = "https://www.cnblogs.com/ccvc/archive/2023/02/28/getTemplateInBatch", blockHandler = "getTemplateInBatch_block")
注解中的blockHandler屬性為當前資源指定了限流后的降級方法,如果當前服務拋出了BlockException,那么就會轉而執行這段限流方法,
設定流控規則
Sentinel支持三種不同的流控模式,分別是直接流控、關聯流控和鏈路流控,
-
直接流控:直接作用于當前資源,如果訪問壓力大于某個閾值,后續請求將被直接攔下來;
-
關聯流控:當關聯資源的訪問量達到某個閾值時,對當前資源進行限流;
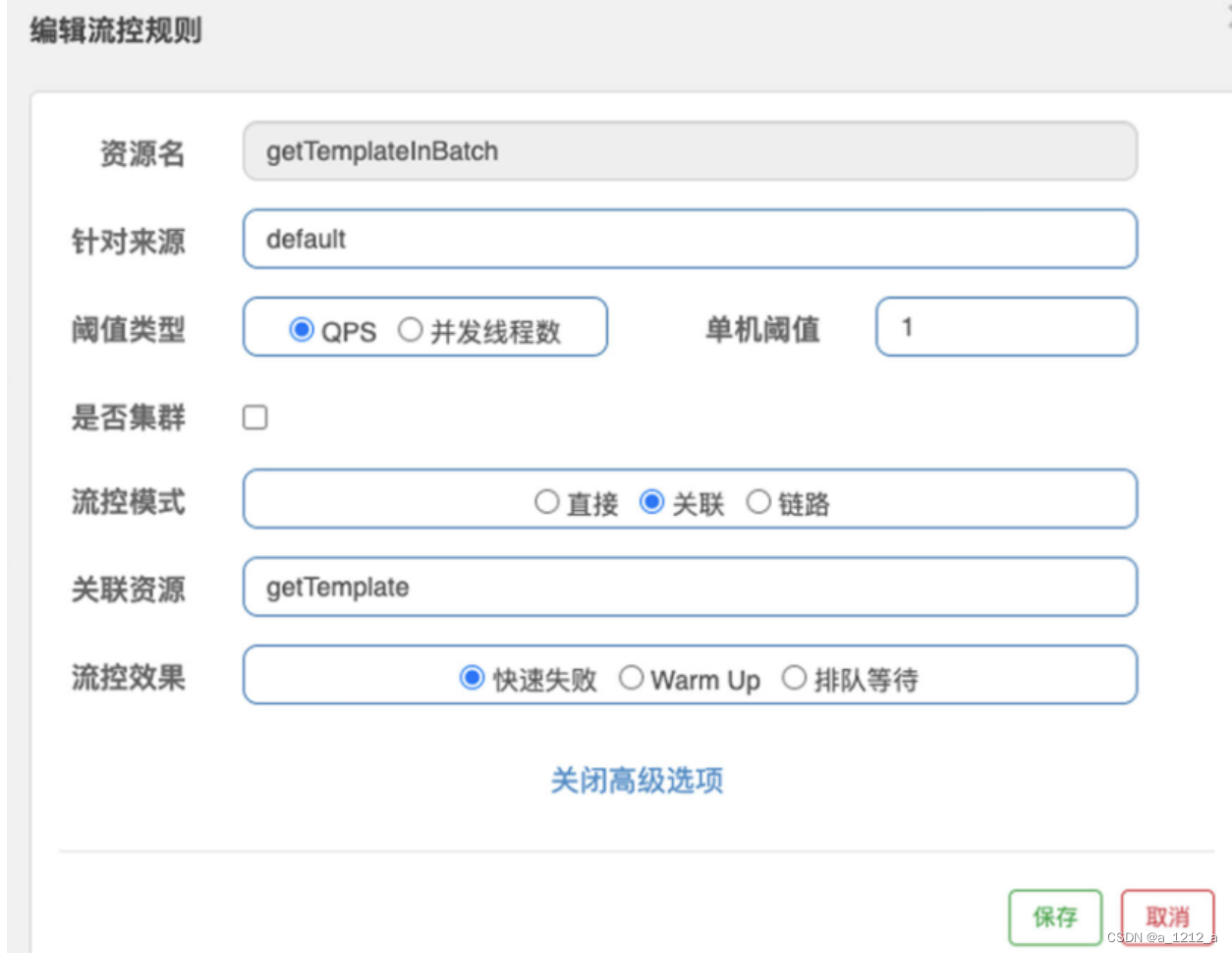
在“關聯資源”一欄填了getTemplate,寫在這里的是高優先級資源的名稱,同時,設定了閾值判斷條件為QPS=1,它的意思是,如果高優先級資源的訪問頻率達到了每秒一次,那么低優先級資源就會被限流,
關聯限流的閾值判斷是作用于高優先級資源之上的,但是流控效果是作用于低優先級資源之上,
-
鏈路流控:當指定鏈路上的訪問量大于某個閾值時,對當前資源進行限流,這里的“指定鏈路”是細化到API級別的限流維度,
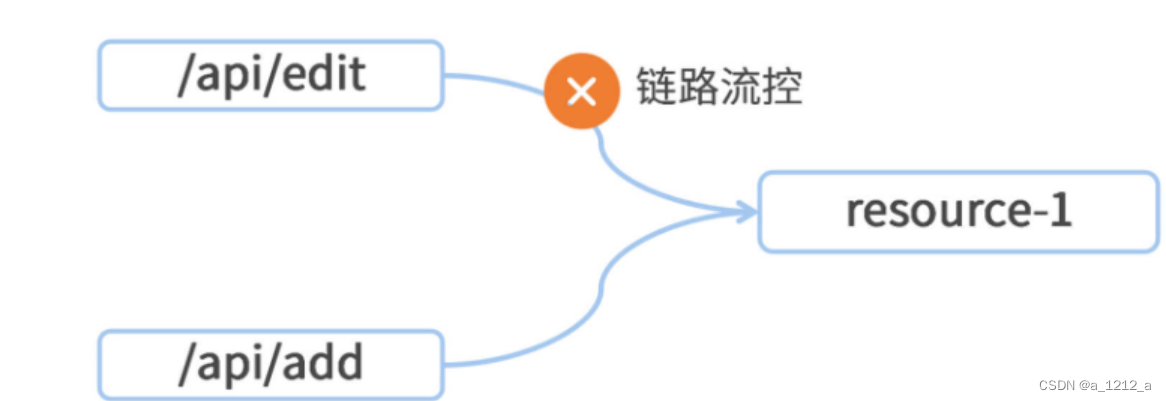
在上面的圖里,一個服務應用中有/api/edit和/api/add兩個介面,這兩個介面都呼叫了同一個資源resource-1,如果想只對/api/edit介面流進行限流,那么就可以將“鏈路流控”應用在resource-1之上,同時指定當前流控規則的“入口資源”是/api/edit,
實作針對呼叫源的限流
在微服務架構中,一個服務可能被多個服務呼叫,比如說,Customer服務會呼叫Template服務的getTemplateInBatch資源,未來可能會研發一個新的服務叫coupon-other-serv,它也會呼叫相同資源,
如果想為getTemplateInBatch資源設定一個限流規則,并指定其只對來自Customer服務的呼叫起作用
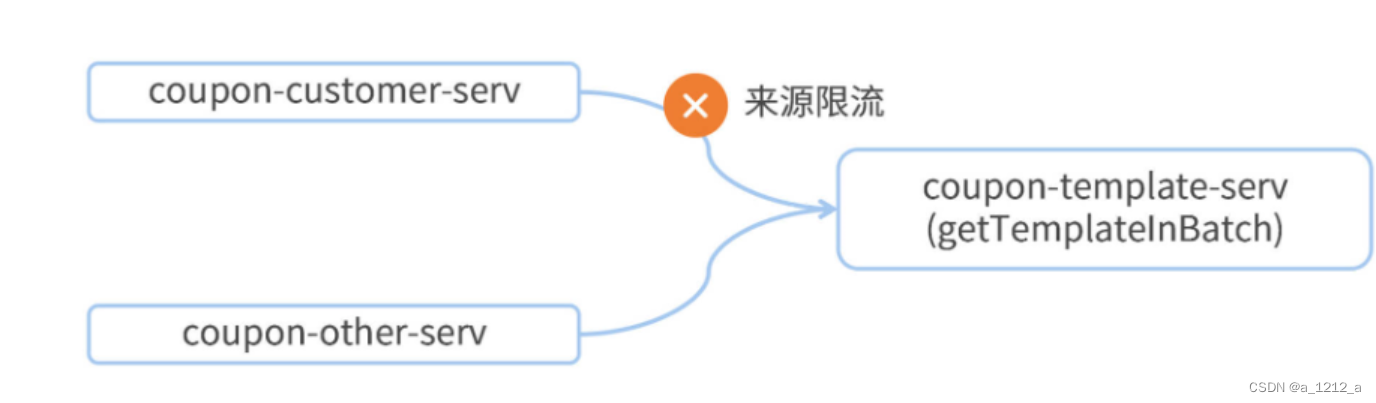
這個實作程序分為兩步,第一步,要想辦法在服務請求中加上一個特殊標記,告訴Template服務是誰呼叫;第二步,需要在Sentinel控制臺設定流控規則的針對來源,
第一步,首先,將呼叫源的應用名加入到由OpenFeign組件構造的Request中,可以借助OpenFeign的RequestInterceptor擴展介面,撰寫一個自定義的攔截器,在服務請求發送出去之前,往Request的Header里寫入一個特殊變數,傳遞給下游服務的“來源標記”
@Configuration
public class OpenfeignSentinelInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
template.header("SentinelSource", "coupon-customer-serv");
}
}
接下來,需要在Template服務中識別來自上游的標記,并將其加入到Sentinel的鏈路統計中,可以借助Sentinel提供的RequestOriginParser擴展介面,撰寫一個自定義的決議器,
@Component
@Slf4j
public class SentinelOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
log.info("request {}, header={}", request.getParameterMap(), request.getHeaderNames());
return request.getHeader("SentinelSource");
}
在方法中,從服務請求的Header中獲取SentinelSource變數的值,作為呼叫源的name
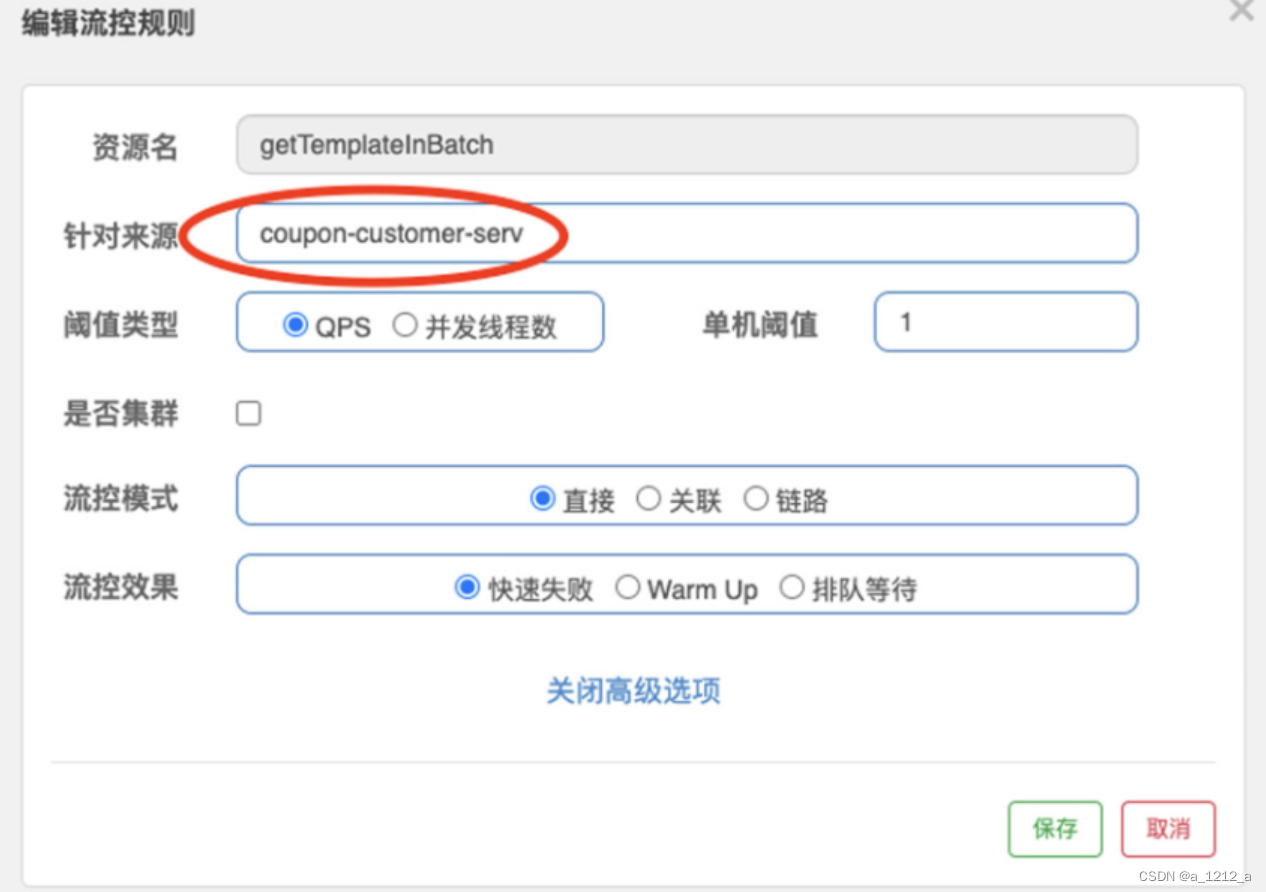
第二步,在流控規則的編輯頁面,“針對來源”這一欄填上coupon-customer-serv并保存,這樣一來,當前限流規則就只會針對來自Customer服務的請求生效了,
Sentinel的流控效果
快速失敗,Sentinel默認的流控效果,在快速失敗模式下,超過閾值設定的請求將會被立即阻攔住,
Warm Up 則實作了“預熱模式的流控效果”,這種方式可以平緩拉高系統水位,避免突發流量對當前處于低水位的系統的可用性造成破壞,舉個例子,如果設定的系統閾值是QPS=10,預熱時間=5,那么Sentinel會在這5秒的預熱時間內,將限流閾值從3緩慢拉高到10,為什么起始閾值是3呢?因為Sentinel內部有一個冷加載因子,它的值是3,在預熱模式下,起始閾值的計算公式是單機閾值/冷加載因子,也就是10/3=3,
排隊等待 模式下,超過閾值的請求不會立即失敗,而是會被放入一個佇列中,排好隊等待被處理,一旦請求在佇列中等待的時間超過了設定的超時時間,那么請求就會被從佇列中移除,
例外降級方案
使用blockHandler屬性指定降級方法的名稱,只能在服務拋出BlockException的情況下執行降級邏輯,
BlockException這個例外類是Sentinel組件自帶的類,當一個請求被Sentinel規則攔截,這個例外便會被拋出,比如請求被Sentinel流控策略阻攔住,或者請求被熔斷策略阻斷了,這些情況下可以使用SentinelResource注解的blockHandler來指定降級邏輯,對于其它RuntimeException的例外型別它就無能為力了,
使用SentinelResource中的另一個屬性fallback可以指定一段通用的降級邏輯,
需要注意,如果降級方法的方法簽名是BlockException,那么fallback是無法正常作業的,在注解中同時使用了fallback和blockHandler屬性,如果服務拋出BlockException,則執行blockHandler屬性指定的方法,其他例外就由fallback屬性所對應的降級方法接管,
可以通過SentinelResource注解的fallbackClass屬性指定一個保存降級邏輯的Class,
在控制臺添加熔斷策略
Sentinel的熔斷規則有3種,分別是例外比例、例外數和慢呼叫比例,
例外比例
指定以“ 例外比例”為熔斷開關的判斷邏輯,指定10秒的統計視窗內,如果例外呼叫的比例超過了60%,并且滿足請求數量>=5,就開啟一段為期5秒的熔斷時間,
“熔斷時長”的時間單位是秒,而“統計視窗”的時間單位是毫秒
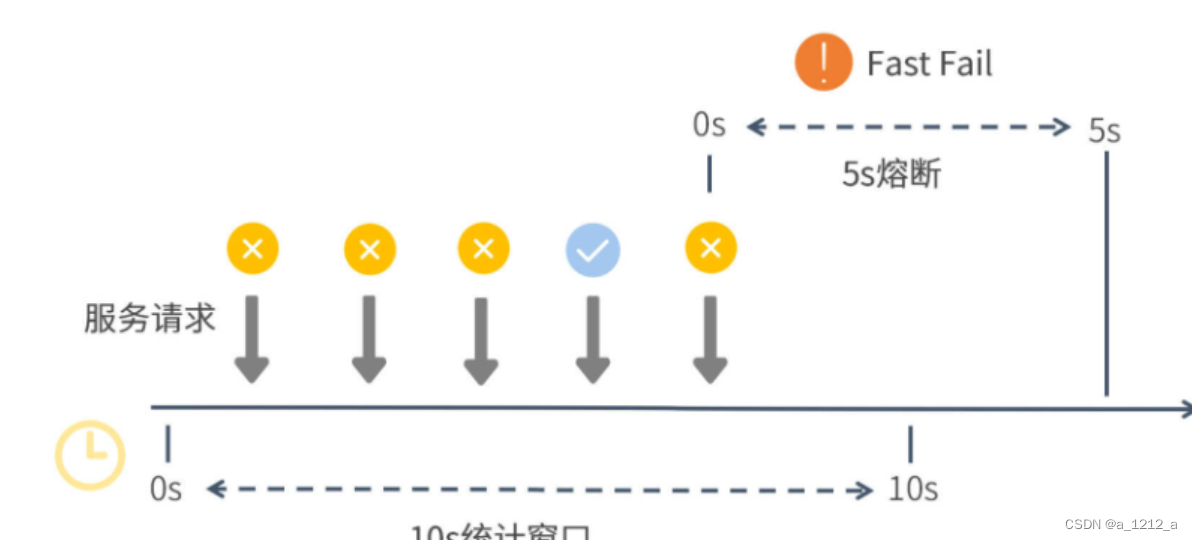
Sentinel底層通過一段跨度為10秒的滑動視窗來統計服務呼叫情況,在這段視窗時間內,前三個服務請求全部失敗,這時失敗率已經達到100%,大大超過了定義的60%的閾值,但是熔斷開關卻沒有打開,這是因為統計視窗的最小請求數還沒有達到設定值5,
之后又有兩個請求被處理,一個成功一個失敗,這時請求個數已經達到了5,失敗率是80%,那么Sentinel就開啟了一段5秒的熔斷時間,在這段時間內,所有來訪請求都不會得到真實的執行,而是轉而執行降級邏輯,
例外數
“ 例外數”熔斷規則和前面設定的例外比例熔斷規則幾乎一樣,唯一的區別就是“例外數”的判定條件是統計視窗內發生例外的個數,
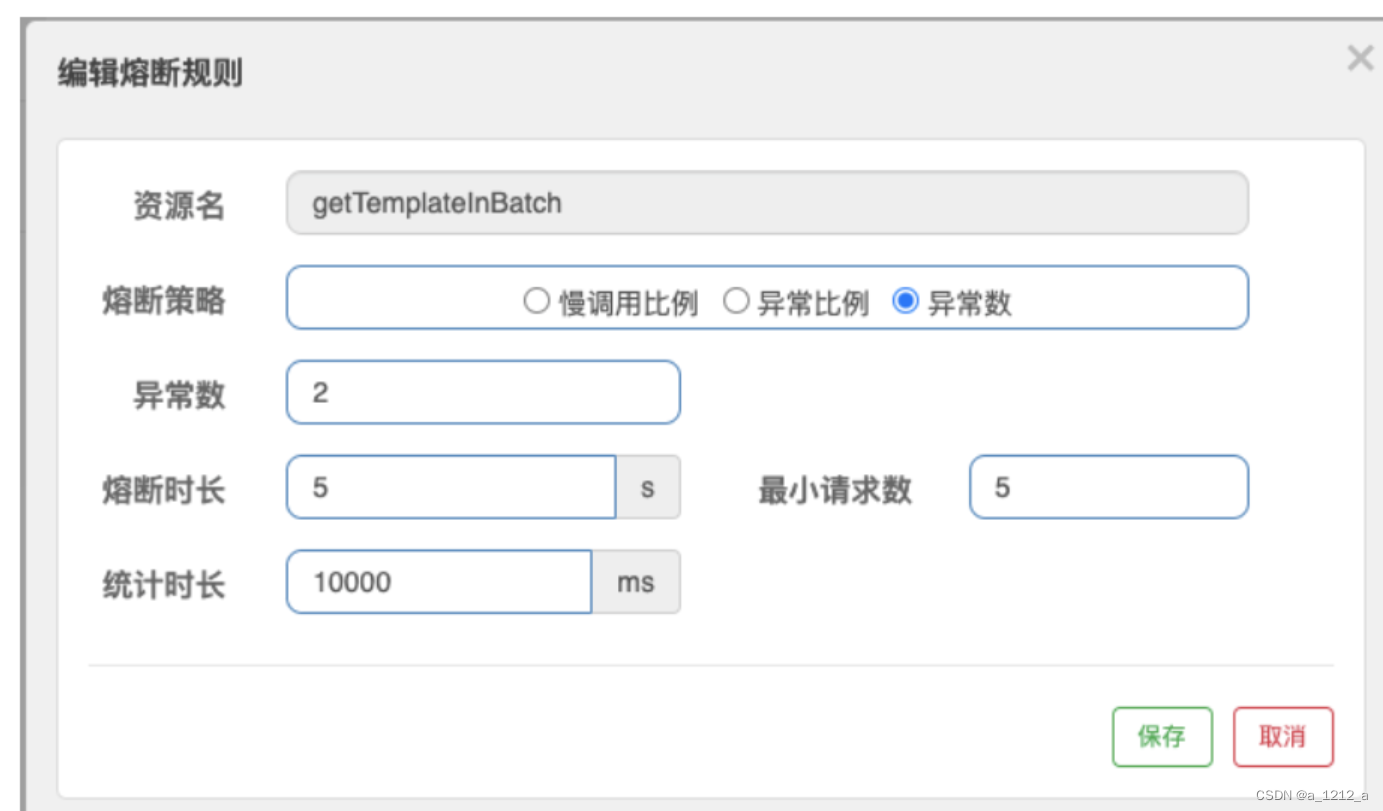
熔斷器開啟的判定條件是例外數>2
慢呼叫比例
通常來說,慢呼叫請求所占比例逐漸增多,這是服務雪崩的前兆,為了將影響范圍縮小,要做的就是 盡早捕捉到慢呼叫請求的比例變化趨勢,及時通過熔斷規則對服務進行減壓,
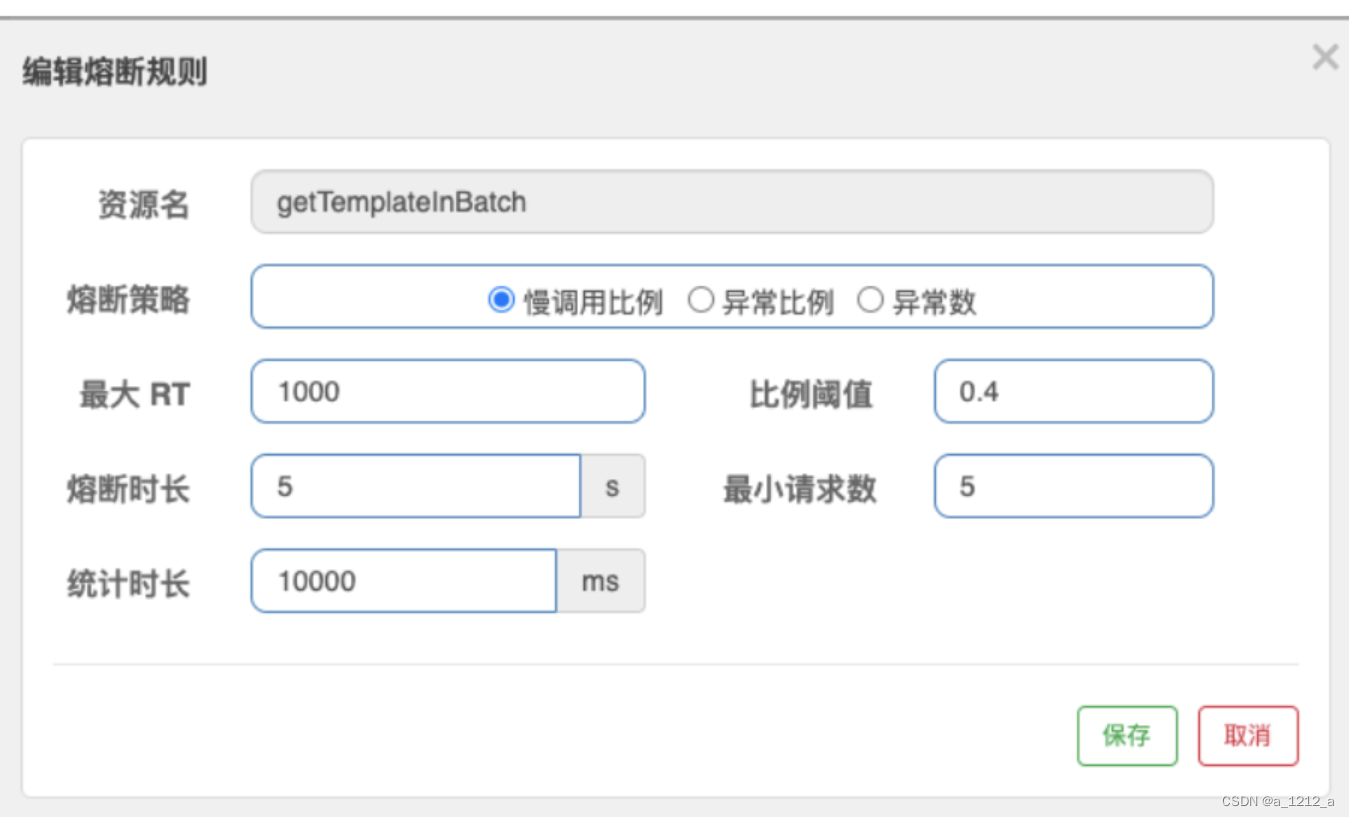
在10秒的統計視窗內,如果回應時間大于1000ms的請求所占總請求數量的比例超過了0.4,并且請求總數量>=5,此時將觸發Sentinel的熔斷開關,開啟5秒的熔斷視窗,
熔斷開關的狀態轉換
Sentinel的熔斷器會在開啟、關閉和半開這三種邏輯狀態之間來回切換
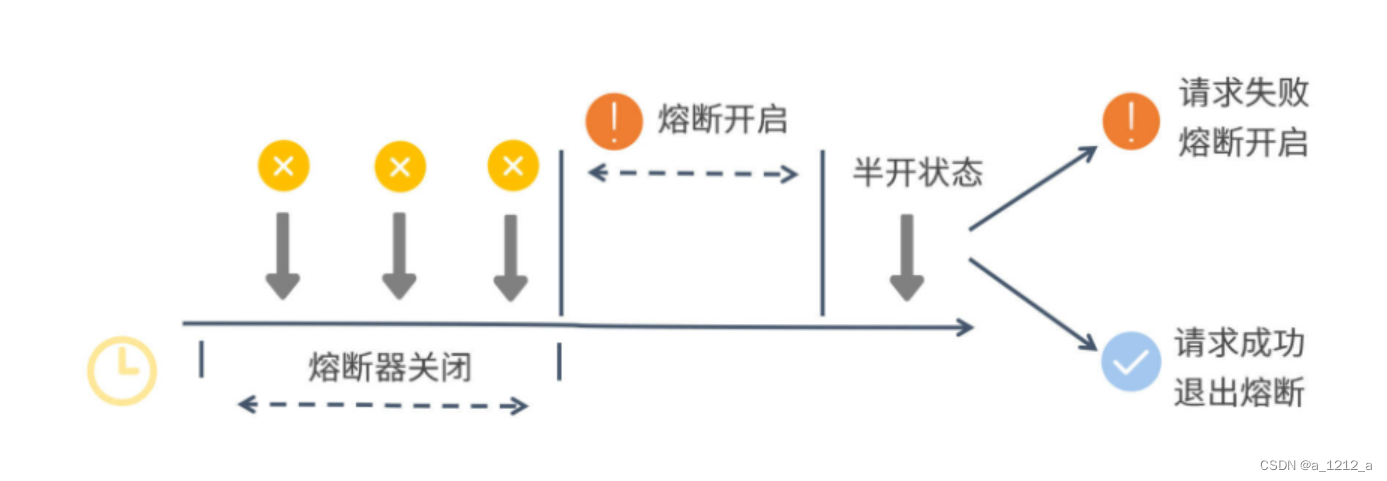
從圖中可以看出,在第一個統計視窗內熔斷器是處于關閉狀態的,達到熔斷判定條件之后,Sentinel開啟了一段熔斷視窗,在這段視窗時間內,熔斷器是處于開啟狀態的,這時新的服務請求會執行降級邏輯,待熔斷視窗結束,Sentinel會將熔斷器狀態置為“半開”狀態,這是一個介于完全開啟和完全關閉之間的中間態,
在半開狀態下,如果有一個新請求過來,那么Sentinel會試探性地讓這個請求去執行正常的業務邏輯,如果執行成功,那么Sentinel將關閉熔斷器并退出熔斷狀態,如果執行失敗,那么Sentinel將再次開啟一個新的熔斷視窗,
接入 Nacos 實作規則持久化
通過集成Nacos Config來實作持久化方案,需要把Sentinel中設定的限流規則保存到Nacos配置中心,這樣一來,當應用服務或Sentinel Dashboard重新啟動時,它們就可以自動把Nacos中的限流規則同步到本地,不管怎么重啟服務都不會導致規則失效了,
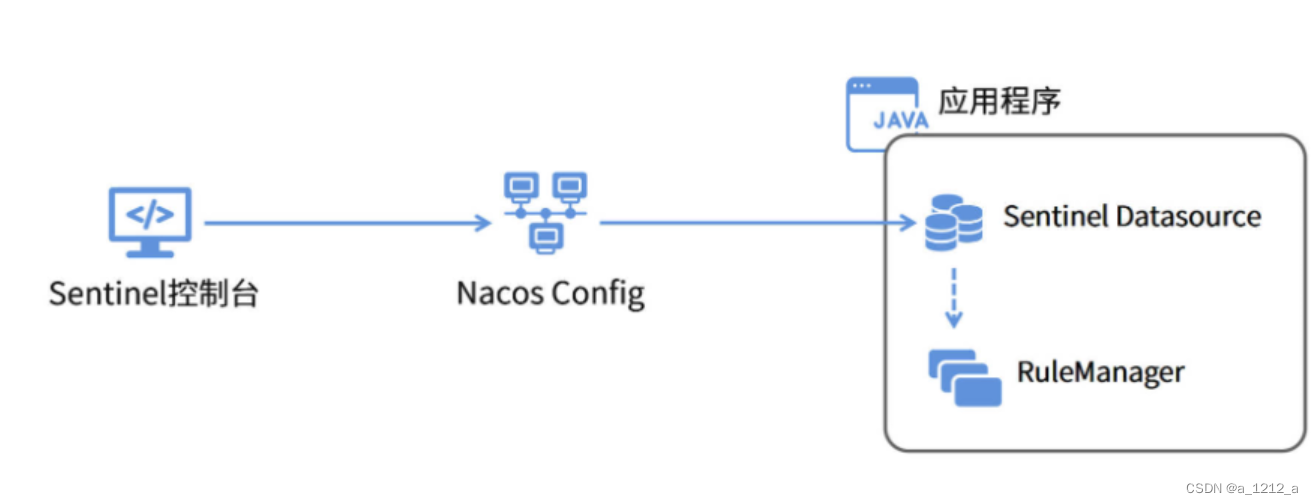
Sentinel控制臺將限流規則同步到了Nacos Config服務器來實作持久化,同時,在應用程式中,配置了一個Sentinel Datasource,從Nacos Config服務器獲取具體配置資訊,
在應用啟動階段,程式會主動從Sentinel Datasource獲取限流規則配置,而在運行期,也可以在Sentinel控制臺動態修改限流規則,應用程式會實時監聽配置中心的資料變化,進而獲取變更后的資料,
Sentinel組件二次開發
