一、識別符號
識別符號是指定義的具有特殊意義的詞,例如變數、常量、函式名等等,任何一門語言中都對自己的識別符號有特殊定義的規則,在 Go 語言中,識別符號由字母數字和下劃線組成,并且只能以字母和下劃線開頭,例如:
-
數字、字母和下劃線組成:
123、abc _ -
只能以字母和下劃線開頭:
abc123、_sysVar、123abc -
識別符號區分大小寫:
name、Name、NAME
二、關鍵字和保留字
關鍵字和保留字是指編程語言中預先定義好的具有特殊含義的識別符號, 關鍵字和保留字都不建議用作變數名,會引起混亂和沖突,
1. GO中的關鍵字
break default func interface select case defer go map struct chan else goto package switch const fallthrough if range type continue for import return var
2. GO中的保留字
Constants: true false iota nil ? Types: int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr float32 float64 complex128 complex64 bool byte rune string error ? Functions: make len cap new append copy close delete complex real imag panic recover
三、命名規范
由于Go語言是一門區分大小寫的語言,因此Go從語法層面進行了以下限定:任何需要對外暴露的名字必須以大寫字母開頭,不需要對外暴露的則應該以小寫字母開頭,
當命名(包括常量、變數、型別、函式名、結構欄位等等)以一個大寫字母開頭,如:GetUserName,那么使用這種形式的識別符號的物件就可以被外部包的代碼所使用(程式需要先匯入這個包),這被稱為匯出(類似面向物件語言中的公共屬性); 命名如果以小寫字母開頭,則對包外是不可見的,但是他們在整個包的內部是可見并且可用的(類似面向物件語言中的私有屬性 ),
Go語言中各類情形的建議命名規則如下:
-
變數命名
變數名稱一般遵循駝峰法,首字母根據訪問控制原則大寫或者小寫
1 var userName string 2 var isExist bool
-
常量命名
常量均需使用全部大寫字母組成,并使用下劃線分詞
const SITE_URL = "http://www.chendacheng.com"
-
結構體命名
采用駝峰命名法,首字母根據訪問控制大寫或者小寫
1 type UserInfo struct { 2 Name string, 3 age int, 4 }
-
介面命名
命名規則基本和上面的結構體型別,單個函式的結構名以er作為后綴
1 type Reader interface { 2 Read(p []byte) (n int, err error) 3 }
-
錯誤處理
錯誤處理的原則就是不能丟棄任何有回傳err的呼叫,不要使用_丟棄,必須全部處理,接收到錯誤,要么回傳err,或者使用log記錄下來盡早return,一旦有錯誤發生,馬上回傳,盡量不要使用panic,除非你知道你在做什么,錯誤描述如果是英文必須為小寫,不需要標點結尾,采用獨立的錯誤流進行處理,
1 if err != nil { 2 // 錯誤處理 3 return // 或者繼續 4 } 5 // 正常代碼
-
包命名
盡量保持和目錄保持一致,采取有意義的包名,簡短且不要和標準庫不要沖突,包名應該為小寫單詞,不要使用下劃線或者混合大小寫,
1 package dao 2 package service 3 package main
-
檔案命名
盡量采取簡短且有意義的檔案名,應該為小寫單詞,使用下劃線分隔各個單詞,
1 customer_dao.go 2 user_manage.go
-
單元測驗
單元測驗檔案名要以 _test.go結尾,測驗檔案中的測驗用例的函式名稱必須以 Test 開頭,
四、變數
變數的作用是存盤資料,不同的變數保存的資料型別可能會不一樣,Go 語言中的每一個變數都有自己的型別,變數必須經過宣告才能開始使用,且同一作用域內不支持重復宣告,
1. 變數的作用域
1.1 全域變數和區域變數
變數可以定義在函式內部(函式外的每個陳述句都必須以關鍵字開始,如:var、const、func等),也可以定義在函式內部,定義在函式外部的變數稱為 全域變數,定義在函式內部的變數稱為 區域變數 ,在 GO 語言中,定義的區域變數必須使用,否則編譯代碼的時候將不被通過,定義的全域變數可以不使用,
1 package main 2 ? 3 var name string = "cdc" // 定義一個全域變數 4 ? 5 func main() { 6 ? 7 }
直接編譯通過:
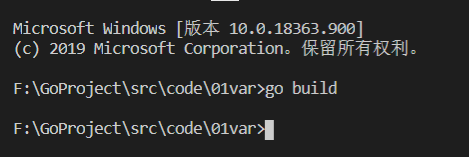
1 package main 2 ? 3 func main() { 4 name := "cdc" // 宣告并初始化了一個區域變數,但是未使用 5 }
直接編譯未通過,報錯:
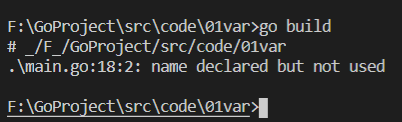
1.2 作用域
-
函式內可以使用全域的變數,但是在全域無法使用區域的變數