需要將Sentinel的代碼下載到本地,可以從 GitHub的Releases頁面 的Assets面板中下載Source code源檔案,
將專案匯入到開發工具中主要針對其中的sentinel-dashboard子模塊做二次開發,整個改造程序按照先后順序將分為三個步驟:
- 修改Nacos依賴項的應用范圍,將其打入jar包中;
- 后端程式對接Nacos,將Sentinel限流規則同步到Nacos;
- 開放單獨的前端限流規則配置頁面,
修改Nacos依賴項
sentinel-dashboard專案的pom.xml檔案中的依賴項sentinel-datasource-nacos是連接Nacos Config所依賴的必要組件,需要將這個依賴項的scope標簽注釋掉,
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
<!-- 將scope注釋掉,改為編譯期打包 -->
<!--<scope>test</scope>-->
</dependency>
后端程式對接Nacos
打開sentinel-dashboard專案下的src/test/java目錄(注意是test目錄而不是main目錄),然后定位到com.alibaba.csp.sentinel.dashboard.rule.nacos包,在這個包下面,看到4個和Nacos Config有關的類,它們的功能描述如下:
- NacosConfig:初始化Nacos Config的連接;
- NacosConfigUtil:約定了Nacos組態檔所屬的Group和檔案命名后綴等常量欄位;
- FlowRuleNacosProvider:從Nacos Config上獲取限流規則;
- FlowRuleNacosPublisher:將限流規則發布到Nacos Config,
為了讓這些類在Sentinel運行期可以發揮作用,需要在src/main/java下創建同樣的包路徑,然后將這四個檔案從test路徑拷貝到main路徑下,
NacosConfig類中配置Nacos連接串:
打開NacosConfig類,找到其中的nacosConfigService方法,這個方法創建了一個ConfigService類,它是Nacos Config定義的通用介面,提供了Nacos配置項的讀取和更新功能,FlowRuleNacosProvider和FlowRuleNacosPublisher這兩個類都是基于這個ConfigService類實作Nacos資料同步的,改造后的代碼:
@Bean
public ConfigService nacosConfigService() throws Exception {
// 將Nacos的注冊地址引入進來
//也可以通過組態檔來注入serverAddr和namespace等屬性,
Properties properties = new Properties();
properties.setProperty("serverAddr", "localhost:8848");
properties.setProperty("namespace", "dev");
return ConfigFactory.createConfigService(properties);
}
在Controller層接入Nacos來實作限流規則持久化:
在FlowControllerV2中正式接入Nacos,FlowControllerV2對外暴露了REST API,用來創建和修改限流規則,在這個類的源代碼中,需要修改兩個變數的Qualifier注解值,
@Autowired
// 指向剛才從test包中遷移過來的FlowRuleNacosProvider類
@Qualifier("flowRuleNacosProvider")
private DynamicRuleProvider<List<FlowRuleEntity>> ruleProvider;
@Autowired
// 指向剛才從test包中遷移過來的FlowRuleNacosPublisher類
@Qualifier("flowRuleNacosPublisher")
private DynamicRulePublisher<List<FlowRuleEntity>> rulePublisher;
通過Qualifier標簽將FlowRuleNacosProvider注入到了ruleProvier變數中,又采用同樣的方式將FlowRuleNacosPublisher注入到了rulePublisher變數中,FlowRuleNacosProvider和FlowRuleNacosPublisher就是從test目錄Copy到main目錄下的兩個類,
修改完成之后,FlowControllerV2底層的限流規則改動就會被同步到Nacos服務器了,這個同步作業是由FlowRuleNacosPublisher執行的,它會發送一個POST請求到Nacos服務器來修改配置項,
FlowRuleNacosPublisher會在Nacos Config上創建一個用來保存限流規則的組態檔,這個組態檔以“application.name”開頭,以“-flow-rules”結尾,而且它所屬的Group為“SENTINEL_GROUP”,這里用到的檔案命名規則和Group都是通過NacosConfigUtil類中的常量指定的,
前端頁面改造
打開sentinel-dashboard模塊下的webapp目錄,該目錄存放了Sentinel控制臺的前端頁面資源,需要改造的檔案是sidebar.html,這個html檔案定義了控制臺的左側導航欄,
<li ui-sref-active="active">
<a ui-sref="dashboard.flow({app: entry.app})">
<i ></i> 流控規則持久化</a>
</li>
微服務改造
只需要添加一個新的sentinel-datasource-nacos依賴項,并在組態檔中添加sentinel datasource連接資訊就可以了
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
spring:
cloud:
sentinel:
datasource:
# 資料源的key,可以自由命名
geekbang-flow:
# 指定當前資料源是nacos
nacos:
# 設定Nacos的連接地址、命名空間和Group ID
server-addr: localhost:8848
namespace: dev
groupId: SENTINEL_GROUP
# 設定Nacos中組態檔的命名規則
dataId: ${spring.application.name}-flow-rules
# 必填的重要欄位,指定當前規則型別是"限流"
rule-type: flow
在微服務端的sentinal資料源中配置的namespace和groupID,一定要和Sentinal Dashoboard二次改造中的中的配置相同,否則將無法正常同步限流規則,Sentinal Dashboard中namespace是在NacosConfig類中指定的,而groupID是在NacosConfigUtil類中指定的,
dataId的檔案命名規則,需要和Sentinel二次改造中的FlowRuleNacosPublisher類保持一致,如果修改了FlowRuleNacosPublisher中的命名規則,那么也要在每個微服務端做相應的變更,
呼叫鏈追蹤:集成 Sleuth 和 Zipkin
Sleuth
如果想提高線上例外排查的效率,那么首先要做的一件事就是: 將一次呼叫請求中所有訪問到的微服務日志前后串聯起來,
鏈路追蹤技識訓為每次服務呼叫生成一個全域唯一的ID(Trace ID),從本次服務呼叫的起點到終點,這個程序中的所有日志資訊都會被打上Trace ID的烙印,這樣一來,根據日志中的Trace ID,就能很清晰地梳理出一次服務請求前后都經過了哪些微服務節點,
Sleuth的底層邏輯
呼叫鏈追蹤有兩個任務,一是 標記出一次呼叫請求中的所有日志,二是 梳理日志間的前后關系,
集成了Sleuth組件之后,它會向日志中打入三個“特殊標記”,其中一個標記是Trace ID,剩下的兩個標記分別是Span ID和Parent Span ID,這倆用來表示呼叫的前后順序關系,
Trace ID完成的是第一個任務:標記,用來標記呼叫鏈的全域唯一ID,
Span是Sleuth下面的一個基本作業單元,當服務請求抵達當前單元時,Sleuth就會為這個單元分配一個獨一無二的Span ID,并標記單元的開始時間和結束時間,這樣就可以記錄每個單元的處理用時了,
Parent Span ID指向了當前單元的父級單元,也就是上游的呼叫者,一個環環相扣的呼叫鏈就通過Parent Span ID被串了起來,
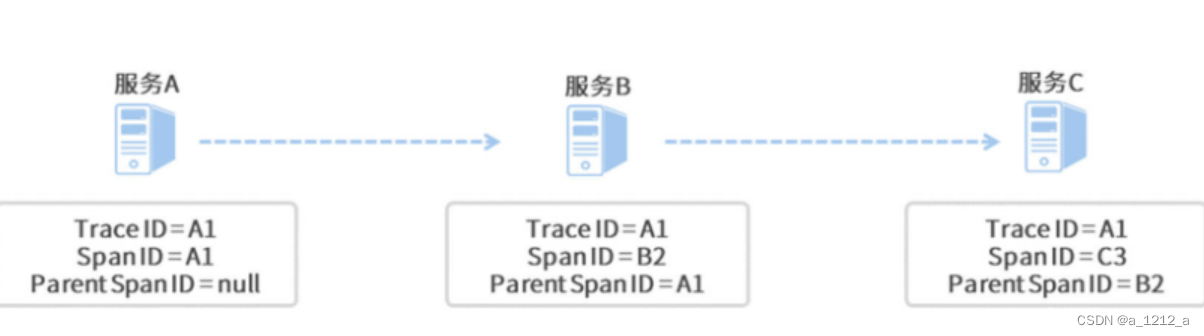
上面的圖示只是一個簡化的流程,在實際的專案中,一次服務呼叫可不光只會生成一個Span,比如說服務A請求通過OpenFeign組件呼叫了服務B,那么服務A接收用戶請求的程序就是一個單元,而OpenFeign組件發起遠程呼叫的程序又是另一個單元,由此可見,單元的顆粒度其實是非常小的,
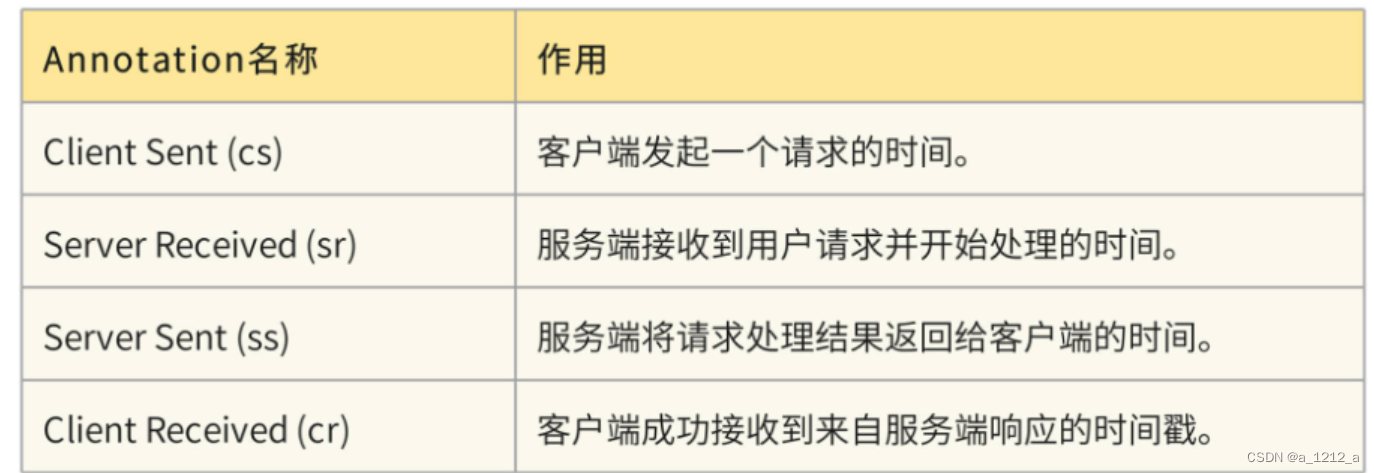
Sleuth還有一個特殊的資料結構,叫做Annotation,被用來記錄一個具體的“事件”,
集成Sleuth實作鏈路打標
將Sleuth的依賴項添加到pom.xml檔案中
<!-- Sleuth依賴項 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
application.yml組態檔
spring:
sleuth:
sampler:
# 采樣率的概率,100%采樣
probability: 1.0
# 每秒采樣數字最高為1000
rate: 1000
probability,是一個0到1的浮點數,用來表示 采樣率,這里設定的probability是1,就表示對請求進行100%采樣,如果把probability設定成小于1的數,就說明有的請求不會被采樣,如果一個請求未被采樣,那么它將不會被呼叫鏈追蹤系統Track起來,
rate引數,它代表 每秒最多可以對多少個Request進行采樣,這有點像一個“限流”引數,如果超過這個閾值,服務請求仍然會被正常處理,但呼叫鏈資訊不會被采樣,
Sleuth如何在呼叫鏈中傳遞標記
Sleuth為了將Trace ID和呼叫方服務的Span ID傳遞給被呼叫的微服務,它在OpenFeign的環節動了一個手腳,Sleuth通過 TracingFeignClient類,將一系列Tag標記塞進了OpenFeign構造的服務請求的Header結構中,
在TracingFeignClient的類中打了一個Debug斷點,將Request的Header資訊列印出來:
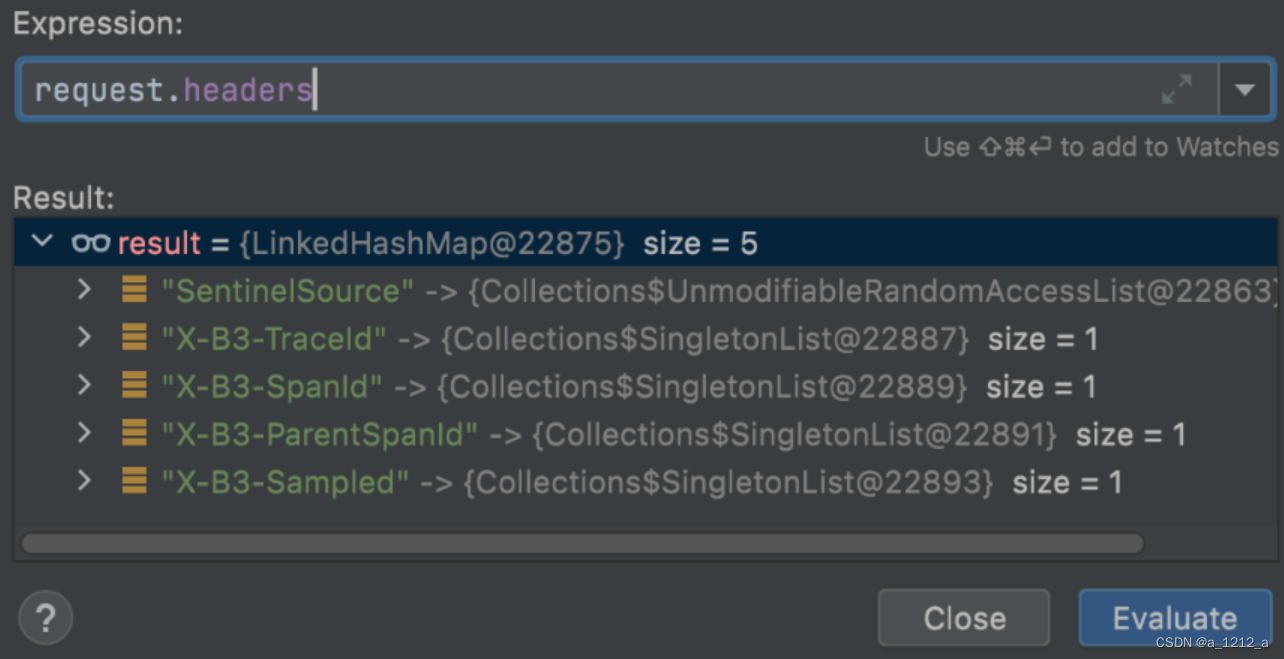
在這個Header結構中,可以看到有幾個以X-B3開頭的特殊標記,這個X-B3就是Sleuth的特殊接頭暗號,其中X-B3-TraceId就是全域唯一的鏈路追蹤ID,而X-B3-SpanId和X-B3-ParentSpandID分別是當前請求的單元ID和父級單元ID,最后的X-B3-Sampled則表示當前鏈路是否是一個已被采樣的鏈路,通過Header里的這些資訊,下游服務就完整地得到了上游服務的情報,
使用Zipkin收集并查看鏈路資料
Zipkin是一個分布式的Tracing系統,它可以用來收集時序化的鏈路打標資料,通過Zipkin內置的UI界面,可以根據Trace ID搜索出一次呼叫鏈所經過的所有訪問單元,并獲取每個單元在當前服務呼叫中所花費的時間,
為了搭建一條高可用的鏈路資訊傳遞通道,使用RabbitMQ作為中轉站,讓各個應用服務器將服務呼叫鏈資訊傳遞給RabbitMQ,而Zipkin服務器則通過監聽RabbitMQ的佇列來獲取呼叫鏈資料,相比于讓微服務通過Web介面直連Zipkin, 使用訊息佇列可以大幅提高資訊的送達率和傳遞效率,
搭建Zipkin服務器
通過訪問 maven的中央倉庫 下載zipkin-server-2.23.9-exec.jar檔案
java -jar zipkin-server-2.23.9-exec.jar --zipkin.collector.rabbitmq.addresses=localhost:5672
Zipkin已經內置了RabbitMQ的默認連接屬性,如果沒有特殊指定,那么Zipkin會使用guest默認用戶登錄RabbitMQ,

搭建Zipkin有兩種方式,一種是直接下載Jar包,這是官方推薦的標準集成方式;另一種是通過引入Zipkin依賴項的方式,在本地搭建一個Spring Boot版的Zipkin服務器,如果需要對Zipkin做定制化開發,那么可以采取后一種方式,
傳送鏈路資料到Zipkin
在每個微服務模塊的pom.xml中添加Zipkin適配插件和Stream的依賴
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
將Zipkin的配置資訊添加到每個微服務模塊的application.yml檔案中,Zipkin配接器還支持ActiveMQ、Kafka和直連的方式
spring:
zipkin:
sender:
type: rabbit
rabbitmq:
addresses: 127.0.0.1:5672
queue: zipkin #在應用中指定的佇列名稱,一定要同Zipkin服務器所指定的佇列名稱保持一致
在瀏覽器中打開localhost:9411進到Zipkin的首頁,在首頁中可以通過各種搜索條件的組合,從服務、時間等不同維度查詢呼叫鏈資料,
Spring Cloud Gateway
Gateway叫“微服務網關”,就說明它自己就是一個微服務,換句話說,它也是Nacos服務注冊中心的一員,既然Gateway能連接到Nacos,那么就意味著它可以輕松獲取到Nacos中所有服務的注冊表,這樣一來,Gateway就可以根據本地的路由規則,將請求精準無誤地送達到每個微服務組件中,
高可擴展性,對后臺的微服務集群做擴容或縮容的時候,Gateway可以從Nacos注冊中心輕松獲取所有服務節點的變動,不需要任何額外的配置,一切都在無感知的情況下自然而然地發生,
高度可定制化,它提供了一種對開發人員非常友好的方式,可以通過Java代碼去定制各種復雜的路由邏輯,還可以使用Filter對請求進行加工,
Gateway路由規則
Gateway的路由規則主要有三個部分,分別是路由、謂詞和過濾器,
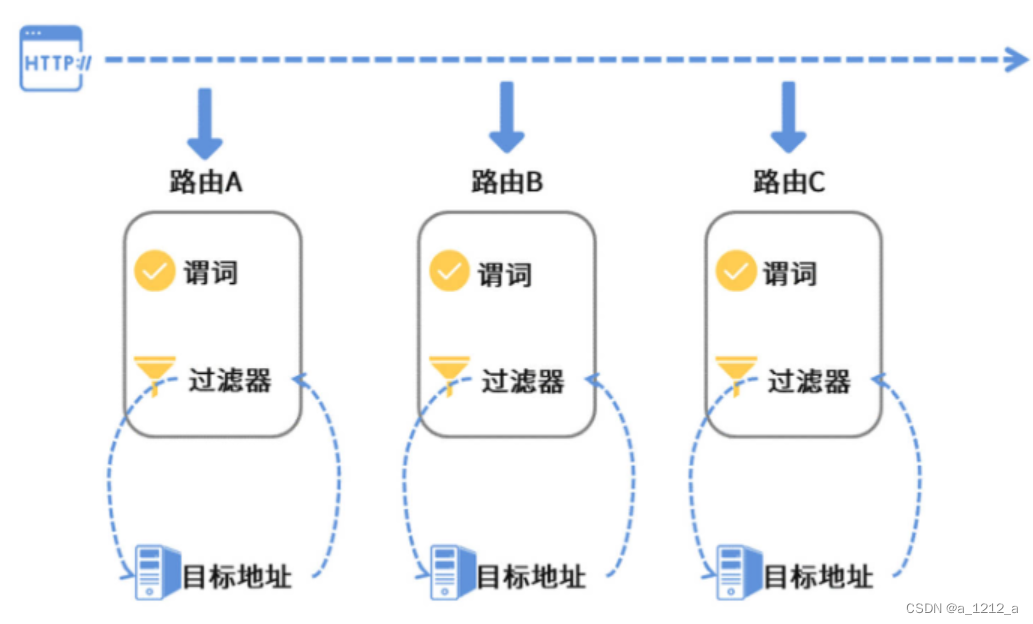
路由
路由是Gateway的一個基本單元,每個路由都有一個目標地址,這個目標地址就是當前路由規則要呼叫的目標服務,那么一條路由規則在什么情況下會去呼叫目標服務呢?這就要看路由的謂詞設定了,
謂詞
所謂謂詞,實際上是路由的判斷規則,一個路由中可以添加多個謂詞的組合,如果一個服務請求滿足某個路由里設定的所有的謂詞規則,那么就說明這個請求是當前路由的心動女神,這時候Gateway就會把請求轉發到路由中設定的目標地址,
過濾器
過濾器和路由、目標地址之間是什么關系呢?其實Gateway在把請求轉發給目標地址的程序中,把這個任務全權委托給了Filter(過濾器)來處理,
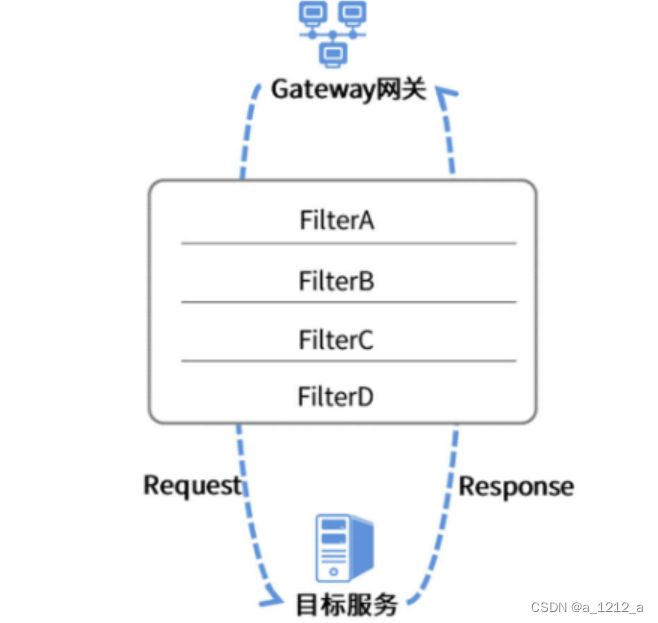
Gateway組件使用了一種FilterChain的模式對請求進行處理,每一個服務請求(Request)在發送到目標服務之前都要被一串FilterChain處理,同理,在Gateway接收服務回應(Response)的程序中也會被FilterChain處理一把,
Gateway的過濾器主要分為兩種,一種是GlobalFilter,也就是“ 全域過濾器”;另一種是GatewayFilter,也就是對指定路由生效的“ 區域過濾器”,
全域過濾器繼承自GlobalFilter介面,它的作用大多是“例行公事”,也就是一些底層能力的支持,比如,RouteToRequestUrlFilter這個全域過濾器就是用來決議“目標服務地址”的,
除此之外,Gateway還有一系列用來做路徑轉發、請求跨域、WebSocket、WebClient和Loadbalancer功能支持的全域過濾器,
GatewayAutoConfiguration這個類是Gateway的自動裝配器,里面包含了大量GlobalFilter的宣告,
GatewayFilter也就是區域過濾器,它的功能可就多了,Gateway提供了一系列的內置過濾器,可以實作對Request/Response的修改、請求路徑修改、呼叫重試、限流等等功能,當然了,也可以通過Gateway的擴展介面實作一個自定義過濾器并應用到路由規則中,
宣告路由的幾種方式
Gateway提供了三種方式來加載路由規則,分別是Java代碼、yaml檔案和動態路由,
第一種加載方式是Java代碼宣告路由,它是可讀性和可維護性最好的方式,使用一種鏈式編程的Builder風格來構造一個route物件,根據path的匹配規則將請求轉發到不同的地址,
@Bean
public RouteLocator declare(RouteLocatorBuilder builder) {
return builder.routes()
.route("id-001", route -> route
.path("/geekbang/**")
.uri("http://time.geekbang.org")
).route(route -> route
.path("/test/**")
.uri("http://www.test.com")
).build();
}
第二種方式是通過組態檔來宣告路由,可以在application.yml檔案中組裝路由規則,
spring:
cloud:
gateway:
routes:
- id: id-001
uri: http://time.geekbang.org
predicates:
- Path=/geekbang2/**
- uri: http://www.test.com
predicates:
- Path=/test2/**
如果想要在Gateway運行期更改路由邏輯,那么就要使用第三種方式:動態路由加載,
動態路由也有不同的實作方式,如果在專案中集成了actuator服務,那么就可以通過Gateway對外開放的actuator端點在運行期對路由規則做增刪改查,但這種修改只是臨時性的,專案重新啟動后就會被打回原形,因為這些動態規則并沒有持久化到任何地方,
動態路由還有另一種實作方式,那就是借助Nacos配置中心來存盤路由規則,Gateway通過監聽Nacos Config中的檔案變動,就可以動態獲取Nacos中配置的規則,并在本地生效了,
Gateway的內置謂詞
比較常用的謂詞大致分為三個型別:尋址謂詞、請求引數謂詞和時間謂詞,
尋址謂詞,顧名思義,就是針對請求地址和型別做判斷的謂詞條件,
.route("id-001", route -> route
.path("/geekbang/**")
.and().method(HttpMethod.GET, HttpMethod.POST)
.uri("http://time.geekbang.org")
在上面這段代碼中,添加了不止一個謂詞,在謂詞與謂詞之間,可以使用and、or、negate這類“與或非”邏輯連詞進行組合,構造一個復雜判斷條件,