1 var name = "cdc" 2 ? 3 func main() { 4 fmt.Printf("%v\n", name) // cdc 5 } 6 func demo() { 7 var name = "cdc" 8 } 9 ? 10 func main() { 11 fmt.Printf("%v\n", name) // undefined: namet 12 ? 13 }
-
代碼執行時,先從函式內部尋找區域變數,找不到再去找全域的變數
1 package main 2 ? 3 import "fmt" 4 ? 5 var name = "cdc" 6 var age = 22 7 ? 8 func main() { 9 ? 10 var name = "ctt" 11 12 ? 13 fmt.Printf("%v\n", name) // ctt 14 fmt.Printf("%v\n", age) // 22 15 }
2. 變數的宣告
2.1 標準宣告方式
變數宣告以關鍵字 var 開頭,變數型別放在變數的后面,行尾無需分號,
1 var name string 2 var age int 3 var isOk bool
2.2 批量宣告
1 var ( 2 a string 3 b int 4 c bool 5 d float32 6 )
注意:在沒有初始化變數之前,不同資料型別的變數會有一個默認值,值為該資料型別對應的0值:
1 package main 2 ? 3 import "fmt" 4 ? 5 func main() { 6 var ( 7 a string 8 b int 9 c bool 10 d float32 11 ) 12 ? 13 fmt.Println(a) // "" 14 fmt.Println(b) // 0 15 fmt.Println(c) // false 16 fmt.Println(d) // 0 17 }
3. 變數初始化
3.1 標準初始化格式
1 var name string = "cdc" 2 var age int = 18 3 ? 4 // 一次宣告多個變數 5 var age, isOk = 18, true
3.2 型別推導
有時候我們會將變數的型別省略,這個時候編譯器會根據等號右邊的值來推導變數的型別完成初始化
1 package main 2 ? 3 import "fmt" 4 ? 5 func main() { 6 var name = "cdc" // 編譯器會根據 “cdc” 推匯出變數 name 是一個字串型別 7 var age = 18 8 ? 9 fmt.Printf("%T\n", name) // string 10 fmt.Printf("%T\n", age) // int 11 }
3.3 短變數宣告
短變數宣告方式只能用于函式內部
1 package main 2 ? 3 import "fmt" 4 ? 5 // 全域變數m 6 var m = 100 7 ? 8 func main() { 9 n := 10 10 m := 200 // 此處宣告區域變數m 11 fmt.Println(m, n) 12 }
3.4 匿名變數
對于宣告的區域變數必須要使用,否則編譯無法通過,如果想要忽略某個值,我們可以使用 匿名變數 來接收該值 ,匿名變數用一個下劃線表示,它不占用命名空間,不會分配記憶體,所以匿名變數之間不存在重復宣告,例如:
1 package main 2 ? 3 import "fmt" 4 ? 5 func function1() (string, int) { 6 return "cdc", 18 7 } 8 ? 9 func main() { 10 var name, _ = function1() 11 fmt.Printf("My name is %s", name) 12 }
匿名變數 _ 并未使用,但是編譯可以通過
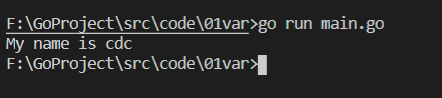
五、常量
常量是指恒定不變的值,多用于定義程式運行期間不會改變的那些值,一旦定義了常量后就無法修改,
1. 標準宣告格式
1 const PI = 3.1415 2 const E = 2.7182
2. 批量宣告
1 const ( 2 STATUS_OK = 200 3 NOT_FOUND = 404 4 )
批量宣告常量時,如果某一行宣告之后沒有賦值,那么后面的常量就默認和上一行一致
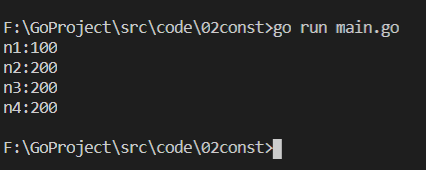
1 package main 2 ? 3 import "fmt" 4 ? 5 const ( 6 n1 = 100 7 n2 = 200 8 n3 9 n4 10 ) 11 ? 12 func main() { 13 fmt.Printf("n1:%v\n", n1) 14 fmt.Printf("n2:%v\n", n2) 15 fmt.Printf("n3:%v\n", n3) 16 fmt.Printf("n4:%v\n", n4) 17 }
編譯執行結果如下,n3、n4 的值都為 200:
3. iota
iota 是go語言的常量計數器,只能在常量的運算式中使用,iota 在 const 關鍵字出現時將被重置為0,const 中每新增一行常量宣告將使 iota 計數一次,可以直接理解 iota 其實就是每一行代碼的索引值,
-
示例1:
1 package main 2 ? 3 import "fmt" 4 ? 5 const ( 6 a1 = iota 7 a2 = iota 8 a3 = iota 9 a4 = iota 10 ) 11 ? 12 func main() { 13 fmt.Printf("a1:%d\n", a1) 14 fmt.Printf("a2:%d\n", a2) 15 fmt.Printf("a3:%d\n", a3) 16 fmt.Printf("a4:%d\n", a4) 17 }
分析:出現了 const 關鍵字,所以 a1 對應的 iota 的值為 0;后面每新增一行常量的宣告,iota 的值就累加1,所以最后列印的結果為:
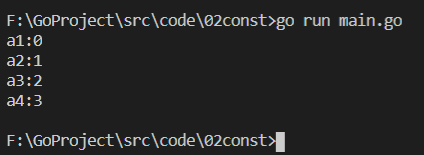
-
示例2,省略
iota:
1 package main 2 ? 3 import "fmt" 4 ? 5 const ( 6 b1 = iota 7 b2 8 b3 9 b4 10 ) 11 ? 12 func main() { 13 fmt.Printf("b1:%d\n", b1) 14 fmt.Printf("b2:%d\n", b2) 15 fmt.Printf("b3:%d\n", b3) 16 fmt.Printf("b4:%d\n", b4) 17 }
分析:出現了 const 關鍵字,所以 b1 對應的 iota 的值為 0;由于常量批量宣告的規則,當某一行宣告之后沒有賦值,那么后面的常量就默認和上一行一致,所以理論上 b2 的值應該也為 iota,每新增一行常量的宣告,iota 的值就累加1,所以 b2 的值應該為1,以此類推,最后列印的結果為:
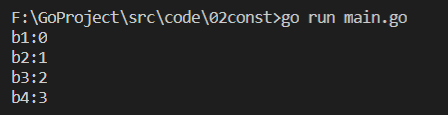
-
示例3,使用
_跳過某些值:
1 package main 2 ? 3 import "fmt" 4 ? 5 func main() { 6 const ( 7 n1 = iota 8 n2 9 _ 10 n4 11 ) 12 ? 13 fmt.Printf("n1: %d\n", n1) 14 fmt.Printf("n2: %d\n", n2) 15 fmt.Printf("n4: %d\n", n4) 16 }
分析:出現了 const 關鍵字,所以 n1 對應的 iota 的值為 0;由于常量批量宣告的規則,當某一行宣告之后沒有賦值,那么后面的常量就默認和上一行一致,所以理論上 n2 的值應該也為 iota,每新增一行常量的宣告,iota 的值就累加1,所以 n2 的值應該為1;雖然匿名變數會被跳過,但是也是作為一個常量宣告的,也會遵循只要新增一行常量宣告 iota 就累加1的規則,所以匿名變數對應的值應該是2,以此類推,最后編譯列印的結果為:
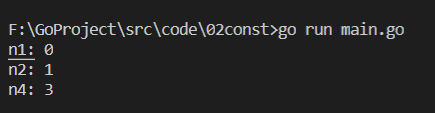
-
示例4,
iota宣告中間插隊:
1 package main 2 ? 3 import "fmt" 4 ? 5 func main() { 6 const ( 7 n1 = iota 8 n2 = 100 9 n3 = iota 10 n4 11 ) 12 ? 13 fmt.Printf("n1: %d\n", n1) 14 fmt.Printf("n3: %d\n", n2) 15 fmt.Printf("n4: %d\n", n4) 16 }
分析:出現了 const 關鍵字,所以 n1 對應的 iota 的值為 0;雖然 n2 沒有使用到 iota,但是 iota 是對當前批量宣告的常量做統計的,只要新增了一行常量宣告,值就累加 1 ,因此宣告 n2 時,iota 還是會加 1,以此類推,最后編譯列印的結果為:
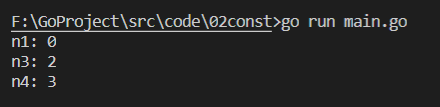
-
示例5,多個
iota定義在一行
1 package main 2 ? 3 import "fmt" 4 ? 5 func main() { 6 const ( 7 n1, n2 = iota + 1, iota + 2 8 n3, n4 = iota + 1, iota + 2 9 ) 10 ? 11 fmt.Printf("n1: %d\n", n1) 12 fmt.Printf("n2: %d\n", n2) 13 fmt.Printf("n3: %d\n", n3) 14 fmt.Printf("n4: %d\n", n4) 15 }
分析:只要每新增了一行常量宣告,iota 值就累加 1 ,但是 n1 和 n2 是在一行宣告的,所以對于 n1 和 n2 ,iota 的值都為 0;到宣告 n3 和 n4 的時候才是新增了一行宣告,這時的 iota 的值才會累加 1,編譯運行的結果如下:
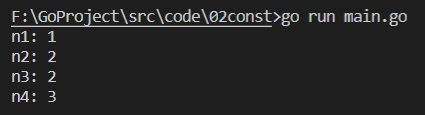
-
示例6,使用
iota定義數量級
1 const ( 2 _ = iota 3 KB = 1 << (10 * iota) 4 MB = 1 << (10 * iota) 5 GB = 1 << (10 * iota) 6 TB = 1 << (10 * iota) 7 PB = 1 << (10 * iota) 8 )
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/545835.html
標籤:其他
上一篇:Ehcache初體驗
下一篇:雙指標