這里用到的path,其實就是一個路徑匹配條件,當請求的URL和Path謂詞中指定的模式相匹配的時候,這個謂詞就會回傳一個True的判斷,而method謂詞則是根據請求的Http Method做為判斷條件,比如這里就限定了只有GET和POST請求才能訪問當前Route,
請求引數謂詞,這類謂詞主要對服務請求所附帶的引數進行判斷,這里的引數不單單是Query引數,還可以是Cookie和Header中包含的引數,
.route("id-001", route -> route
// 驗證cookie
.cookie("myCookie", "regex")
// 驗證header
.and().header("myHeaderA")
.and().header("myHeaderB", "regex")
// 驗證param
.and().query("paramA")
.and().query("paramB", "regex")
.and().remoteAddr("遠程服務地址")
.and().host("pattern1", "pattern2")
時間謂詞,可以借助before、after、between這三個時間謂詞來控制當前路由的生效時間段,
.route("id-001", route -> route
// 在指定時間之前
.before(ZonedDateTime.parse("2022-12-25T14:33:47.789+08:00"))
// 在指定時間之后
.or().after(ZonedDateTime.parse("2022-12-25T14:33:47.789+08:00"))
// 或者在某個時間段以內
.or().between(
ZonedDateTime.parse("起始時間"),
ZonedDateTime.parse("結束時間"))
自定義的謂詞邏輯
Gateway組件提供了一個統一的抽象類AbstractRoutePredicateFactory作為謂詞工廠,可以通過繼承這個類來添加新的謂詞邏輯,
// 繼承自通用擴展抽象類AbstractRoutePredicateFactory
public class MyPredicateFactory extends
AbstractRoutePredicateFactory<MyPredicateFactory.Config> {
public MyPredicateFactory() {
super(Config.class);
}
// 定義當前謂詞所需要用到的引數
@Validated
public static class Config {
private String myField;
}
@Override
public List<String> shortcutFieldOrder() {
// 宣告當前謂詞引數的傳入順序
// 引數名要和Config中的引數名稱一致
return Arrays.asList("myField");
}
// 實作謂詞判斷的核心方法
// Gateway會將外部傳入的引數封裝為Config物件
@Override
public Predicate<ServerWebExchange> apply(Config config) {
return new GatewayPredicate() {
// 在這個方法里撰寫自定義謂詞邏輯
@Override
public boolean test(ServerWebExchange exchange) {
return true;
}
@Override
public String toString() {
return String.format("myField: %s", config.myField);
}
};
}
}
這里面的關鍵步驟就兩步,一是定義Config結構來接收外部傳入的謂詞引數,二是實作apply方法撰寫謂詞判斷邏輯,
請求轉發、跨域和限流規則
微服務網關模塊的pom.xml檔案中添加幾個關鍵依賴項
<!-- Gateway依賴 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- Nacos服務發現 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!-- Redis+Lua限流 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
Nacos和Loadbalancer則扮演了“導航”的作用,讓Gateway在請求轉發的程序中可以通過“服務發現+負載均衡”定位到對應的服務節點,最后一個是Redis依賴項,用它來實作網關層限流,
添加組態檔
server:
port: 30000
spring:
# 分布式限流的Redis連接
redis:
host: localhost
port: 6379
cloud:
nacos:
# Nacos配置項
discovery:
server-addr: localhost:8848
heart-beat-interval: 5000
heart-beat-timeout: 15000
cluster-name: Cluster-A
namespace: dev
group: myGroup
register-enabled: true
gateway:
discovery:
locator:
# 創建默認路由,以"/服務名稱/介面地址"的格式規則進行轉發
# Nacos服務名稱本來就是小寫,但Eureka默認大寫
enabled: true
lower-case-service-id: true
# 跨域配置
globalcors:
cors-configurations:
'[/**]':
# 授信地址串列
allowed-origins:
- "http://localhost:10000"
- "https://www.geekbang.com"
# cookie, authorization認證資訊
expose-headers: "*"
allowed-methods: "*"
allow-credentials: true
allowed-headers: "*"
# 瀏覽器快取時間
max-age: 1000

定義路由規則
@Configuration
public class RoutesConfiguration {
@Bean
public RouteLocator declare(RouteLocatorBuilder builder) {
return builder.routes()
.route(route -> route
.path("/gateway/coupon-customer/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-customer-serv")
).route(route -> route
.order(1)
.path("/gateway/template/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-template-serv")
).route(route -> route
.path("/gateway/calculator/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://coupon-calculation-serv")
).build();
}
}
以第二個路由規則為例,使用path謂詞約定了路由的匹配規則為path=“/template/**”,這里要注意的是,如果某一個請求匹配上了多個路由,但又想讓各個路由之間有個先后匹配順序,這時就可以使用order(n)方法設定路由優先級,n數字越小則優先級越高,
接下來,使用了一個stripPrefix過濾器,將path訪問路徑中的第一個前置子路徑洗掉掉,這樣一來,/gateway/template/xxx的訪問請求經由過濾器處理后就變成了/template/xxx,同理,如果想去除path中打頭的前兩個路徑,那就使用stripPrefix(2),引數里傳入幾它就能吞掉幾個prefix path,
最后,使用uri方法指定了當前路由的目標轉發地址,這里的“lb://coupon-template-serv”表示使用本地負載均衡將請求轉發到名為“coupon-template-serv”的服務,
Filter和網關限流
對Request Header和Parameter進行刪改,又或者從Response里面洗掉某個Header
.route(route -> route
.order(1)
.path("/gateway/template/**")
.filters(f -> f.stripPrefix(1)
// 修改Request引數
.removeRequestHeader("mylove")
.addRequestHeader("myLove", "u")
.removeRequestParameter("urLove")
.addRequestParameter("urLove", "me")
// response系列引數
.removeResponseHeader("responseHeader")
)
.uri("lb://coupon-template-serv")
網關限流
一個輕量級的網關層限流方案所采用的底層技術是Redis + Lua,
Lua是一類很小巧的腳本語言,它和Redis可以無縫集成,可以在Lua腳本中執行Redis的CRUD操作,在這個限流方案中,Redis用來保存限流計數,而限流規則定義在Lua腳本中,默認使用令牌桶限流演算法,
在Gateway模塊里新建了一個RedisLimitationConfig類,專門用來定義限流引數
@Configuration
public class RedisLimitationConfig {
// 限流的維度
@Bean
@Primary
public KeyResolver remoteHostLimitationKey() {
return exchange -> Mono.just(
exchange.getRequest()
.getRemoteAddress()
.getAddress()
.getHostAddress()
);
}
//template服務限流規則
@Bean("tempalteRateLimiter")
public RedisRateLimiter templateRateLimiter() {
return new RedisRateLimiter(10, 20);
}
// customer服務限流規則
@Bean("customerRateLimiter")
public RedisRateLimiter customerRateLimiter() {
return new RedisRateLimiter(20, 40);
}
@Bean("defaultRateLimiter")
@Primary
public RedisRateLimiter defaultRateLimiter() {
return new RedisRateLimiter(50, 100);
}
}
remoteHostLimitationKey這個方法中定義了一個以Remote Host Address為維度的限流規則,也可以改用某個請求引數或者用戶ID為限流規則的統計維度,其它的三個方法定義了基于令牌桶演算法的限流速率,RedisRateLimiter類接收兩個int型別的引數,第一個引數表示每秒發放的令牌數量,第二個引數表示令牌桶的容量,通常來說一個請求會消耗一張令牌,如果一段時間內令牌產生量大于令牌消耗量,那么積累的令牌數量最多不會超過令牌桶的容量,
將限流規則應用到路由表中:
Gateway路由規則都定義在RoutesConfiguration類中,所以需要把定義的限流引數類注入到RoutesConfiguration類中,考慮到不同的路由表可能會使用不同的限流引數,所以在定義多個限流引數的時候,可以使用@Bean(“customerRateLimiter”)這種方式來做區分,然后在Autowired注入物件的時候,使用@Qualifier(“customerRateLimiter”)指定想要加載的限流引數就可以了,
@Autowired
private KeyResolver hostAddrKeyResolver;
@Autowired
@Qualifier("customerRateLimiter")
private RateLimiter customerRateLimiter;
@Autowired
@Qualifier("tempalteRateLimiter")
private RateLimiter templateRateLimiter;
限流引數注入完成之后,接下來只需要添加一個內置的限流過濾器,分別指定限流的維度、限流速率就可以了
.route(route -> route.path("/gateway/coupon-customer/**")
.filters(f -> f.stripPrefix(1)
.requestRateLimiter(limiter-> {
limiter.setKeyResolver(hostAddrKeyResolver);
limiter.setRateLimiter(customerRateLimiter);
// 限流失敗后回傳的HTTP status code
limiter.setStatusCode(HttpStatus.BANDWIDTH_LIMIT_EXCEEDED);
}
)
)
.uri("lb://coupon-customer-serv")
Gateway組件本身提供了豐富的內置謂詞和過濾器,但在實際專案中大多用不到它們,因為網關層的核心用途只是簡單的路由轉發, 為了保證組件之間的職責隔離,并不建議通過謂詞和過濾器實作帶有業務屬性的邏輯,
那什么樣的邏輯可以在網關層實作呢?比如一些通用的身份鑒權、登錄檢測和簽名驗簽之類的服務,可以將這類安全檢測的邏輯前置到網關層來實作,這樣可以對不合法請求做快速失敗處理,
借助 Nacos 實作動態路由規則持久化
定義一個底層的網關路由規則編輯類,它的作用是將變化后的路由資訊添加到網關背景關系中,
@Slf4j
@Service
public class GatewayService {
@Autowired
private RouteDefinitionWriter routeDefinitionWriter;
@Autowired
private ApplicationEventPublisher publisher;
public void updateRoutes(List<RouteDefinition> routes) {
if (CollectionUtils.isEmpty(routes)) {
log.info("No routes found");
return;
}
routes.forEach(r -> {
try {
routeDefinitionWriter.save(Mono.just(r)).subscribe();
publisher.publishEvent(new RefreshRoutesEvent(this));
} catch (Exception e) {
log.error("cannot update route, id={}", r.getId());
}
});
}
}
這段代碼接收了一個RouteDefinition List物件作為入參,它是Gateway網關組件用來封裝路由規則的標準類,在里面包含了謂詞、過濾器和metadata等一系列構造路由規則所需要的元素,在主體邏輯部分,呼叫了Gateway內置的路由編輯類RouteDefinitionWriter,將路由規則寫入背景關系,再呼叫ApplicationEventPublisher類發布一個路由重繪事件,
這里不使用@RefreshScope來獲取Nacos動態引數,而使用了一種更為靈活的監聽機制,通過注冊一個“監聽器”來獲取Nacos Config的配置變化通知,這段邏輯封裝在了DynamicRoutesListener類中
@Slf4j
@Component
public class DynamicRoutesListener implements Listener {
@Autowired
private GatewayService gatewayService;
@Override
public Executor getExecutor() {
log.info("getExecutor");
return null;
}
// 使用JSON轉換,將plain text變為RouteDefinition
@Override
public void receiveConfigInfo(String configInfo) {
log.info("received routes changes {}", configInfo);
List<RouteDefinition> definitionList = JSON.parseArray(configInfo, RouteDefinition.class);
gatewayService.updateRoutes(definitionList);
}
}
DynamicRoutesListener實作了Listener介面,后者是Nacos Config提供的標準監聽器介面,當被監聽的Nacos組態檔發生變化的時候,框架會自動呼叫receiveConfigInfo方法執行自定義邏輯,在這段方法里,接收到的文本物件configInfo轉換成了List類,并呼叫GatewayService完成路由表的更新,
需要注意的一點是,需要按照RouteDefinition的JSON格式來撰寫Nacos Config中的配置項,如果兩者格式不匹配,那么這一步格式轉換就會拋出例外,
加載Nacos路由配置項需要在兩個場景下加載組態檔,一個是專案首次啟動的時候,從Nacos讀取檔案用來初始化路由表;另一個場景是當Nacos的配置項發生變化的時候,動態獲取配置項,定義一個叫做DynamicRoutesLoader的類,它實作了InitializingBean介面,后者是Spring框架提供的標準介面,它的作用是在當前類所有的屬性加載完成后,執行一段定義在afterPropertiesSet方法中的自定義邏輯,
@Slf4j
@Configuration
public class DynamicRoutesLoader implements InitializingBean {
@Autowired
private NacosConfigManager configService;
@Autowired
private NacosConfigProperties configProps;
@Autowired
private DynamicRoutesListener dynamicRoutesListener;
private static final String ROUTES_CONFIG = "routes-config.json";
@Override
public void afterPropertiesSet() throws Exception {
// 首次加載配置
String routes = configService.getConfigService().getConfig(
ROUTES_CONFIG, configProps.getGroup(), 10000);
dynamicRoutesListener.receiveConfigInfo(routes);
// 注冊監聽器
configService.getConfigService().addListener(ROUTES_CONFIG,
configProps.getGroup(),
dynamicRoutesListener);
}
}
在afterPropertiesSet方法中執行了兩項任務,第一項任務是呼叫Nacos提供的NacosConfigManager類加載指定的路由組態檔,組態檔名是routes-config.json;第二項任務是將前面定義的DynamicRoutesListener注冊到routes-config.json檔案的監聽串列中,這樣一來,每次這個檔案發生變動,監聽器都能夠獲取到通知,
往專案的bootstrap.yml檔案中添加Nacos Config的配置項
spring:
application:
name: coupon-gateway
cloud:
nacos:
config:
server-addr: localhost:8848
file-extension: yml
namespace: dev
timeout: 5000
config-long-poll-timeout: 1000
config-retry-time: 100000
max-retry: 3
refresh-enabled: true
enable-remote-sync-config: true
完成了以上步驟之后,Gateway組件的改造任務就算搞定了
添加Nacos組態檔
在Nacos配置串列頁中,需要在“dev”的命名空間下創建一個JSON格式的檔案,檔案名要和Gateway代碼中的名稱一致,叫做“routes-config.json”,它的Group是默認分組,也就是DEFAULT_GROUP
創建好之后,需要根據RoutesDefinition這個類的格式定義組態檔的內容
[{
"id": "customer-dynamic-router",
"order": 0,
"predicates": [{
"args": {
"pattern": "/dynamic-routes/**"
},
"name": "Path"
}],
"filters": [{
"name": "StripPrefix",
"args": {
"parts": 1
}
}
],
"uri": "lb://coupon-customer-serv"
}]
在這段組態檔中,指定當前路由的ID是customer-dynamic-router,并且優先級為0,除此之外,還定義了一段Path謂詞作為路徑匹配規則,還通過StripPrefix過濾器將Path中第一個前置路徑洗掉,
洗掉某個路由:可以對Nacos配置項做一層額外封裝,添加幾個新欄位用來表示“洗掉路由”這個語意,并創建一個自定義POJO類接收引數;還可以在路由的metadata里為Nacos的動態路由做一個特殊標記,每次當Nacos重繪路由表的時候,就洗掉背景關系當中的所有Nacos路由表,再重新創建;又或者通過metadata做一個邏輯洗掉的標記,每次更新路由表的時候只要見到這個標記就洗掉當前路由,否則就更新或新建路由,
Stream
Stream依賴項添加到coupon-customer-impl專案的pom檔案中,由于底層使用的中間件是RabbitMQ,所以引入的是stream-rabbit組件
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
添加生產者
使用StreamBridge這個Stream的原生組件,將資訊發送給RabbitMQ,
@Service
@Slf4j
public class CouponProducer {
@Autowired
private StreamBridge streamBridge;
public void sendCoupon(RequestCoupon coupon) {
log.info("sent: {}", coupon);
streamBridge.send("addCoupon-out-0", coupon);
}
public void deleteCoupon(Long userId, Long couponId) {
log.info("sent delete coupon event: userId={}, couponId={}", userId, couponId);
streamBridge.send("deleteCoupon-out-0", userId + "," + couponId);
}
}
在這段代碼里,streamBridge.send方法的第一個引數是Binding Name,它指定了這條訊息要被發到哪一個信道中
添加訊息消費者
在這段代碼中,有一個“ 約定大于配置”的規矩一定要遵守,那就是不要亂起方法名,要確保消費者方法的名稱和組態檔中所定義的Function Name以及Binding Name保持一致,這是function event的一條潛規則,因為在默認情況下,框架會使用消費者方法的method name作為當前消費者的標識,如果消費者標識和組態檔中的名稱不一致,那么Spring應用就不知道該把當前的消費者系結到哪一個Stream信道上去,
@Slf4j
@Service
public class CouponConsumer {
@Autowired
private CouponCustomerService customerService;
@Bean
public Consumer<RequestCoupon> addCoupon() {
return request -> {
log.info("received: {}", request);
customerService.requestCoupon(request);
};
}
@Bean
public Consumer<String> deleteCoupon() {
return request -> {
log.info("received: {}", request);
List<Long> params = Arrays.stream(request.split(","))
.map(Long::valueOf)
.collect(Collectors.toList());
customerService.deleteCoupon(params.get(0), params.get(1));
};
}
}
添加組態檔
Stream的配置項比較多,分Binder和Binding兩部分,
Binder中配置了對接外部訊息中間件所需要的連接資訊,如果程式中只使用了單一的中間件,比如只接入了RabbitMQ,那么可以直接在spring.rabbitmq節點下配置連接串,不需要特別指定binders配置,
如果在Stream中需要同時對接多個不同型別,或多個同型別但地址埠各不相同的訊息中間件,那么可以把這些中間件的資訊配置在spring.cloud.stream.binders節點下,其中type屬性指定了當前訊息中間件的型別,而environment則指定了連接資訊,
spring:
cloud:
stream:
# 如果專案里只對接一個中間件,那么不用定義binders
# 當系統要定義多個不同訊息中間件的時候,使用binders定義
binders:
my-rabbit:
type: rabbit # 訊息中間件型別
environment: # 連接資訊
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
spring.cloud.stream.bindings節點保存了生產者、消費者、binder和RabbitMQ四方的關聯關系
spring:
cloud:
stream:
bindings:
# 添加coupon - Producer
addCoupon-out-0:
destination: request-coupon-topic
content-type: application/json
binder: my-rabbit
# 添加coupon - Consumer
addCoupon-in-0:
destination: request-coupon-topic
content-type: application/json
# 消費組,同一個組內只能被消費一次
group: add-coupon-group
binder: my-rabbit
# 洗掉coupon - Producer
deleteCoupon-out-0:
destination: delete-coupon-topic
content-type: text/plain
binder: my-rabbit
# 洗掉coupon - Consumer
deleteCoupon-in-0:
destination: delete-coupon-topic
content-type: text/plain
group: delete-coupon-group
binder: my-rabbit
function:
definition: addCoupon;deleteCoupon
以addCoupon為例,定義了addCoupon-out-0和addCoupon-in-0這兩個節點,節點名稱中的out代表當前配置的是一個生產者,而in則代表這是一個消費者,這便是spring-function中約定的命名關系:
Input信道(消費者):< functionName > - in - < index >;
Output信道(生產者):< functionName > - out - < index >;
命名規則的最后還有一個index,它是input和output的序列,如果同一個function name只有一個output和一個input,那么這個index永遠都是0,而如果需要為一個function添加多個input和output,就需要使用index變數來區分每個生產者消費者了,官方社區檔案,
信道和RabbitMQ里定義的訊息佇列之間的關系:
信道和RabbitMQ的系結關系是通過binder屬性指定的,如果當前組態檔的背景關系中只有一個訊息中間件(比如使用默認的MQ),并不需要宣告binder屬性,但如果配置了多個binder,那就需要為每個信道宣告對應的binder是誰,addCoupon-out-0對應的binder名稱是my-rabbit,這個binder就是在spring.cloud.stream.binders里宣告的配置,通過這種方式,生產者消費者信道到訊息中間件(binder)的聯系就建立起來了,
信道和訊息佇列的關系是通過destination屬性指定的,以addCoupon為例,在addCoupon-out-0生產者配置項中指定了destination=request-coupon-topic,意思是將訊息發送到名為request-coupon-topic的Topic中,又在addCoupon-in-0消費者里添加了同樣的配置,意思是讓當前消費者從request-coupon-topic消費新的訊息,
spring.cloud.stream.function:
如果專案中存在多個消費者,使用spring.cloud.stream.function或者spring.cloud.function把所有消費者的function name寫出來,
如果專案中只有一組消費者,那么完全不用搭理這個配置項,只要確保消費者代碼中的method name和bindings下宣告的消費者信道名稱相對應就好了;如果專案中有多組消費者(比如宣告了addCoupon和deleteCoupon兩個消費者),在這種情況下,需要將消費者所對應的function name添加到spring.cloud.function或者spring.cloud.stream.function,否則消費者無法被系結到正確的信道,
Seata
Seata 是一款開源的分布式事務解決方案,致力于提供高性能和簡單易用的分布式事務服務,
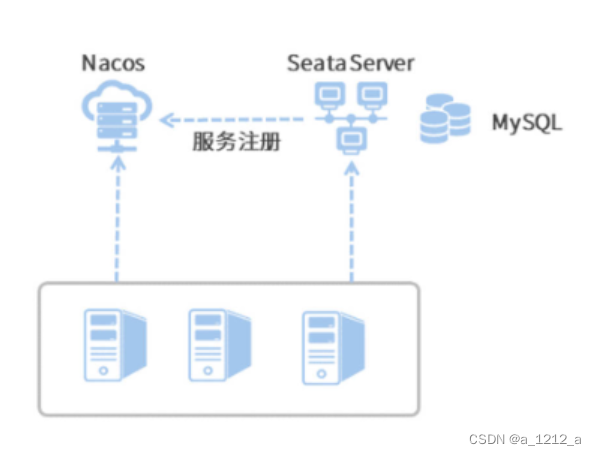
在分布式事務的執行程序中,各個微服務都要向Seata匯報自己的分支事務狀態,亦或是接收來自Seata的Commit/Rollback決議,Seata Server把自己作為了一個微服務注冊到了Nacos,各個微服務利用Nacos的服務發現能力獲取到Seata Server的地址,如此一來,微服務到Seata Server的通信鏈路就構建起來了,
搭建Seata服務器
Seata Github地址 Release頁面 下載
更改持久化配置
打開Seata安裝目錄下的conf檔案夾,找到file.conf.example檔案,把里面的內容復制一下并且Copy到file.conf里,
第一個改動點是 持久化模式,Seata支持本地檔案和資料庫兩種持久化模式,前者只能用在本地開發階段,因為基于本地檔案的持久化方案并不具備高可用能力,這里需要把store節點下的mode屬性改成“db”,
## transaction log store, only used in server side
store {
## store mode: file、db
## 【改動點01】 - 替換成db型別
mode = "db"
第二個改動點就是 DB的連接方式,需要把本地的connection配置到store節點下的db節點里
store {
mode = "db"
## 【改動點02】 - 更改引數
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
## if using mysql to store the data, recommend add rewriteBatchedStatements=true in jdbc connection param
url = "jdbc:mysql://127.0.0.1:3306/seata?rewriteBatchedStatements=true"
user = "root"
password = ""
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
}
}
創建資料庫表
創建global_table、branch_table和lock_table三張表,這是Seata Server用來保存全域事務、分支事務還有事務鎖定狀態的表,Seata正是用這三個Table來記錄分布式事務執行狀態,并控制最終一致性的,
每個微服務背后的資料庫(創建在微服務專案自個兒的資料庫)創建一個特殊的表,叫做undo_log,在Seata的AT模式下,Seata Server發起一個Rollback指令后,微服務作為Client端要負責執行一段Rollback腳本,這個腳本所要執行的回滾邏輯就保存在undo_log中,
開啟服務發現
打開Seata安裝目錄下的conf/registry.conf檔案,找到registry節點,這就是用來配置服務注冊的地方,
registry {
# 【改動點01】 - type變成nacos
type = "nacos"
# 【改動點02】 - 更換
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "myGroup"
namespace = "dev"
cluster = "default"
username = ""
password = ""
}
}
接下來,還需要修改registry.nacos里的內容

AT模式
Seata框架的三個重要角色,TC、TM和RM,
TC全稱是Transaction Coordinator,TC扮演了一個中心化的事務協調者的角色,負責協調全域事務的提交和回滾,并維護全域事務和分支事務的狀態,
TM全稱是Transaction Manager,它是事務管理器,主要作用是發起一個全域事務,對全域事務的提交和回滾做出決議,在AT方案中,TM通常是由發起全域事務的那個微服務所扮演的,
RM全稱是Resource Manager,它是資源管理器,向TC注冊分支事務并上報事務狀態,同時負責對當前分支事務進行提交和回滾,每一個分支事務都是全域事務的參與者,這些分支事務的所屬應用扮演了RM的角色,
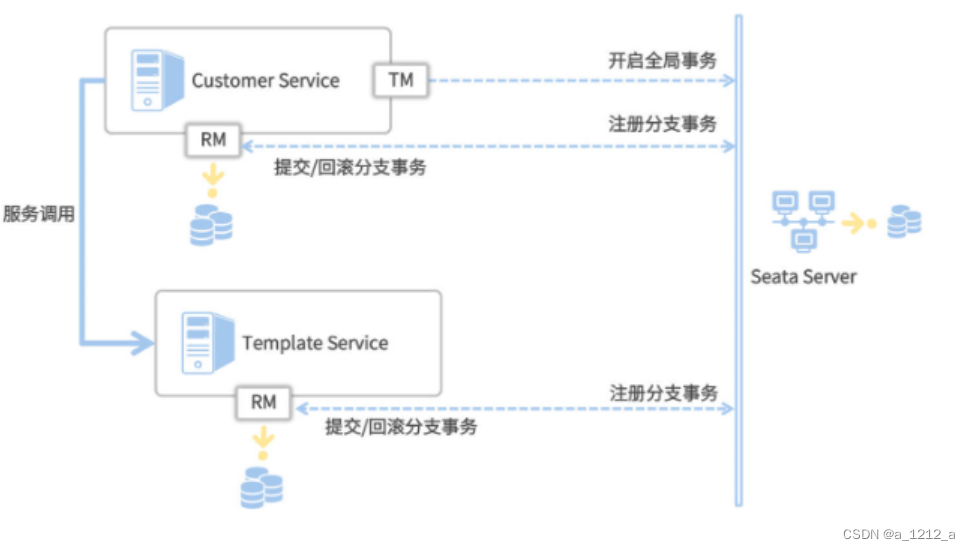
Seata AT的業務流程分為兩個階段來執行,
- 一階段: 執行核心業務邏輯(即代碼中的CRUD操作),Seata會根據DB操作自動生成相應的回滾日志,并將回滾日志添加到RM對應的undo_log表中,執行業務代碼和添加回滾日志這兩步都是在同一個本地事務中提交的,
- 二階段: 如果全域事務的最終決議是Commit,則更新分支事務狀態并清慷訓滾日志;如果最終決議是Rollback,則根據undo_log中的回滾日志進行rollback操作,二階段是以異步化的方式來執行的,
Seata AT方案的核心在于這個undo_log,正是有了這個記錄回滾日志的undo_log表,才能將一階段和二階段剝離成兩個獨立的本地事務來執行,而Seata AT之所以執行效率高,主要原因有兩個,一是核心業務邏輯可以在一階段得到快速提交,DB資源被快速釋放;二是全域事務的Commit和Rollback是異步執行,
分布式事務的起點,扮演了一個TM的角色,它會向TC注冊并發起一個全域事務,全域事務會生成一個XID,它是全域唯一的ID標識,所有分支事務都會和這個XID進行系結,XID在服務內部(非跨服務呼叫)的傳播機制是基于ThreadLocal構建的,即XID在當前執行緒的背景關系中進行透傳,對于跨服務呼叫來說,則依賴seata-all組件內置的各個配接器(如Interceptor和Filter)將XID傳遞給物件服務,
被呼叫服務的RM開啟了一個分支事務,并注冊到TC,在執行分支事務的程序中,RM還會生成回滾日志并提交到undo_log表中,除此之外,RM還需要獲取到兩個特殊的Lock,其中一個是Local Lock(本地鎖),另一個是Global Lock(全域鎖),
Lock資訊存放在lock_table這張表里,它會記錄待修改的資源ID以及它的全域事務和分支事務ID等資訊,無論是一階段提交還是二階段回滾,RM都需要獲取待修改記錄的本地鎖,然后才會去執行CRUD操作,而在RM提交一階段事務之前,它還會嘗試獲取Global Lock(全域鎖),目的是防止多個分布式事務對同一條記錄進行修改,假設有兩個不同的分布式事務想要修改記錄A,那么只有同時獲取到Local Lock和Global Lock的事務才能正常提交一階段事務,
本地鎖會隨一階段事務的提交/回滾而釋放,而全域鎖只有等到全域事務提交/回滾之后才會被釋放,在一階段中,如果某一個事務在一定的嘗試次數后仍然無法獲取全域鎖,它會知難而退,執行本地事務回滾操作,而如果在二階段回滾的時候,RM無法獲取本地鎖,它會原地打轉不停重試,直到成功獲取本地鎖并完成重試,
接下來,服務呼叫成功,起點服務開始執行自己的本地事務,流程都大同小異,TM端根據業務的執行情況,最終做出二階段決議,Commit或Rollback,
最后,TC向各個分支下達了二階段決議,如果最終決議是Commit,那么各個RM會執行一段異步操作,洗掉undo_log;如果最終決議是Rollback,那么RM端會根據undo_log中記錄的回滾日志做反向補償,
添加依賴項
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
宣告資料源代理
Seata AT之所以能夠實作無感知的編程體驗,其中的一個秘訣就在這個資料源代理上了
在分布式事務的場景上,為了能夠在分支事務開啟/提交等關鍵節點上做一番手腳(比如向Seata注冊分支事務、生成undo_log等),需要用Seata特有的資料源“接管”專案原有的資料源,
創建一個SeataConfiguration的類,用來宣告一個Seata特有的資料源,作為當前專案的DataSrouce代理,
@Configuration
public class SeataConfiguration {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Bean("dataSource")
@Primary
public DataSource dataSourceDelegation(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}
在上面的代碼中,先是創建了一個DruidDataSource作為資料源連接池,并指定其讀取spring.datasoource下的資料庫連接資訊,
在dataSourceDelegation方法中,宣告了一個DataSourceProxy的類,并接收DruidDataSource作為構造器初始化引數,DataSourceProxy是由Seata框架提供的一個資料源代理類,為了確保Spring背景關系使用DataSourceProxy而不是其它三方資料源,在dataSourceDelegation方法上添加了@Primary注解,將其作為javax.sql.DataSource的默認代理類,
添加Seata配置項
spring:
cloud:
alibaba:
seata:
tx-service-group: seata-server-group
seata:
application-id: coupon-customer-serv
registry:
type: nacos
nacos:
application: seata-server
server-addr: localhost:8848
namespace: dev
group: myGroup
cluster: default
service:
vgroup-mapping:
seata-server-group: default
spring.cloud.alibaba.seata.tx-service-group中的分組名稱一定要和seata.service.vgroup-mapping中定義的分組名稱一致,seata-server-group分組所指定的值是default,這個值會被用來獲取Seata Server地址,
在專案啟動的時候,Seata框架會嘗試從Nacos獲取Seata Server的地址資訊,執行這個操作的類是NacosRegistryServiceImpl,在這個類的lookup方法中,Seata使用了下面這行代碼查找seata-server服務,其中clusters引數的值就來自于seata.service.vgroup-mapping.seata-server-group所對應的值,
List<Instance> firstAllInstances = getNamingInstance()
.getAllInstances(getServiceName(), getServiceGroup(), clusters);
實作AT
@GlobalTransactional,它是Seata用來開啟分布式事務的頂層注解,=只要在全域事務“開始”的地方把這個注解添加上去就好了,并不需要在每個分支事務中都宣告它,全域事務碰到任何Exception例外,都會觸發全域事務回滾操作,這個行為是通過GlobalTransactional注解的rollbackFor方法指定的,
@GlobalTransactional(name = "coupon-customer-serv", rollbackFor = Exception.class)
在開啟Seata分布式事務的時候,必須把例外拋出到全域事務的發起方,讓@GlobalTransactional注解的方法能夠感知到這個例外,才能順利觸發事務的回滾,如果開發了統一的例外處理攔截器,記得千萬不要把例外吞掉,
TCC 補償模式
TCC事務模型
TCC名字里這三個字母分別是三個單詞的首字母縮寫,從前到后分別是Try、Confirm和Cancel,這三個單詞分別對應了TCC模式的三個執行階段,每一個階段都是獨立的本地事務,
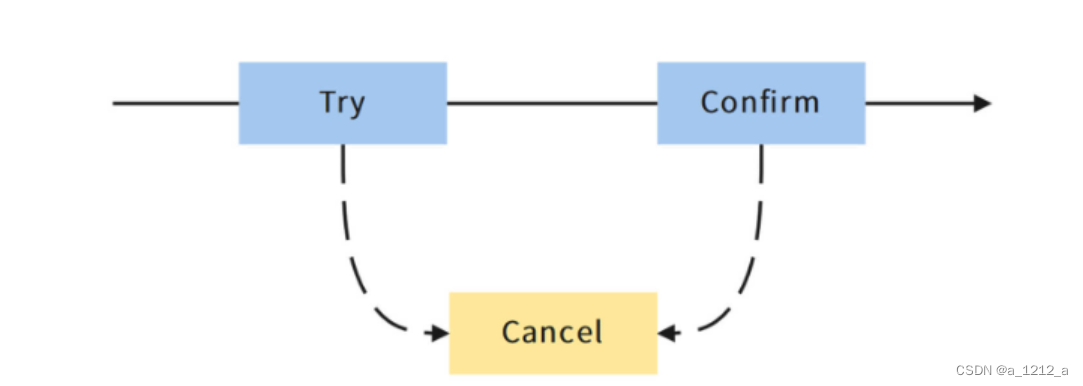
Try階段完成的作業是 預定操作資源(Prepare), 說白了就是“占座”的意思,在正式開始執行業務邏輯之前,先把要操作的資源占上座,
Confirm階段完成的作業是 執行主要業務邏輯(Commit),它類似于事務的Commit操作,在這個階段中,可以對Try階段鎖定的資源進行各種CRUD操作,如果Confirm階段被成功執行,就宣告當前分支事務提交成功,
Cancel階段的作業是 事務回滾(Rollback), 它類似于事務的Rollback操作,在這個階段中,沒有AT方案的undo_log幫做自動回滾,需要通過業務代碼,對Confirm階段執行的操作進行人工回滾,
實作TCC
注冊TCC介面
@LocalTCC
public interface CouponTemplateServiceTCC extends CouponTemplateService {
@TwoPhaseBusinessAction(
name = "deleteTemplateTCC",
commitMethod = "deleteTemplateCommit",
rollbackMethod = "deleteTemplateCancel"
)
void deleteTemplateTCC(@BusinessActionContextParameter(paramName = "id") Long id);
void deleteTemplateCommit(BusinessActionContext context);
void deleteTemplateCancel(BusinessActionContext context);
}
@LocalTCC注解被用來修飾實作了二階段提交的本地TCC介面,而@TwoPhaseBusinessAction注解標識當前方法使用TCC模式管理事務提交,
Try階段所要執行的方法,便是被@TwoPhaseBusinessAction所修飾的deleteTemplateTCC方法了,
在deleteTemplateCommit和deleteTemplateCancel這兩個方法中使用了一個特殊的入參BusinessActionContext,可以使用它傳遞查詢引數,在TCC模式下,查詢引數將作為BusinessActionContext的一部分,在事務背景關系中進行傳遞,
撰寫一階段Prepare邏輯
@Transactional
在一階段Prepare的程序中,執行的是Try邏輯,對資料庫做一個小修改,引入一個名為locked的變數,用來標記當前資源是否被鎖定,
資源不存在的話,在Try階段就會拋出例外,TCC會轉而執行Rollback方法,進不到Commit階段,
撰寫二階段Commit邏輯
@Transactional
二階段Commit就是TCC中的Confirm階段,只要TCC框架執行到了Commit邏輯,那么就代表各個分支事務已經成功執行了Try邏輯,但是別忘了還要將Try階段的資源鎖定解除掉,
撰寫二階段Rollback邏輯
@Transactional
二階段Rollback對應的是TCC中的Cancel階段,如果在Try或者Confirm階段發生了例外,就會觸發TCC全域事務回滾,Seata Server會將Rollback指令發送給每一個分支事務,
TCC慷訓滾
所謂慷訓滾,是在沒有執行Try方法的情況下,TC下發了回滾指令并執行了Cancel邏輯,
比如某個分支事務的一階段Try方法因為網路不可用發生了Timeout例外,或者Try階段執行失敗,這時候TM端會判定全域事務回滾,TC端向各個分支事務發送Cancel指令,這就產生了一次慷訓滾,
處理慷訓滾的正確的做法是,在Cancel階段,應當先判斷一階段Try有沒有執行成功,先是判斷資源是否已經被鎖定,再執行釋放操作,如果資源未被鎖定或者壓根不存在,可以認為Try階段沒有執行成功,這時在Cancel階段直接回傳成功即可,
更為完善的一種做法是,引入獨立的事務控制表,在Try階段中將XID和分支事務ID落表保存,如果Cancel階段查不到事務控制記錄,那么就說明Try階段未被執行,同理,Cancel階段執行成功后,也可以在事務控制表中記錄回滾狀態,這樣做是為了防止另一個TCC的坑,“倒懸”,
TCC倒懸
倒懸又被叫做“懸掛”,它是指TCC三個階段沒有按照先后順序執行,拿剛講過的慷訓滾的例子來說,如果Try方法因為網路問題卡在了網關層,導致鎖定資源超時,這時Cancel階段執行了一次慷訓滾,到目前為止一切正常,但回滾之后,原先超時的Try方法經過網關層的重試,又被后臺服務接收到了,這就產生了一次倒懸場景,即一階段Try在二階段回滾之后被觸發,
在倒懸的情況下,整個事務已經被全域回滾,那么如果再執行一次Try操作,當前資源將被長期鎖定,這就造成了一種類似死鎖的局面,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/545307.html
標籤:其他